《零基础入门学习Python》第056讲:论一只爬虫的自我修养4:网络爬图
今天我们结合前面学习的知识,进行一个实例,从网络上下载图片,话说我们平时闲来无事会上煎蛋网看看新鲜事,那么,熟悉煎蛋网的朋友一定知道,这里有一个 随手拍 的栏目,我们今天就来写一个爬虫,自动抓取每天更新的 随手拍。
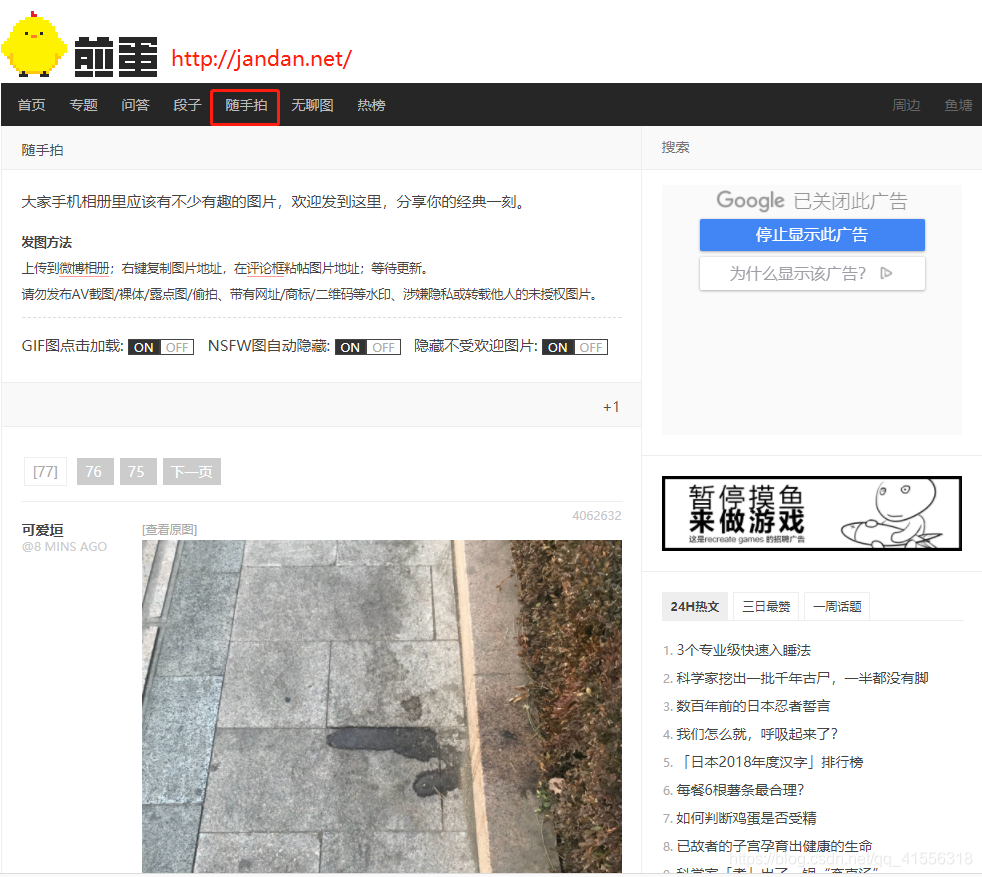
要写爬虫,首先要做的第一件事就是踩点,主动发现网页之间的规律,还有图片链接之间有什么规律,例如说,该网站的链接形式为:http://jandan.net/ooxx/page-‘页码数’#comments,(页码数应该小于等于当天的页码数(即目前最大页码数)),
1.那我们怎样获取目前最大的页码数呢(最新页码),我们在页码[77]这个位置点击右键,审查元素,看到了:<span class="current-comment-page">[77]</span>
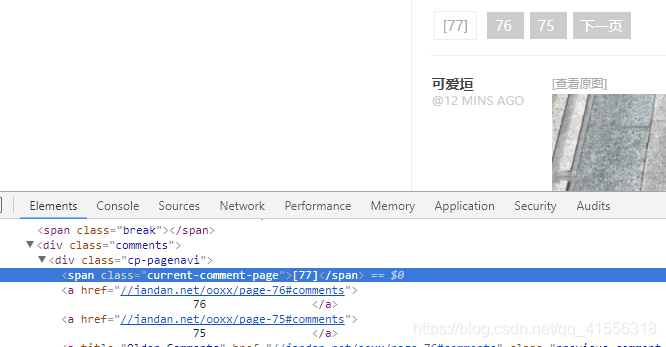
我们完全可以通过搜索 current-comment-page 在后面偏移 3 位就可以得到 77 这个最新的页面,因为你不能去输入一个具体的数字,因为这里的数字每天都会改变。
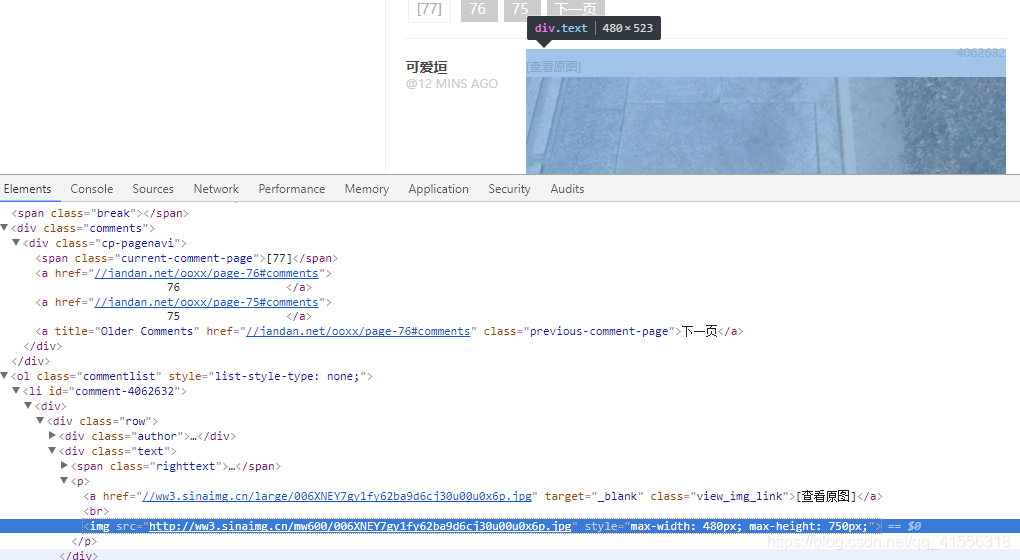
2.我们在图片的位置点击右键,审查元素,发现了图片的地址,都是来自于新浪,然后都在 img 标签里,我们就可以使用 img src 作为关键词来进行查找,搜索到了图片的地址就可以参照我们之前下载一只猫的例子了。把下面图片的地址用 urlopen() 打开,然后将其 save 到一个文件里去(二进制),就可以了。
<img src="http://ww3.sinaimg.cn/mw600/006XNEY7gy1fy62ba9d6cj30u00u0x6p.jpg" style="max-width: 480px; max-height: 750px;">
我们弄清楚了以上几点,就可以开始写我们的爬虫程序啦.....
(我们抓取前10页的图片,保存到指定的本地文件夹中)
下面是老师讲的代码:
-
#从煎蛋网的随手拍栏目下载图片 -
import urllib.request -
import os -
import random -
def url_open(url): -
req = urllib.request.Request(url) -
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.65 Safari/537.36') -
#使用代理(就加入下面五行) -
#proxies = ['119.6.144.70:81', '111.1.36.9:80', '203.144.144.162:8080'] -
#proxy = random.choice(proxies) -
#proxy_support = urllib.request.ProxyHandler({'http':proxy}) -
#opener = urllib.request.build_opener(proxy_support) -
#urllib.request.install_opener(opener) -
response = urllib.request.urlopen(url) -
html = response.read() -
return html -
def get_page(url): #得到最新页面的页码数 -
html = url_open(url) -
html = html.decode('utf-8') #因为要以字符串的形式查找,所以要 decode -
#然后就是查找 html 中的 'current-comment-page' -
a = html.find( 'current-comment-page') + 23 #加上 23 位偏移就刚到到页码数的第一位数字 -
b = html.find(']', a) #找到 a 位置之后的第一个方括号所在位置的索引坐标 -
return html[a : b] #这就是最新的页码数啦 -
def find_imgs(url): #给一个页面的链接,返回所有图片地址组成的列表 -
html = url_open(url).decode('utf-8') -
img_addrs = [] #声明一个保存图片地址的列表 -
#查找图片地址 -
a = html.find('img src=') -
while a != -1: -
b = html.find('.jpg', a, a+255) #在 a 到 a+255 区间找 '.jpg',防止有不是 '.jpg' 格式的图片 -
#如果 b 找不到,b 就返回 -1 -
if b != -1: -
img_addrs.append(html[a+9: b+4]) -
else: -
b = a + 9 -
a = html.find('img src=', b) -
return img_addrs -
def save_imgs(folder, img_addrs): -
for each in img_addrs: -
filename = each.split('/')[-1] -
with open(filename, 'wb') as f: -
img = url_open(each) -
f.write(img) -
def download_figures(folder = 'figures', page = 10): -
os.mkdir(folder) #创建文件夹 -
os.chdir(folder) -
url = "http://jandan.net/ooxx/" #随手拍栏目的链接,也是最新页面的链接 -
page_num = int(get_page(url)) #得到最新页面的页码数 -
for i in range(page): -
page_url = url + 'page-' + str(page_num) + '#comments' #得到要爬取的页面的链接 -
print(page_url) -
img_addrs = find_imgs(page_url) #得到页面所有图片的地址,保存为列表 -
save_imgs(folder, img_addrs) #保存图片到本地文件夹 -
page_num -= 1 #逐步找到前几个页面 -
if __name__ == '__main__': -
download_figures()
但是现在,煎蛋网用这段代码是无法实现的了,主要问题在于 没有办法爬取到 .jpg,这是因为这个网站已经被加密了。
怎样判断一个网站被加密了,就是
使用urllib.urlopen导出html文本和审查元素中相应字段对不上。
以后你会发现对不上是常态,一般是JS加密的 可以说大一点的网站这些信息都会对不上。
那怎么解决呢?
目前我只用的一种方法就是:使用selenium爬取js加密的网页
需要详细讲解的可以查看:python使用selenium爬取js加密的网页
所以呢,我的代码就是下面这样子了:
-
#从加密的煎蛋网的随手拍栏目下载图片 -
import os -
from selenium import webdriver -
import urllib.request -
def url_open(url): #返回普通不加密网页的源码(速度快) -
req = urllib.request.Request(url) -
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36') -
response = urllib.request.urlopen(url) -
html = response.read() -
return html -
def url_open_jm(url): #返回加密网页的源码(速度慢) -
chrome = webdriver.Chrome() -
chrome.get(url) -
html = chrome.page_source -
return html #返回的就是字符串 -
''' -
def get_page(url): #得到最新页面的页码数(可以使用不加密读码得到,为了加快速度) -
html = url_open(url) -
#然后就是查找 html 中的 'current-comment-page' -
a = html.find( 'current-comment-page') + 23 #加上 23 位偏移就刚到到页码数的第一位数字 -
b = html.find(']', a) #找到 a 位置之后的第一个方括号所在位置的索引坐标 -
return html[a : b] #这就是最新的页码数啦 -
''' -
def get_page(url): #得到最新页面的页码数 -
html = url_open(url) -
html = html.decode('utf-8') #因为要以字符串的形式查找,所以要 decode -
#然后就是查找 html 中的 'current-comment-page' -
a = html.find( 'current-comment-page') + 23 #加上 23 位偏移就刚到到页码数的第一位数字 -
b = html.find(']', a) #找到 a 位置之后的第一个方括号所在位置的索引坐标 -
return html[a : b] #这就是最新的页码数啦 -
def find_imgs(url): #给一个页面的链接,返回所有图片地址组成的列表 -
html = url_open_jm(url) #这个必须使用加密打开的方式 -
img_addrs = [] #声明一个保存图片地址的列表 -
#查找图片地址 -
#加密的网页破解后得到的图像在这里: -
#<img src="http://ww3.sinaimg.cn/mw600/006XNEY7gy1fy66dacugfj30qh0zkdhu.jpg" -
#所以要先找jpg,然后找img src= -
a = html.find('.jpg') -
while a != -1: -
b = html.rfind('img src=', a-100, a) #在 a-100 到 a区间找 'img src=',必须反向查找 -
#如果 b 找不到,b 就返回 -1 -
if b != -1: -
img_addrs.append(html[b+9: a+4]) -
a = html.find('.jpg', a+4) -
for each in img_addrs: -
print(each) -
return img_addrs -
def save_imgs(folder, img_addrs): -
for each in img_addrs: -
filename = each.split('/')[-1] -
with open(filename, 'wb') as f: -
img = url_open(each) -
f.write(img) -
def download_figures(folder = 'figures', page = 2): -
os.mkdir(folder) #创建文件夹 -
os.chdir(folder) -
url = "http://jandan.net/ooxx/" #随手拍栏目的链接,也是最新页面的链接 -
page_num = int(get_page(url)) #得到最新页面的页码数 -
for i in range(page): -
page_url = url + 'page-' + str(page_num) + '#comments' #得到要爬取的页面的链接 -
print(page_url) -
img_addrs = find_imgs(page_url) #得到页面所有图片的地址,保存为列表 -
save_imgs(folder, img_addrs) #保存图片到本地文件夹 -
page_num -= 1 #逐步找到前几个页面 -
if __name__ == '__main__': -
download_figures()
完美实现目标,只不过selenium 的速度是真的慢,以后如果有更好的办法,会继续改进的,也希望大家多多批评指导。
相关文章:
《零基础入门学习Python》第056讲:论一只爬虫的自我修养4:网络爬图
今天我们结合前面学习的知识,进行一个实例,从网络上下载图片,话说我们平时闲来无事会上煎蛋网看看新鲜事,那么,熟悉煎蛋网的朋友一定知道,这里有一个 随手拍 的栏目,我们今天就来写一个爬虫&…...
)
23.7.26总结(博客项目)
接下来要完成: 从主页面点击进入时,通过作者id从数据库查找作者的nickname点击文章收藏(需要有收藏列表)首页还要加最新发布,点赞收藏最多作者名得改成文章作者(通过user_id从user表中拿数据)消…...
安全第一天
1. 编码 1.1 ASCLL编码 ASCII 是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。它是最通用的信息交换标准,并等同于国际标准ISO/IEC 646。 1.2 URL编码 URL:(统一资源定位器、定位地址,俗称网页…...

SpringCloud学习路线(12)——分布式搜索ElasticSeach数据聚合、自动补全、数据同步
一、数据聚合 聚合(aggregations): 实现对文档数据的统计、分析、运算。 (一)聚合的常见种类 桶(Bucket)聚合: 用来做文档分组。 TermAggregation: 按照文档字段值分组…...

cloudstack的PlugNicCommand的作用
PlugNicCommand是CloudStack中的一个命令,用于将一个网络接口卡(NIC)插入到虚拟机实例中。它的作用是将一个已存在的NIC连接到指定的虚拟机,以扩展虚拟机的网络功能。 具体来说,PlugNicCommand可以完成以下几个步骤&a…...
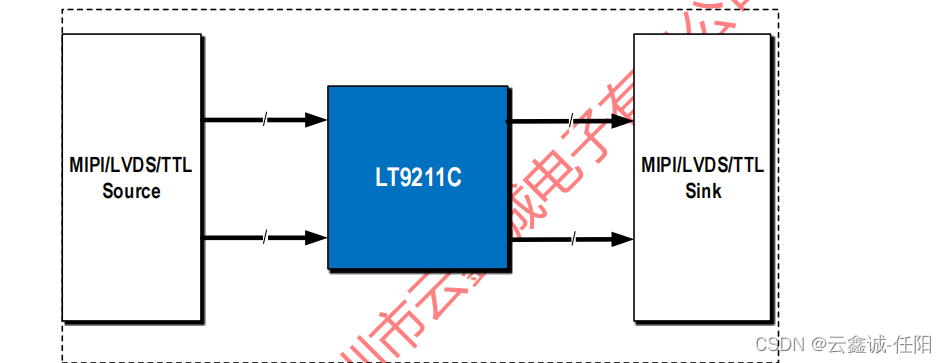
LT9211C 是一款MIPI/RGB/2PORT LVDS互转的芯片
LT9211C 1.描述: Lontium LT9211C是一个高性能转换器,可以在MIPI DSI/CSI-2/双端口LVDS和TTL之间相互转换,除了24位TTL到24位TTL,并且不推荐同步和DE的2端口10位LVDS和24位TTL之间的转换。LT9211C反序列化输入的MIPI/LVDS/TTL视…...
)
【Rust 基础篇】Rust 通道(Channel)
导言 在 Rust 中,通道(Channel)是一种用于在多个线程之间传递数据的并发原语。通道提供了一种安全且高效的方式,允许线程之间进行通信和同步。本篇博客将详细介绍 Rust 中通道的使用方法,包含代码示例和对定义的详细解…...
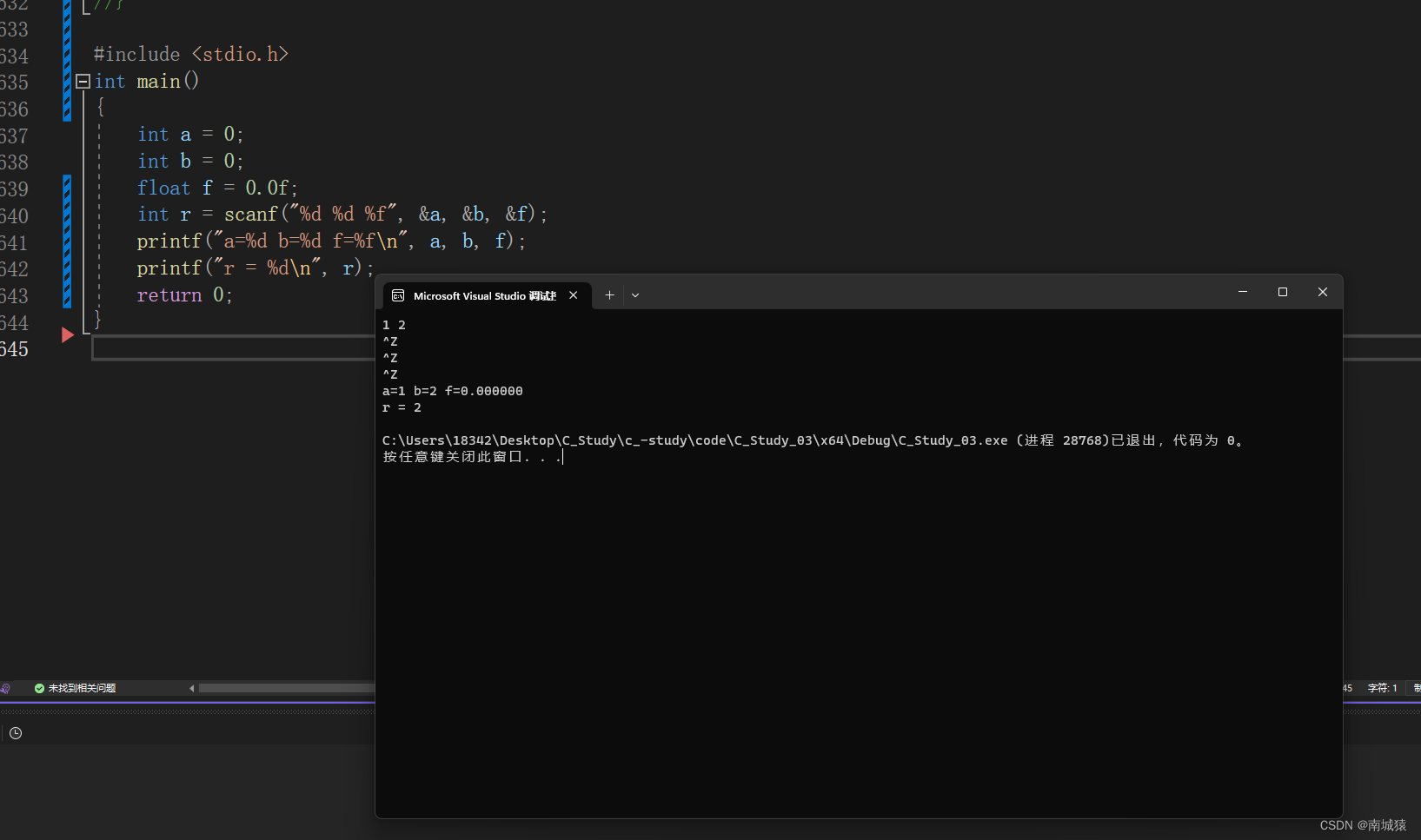
学习 C语言第二天 :C语言数据类型和变量(下)
目录: 1.变量的介绍以及存储 2.算术操作符、赋值操作符、单目操作符 3.scanf和printf的介绍 1.变量的介绍以及存储 1.1.变量的创建 了解了什么是类型了,类型是用来创建变量的。 变量是什么呢?在C语言当中不经常变的量称为常量,经常…...
【Kubernetes资源篇】ingress-nginx最佳实践详解
文章目录 一、Ingress Controller理论知识1、Ingress Controller、Ingress简介2、四层代理与七层代理的区别3、Ingress Controller中封装Nginx,为什么不直接用Nginx呢?4、Ingress Controller代理K8S内部Pod流程 二、实践:部署Ingress Control…...

Java基础阶段学习哪些知识内容?
Java是一种面向对象的编程语言,刚接触Java的人可能会感觉比较抽象,不要着急可以先从概念知识入手,先了解Java,再吃透Java,本节先来了解下Java的基础语法知识。 对象:对象是类的一个实例,有状态…...

【HISI IC萌新虚拟项目】ppu整体uvm验证环境搭建
关于整个虚拟项目,请参考: 【HISI IC萌新虚拟项目】Package Process Unit项目全流程目录_尼德兰的喵的博客-CSDN博客 前言 本篇文章完成ppu整体uvm环境搭建的指导,在进行整体环境搭建之前,请确认spt_utils、cpu_utils和ral_model均已经生成。此外,如果参考现在的工程目录…...

图像处理之hough圆形检测
hough检测原理 点击图像处理之Hough变换检测直线查看 下面直接描述检测圆形的方法 基于Hough变换的圆形检测方法 对于一个半径为 r r r,圆心为 ( a , b ) (a,b) (a,b)的圆,我们将…...
 vue3+vite+ts)
el-upload文件上传(只能上传一个文件且再次上传替换上一个文件) vue3+vite+ts
组件: <template><el-upload class"upload-demo" v-model:file-list"fileList" ref"uploadDemo" action"/public-api/api/file" multiple:on-preview"handlePreview" :on-remove"handleRemove&quo…...

随手笔记——根据点对来估计相机的运动综述
随手笔记——根据点对来估计相机的运动综述 说明计算相机运动 说明 简单介绍3种情况根据点对来估计相机运动所使用的方法 计算相机运动 有了匹配好的点对,接下来,要根据点对来估计相机的运动。这里由于相机的原理不同分为: 当相机为单目时…...

ip校园广播音柱特点
ip校园广播音柱特点IP校园广播音柱是一种基于IP网络技术的音频播放设备,广泛应用于校园、商业区、公共场所等地方。它可以通过网络将音频信号传输到不同的音柱设备,实现远程控制和集中管理。IP校园广播音柱具备以下特点和功能:1. 网络传输&am…...
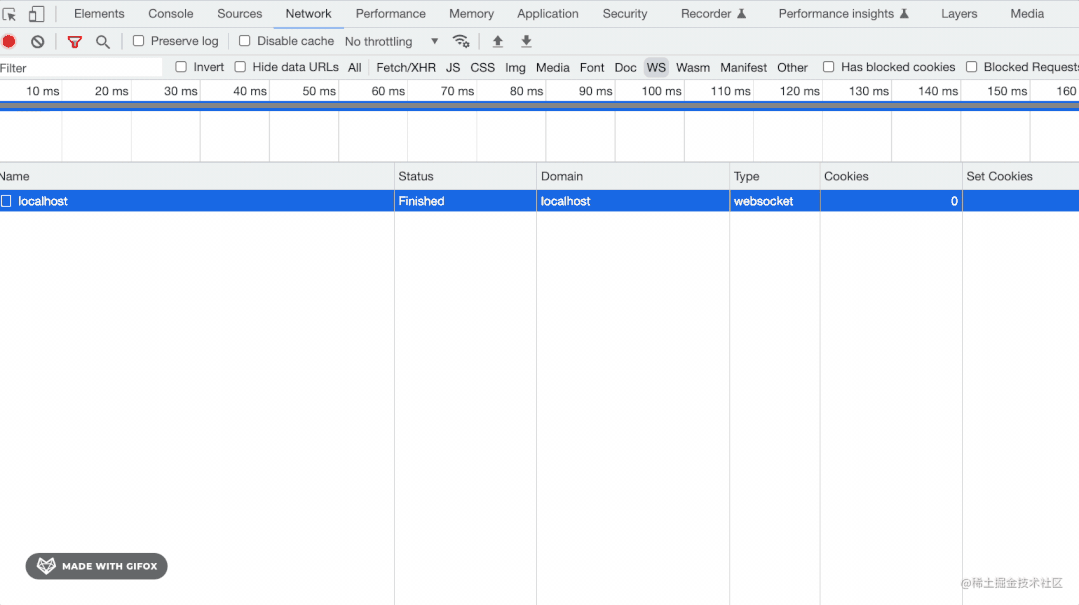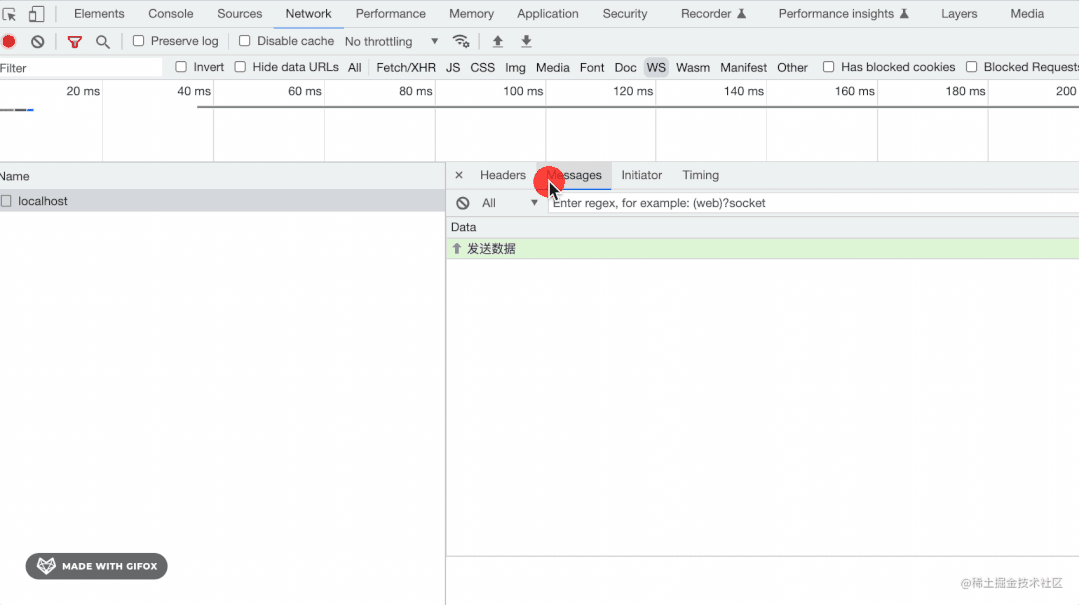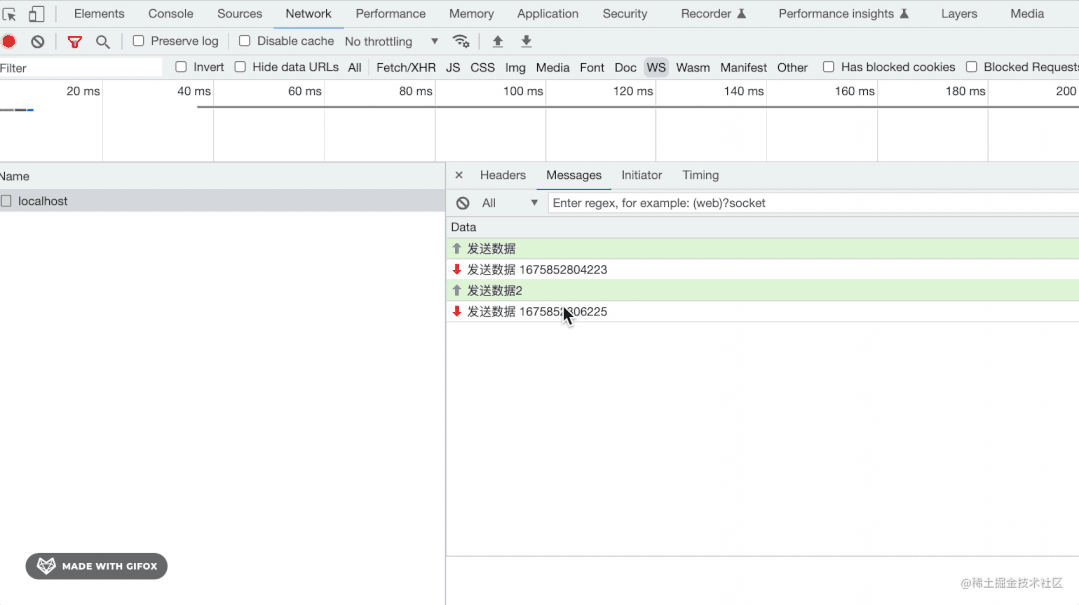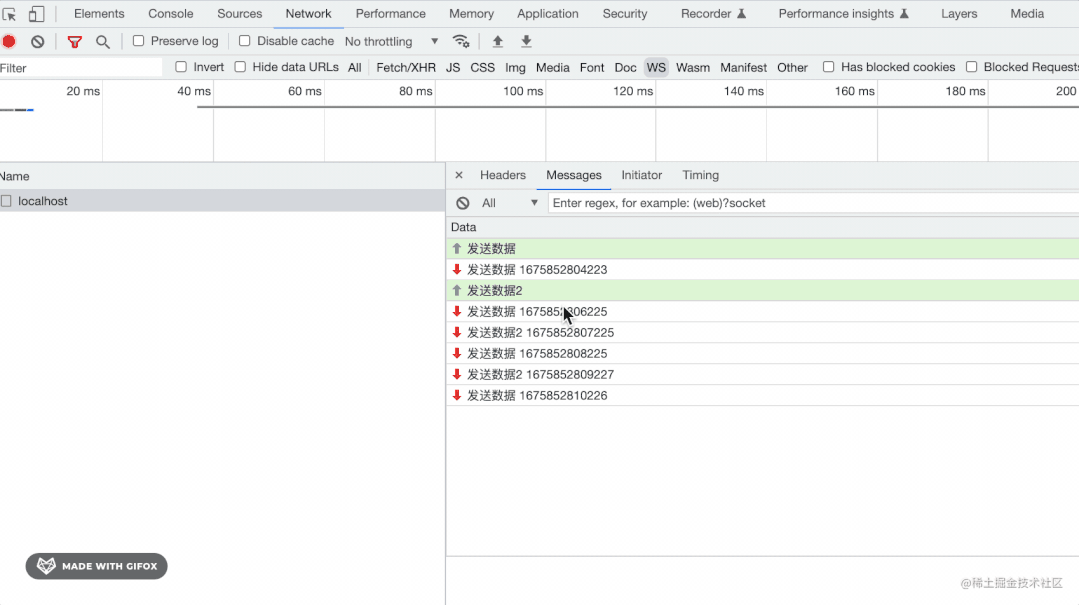
用 Node.js 手写 WebSocket 协议
目录 引言 从 http 到 websocekt 的切换 Sec-WebSocket-Key 与 Sec-WebSocket-Accept 全新的二进制协议 自己实现一个 websocket 服务器 按照协议格式解析收到的Buffer 取出opcode 取出MASK与payload长度 根据mask key读取数据 根据类型处理数据 frame 帧 数据的发…...
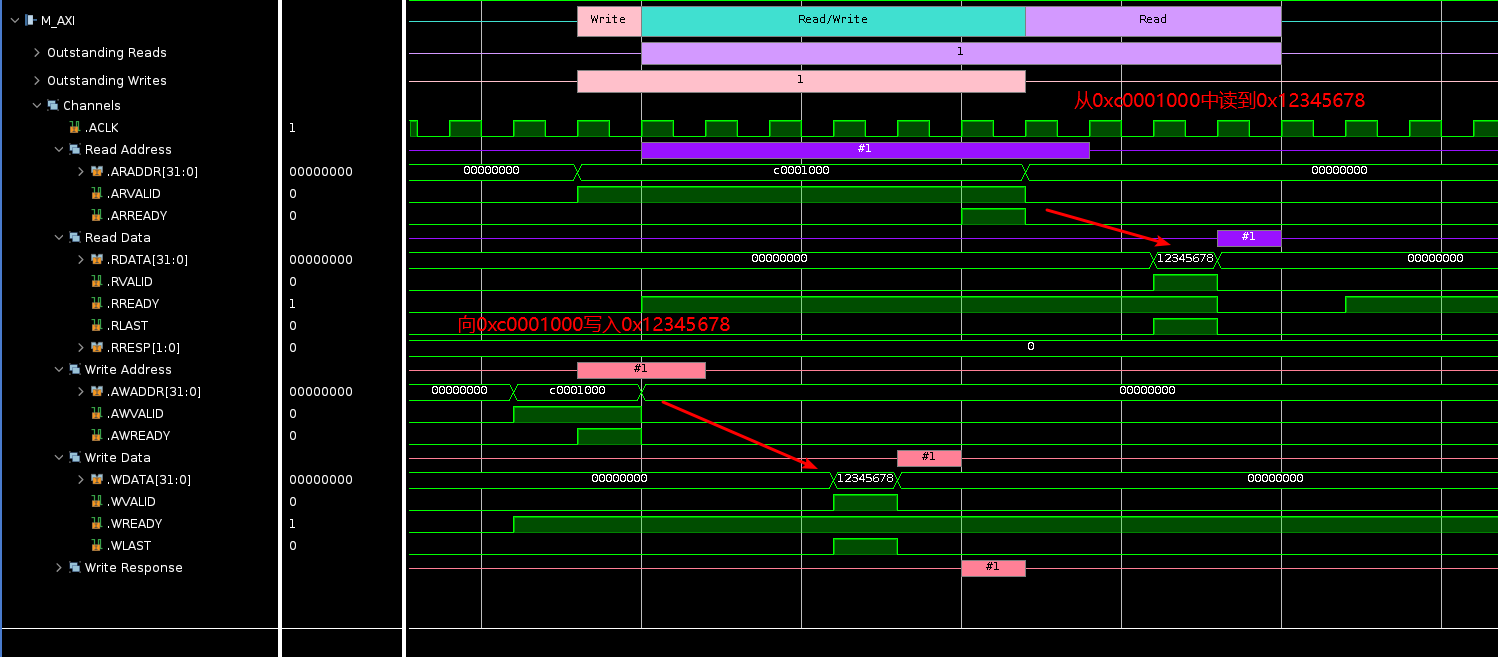
Xilinx AXI VIP使用教程
AXI接口虽然经常使用,很多同学可能并不清楚Vivado里面也集成了AXI的Verification IP,可以当做AXI的master、pass through和slave,本次内容我们看下AXI VIP当作master时如何使用。 新建Vivado工程,并新建block design,命…...

mysql主主架构搭建,删库恢复
mysql主主架构搭建,删库恢复 搭建mysql主主架构环境信息安装msql服务mysql1mysql2设置mysql2同步mysql1设置mysql1同步mysql2授权测试用账户 安装配置keepalivedmysql1检查脚本mysql2检查脚本 备份策略mysqldump全量备份mysqldump增量备份数据库目录全量备份 删除my…...

pythonweek1
引言 做任何事情都要脚踏实地,虽然大一上已经学习了python的基础语法,大一下也学习了C加加中的类与对象,但是自我觉得基础还不太扎实,又害怕有什么遗漏,所以就花时间重新学习了python的基础,学习Python的基…...
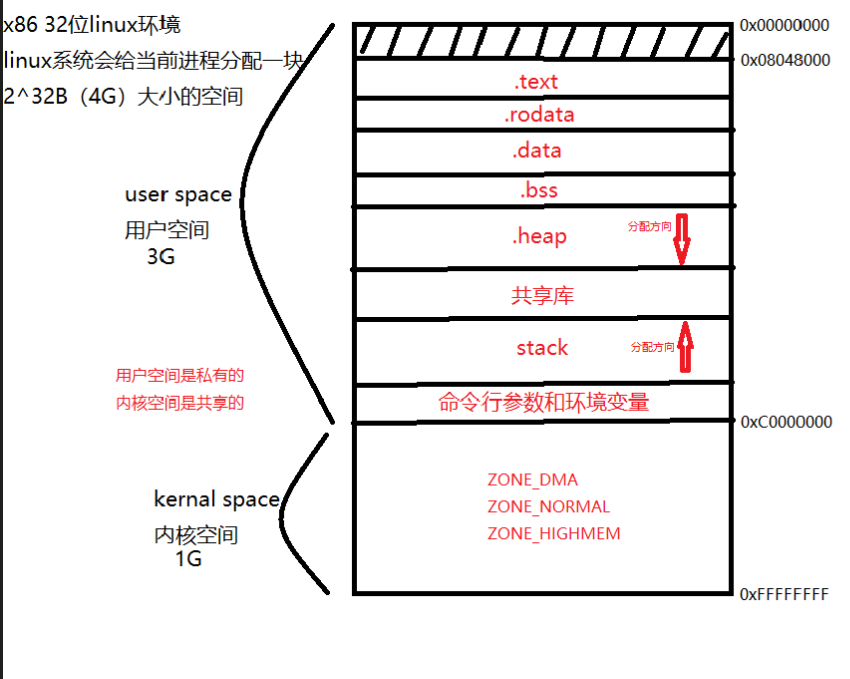
进程虚拟地址空间区域划分
目录 图示 详解 代码段 备注:x86 32位linux环境下,进程虚拟地址空间区域划分 图示 详解 用户空间 用于存储用户进程代码和数据,只能由用户进程访问 内核空间 用于存储操作系统内核代码和数据,只能由操作系统内核访问 text t…...

打造你的专属数字伙伴:BongoCat虚拟桌宠完全指南 [特殊字符]
打造你的专属数字伙伴:BongoCat虚拟桌宠完全指南 🐱 【免费下载链接】BongoCat 🐱 跨平台互动桌宠 BongoCat,为桌面增添乐趣! 项目地址: https://gitcode.com/gh_mirrors/bong/BongoCat 你是否曾幻想过在单调的…...

从无人机防抖到股票预测:聊聊卡尔曼滤波在你身边的那些‘隐藏’应用
从无人机防抖到股票预测:卡尔曼滤波如何悄悄优化你的日常生活 想象一下,你正在用手机拍摄一段奔跑中的宠物视频,画面却出奇地稳定;或者驾驶着搭载自动驾驶辅助系统的车辆,它总能精准预判前车距离。这些看似"智能&…...

破局Xbox存档困境:XGP-save-extractor技术原理与实战指南
破局Xbox存档困境:XGP-save-extractor技术原理与实战指南 【免费下载链接】XGP-save-extractor Python script to extract savefiles out of Xbox Game Pass for PC games 项目地址: https://gitcode.com/gh_mirrors/xg/XGP-save-extractor 用户痛点场景剧场…...
)
保姆级教程:用Python脚本一键划分LS-SSDD-v1.0数据集(附近岸/离岸测试集处理)
Python自动化处理LS-SSDD数据集:从混乱到规范的完整指南 当你第一次打开LS-SSDD-v1.0数据集时,面对24,00016,000像素的大图和9000张800800的小图,以及各种划分文件,可能会感到无从下手。这份数据集虽然为SAR图像中的小舰船检测提供…...

如何进行 SEO 网站建设的链接优化
如何进行 SEO 网站建设的链接优化 在当今的数字化时代,搜索引擎优化(SEO)无疑是任何网站建设项目中不可或缺的一部分。尤其是在百度这样的主要搜索引擎上,SEO的重要性更是不言而喻。如何进行 SEO 网站建设的链接优化呢࿱…...
Pixel Script Temple多场景落地:政务宣传短视频、乡村振兴纪录片脚本生成
Pixel Script Temple多场景落地:政务宣传短视频、乡村振兴纪录片脚本生成 1. 专业剧本创作工具介绍 Pixel Script Temple(像素剧本圣殿)是一款基于Qwen2.5-14B-Instruct大模型深度优化的专业剧本创作工具。它将先进的AI推理能力与独特的8-B…...

Java 上位机防空警报系统开发
通讯结构中央站 -区域站-终端支持全控 选控 单控。可诊断每个设备回示记录通讯协议 使用modbus相关核心代码通讯线程池package com.common.buscomm.taskRun.base.runable;import cn.hutool.core.bean.BeanUtil; import cn.hutool.core.date.DatePattern; import cn.hutool.core…...
3步打造个性化Windows任务栏:轻量级桌面美化工具TranslucentTB使用指南
3步打造个性化Windows任务栏:轻量级桌面美化工具TranslucentTB使用指南 【免费下载链接】TranslucentTB A lightweight utility that makes the Windows taskbar translucent/transparent. 项目地址: https://gitcode.com/gh_mirrors/tr/TranslucentTB 你是否…...

3大核心策略!Langchain-Chatchat RAG语义匹配效率提升实战指南
3大核心策略!Langchain-Chatchat RAG语义匹配效率提升实战指南 【免费下载链接】Langchain-Chatchat Langchain-Chatchat(原Langchain-ChatGLM)基于 Langchain 与 ChatGLM, Qwen 与 Llama 等语言模型的 RAG 与 Agent 应用 | Langchain-Chatch…...

interactive-deep-colorization与Adobe Photoshop Elements对比分析:免费AI上色工具如何超越专业软件?
interactive-deep-colorization与Adobe Photoshop Elements对比分析:免费AI上色工具如何超越专业软件? 【免费下载链接】interactive-deep-colorization Deep learning software for colorizing black and white images with a few clicks. 项目地址: …...