大数据课程D5——hadoop的Sink
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 掌握Sink的HDFS Sink;
⚪ 掌握Sink的Logger Sink;
⚪ 掌握Sink的File Roll Sink;
⚪ 掌握Sink的Null Sink;
⚪ 掌握Sink的AVRO Sink;
⚪ 掌握Sink的Custom Sink;
一、HDFS Sink
1. 概述
1. HDFS Sink将收集到的数据写到HDFS中。
2. 在往HDFS上写的时候,支持三种文件类型:文本类型,序列类型以及压缩类型。如果不指定,那么默认使用使得序列类型。
3. 在往HDFS上写数据的时候,数据的存储文件会定时的滚动,如果不指定,那么每隔30s会滚动一次,生成一个文件,那么此时会生成大量的小文件。
2. 配置属性
| 属性 | 解释 |
| type | 必须是hdfs |
| hdfs.path | 数据在HDFS上的存储路径 |
| hdfs.rollInterval | 指定文件的滚动的间隔时间 |
| hdfs.fileType | 指定文件的存储类型:DataSteam(文本),SequenceFile(序列),CompressedStream(压缩) |
3. 案例
1. 编写格式文件,添加如下内容:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = hadoop01
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置HDFS Sink
# 类型必须是hdfs
a1.sinks.k1.type = hdfs
# 指定数据在HDFS上的存储路径
a1.sinks.k1.hdfs.path = hdfs://hadoop01:9000/flumedata
# 指定文件的存储类型
a1.sinks.k1.hdfs.fileType = DataStream
# 指定文件滚动的间隔时间
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
2. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f hdfssink.conf -
Dflume.root.logger=INFO,console
二、Logger Sink
1. 概述
1. Logger Sink是将Flume收集到的数据打印到控制台上。
2. 在打印的时候,为了防止过多的数据将屏幕占满,所以要求body部分的数据不能超过16个字节,超过的部分不打印。
3. Logger Sink在打印的时候,对中文支持不好。
2. 配置属性
| 属性 | 解释 |
| type | 必须是logger |
| maxBytesToLog | 指定body部分打印的字节数 |
三、File Roll Sink
1. 概述
1. File Roll Sink将数据写到本地磁盘上。
2. 同HDFS Sink类似,File Roll Sink在往磁盘上写的时候,也有一个滚动的间隔时间,同样是30s,因此在磁盘上同样会形成大量的小文件。
2. 配置属性
| 属性 | 解释 |
| type | 必须是file_roll |
| sink.directory | 指定数据的存储目录 |
| sink.rollInterval | 指定文件滚动的间隔时间 |
3. 案例
1. 编写格式文件,添加如下内容:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = hadoop01
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置File Roll Sink
# 类型必须是file_roll
a1.sinks.k1.type = file_roll
# 指定数据在磁盘上的存储目录
a1.sinks.k1.sink.directory = /home/flumedata
# 指定文件的滚动间隔时间
a1.sinks.k1.sink.rollInterval = 3600
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
2. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f filerollsink.conf -
Dflume.root.logger=INFO,console
四、Null Sink
1. 概述
1. Null Sink会抛弃所有接收到的数据。
2. 配置属性
| 属性 | 解释 |
| type | 必须是null |
3. 案例
1. 编写格式文件,添加如下内容:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = hadoop01
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置Null Sink
# 类型必须是null
a1.sinks.k1.type = null
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1f
2. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f nullsink.conf -
Dflume.root.logger=INFO,console
五、AVRO Sink
1. 概述
1. AVRO Sink会将数据利用AVRO序列化之后写出到指定的节点的指定端口。
2. AVRO Sink结合AVRO Source实现多级、扇入、扇出流动效果。
2. 配置属性
| 属性 | 解释 |
| type | 必须是avro |
| hostname | 数据要发往的主机的主机名或者IP |
| port | 数据要发往的主机的接收端口 |
3. 多级流动
1. 第一个节点:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置多级流动
# 类型必须是avro
a1.sinks.k1.type = avro
# 指定主机名或者IP
a1.sinks.k1.hostname = hadoop02
# 指定端口
a1.sinks.k1.port = 8090
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
2. 第二个节点:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置多级流动
# 类型必须是avro
a1.sinks.k1.type = avro
# 指定主机名或者IP
a1.sinks.k1.hostname = hadoop03
# 指定端口
a1.sinks.k1.port = 8090
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
3. 第三个节点:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
4. 启动Flume,启动的时候,谁接收数据,就先启动谁:
../bin/flume-ng agent -n a1 -c ../conf -f duoji.conf -
Dflume.root.logger=INFO,console
4. 扇入流动
1. 第一个和第二个节点:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置多级流动
# 类型必须是avro
a1.sinks.k1.type = avro
# 指定主机名或者IP
a1.sinks.k1.hostname = hadoop03
# 指定端口
a1.sinks.k1.port = 8090
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
2. 第三个节点:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
3. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f shanru.conf -
Dflume.root.logger=INFO,console
5. 扇出流动
1. 第一个节点:
a1.sources = s1
a1.channels = c1 c2
a1.sinks = k1 k2
a1.sources.s1.type = netcat
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.channels.c2.type = memory
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop02
a1.sinks.k1.port = 8090
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop03
a1.sinks.k2.port = 8090
a1.sources.s1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
2. 第二个和第三个节点::
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
3. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f shanchu.conf -
Dflume.root.logger=INFO,console
六、Custom Sink
1. 概述
1. 定义一个类实现Sink接口,考虑到需要获取配置属性,所以同样需要实现Configurable接口。
2. 不同于自定义Source,自定Sink需要考虑事务问题。
2. 事务
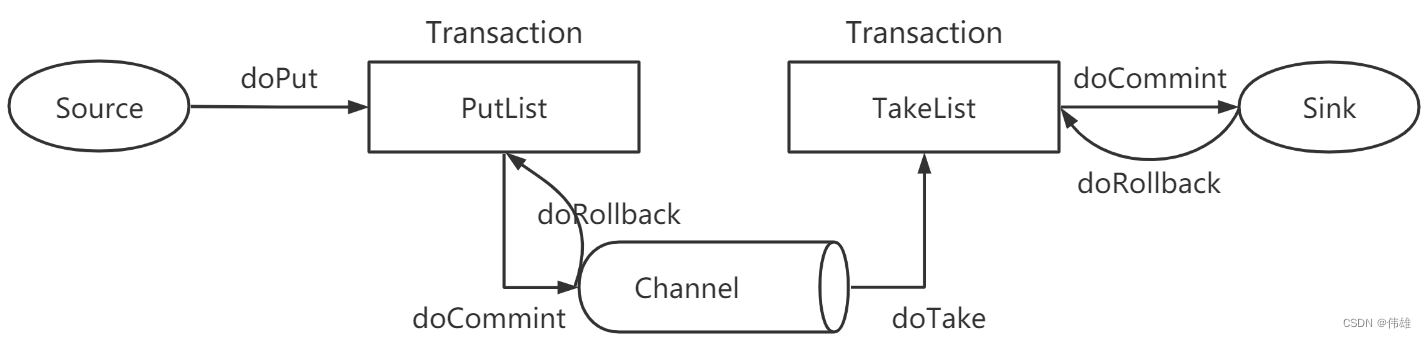
1. Source收集到数据之后,会通过doPut操作将树放到队列PutList(本质上是一个阻塞式队列)中。
2. PutList会试图将数据推送到Channel中。如果PutList成功将数据放到了Channel中,那么执行doCommit操作;反之执行doRollback操作。
3. Channel有了数据之后,会将数据通过doTake操作推送到TakeList中。
4. TakeList会将数据推送给Sink,如果Sink写出成功,那么执行doCommit;反之执行doRollvack。
3. 自定义Sink步骤
1. 构建Maven工程,导入对应的POM依赖。
2. 定义一个类继承AbstractSink,实现Sink接口和Configurable接口,覆盖configure,start,process和stop方法。
3. 完成之后打成jar包放到Flume安装目录的lib目录下。
4. 编写格式文件:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = hadoop01
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置自定义Sink
# 类型必须是类的全路径名
a1.sinks.k1.type = cn.tedu.flume.sink.AuthSink
# 指定文件的存储路径
a1.sinks.k1.path = /home/flumedata
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
5. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f authsink.conf -
Dflume.root.logger=INFO,console
相关文章:
大数据课程D5——hadoop的Sink
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 掌握Sink的HDFS Sink; ⚪ 掌握Sink的Logger Sink; ⚪ 掌握Sink的File Roll Sink; ⚪ 掌握Sink的Null Sink; ⚪ 掌握Si…...
【数据结构】27.移除元素
💐 🌸 🌷 🍀 🌹 🌻 🌺 🍁 🍃 🍂 🌿 🍄🍝 🍛 🍤 📃个人主页 :阿然成长日记 …...

机器学习分布式框架ray运行xgboost实例
Ray是一个开源的分布式计算框架,专门用于构建高性能的机器学习和深度学习应用程序。它的目标是简化分布式计算的复杂性,使得用户能够轻松地将任务并行化并在多台机器上运行,以加速训练和推理的速度。Ray的主要特点包括支持分布式任务执行、Ac…...

C++设计模式笔记
设计模式 如何解决复杂性? 分解 核心思想:分而治之,将大问题分解为多个小问题,将复杂问题分解为多个简单的问题。 抽象 核心思想:从高层次角度讲,人们处理复杂性有一个通用的技术,及抽象。…...
简单聊聊创新与创造力
文章目录 前言一、大脑运行的两种方式1、聚焦模式2、发散模式3、影响想法的因素a、背景知识b、兴趣c、天赋 4、思维固化 二、想法的不可靠1、对想法进行验证2、颠覆性创新,挤牙膏式创新3、为什么模仿这么多 三、更多更多的idea1、个人的方面a、积累不同的背景知识b、…...

使用TensorFlow训练深度学习模型实战(上)
大家好,尽管大多数关于神经网络的文章都强调数学,而TensorFlow文档则强调使用现成数据集进行快速实现,但将这些资源应用于真实世界数据集是很有挑战性的,很难将数学概念和现成数据集与我的具体用例联系起来。本文旨在提供一个实用…...
【Spring】什么是Bean的生命周期及作用域,什么是Spring的执行流程?
博主简介:想进大厂的打工人博主主页:xyk:所属专栏: JavaEE进阶 在前面的播客中讲解了如何从Spring中存取Bean对象,那么本篇我们来讲解Bean对象的生命周期是什么,Bean对象的6种作用域分别是什么,都有哪些区别ÿ…...
立创EDA学习
学习树莓派3B的板子发现有个扩展板比较好,自己最好画一个,反正免费。 学习视频:立创EDA(专业版)电路设计与制作快速入门。 下载专业版,并激活。【分专业版和标准版,专业版也是免费的】 手机…...

清风学习笔记—层次分析法—matlab对判断矩阵的一致性检验
在判断矩阵是否为正互反矩阵这块,我写了两种代码,改进前很麻烦且有错误,改进后简洁多了,改进前的代码还有错误,忽略了对角线的值必须都是1,只考虑了除开对角线的元素相乘为1。 %% 改进前代码 A[3 2 4;1/2 …...

大众安徽内推
大众汽车(安徽)有限公司是大众汽车集团在中国第一家专注于新能源汽车的合资企业,是集团在中国首家拥有全面运营管理权的合资企业,担负着产品研发及数字化研发的重任,将成为集团全球电动出行中心之一。 VW Anhui Offic…...

Meta “地平线世界”移动端应用即将上线,手机快乐元宇宙?
根据海外记者 Janko Roettgers 的报道,Meta 预计很快推出移动版的 VR 元宇宙服务 "地平线世界",这是Meta 长期开发的产品。 根据最新报道,Meta宣布正在研发“地平线世界”的移动版,并表示这一服务已经可以在Quest VR设…...

更省更快更安全的云服务器,一站式集中管理,随时随地远程——站斧云桌面
随着全球化和数字化经济的发展,越来越多的企业开始海外扩张和拓展国际市场。而云服务器作为一种高效、灵活且可靠的IT基础设施方案,已成为出海企业不可或缺的重要工具。这里就为大家介绍云服务器在出海企业中的几个使用场景。 1.全球范围内协同办公 对…...
 的解决方法)
出现 Try run Maven import with -U flag (force update snapshots) 的解决方法
目录 1. 问题所示2. 原理分析3. 解决方法1. 问题所示 在配置Maven依赖信息的时候,出现如下问题: com.alibaba.nacos:nacos‐client:pom:1.1.3 failed to transfer from http://nexus.hepengju.cn:8081/nexus/content/groups/public/ during a previous attempt. This failu…...

python多线程
目录 一.多线程的定义 A.什么是多线程? B.多线程如今遇到的挑战 C.总结 二.python中的多线程 A.python中的多线程底层原理: B.全局解释器锁导致python多线程不能实现真正的并行执行! C.总结应用场景 三.java多线程,以及…...

Spring Framework 提供缓存管理器Caffeine
说明 Spring Framework 提供了一个名为 Caffeine 的缓存管理器。Caffeine 是一个基于 Java 的高性能缓存库,被广泛用于处理大规模缓存数据。 使用 Caffeine 缓存管理器,可以轻松地在 Spring 应用程序中添加缓存功能。它提供了以下主要特性:…...

ZQC的游戏 题解
前言 这题题意描述不是很清楚啊,所以我找了个有权限的人把题面改了改,应该还是比较清楚了。 感觉这道题挺妙的,就来写一篇题解。 思路 首先,根据贪心思想,我们会将 1 1 1 号点半径以内能吃的都吃了,假…...
24考研数据结构-第一章 绪论
数据结构 引用文章第一章:绪论1.0 数据结构在学什么1.1 数据结构的基本概念1.2 数据结构的三要素1.3 算法的基本概念1.4 算法的时间复杂度1.4.1 渐近时间复杂度1.4.2 常对幂指阶1.4.3 时间复杂度的计算1.4.4 最好与最坏时间复杂度 1.5 算法的空间复杂度1.5.1 空间复…...
Gitlab 备份与恢复
备份 1、备份数据(手动备份) gitlab-rake gitlab:backup:create2、备份数据(定时任务备份) [rootlocalhost ]# crontab -l 00 1 * * * /opt/gitlab/bin/gitlab-rake gitlab:backup:create 说明:每天凌晨1点备份数据…...
数据库—用户权限管理(三十三)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 一、概述 二、用户权限类型 三、用户赋权 四、权限删除 五、用户删除 前言 数据库用户权限管理是指对数据库用户的权限进行控制和管理,确保用户只能执…...

C语言【怎么定义变量?】
变量定义的目的是向编译器说明在哪里创建变量的存储,并指明如何创建变量的存储方式。变量定义会明确指定一个数据类型,并包含一个或多个变量的列表。例如: type variable_list; 在这里,"type"必须是一个合法的C数据类…...

Unity Il2CppDumper原理与实战:解析元数据与二进制对齐
1. 这不是“破解工具”,而是Unity开发者该懂的二进制真相课 你刚在Unity Asset Store下载了一个功能惊艳的插件,却在打包iOS后发现部分逻辑失效;或者接手一个没有源码的旧项目,只有一堆 .dll 和 .so 文件,连主入口…...

AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度
AlphaFold 3终极指南:掌握Jackhmmer与HMMER提升蛋白质结构预测精度 【免费下载链接】alphafold3 AlphaFold 3 inference pipeline. 项目地址: https://gitcode.com/gh_mirrors/alp/alphafold3 你是否在蛋白质结构预测项目中遇到MSA生成效率低下的瓶颈&#x…...
)
DeepSeek RAG系统渗透测试全链路复现(含PoC代码与防御加固清单)
更多请点击: https://kaifayun.com 第一章:DeepSeek RAG系统渗透测试全链路复现概览 DeepSeek RAG系统作为面向企业级知识检索增强生成的典型架构,其安全边界不仅涵盖LLM服务层,更延伸至向量数据库、检索代理、提示工程网关及外部…...

CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测
CVPR 2023反无人机数据集实战:用ModelScope上的开源模型快速上手目标检测无人机技术的普及带来了新的安全挑战,从隐私侵犯到关键设施威胁,反无人机技术正成为计算机视觉领域的热点。CVPR 2023反无人机竞赛提供的开源数据集和基线模型…...

Office RibbonX Editor:让Office界面定制变得像搭积木一样简单
Office RibbonX Editor:让Office界面定制变得像搭积木一样简单 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbon…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

全链路压测实战:双十一级别的流量,我是这样扛住的
作为一名在质量保障领域摸爬滚打多年的测试工程师,我深知传统的单接口压测在如今分布式架构下的无力感。当业务流量达到双十一这种脉冲式、高并发的级别时,任何一个非核心链路上的“短板”都可能引发系统性的雪崩。全链路压测不再是选择题,而…...
:执行计划教我做事)
开发转兼职DBA(二):执行计划教我做事
开发转兼职DBA(二):执行计划教我做事 查询慢了不知道为什么,加了索引还是慢,复合索引怎么建,执行计划怎么看——这些不是DBA的专利,是每个写SQL的开发者迟早要面对的事。 文章目录 开发转兼职DB…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

Matlab,plot绘图如何添加边框
matlab生成的图——编辑(E)——坐标区属性(A)——框样式——Box,勾选效果:...