LLM 大语言模型 Prompt Technique 论文精读-3
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents 面向可扩展的基于语言引导的真实世界网络交互
链接:https://arxiv.org/abs/2207.01206
摘要:现有的用于在交互环境中引导语言的基准测试要么缺乏真实世界的语言元素,要么由于数据收集或反馈信号中涉及大量人类参与而难以扩展。为了弥合这一差距,我们开发了WebShop——一个模拟的电子商务网站环境,拥有118万个真实世界的产品和12,087个众包文本指令。给定一个指定产品要求的文本指令,代理需要导航多种类型的网页并发出各种操作来查找、定制和购买商品。WebShop提供了几个语言引导的挑战,包括理解组合指令、查询(重新)构建、理解和处理网页中的嘈杂文本,以及进行战略性探索。我们收集了超过1600个人类示范任务,并使用强化学习、模仿学习和预训练的图像和语言模型训练和评估了各种不同类型的代理。我们最好的模型实现了29%的任务成功率,超过了基于规则的启发式方法(9.6%),但远低于人类专家的表现(59%)。我们还分析了代理和人类的轨迹,并对各种模型组件进行了消融分析,为开发具有更强语言理解和决策能力的未来代理提供了见解。最后,我们展示了在amazon.com和ebay.com上评估时,在WebShop上训练的代理表现出非平凡的模拟到真实世界的迁移,表明WebShop在开发能够在实际网络环境中运行的实用网络代理方面具有潜在价值。
关键词:grounding language, interactive environments, WebShop, e-commerce website, real-world products, text instructions, language grounding, reinforcement learning, imitation learning, pre-trained models, task success rate, sim-to-real transfer
关键见解:
- WebShop是一个模拟的电子商务网站环境,具有118万个真实世界产品和12,087个众包文本指令。
- WebShop提供了多种语言基础的挑战,包括理解组合指令、查询重构、理解和处理网页中的噪声文本,以及进行战略性探索。
- 通过强化学习、模仿学习和预训练的图像和语言模型,我们训练和评估了各种不同类型的代理模型。
- 最佳模型的任务成功率为29%,优于基于规则的启发式方法(9.6%),但远低于人类专家的表现(59%)。
- 通过分析代理和人类的轨迹,并对各种模型组件进行消融实验,为开发具有更强语言理解和决策能力的未来代理提供了见解。
- 最后,我们展示了在amazon.com和ebay.com上评估时,经过WebShop训练的代理表现出非平凡的模拟到真实世界的迁移能力,这表明了WebShop在开发能够在实际网络环境中运行的实用网络代理方面的潜在价值。
经验教训:
- 现有的基准测试环境在语言基础方面存在一些限制,需要更多真实世界的语言元素。
- 人类参与数据收集或反馈信号会导致基准测试环境难以扩展。
- 强化学习、模仿学习和预训练模型是训练和评估代理模型的有效方法。
- 代理模型的性能仍远低于人类专家,需要进一步提升语言理解和决策能力。
- WebShop训练的代理在真实世界的网站上表现出了一定的迁移能力,这对于开发实用的网络代理具有潜在价值。
相关建议:
- 进一步研究语言理解和决策能力:针对WebShop中的语言理解和决策能力的不足,可以进一步研究和改进模型,以提高任务成功率。可以探索使用更先进的强化学习算法、深度学习模型或结合图像和语言的方法来增强模型的能力。
- 改进数据收集方法:为了解决数据收集中的人力成本和困难问题,可以探索更高效的数据收集方法。例如,可以考虑使用自动化技术来生成更多的真实世界语言元素,并减少人工参与的程度。
- 深入分析模型组件:通过对模型组件进行深入分析,可以获得关于语言理解和决策能力的更多见解。可以通过消融实验等方法,研究不同模型组件对任务性能的影响,从而为未来开发更强大的语言理解和决策能力的代理提供指导。
- 探索实际应用场景:通过在实际网站(如amazon.com和ebay.com)上评估训练在WebShop上的代理模型,可以进一步验证WebShop在开发实际网络代理方面的潜在价值。可以研究如何进一步提高模型在真实环境中的泛化能力,以实现更好的实际应用效果。
- 拓展任务挑战:除了已有的任务挑战,可以考虑引入更多复杂的语言指令和操作,以提高任务的难度和多样性。可以探索如何处理更复杂的语言组合指令、更嘈杂的网页文本以及更具策略性的探索行为,从而推动语言理解和决策能力的进一步发展。
LoRA: Low-Rank Adaptation of Large Language Models 大型语言模型的低秩自适应
摘要:自然语言处理的主导范式包括对通用领域数据进行大规模预训练,以及对特定任务或领域进行适应。随着我们预训练的模型越来越大,传统的微调方法,即重新训练所有模型参数,变得不太可行。以GPT-3 175B为例,部署许多独立的微调模型实例,每个实例都有175B个参数,非常昂贵。我们提出了低秩自适应(LoRA)方法,它冻结了预训练模型的权重,并将可训练的秩分解矩阵注入到Transformer架构的每一层中,大大减少了下游任务的可训练参数数量。对于GPT-3,相比于完全微调,LoRA可以将可训练参数数量减少10,000倍,并将计算硬件需求减少3倍。尽管LoRA具有更少的可训练参数、更高的训练吞吐量和没有额外的推理延迟,但在GPT-3和GPT-2的模型质量上表现与微调相当甚至更好。我们还对语言模型自适应中的秩缺失进行了实证研究,这为LoRA的有效性提供了启示。我们在GPT-2中发布了我们的实现,网址为https://github.com/microsoft/LoRA。
关键词:LoRA, large language models, pre-training, fine-tuning, trainable parameters, rank decomposition matrices, Transformer architecture
关键见解:
- 传统的大规模预训练和微调模型的方法在处理越来越大的语言模型时变得不可行。
- LoRA(Low-Rank Adaptation)通过在Transformer架构的每一层中注入可训练的秩分解矩阵,冻结预训练模型权重,从而大大减少了下游任务的可训练参数数量。
- 在GPT-3和GPT-2上,LoRA在模型质量上表现与微调相当甚至更好,尽管它具有更少的可训练参数、更高的训练吞吐量和没有额外的推理延迟。
经验教训:
- LoRA方法可以显著减少大型语言模型的可训练参数数量和计算硬件需求,同时保持模型质量。
- LoRA方法在处理大规模语言模型时具有更高的训练吞吐量,可以提高训练效率。
- 通过对语言模型自适应中的秩缺失进行实证研究,我们对LoRA的有效性有了更深入的了解。
注意:以上总结仅基于论文摘要,具体细节和结论可能需要进一步阅读完整论文来确认。
相关建议:
- 进一步研究和改进LoRA的性能:LoRA在GPT-3和GPT-2上表现出与fine-tuning相当甚至更好的模型质量,但仍有进一步改进的空间。可以通过实验和分析来探索不同的rank decomposition方法和参数设置,以提高LoRA在不同任务和领域上的适应性和性能。
- 探索LoRA在其他大型语言模型上的应用:LoRA的思想和方法可以尝试应用于其他大型语言模型,如BERT、RoBERTa等。通过在不同模型上的实验比较,可以进一步验证LoRA的通用性和有效性,并探索其在不同模型架构上的适应性。
- 研究LoRA在特定领域数据上的表现:本文主要关注LoRA在通用领域数据上的表现,但对于特定领域的数据,LoRA的适应性和性能如何仍需进一步研究。可以选择一些特定领域的数据集,如医疗、法律等,进行实验和评估,以验证LoRA在特定领域上的可行性和效果。
- 探索LoRA与其他模型压缩方法的结合:LoRA通过降低可训练参数的数量来减少计算硬件需求,但与其他模型压缩方法的结合可能会进一步提高性能和效率。可以尝试将LoRA与剪枝、量化等方法相结合,以进一步减少模型的存储和计算资源需求,同时保持模型的性能和质量。
- 推广和应用LoRA的开源实现:作者在GPT-2上实现了LoRA,并将其代码开源。可以进一步推广和应用这个开源实现,吸引更多的研究者和开发者使用LoRA,并在不同任务和领域上进行实验和应用,以验证和拓展LoRA的适用性和效果。
相关论文:
[1] Initialization and Regularization of Factorized Neural Layers
[2] The Power of Scale for Parameter-Efficient Prompt Tuning
[3] GPT Understands, Too
[4] WARP: Word-level Adversarial ReProgramming
[5] Intrinsic Dimensionality Explains the Effectiveness of Language Model Fine-Tuning
[6] Feature Learning in Infinite-Width Neural Networks
[7] AdapterDrop: On the Efficiency of Adapters in Transformers
[8] DART: Open-Domain Structured Data Record to Text Generation
[9] GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding
[10] When do neural networks outperform kernel methods?
FLASK: Fine-grained Language Model Evaluation based on Alignment Skill Sets 基于对齐技能集的细粒度语言模型评估FLASK
链接:https://arxiv.org/abs/2307.10928
摘要:由于对齐到人类价值观需要组合多种技能,并且所需的技能集因指令而异,因此评估大型语言模型(LLMs)具有挑战性。最近的研究以两种方式评估LLMs的性能:(1)在几个独立基准上进行自动评估,和(2)基于人工或机器的评估给出响应的总体得分。然而,这两种设置都是粗粒度评估,没有考虑到需要逐个实例进行技能组合的用户指令的性质,这限制了对LLMs真实能力的解释。在本文中,我们介绍了FLASK(基于对齐技能集的细粒度语言模型评估),这是一种细粒度评估协议,可用于基于模型和基于人的评估,将粗粒度评分分解为逐个实例的技能集级别。具体而言,我们定义了12种细粒度技能,用于LLMs遵循开放式用户指令,并通过为每个实例分配一组技能来构建评估集。此外,通过为每个实例注释目标领域和难度级别,FLASK提供了一个全面的视角,对模型的性能进行了综合分析,这取决于技能、领域和难度。通过使用FLASK,我们比较了多个开源和专有的LLMs,并观察到了基于模型和基于人的评估之间高度相关的发现。FLASK使开发人员能够更准确地衡量模型的性能,并通过分析使LLMs在特定技能上熟练的因素来改进模型。对于从业者来说,FLASK可以通过对各种LLMs进行全面比较,推荐适合特定情况的模型。我们在https://github.com/kaistAI/FLASK上发布了评估数据和代码实现。
关键词:FLASK, Fine-grained Language Model Evaluation, Alignment Skill Sets, Large Language Models, automatic evaluation, human-based evaluation, instance-wise skill composition
关键见解:
- 传统的评估方法无法准确评估大型语言模型(LLMs)的真实能力,因为它们没有考虑到用户指令的细粒度技能组合。
- FLASK是一种细粒度评估协议,可以用于模型和人工评估,将粗粒度评分分解为实例级别的技能集合。
- FLASK定义了12种细粒度技能,用于评估LLMs在遵循开放式用户指令时所需的技能。
- FLASK通过为每个实例分配一组技能来构建评估集,并通过为每个实例注释目标领域和难度级别,提供了对模型性能的全面分析。
- 使用FLASK,我们比较了多个开源和专有的LLMs,并观察到模型评估和人工评估之间高度相关的结果。
- FLASK使开发人员能够更准确地衡量模型的性能,并通过分析使LLMs在特定技能上熟练的因素来改进模型。
经验教训:
- 传统的粗粒度评估方法无法提供对LLMs真实能力的准确评估,需要采用细粒度评估方法。
- FLASK的细粒度评估协议可以帮助开发人员更好地理解模型的性能,并找到改进模型的方法。
- FLASK的评估结果可以用于为特定情况推荐适合的模型,对从业人员具有实际应用价值。
- FLASK的评估数据和代码实现已在https://github.com/kaistAI/FLASK 上发布,可以供其他研究者和开发人员使用。
相关建议:
- 进一步研究和扩展细粒度技能集:在FLASK中定义了12个细粒度技能,但可以考虑进一步研究和扩展这些技能集,以更全面地评估LLMs的能力。
- 探索其他评估指标:除了细粒度技能集,可以考虑引入其他评估指标,如语言流畅度、逻辑推理能力等,以更全面地评估LLMs的性能。
- 拓宽评估领域和难度级别:FLASK中注释了目标领域和难度级别,可以进一步拓宽评估领域和难度级别的范围,以更全面地了解LLMs在不同情境下的表现。
- 推广FLASK的应用:可以将FLASK应用于其他语言模型的评估,以及其他自然语言处理任务的评估,从而推广FLASK的应用范围。
- 进一步分析LLMs的性能提升方法:通过FLASK的分析结果,可以进一步研究和探索提升LLMs性能的方法,例如针对特定技能的训练策略或模型结构的改进。
Challenges and Applications of Large Language Models 大型语言模型的挑战和应用
链接:https://arxiv.org/abs/2307.10169
摘要:在机器学习领域,大型语言模型(LLMs)在几年内从不存在变得无处不在。由于领域发展迅速,很难确定剩余的挑战和已经取得的应用领域。本文旨在建立一个系统的开放问题和应用成功案例集,以便机器学习研究人员能够更快地了解该领域的当前状态并提高生产力。
关键词:Large Language Models, challenges, applications, machine learning, open problems, application successes, ML researchers
关键见解:
- Large Language Models (LLMs) have become widely discussed in the machine learning field in a short period of time.
- The field of LLMs is evolving rapidly, making it challenging to identify the remaining challenges and successful applications.
- The paper aims to provide a systematic set of open problems and application successes to help ML researchers understand the current state of the field and be more productive.
经验教训:
- Keeping up with the fast pace of the LLM field is crucial to stay informed about the latest challenges and applications.
- Systematically identifying open problems and successful applications can help researchers gain a comprehensive understanding of the field.
- By understanding the current state of LLMs, researchers can make more informed decisions and contribute effectively to the field.
相关建议:
- 研究LLMs的可解释性:LLMs在自然语言处理领域取得了巨大的成功,但其内部工作机制仍然是一个黑盒子。未来的研究可以探索如何解释LLMs的决策过程和生成结果,以提高其可解释性。
- 改进LLMs的训练和调优方法:目前的LLMs训练和调优方法仍然存在一些挑战,如训练时间长、需要大量的计算资源等。未来的研究可以致力于开发更高效、更稳定的训练和调优方法,以提高LLMs的性能和可用性。
- 探索LLMs在特定领域的应用:LLMs在自然语言处理领域的广泛应用已经取得了很多成功,但在特定领域的应用仍然有待探索。未来的研究可以针对特定领域,如医疗、法律等,探索LLMs的应用潜力,并开发相应的应用系统和工具。
- 研究LLMs的隐私和安全性:LLMs在处理大量文本数据时可能涉及到用户隐私和数据安全的问题。未来的研究可以关注如何保护用户隐私和数据安全,同时提高LLMs的性能和效果。
- 推动LLMs与其他领域的交叉研究:LLMs在自然语言处理领域的应用已经取得了很多成果,但与其他领域的交叉研究仍然有待加强。未来的研究可以促进LLMs与计算机视觉、机器人学等领域的交叉研究,以实现更广泛的应用和进一步的创新。
相关文章:

LLM 大语言模型 Prompt Technique 论文精读-3
WebShop: Towards Scalable Real-World Web Interaction with Grounded Language Agents 面向可扩展的基于语言引导的真实世界网络交互 链接:https://arxiv.org/abs/2207.01206 摘要:现有的用于在交互环境中引导语言的基准测试要么缺乏真实世界的语言元…...
架构重构实践心得
一、前言 大多数的技术研发都对重构有所了解,而每个研发又都有自己的理解。从代码重构到架构重构,我参与了携程大型全链路重构项目,积累了一点经验心得,在此抛砖引玉和大家分享。 二、重构的定义 重构是指在不改变外部行为的情…...
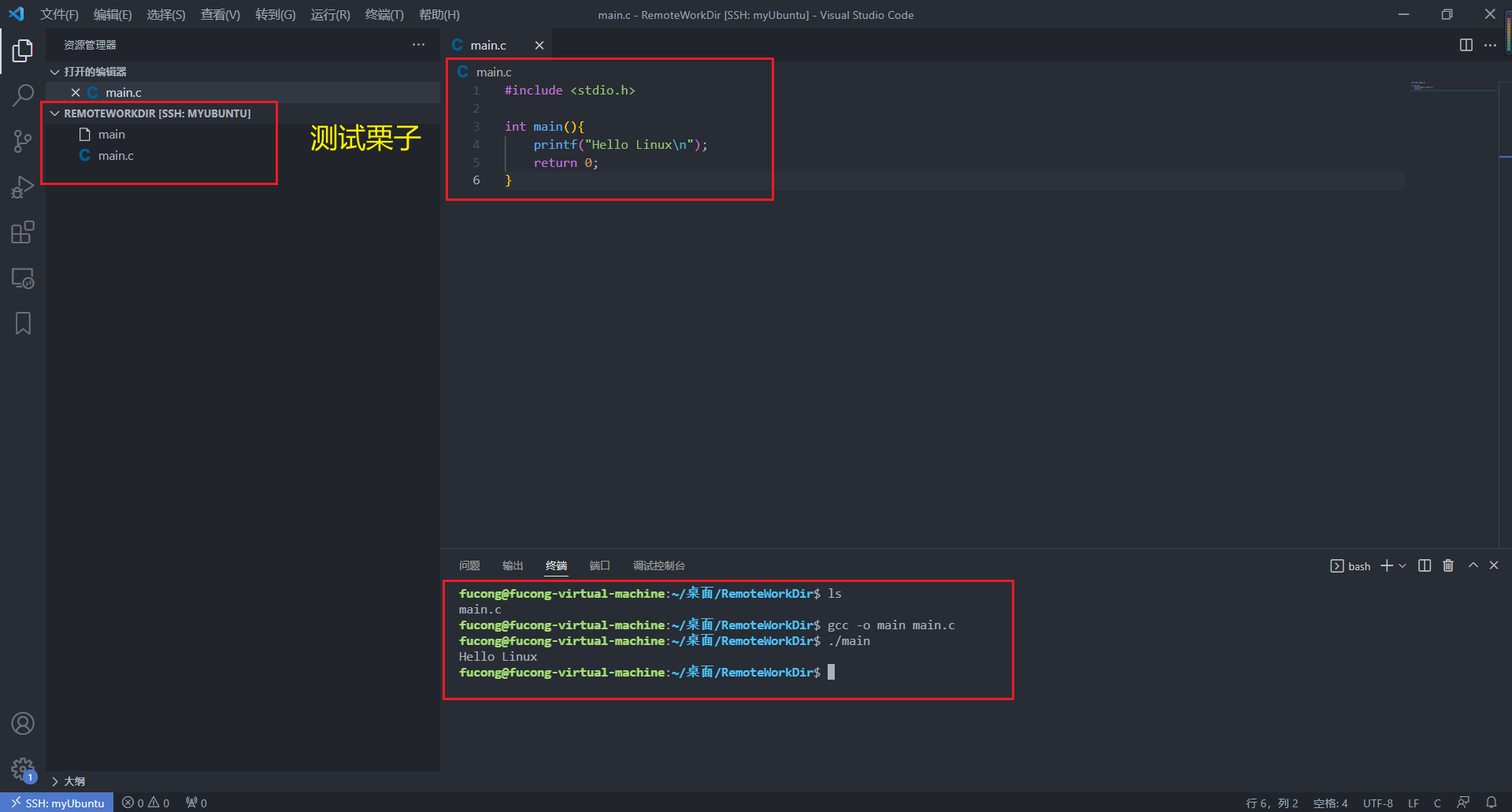
【配置环境】Windows下 VS Code 远程连接虚拟机Ubuntu
一,环境 Windows 11 家庭中文版VMware Workstation 16 Pro (版本:16.1.2 build-17966106)ubuntu-22.04.2-desktop-amd64 二,关键步骤 Windows下安装OpenSSHVS Code安装Remote - SSH插件 三,详细步骤 在Ubun…...
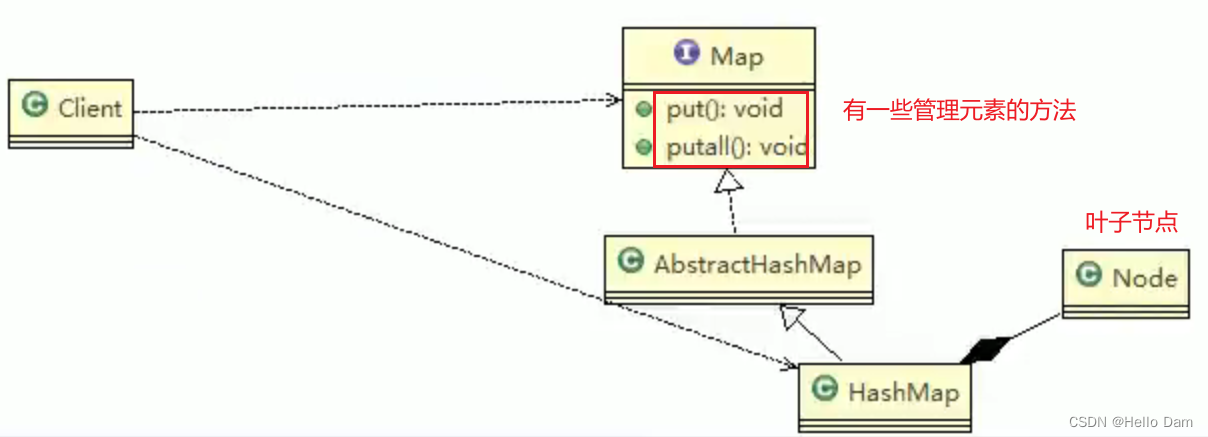
【设计模式——学习笔记】23种设计模式——组合模式Composite(原理讲解+应用场景介绍+案例介绍+Java代码实现)
案例引入 学校院系展示 编写程序展示一个学校院系结构: 需求是这样,要在一个页面中展示出学校的院系组成,一个学校有多个学院,一个学院有多个系 【传统方式】 将学院看做是学校的子类,系是学院的子类,小的组织继承大…...
vue3+Luckysheet实现表格的在线预览编辑(electron可用)
前言: 整理中 官方资料: 1、github 项目地址https://github.com/oy-paddy/luckysheet-vue-importAndExport/tree/master/https://github.com/oy-paddy/luckysheet-vue-importAndExport/tree/master/ 2、xlsx vue3 json数据导出excel_vue3导出excel_羊…...

前端html中让两个或者多个div在一行显示,用style给div加上css样式
文章目录 前言一、怎么让多个div在一行显示 前言 DIV是层叠样式表中的定位技术,全称DIVision,即为划分。有时可以称其为图层。DIV在编程中又叫做整除,即只得商的整数。 DIV元素是用来为HTML(标准通用标记语言下的一个应用&#x…...

【linux基础(二)】Linux基本指令(中)
💓博主CSDN主页:杭电码农-NEO💓 ⏩专栏分类:Linux从入门到开通⏪ 🚚代码仓库:NEO的学习日记🚚 🌹关注我🫵带你学更多操作系统知识 🔝🔝 Linux基本指令 1. 前言2. 删除…...

ceph集群---使用RBD块存储
文章目录 创建和删除池RBD设备的配置及使用RBD 块设备数据的导出和导入 块存储接口是一种主流的存储访问接口,也是常见的存储形态,比如服务器下的/dev/sdx都是块存储设备。你可以像使用磁盘一样来使用Ceph提供的块存储设备。 在创建块存储设备之前&#…...
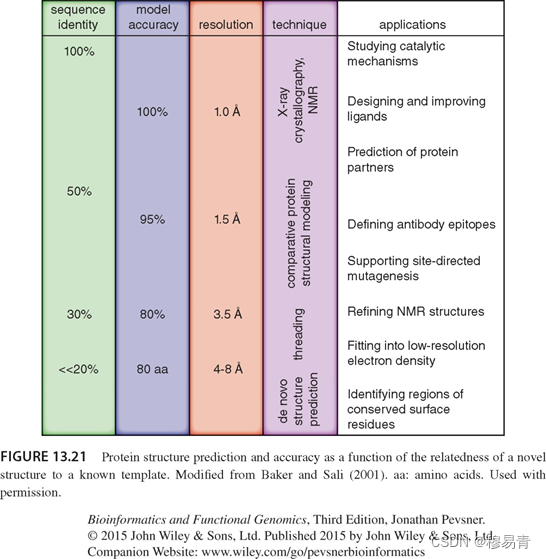
2022.09.17【读书笔记】丨生物信息学与功能基因组学(第十三章 蛋白质结构预测 下)
目录 蛋白质结构预测三种方法同源建模(比较建模)穿线法从头预测(ab initio)基于假设推荐策略 精度与方法选择Alphafold2相关信息 蛋白质结构预测 三种方法 同源建模(比较建模) 建模4步骤 1.模板选择和确定折叠构象 通过blast或delta-blast搜索同源蛋白…...

ardupilot获取飞行员目标倾斜角度
目录 文章目录 目录摘要1. 4.0.7获取目标倾斜角度2. 4.3.7获取目标倾斜角度3.仿真摘要 本节主要记录ardupilot获取目标倾斜角度的两种实现方法,主要针对4.0.7和4.3.7进行对比。 1. 4.0.7获取目标倾斜角度 1.姿态模式下获取函数 //获取飞行员期望的倾斜角度get_pilot_desire…...
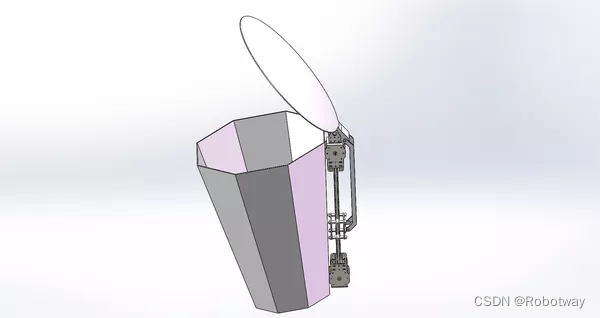
机器人制作开源方案 | 智能垃圾桶
1. 功能说明 智能垃圾桶是一种利用物联网技术和智能感知能力的智能设备,旨在提高垃圾分类和处理的效率。通常具备以下特点和功能: ① 智能感知:智能垃圾桶配备各种传感器,如压力传感器、红外线传感器等,可以实时感知…...

【手撕】list
系列文章目录 文章目录 系列文章目录前言list_node<T>(节点)_list_iterator<T, Ref, Ptr>(迭代器)成员变量构造函数运算符重载 List<T>(链表)成员变量构造函数析构函数区间构造函数拷贝构…...

QMQTT快速入门
文章目录 QMQTT快速入门环境搭建mosquitto 服务器和客户端配置服务器配置客户端配置模拟MQTT的发布订阅 QMQTT - Windows下的客户端项目代码展示遇到的问题 QMQTT快速入门 环境搭建 准备一台linux设备和一台windows设备虚拟机也是可以的;安装mosquitto ࿱…...

Dooring-Saas低代码技术详解
hello, 大家好, 我是徐小夕, 今天和大家分享一下基于 H5-Dooring零代码 开发的全新零代码搭建平台 Dooring-Saas 的技术架构和设计实现思路. 背景介绍 3年前我上线了第一版自研零代码引擎 H5-Dooring, 至今已迭代了 300 多个版本, 主要目的是快速且批量化的生产业务/营销过程中…...

Linux chmod
chmod 首先chmod 用于修改文件权限,使用命令 ll 查看文件列表,或者使用stat文件名 可以查看其相应的权限 显示的形式为例如 rwx r- - r-- ,即所有者拥有读写执行的权限 ,同组人员和其他人都只拥有读的权限 一般修改权限为三部分…...

java商城系统和php商城系统有什么差异?如何选择?
java商城系统和php商城系统是两种常见的电子商务平台,它们都具有一定的优势和劣势。那么,java商城系统和php商城系统又有哪些差异呢? 一、开发难度 Java商城系统和PHP商城系统在开发难度方面存在一定的差异。Java商城系统需要使用Java语言进…...
)
【HTML】常用实体字符(如 nbsp; 空格)
文章目录 显示结果描述实体名称实体编号空格 <小于号<<>大于号>>&和号&"引号" ’撇号' (IE不支持)¢分(cent)¢¢£镑(pound)£ £元&…...
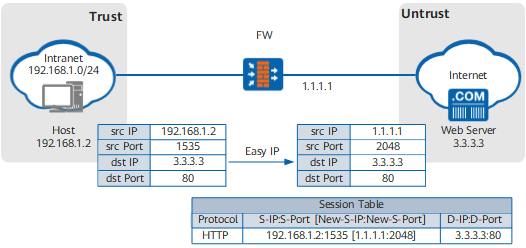
华为eNSP通过VMnet8虚拟网卡,NAT转换访问互联网
防火墙上配置: 配置G1/0/1接口IP地址,其实G1/0/1的IP就是终端PC1的网关地址。 配置G1/0/0接口自动获取IP地址,从VMnet8中自动获取地址。 配置安全区域zone,把对应的接口加入到对应的zone中 配置安全策略,放通trust安全区域到u…...

手撕顺序表
> 作者简介:დ旧言~,目前大一,现在学习Java,c,c,Python等 > 座右铭:松树千年终是朽,槿花一日自为荣。 > 望小伙伴们点赞👍收藏✨加关注哟💕…...

Python实战项目——旅游数据分析(四)
由于有之前的项目,所以今天我们直接开始,不做需求分析,还不会需求分析的可以看我之前的文章。Python实战项目——用户消费行为数据分析(三) 导入库 import numpy as np import pandas as pd import matplotlib.pyplo…...

AI大模型岗位薪资揭秘:2026大模型岗位薪资,非常详细收藏我这一篇就够了
1. AI系统架构师 薪资范围:100万 - 200万/年 职位要求:需要具备全面的技术背景,精通系统架构设计,能够有效整合AI技术,提升系统性能。要求硕士及以上学历,计算机科学或相关专业背景。 目标院校࿱…...
)
从锡膏印刷到炉温曲线:手把手调试你的第一条SMT生产线(避坑指南)
从锡膏印刷到炉温曲线:手把手调试你的第一条SMT生产线(避坑指南) 第一次接手SMT生产线调试时,我盯着那台二手贴片机的报警提示,手心全是汗。钢网上残留的锡膏像在嘲笑我的无知,而流水线上堆积的PCB板则不断…...
)
别死记硬背了!用Python的NumPy库,5分钟搞定线性代数里的矩阵运算(附代码)
用Python的NumPy库轻松玩转线性代数:矩阵运算实战指南 线性代数作为现代科学与工程的基石,在机器学习、计算机图形学、量化金融等领域无处不在。但传统教材中抽象的数学符号和繁琐的手工计算,往往让学习者望而生畏。今天,我们将用…...

MySQL服务启动失败:NET HELPMSG 3534错误全面解析与实战解决方案
1. 遇到NET HELPMSG 3534错误时该怎么办 当你兴致勃勃地安装完MySQL,准备大干一场时,突然在命令行输入net start mysql后,屏幕上跳出"MySQL服务无法启动。服务没有报告任何错误。请键入NET HELPMSG 3534以获得更多的帮助"这样的提…...

5分钟搞定fastANI安装与基因组比对:从conda安装到结果解读全流程
5分钟搞定fastANI安装与基因组比对:从conda安装到结果解读全流程 第一次接触基因组比对时,我被各种复杂的参数和晦涩的结果文件搞得晕头转向。直到发现了fastANI这个神器——它不仅能快速计算基因组间的平均核苷酸相似性(ANI)&am…...

力扣原题《有效的数独游戏》,纯手搓,已验证
请你判断一个 9 x 9 的数独是否有效。只需要 根据以下规则 ,验证已经填入的数字是否有效即可。 数字 1-9 在每一行只能出现一次。 数字 1-9 在每一列只能出现一次。 数字 1-9 在每一个以粗实线分隔的 3x3 宫内只能出现一次。(请参考示例图) 注…...

如何高效使用抖音批量下载工具:3个技巧让视频收集效率提升90%
如何高效使用抖音批量下载工具:3个技巧让视频收集效率提升90% 【免费下载链接】douyin-downloader 项目地址: https://gitcode.com/GitHub_Trending/do/douyin-downloader 在短视频内容爆炸的时代,抖音作为国内领先的内容平台,每天产…...

Qwen3.5-4B-Claude-Opus部署教程:supervisor托管+健康检查全流程详解
Qwen3.5-4B-Claude-Opus部署教程:supervisor托管健康检查全流程详解 1. 模型介绍 Qwen3.5-4B-Claude-4.6-Opus-Reasoning-Distilled-GGUF 是一个基于 Qwen3.5-4B 的推理蒸馏模型,重点强化了结构化分析、分步骤回答、代码与逻辑类问题的处理能力。该版本…...

多模态扩展:OpenClaw+GLM-4.7-Flash处理图片信息
多模态扩展:OpenClawGLM-4.7-Flash处理图片信息 1. 为什么需要多模态能力 上周我在整理产品截图时遇到一个典型问题:需要从200多张UI截图中提取所有按钮文字和位置信息。手动操作不仅耗时,还容易遗漏细节。这让我开始思考——能否让OpenCla…...

造相-Z-Image-Turbo亚洲美女LoRA创作实战:三个案例教你玩转AI绘画
造相-Z-Image-Turbo亚洲美女LoRA创作实战:三个案例教你玩转AI绘画 1. 认识造相-Z-Image-Turbo与亚洲美女LoRA 造相-Z-Image-Turbo是一款强大的AI图片生成模型,而亚洲美女LoRA则是专门针对亚洲人物特征优化的风格适配器。这个组合让普通用户也能轻松创作…...