Hadoop 之 Hbase 配置与使用(四)
Hadoop 之 Hbase 配置与使用
- 一.Hbase 下载
- 1.Hbase 下载
- 二.Hbase 配置
- 1.单机部署
- 2.伪集群部署(基于单机配置)
- 3.集群部署
- 1.启动 hadoop 集群
- 2.启动 zookeeper 集群
- 3.启动 hbase 集群
- 4.集群启停脚本
- 三.测试
- 1.Pom 配置
- 2.Yml 配置
- 3.Hbase 配置类
- 4.Hbase 连接池配置
- 5.测试类
- 6.启动类
- 7.测试
一.Hbase 下载
HBase 是一个分布式的、面向列的开源数据库:Hbase API
1.Hbase 下载
Hbase 下载
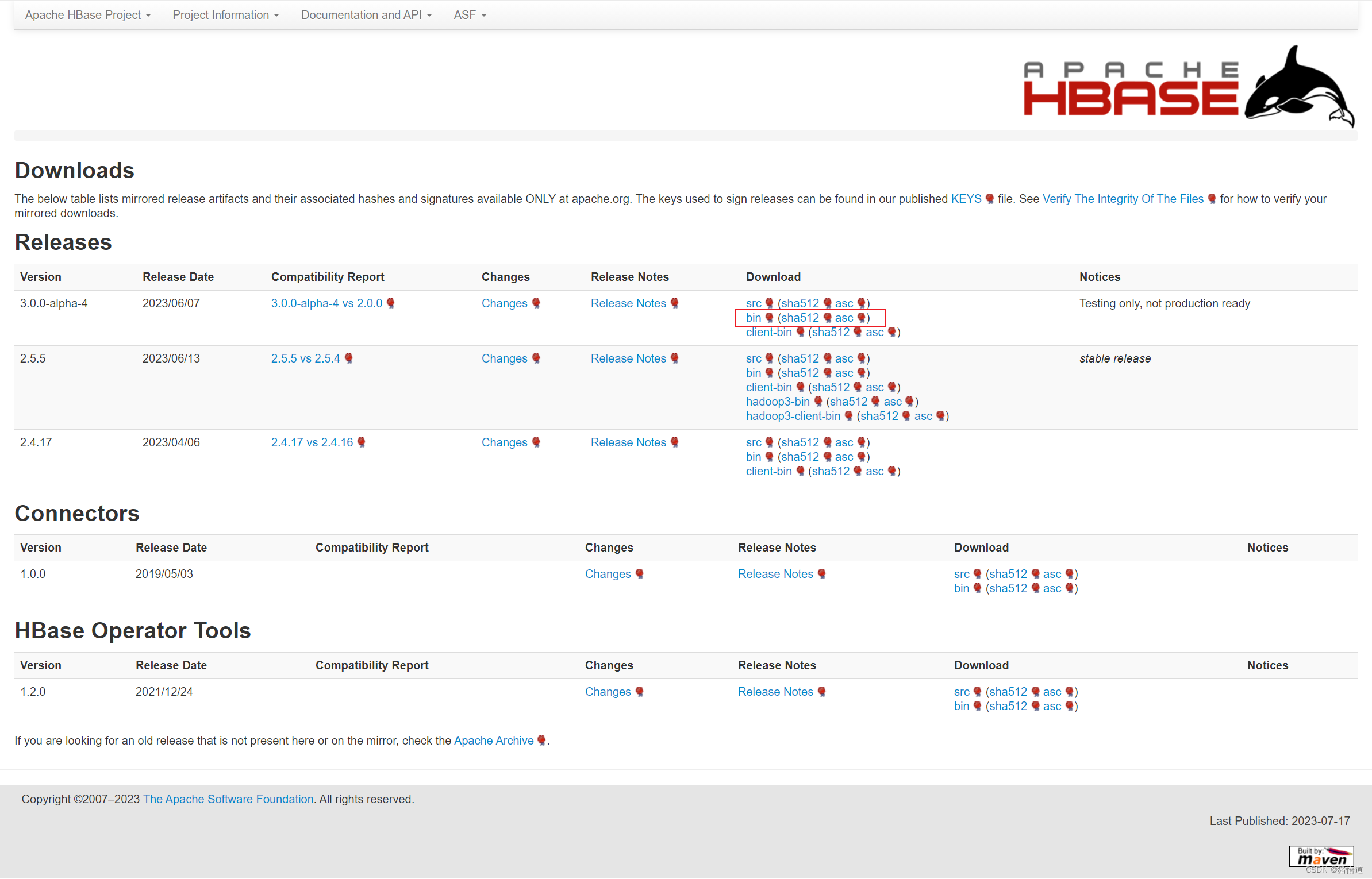
跳转到下载链接
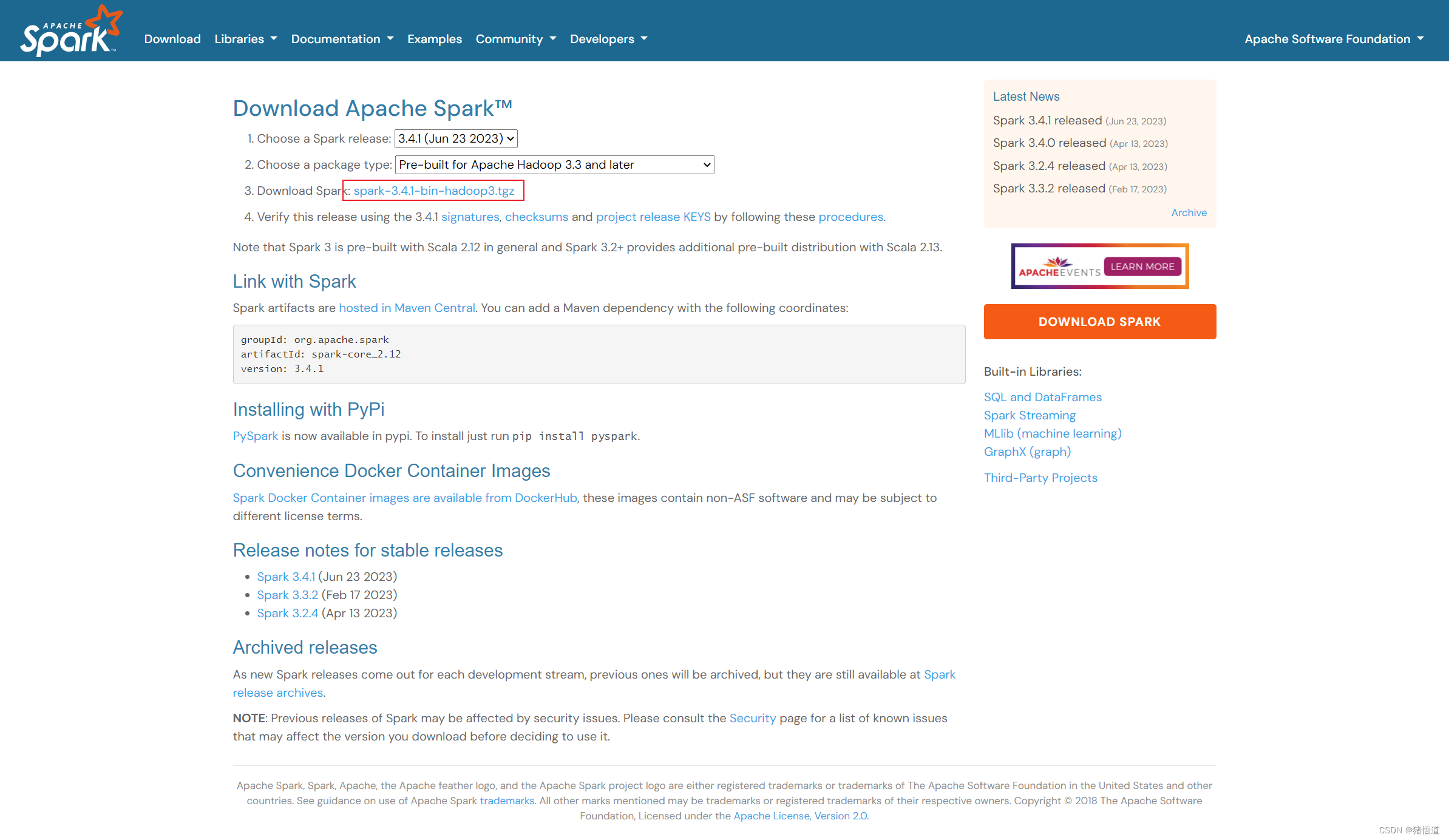
二.Hbase 配置
1.单机部署
## 1.创建安装目录
mkdir -p /usr/local/hbase
## 2.将压缩包拷贝到虚拟机并解压缩
tar zxvf hbase-3.0.0-alpha-4-bin.tar.gz -C /usr/local/hbase/
## 3.添加环境变量
echo 'export HBASE_HOME=/usr/local/hbase/hbase-3.0.0-alpha-4' >> /etc/profile
echo 'export PATH=${HBASE_HOME}/bin:${PATH}' >> /etc/profile
source /etc/profile
## 4.指定 JDK 版本
echo 'export JAVA_HOME=/usr/local/java/jdk-11.0.19' >> $HBASE_HOME/conf/hbase-env.sh
## 5.创建 hbase 存储目录
mkdir -p /home/hbase/data
## 6.修改配置
vim $HBASE_HOME/conf/hbase-site.xml添加如下信息<property><name>hbase.rootdir</name><value>file:///home/hbase/data</value></property>
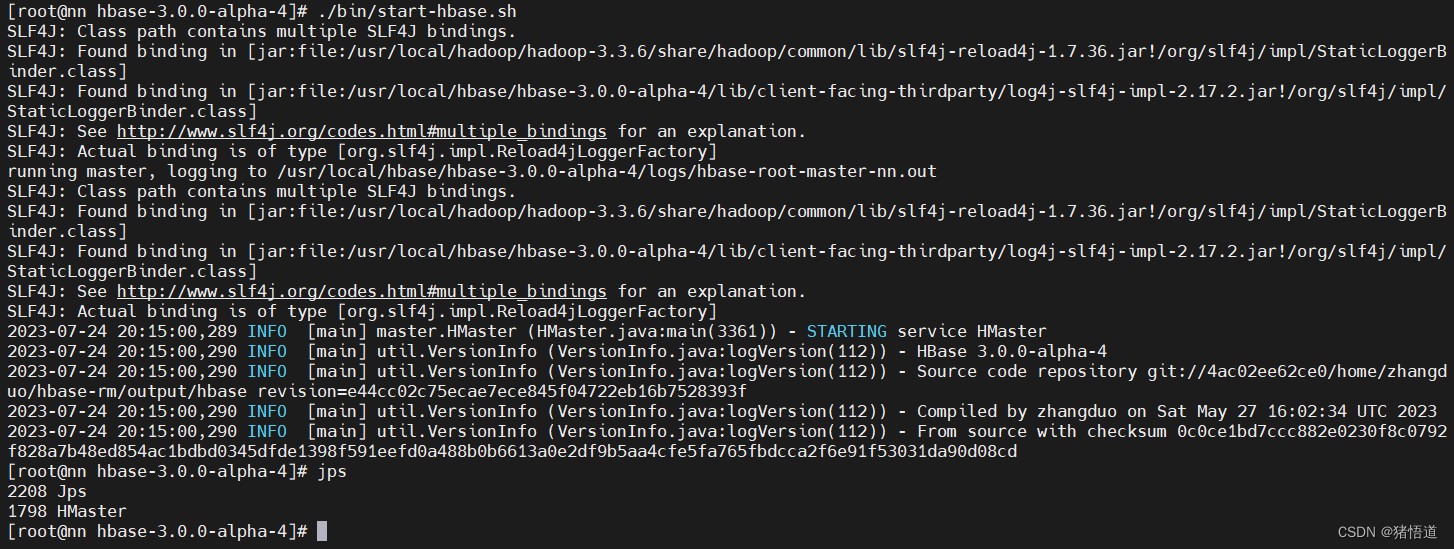
## 1.进入安装目录
cd $HBASE_HOME
## 2.启动服务
./bin/start-hbase.sh
## 1.进入安装目录
cd $HBASE_HOME
## 2.关闭服务
./bin/stop-hbase.sh

2.伪集群部署(基于单机配置)
## 1.修改 hbase-env.sh
echo 'export JAVA_HOME=/usr/local/java/jdk-11.0.19' >> $HBASE_HOME/conf/hbase-env.sh
echo 'export HBASE_MANAGES_ZK=true' >> $HBASE_HOME/conf/hbase-env.sh
## 2.修改 hbase_site.xml
vim $HBASE_HOME/conf/hbase-site.xml<!-- 将 hbase 数据保存到 hdfs --><property><name>hbase.rootdir</name><value>hdfs://nn/hbase</value></property><!-- 分布式配置 --><property><name>hbase.cluster.distributed</name><value>true</value></property><!-- 配置 ZK 地址 --><property><name>hbase.zookeeper.quorum</name><value>nn</value></property><!-- 配置 JK 地址 --><property><name>dfs.replication</name><value>1</value></property>
## 3.修改 regionservers 的 localhost 为 nn
echo nn > $HBASE_HOME/conf/regionservers
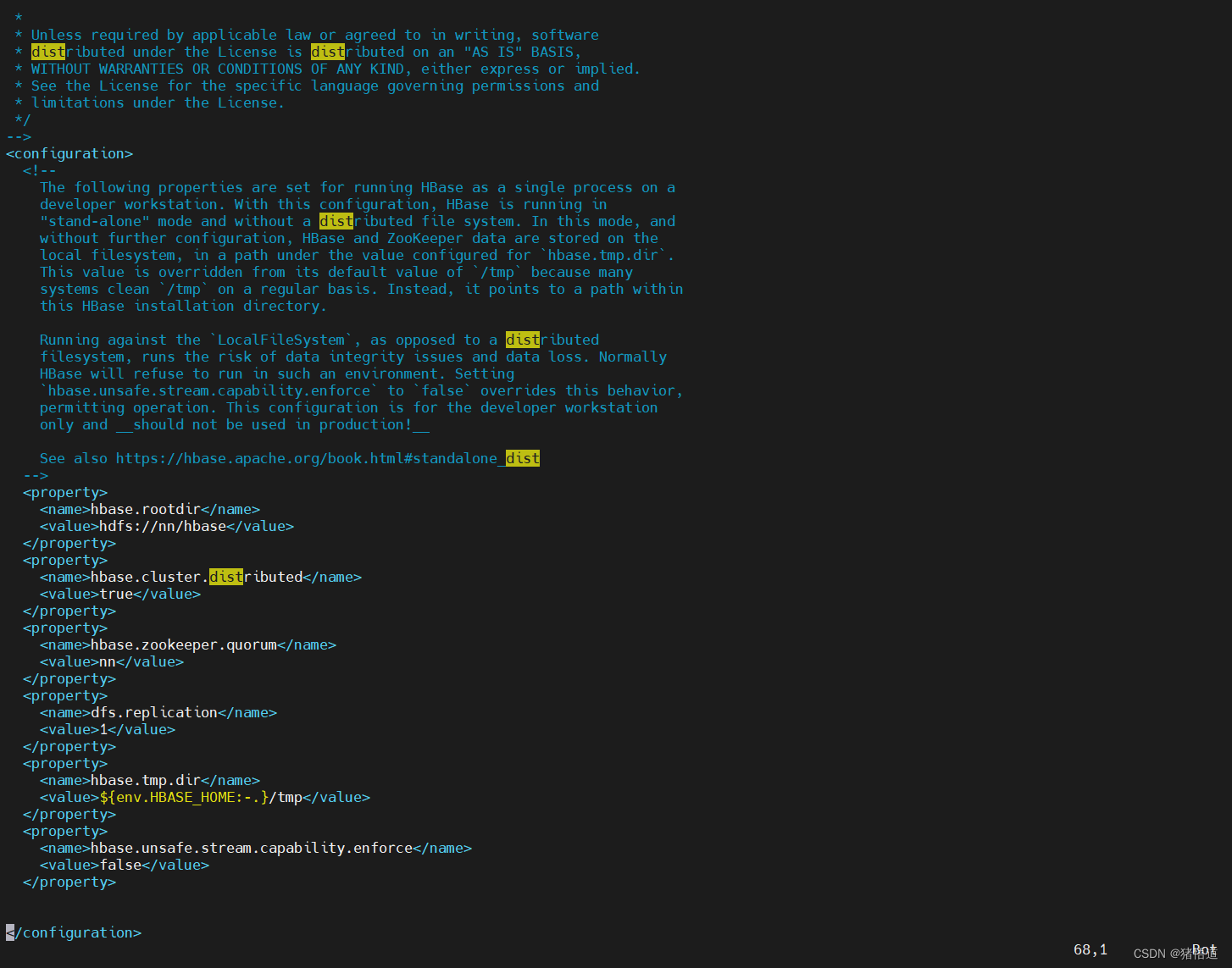
## 1.进入安装目录
cd $HADOOP_HOME
## 2.启动 hadoop 服务
./sbin/start-all.sh
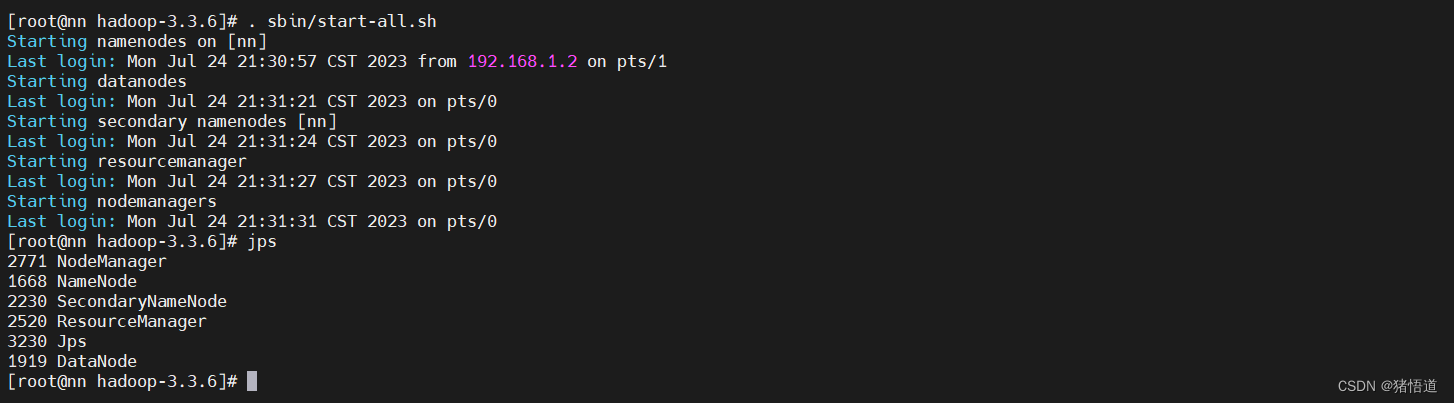
## 1.进入安装目录
cd $HBASE_HOME
## 2.启动服务
./bin/start-hbase.sh

## 1.进入安装目录
cd $HBASE_HOME
## 2.关闭主节点服务(直接关服务是关不掉的,如图)
. bin/hbase-daemon.sh stop master
## 3.关闭服务
./bin/stop-hbase.sh
3.集群部署
## 1.创建 zookeeper 数据目录
mkdir -p $HBASE_HOME/zookeeper/data
## 2.进入安装目录
cd $HBASE_HOME/conf
## 3.修改环境配置
vim hbase-env.sh
## 添加 JDK / 启动外置 Zookeeper# JDKexport JAVA_HOME=/usr/local/java/jdk-11.0.19# Disable Zookeeperexport HBASE_MANAGES_ZK=false
## 4.修改 hbase-site.xml
vim hbase-site.xml
## 配置如下信息<!--允许的最大同步时钟偏移--><property><name>hbase.master.maxclockskew</name>`<value>6000</value></property><!--配置 HDFS 存储实例--><property><name>hbase.rootdir</name><value>hdfs://nn:9000/hbase</value></property><!--启用分布式配置--><property><name>hbase.cluster.distributed</name><value>true</value></property><!--配置 zookeeper 集群节点--><property><name>hbase.zookeeper.quorum</name><value>zk1,zk2,zk3</value></property><!--配置 zookeeper 数据目录--><property><name>hbase.zookeeper.property.dataDir</name><value>/usr/local/hbase/hbase-3.0.0-alpha-4/zookeeper/data</value></property><!-- Server is not running yet --><property><name>hbase.wal.provider</name><value>filesystem</value></property>
## 5.清空 regionservers 并添加集群节点域名
echo '' > regionservers
echo 'nn' >> regionservers
echo 'nd1' >> regionservers
echo 'nd2' >> regionservers
## 6.分别为 nd1 / nd2 创建 hbase 目录
mkdir -p /usr/local/hbase
## 7.分发 hbase 配置到另外两台虚拟机 nd1 / nd2
scp -r /usr/local/hbase/hbase-3.0.0-alpha-4 root@nd1:/usr/local/hbase
scp -r /usr/local/hbase/hbase-3.0.0-alpha-4 root@nd2:/usr/local/hbase
## 8.分发环境变量配置
scp /etc/profile root@nd1:/etc/profile
scp /etc/profile root@nd2:/etc/profile
1.启动 hadoop 集群
Hadoop 集群搭建参考:Hadoop 搭建
## 1.启动 hadoop
cd $HADOOP_HOME
. sbin/start-all.sh
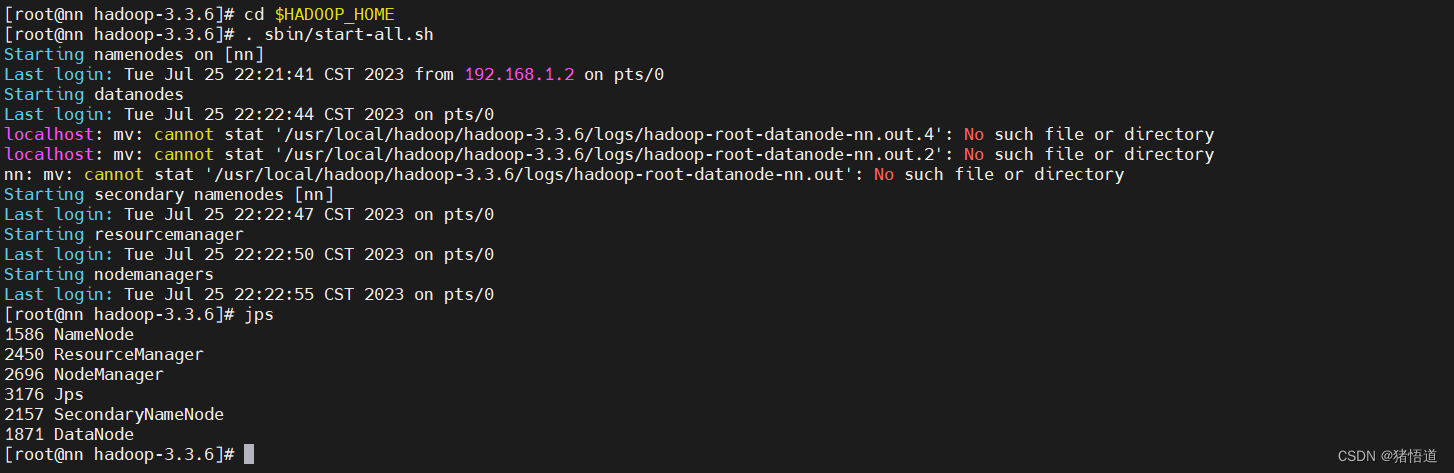
## 1.关闭 hadoop 安全模式
hadoop dfsadmin -safemode leave

2.启动 zookeeper 集群
ZOOKEEPER 集群搭建说明
## 1.启动 zookeeper 集群
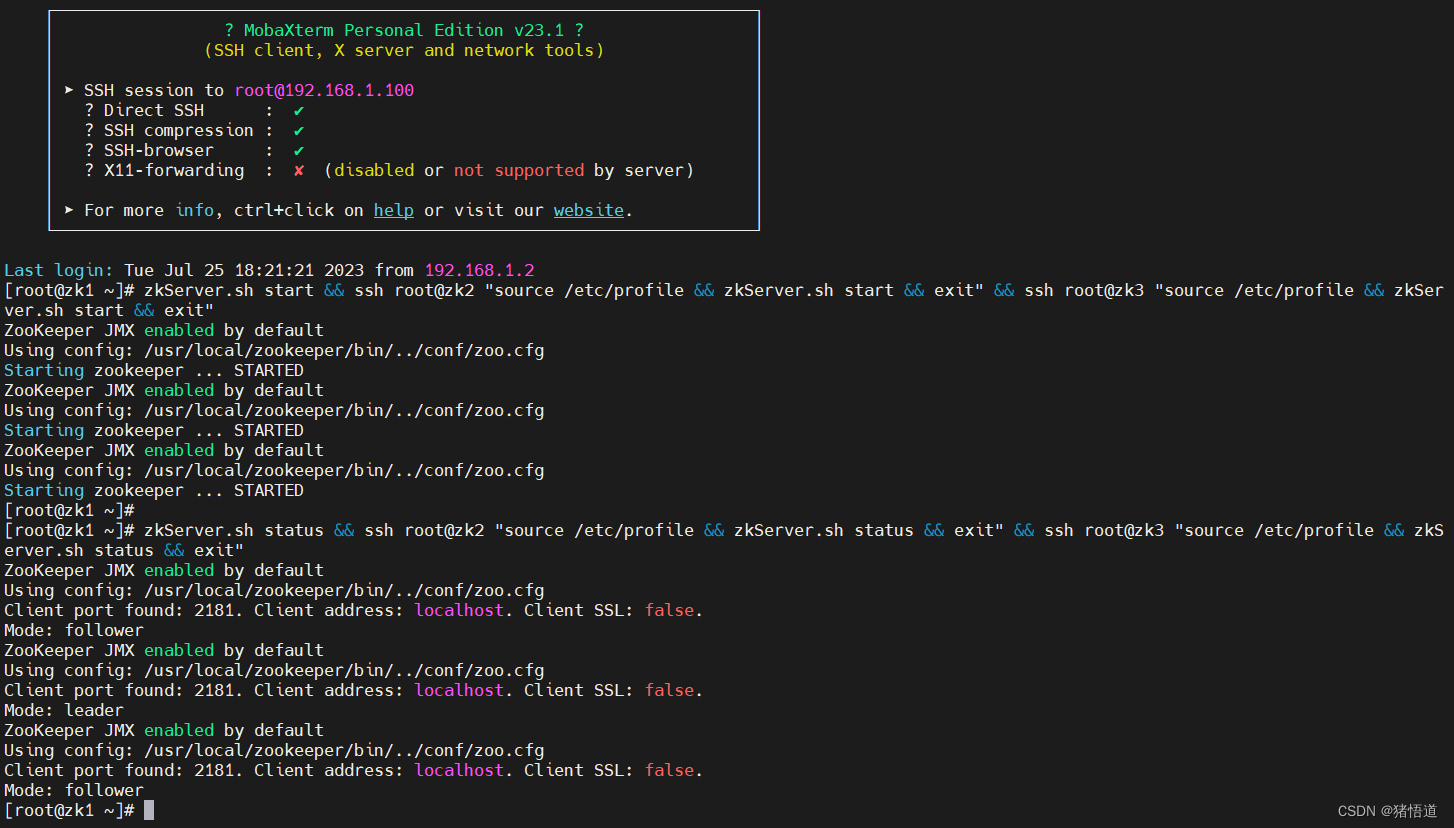
zkServer.sh start && ssh root@zk2 "source /etc/profile && zkServer.sh start && exit" && ssh root@zk3 "source /etc/profile && zkServer.sh start && exit"
## 2.查看状态
zkServer.sh status && ssh root@zk2 "source /etc/profile && zkServer.sh status && exit" && ssh root@zk3 "source /etc/profile && zkServer.sh status && exit"
3.启动 hbase 集群
## 1.分别为 nn /nd1 / nd2 配置 zookeeper 域名解析
echo '192.168.1.100 zk1' >> /etc/hosts
echo '192.168.1.101 zk2' >> /etc/hosts
echo '192.168.1.102 zk3' >> /etc/hosts
## 2.启动 habase
cd $HBASE_HOME
. bin/start-hbase.sh
## 3.停止服务
. bin/hbase-daemon.sh stop master
. bin/hbase-daemon.sh stop regionserver
. bin/stop-hbase.sh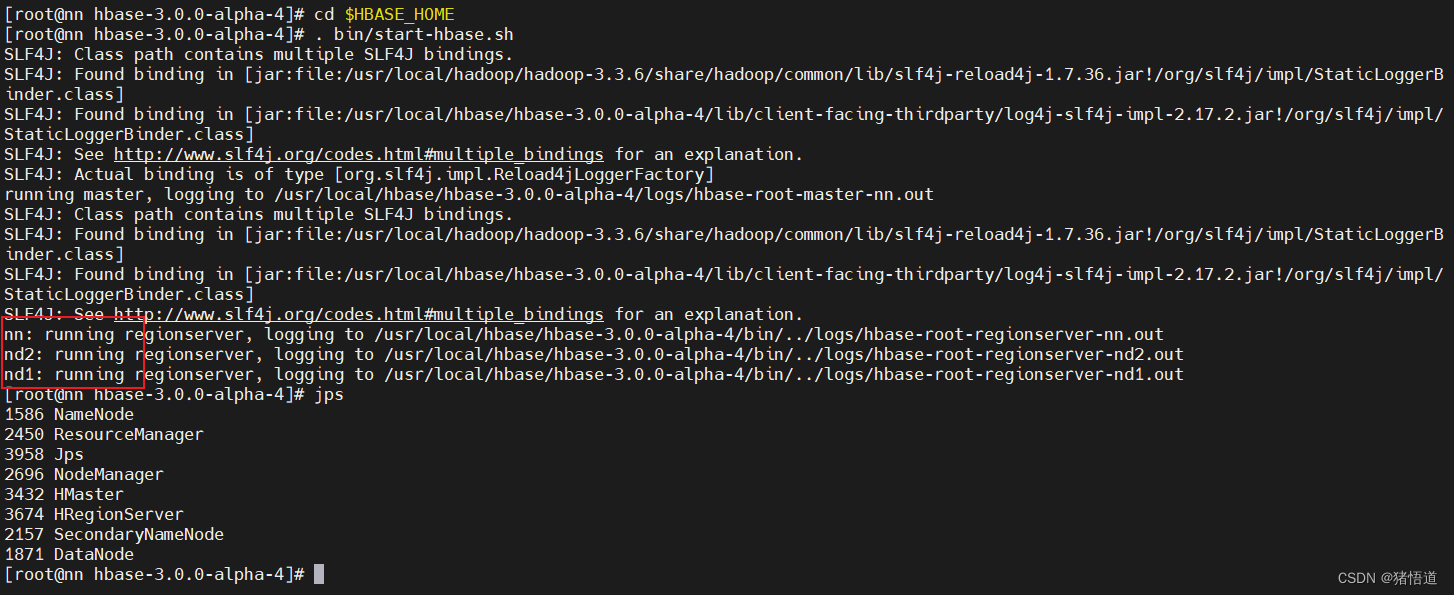
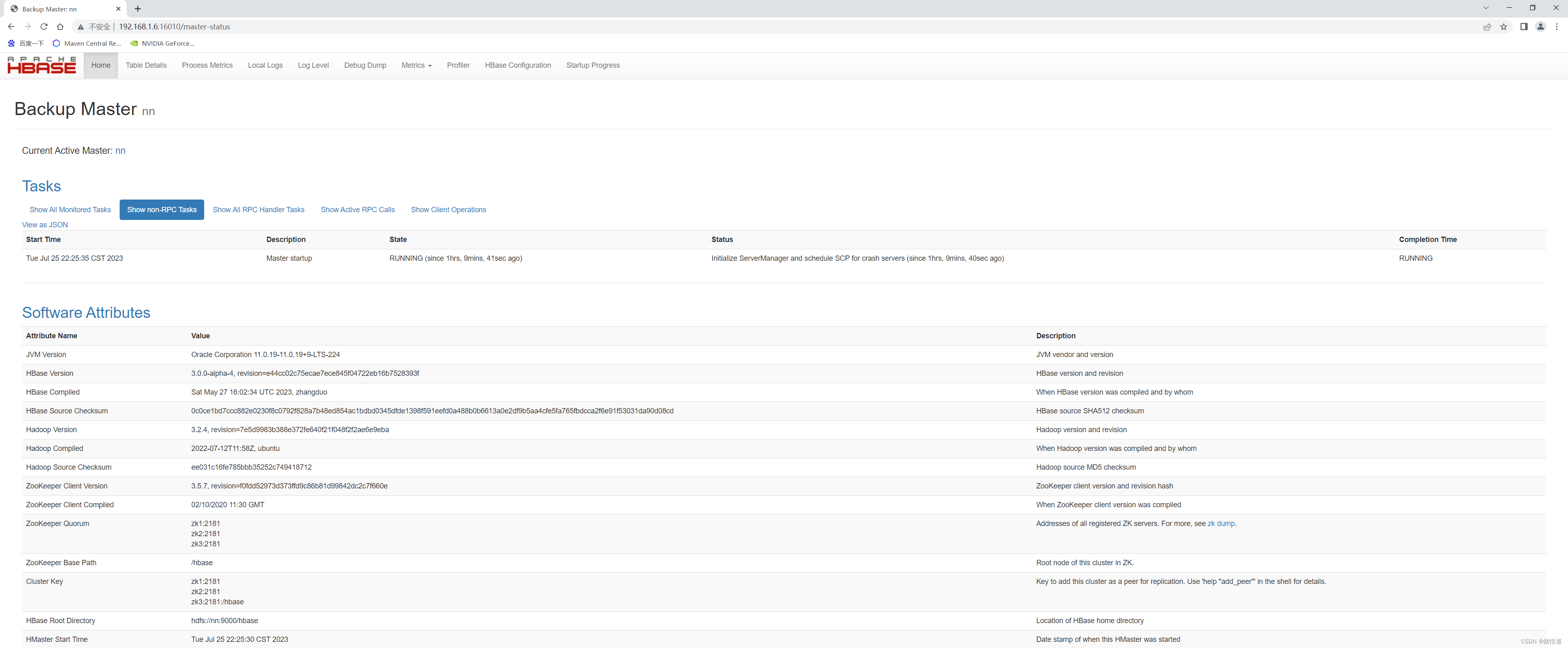
查看 UI 监控:http://192.168.1.6:16010/master-status
4.集群启停脚本
#!/bin/bashcase $1 in
"start")## start hadoopstart-all.sh## start zookeeper (先配置免密登录)zkServer.sh start && ssh root@zk2 "source /etc/profile && zkServer.sh start && exit" && ssh root@zk3 "source /etc/profile && zkServer.sh start && exit"## start hbasestart-hbase.sh;;
"stop")## stop hbasessh root@nd1 "source /etc/profile && hbase-daemon.sh stop regionserver && stop-hbase.sh && exit"ssh root@nd2 "source /etc/profile && hbase-daemon.sh stop regionserver && stop-hbase.sh && exit"hbase-daemon.sh stop master && hbase-daemon.sh stop regionserver && stop-hbase.sh## stop zookeeperzkServer.sh stop && ssh root@zk2 "source /etc/profile && zkServer.sh stop && exit" && ssh root@zk3 "source /etc/profile && zkServer.sh stop && exit"## stop hadoopstop-all.sh;;
*)echo "pls inout start|stop";;
esac三.测试
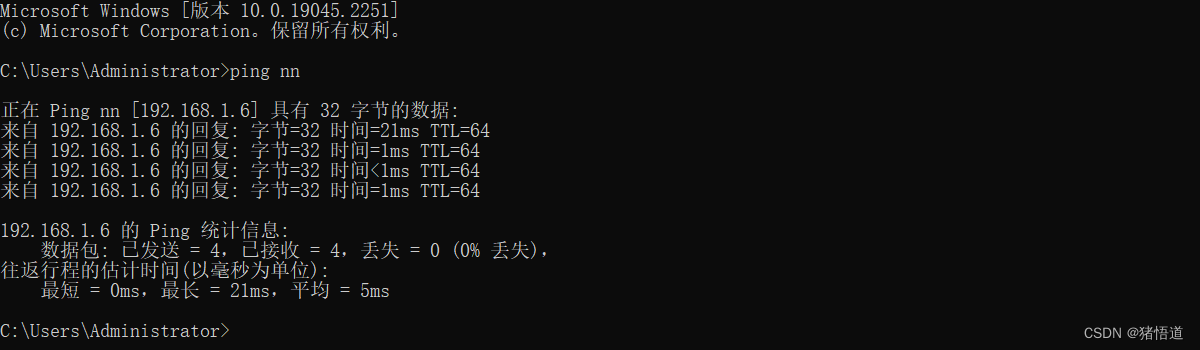
## 1.为 Windows 增加 Hosts 配置,添加 Hbase 集群域名解析 编辑如下文件
C:\Windows\System32\drivers\etc\hosts
## 2.增加如下信息
192.168.1.6 nn
192.168.1.7 nd1
192.168.1.8 nd2
测试配置效果
JDK 版本

工程结构
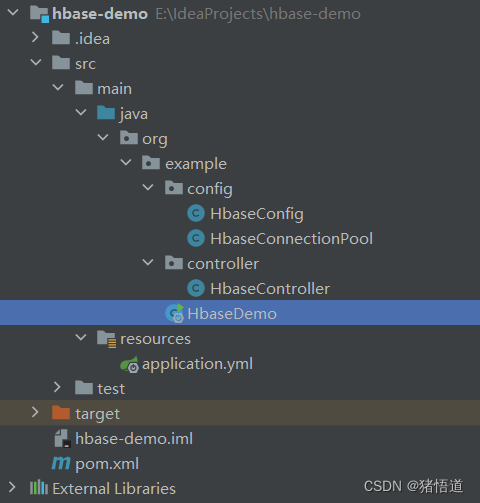
1.Pom 配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>hbase-demo</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>11</maven.compiler.source><maven.compiler.target>11</maven.compiler.target><spring.version>2.7.8</spring.version><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>${spring.version}</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><version>1.18.28</version></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>2.0.32</version></dependency><dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>3.0.0-alpha-4</version></dependency></dependencies></project>
2.Yml 配置
hbase:zookeeper:quorum: 192.168.1.100,192.168.1.101,192.168.1.102property:clientPort: 2181master:ip: 192.168.1.6port: 160003.Hbase 配置类
package org.example.config;import org.apache.hadoop.hbase.HBaseConfiguration;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** @author Administrator* @Description* @create 2023-07-25 0:26*/
@Configuration
public class HbaseConfig {@Value("${hbase.zookeeper.quorum}")private String zookeeperQuorum;@Value("${hbase.zookeeper.property.clientPort}")private String clientPort;@Value("${hbase.master.ip}")private String ip;@Value("${hbase.master.port}")private int masterPort;@Beanpublic org.apache.hadoop.conf.Configuration hbaseConfiguration(){org.apache.hadoop.conf.Configuration conf = HBaseConfiguration.create();conf.set("hbase.zookeeper.quorum",zookeeperQuorum);conf.set("hbase.zookeeper.property.clientPort",clientPort);conf.set("hbase.masters", ip + ":" + masterPort);conf.set("hbase.client.keyvalue.maxsize","20971520");return HBaseConfiguration.create(conf);}}4.Hbase 连接池配置
package org.example.config;import lombok.Data;
import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import java.util.Enumeration;
import java.util.Vector;/*** @author Administrator* @Description* @create 2023-07-25 22:39*/
@Slf4j
@Component
public class HbaseConnectionPool {/*** 连接池的初始大小* 连接池的创建步长* 连接池最大的大小*/private int nInitConnectionAmount = 3;private int nIncrConnectionAmount = 3;private int nMaxConnections = 20;/*** 存放连接池中数据库连接的向量*/private Vector vcConnections = new Vector();/*** 注入连接配置*/@Resourceprivate Configuration hbaseConfiguration;/*** 初始化连接*/@PostConstructpublic void init() {createConnections(nInitConnectionAmount);}/*** 获取可用连接* @return*/public synchronized Connection getConnection() {Connection conn;while (null == (conn =getFreeConnection())){try {wait(1000);} catch (InterruptedException e) {e.printStackTrace();}}// 返回获得的可用的连接return conn;}/*** 释放连接* @param conn*/public synchronized void releaseConnection(Connection conn) {ConnectionWrapper connWrapper;Enumeration enumerate = this.vcConnections.elements();while(enumerate.hasMoreElements()) {connWrapper = (ConnectionWrapper) enumerate.nextElement();if (conn == connWrapper.getConnection()) {connWrapper.setBusy(false);break;}}}/*** 获取可用连接 当前无可用连接则创建 如果已达到最大连接数则返回 null 阻塞后重试获取* @return*/private Connection getFreeConnection() {Connection conn;if (null == (conn = findFreeConnection())) {// 创建新连接createConnections(nIncrConnectionAmount);// 查看是否有可用连接if (null == (conn = findFreeConnection())) {return null;}}return conn;}/*** 查找可用连接* @return*/private Connection findFreeConnection() {ConnectionWrapper connWrapper;//遍历向量内连接对象Enumeration enumerate = vcConnections.elements();while (enumerate.hasMoreElements()) {connWrapper = (ConnectionWrapper) enumerate.nextElement();//判断当前连接是否被占用if (!connWrapper.isBusy()) {connWrapper.setBusy(true);return connWrapper.getConnection();}}// 返回 NULLreturn null;}/*** 创建新连接* @param counts*/private void createConnections(int counts) {// 循环创建指定数目的数据库连接try {for (int i = 0; i < counts; i++) {if (this.nMaxConnections > 0 && this.vcConnections.size() >= this.nMaxConnections) {log.warn("已达到最大连接数...");break;}// 创建一个新连接并加到向量vcConnections.addElement(new ConnectionWrapper(newConnection()));}} catch (Exception e) {log.error("创建连接失败...");}}/*** 创建新连接* @return*/private Connection newConnection() {/** hbase 连接 */Connection conn = null;// 创建一个数据库连接try {conn = ConnectionFactory.createConnection(hbaseConfiguration);} catch (Exception e) {log.error("HBase 连接失败...");}// 返回创建的新的数据库连接return conn;}/*** 封装连接对象*/@Dataclass ConnectionWrapper {/*** 数据库连接*/private Connection connection;/*** 此连接是否正在使用的标志,默认没有正在使用*/private boolean busy = false;/*** 构造函数,根据一个 Connection 构告一个 PooledConnection 对象*/public ConnectionWrapper(Connection connection) {this.connection = connection;}}}5.测试类
package org.example.controller;import lombok.extern.slf4j.Slf4j;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CompareOperator;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.filter.ColumnValueFilter;
import org.apache.hadoop.hbase.filter.Filter;
import org.apache.hadoop.hbase.util.Bytes;
import org.example.config.HbaseConnectionPool;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import javax.annotation.Resource;
import java.io.IOException;
import java.util.*;/*** @author Administrator** 可利用 aop 进行连接获取和释放处理** @Description* @create 2023-07-25 23:06*/
@Slf4j
@RestController
@RequestMapping("/hbase")
public class HbaseController {@Resourceprivate HbaseConnectionPool pool;/*** 表名*/private String tbl_user = "tbl_user";/*** 创建表(不允许重复创建)*/@GetMapping("/create")public void createTable(){Connection conn = null;//获取连接try {conn = pool.getConnection();Admin admin = conn.getAdmin();TableName tableName = TableName.valueOf(tbl_user);if (!admin.tableExists(tableName)){//指定表名TableDescriptorBuilder tdb_user = TableDescriptorBuilder.newBuilder(tableName);//添加列族(info,data)ColumnFamilyDescriptor hcd_info = ColumnFamilyDescriptorBuilder.of("name");ColumnFamilyDescriptor hcd_data = ColumnFamilyDescriptorBuilder.of("age");tdb_user.setColumnFamily(hcd_info);tdb_user.setColumnFamily(hcd_data);//创建表TableDescriptor td = tdb_user.build();admin.createTable(td);}} catch (IOException e) {throw new RuntimeException(e);} finally {if (null != conn){pool.releaseConnection(conn);}}}/*** 删除表(不允许删除不存在的表)*/@GetMapping("/drop")public void dropTable(){Connection conn = null;try {conn = pool.getConnection();Admin admin = conn.getAdmin();TableName tableName = TableName.valueOf(tbl_user);if (admin.tableExists(tableName)){admin.disableTable(tableName);admin.deleteTable(tableName);}} catch (IOException e) {throw new RuntimeException(e);} finally {if (null != conn){pool.releaseConnection(conn);}}}/*** 插入测试*/@GetMapping("/insert")public void insert(){log.info("---插入一列数据---1");putData(tbl_user, "row1", "name", "a", "zhangSan");putData(tbl_user, "row1", "age", "a", "18");log.info("---插入多列数据---2");putData(tbl_user, "row2", "name",Arrays.asList("a", "b", "c"), Arrays.asList("liSi", "wangWu", "zhaoLiu"));log.info("---插入多列数据---3");putData(tbl_user, "row3", "age",Arrays.asList("a", "b", "c"), Arrays.asList("18","19","20"));log.info("---插入多列数据---4");putData(tbl_user, "row4", "age",Arrays.asList("a", "b", "c"), Arrays.asList("30","19","20"));}/*** 插入数据(单条)* @param tableName 表名* @param rowKey rowKey* @param columnFamily 列族* @param column 列* @param value 值* @return true/false*/public boolean putData(String tableName, String rowKey, String columnFamily, String column,String value) {return putData(tableName, rowKey, columnFamily, Arrays.asList(column),Arrays.asList(value));}/*** 插入数据(批量)* @param tableName 表名* @param rowKey rowKey* @param columnFamily 列族* @param columns 列* @param values 值* @return true/false*/public boolean putData(String tableName, String rowKey, String columnFamily,List<String> columns, List<String> values) {Connection conn = null;try {conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Put put = new Put(Bytes.toBytes(rowKey));for (int i=0; i<columns.size(); i++) {put.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columns.get(i)), Bytes.toBytes(values.get(i)));}table.put(put);table.close();return true;} catch (IOException e) {e.printStackTrace();return false;} finally {if (null != conn){pool.releaseConnection(conn);}}}/*** 查询测试*/@GetMapping("/query")public void getResultScanner(){log.info("全表数据:{}",getData(tbl_user));log.info("过滤器,按年龄 [18]:{}",getData(tbl_user,new ColumnValueFilter(Bytes.toBytes("age"), Bytes.toBytes("a"), CompareOperator.EQUAL, Bytes.toBytes("18"))));log.info("根据 rowKey [row1]:{}",getData(tbl_user,"row1"));log.info("根据 rowKey 列族 列 [row2 name a]:{}",getData(tbl_user,"row2","name","a"));}/*** 获取数据(全表数据)* @param tableName 表名* @return map*/public List<Map<String, String>> getData(String tableName) {List<Map<String, String>> list = new ArrayList<>();Connection conn = null;try {conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Scan scan = new Scan();ResultScanner resultScanner = table.getScanner(scan);for(Result result : resultScanner) {HashMap<String, String> map = new HashMap<>(result.listCells().size());map.put("row", Bytes.toString(result.getRow()));for (Cell cell : result.listCells()) {//列族String family = Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength());//列String qualifier = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());//值String data = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());map.put(family + ":" + qualifier, data);}list.add(map);}table.close();} catch (IOException e) {e.printStackTrace();} finally {if (null != conn){pool.releaseConnection(conn);}}return list;}/*** 获取数据(根据 filter)* @param tableName 表名* @param filter 过滤器* @return map*/public List<Map<String, String>> getData(String tableName, Filter filter) {List<Map<String, String>> list = new ArrayList<>();Connection conn = null;try {conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Scan scan = new Scan();// 添加过滤器scan.setFilter(filter);ResultScanner resultScanner = table.getScanner(scan);for(Result result : resultScanner) {HashMap<String, String> map = new HashMap<>(result.listCells().size());map.put("row", Bytes.toString(result.getRow()));for (Cell cell : result.listCells()) {String family = Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength());String qualifier = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());String data = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());map.put(family + ":" + qualifier, data);}list.add(map);}table.close();} catch (IOException e) {e.printStackTrace();} finally {if (null != conn){pool.releaseConnection(conn);}}return list;}/*** 获取数据(根据 rowKey)* @param tableName 表名* @param rowKey rowKey* @return map*/public Map<String, String> getData(String tableName, String rowKey) {HashMap<String, String> map = new HashMap<>();Connection conn = null;try {conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Get get = new Get(Bytes.toBytes(rowKey));Result result = table.get(get);if (result != null && !result.isEmpty()) {for (Cell cell : result.listCells()) {String family = Bytes.toString(cell.getFamilyArray(), cell.getFamilyOffset(), cell.getFamilyLength());String qualifier = Bytes.toString(cell.getQualifierArray(), cell.getQualifierOffset(), cell.getQualifierLength());String data = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());map.put(family + ":" + qualifier, data);}}table.close();} catch (IOException e) {e.printStackTrace();} finally {if (null != conn){pool.releaseConnection(conn);}}return map;}/*** 获取数据(根据 rowKey 列族 列)* @param tableName 表名* @param rowKey rowKey* @param columnFamily 列族* @param columnQualifier 列* @return map*/public String getData(String tableName, String rowKey, String columnFamily,String columnQualifier) {String data = "";Connection conn = null;try {conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Get get = new Get(Bytes.toBytes(rowKey));get.addColumn(Bytes.toBytes(columnFamily), Bytes.toBytes(columnQualifier));Result result = table.get(get);if (result != null && !result.isEmpty()) {Cell cell = result.listCells().get(0);data = Bytes.toString(cell.getValueArray(), cell.getValueOffset(), cell.getValueLength());}table.close();} catch (IOException e) {e.printStackTrace();} finally {if (null != conn){pool.releaseConnection(conn);}}return data;}/*** 删除数据*/@GetMapping("/delete")public void delete(){log.info("---删除 rowKey --- row1 ");deleteData(tbl_user,"row1");log.info("---删除 rowKey 列族 --- row2 age ");deleteData(tbl_user,"row2","age");}/*** 删除数据(根据 rowKey)* @param tableName 表名* @param rowKey rowKey*/public void deleteData(String tableName, String rowKey) {Connection conn = null;try {conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Delete delete = new Delete(Bytes.toBytes(rowKey));table.delete(delete);table.close();} catch (IOException e) {e.printStackTrace();} finally {if (null != conn){pool.releaseConnection(conn);}}}/*** 删除数据(根据 row key,列族)* @param tableName 表名* @param rowKey rowKey* @param columnFamily 列族*/public void deleteData(String tableName, String rowKey, String columnFamily) {Connection conn = null;try {conn = pool.getConnection();Table table = conn.getTable(TableName.valueOf(tableName));Delete delete = new Delete(Bytes.toBytes(rowKey));delete.addFamily(columnFamily.getBytes());table.delete(delete);table.close();} catch (IOException e) {e.printStackTrace();} finally {if (null != conn){pool.releaseConnection(conn);}}}}6.启动类
package org.example;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;/*** @author Administrator*/
@SpringBootApplication
public class HbaseDemo {public static void main(String[] args) {SpringApplication.run(HbaseDemo.class,args);}
}
7.测试
创建表:http://127.0.0.1:8080/hbase/create
插入:http://127.0.0.1:8080/hbase/insert
查询:http://127.0.0.1:8080/hbase/query
删除:http://127.0.0.1:8080/hbase/delete
删除表:http://127.0.0.1:8080/hbase/drop
查看 UI
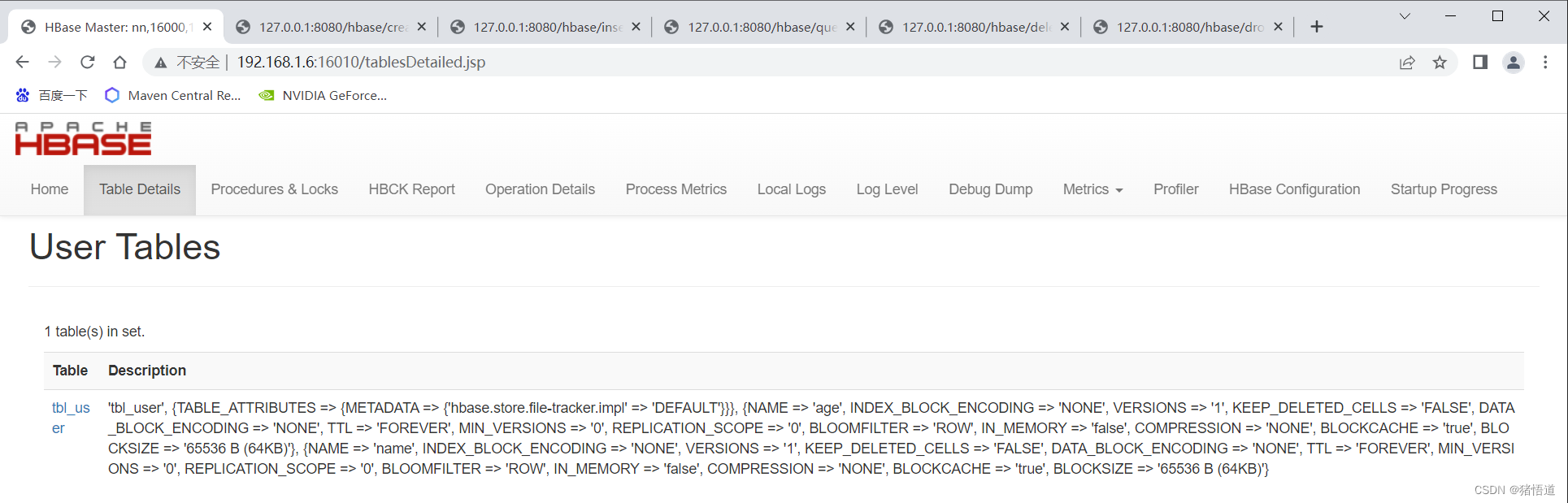
测试输出日志

相关文章:
Hadoop 之 Hbase 配置与使用(四)
Hadoop 之 Hbase 配置与使用 一.Hbase 下载1.Hbase 下载 二.Hbase 配置1.单机部署2.伪集群部署(基于单机配置)3.集群部署1.启动 hadoop 集群2.启动 zookeeper 集群3.启动 hbase 集群4.集群启停脚本 三.测试1.Pom 配置2.Yml 配置3.Hbase 配置类4.Hbase 连…...

使用TensorFlow和VGG-19模型实现艺术风格迁移:一步一步打造你的数字艺术世界
在当下的AI领域,神经风格迁移是最富有创新性和艺术性的技术之一。这项技术可以将一种图像的风格迁移至另一种图像,创造出让人眼前一亮的视觉效果。这种转变所展现的技术之美,让我们深感人工智能所带来的可能性。本文将带领大家一步步通过TensorFlow和VGG-19模型实现风格迁移…...
FBX/GLTF在线转换
3Dconvert是一个可以进行3D模型格式转换的在线工具,并支持3D模型在线预览和转换成果下载。网站访问地址:3D模型在线转换。 1、上传3D模型文件 3D模型在线转换工具的使用非常便捷,首先在网站首页选择需要转换的目标格式,网站支持…...
Tensorflow(二)
一、过拟合 过拟合现象:机器对于数据的学习过于自负(想要将误差减到最小)。 解决方法:利用正规化方法 二、卷积神经网络(CNN) 卷积神经网络是近些年来逐渐兴起的人工神经网络,主要用于图像分类、计算机视觉等。 卷积:例如对图片每一小块像素区域的处理ÿ…...

NoSQL之 Redis 部署,配置与优化
文章目录 NoSQL之 Redis配置与优化一.关系数据库与非关系型数据库1.关系型数据库2.非关系型数据库3.关系型数据库和非关系型数据库区别4.非关系型数据库产生背景 二.Redis简介1.了解Redis2.Redis 具有以下几个优点3.Redis为何这么快 三.Redis 安装及应用1.Redis 安装部署2.Redi…...
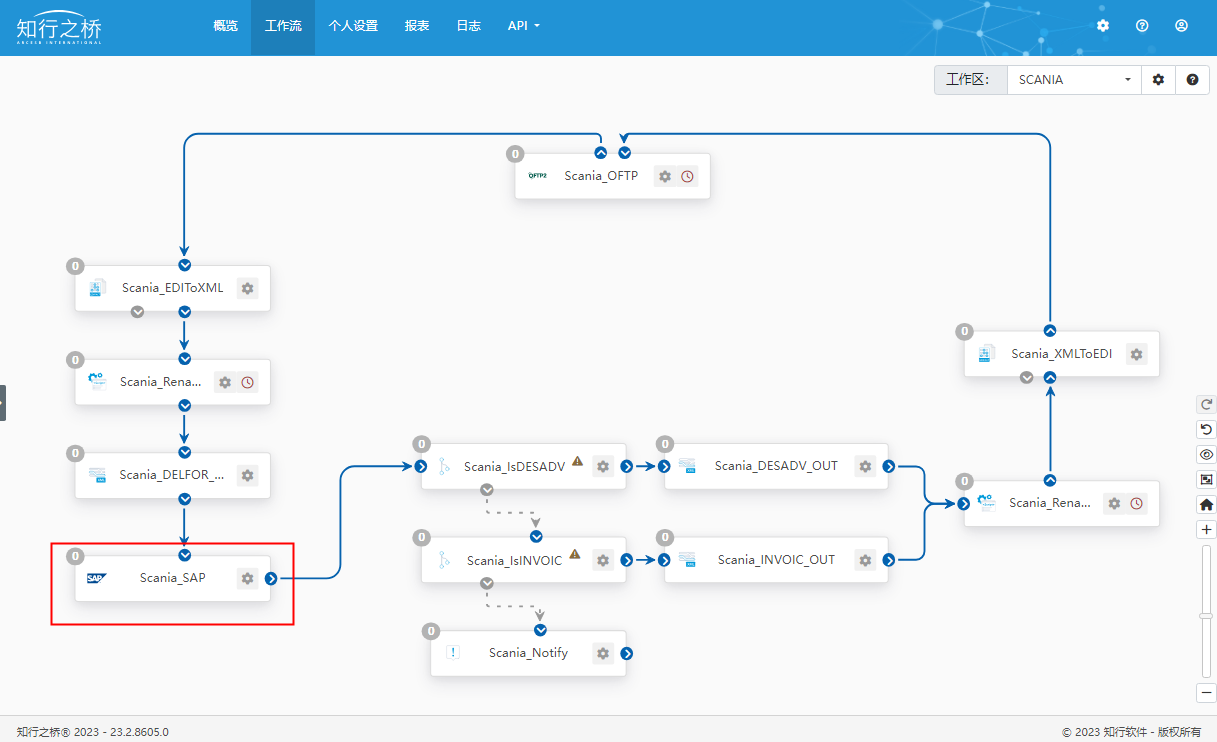
汽车行业 Y 公司对接斯堪尼亚 SCANIA EDI 项目案例
斯堪尼亚是一家来自瑞典的重型车辆制造公司,成立于1891年,总部位于斯德哥尔摩,主要专注于生产卡车、客车和工业发动机,以及相应的服务与解决方案。斯堪尼亚的产品以其高品质、可靠性和先进技术而闻名。其卡车广泛应用于货运和运输…...
)
mysql到doris踩坑记录(如果有问题希望大家帮忙指出问题)
1安装mysql(该步骤晚上很多,不做记录) 2安装docker(同上) 3安装并部署doris(下载镜像步骤省略) sudo docker run -p 9030:9030 -p 8030:8030 -p 8040:8040 \-itd starrocks.docker.scarf.sh/starrocks/allin1-ubuntu 官网地址从 Apache Flink 持续导入 Flink-c…...
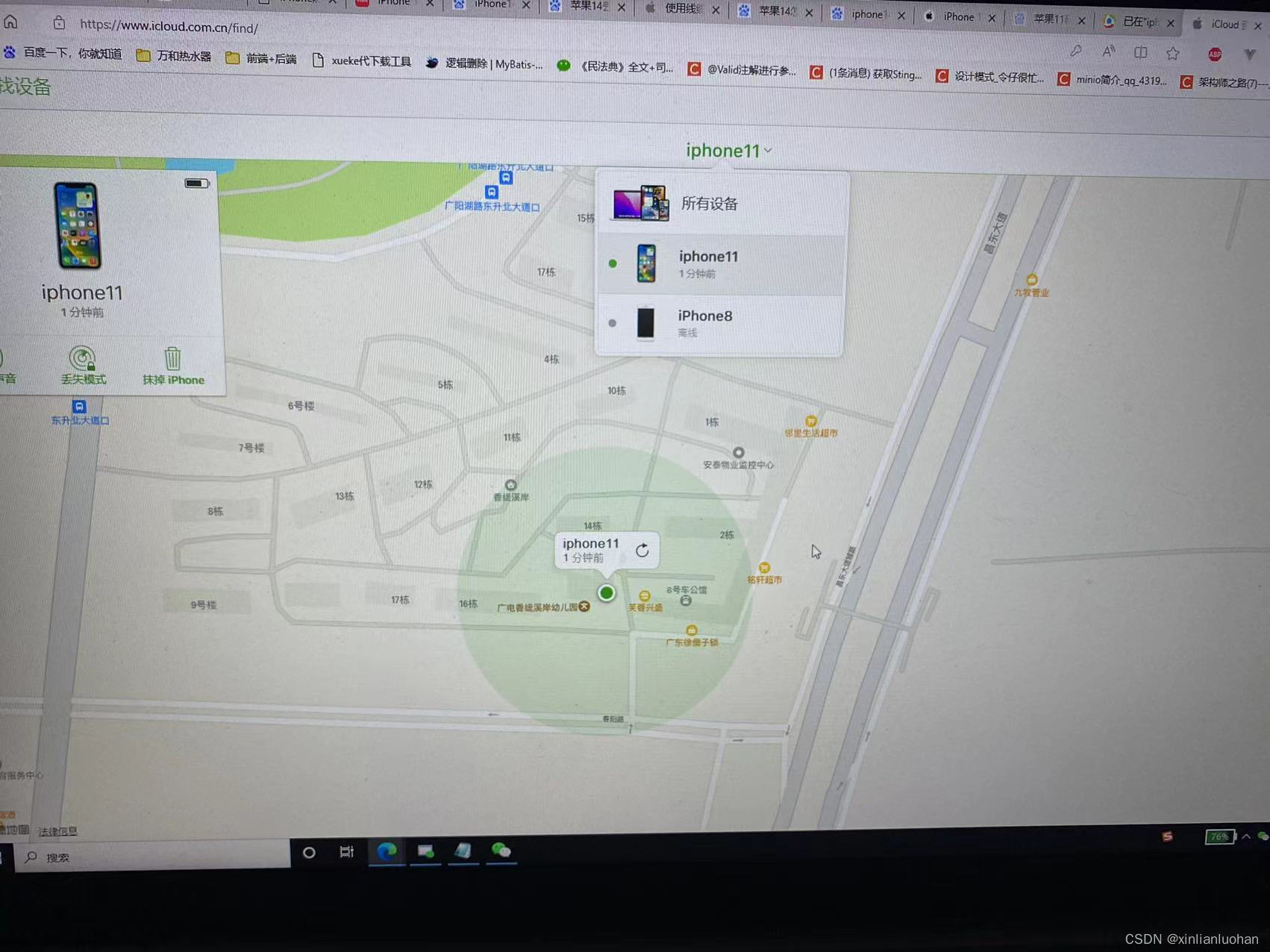
苹果11手机设置手机跟踪功能
苹果11手机设置手机跟踪功能,就算是手机丢了,也能通过查询手机定位在哪里。 第一步:点击Apple ID进入详情 第二步:点击“查找” 第三步: 第四步: 到了这步,就算是设置成功。 下面需要到官方查询…...
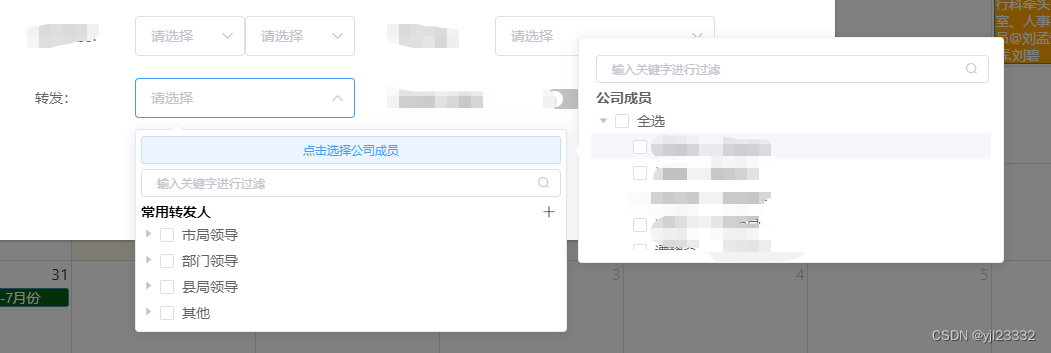
下拉框可筛选可树状多选组件
实际效果图片 父页面 <el-form-item label"转发:" :label-width"formLabelWidth" class"formflex_item"><el-select ref"select" :clearable"true" clear"clearSelect" remove-tag"r…...

【LeetCode】70.爬楼梯
题目 假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? 示例 1: 输入:n 2 输出:2 解释:有两种方法可以爬到楼顶。 1. 1 阶 1 阶 2. 2 阶 示例 2…...
和Math.Round())
c#中的Math.Ceiling和Math.floor()和Math.Round()
Math.Ceiling(),只要有小数就加1(小数部分不为0) 例如: Math.Ceiling(0.0) -> 0 Math.Ceiling(0.1) -> 1 Math.Ceiling(0.2) -> 1 Math.Ceiling(0.3) -> 1 Math.Ceiling(0.4) -> 1 Math.Ceiling(0.5) -> 1 Math.Ceiling(0.6) -> 1…...
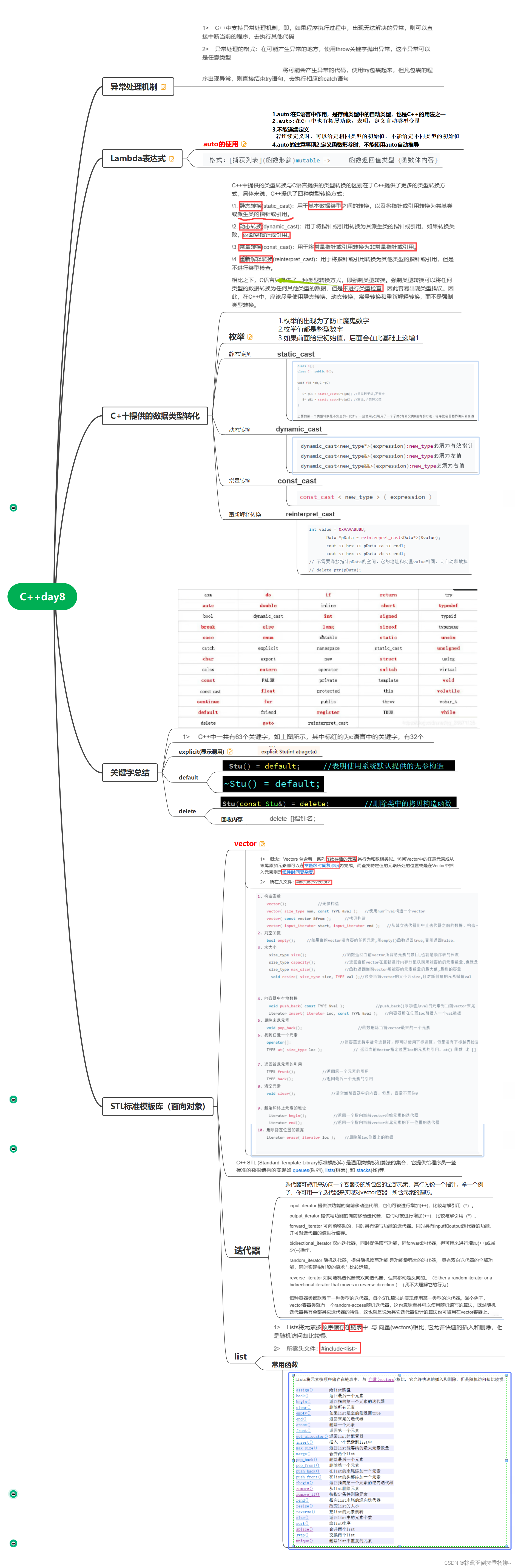
C++day7(异常处理机制、Lambda表达式、类型转换、STL标准库模板、迭代器、list)
#include <iostream>using namespace std; template <typename T> class vector { private:T* first;T* last;T* end; public:vector():first(new T),last(first),end(first){cout<<"无参构造"<<endl;}//无参构造vector(T* f):first(f),last…...

性能优化问题
提升首屏的加载速度,是前端性能优化中「最重要」的环节,这里笔者梳理出一些 常规且有效 的首屏优化建议 1、路由懒加载 SPA 项目,一个路由对应一个页面,如果不做处理,项目打包后,会把所有页面打包成一个文…...

【云原生系列】云计算概念与架构设计介绍
1 什么是云计算 云计算是一种基于互联网的计算模式,在这个模式下,各种计算资源(例如计算机、存储设备、网络设备、应用程序等)可以通过互联网实现共享和交付。云计算架构设计的主要目标是实现高效、可扩展、可靠、安全和经济的计算…...

Swoole协程系统HTTP服务
先启动宝塔 /etc/init.d/bt start 源码参考 https://github.com/zhangyue0503/swoole/tree/main/4.Swoole%E5%8D%8F%E7%A8%8B 对于异步来说,我们需要监听事件,并且监听的进程是并发的,所以会有一个问题,那就是无法保证前后顺…...
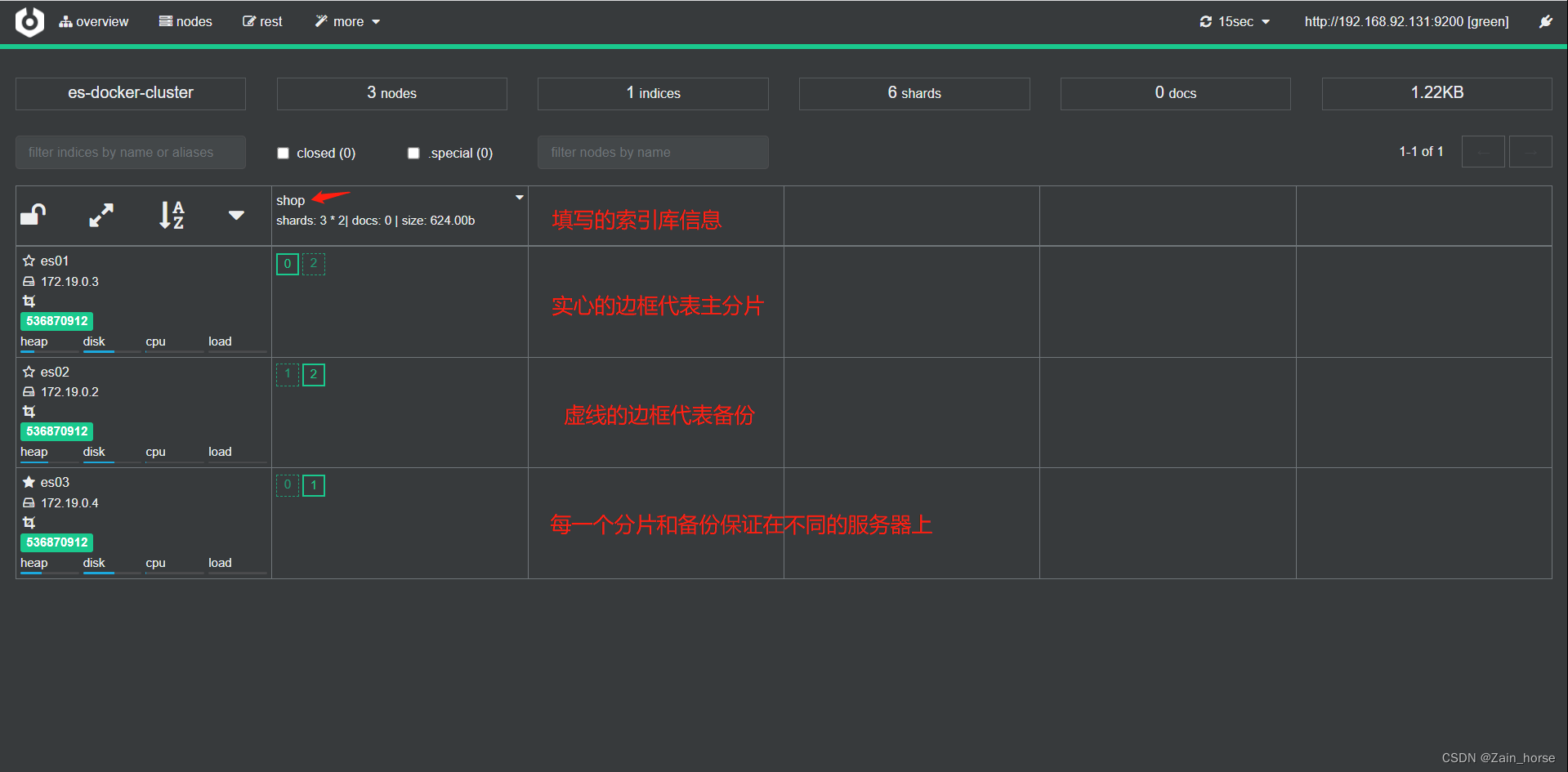
SpringCloud学习路线(13)——分布式搜索ElasticSeach集群
前言 单机ES做数据存储,必然面临两个问题:海量数据的存储,单点故障。 如何解决这两个问题? 海量数据的存储问题: 将索引库从逻辑上拆分为N个分片(shard),存储到多个节点。单点故障…...
CMIP6数据处理及在气候变化、水文、生态等领域中的应用
目录 专题一 CMIP6中的模式比较计划 专题二 数据下载 专题三 基础知识 专题四 单点降尺度 专题五 统计方法的区域降尺度 专题六 基于WRF模式的动力降尺度动态降尺度 专题七 典型应用案例-气候变化1 专题八 典型应用案例-气候变化2 专题九 典型应用案例-生态领域 专题…...

hadoop之mapreduce详解
一、概述 优化前我们需要知道hadoop适合干什么活,适合什么场景,在工作中,我们要知道业务是怎样的,能才结合平台资源达到最有优化。除了这些我们当然还要知道mapreduce的执行过程,比如从文件的读取,map处理&…...

leetcode做题笔记44
给你一个输入字符串 (s) 和一个字符模式 (p) ,请你实现一个支持 ? 和 * 匹配规则的通配符匹配: ? 可以匹配任何单个字符。 * 可以匹配任意字符序列(包括空字符序列)。 判定匹配成功的充要条件是:字符模式必须能够 完…...

mac brew安装 node 踩坑日记- n切换node不生效
最近用了一个旧电脑开发,发现里面node管理混乱,有nvm、n和homebrew,导致切换node 切换不了,开发也有莫名其妙的错误。所以我打算重新装一下node,使用n做为管理工具。 1. 删除nvm cd ~ rm -rf .nvm2. 删除n sudo rm -…...

BilibiliDown:三步实现B站音频高效提取与批量处理全攻略
BilibiliDown:三步实现B站音频高效提取与批量处理全攻略 【免费下载链接】BilibiliDown (GUI-多平台支持) B站 哔哩哔哩 视频下载器。支持稍后再看、收藏夹、UP主视频批量下载|Bilibili Video Downloader 😳 项目地址: https://gitcode.com/gh_mirrors…...

BiliTools智能视频总结:高效提取B站视频知识精华的全指南
BiliTools智能视频总结:高效提取B站视频知识精华的全指南 【免费下载链接】BiliTools A cross-platform bilibili toolbox. 跨平台哔哩哔哩工具箱,支持下载视频、番剧等等各类资源 项目地址: https://gitcode.com/GitHub_Trending/bilit/BiliTools …...

VideoAgentTrek Screen Filter 工业应用:基于C语言与嵌入式系统的实时质量检测原型
VideoAgentTrek Screen Filter 工业应用:基于C语言与嵌入式系统的实时质量检测原型 最近和几个在工厂做设备集成的朋友聊天,他们提到一个挺实际的痛点:产线上有些产品需要做视觉检测,但检测画面里可能包含一些不想让外部人员看到…...

如何无损提取Python可执行文件?解锁逆向工程新姿势
如何无损提取Python可执行文件?解锁逆向工程新姿势 【免费下载链接】python-exe-unpacker A helper script for unpacking and decompiling EXEs compiled from python code. 项目地址: https://gitcode.com/gh_mirrors/py/python-exe-unpacker 破解打包黑箱…...

实用指南:使用applera1n安全绕过iOS 15-16激活锁的完整教程
实用指南:使用applera1n安全绕过iOS 15-16激活锁的完整教程 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n iOS设备的激活锁是Apple保护用户隐私的重要安全功能,但当您忘记Appl…...

如何在5分钟内从零创建专业解说视频?Auto-Video-Generator让AI为你完成所有繁重工作
如何在5分钟内从零创建专业解说视频?Auto-Video-Generator让AI为你完成所有繁重工作 【免费下载链接】auto-video-generateor 自动视频生成器,给定主题,自动生成解说视频。用户输入主题文字,系统调用大语言模型生成故事或解说的文…...

Dell R730服务器iDRAC远程安装操作系统的完整指南
1. Dell R730服务器iDRAC远程安装操作系统全流程 第一次接触iDRAC远程管理功能时,我完全被它的便捷性震惊了。想象一下,你躺在家里沙发上,用笔记本就能完成机房服务器的系统安装,这种体验简直不要太爽。Dell R730作为经典的2U机架…...

NeuroKit2:Python神经生理信号处理的全流程解决方案
NeuroKit2:Python神经生理信号处理的全流程解决方案 【免费下载链接】NeuroKit NeuroKit2: The Python Toolbox for Neurophysiological Signal Processing 项目地址: https://gitcode.com/gh_mirrors/ne/NeuroKit 神经生理信号处理是连接生理数据与临床洞察…...

终极字体合并方案:如何一键解决游戏字体兼容性难题
终极字体合并方案:如何一键解决游戏字体兼容性难题 【免费下载链接】Warcraft-Font-Merger Warcraft Font Merger,魔兽世界字体合并/补全工具。 项目地址: https://gitcode.com/gh_mirrors/wa/Warcraft-Font-Merger 还在为游戏中文字显示不全而烦…...

小米智能家居与Home Assistant集成实战指南:从功能解析到问题诊断完全解析
小米智能家居与Home Assistant集成实战指南:从功能解析到问题诊断完全解析 【免费下载链接】ha_xiaomi_home Xiaomi Home Integration for Home Assistant 项目地址: https://gitcode.com/GitHub_Trending/ha/ha_xiaomi_home 小米智能家居集成项目࿰…...