深度探索 Elasticsearch 8.X:function_score 参数解读与实战案例分析
在 Elasticsearch 中,function_score 可以让我们在查询的同时对搜索结果进行自定义评分。
function_score 提供了一系列的参数和函数让我们可以根据需求灵活地进行设置。
近期有同学反馈,function_score 的相关参数不好理解,本文将深入探讨 function_score 的核心参数和函数。

1、function_score 函数的用途及适用场景
Elasticsearch 的 function_score 查询是一种强大的工具,它可以允许我们修改文档的基本的相关评分,让我们在特定的应用场景下获得更好的搜索结果。
这个功能通过提供了一组内置函数(如 script_score, weight, random_score, field_value_factor, decay functions等),以及一系列参数(如boost_mode和score_mode等)来实现。
以下是一些 function_score 可以应用的场景:
1.1 用户偏好场景
如果需要了解用户的兴趣或者行为,我们可以使用 function_score 来提升用户可能感兴趣的结果。
比如在推荐系统中,如果我们已知道用户喜欢某个作者的文章,可以提升这个作者的文章的得分。
比如最近火热的“罗刹海市”就被网易云音乐推荐到最前面。
1.2 随机抽样场景
如果我们需要从一个大的数据集中随机抽样,可以使用 random_score 函数。
这个函数会给每个文档生成一个随机得分,从而让我们能够得到随机的搜索结果。
1.3 时间敏感的查询场景
对于一些时间敏感的数据,比如新闻、博客文章或者论坛帖子,新的文档通常比旧的文档更相关。
在这种情况下,我们可以使用 decay functions(衰减函数) 来降低旧的文档的得分。
1.4 地理位置敏感的查询场景
如果我们的应用关心地理位置,比如房地产或者旅游相关的应用。
可以使用 decay functions (衰减函数)来提升接近某个地理位置的文档的得分。
1.5 特定字段影响场景
如果我们的文档有一些字段值可以影响相关度评分,可以使用 field_value_factor (字段值因子)函数。
比如在电商场景,一个商品的销量、评分或者评论数量可能会影响搜索结果的排序。
总的来说,function_score 提供了一种灵活的方式来满足各种复杂的相关度评分需求。
2、function_score 参数介绍
2.1 boost_mode 参数
boost_mode 决定了如何将查询得分和函数得分进行组合。
可接受的参数有:
| boost_mode | 描述 |
|---|---|
| multiply | 查询得分和函数得分相乘(默认值) |
| sum | 查询得分和函数得分相加 |
| avg | 查询得分和函数得分的平均值 |
| first | 仅仅使用函数得分 |
| max | 查询得分和函数得分中的最大值 |
| min | 查询得分和函数得分中的最小值 |
| replace | 完全替换查询得分,只使用函数得分 |
2.2 score_mode
score_mode 决定了如何处理多个函数的分数。
可接受的参数有:
| score_mode | 描述 |
|---|---|
| multiply | 各个函数得分相乘 |
| sum | 各个函数得分相加(默认值) |
| avg | 各个函数得分的平均值 |
| first | 仅仅使用第一个函数的得分 |
| max | 各个函数得分中的最大值 |
| min | 各个函数得分中的最小值 |
2.3 提供的函数
function_score 提供了多种函数类型来进行自定义评分:
| Score Function | 描述 |
|---|---|
| script_score | 用脚本计算得分 |
| weight | 简单地修改查询得分,不考虑字段值 |
| random_score | 生成随机得分 |
| field_value_factor | 使用字段值进行计算得分 |
| decay functions | 衰减函数,根据字段值的距离计算得分,越近得分越高 |
3、function_score 使用实战解读
3.1 构造数据
为了帮助大家更好地理解,我们将创建一个简单的索引,插入一些文档,并对它们执行 function_score 查询。
假设我们有一个名为 articles 的索引,里面存储了一些博客文章的数据,包括作者(author),标题(title),内容(content),以及这篇文章的喜欢数量(likes)。
首先,创建索引并添加一些文档:
PUT /articles
{"mappings": {"properties": {"title": { "type": "text" },"author": { "type": "text" },"content": { "type": "text" },"likes": { "type": "integer" }}}
}POST /_bulk
{ "index" : { "_index" : "articles", "_id" : "1" } }
{ "title": "Elasticsearch Basics", "author": "John Doe", "content": "This article introduces the basics of Elasticsearch.", "likes": 100 }
{ "index" : { "_index" : "articles", "_id" : "2" } }
{ "title": "Advanced Elasticsearch", "author": "Jane Doe", "content": "This article covers advanced topics in Elasticsearch.", "likes": 500 }
{ "index" : { "_index" : "articles", "_id" : "3" } }
{ "title": "Elasticsearch Function Score Query", "author": "John Doe", "content": "This article discusses the function_score query in Elasticsearch.", "likes": 250 }现在我们有了一些文档,让我们对它们执行 function_score 查询。
3.2 使用 script_score 函数实现基于 'likes' 字段的对数加权排序
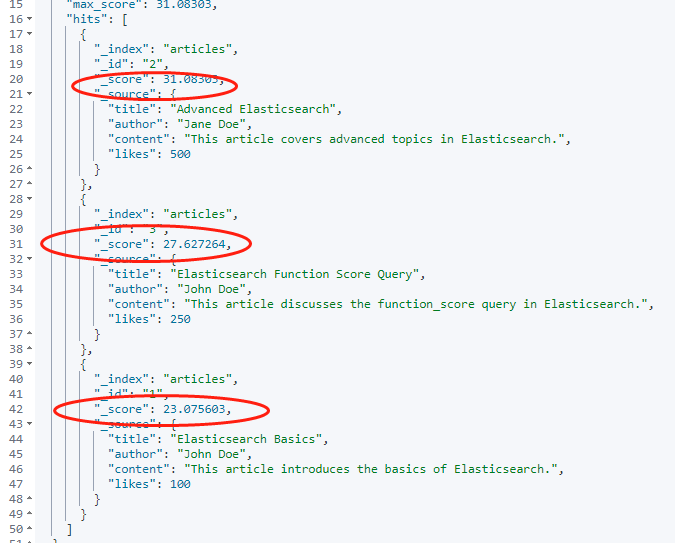
GET /articles/_search
{"query": {"function_score": {"query": {"match_all": {}},"boost": "5","functions": [{"script_score": {"script": {"source": "Math.log(1 + doc['likes'].value)"}}}],"boost_mode": "multiply"}}
}上述查询使用了 Elasticsearch 的 function_score 查询。
它首先对 "articles" 索引中的所有文档进行匹配(使用 match_all 查询),然后使用一个脚本函数(script_score),该脚本会计算每个文档的 "likes" 字段的自然对数值加一(Math.log(1 + doc['likes'].value)),然后把这个得分与原始查询得分相乘(由于 boost_mode 被设为了 "multiply"),最终的得分再乘以5(由于 boost 被设为了 "5")。这种查询用于根据 "likes" 字段对结果进行加权排序。
执行结果如下:
3.3 使用 random_score 生成基于 'likes' 字段的全随机结果查询
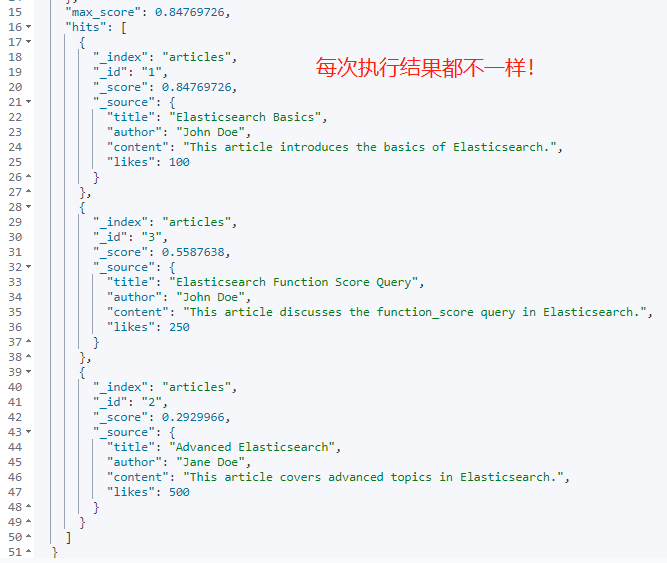
GET /articles/_search
{"query": {"function_score": {"query": { "match_all": {} },"functions": [{"random_score": {"field": "likes"}}],"boost_mode": "replace"}}
}上述查询使用 Elasticsearch 的 function_score 查询,并配合使用 random_score 函数。random_score 函数根据 "likes" 字段的值生成一个随机分数。
重要的是,由于没有提供一个固定的种子(seed),所以每次执行这个查询都会返回一个全新的随机排序结果。
match_all 是基础查询,用来匹配所有文档。然后 random_score 函数基于 "likes" 字段值生成随机分数。
boost_mode 设为 "replace" 表示忽略基础查询的分数,完全使用 random_score 函数的分数作为最终结果。所以,这个查询会在每次执行时都返回全新的随机排序结果。
执行结果如下图所示:
3.4 field_value_factor 函数根据某个字段的值来修改_score
这对于一些字段很有用,比如"likes":一篇有很多"likes"的文章可能比"likes"少的文章更相关。
示例如下:
GET /articles/_search
{"query": {"function_score": {"query": {"match": {"content": "Elasticsearch"}},"functions": [{"field_value_factor": {"field": "likes","factor": 1.2,"modifier": "sqrt","missing": 1}}],"boost_mode": "multiply"}}
}在这个查询中:
"match": { "content": "Elasticsearch" }
表示基础查询是在 "content" 字段中匹配包含 "Elasticsearch" 的文章。
field_value_factor
函数用来基于 "likes" 字段的值调整查询得分。它首先取 "likes" 字段的值,如果文档没有 "likes" 字段或者该字段的值为空,那么将使用 "missing" 参数指定的默认值1。然后,它将取得的值乘以 "factor" 参数指定的因子1.2。最后,它将结果进行 "modifier" 参数指定的平方根运算("sqrt")。
boost_mode
参数设置为 "multiply",这表示将基础查询的得分和 field_value_factor 函数计算得出的得分相乘,以得到最终的文档得分。
所以,这个查询会返回包含 "Elasticsearch" 的文章,并且文章的得分会根据 "likes" 字段的值进行调整,"likes" 值越高的文章,得分也会越高。
执行结果如下:

3.5 decay functions 根据某个字段的值的距离来调整_score。
如果值接近某个中心点,得分就会更高。这对于日期或地理位置字段特别有用。
Elasticsearch 提供了三种衰减函数:线性(linear)、指数(exp)、和高斯(gauss)。
以下是使用 gauss 函数的一个示例:
GET /articles/_search
{"query": {"function_score": {"query": {"match": {"content": "Elasticsearch"}},"functions": [{"gauss": {"likes": {"origin": "100","scale": "20","offset": "0","decay": 0.5}}}],"boost_mode": "multiply"}}
}上述执行可概括为:使用 function_score 和 gauss 函数对含有 'Elasticsearch' 的文章进行基于 'likes' 字段的高斯衰减得分调整"。
在这个查询中:
"match": { "content": "Elasticsearch" }
表示基础查询是在 "content" 字段中匹配包含 "Elasticsearch" 的文章。
gauss
函数则是用来对 "likes" 字段的值进行高斯衰减处理。
其中,
| 参数 | 值 | 描述 |
|---|---|---|
| origin | 100 | 期望的中心点,即 "likes" 字段的最理想值 |
| scale | 20 | 表示衰减的速度,也就是距离 "origin" 值多远时,得分会衰减到原始得分的一半 |
| offset | 0 | 表示在距离 "origin" 多少的范围内不进行衰减 |
| decay | 0.5 | 表示当距离超过了 "scale" 之后,得分会以多快的速度衰减,例如 0.5 表示超过 "scale" 距离后,得分会衰减到原始得分的一半 |
boost_mode
参数设置为 "multiply",这表示将基础查询的得分和 gauss 函数计算得出的得分相乘,以得到最终的文档得分。
所以,这个查询会返回包含 "Elasticsearch" 的文章,并且文章的得分会根据 "likes" 字段的值进行高斯衰减处理,"likes" 值越接近100的文章,得分也会越高。

4、小结
在深入了解 Elasticsearch 的 function_score 后,我们可以明显感受到其在搜索应用中的强大作用。无论是基于特定字段值的排序,还是利用自定义脚本微调搜索结果,function_score 都能发挥其出色的性能。
尽管 function_score 的参数和选项多样,初看可能会觉得复杂,但只需理解各参数的含义和作用,我们就能根据需求灵活运用。实际案例中,我们使用了 script_score、field_value_factor、random_score 和 decay functions 等函数,演示了如何通过 function_score 满足复杂的搜索需求。
但是,我们也必须注意,在使用 function_score 时,要慎重考虑性能问题,因为复杂的函数和脚本可能占用大量计算资源。在实际应用中,我们应始终关注这一点,以维护良好的系统性能。
此外,随着数据和用户行为的不断变化,我们需要持续观察、学习和调整搜索策略,以不断提升用户体验。在这个过程中,function_score 将是我们强有力的工具。
总的来说,Elasticsearch 的 function_score 是一个强大而灵活的工具,只要我们深入了解并恰当使用,就能够挖掘其巨大的潜力,提升我们的搜索应用性能和用户体验。
推荐阅读
全网首发!从 0 到 1 Elasticsearch 8.X 通关视频
重磅 | 死磕 Elasticsearch 8.X 方法论认知清单
如何系统的学习 Elasticsearch ?
2023,做点事
实战 | Elasticsearch自定义评分的N种方法
干货 | 一步步拆解 Elasticsearch BM25 模型评分细节
Elasticsearch 如何把评分限定在0到1之间?

更短时间更快习得更多干货!
和全球 近2000+ Elastic 爱好者一起精进!

大模型时代,抢先一步学习进阶干货!
相关文章:
深度探索 Elasticsearch 8.X:function_score 参数解读与实战案例分析
在 Elasticsearch 中,function_score 可以让我们在查询的同时对搜索结果进行自定义评分。 function_score 提供了一系列的参数和函数让我们可以根据需求灵活地进行设置。 近期有同学反馈,function_score 的相关参数不好理解,本文将深入探讨 f…...
)
测牛学堂:软件测试之andorid app性能测试面试知识点总结(二)
APP性能测试指标之FPS 如果经常玩游戏的同学应该听过FPS。 FPS本来是图像领域中的概念,是指画面每秒传输的帧数。每秒钟帧数越多,所显示的动作就会越流畅。 但是因为功耗的限制,一般60fps就是跑满的效果了。 我们测试的话,一般…...

尚医通06:数据字典+EasyExcel+mongodb
内容介绍 1、数据字典列表前端 2、EasyExcel介绍、实例 3、数据字典导出接口、前端 4、数据字典导入接口、前端 5、数据字典添加redis缓存 6、MongoDB简介 7、MongoDB安装 8、MongoDB基本概念 数据字典列表前端 1、测试问题 (1)报错日志 &am…...

【前端知识】React 基础巩固(三十二)——Redux的三大原则、使用流程及实践
React 基础巩固(三十二)——Redux的三大原则 一、Redux的三大原则 单一数据源 整个应用程序的state被存储在一颗object tree 中,并且这个object tree 只存储在一个store中;Redux并没有强制让我们不能创建多个Store,但是那样做不利于数据维护…...

[NLP]使用Alpaca-Lora基于llama模型进行微调教程
Stanford Alpaca 是在 LLaMA 整个模型上微调,即对预训练模型中的所有参数都进行微调(full fine-tuning)。但该方法对于硬件成本要求仍然偏高且训练低效。 [NLP]理解大型语言模型高效微调(PEFT) 因此, Alpaca-Lora 则是利用 Lora…...
 】)
Linux Shell 脚本编程学习之【第5章 文件的排序、合并与分割 (第四部分之cut命令) 】
第5章 文件的排序、合并与分割 (第四部分之cut命令) 4 cut 命令4.1 选项及其意义4.2 输出字符 (-c)4.3 改变分隔符(-d)和提取特定域(-f) 5 paste 命令5.1 paste 命令选项及其意义5.2…...

php-golang-rpc jsonrpc和php客户端tivoka/tivoka包实践
golang 代码: package main import ( "fmt" "net" "net/rpc" "net/rpc/jsonrpc" ) type App struct{} type Res struct { Code int json:"code" Msg string json:"msg" Data any json:"…...
flutter 打包iOS安装包
flutter iOS Xcode打包并导出ipa文件安装包 1、 Xcode配置 1、 启动打包 1、 等待打包 1、 打包完成、准备导出ipa 1、 选择模式 1、 选择配置文件 1、 导出 1、 选择导出位置 1、 得到ipa...

二进制重排
二进制重排作用 二进制重排的主要目的是将连续调用的函数连接到相邻的虚拟内存地址,这样在启动时可以减少缺页中断的发生,提升启动速度。目前网络上关于ios应用启动优化,通过XCode实现的版本比较多。MacOS上的应用也是通过clang进行编译的&am…...
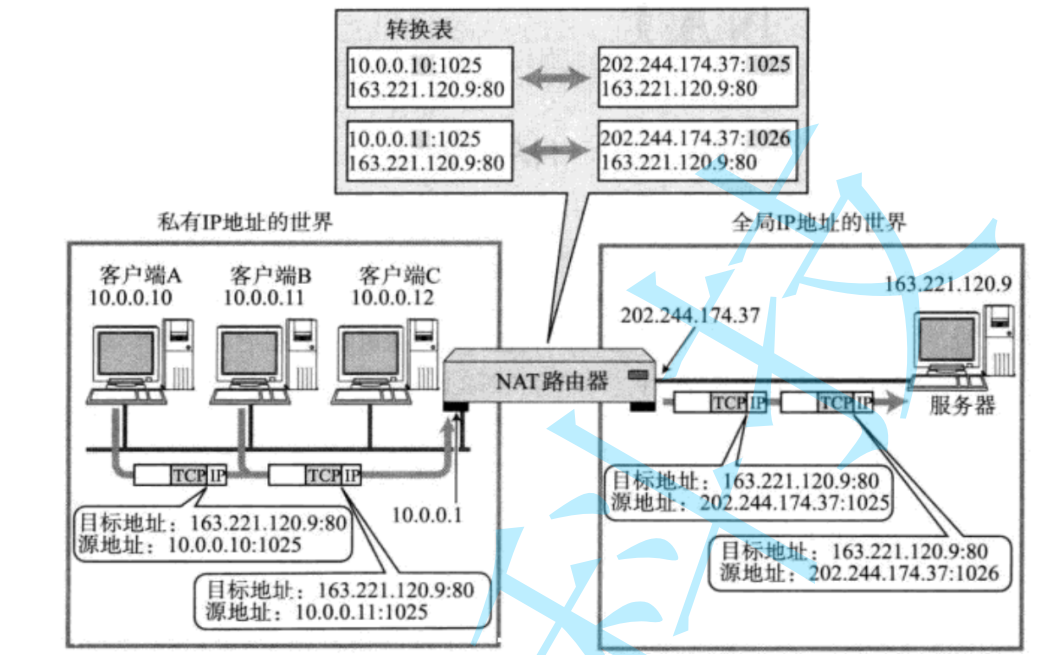
【Linux后端服务器开发】MAC地址与其他重要协议
目录 一、以太网 二、MAC地址 三、MTU 四、ARP协议 五、DNS系统 六、ICMP协议 七、NAT技术 八、代理服务器 一、以太网 “以太网”不是一种具体的网路,而是一种技术标准:既包含了数据链路层的内容,也包含了一些物理层的内容…...

WebGPU入门
1. 引言 前序博客: CUDA入门WebGPUZKP:客户端证明 WebGPU——Draft 2023.7.17 由苹果、谷歌、Mozilla团队发起,当前处于草稿阶段,旨在成为W3C推荐标准。 WebGPU为 在图形处理单元(GPU)上执行诸如渲染和…...
React Dva项目中.roadhogrc.mock.js直接自动导入mock目录下所有文件方式
上文 React Dva项目中模仿网络请求数据方法 中,我们书写了Dva项目模拟后端数据的方式 但是 我们.roadhogrc.mock.js中的这个处理其实并不好用 我们还需要一个一个的引入 我们可以直接靠一段代码 import fs from fs; import path from path; const mock {} fs.re…...
跨境独立站如何应对恶意网络爬虫?
目录 跨境出海独立站纷纷成立 爬虫威胁跨境电商生存 如何有效识别爬虫? 技术反爬方案 防爬虫才能保发展 中国出海跨境电商业务,主要选择大平台开设店铺,例如,亚马逊、eBay、Walmart、AliExpress、Zalando等。随着业务的扩大&…...

C# SourceGenerator 源生成器初探
简介 注意: 坑极多。而且截至2023年,这个东西仅仅是半成品 利用SourceGenerator可以在编译结束前生成一些代码参与编译,比如编译时反射之类的,还有模板代码生成都很好用。 演示仓库传送门-Github-yueh0607 使用 1. 创建项目 …...

网络安全/信息安全—学习笔记
一、网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等哪个领域,都有攻与防两面…...

【Visual Studio】无法打开包括文件: “dirent.h”: No such file or directory
VS2017/2019 无法打开包括文件: “dirent.h”: No such file or directory 1 “dirent.h”: No such file or directory 在windows下的VS2017/2019编译器中,发现无法打开“dirent.h”,主要是MSVC并没有实现这个头文件,但是在Linux这个头文件…...

asp.net MVC markdown编辑器
在 ASP.NET MVC 中,你可以使用一些第三方 Markdown 编辑器来让用户在网页上方便地编辑和预览 Markdown 内容。这些编辑器通常提供实时预览功能,将 Markdown 文本转换为实时渲染的 HTML,并支持编辑器工具栏来辅助用户编辑。 以下是一些流行的…...

论文浅尝 | 预训练Transformer用于跨领域知识图谱补全
笔记整理:汪俊杰,浙江大学硕士,研究方向为知识图谱 链接:https://arxiv.org/pdf/2303.15682.pdf 动机 传统的直推式(tranductive)或者归纳式(inductive)的知识图谱补全(KGC)模型都关注于域内(in-domain)数据,而比较少关…...
)
算法工程师-机器学习面试题总结(2)
线性回归 线性回归的基本思想是? 线性回归是一种用于建立和预测变量之间线性关系的统计模型。其基本思想是假设自变量(输入)和因变量(输出)之间存在线性关系,通过建立一个线性方程来拟合观测数据ÿ…...

低成本32位单片机空调内风机方案
空调内风机方案主控芯片采用低成本32位单片机MM32SPIN0230,内部集成了具有灵动特色的电机控制功能:高阶4路互补PWM、注入功能的高精度ADC、轨到轨运放、轮询比较器、32位针对霍尔传感器的捕获时钟、以及硬件除法器和DMA等电机算法加速引擎。 该方案具有…...
)
保姆级教程:在CentOS 7上用达梦8搭建DCA练习环境(附ulimit、VNC、ODBC全配置)
达梦8 DCA认证实战:CentOS 7环境搭建与调优全指南 在国产数据库技术快速发展的今天,达梦数据库作为核心产品之一,其DCA认证已成为众多从业者提升竞争力的重要选择。与理论为主的认证不同,DCA更注重实际操作能力,而一个…...
)
别再手动点菜单了!用这招让Cadence Virtuoso Schematic效率翻倍(附Net高亮快捷键配置)
电路设计效率革命:Cadence Virtuoso Schematic高阶快捷键配置指南 在集成电路设计的浩瀚宇宙中,Cadence Virtuoso如同设计师手中的光刻机,每一次精准操作都直接影响最终芯片的性能与可靠性。然而,当面对数百个晶体管组成的复杂模…...
到panic:深入Linux 5.4内核,看异常处理如何层层递进)
从BUG()到panic:深入Linux 5.4内核,看异常处理如何层层递进
从BUG()到panic:Linux内核异常处理的防御体系全解析当你在深夜调试一个内核模块时,突然屏幕刷出一串红色警告——这可能是每个Linux内核开发者都经历过的噩梦时刻。但你是否想过,从第一行警告出现到系统完全崩溃,内核究竟经历了怎…...

为什么鸿蒙 App 最终都会走向状态驱动?
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

在Hermes Agent项目中接入Taotoken作为自定义模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Hermes Agent项目中接入Taotoken作为自定义模型供应商 基础教程类,针对使用Hermes Agent框架的开发者,详…...

CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战
CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战 【免费下载链接】CSharpVerbalExpressions 项目地址: https://gitcode.com/gh_mirrors/cs/CSharpVerbalExpressions CSharpVerbalExpressions是一个强大的C#库,它通过类自然语…...

WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案
WarcraftHelper终极指南:深度解析魔兽争霸III现代化兼容性解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper WarcraftHelper是一款专…...

什么情况下会核销贷款
贷款核销的核心前提是:贷款被认定为 “损失类” 且经 “穷尽追偿” 仍无法收回,银行按监管与会计规则从账面冲销,但债权不消灭、仍可追偿。一、核心认定条件(满足其一即可)破产 / 注销 / 吊销:借款人和担保…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...

通过TaotokenCLI工具一键配置开发环境接入参数
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过Taotoken CLI工具一键配置开发环境接入参数 对于需要接入多个大模型服务的开发者而言,手动配置每个项目的API密钥、…...