【 Python 全栈开发 - 人工智能篇 - 45 】决策树与随机森林
文章目录
- 一、概念与原理
- 1.1 决策树
- 1.1.1 概念
- 1.1.2 原理
- 特征选择
- 分割方法
- 1.1.3 优点与缺点
- 1.1.4 Python常用决策树算法
- 1.2 随机森林
- 1.2.1 概念
- 1.2.2 原理
- 1.2.3 优点与缺点
- 1.2.4 Python常用随机森林算法
- 1.3 决策树与随机森林的比较
- 1.3.1 相同之处
- 1.3.2 不同之处
- 二、决策树算法
- 三、随机森林
- 3.1 构建和训练随机森林模型
- 3.1.1 随机选择样本
- 3.1.2 随机选择特征
- 3.2 特征重要性的评估方法
- 四、决策树与随机森林的应用
- 4.1 实际问题中的应用场景
- 4.1.1 医疗诊断
- 4.1.2 金融风控
- 4.1.3 客户分类
- 4.2 泰坦尼克号生存预测
- 4.2.1 数据预处理
- 4.2.2 随机森林模型
- 4.2.3 预测文件内容
- 4.2.4 预测输入数据
- 五、调优
- 5.1 超参数调优
- 5.2 交叉验证和网格搜索
- 5.3 提升模型性能的技巧和策略
一、概念与原理
1.1 决策树
1.1.1 概念
决策树是一种机器学习算法,其模型呈现为一个树状结构,用于解决分类和回归问题。决策树通过对数据集的特征进行分析和判断,构建出一系列的决策规则,并根据这些规则对新的数据进行预测。
决策树的每个节点表示一个特征,每个分支代表该特征的某个取值,而每个叶子节点代表一个分类或预测值。树的顶部节点称为根节点,最底部的叶子节点称为叶节点。决策树的每个内部节点都包含一个条件,用于决定当前样本实例的下一个分支。通过从根节点一直向下移动,并根据样本的特征值和条件进行逐级分支,直到达到一个叶节点,就可以得到对该样本的预测或分类结果。
构建决策树的过程基于信息熵、信息增益、基尼系数等指标来选择最佳的划分特征,并递归地将数据集划分为更小的子集,直到满足某种终止条件(如达到最大深度、节点包含的样本数达到最小值等)为止。
决策树在机器学习中具有较好的可解释性和可视化性,它能够处理离散和连续特征,也能够处理多分类和回归问题。然而,决策树容易过拟合训练数据,可以通过剪枝、设置模型参数等方法来改善模型性能。
1.1.2 原理
我们将从特征选择和分割方法两个方面介绍决策树的实现原理。
特征选择
决策树通过选择最佳的特征作为当前节点的划分特征,以获得最大的信息增益或最小的基尼指数。我们使用信息熵来度量数据的混乱程度,其数学公式如下:
熵 ( D ) = − Σ ( p i ∗ l o g 2 ( p i ) ) 熵(D) = -Σ(p_i * log2(p_i)) 熵(D)=−Σ(pi∗log2(pi))
其中,D 表示数据集,p_i 表示数据集中第i个类别的概率。熵的值越大,表示数据集的不确定性越高。
信息增益(ID3 算法)用于选择最佳特征,其计算公式如下:
信息增益 ( D , A ) = 熵 ( D ) − Σ ( ∣ D v ∣ / ∣ D ∣ ∗ 熵 ( D v ) ) 信息增益(D, A) = 熵(D) - Σ(|D_v| / |D| * 熵(D_v)) 信息增益(D,A)=熵(D)−Σ(∣Dv∣/∣D∣∗熵(Dv))
其中,A 表示特征,D_v 表示特征 A 下的子数据集,|D| 表示数据集 D 的样本数,|D_v| 表示子数据集 D_v 的样本数。信息增益越大,表示特征 A 对于分类的贡献越大。
基尼指数(CART 算法)在特征选择中也常被使用,其计算公式如下:
基尼指数 ( D ) = 1 − Σ ( p i 2 ) 基尼指数(D) = 1 - Σ(p_i^2) 基尼指数(D)=1−Σ(pi2)
基尼指数的值越小,表示数据集的纯度越高。基尼指数越小,表示特征的分类能力越好。
分割方法
在特征选择后,我们使用不同的分割方法将数据集划分为子集。对于离散特征,我们可以使用简单的等于或不等于条件进行划分,如 A = a 或 A != a。对于连续特征,我们可以选择一个阈值进行划分,如 A <= t 或 A > t。
根据选择的特征和划分方法,我们可以得到一个决策树的节点,每个分支对应一个特征的取值。我们可以递归地对每个子数据集进行特征选择和分割方法的确定,从而构建整个决策树。
最终,当达到终止条件时,我们将最后的叶节点分配为一个类别,或者对回归问题进行平均值预测。
1.1.3 优点与缺点
决策树具有以下优点:
-
可解释性:决策树是一种直观且易于理解的模型,可以提供清晰的决策规则。它可以帮助我们了解特征的重要性和影响,以及预测结果的推理过程。
-
处理多种数据类型:决策树可以同时处理离散特征和连续特征,以及具有多个类别的分类问题。
-
没有复杂的假设:决策树不需要任何附加的假设或参数,因此可以很好地适应不同类型的数据集。
-
可以处理缺失值和异常值:决策树具有容忍缺失值和异常值的能力,在数据预处理方面更加灵活。
-
可以处理高维数据:决策树可以处理具有很多特征的高维数据集,而不需要进行降维操作。
-
可扩展性:决策树可以与其他机器学习技术(如集成学习)结合使用,以提高模型的性能。
然而,决策树也存在一些缺点:
-
容易过拟合:决策树在处理复杂数据时容易过度匹配训练数据,导致模型过拟合,无法泛化到未见过的数据。
-
对输入数据的变化敏感:数据集中较小的变化可能导致不同的决策树生成,这使得模型不稳定。
-
忽略数据间的相关性:决策树通常基于每个节点最优的特征进行划分,而不考虑特征之间的相关性。
-
选择最佳划分特征的计算开销较大:决策树需要计算每个特征的信息增益或基尼指数,这对于具有大量特征的数据集来说可能是计算密集型的。
-
对于类别不平衡的数据集可能不敏感:决策树在处理类别不平衡的数据集时可能会倾向于选择具有更多样本的类别作为主要决策规则。
总之,决策树是一种强大而灵活的算法,但也有其局限性。在使用决策树时需要注意并解决过拟合问题,并结合其他技术对其进行改进和加强。
1.1.4 Python常用决策树算法
在 Python 中,有几个常用的决策树算法可以使用,以下是其中的一些:
-
ID3 算法:基于信息增益来选择最佳划分特征的决策树算法。它使用信息熵来度量数据集的混乱程度,并选择具有最大信息增益的特征作为节点的划分特征。
-
C4.5 算法:与 ID3 算法类似,但它使用信息增益比来选择最佳特征。信息增益比考虑了特征的取值个数对信息增益的影响,避免了对取值多的特征倾向的问题。
-
CART 算法:Classification and Regression Trees(分类和回归树)是一种非常通用的决策树算法。与 ID3 和 C4.5 不同,CART 算法既可以处理分类问题,也可以处理回归问题。它使用基尼指数来选择最佳划分特征,以最小化数据集的不纯度。
-
RandomForest(随机森林):随机森林是一种集成学习的决策树算法。它通过随机选择一部分特征和样本子集来构建多个决策树,并对它们的结果进行平均或投票来进行预测。随机森林可以减少过拟合风险,并具有较好的性能。
这些算法都可以通过 Python 中的 sklearn 库来实现。sklearn 库提供了DecisionTreeClassifier和DecisionTreeRegressor类来构建决策树模型,并提供相应的参数和方法来调整和评估模型。在使用这些决策树算法时,还可以进行一些技术手段来改善模型的性能,如剪枝、调整参数、采用交叉验证等。
1.2 随机森林
1.2.1 概念
随机森林是一种集成学习方法,它由多个决策树组成的模型。每个决策树都基于不同的随机样本集和随机特征子集进行训练。随机森林通过整合所有决策树的预测结果来进行最终的预测或分类。随机森林可以提高模型的鲁棒性和准确性,并且对于大规模数据集具有较好的性能。
1.2.2 原理
假设我们有一个训练数据集 D,包含 N 个样本和 M 个特征。我们要构建一个包含 T 个决策树的随机森林模型。
随机森林的实现原理如下:
-
随机采样:首先,从原始数据集D中进行有放回的随机采样,生成T个训练子集。每个训练子集的大小约为N个样本的63%。用D_i表示第i个训练子集。
-
随机选择特征:对于每个决策树的每个节点,在特征上进行随机选择。这里我们设置一个可调节的参数
max_features,它决定了每个节点的最大候选分割特征数。通常,max_features的推荐值是总特征数的平方根。 -
决策树的构建:使用随机采样的训练子集和随机选择的特征子集来构建每个决策树。对于第t个决策树,使用训练子集D_t进行构建。决策树的构建过程与传统决策树算法相似,通过递归地选择最佳特征进行节点分割,直到满足终止条件。
-
集成预测:对于分类问题,随机森林使用多数投票法来确定最终的分类结果。对于回归问题,随机森林取所有决策树的预测结果的平均值作为最终的回归值。
下面是一段示例代码,展示了如何使用 sklearn 库来实现随机森林模型。
from sklearn.ensemble import RandomForestClassifier# 创建随机森林分类器对象
rf_classifier = RandomForestClassifier(n_estimators=100, max_features="sqrt")# 使用训练数据拟合模型
rf_classifier.fit(train_features, train_labels)# 使用随机森林进行预测
predictions = rf_classifier.predict(test_features)
在上述代码中,我们使用RandomForestClassifier类来实现随机森林分类器。通过设置n_estimators参数来指定决策树的数量,max_features参数用于控制每个节点的特征子集大小。通过fit方法拟合训练数据,然后使用predict方法进行预测。
通过组合多个决策树的预测,随机森林能够减少过拟合的风险,并获得更稳定和准确的预测结果。它在机器学习中被广泛应用于分类和回归问题,并展现出良好的性能和鲁棒性。
1.2.3 优点与缺点
随机森林的优点:
- 随机森林可以处理高维数据集,且不需要特征选择进行降维。
- 在处理大规模数据集时,随机森林具有很好的效率。
- 随机森林能够处理不平衡的数据集,并且能够生成平衡的分类器。
- 随机森林可以估测缺失数据并保持精确性。
- 随机森林具有较好的预测准确性。
随机森林的缺点:
- 随机森林相对于其他算法,如支持向量机等,在处理小规模数据集时可能会出现过拟合的情况。
- 随机森林的模型复杂度较高,在训练时需要较大的内存空间。
- 对于非线性的数据集,随机森林的表现可能不如其他算法。
- 随机森林的建模过程比较难解释,不利于提取模型的特征解释性。
1.2.4 Python常用随机森林算法
在 Python 中,常用的随机森林算法实现主要包括以下几种:
-
scikit-learn 库中的
RandomForestClassifier和RandomForestRegressor类:这两个类提供了随机森林分类和回归的功能,并提供了一系列参数供用户调整,如树的数量、最大深度等。 -
XGBoost 库中的
XGBClassifier和XGBRegressor类:XGBoost 是一种梯度提升树算法,通过集成多棵树进行分类或回归。它可以使用 sklearn 的接口形式进行使用。 -
LightGBM 库中的
LGBMClassifier和LGBMRegressor类:LightGBM 是一种基于梯度提升树的高效算法,也可以用来进行分类和回归问题。同样,它也提供了与 sklearn 兼容的接口。 -
CatBoost 库中的
CatBoostClassifier和CatBoostRegressor类:CatBoost 是一种基于梯度提升树的机器学习算法,特别适用于处理类别型特征和高维稀疏数据。它也提供了与 sklearn 兼容的接口。
1.3 决策树与随机森林的比较
决策树和随机森林是常用的机器学习算法,常用于分类和回归问题。它们的设计和实现原理有一些相同之处,但也存在一些显著的差异。
1.3.1 相同之处
首先,让我们先了解决策树和随机森林的相同之处:
-
决策树和随机森林都是基于树结构的算法,用于从数据中学习一系列的决策规则。它们都能够处理分类和回归问题。
-
决策树和随机森林都以属性值的比较进行分割。在每个节点上,通过计算属性的信息增益或基尼指数等指标,选择最优的属性进行分割。
-
决策树和随机森林都可以处理离散型和连续型属性。对于离散型属性,可以通过计算属性值的频率或熵来进行选择;对于连续型属性,可以通过计算属性值的二分点来进行选择。
下面,我们将讨论决策树和随机森林的不同之处。
1.3.2 不同之处
-
决策树与随机森林的关系:决策树是随机森林中的基本构成单元。随机森林是由多棵决策树组成的集成模型。
-
处理过拟合的能力:决策树容易发生过拟合现象,特别是当树的深度较大时。而随机森林通过集成多个决策树,并根据随机抽样来生成不同的训练集,可以有效减轻过拟合问题,提高模型的泛化能力。
-
数据特征选择:在决策树中,由于每个节点只考虑其中一个属性进行分裂,可能会忽略其他重要属性的影响。而在随机森林中,每个决策树都是在随机选择的子集上进行训练,因此可以更全面地考虑所有属性的重要性,减少了特征选择的偏差。
接下来,让我们通过 Python 代码来演示决策树和随机森林的实现。
首先,我们导入需要的库:
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
接着,我们加载一个示例数据集(使用 sklearn 的鸢尾花数据集):
iris = datasets.load_iris()
X = iris.data
y = iris.target
然后,我们将数据分割为训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
接下来,我们分别使用决策树和随机森林进行模型训练和预测:
# 决策树
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, y_train)
y_pred_dt = decision_tree.predict(X_test)# 随机森林
random_forest = RandomForestClassifier()
random_forest.fit(X_train, y_train)
y_pred_rf = random_forest.predict(X_test)
最后,我们分别计算决策树和随机森林的准确率:
accuracy_dt = accuracy_score(y_test, y_pred_dt)
accuracy_rf = accuracy_score(y_test, y_pred_rf)print("决策树准确率:", accuracy_dt)
print("随机森林准确率:", accuracy_rf)
通过以上代码,我们可以看到决策树和随机森林都能够实现对鸢尾花数据集的分类任务,并得到相应的准确率。
二、决策树算法
首先,我们需要导入相应的库:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
接下来,我们加载一个示例数据集(使用 sklearn 的鸢尾花数据集):
iris = datasets.load_iris()
X = iris.data
y = iris.target
然后,我们将数据分割为训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
接下来,我们创建一个决策树分类器,并用训练数据进行模型训练:
decision_tree = DecisionTreeClassifier()
decision_tree.fit(X_train, y_train)
此时,决策树模型已经训练完毕。接下来,我们可以使用测试集进行预测,并计算模型的准确率:
y_pred = decision_tree.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)print("决策树准确率:", accuracy)
以上代码中,我们使用了 sklearn 库中的DecisionTreeClassifier类来构建决策树分类器,并使用fit()方法进行模型训练。然后,使用predict()方法对测试集进行预测,最后使用accuracy_score()方法计算模型的准确率。
三、随机森林
3.1 构建和训练随机森林模型
随机森林的构建过程主要包括两个步骤:随机选择样本和随机选择特征。
3.1.1 随机选择样本
在构建每棵决策树时,随机森林从原始训练集中进行有放回抽样,构建一个新的训练集,该新训练集的样本数量与原始训练集相同,但有些样本可能会重复。这种有放回抽样的方式确保了每棵决策树之间的差异性,增加了模型的多样性,从而提高了模型的泛化能力。
3.1.2 随机选择特征
在构建每棵决策树的节点时,随机森林从所有特征中随机选择一部分特征,然后根据选定的特征来进行节点分裂。这样做的好处是,它减少了特征之间的相关性,避免了某些特定特征对模型的过度依赖。
下面是使用 Python 中的sklearn库来构建和训练随机森林模型的示例代码:
# 导入所需的库和模块
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score# 加载数据集
iris = load_iris()
X, y = iris.data, iris.target# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 构建随机森林模型
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)# 训练模型
rf_model.fit(X_train, y_train)# 在测试集上进行预测
y_pred = rf_model.predict(X_test)# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print("随机森林模型的准确率:", accuracy)
3.2 特征重要性的评估方法
随机森林除了能够用于预测,还可以通过评估特征的重要性来帮助我们理解数据和模型。特征重要性指的是在模型训练过程中,各个特征对于模型性能的贡献程度。
随机森林通过衡量每个特征在模型中的节点分裂中的纯度提高(通常是基尼系数或信息增益),来评估特征的重要性。在训练完成后,我们可以通过以下方法来获取特征重要性:
# 获取特征重要性
importance = rf_model.feature_importances_# 将特征重要性与对应特征名称进行关联
feature_importance = dict(zip(iris.feature_names, importance))# 按照重要性降序排列
sorted_feature_importance = dict(sorted(feature_importance.items(), key=lambda x: x[1], reverse=True))# 输出特征重要性
print("特征重要性排名:")
for feature, importance in sorted_feature_importance.items():print(f"{feature}: {importance}")
特征重要性的值越大,表示该特征对于模型的预测能力越强,因此在特征工程中,我们可以根据这些重要性信息来选择最有用的特征或者排除不重要的特征,以提高模型的性能。
四、决策树与随机森林的应用
4.1 实际问题中的应用场景
决策树与随机森林是在机器学习领域中常用的分类与回归算法。它们在实际问题中的应用场景非常广泛,包括但不限于以下几个方面:
4.1.1 医疗诊断
决策树与随机森林可以用于医疗领域,辅助医生进行疾病诊断。通过输入患者的临床指标、生理参数等信息,决策树可以帮助医生快速判断患者可能患有哪种疾病,从而更好地进行治疗与护理。
4.1.2 金融风控
在金融行业中,决策树与随机森林可用于评估贷款申请人的信用风险。根据申请人的个人信息、信用历史、财务状况等数据,这些算法可以预测出借款人是否有能力按时还款,从而帮助银行做出贷款决策,降低坏账率。
4.1.3 客户分类
在市场营销中,决策树与随机森林可以用于客户分类与定向广告。通过分析客户的购买行为、兴趣偏好等信息,这些算法可以将客户分为不同的群体,并针对性地推送广告与优惠活动,提高营销效率。
4.2 泰坦尼克号生存预测
下载地址:
训练文件train.csv(892 条数据):
测试数据test.csv(419 条数据):
4.2.1 数据预处理
导入库:
import pandas as pd
读取数据:
# 读取数据
data = pd.read_csv('titanic\\train.csv')
数据预处理:
# 数据预处理
data = data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin', 'Embarked'], axis=1)
data['Age'] = data['Age'].fillna(data['Age'].mean())
data['Sex'] = data['Sex'].map({'female': 0, 'male': 1})
划分特征和标签:
# 划分特征和标签
X = data.drop('Survived', axis=1)
y = data['Survived']
4.2.2 随机森林模型
导入库:
from sklearn.ensemble import RandomForestClassifier
构建模型:
# 构建随机森林模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X, y)
4.2.3 预测文件内容
导入库:
from sklearn.impute import SimpleImputer
读取测试数据:
# 读取测试数据
test_data = pd.read_csv('titanic\\test.csv')
数据预处理:
# 数据预处理
test_data = test_data.drop(['PassengerId', 'Name', 'Ticket', 'Cabin', 'Embarked'], axis=1)
test_data['Age'] = test_data['Age'].fillna(test_data['Age'].mean())
test_data['Sex'] = test_data['Sex'].map({'female': 0, 'male': 1})
填充缺失值:
# 填充缺失值
imputer = SimpleImputer(strategy='mean')
test_data = pd.DataFrame(imputer.fit_transform(test_data), columns=test_data.columns)
预测:
# 预测
predictions = model.predict(test_data)
print(predictions)
4.2.4 预测输入数据
输入数据:
# 输入数据
pclass = int(input('Pclass(1-3):')) # 船票级别(1,2或3)
sex = int(input('Sex(male:1,female:0):')) # 性别(男1,女0)
age = int(input('Age:')) # 年龄
sibsp = int(input('SibSp:')) # 船上的兄弟姐妹以及配偶的人数
parch = int(input('Parch:')) # 船上的父母以及子女的人数
fare = float(input('Fare:')) # 船票费用
input_data = pd.DataFrame({'Pclass': [pclass], 'Sex': [sex], 'Age': [age], 'SibSp': [sibsp], 'Parch': [parch], 'Fare': [fare]})
预测结果:
# 预测结果
prediction = model.predict(input_data)
if 0 in prediction:print('survive')
else:print('do not survive')
Pclass(1-3):2
Sex(male:1,female:0):1
Age:25
SibSp:0
Parch:0
Fare:1000
survive
五、调优
5.1 超参数调优
在机器学习中,超参数是指在模型训练之前需要手动设置的参数。决策树和随机森林模型都有一些重要的超参数,调优这些超参数可以提高模型的性能。
决策树的超参数包括最大深度(max_depth)、最小样本划分数(min_samples_split)、最小叶子节点样本数(min_samples_leaf)等。通过调整这些超参数,可以控制决策树的复杂度和泛化能力。
随机森林的超参数包括决策树数量(n_estimators)、最大特征数(max_features)、最大深度(max_depth)等。通过调整这些超参数,可以控制随机森林的复杂度和泛化能力。
5.2 交叉验证和网格搜索
为了找到最优的超参数组合,可以使用交叉验证和网格搜索的方法。
交叉验证是一种评估模型性能的方法,它将数据集分成训练集和验证集,多次训练模型并计算验证集上的性能指标,最后取平均值作为模型的性能评估。
网格搜索是一种系统地遍历多个超参数组合的方法,通过交叉验证评估每个超参数组合的性能,最后选择性能最好的超参数组合作为最终模型的超参数。
下面是使用交叉验证和网格搜索调优决策树和随机森林模型的示例代码:
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier# 决策树调优
param_grid = {'max_depth': [3, 5, 7],'min_samples_split': [2, 4, 6],'min_samples_leaf': [1, 2, 3]
}
dt = DecisionTreeClassifier()
grid_search = GridSearchCV(dt, param_grid, cv=5)
grid_search.fit(X_train, y_train)
best_dt = grid_search.best_estimator_# 随机森林调优
param_grid = {'n_estimators': [50, 100, 200],'max_features': ['auto', 'sqrt', 'log2'],'max_depth': [3, 5, 7]
}
rf = RandomForestClassifier()
grid_search = GridSearchCV(rf, param_grid, cv=5)
grid_search.fit(X_train, y_train)
best_rf = grid_search.best_estimator_
5.3 提升模型性能的技巧和策略
除了调优超参数,还有一些其他的技巧和策略可以提升决策树和随机森林模型的性能。
一种常用的技巧是特征选择,通过选择最相关的特征来减少决策树和随机森林的复杂度,提高模型的泛化能力。
另一种常用的策略是集成学习,通过组合多个决策树或随机森林模型的预测结果来提高模型的性能。常见的集成学习方法包括投票法、平均法和堆叠法等。
下面是使用特征选择和集成学习提升决策树和随机森林模型性能的示例代码:
from sklearn.feature_selection import SelectKBest
from sklearn.ensemble import VotingClassifier# 特征选择
selector = SelectKBest(k=10)
X_train_selected = selector.fit_transform(X_train, y_train)
X_test_selected = selector.transform(X_test)# 集成学习
dt1 = DecisionTreeClassifier()
dt2 = DecisionTreeClassifier()
rf1 = RandomForestClassifier()
rf2 = RandomForestClassifier()
voting_clf = VotingClassifier(estimators=[('dt1', dt1), ('dt2', dt2), ('rf1', rf1), ('rf2', rf2)], voting='hard')
voting_clf.fit(X_train_selected, y_train)
通过调优超参数、特征选择和集成学习等技巧和策略,可以提高决策树和随机森林模型的性能,使其更适用于实际问题的解决。
相关文章:
【 Python 全栈开发 - 人工智能篇 - 45 】决策树与随机森林
文章目录 一、概念与原理1.1 决策树1.1.1 概念1.1.2 原理特征选择分割方法 1.1.3 优点与缺点1.1.4 Python常用决策树算法 1.2 随机森林1.2.1 概念1.2.2 原理1.2.3 优点与缺点1.2.4 Python常用随机森林算法 1.3 决策树与随机森林的比较1.3.1 相同之处1.3.2 不同之处 二、决策树算…...
SpringBoot集成kafka全面实战
本文是SpringBootKafka的实战讲解,如果对kafka的架构原理还不了解的读者,建议先看一下《大白话kafka架构原理》、《秒懂kafka HA(高可用)》两篇文章。 一、生产者实践 普通生产者 带回调的生产者 自定义分区器 kafka事务提交…...
新建Git仓库,将本地文件上传至仓库
1、新建仓库,勾选初始化仓库 2、复制仓库链接 3、打开本地文件目录 右键选择 Git Bash Here 打开命令窗口 4、依次按照下面的步骤(*如果报错,看原目录下是否存在 .git 需要删除) // 生成git文件 git init // 把文件加入暂存区 g…...

算法练习——力扣随笔【LeetCode】【C++】
文章目录 LeetCode 练习随笔力扣上的题目和 OJ题目相比不同之处?定义问题排序问题统计问题其他 LeetCode 练习随笔 做题环境 C 中等题很值,收获挺多的 不会的题看题解,一道题卡1 h ,多来几道,时间上耗不起。 力扣上的题…...

web服务器(Tomcat)
目录 一、web服务器 1. 常见web服务器 2. web服务器简介 二、 Apache Tomcat服务器 1. Tomcat服务器简介 2. Tomcat服务器基本使用 3. 启动tomcat常见问题 (1)启动tomcat控制台乱码 (2)启动tomcat闪退问题 (…...

测试方案、功能测试报告、性能测试报告
测试方案内容概要: 项目内容介绍,测试计划安排(人员时间),测试环境(系统配置)需求功能点(内容介绍,测试安排),重点难点场景,系统集成…...
【代码随想录day21】二叉搜索树的最近公共祖先
题目 思路 解题的关键是知道自顶向低递归遍历,第一次遇到root在p和q的区间中时,则root就是p和q的最近公共祖先节点。 递归法 # Definition for a binary tree node. # class TreeNode: # def __init__(self, x): # self.val x # …...
ssm文章发布管理系统java小说作品发表jsp源代码mysql
本项目为前几天收费帮学妹做的一个项目,Java EE JSP项目,在工作环境中基本使用不到,但是很多学校把这个当作编程入门的项目来做,故分享出本项目供初学者参考。 一、项目描述 ssm文章发布管理系统 系统有2权限:前台账…...

AXI协议之AXILite开发设计(二)
微信公众号上线,搜索公众号小灰灰的FPGA,关注可获取相关源码,定期更新有关FPGA的项目以及开源项目源码,包括但不限于各类检测芯片驱动、低速接口驱动、高速接口驱动、数据信号处理、图像处理以及AXI总线等 二、AXI-Lite关键代码分析 1、时钟与…...
Qgis二次开发-QgsMapTool地图交互工具详解
1.简介 QgsMapTool地图工具是用于操作地图画布的用户交互式工具。例如,地图平移和缩放功能被实现为地图工具。 QgsMapTool是抽象基类,以下是类的继承关系: 2.常用接口 virtual void canvasDoubleClickEvent (QgsMapMouseEvent *e)重写鼠标…...
MySQL基础(四)数据库备份
目录 前言 一、概述 1.数据备份的重要性 2.造成数据丢失的原因 二、备份类型 (一)、物理与逻辑角度 1.物理备份 2.逻辑备份 (二)、数据库备份策略角度 1.完整备份 2.增量备份 三、常见的备份方法 四、备份(…...
子类化QThread来实现多线程,moveToThread函数的作用
子类化QThread来实现多线程, QThread只有run函数是在新线程里的,其他所有函数都在QThread生成的线程里。正确启动线程的方法是调用QThread::start()来启动。 一、步骤 子类化 QThread;重写run,将耗时的事件放到此函数执行&#…...
经典面试题(力扣,接雨水)
接雨水 方法一思路测试代码复杂度测试结果 方法二思路测试代码复杂度测试结果 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1]…...

2023年深圳杯数学建模C题无人机协同避障航迹规划
2023年深圳杯数学建模 C题 无人机协同避障航迹规划 原题再现: 平面上A、B两个无人机站分别位于半径为500 m的障碍圆两边直径的延长线上,A站距离圆心1 km,B站距离圆心3.5 km。两架无人机分别从A、B两站同时出发,以恒定速率10 m/s…...
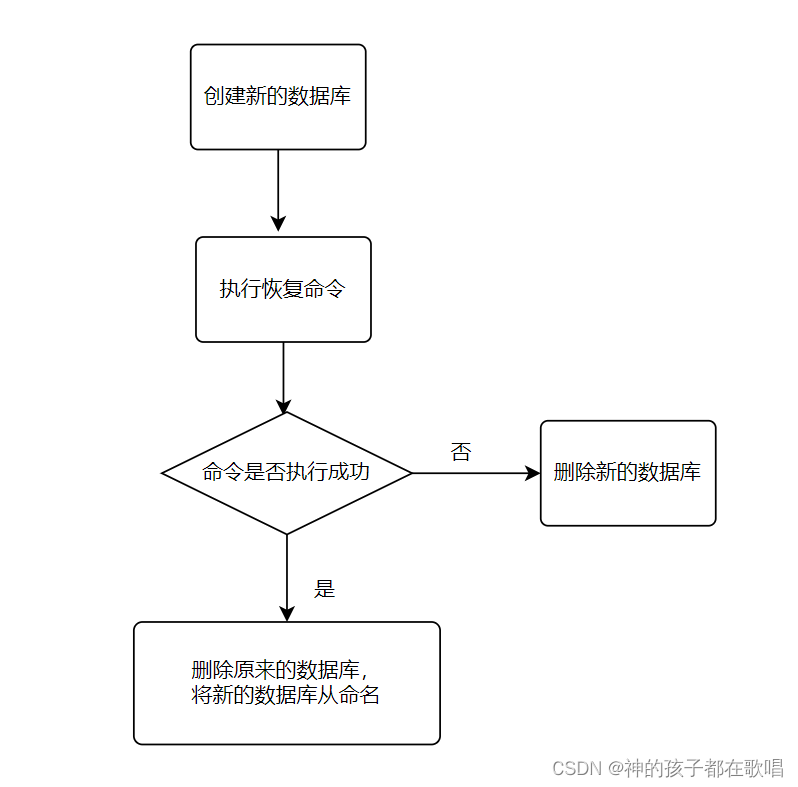
PostgreSQL--实现数据库备份恢复详细教学
前言 这是我在这个网站整理的笔记,关注我,接下来还会持续更新。 作者:RodmaChen PostgreSQL--实现数据库备份恢复详细教学 一. 数据库备份二. 数据库恢复三. 存留问题 数据库备份恢复功能是每个产品所需的,以下是简单的脚本案例&a…...

JDK工具之jstack说明
JDK工具之jstack说明 前言什么是jstack?如何使用jstack?获取Java进程的PID分析jstack输出 常用的jstack命令选项jstack的应用场景结论 前言 作为Java开发人员,在开发和维护复杂的Java应用程序时,我们经常会遇到各种各样的问题&am…...

34 | 牛顿迭代法
文章目录 牛顿迭代法一、原理二、Python实现三、练习题四、总结牛顿迭代法 一、原理 牛顿迭代法(Newton’s Method)是一种用于寻找方程的实根的数值方法。其基本思想是通过一系列逼近来求解方程的根。对于方程 f ( x ) = 0 f(x) = 0 f(x...

ChatGPT如何帮助学生学习
一些教育工作者担心学生可能使用ChatGPT作弊。因为这个AI工具能写报告和计算机代码,画出复杂图表……甚至已经有许多学校把ChatGPT屏蔽。 研究发现,学生作弊的主要原因是想考得好。是否作弊与作业和考试的打分方式有关,所以这与技术的便…...

easyexcel导出excel-50行代码搞定大量数据导出
文章目录 一、写在前面二、使用步骤定义导出的数据实体导出 一、写在前面 场景: 当数据量导出过大时如果一次从数据库取出所有数据会导致内存飙升导致系统奔溃,所以我们采取循环读取和循环写入。 准备: mave导入:easyexcel:3.0.5 二、使用…...
OpenAI宣布安卓版ChatGPT正式上线;一站式 LLM底层技术原理入门指南
🦉 AI新闻 🚀 OpenAI宣布安卓版ChatGPT正式上线 摘要:OpenAI今日宣布,安卓版ChatGPT已正式上线,目前美国、印度、孟加拉国和巴西四国的安卓用户已可在谷歌Play商店下载,并计划在下周拓展到更多地区。Chat…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...

从电磁炉到户外电源:拆解单相SVPWM如何让你的逆变器更安静、更高效
从电磁炉到户外电源:单相SVPWM如何实现静音与高效的双重突破当你深夜用电磁炉煮面时,是否曾被突然的蜂鸣声吓一跳?或是发现户外电源给设备充电时,散热风扇的噪音盖过了山林鸟鸣?这些常见问题背后,隐藏着一个…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

RevSSH反向SSH隧道:无公网IP设备的安全远程运维方案
1. 这不是又一个SSH封装工具——RevSSH解决的是“根本性连接悖论”你有没有遇到过这样的场景:一台部署在客户内网的嵌入式设备,没有公网IP,NAT穿透失败,防火墙策略死死锁住所有入向端口,连ICMP都被禁了;或者…...
)
Unity/Unreal开发者必看:用手机和陀螺仪实验,5分钟搞懂万向节死锁(附避坑指南)
Unity/Unreal开发者实战指南:用手机陀螺仪5分钟破解万向节死锁当你调试第一人称视角时,角色突然卡在墙面无法转动;当无人机模型在俯冲90度时失控乱转——这些很可能都是万向节死锁(Gimbal Lock)在作祟。作为实时3D开发中最恼人的数学陷阱之一…...

5A智慧景区建设|对标一流!巨有科技打造数智化标杆景区
5A级景区是中国旅游的最高标准,代表着服务与管理的顶尖水平。随着5A评审标准日益严苛,“智慧化”已成为核心硬性指标。然而,不少景区的智慧化建设陷入“重硬件、轻整合”的误区,系统林立、数据孤岛,投入巨大却效果不佳…...

通过Taotoken标准OpenAI协议实现分钟级集成现有代码
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken标准OpenAI协议实现分钟级集成现有代码 1. 迁移背景与核心思路 许多开发团队在构建AI应用时,会直接使用O…...
)
微信聊天图片丢了别慌!保姆级教程:找回并解密DAT文件(支持新旧版微信路径)
微信DAT图片恢复实战:从文件定位到批量解密的完整指南 微信聊天记录中的图片突然消失?别急着放弃!那些看似无法打开的DAT文件里,可能藏着您的重要回忆或工作资料。本文将带您深入微信存储机制,手把手完成从文件定位到…...

完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包
完整指南:如何在5分钟内快速上手BioAge生物年龄计算工具包 【免费下载链接】BioAge Biological Age Calculations Using Several Biomarker Algorithms 项目地址: https://gitcode.com/gh_mirrors/bi/BioAge BioAge生物年龄计算工具包是一款基于R语言开发的强…...