Mysql执行计划字段解释
文章目录
- 一、前言
- 二、如何查看执行计划
- 三、执行计划各字段解释
- 四、select_type
- 4.1、SIMPLE(简单查询)
- 4.1.1、简单的单表查询
- 4.1.2、多表连接查询
- 4.2、PRIMARY(主查询)
- 4.2.1、包含复杂子查询的外层查询
- 4.2.2、UNION语句中的第一个查询
- 4.3、SUBQUERY(子查询)、DEPENDENT SUBQUERY(依赖子查询)、UNCACHEABLE SUBQUERY(不可缓存子查询)
- 4.3.1、SUBQUERY(子查询)
- 4.3.2、DEPENDENT SUBQUERY(依赖子查询)
- 4.3.3、UNCACHEABLE SUBQUERY(不可缓存子查询)
- 4.4、UNION(合并查询)、UNION RESULT(合并查询结果)、DEPENDENT UNION(依赖合并查询)、UNCACHEABLE UNION(不可缓存合并查询)
- 4.4.1、UNION(合并查询)、UNION RESULT(合并查询结果)
- 4.4.2、DEPENDENT UNION(依赖合并查询)
- 4.4.3、UNCACHEABLE UNION(不可缓存合并查询)
- 4.5、DERIVED(派生表)
- 4.6、MATERIALIZED(物化)
- 五、type
- 5.1、system
- 5.2、const
- 5.3、eq_ref
- 5.4、ref
- 5.5、fulltext
- 5.6、ref_or_null
- 5.7、index_merge
- 5.8、unique_subquery
- 5.9、index_subquery
- 5.10、range
- 5.11、index
- 5.12、ALL
- 六、Extra
- 6.1、Using index
- 6.2、Using where
- 6.3、Using temporary
- 6.4、Using filesort
- 6.5、Using index condition
一、前言
每次遇到 sql 优化,查看执行计划,其中的字段是什么含义总是会忘,所以有了这篇文章方便查阅。
二、如何查看执行计划
第一种方法,在 SELECT 语句前面加上 EXPLAIN 关键字
第三种方法,如果用 Navicat 数据库工具的话,点击上面的解释按钮
三、执行计划各字段解释
先贴上 Mysql 官方文档中关于执行计划字段解释的地址:
官网:MySQL 8.0 Reference Manual / Optimization / Understanding the Query Execution Plan / EXPLAIN Output Format
中文网:MySQL 8.0 参考手册 / 第8章优化 / 8.8 了解查询执行计划 / 8.8.2 EXPLAIN 输出格式
| 字段 | 说明 |
|---|---|
| id | 操作的唯一标识符 |
| select_type | 操作的类型 |
| table | 涉及的表名 |
| partitions | 操作涉及的分区 |
| type | 表示使用的连接类型或扫描类型 |
| possible_keys | 可能使用的索引列表 |
| key | 实际选择使用的索引 |
| key_len | 索引键的长度 |
| ref | 连接条件所使用的列或常量 |
| rows | 估计的扫描行数 |
| filtered | 从结果中过滤返回行的百分比 |
| Extra | 额外的信息 |
下面就结合一些实际例子看下 select_type、type、Extra
准备脚本如下:
– 创建用户表
CREATE TABLE user (
id int(11) NOT NULL AUTO_INCREMENT ,
name varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL ,
age int(11) NULL DEFAULT NULL ,
dept_id int(11) NULL DEFAULT NULL ,
remark text CHARACTER SET utf8 COLLATE utf8_general_ci NULL ,
PRIMARY KEY (id),
INDEX index_name_age (name, age) USING BTREE ,
INDEX index_dept_id (dept_id) USING BTREE ,
FULLTEXT INDEX index_remark (remark)
)
ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci
AUTO_INCREMENT=38
ROW_FORMAT=DYNAMIC
;– 初始化用户数据
INSERT INTO user (id, name, age, dept_id, remark) VALUES (‘1’, ‘张三’, ‘20’, ‘1’, ‘abc’);
INSERT INTO user (id, name, age, dept_id, remark) VALUES (‘2’, ‘李四’, ‘18’, ‘1’, ‘bcd’);
INSERT INTO user (id, name, age, dept_id, remark) VALUES (‘3’, ‘王五’, ‘22’, ‘1’, ‘cde’);
INSERT INTO user (id, name, age, dept_id, remark) VALUES (‘4’, ‘赵六’, ‘23’, ‘2’, ‘def’);
INSERT INTO user (id, name, age, dept_id, remark) VALUES (‘5’, ‘孙七’, ‘25’, ‘2’, ‘efg’);
INSERT INTO user (id, name, age, dept_id, remark) VALUES (‘6’, ‘周八’, ‘16’, ‘2’, ‘fgh’);
INSERT INTO user (id, name, age, dept_id, remark) VALUES (‘7’, ‘吴九’, ‘19’, ‘3’, ‘ghi’);
INSERT INTO user (id, name, age, dept_id, remark) VALUES (‘8’, ‘郑十’, ‘13’, ‘3’, ‘hij’);– 创建部门表
CREATE TABLE dept (
id int(11) NOT NULL ,
name varchar(50) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL ,
PRIMARY KEY (id),
INDEX index_name (name) USING BTREE
)
ENGINE=InnoDB
DEFAULT CHARACTER SET=utf8 COLLATE=utf8_general_ci
ROW_FORMAT=DYNAMIC
;– 初始化部门数据
INSERT INTO dept (id, name) VALUES (‘1’, ‘人事部’);
INSERT INTO dept (id, name) VALUES (‘2’, ‘财务部’);
INSERT INTO dept (id, name) VALUES (‘3’, ‘技术部’);
四、select_type
| select_type | 说明 |
|---|---|
| SIMPLE | 简单查询 |
| PRIMARY | 主查询(外部查询) |
| SUBQUERY | 子查询 |
| DEPENDENT SUBQUERY | 依赖子查询 |
| UNCACHEABLE SUBQUERY | 不可缓存子查询 |
| UNION | 合并查询 |
| UNION RESULT | 合并查询结果 |
| DEPENDENT UNION | 依赖合并查询 |
| UNCACHEABLE UNION | 不可缓存合并查询 |
| DERIVED | 派生表 |
| MATERIALIZED | 物化 |
下面针对各种情况举例,不用纠结sql本身的业务含义
4.1、SIMPLE(简单查询)
不包含UNION或者子查询
4.1.1、简单的单表查询
EXPLAIN SELECT * FROM user;

4.1.2、多表连接查询
EXPLAIN SELECT
a.* , b.*
FROM
USER a
INNER JOIN dept b ON b.id = a.dept_id;

4.2、PRIMARY(主查询)
包含复杂子查询的外层查询,或者UNION语句中的第一个查询
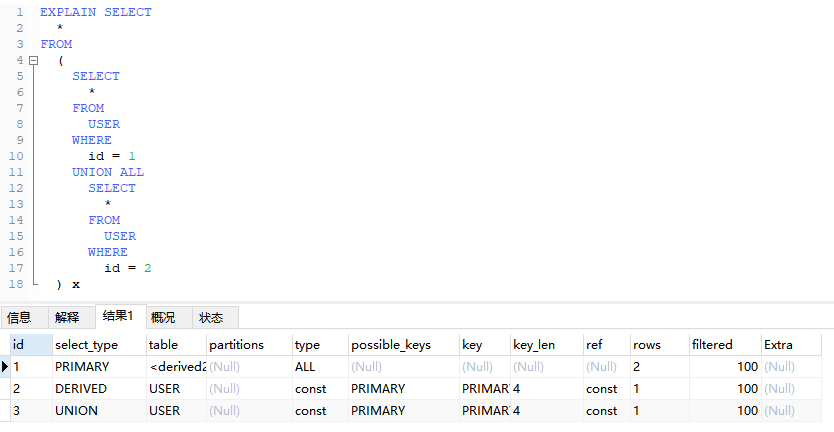
4.2.1、包含复杂子查询的外层查询
EXPLAIN SELECT
*
FROM
(
SELECT
*
FROM
USER
WHERE
id = 1
UNION ALL
SELECT
*
FROM
USER
WHERE
id = 2
) x
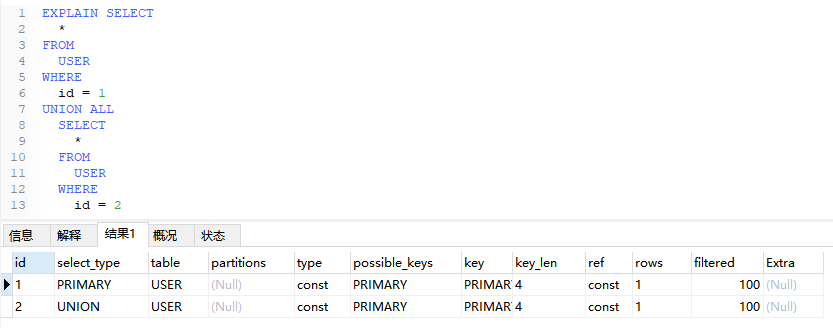
4.2.2、UNION语句中的第一个查询
EXPLAIN SELECT
*
FROM
USER
WHERE
id = 1
UNION ALL
SELECT
*
FROM
USER
WHERE
id = 2
4.3、SUBQUERY(子查询)、DEPENDENT SUBQUERY(依赖子查询)、UNCACHEABLE SUBQUERY(不可缓存子查询)
- SUBQUERY(子查询):子查询是指嵌套在主查询中的查询语句。当 Mysql 优化器将子查询作为单独的查询执行,并将结果作为主查询的条件之一时,
select_type会被标记为 SUBQUERY 。这种情况下,子查询会在主查询之前执行,并将结果传递给主查询使用。 - DEPENDENT SUBQUERY(依赖子查询):当一个子查询需要根据外部查询的结果来确定查询条件或提供必要的数据时,它就被称为依赖子查询。依赖子查询会在外部查询的每一行上执行,并根据外部查询的结果进行计算。
- UNCACHEABLE SUBQUERY(不可缓存子查询):优化器可以根据查询中的各种条件和索引信息来对查询进行优化,以获得更好的性能。然而,某些类型的子查询由于其特殊的性质,无法被优化器缓存。
4.3.1、SUBQUERY(子查询)
如果是SUBQUERY(子查询)需要满足以下条件:
- 子查询不能转化为半连接,关于半连接可参考:8.2.2.1 使用半连接转换优化 IN 和 EXISTS 子查询谓词
- 子查询是不相关子查询
这里补充下不相关子查询和相关子查询的含义
不相关子查询:子查询与主查询之间没有依赖关系,独立于主查询执行,只执行一次,然后将结果用于主查询的条件或者计算
相关子查询:子查询与主查询之间存在依赖关系,子查询的结果依赖于主查询的每一行数据
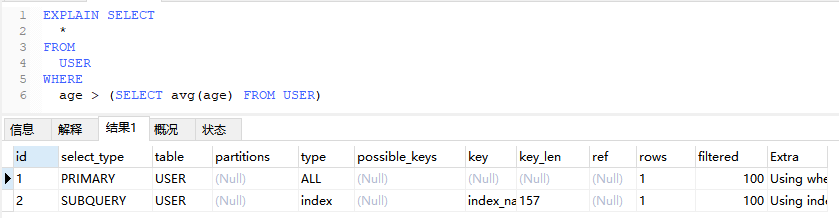
EXPLAIN SELECT
*
FROM
USER
WHERE
age > (SELECT avg(age) FROM USER)
4.3.2、DEPENDENT SUBQUERY(依赖子查询)
如果是DEPENDENT SUBQUERY(依赖子查询)需要满足以下条件:
- 子查询不能转化为半连接
- 子查询是相关子查询
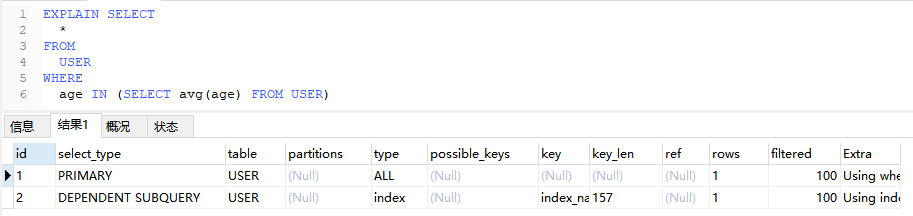
只要把上面例子里的 > 改成 IN,子查询就会变成相关子查询
EXPLAIN SELECT
*
FROM
USER
WHERE
age IN (SELECT avg(age) FROM USER)
4.3.3、UNCACHEABLE SUBQUERY(不可缓存子查询)
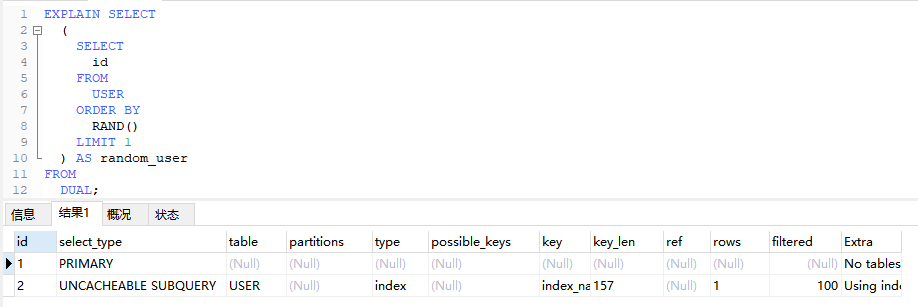
当子查询中使用了不支持查询缓存的函数,会导致该子查询被标记为不可缓存
EXPLAIN SELECT
(
SELECT
id
FROM
USER
ORDER BY
RAND()
LIMIT 1
) AS random_user
FROM
DUAL;
4.4、UNION(合并查询)、UNION RESULT(合并查询结果)、DEPENDENT UNION(依赖合并查询)、UNCACHEABLE UNION(不可缓存合并查询)
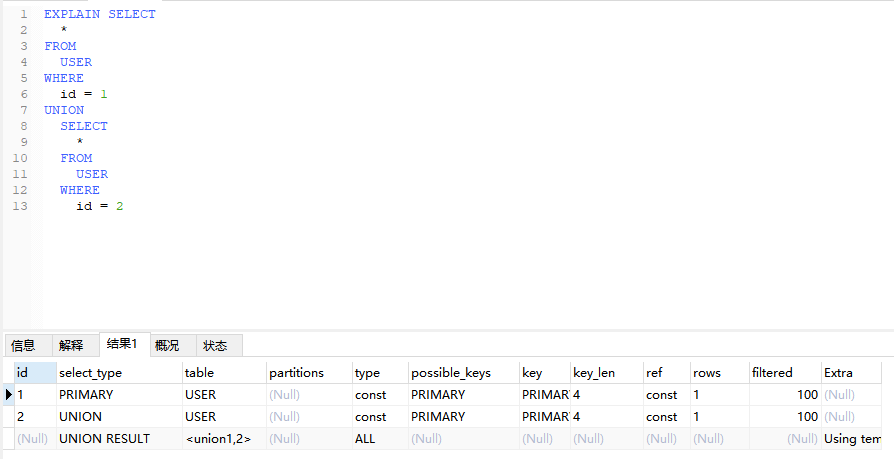
- UNION(合并查询):在 UNION 语句中,第二个及之后的 select 会标记成 UNION。
- UNION RESULT(合并查询结果):当执行 UNION 操作时,MySQL 可能会生成一个 UNION RESULT 来存储合并后的结果集,以供后续处理使用,这个结果集就会标记为 UNION RESULT。
- DEPENDENT UNION(依赖合并查询):依赖于外部查询的 UNION 操作,UNION 的结果取决于外部查询的结果,无法独立地进行计算,通常表现为子查询中,第二个及之后的 select。
- UNCACHEABLE UNION(不可缓存合并查询):和 UNCACHEABLE SUBQUERY(不可缓存子查询)类似,表示一个无法通过查询缓存来进行优化的 UNION 操作。
4.4.1、UNION(合并查询)、UNION RESULT(合并查询结果)
EXPLAIN SELECT
*
FROM
USER
WHERE
id = 1
UNION
SELECT
*
FROM
USER
WHERE
id = 2
4.4.2、DEPENDENT UNION(依赖合并查询)
当UNION作为子查询时,第二个或者后面的查询语句
EXPLAIN SELECT
*
FROM
USER
WHERE
id IN (
SELECT
id
FROM
USER
WHERE
NAME = ‘张三’
UNION ALL
SELECT
id
FROM
USER
WHERE
NAME = ‘李四’
);
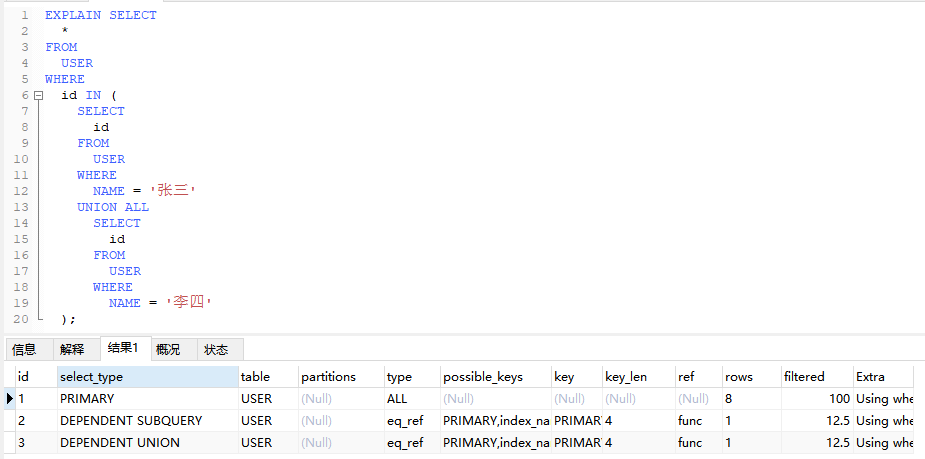
4.4.3、UNCACHEABLE UNION(不可缓存合并查询)
EXPLAIN SELECT
*
FROM
USER
WHERE
id IN (
SELECT
id
FROM
USER
WHERE
NAME = ‘张三’
UNION
SELECT
id
FROM
USER
WHERE
NAME <> ‘张三’
ORDER BY
RAND()
)
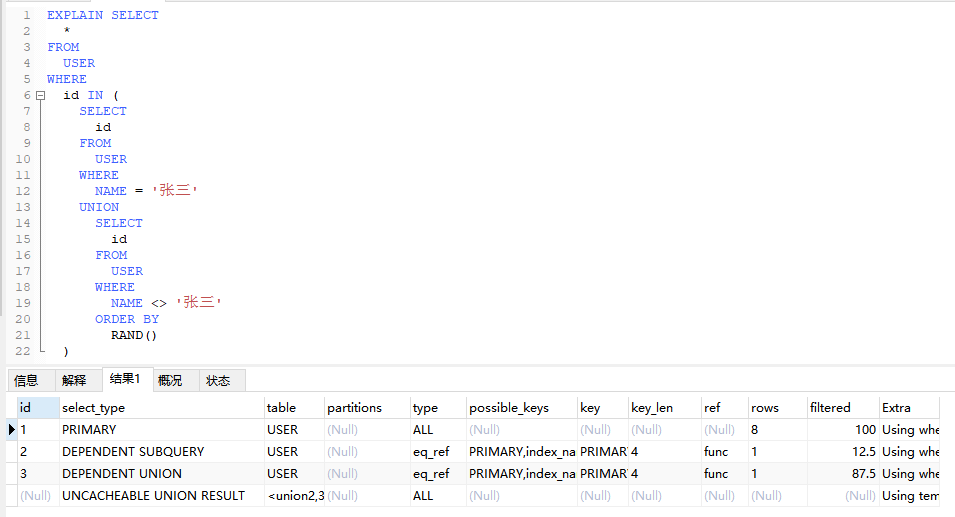
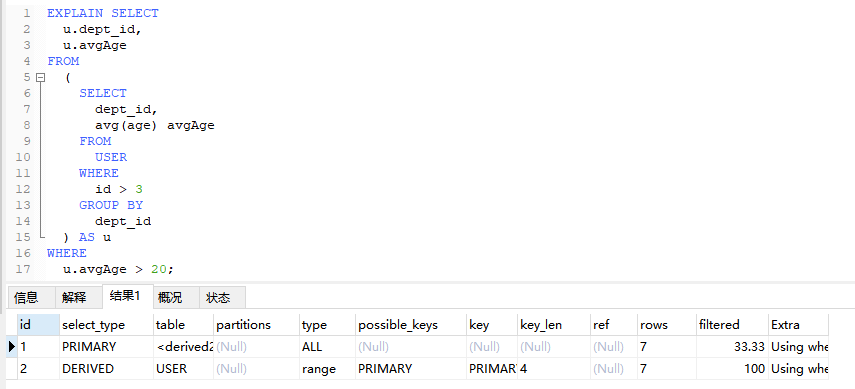
4.5、DERIVED(派生表)
在查询中使用子查询生成的临时表
EXPLAIN SELECT
u.dept_id,
u.avgAge
FROM
(
SELECT
dept_id,
avg(age) avgAge
FROM
USER
WHERE
id > 3
GROUP BY
dept_id
) AS u
WHERE
u.avgAge > 20;
4.6、MATERIALIZED(物化)
当查询包含子查询或派生表,并且优化器认为将其结果保存到临时表中会更有效率时,就会使用物化表。使用物化表可以避免在每次引用子查询或派生表时都需要重新计算结果集,从而提高查询性能。特别是当子查询或派生表的结果集较大或计算复杂时。
五、type
| type | 说明 |
|---|---|
| system | 该表只有一行(相当于系统表),system是const类型的特例 |
| const | 键或唯一索引的等值查询,最多只返回一行数据 |
| eq_ref | 当使用了索引的全部组成部分,并且索引是PRIMARY KEY或UNIQUE NOT NULL 才会使用该类型 |
| ref | 如果仅使用了索引的最左边前缀,或者索引不是PRIMARY KEY或UNIQUE |
| fulltext | 全文索引 |
| ref_or_null | 和ref类似,但是会额外搜索哪些行包含了NULL |
| index_merge | 使用索引合并优化 |
| unique_subquery | 和eq_ref类似,但是使用了IN查询,且子查询是主键或者唯一索引 |
| index_subquery | 和unique_subquery类似,只是子查询使用的是非唯一索引 |
| range | 仅检索给定范围内的行,使用索引来选择行,可以在使用 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, 或 IN()等操作符。 |
| index | 与ALL类似,只是扫描了索引树 |
| ALL | 全表扫描 |
性能从优到劣依次为:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
5.1、system
该表只有一行(相当于系统表),system是const类型的特例
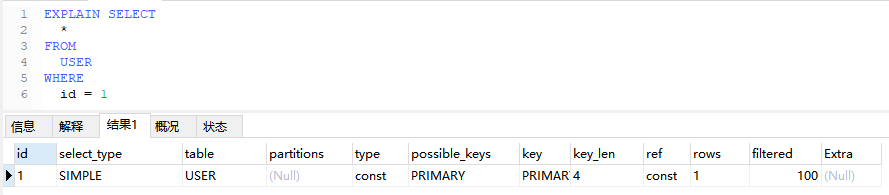
5.2、const
键或唯一索引的等值查询,最多只返回一行数据
EXPLAIN SELECT
*
FROM
USER
WHERE
id = 1
5.3、eq_ref
当使用了索引的全部组成部分,并且索引是PRIMARY KEY或UNIQUE NOT NULL 才会使用该类型
EXPLAIN SELECT
u.* , d.*
FROM
USER u
INNER JOIN dept d ON d.id = u.dept_id
WHERE
u. NAME = ‘张三’;
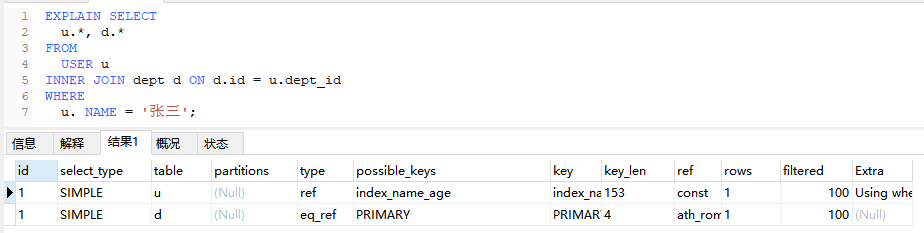
5.4、ref
如果仅使用了索引的最左边前缀,或者索引不是PRIMARY KEY或UNIQUE
EXPLAIN SELECT
*
FROM
USER
WHERE
NAME = ‘张三’;
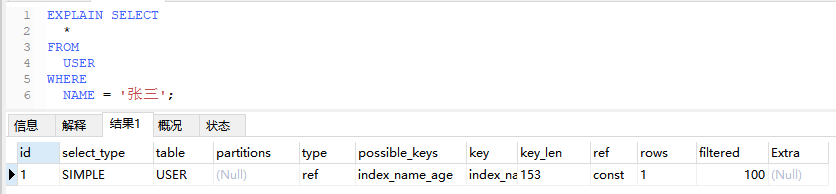
5.5、fulltext
全文索引
EXPLAIN SELECT
*
FROM
USER
WHERE
MATCH (remark) AGAINST (‘c*’ IN boolean MODE);
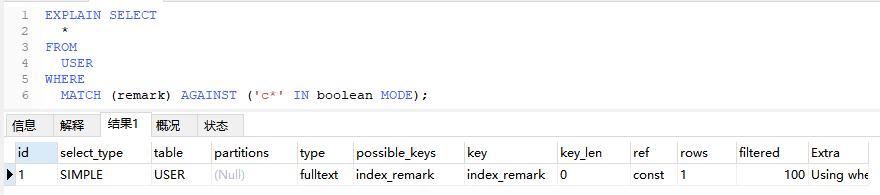
5.6、ref_or_null
和ref类似,但是会额外搜索哪些行包含了NULL
EXPLAIN SELECT
*
FROM
USER
WHERE
NAME = ‘zhangsan’
OR NAME IS NULL;
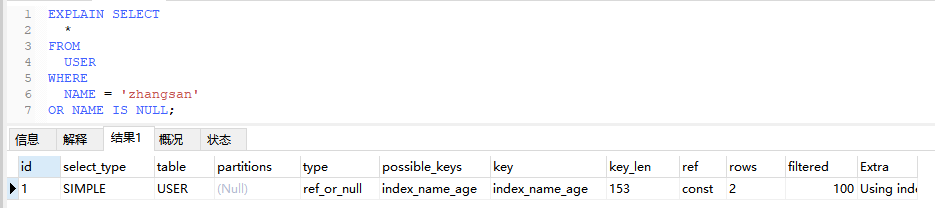
5.7、index_merge
使用索引合并优化
EXPLAIN SELECT
*
FROM
USER
WHERE
id = ‘1’
OR NAME = ‘张三’;

5.8、unique_subquery
和eq_ref类似,但是使用了IN查询,且子查询是主键或者唯一索引
5.9、index_subquery
和unique_subquery类似,只是子查询使用的是非唯一索引
5.10、range
仅检索给定范围内的行,使用索引来选择行,可以在使用 =, <>, >, >=, <, <=, IS NULL, <=>, BETWEEN, LIKE, 或 IN()等操作符。
EXPLAIN SELECT
*
FROM
USER
WHERE
id > 5;
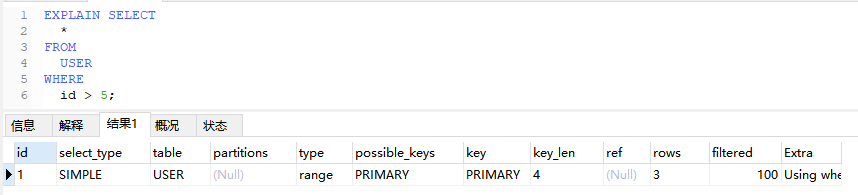
5.11、index
与ALL类似,只是扫描了索引树
5.12、ALL
全表扫描
六、Extra
这里列出一些常见的,其他的参考官方文档
6.1、Using index
查询使用了覆盖索引,查询的所有列都可以从索引中获取,而不需要回表查询数据行。
EXPLAIN SELECT
id
FROM
USER
WHERE
id = 1;
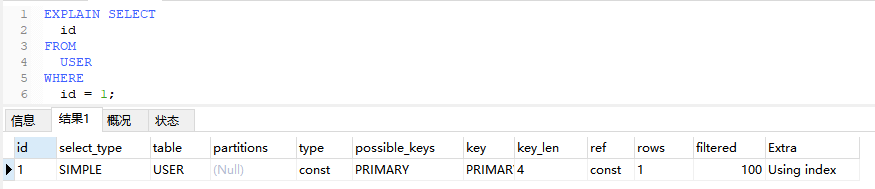
6.2、Using where
在执行查询时会使用WHERE子句对结果进行进一步的筛选,或者全表扫描
EXPLAIN SELECT
*
FROM
USER
WHERE
age > 18;
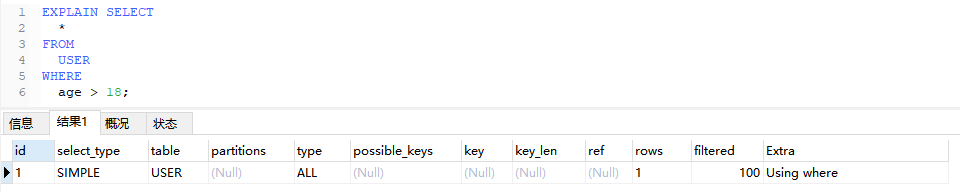
6.3、Using temporary
为了解析查询,MySQL 需要创建一个临时表来保存结果。
EXPLAIN SELECT
NAME
FROM
USER
WHERE
id = 1
UNION
SELECT
NAME
FROM
USER
WHERE
id = 2
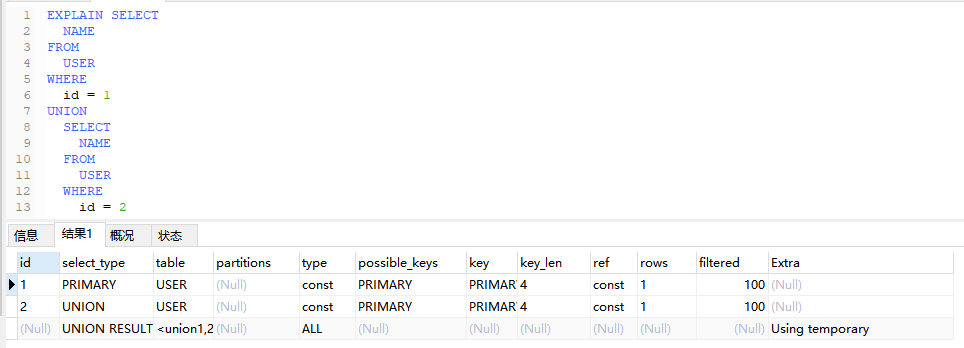
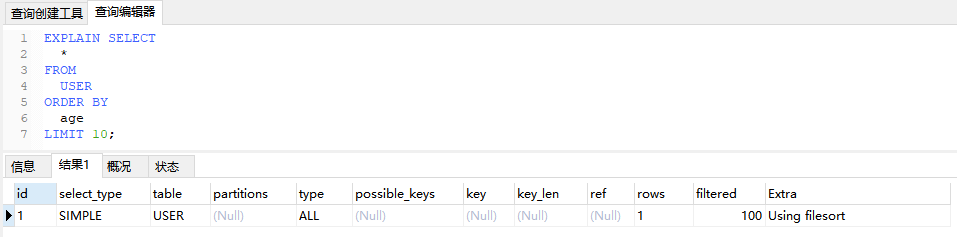
6.4、Using filesort
无法使用索引或其他优化方式直接按照查询语句中的顺序返回结果,而是需要额外的排序操作。会对性能产生一定影响,特别是对大数据量的查询语句。
EXPLAIN SELECT
*
FROM
USER
ORDER BY
age
LIMIT 10;
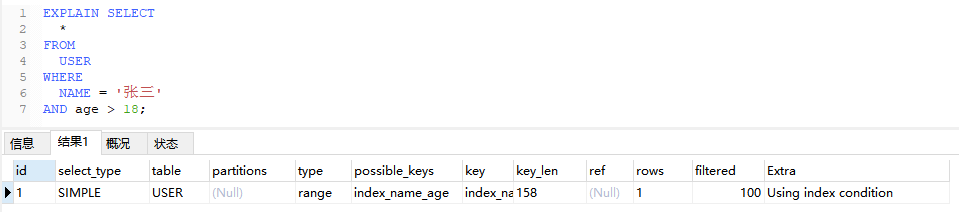
6.5、Using index condition
表示查询使用了索引条件过滤数据,通常表示使用了索引下推,是一个好的优化迹象
索引下推:指 MySQL 将 WHERE 条件中可用于索引的部分推到存储引擎层级进行处理,而不是等到存储引擎返回数据行后再应用 WHERE 条件进行过滤。这样可以减少 IO 操作和数据传输,提高查询性能。
EXPLAIN SELECT
*
FROM
USER
WHERE
NAME = ‘张三’
AND age > 18;
相关文章:
Mysql执行计划字段解释
文章目录 一、前言二、如何查看执行计划三、执行计划各字段解释四、select_type4.1、SIMPLE(简单查询)4.1.1、简单的单表查询4.1.2、多表连接查询 4.2、PRIMARY(主查询)4.2.1、包含复杂子查询的外层查询4.2.2、UNION语句中的第一个…...
Linux -- 线程
文章目录 1. 线程概念1.1 概念1.2 理解(Linux OS角度)1.3 见一见 2. 线程优缺点3. 线程使用3.1 认识线程库3.2 使用3.2.1 线程创建3.2.2 线程等待3.2.3 线程退出3.2.4 线程取消3.2.5 获取线程id3.2.6 线程分离 3.3 理解线程库3.4 证明线程栈3.5 线程局部…...

Android:实时更新时间
心想着也就是更新精确到分钟,不用精确到秒,定时器就没有必要,系统是有广播Intent.ACTION_TIME_TICK可以直接用 动态注册广播 主方法里面调用一下 //要先设置一下当前时间,不然刷新时间会等到1分钟后再刷新 tv_HM.setText(getHM…...

24 鼠标常用事件
鼠标进入:enterEvent鼠标离开:leaveEvent鼠标按下:mousePressEvent鼠标释放:mouseRelaseEvent鼠标移动:mouseMoveEvent 提升为自定义控件MyLabel 代码: //mylabel.h #ifndef MYLABEL_H #define MYLABEL_H#…...
了解 3DS MAX 3D摄像机跟踪设置:第 4 部分
推荐: NSDT场景编辑器助你快速搭建可二次开发的3D应用场景 1. 项目设置 步骤 1 打开“后效”。 打开后效果 步骤 2 转到合成>新合成以创建新合成。 将“宽度”和“高度”值分别设置为 1280 和 720。将帧速率设置为 25,将持续时间设置为 12 秒。单…...

nginx吞吐量调优
调整worker_processes和worker_connections: worker_processes:设置为服务器的CPU核心数或更高。例如,如果服务器有8个CPU核心,可以将worker_processes设置为8。worker_connections:设置每个worker进程所能处理的最大连…...
)
Python操作Excel文件,修改Excel样式(openpyxl)
秋风阁-北溪入江流 文章目录 安装依赖库openpyxlopenpyxl的操作加载文件,获取sheet加载文件load_workbook获取sheet 遍历单元格迭代遍历索引遍历 单元格行高和列宽的修改Excel列号与字母的转换Excel行高修改Excel列宽修改 Excel表格文字对齐属性设置修改单元格框线保…...
7.6-实验:配置SWCRTE(下))
AutoSAR系列讲解(实践篇)7.6-实验:配置SWCRTE(下)
阅读建议: 实验篇是重点,有条件的同学最好跟着做一遍,然后回头对照着AutoSAR系列讲解(实践篇)7.5-OS原理进阶_ManGo CHEN的博客-CSDN博客理解其配置的目的和意义。本篇是接着AutoSAR系列讲解(实践篇)7.4-实验:配置SWC&RTE_ManGo CHEN的博客-CSDN博客的实验篇接着做…...
【node】使用express+gitee搭建图床,并解决防盗链问题
首先创建一个gitee的项目,详细步骤我就不一一说明 注解:大家记得将这个项目开源,还有记得获取自己的私钥,私钥操作如下: node依赖下载: "axios": "cors": "express"…...
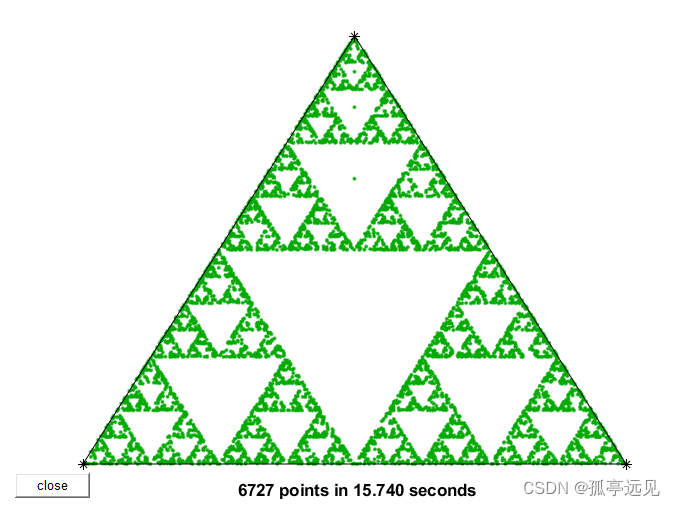
蕨型叶分形
目录 要点 基本语句 EraseMode 习题 1 设置颜色 2 旋转蕨型叶图 3 枝干 4 塞平斯基三角形 要点 蕨型叶是通过一个点的反复变换产生的,假设x是一个含有两个分量的向量,可以用来表示平面内的一个点,则可以用Axb的形式对其进行变换。 基本…...
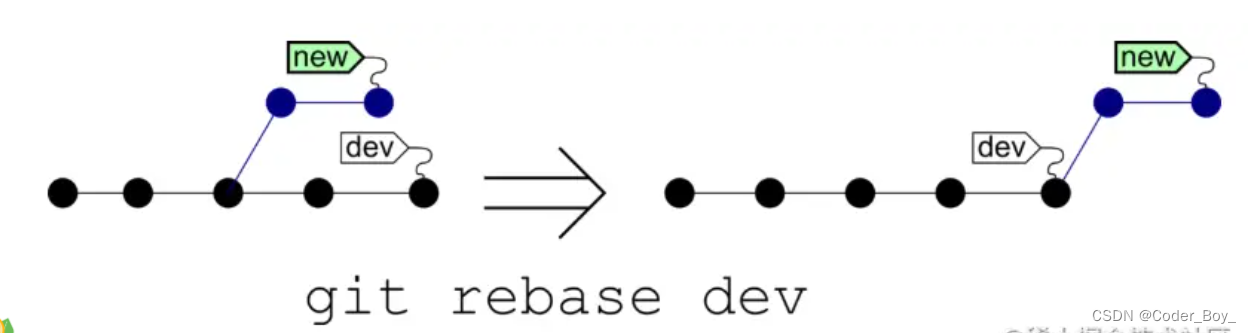
DevOps系列文章之 Git知识大全
Git常用命令 配置Git-SSH 配置Git的user name以及Git要关联的邮箱email git config --global user.name your name git config --global user.email your email 生成密钥 ruby 复制代码 $ ssh-keygen -t rsa -C "your email" 按三个回车,跳过设置密码&am…...
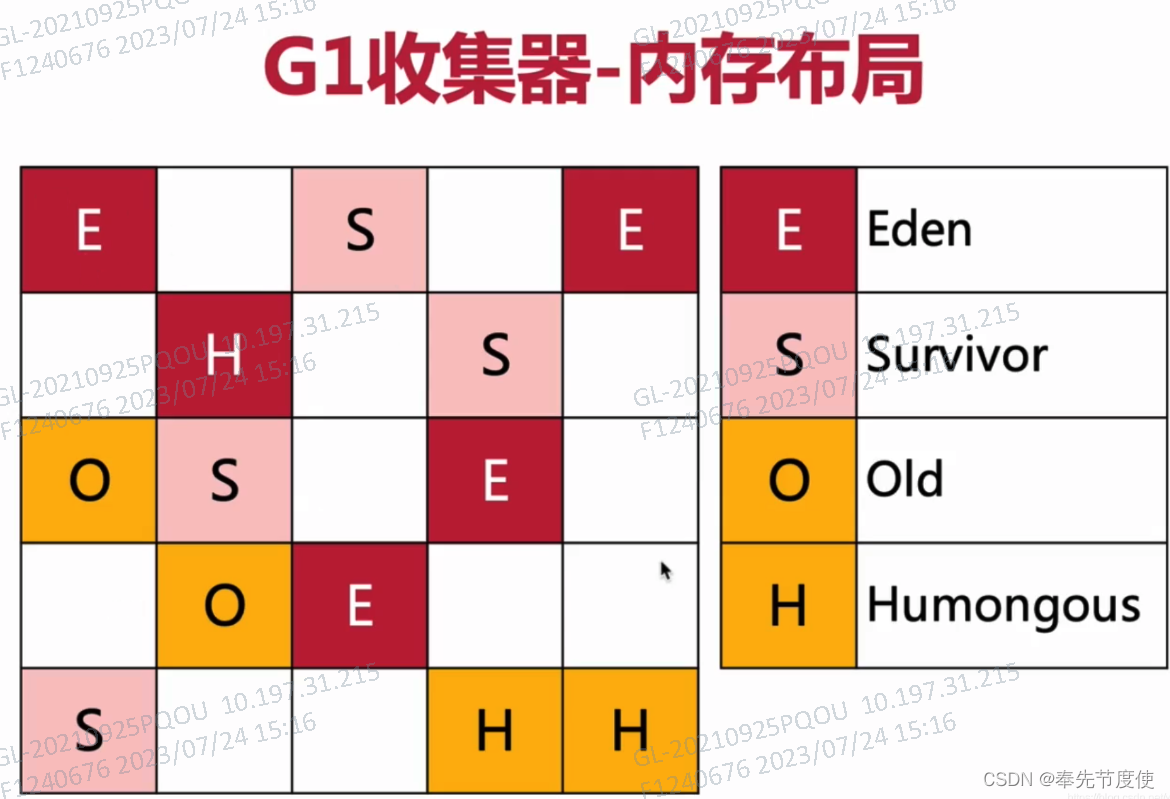
JVM理论(六)执行引擎--垃圾回收
概述 垃圾: 指的是在运行程序中没有任何指针指向的对象垃圾回收目的: 为了及时清理空间使得程序可以正常运行垃圾回收机制: JVM采取的是自动内存管理,即JVM负责对象的创建以及回收,将程序员从繁重的内存管理释放出来,更加专注业务的开发垃圾回收区域: 频繁收集Young区(新生代)…...

贪心算法重点内容
贪心算法重点内容 4.1部分背包 按照单位重量的价值排序 4.2最小生成树 两种算法 4.3单源最短路径 4.4哈夫曼树...

基于深度学习的高精度交通信号灯检测系统(PyTorch+Pyside6+YOLOv5模型)
摘要:基于深度学习的高精度交通信号灯检测识别可用于日常生活中检测与定位交通信号灯目标,利用深度学习算法可实现图片、视频、摄像头等方式的交通信号灯目标检测识别,另外支持结果可视化与图片或视频检测结果的导出。本系统采用YOLOv5目标检…...
【3D目标检测】DSVT-2023CVPR
论文:https://arxiv.org/pdf/2301.06051.pdf 作者:北大,华为 代码:https://github.com/Haiyang-W/DSVT ( OpenPCDet 框架已集成) 讲解:实时部署!DSVT:3D动态稀疏体素Tr…...
我在VScode学Python(Python函数,Python模块导入)
我的个人博客主页:如果’真能转义1️⃣说1️⃣的博客主页 (1)关于Python基本语法学习---->可以参考我的这篇博客《我在VScode学Python》 (2)pip是必须的在我们学习python这门语言的过程中Python ---->&a…...

【目标跟踪】1、基础知识
文章目录 一、卡尔曼滤波二、匈牙利匹配 一、卡尔曼滤波 什么是卡尔曼滤波?——状态估计器 卡尔曼滤波用于在包含不确定信息的系统中做出预测,对系统下一步要做什么进行推测,且会结合推测值和观测值来得到修正后的最优值卡尔曼滤波就是利用…...

33. 搜索旋转排序数组
题目描述 整数数组 nums 按升序排列,数组中的值 互不相同 。 在传递给函数之前,nums 在预先未知的某个下标 k(0 < k < nums.length)上进行了 旋转,使数组变为 [nums[k], nums[k1], ..., nums[n-1], nums[0], n…...

接口自动化测试要做什么?8个步骤讲的明明白白(小白也能看懂系列)
先了解下接口测试流程: 1、需求分析 2、Api文档分析与评审 3、测试计划编写 4、用例设计与评审 5、环境搭建(工具) 6、执行用例 7、缺陷管理 8、测试报告 那"接口自动化测试"怎么弄?只需要在上篇文章的基础上再梳理下就…...

Flutter 自定义 虚线 分割线
学习使用Flutter 进行 虚线 自定义控件 练习 // 自定义虚线 (默认是垂直方向) class DashedLind extends StatelessWidget {final Axis axis; // 虚线方向final double dashedWidth; // 根据虚线的方向确定自己虚线的宽度final double dashedHeight; //…...

聊天记录丢失?这款开源工具让数据安全不再愁
聊天记录丢失?这款开源工具让数据安全不再愁 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter 你是否曾经历过手机意外损坏后丢失数年聊天记录的痛苦࿱…...
)
【PAT甲级真题】- Shopping in Mars (25)
题目来源 Shopping in Mars (25) 题目描述点击链接自行查看 注意点: 输出时按照区间左端点从小到大输出 思路简介 简单的滑动窗口 我做了一个小处理 因为题目实际上要求找的是大于等于目标值的区间 所以移动左指针的条件写成 l>r&&sum>m 这样我认…...

3步突破3D点云标注效率瓶颈,让训练数据生成速度提升60%
3步突破3D点云标注效率瓶颈,让训练数据生成速度提升60% 【免费下载链接】labelCloud 项目地址: https://gitcode.com/gh_mirrors/la/labelCloud 在自动驾驶、机器人导航和AR/VR等领域,3D点云标注是构建精确模型的关键步骤。然而,传统…...

VibeVoice语音合成效果展示:印度英语in-Samuel_man技术讲座样例
VibeVoice语音合成效果展示:印度英语in-Samuel_man技术讲座样例 1. 真实语音合成效果体验 今天我要带大家体验一个让人惊艳的语音合成技术——VibeVoice实时语音合成系统。这不是普通的文字转语音工具,而是一个能够生成极其自然、富有表现力的人工智能…...

OpenClaw配置备份指南:Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF模型参数迁移方案
OpenClaw配置备份指南:Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF模型参数迁移方案 1. 为什么需要备份OpenClaw配置 上周我的主力开发机突然硬盘故障,导致精心调校三个月的OpenClaw配置全部丢失。最痛心的不是框架重装,而是那些…...

别再死记硬背ATT报文了!用Wireshark抓包实战,带你搞懂BLE通信里Handle和UUID的映射过程
实战拆解BLE通信:用Wireshark透视Handle与UUID的动态映射 当你第一次看到BLE设备通信时,那些十六进制数字在屏幕上闪烁,就像在看天书。Handle、UUID、ATT报文——这些概念在文档里写得清清楚楚,但真正抓包分析时,却总感…...

书匠策AI:解锁毕业论文写作新姿势,你的学术“超级大脑”已上线!
毕业季的钟声敲响,论文写作的“战役”也随之打响。面对堆积如山的文献、错综复杂的逻辑框架,以及那令人抓狂的格式要求,你是不是也感到力不从心,甚至开始怀疑人生?别怕,今天咱们就来认识一位学术界的“超级…...

OpenClaw+GLM-4.7-Flash隐私方案:本地化处理敏感数据
OpenClawGLM-4.7-Flash隐私方案:本地化处理敏感数据 1. 为什么需要本地化隐私方案 去年我在帮一家诊所设计病历管理系统时,遇到了一个棘手问题:他们需要自动化处理患者检查报告,但又担心将敏感数据上传到云端存在泄露风险。这促…...

新手入门:在快马上亲手实现第一个限流器,看懂‘rate limit exceeded’
最近在学习后端开发时,经常遇到"rate limit exceeded"这个错误提示。作为新手,一开始完全不明白这是什么意思,直到在InsCode(快马)平台上动手实现了一个简单的限流器,才真正理解了它的原理。今天就来分享一下这个入门项…...
Mamba模型实战:如何用S6替代Transformer处理长文本(附代码示例)
Mamba模型实战:如何用S6替代Transformer处理长文本(附代码示例) 在自然语言处理领域,Transformer架构因其强大的注意力机制而长期占据主导地位。然而,当面对长文本处理任务时,Transformer的二次方计算复杂度…...