进阶-自定义类型(结构体、位段、枚举、联合)
自定义类型:结构体,枚举,联合
结构体
结构体类型的声明
结构的自引用
结构体变量的定义和初始化
结构体内存对齐
结构体传参
结构体实现位段(位段的填充&可移植性)
枚举
枚举类型的定义
枚举的优点
枚举的使用
联合
联合类型的定义
联合的特点
联合大小的计算
结构体
1. 结构体的声明
1.1 结构的基础知识
结构是一些值的集合,这些值称为成员变量。结构的每个成员可以是不同类型的变量。
1.2 结构的声明
struct tag
{
member - list;
}variable - list;
例如描述一个学生:
struct stu
{
//学生的相关属性
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
};//分号不能丢
这只是一个类型,类似与int char
struct stu
{
//学生的相关属性
char name[20];//名字
int age;//年龄
char sex[5];//性别
char id[20];//学号
}s1, s2;//全局变量
利用这个类型,创建变量s1,s2,创建类型的时候捎带创建变量
两种写法都行
int main()
{
struct stu s3;//内部创建也行,只不过变成了局部变量
return 0;
}
1.3 特殊的声明
在声明结构的时候,可以不完全的声明。
比如 :
//匿名结构体类型
//只能用一次
struct
{
int a;
char b;
float c;
}x;
struct
{
int a;
char b;
float c;
}a[20], * P;
P = &x;
警告:
编译器会把上面的两个声明当成完全不同的两个类型。
所以是非法的。
1.4 结构的自引用
在结构中包含一个类型为该结构本身的成员是否可以呢 ?
前提补充:
数据结构
数据在内存中的存储结构
线形:数组,存储地址连续的 1 2 3 4 5 6
链表:在内存中各个位置,但是可以通过1找到2,通过2找到3...(把1,2,3..称为节点)
树形
二叉树
struct Node//节点
{
int data;//存放一个数值
struct Node next;//存放下一个节点
};
//可行否?
如果可以,那sizeof(struct Node)是多少 ?
是未知的,所以这种写法是错误的
struct Node//节点
{
int data; //存放一个数值(数据域)
struct Node* next;//存放下一个节点的指针(指针域)
};
这样sizeof(struct Node)就是固定的了
结构体内可以包含一个同类型的结构体指针
1.5 结构体变量的定义和初始化
有了结构体类型,那如何定义变量
struct Point
{
int x;
int y;
}p1;//声明类型的同时定义变量p1
struct Point p2;//创建类型后,再重新定义结构体变量p2
struct Point p3 = { x,y }//初始化:定义变量的同时赋初值。;
struct stu//类型声明
{
char name[15];//名字
int age;//年龄
};
struct stu s = { "zhangsan",20 };//初始化
初始化
struct Point
{
int x;
int y;
}p1 = { 2,3 };
struct score
{
int n;
char ch;
};
struct Stu
{
char name[20];
int age;
struct _score s;
};
int main()
{
struct Point p2 = { 3,4 };
struct Stu sl = { "zhangsan",20 ,{100,'q'} };
printf("%s %d %d %c\n", sl.name, sl.age, sl.s.n, sl.s.ch);
return 0;
}
1.6 结构体内存对齐
我们已经掌握了结构体的基本使用了。
现在我们深入讨论一个问题 : 计算结构体的大小。
这也是一个特别热门的考点 : 结构体内存对齐
struct s1
{
char c1;//1
int i;//4
char c2;//1
};
struct s2
{
char c1;//1
char c2;//1
int i;//4
};
int main()
{
printf("%d\n", sizeof(struct s1));//12.
printf("%d\n", sizeof(struct s2));//8
return 0;
}
成员相同,只是顺序发生变化后,大小也发生了变化,那这到底是为什么呢?
如何计算 ?
首先得掌握结构体的对齐规则 :
1.第一个成员在与结构体变量偏移量为0的地址处。
2.其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
对齐数 = 编译器默认的一个对齐数 与 该成员大小 的较小值。
vs中默认的值为8
3.结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
4.如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
struct s1
{
char c1;//1
int i;//4
char c2;//1
};
偏移量
0 c1
1
2
3
4 i 对齐数为8和4的较小值,选4,对齐到4的倍数,四个字节
5 i
6 i
7 i
8 c2 对齐数为1和8的较小值,1个字节
9 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
10
11
12 三个对齐数1,4,1 最大为4,4的整数倍,12,结构体的最终大小
13
14
补充
offsetof,是一个宏,头文件为#include<stddef.h>
可以返回一个成员在这个类型中的偏移量
printf("%d\n", offsetof(struct s1, c1));//0
printf("%d\n",offsetof(struct s1, i));//4
printf("%d\n", offsetof(struct s1, c2));//8
struct s2
{
char c1;//1
char c2;//1
int i;//4
};
偏移量
0 c1
1 c2,编译器默认对齐数为8,自身为1,选最小值1,偏移量为1就行了
2
3
4 i 对齐数为8和4的较小值4,偏移量为4
5 i 四个字节
6 i
7 i
8 结构体总大小为最大对齐数(每个成员变量都有一个对齐数)的整数倍。
9 三个对齐数1,4,1 最大为4,4的整数倍,8就行了,结构体的最终大小为8
10
11
12
13
14
printf("%d\n", offsetof(struct s1, c1));//0
printf("%d\n",offsetof(struct s1, c2));//1
printf("%d\n", offsetof(struct s1, i));//4
gcc等其他一些编译器没有默认对齐数这个概念,
他们的对齐数就是自身的大小
练习:
struct s3
{
double d;
char c;
int i;
};
求s3类型的大小
0 d 偏移量为0,
1 .....
2 double占8个字节
3
4
5
6
7 d
8 c 的对齐数为1和8的较小值,为1,接下来最近的一个1的整数倍为8,c占一个字节
9
10
11
12 i 的对齐数为4和8的较小值,为4,接下来最近的一个4的整数倍为12,
13
14
15 i 占4个字节
16 结构体最终大小为每个成员对齐数最大值的整数倍 1 8 4 ,8的足够内存的整数倍为16
17
18
#include<stddef.h>
int main()
{
struct S3
{
double d;
char c;
int i;
};
printf("%d\n", sizeof(struct S3));//16
printf("%d\n", offsetof(struct S3, d));//0
printf("%d\n", offsetof(struct S3, c));//8
printf("%d\n", offsetof(struct S3, i));//12
return 0;
}
struct S4
{
char c1;
struct S3 s3;
double d;
};
c1在偏移量为0的地址处,c1为char类型,占1个字节,
s3为嵌套结构体,嵌套的结构体对齐到自己的最大对齐数的整数倍处,
即s3的类型为struct S3这个结构体中最大的对齐数,struct S3的对齐数为8 1 4,最大为8
s3要对齐到8的整数倍,即从偏移量8开始
s3的类型为struct S3,本身大小为16,从偏移量8处占16个字节,到偏移量为23处结束
d的对齐数为8,要对齐到最近的8的整数倍处,即24,偏移量为24
d为double类型,从偏移量24往下占8个字节,到偏移量31处,即32字节
结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。(8 1 4 S3中的 1 8 1) 即8的整数倍
所以struct S4的大小为32
那为什么存在内存对齐呢 ?
大部分的参考资料都是如是说的 :
1.平台原因(移植原因) :
不是所有的硬件平台都能访问任意地址上的任意数据的; 某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2.性能原因 :
数据结构(尤其是栈)应该尽可能地在自然边界上对齐,
原因在于,为了访问未对齐的内存,处理器需要作两次内存访问; 而对齐的内存访问仅需要一次访问。
未对齐:
c i(c紧挨着i,c占一个字节,i占四个字节)
对齐:
c i(c和i之间空着三个字节)
32位机器,一次性可以访问32bit即四个字节,
如果未对齐,从c开始访问i,一次访问对i未访问完全,还剩一个字节,需要再访问一次
如果对齐了,可以直接从i的首字节开始访问四个字节,直接把i访问完全了
总体来说 :
结构体的内存对齐是拿空间来换取时间的做法。
“对齐是为了让CPU更高效地访问内存。如果数据未按对齐要求存放,CPU可能需要多次读取或触发错误,导致性能下降甚至崩溃。
同时,不同硬件的对齐要求不同,对齐规则能保证代码在多种平台上正常运行。”
那在设计结构体的时候,我们既要满足对齐,又要节省空间,如何做到 :
让占用空间小的成员尽量集中在一起。
1.7 修改默认对齐数
之前我们见过了 #pragma 这个预处理指令,这里我们再次使用,可以改变我们的默认对齐数。
#pragma pack(4)
struct s
int i;//4 4 4 0~3
//4
double d;//8 4 4 4~11
};
#pragma pack()
int main()
{
printf("%d\n", sizeof(struct s));//12
return 0;
}
如果不想对齐的话就改为1
#pragma pack(1)
struct s
int i;
double d;
};
#pragma pack()
1.8 结构体传参
变量和指针都行
struct S
{
int data[1000];
int num;
};
void print1(struct S ss)
{
int i = 0;
for (i = 0; i < 3; i++)
{
printf("%d", ss.data[i]);
}
printf("%d\n", ss.num);
}
void print2( const struct S* ps)//conts 修饰防止通过指针修改了结构体
{
int i = 0;
for (i = 0; i < 3; i++)
{
printf("%d", p->data[i]);
}
printf("%d\n", p->num);
}
int main()
{
struct S s = { {1,2,3},100 };
print1(s);//传值调用
print2(&s);//传指调用
return 0;
}
首选print2函数。
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。如果传递一个结构体对象的时候,结构体过大,参数压栈的的系统开销比较大,所以会导致性能的下降。
结论:结构体传参尽量传结构体的地址
2. 位段
2.1 什么是位段
位段的声明和结构是类似的,有两个不同:
1. 位段的成员必须是 int、 unsigned int 或者 signed int(char也可以,只要是整型家族的都可以)
2. 位段的成员名后边有一个冒号和一个数字。
比如 :
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
A就是一个位段类型。
位段的位就是比特位,后面的数字代表所占的比特位
比如,
2代表_a只需要2个比特位,只用给它分配两个比特位就行了,不用那么多
5代表_b只需要5个比特位
比如定义一个变量flag,
int flag;
只需要它表示真假,真为1,假为0。
这时候就只需要1个比特位,不需要4个字节32个比特位那么多。
如果一个值的取值范围是0 1 2 3
那只需要两个比特位就够了
因为
00就是0
01就是1
10就是2
11就是3
位段是可以节省空间的
那位段A的大小是多少?
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main()
{
printf("%d\n", sizeof(struct A));//8
return 0;
}
47个比特位
6byte就够了,48bit
但是结果是8byte - 64bit
2.2 位段的内存分配
1.位段的成员可以是int unsigned int signed int 或者是char(属于整形家族)类型
2.位段的空间上是按照需要以4个字节(int)或者1个字节(char)的方式来开辟的。
3.位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
位段的空间上是按照需要以4个字节(int)或者1个字节(char)的方式来开辟的。
A里面都是int上来先开辟4个字节,32bit
到_c的时候,还剩15个bit,但是不够_d用,就再开辟4个字节,32bit,一共8个字节
一般位段的成员是同一类型的
看一个例子:
struct S
{
char a : 3;
char b : 4;
char c : 5;
char d : 4 //冒号后面的数字,不能超过前面类型的大小<8
};
int main()
{
struct S s = { 0 };
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
return 0;
}
首先开辟一个字节,8bit,到c的时候只剩1个bit了,不够,再开辟一个字节
c有5个bit,那么它是把前面剩余的1个bit消耗完再使用新开辟的8个bit呢,还是直接使用新的
如果c用了前面剩余的1个bit,那么还会使用新开辟的4个bit,新开辟的一个byte还是4个字节,够存放d4个bit,这个时候位段一共开辟2个字节
如果c不使用前面剩余的bit直接使用新开辟的,使用完后,新开辟的还剩8 - 5 = 3个bit,那么存放d的时候是不够的,还需要再开辟一个字节,那这个时候一共开辟3个字节
我们计算一下就好了
printf("%d\n", sizeof(struct S));
结果是3byte
说明,不够的时候会跳过前面剩余的bit直接开始使用新开辟的字节。
详细分析一下:
前面提到位段struct S一共开辟3个字节,定义变量s,初始化为0
00000000 00000000 00000000
a占3bit, b占4bit, c占5bit, d占4bit
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
a占3bit,将10存进a里面,10的二进制为1010,假设内部,字节从低位向高位访问,a只占3bit,存放1010存不下
就会类似于截断,把010存放进去,现在内存中就变成了:
00000 010 00000000 00000000
b占4bit,将12存进b里面,12的二进制为1100,四个bit刚好放进b里现在内存中就变成了
0 1100 010 00000000 00000000
c占5bit现在还剩一个bit但是不够放c,跳过直接使用下一个字节,现在把3放进c里,3的二进制是011,可以放进,不够5位,补0,00011,现在内存中就变成了
0 1100 010 000 00011 00000000
d占4bit,现在还剩3个bit不够,浪费掉,直接再开辟一个字节,把4放进d,4的二进制为0100,现在内存中就变成了
0 1100 010 000 00011 0000 0100
整理一下:
01100010 00000011 00000100
十六进制就是
6 2 0 3 0 4
如果内存中看到的是 62 03 04,那么前面的假设存放方式就是对的
调试,查看内存,&s,看s的内存
s占3个字节
果真是 62 03 04
说明在vs2019环境下就是这样存储进去的
该浪费的浪费,字节内从左向右存储进去
区别于大小端,大小端是字节顺寻,这里每次只有一个字节
2.3 位段的跨平台问题
1.int 位段被当成有符号数还是无符号数是不确定的。
2.位段中最大位的数目不能确定。(16位机器最大16,32位机器最大32,当写成27比如int a : 27 ,在16位机器会出问题。
3.位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
4.当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
总结 : 跟结构相比,位段可以达到同样的效果,但是可以很好的节省空间,但是有跨平台的问题存在。
2.4 位段的应用
位段允许你在结构体中以位为单位指定成员的宽度,常用于需要高效利用内存或按位操作的场景
1. 硬件寄存器映射:
如在嵌入式系统中,硬件寄存器通常按位定义功能。使用位段可以直接映射寄存器结构,方便读写特定位:
struct GPIO_Register
{
unsigned int pin0 : 1; // 1位:引脚0状态
unsigned int pin1 : 1; // 1位:引脚1状态
unsigned int pin2 : 1; // 1位:引脚2状态
unsigned int pin3 : 1; // 1位:引脚3状态
unsigned int : 4; // 4位填充,未使用
unsigned int mode : 2; // 2位:工作模式
};
// 使用示例
volatile struct GPIO_Register* gpio = (struct GPIO_Register*)0x40000000;
gpio->pin0 = 1; // 设置引脚0为高电平
gpio->mode = 0b10; // 设置为模式2
2. 标志位集合
当程序需要管理多个布尔标志时,使用位段可以将它们压缩到一个字节或字中:
struct ProcessFlags
{
unsigned int running : 1; // 进程是否运行
unsigned int paused : 1; // 进程是否暂停
unsigned int has_error : 1; // 进程是否有错误
unsigned int priority : 2; // 进程优先级(0-3)
};
// 使用示例
struct ProcessFlags flags = { 1, 0, 0, 2 }; // 运行中,优先级2
if (flags.running) {
printf("进程正在运行\n");
}
3. 节省内存
当需要存储大量小范围数据时,位段可以显著减少内存占用:
// 存储颜色信息(8位:3位红、3位绿、2位蓝)
struct Color
{
unsigned int red : 3; // 范围0-7
unsigned int green : 3; // 范围0-7
unsigned int blue : 2; // 范围0-3
};
// 1000个颜色只需250字节(而非3000字节)
struct Color palette[1000];
注意事项
1. 位段的布局依赖编译器:不同编译器可能以不同方式排列位段(如从左到右或从右到左),建议配合 #pragma pack 或特定编译选项使用。
2. 不可取地址:位段成员不能使用& 取地址,因为它们可能不占用完整字节。
3. 性能权衡:位段访问可能比直接位操作稍慢,因为需要编译器生成额外代码。
3. 枚举
枚举顾名思义就是--列举。
把可能的取值--列举。
比如我们现实生活中 :
一周的星期一到星期日是有限的7天,可以一一列举。
性别有 : 男、女、保密,也可以一一列举
月份有12个月,也可以一一列举
这里就可以使用枚举了。
3.1 枚举类型的定义
enum Day//星期
{
Mon,//0
Tues,//1
wed,//2
Thur,//3
Fri,//4
Sat,//5
Sun//6
};
enum sex//性别
{
MALE,
FEMALE,
SECRET
};
enum color//颜色
{
RED,
GREEN,
BLUE
};
int main()
{
enum Day d = Thur;
printf("%d\n", Mon);//0
printf("%d\n", Tues);//1
printf("%d\n", Wed);//2
return 0;
}
以上定义的 enum Day,enum sex,enum co1or 都是枚举类型。
{ }中的内容是枚举类型的可能取值,也叫 枚举常量。
这些可能取值都是有值的,默认从0开始,一次递增1,当然在定义的时候也可以赋初值。
如:
enum Day//星期
{
Mon,//0
Tues,//1
wed,//2
Thur,//3
Fri,//4
Sat,//5
Sun//6
};
int main()
{
enum Day d = Thur;
printf("%d\n", Mon);//0
printf("%d\n", Tues);//1
printf("%d\n", Wed);//2
return 0;
}
enum Day//星期
{
Mon = 1,
Tues,
wed,
Thur,
Fri,
Sat,
Sun
};
int main()
{
printf("%d\n", Mon);//1
printf("%d\n", Tues);//2
printf("%d\n", Wed);//3
return 0;
}
enum Color//颜色
{
//枚举常量,不能修改,赋值只是初始化
RED = 1,
GREEN = 2,
BLUE = 4
};
3.2 枚举的优点
为什么使用枚举 ?
我们可以使用 #define 定义常量,为什么非要使用枚举 ?
枚举的优点 :
1.增加代码的可读性和可维护性
2.和#define定义的标识符比较枚举有类型检查,更加严谨。
3.防止了命名污染(封装)
4. 便于调试
5.使用方便,一次可以定义多个常量
3.3 枚举的使用
3.3 枚举的使用
enum Color//颜色
{
RED = 1,
GREEN = 2,
BLUE = 4
};
enum color cIr = GREEN;//只能拿枚举常量给枚举变量赋值,才不会出现类型的差异。
clr = 5;//ok??
枚举在 C 语言中 本质是整数类型,枚举变量的底层存储是 int(默认)。例如:
printf("%d\n", clr); // 输出:2(GREEN的值)
clr = 100; // 合法,但无对应枚举常量
printf("%d\n", clr); // 输出:100
4.联合(共用体)(共享单车,你用的时候我不用,不会同时用)
4.1 联合类型的定义
联合也是一种特殊的自定义类型
这种类型定义的变量也包含一系列的成员,特征是这些成员公用同一块空间(所以联合也叫共用体)。比如:
union Un//类似于结构体
{
int a;//4
char c;//1
};
struct St
{
int a;
char c;
};
int main()
{
union Un u;
printf("%d\n", sizeof(u));//4
printf("%p\n", &u);//004FF8A8
printf("%p\n", &(u.a));//004FF8A8
printf("%p\n", &u(u.c));//004FF8A8
eturn 0;
}
4.2 联合的特点
联合的成员是共用同一块内存空间的,这样一个联合变量的大小,至少是最大成员的大小(因为联合至少得有能力保存最大的那个成员)
union Un//类似于结构体
{
int a;//4
char c;//1
};
u.a = 0x11223344;//44 33 22 11(小端存储,倒着的)
u.c = 0x00;
a变成了 // 00 33 22 11
改c也改变了a
题目:
判断当前计算机的大小端存储
int a = 1;
小端:
低 01 00 00 00 高
大端:
低 00 00 00 01 低
只要能拿出a四个字节中的第一个字节就能判断
如果是1就是小端,0就是大端
int main()
{
int a = 1;
char* p = (char*)&a;
if (*p == 1)
printf("小端\n");
else
printf("大端\n");
return 0;
}
现在可以用联合
int check_sys()
{
union un
{
char c;
int i;
}u;
u.i = 1;
return u.c;
}
int main()
{
int ret = check_sys();
if (ret == 1)
{
printf("小端");
}
else
{
printf("大端");
}
return 0;
}
u:
01 00 00 00
int i:
01 00 00 00
char c:
01 00 00 00
c一定和i共用第一个字节
4.3 联合大小的计算
联合的大小至少是最大成员的大小。
当最大成员大小不是最大对齐数的整数倍的时候,就要对齐到最大对齐数的整数倍。
union Un {
char arr[5];//5,对齐数是char类型的是1相当于5个char
int i;//4
}
int main()
{
printf("%d\n", sizeof(union Un));//8
return 0;
}
答案是8,需要对其至最大成员对齐数的整数被,最大对齐数是4,4不够,只能是8
char char char char char null null null
int int int int
int 和arr共用前4个字节,后面3个字节浪费掉
结构体、位段、枚举、联合结束!
相关文章:
)
进阶-自定义类型(结构体、位段、枚举、联合)
自定义类型:结构体,枚举,联合 结构体 结构体类型的声明 结构的自引用 结构体变量的定义和初始化 结构体内存对齐 结构体传参 结构体实现位段(位段的填充&可移植性) 枚举 枚举类型的定义 枚举的优点 枚举的使用 联合 联合类型的定义 联…...

5G 网络全场景注册方式深度解析:从信令交互到报文分析
摘要 本文全面梳理 5G 网络包含的初始注册、移动性注册更新、紧急注册、周期性注册更新、服务请求触发注册、切换触发注册、基于策略的注册更新等多种注册方式。详细阐述每种注册方式的触发条件、信令流程、关键报文结构,结合对比分析与实际案例,助力读者深入理解 5G 网络接…...
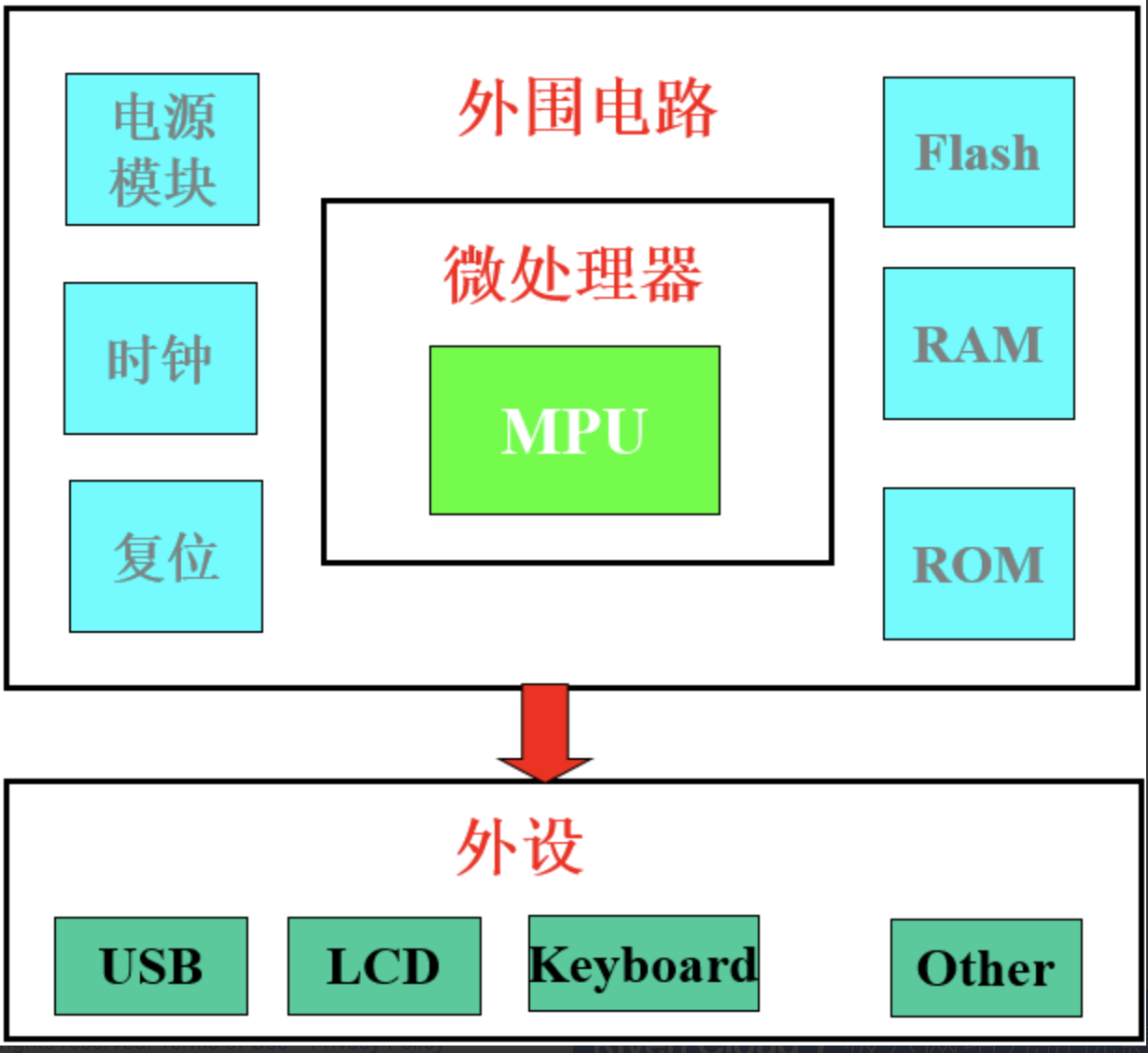
ARM笔记-嵌入式系统基础
第一章 嵌入式系统基础 1.1嵌入式系统简介 1.1.1嵌入式系统定义 嵌入式系统定义: 嵌入式系统是以应用为中心,以计算机技术为基础,软硬件可剪裁,对功能、可靠性、成本、体积、功耗等有严格要求的专用计算机系统 ------Any devic…...

一文讲透golang channel 的特点、原理及使用场景
在 Go 语言中,通道(Channel) 是实现并发编程的核心机制之一,基于 CSP(Communicating Sequential Processes) 模型设计。它不仅用于协程(Goroutine)之间的数据传递,还通过…...
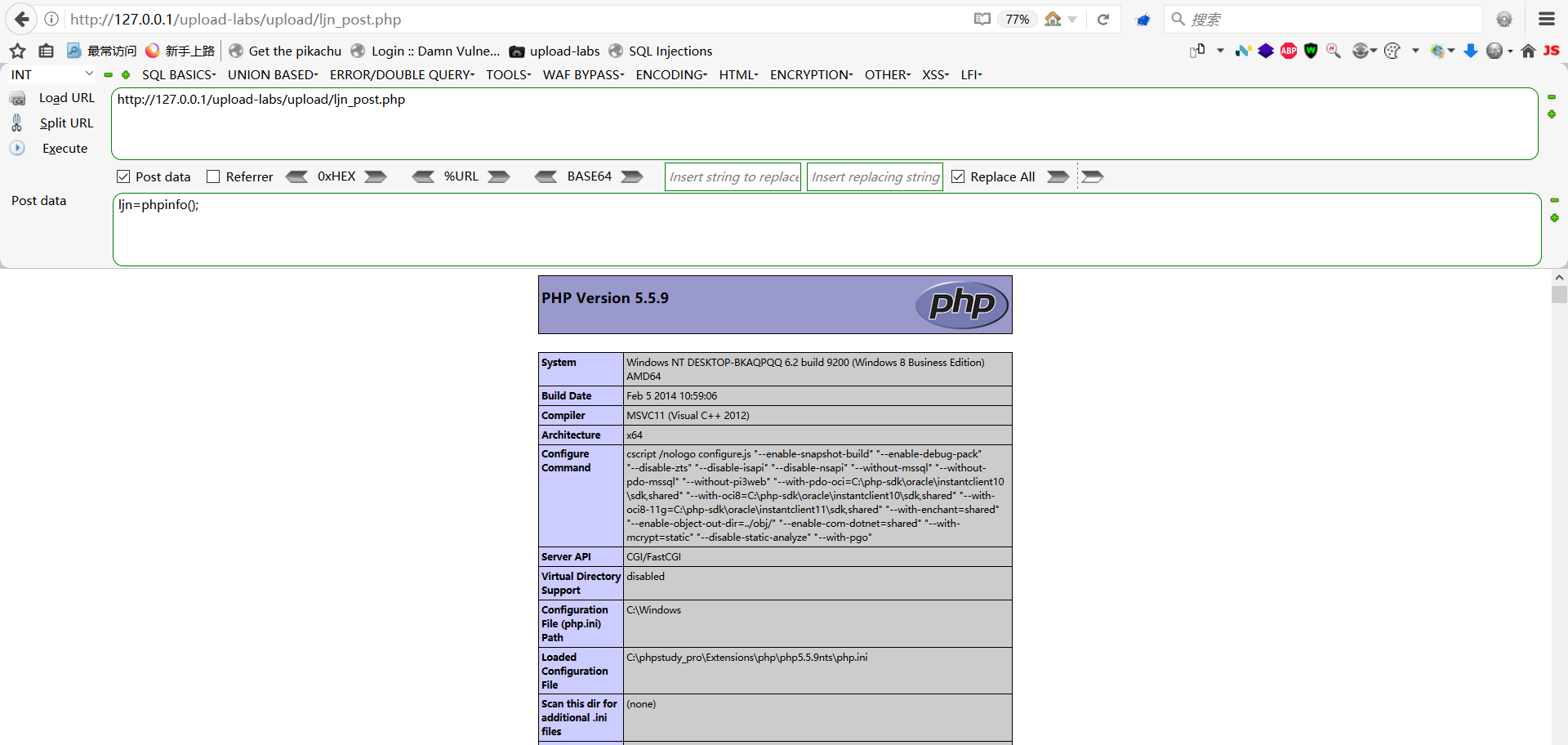
upload-labs通关笔记-第19关文件上传之条件竞争
系列目录 upload-labs通关笔记-第1关 文件上传之前端绕过(3种渗透方法) upload-labs通关笔记-第2关 文件上传之MIME绕过-CSDN博客 upload-labs通关笔记-第3关 文件上传之黑名单绕过-CSDN博客 upload-labs通关笔记-第4关 文件上传之.htacess绕过-CSDN…...
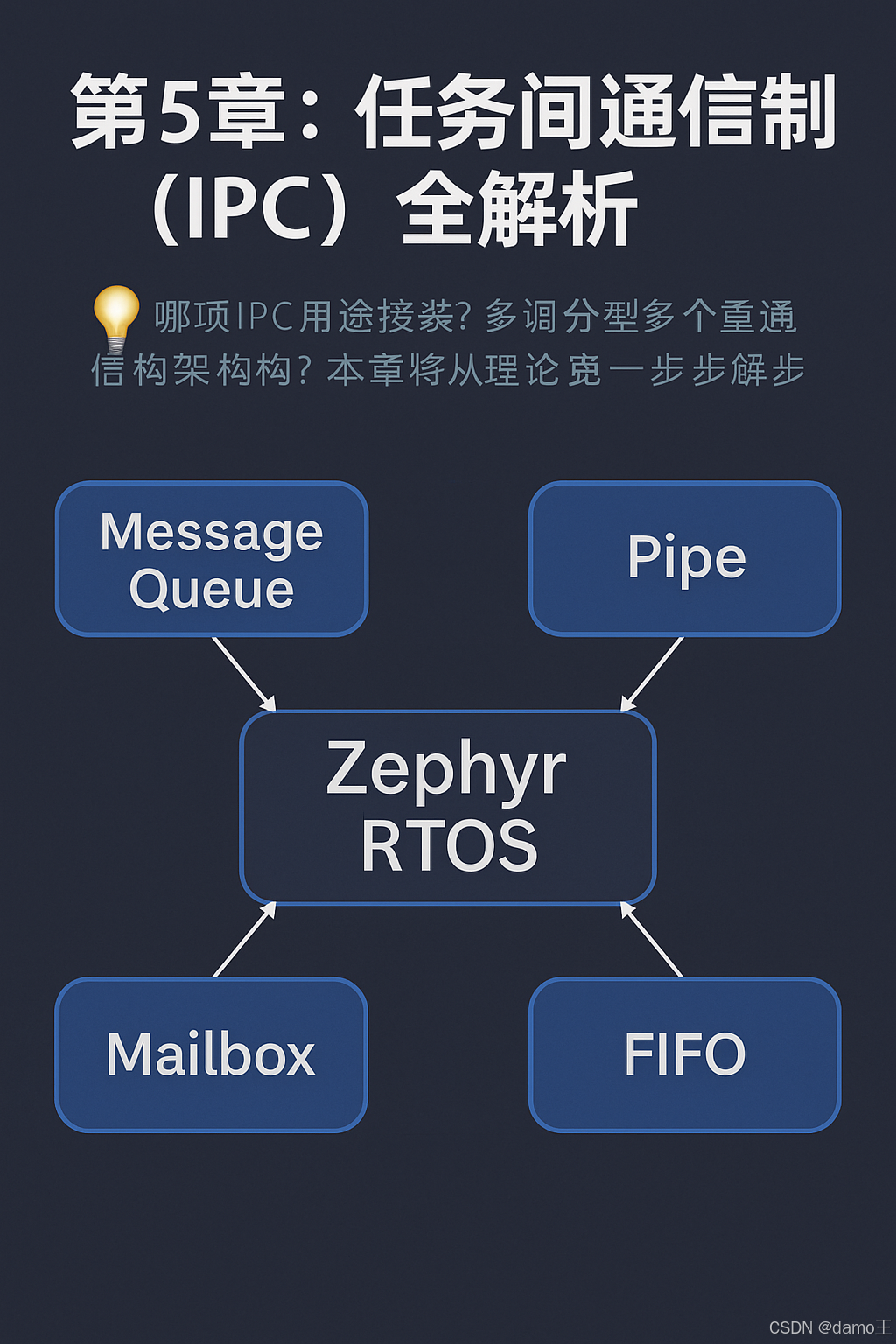
第5章:任务间通信机制(IPC)全解析
💬 在多线程开发中,线程之间如何协作?如何让一个线程产生数据,另一个线程消费数据?本章聚焦 Zephyr 提供的多种任务间通信机制(IPC)及实战使用技巧。 📚 本章导读 你将学到: Zephyr 提供的常用 IPC 接口:FIFO、消息队列、邮箱、信号量 每种机制适用场景和用法对比…...
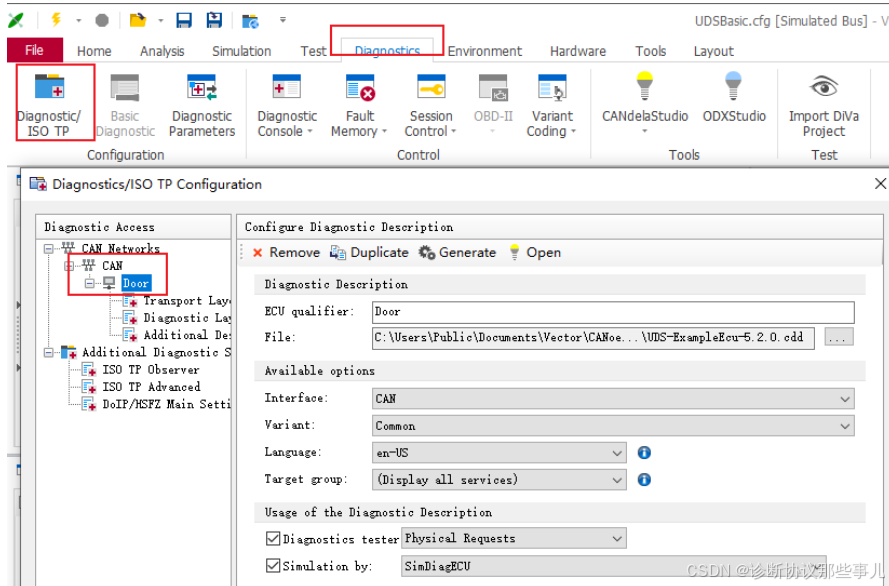
CAPL自动化-诊断Demo工程
文章目录 前言一、诊断控制面板二、诊断定义三、发送诊断通过类.方法的方式req.SetParameterdiagSetParameter四、SendRequestAndWaitForResponse前言 本文将介绍CANoe的诊断自动化测试,工程可以从CANoe的 Sample Configruration 界面打开,也可以参考下面的路径中打开(以实…...
SVN被锁定解决svn is already locked
今天遇到一个问题,svn 在提交代码的时候出现了svn is already locked,解决方案...
【深度学习】1. 感知器,MLP, 梯度下降,激活函数,反向传播,链式法则
一、感知机 对于分类问题,我们设定一个映射,将x通过函数f(x)映射到y 1. 感知机的基本结构 感知机(Perceptron)是最早期的神经网络模型,由 Rosenblatt 在 1958 年提出,是现代神经网络和深度学习模型的雏形…...
云原生安全:网络协议TCP详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 (注:文末附可视化流程图与专有名词说明表) 1. 基础概念 TCP(Transmission Control Protocol)是…...
使用CentOS部署本地DeekSeek
一、查看服务器的操作系统版本 cat /etc/centos-release二、下载并安装ollama 1、ollama下载地址: Releases ollama/ollama GitHubGet up and running with Llama 3.3, DeepSeek-R1, Phi-4, Gemma 3, Mistral Small 3.1 and other large language models. - Re…...

Spring Boot与Eventuate Tram整合:构建可靠的事件驱动型分布式事务
精心整理了最新的面试资料和简历模板,有需要的可以自行获取 点击前往百度网盘获取 点击前往夸克网盘获取 一、引言 在现代微服务架构中,分布式事务管理一直是复杂系统中的核心挑战之一。传统的两阶段提交(2PC)方案存在性能瓶颈&…...

Python:从脚本语言到工业级应用的传奇进化
一、Python的诞生:一场喜剧与编程的奇妙相遇 1989年的冬天,荷兰程序员Guido van Rossum在阿姆斯特丹的CWI研究所里,用一段独特的代码开启了编程语言的新纪元。这个被命名为"Python"的项目,灵感并非源自冷血的蟒蛇,而是源于Guido对英国喜剧团体Monty Python的痴…...

【排序算法】典型排序算法 Java实现
以下是典型的排序算法分类及对应的 Java 实现,包含时间复杂度、稳定性说明和核心代码示例: 一、比较类排序(通过元素比较) 1. 交换排序 ① 冒泡排序 时间复杂度:O(n)(优化后最优O(n)) 稳定性&…...

node.js如何实现双 Token + Cookie 存储 + 无感刷新机制
node.js如何实现双 Token Cookie 存储 无感刷新机制 为什么要实施双token机制? 优点描述安全性Access Token 短期有效,降低泄露风险;Refresh Token 权限受限,仅用于获取新 Token用户体验用户无需频繁重新登录,Toke…...

[DS]使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码
使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码 摘要:由于 sample_data.csv 是一个占位符文件,用于代表任意数据集,我将使用 Python 库中自带的数据集来实现上述 50 个数据分析和数据可视化程序的示例代码…...

探索智能仓颉
探索智能仓颉:Cangjie Magic体验有感 一、引言 在人工智能和智能体开发领域,新的技术和框架不断涌现,推动着行业的快速发展。2025年3月,仓颉社区开源了Cangjie Magic,这是一个基于仓颉编程语言原生构建的LLM Agent开…...

Ubuntu 上开启 SSH 服务、禁用密码登录并仅允许密钥认证
1. 安装 OpenSSH 服务 如果尚未安装 SSH 服务,运行以下命令: sudo apt update sudo apt install openssh-server2. 启动 SSH 服务并设置开机自启 sudo systemctl start ssh sudo systemctl enable ssh3. 生成 SSH 密钥对(本地机器…...
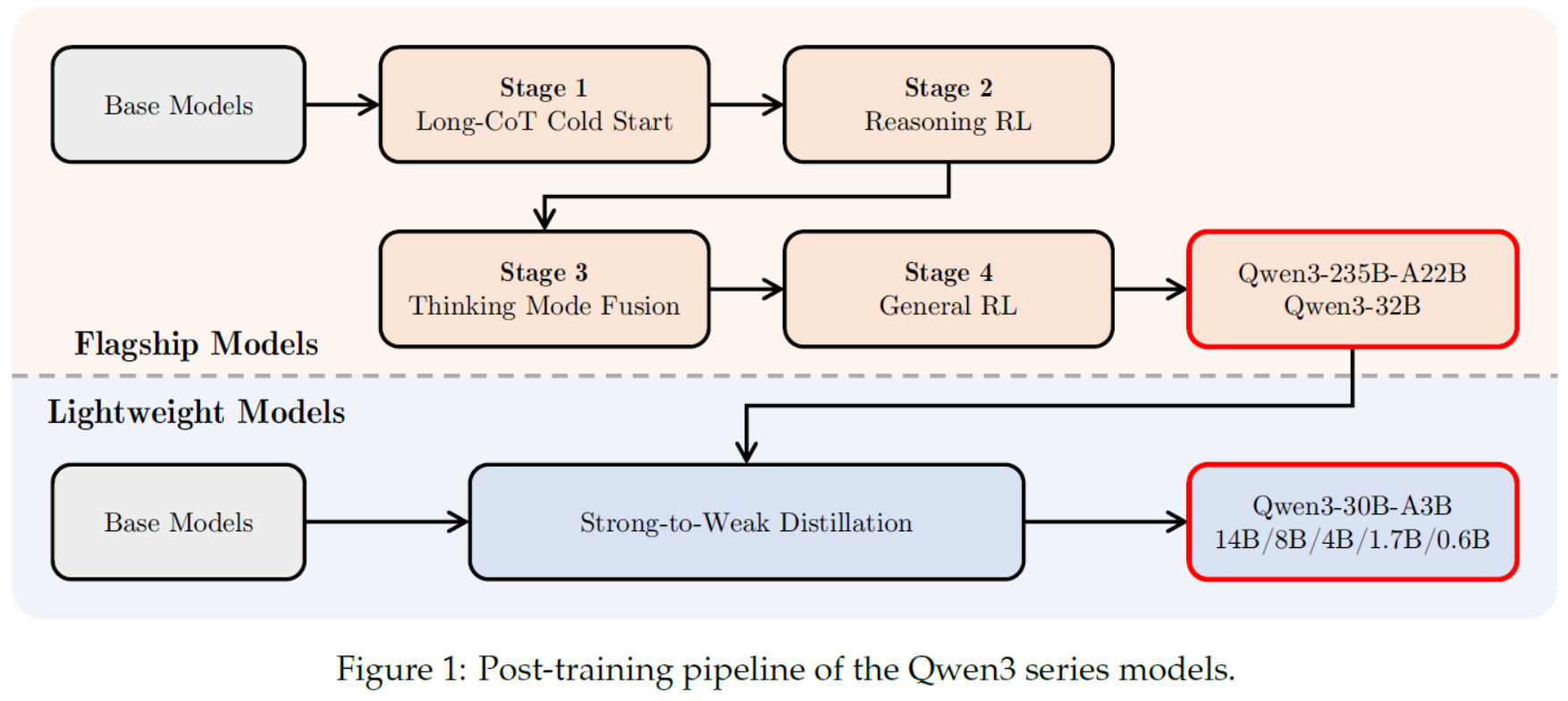
LLMs之Qwen:《Qwen3 Technical Report》翻译与解读
LLMs之Qwen:《Qwen3 Technical Report》翻译与解读 导读:Qwen3是Qwen系列最新的大型语言模型,它通过集成思考和非思考模式、引入思考调度机制、扩展多语言支持以及采用强到弱的知识等创新技术,在性能、效率和多语言能力方面都取得…...

springboot3 configuration
1 多数据库配置 github: https://github.com/baomidou/dynamic-datasource 使用DS()注解来切换数据库 详情介绍:https://www.kancloud.cn/tracy5546/dynamic-datasource/2264611 注意:DS 可以注解在方法上或类上,同时存在就近原则 方法上注…...
从工程实践角度分析H.264与H.265的技术差异
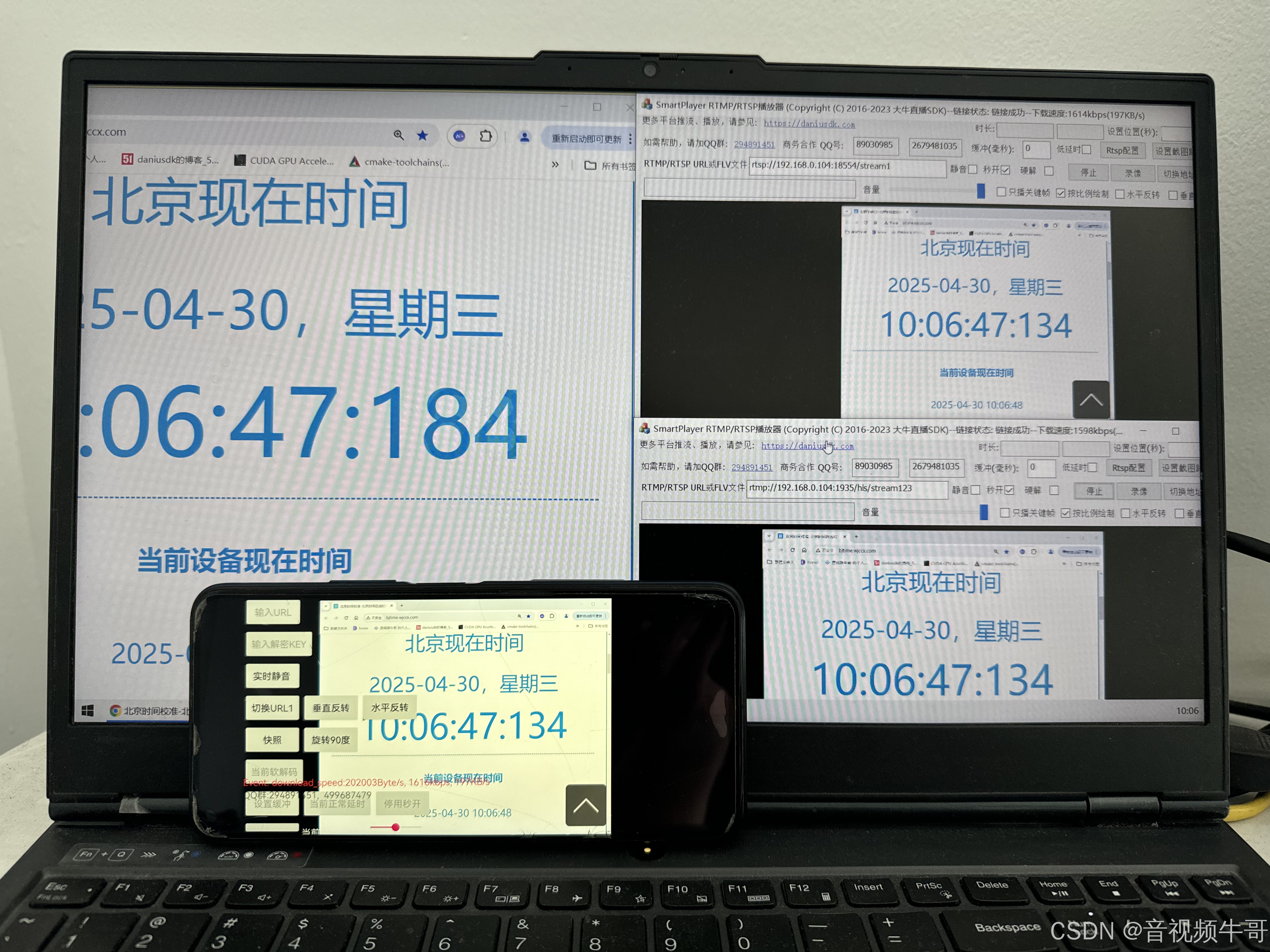
作为音视频从业者,我们时刻关注着视频编解码技术的最新发展。RTMP推流、轻量级RTSP服务、RTMP播放、RTSP播放等模块是大牛直播SDK的核心功能,在这些模块的实现过程中,H.264和H.265两种视频编码格式的应用实践差异是我们技术团队不断深入思考的…...
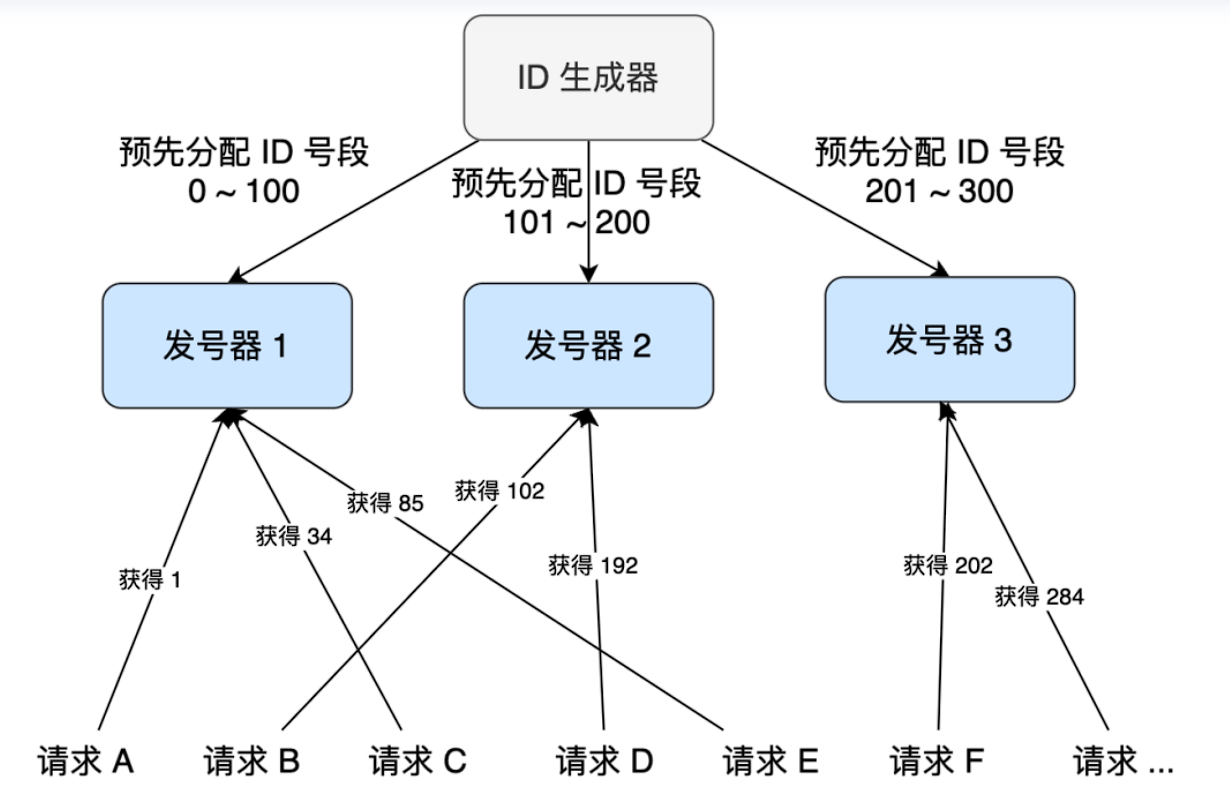
如何设计一个高性能的短链设计
1.什么是短链 短链接(Short URL) 是通过算法将长 URL 压缩成简短字符串的技术方案。例如将 https://flowus.cn/veal/share/3306b991-e1e3-4c92-9105-95abf086ae4e 缩短为 https://sourl.cn/aY95qu,用户点击短链时会自动重定向到原始长链接。其…...
提升工作效率的可视化笔记应用程序
StickyNotes桌面便签软件介绍 StickyNotes是一款极为简洁的桌面便签应用程序,让您能够快速记录想法、待办事项或其他重要信息。这款工具操作极其直观,只需输入文字内容,选择合适的字体大小和颜色,然后点击添加按钮即可创建个性化…...
11|省下钱买显卡,如何利用开源模型节约成本?
不知道课程上到这里,你账户里免费的5美元的额度还剩下多少了?如果你尝试着完成我给的几个数据集里的思考题,相信这个额度应该是不太够用的。而ChatCompletion的接口,又需要传入大量的上下文信息,实际消耗的Token数量其…...

GDB调试工具详解
GDB调试工具详解 一、基本概念 调试信息 编译时需添加 -g 选项(如 gcc -g -o program program.c),生成包含变量名、函数名、行号等调试信息的可执行文件。断点(Breakpoint) 程序执行到指定位置(函数、行号…...

机器学习圣经PRML作者Bishop20年后新作中文版出版!
机器学习圣经PRML作者Bishop20年后新书《深度学习:基础与概念》出版。作者克里斯托弗M. 毕晓普(Christopher M. Bishop)微软公司技术研究员、微软研究 院 科学智 能 中 心(Microsoft Research AI4Science)负责人。剑桥…...

Armadillo C++ 线性代数库介绍与使用
文章目录 Armadillo C 线性代数库介绍与使用主要特点安装Linux (Ubuntu/Debian)macOS (使用 Homebrew)Windows (使用 vcpkg) 基本使用包含头文件矩阵创建与初始化基本运算矩阵分解统计运算保存和加载数据 性能优化建议示例程序与 MATLAB 语法对比 使用Armadillo函数库的稀疏矩阵…...
吴恩达机器学习笔记:逻辑回归3
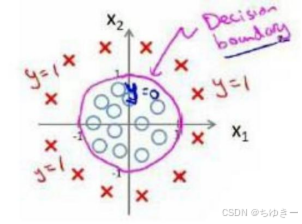
3.判定边界 现在说下决策边界(decision boundary)的概念。这个概念能更好地帮助我们理解逻辑回归的假设函数在计算什么。 在逻辑回归中,我们预测: 当ℎθ (x) > 0.5时,预测 y 1。 当ℎθ (x) < 0.5时,预测 y 0 。 根据…...

大模型知识
############################################################## 一、vllm大模型测试参数和原理 tempreature top_p top_k ############################################################## tempreature top_p top_k 作用:总体是控制模型的发散程度、多样…...

C/C++ 结构体:. 与 -> 的区别与用法及其STM32中的使用
目录 引言 一、深入理解 C/C 结构体:. 与 -> 的区别与用法 1. .(点运算符)详解2. ->(箭头运算符)详解3. . 与 -> 的等价与转换4. 常见错误与调试技巧5. C 特性与运算符重载6. 实战案例:链表与智能…...