Python Web开发技巧VII
目录
装饰器inject_serializer
装饰器@atomic
rebase
git 清理add的数据
查看git的当前工作目录
makemigrations文件名称
@action(detail=True, methods=["GET"])
如何只取序列化器的一个字段进行返回
Response和JsonResponse有什么区别
序列化器填表和单字段如何写
序列化器里包含多对象数据-序列化器嵌套序列化器
from django.db.models import Q的Q对象有什么用,是什么
装饰器inject_serializer
用于动态地将一个序列化器(serializer)注入到Django REST framework(DRF)视图中。
举个例子:
from blue_krill.web.drf_utils import inject_serializer@inject_serializer(body_in=serializers.SLZ1, out=serializers.SLZ2, tags=["项目A"], operation_summary="获取B")def xxx(self, request, args):pass以上,
body_in: 指定请求体的序列化器,这里使用的是serializers.SLZ1。out: 指定响应体的序列化器,这里使用的是serializers.SLZ2。tags: 对 API 分类,方便在生成的 API 文档中查找(比如swagger)。这里标签:项目A。operation_summary: 提供 API 的简短描述,这里描述:获取B。
通过该装饰器,可以让 API 接口更具可读性和规范性,同时也能方便生成 API 文档。
在swagger中的显示就是:

装饰器@atomic
在 Django 中用于确保一个函数或方法在数据库中执行的操作具有原子性。
from django.db.transaction import atomic # transaction 即事务的意思@atomic
def create_user_and_profile(username, email, age):user = User.objects.create(username=username, email=email)profile = UserProfile.objects.create(user=user, age=age)相当于在视图函数中开了个事务,主要目的是维护DB的一致性和完整性。
rebase
大家可能都是常用merge去合并,这样能保留具体的commit记录,但对不复杂或说不大型的项目,rebase其实更简洁干净些。
git checkout v1
git rebase masterv1合并到master,往往还要解决冲突,就处理后git add <File>然后git rebase
git 清理add的数据
从暂存区中移除单个文件
git restore --staged <file-path>从暂存区中移除多个文件
git restore --staged <file-path-1> <file-path-2> ...从暂存区中移除所有文件(原来冒红冒黄的文件又恢复冒红冒黄):
git restore --staged .查看git的当前工作目录
场景:比如git add需要直接加文件的方式
git rev-parse --show-toplevelmakemigrations文件名称
为让迁移文件更加清晰目的,迁移文件往往是要命名规范的,指定生成文件名称:
python manage.py makemigrations --name xxxx
python manage.py makemigrations -n xxxx如果意外直接创建了,那么修改文件名即可,但前缀的0001这种数字不要去修改,关联到这个文件名的name也要修改(比如一般是下一个迁移文件用到),即可。
但注意,如果已经migrate的,那么需要在django_migration修改对应表名,如果为migrate那就不需要。
@action(detail=True, methods=["GET"])
detail标识是否针对单个对象,
@action(detail=True, methods=["GET"]) =》 /users/{id}/get_username/
@action(detail=False, methods=["GET"]) =》 /users/get_username/
如何只取序列化器的一个字段进行返回
from rest_framework import serializers
from myapp.models import MyModelclass MyModelSerializer(serializers.ModelSerializer):class Meta:model = MyModelfields = ['field_name', 'another_field']# 假设你已经有一个 MyModel 实例
my_model_instance = MyModel.objects.get(pk=1)# 使用序列化器序列化实例
serializer = MyModelSerializer(my_model_instance)# 获取序列化后的数据
serialized_data = serializer.data# 仅提取名为 'field_name' 的字段
field_name_data = serialized_data['field_name']# 返回或使用 'field_name' 字段的值
return field_name_dataResponse和JsonResponse有什么区别
Response 和 JsonResponse 都是用于构建和返回 HTTP 响应的 Django 类,但它们之间存在一些差异。
-
来源:
Response类来自 Django REST framework(DRF),通常在 DRF 视图和 APIView 中使用。JsonResponse类是 Django 内置的,用于构建 JSON 响应。 -
内容类型:
Response类可以处理多种内容类型(如 JSON、XML 等),默认情况下,它会根据客户端请求的 "Accept" 头选择合适的内容类型。JsonResponse类专门用于构建 JSON 响应,其 "Content-Type" 头始终设置为 "application/json"。 -
序列化:
Response类可以与 DRF 序列化器一起使用,自动序列化和反序列化数据。JsonResponse类仅处理已序列化为 JSON 的数据,您需要确保传递给JsonResponse的数据是 JSON 可序列化的(例如 Python 字典、列表等)。
如果正使用 Django REST framework 构建 API,建议使用 Response 类。如果您正在使用 Django 的基本视图或类视图,并需要返回 JSON 数据,可以使用 JsonResponse 类
序列化器填表和单字段如何写
class HahaSLZ(serializers.Serializer):haha_id = serializers.IntegerField(required=False)class Meta:model = Userfields = [field.name for field in User._meta.get_fields()] + ['haha_id'] # 注,直接__all__并不能涵盖haha_id序列化器里包含多对象数据-序列化器嵌套序列化器
results该字段的类型是 AASLZ,并设置了 many=True 参数,表示这是一个列表,其中包含多个 AASLZ实例。
class AASLZ(serializers.Serializer):user = serializers.CharField(help_text="用户", required=True)class BBSLZ(serializers.Serializer):results = AASLZ(help_text="用户列表", many=True)from django.db.models import Q的Q对象有什么用,是什么
Django 的 Q 对象是一个用于构建更复杂查询的工具。它允许您在查询中使用 OR 语句、NOT 语句以及更高级的查询结构。Q 对象可以与 filter()、exclude() 和 get() 等查询方法一起使用。
相关文章:
Python Web开发技巧VII
目录 装饰器inject_serializer 装饰器atomic rebase git 清理add的数据 查看git的当前工作目录 makemigrations文件名称 action(detailTrue, methods["GET"]) 如何只取序列化器的一个字段进行返回 Response和JsonResponse有什么区别 序列化器填表和单字段如…...

LaTex4【下载模板、引入文献】
下载latex模板:(模板官网一般都有,去找) 我这随便找了一个: 下载得到一个压缩包,然后用overleaf打开👇: (然后改里面的内容就好啦) 另外,有很多在线的数学公式编辑器&am…...
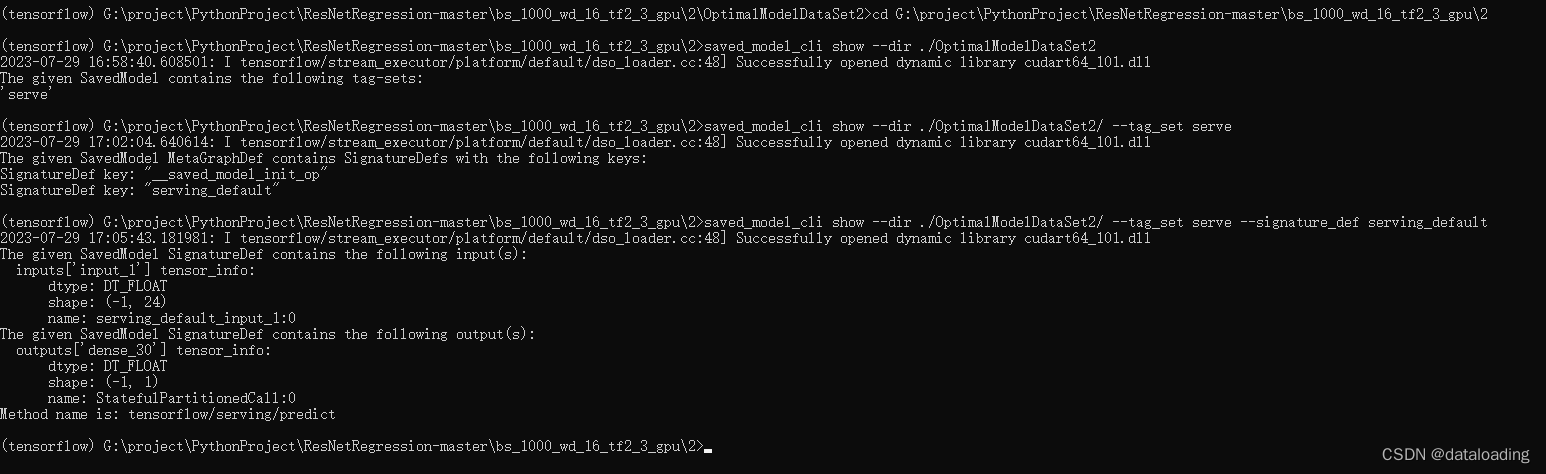
【VSCode部署模型】导出TensorFlow2.X训练好的模型信息
参考tensorflow2.0 C加载python训练保存的pb模型 经过模型训练及保存,我们得到“OptimalModelDataSet2”文件夹,模型的保存方法(.h5或.pb文件),参考【Visual Studio Code】c/c部署tensorflow训练的模型 其中“OptimalModelDataSet2”文件夹保…...
windows环境下,安装elasticsearch
目录 前言准备安装 jdk 安装nodejsElasticSearch下载ElasticSearch-head 下载 安装ElasticSearch安装ElasticSearch-head插件设置用户名密码访问ElasticSearch 默认用户名和密码参考 前言 win10elasticsearch 8.9.0 准备 安装 jdk ElasticSearch 是基于lucence开发的&#…...
)
Elasticsearch入门笔记(一)
环境搭建 Elasticsearch是搜索引擎,是常见的搜索工具之一。 Kibana 是一个开源的分析和可视化平台,旨在与 Elasticsearch 合作。Kibana 提供搜索、查看和与存储在 Elasticsearch 索引中的数据进行交互的功能。开发者或运维人员可以轻松地执行高级数据分析…...
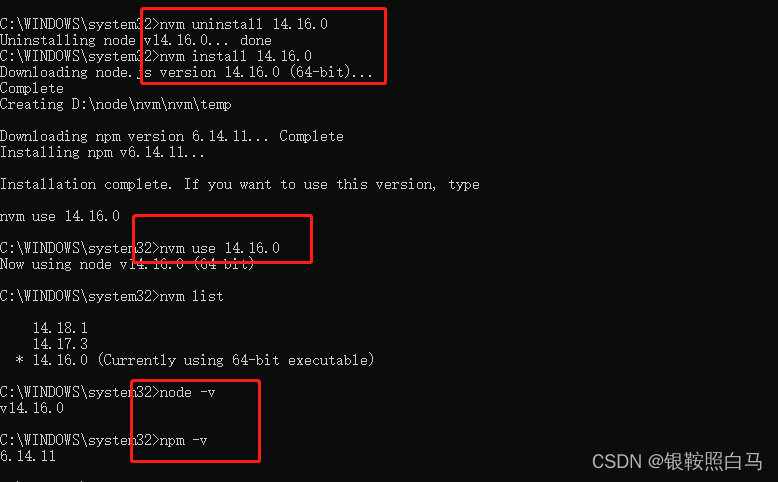
记一次安装nvm切换node.js版本实例详解
最后效果如下: 背景:由于我以前安装过node.js,后续想安装nvm将node.js管理起来。 问题:nvm-use命令行运行成功,但是nvm-list显示并没有成功。 原因:因为安装过node.js,所以原先的node.js不收n…...

生态共建丨YashanDB与构力科技完成兼容互认证
近日,深圳计算科学研究院崖山数据库系统YashanDB V22.2与北京构力科技有限公司BIMBase云平台完成兼容性互认证。经严格测试,双方产品完全兼容、运行稳定。 崖山数据库系统YashanDB是深算院自主研发设计的新型数据库系统,融入原创理论…...

React从入门到实战-react脚手架,消息订阅与发布
创建项目并启动 全局安装 npm install -g create-react-app切换到想创建项目的目录,使用命令:create-react-app 项目名称 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存中…(iQ6hEUgAABpQAAAD1CAYAAABeIRZoAAAAAXNSR0IArs4c6QAAIABJREFUe…...
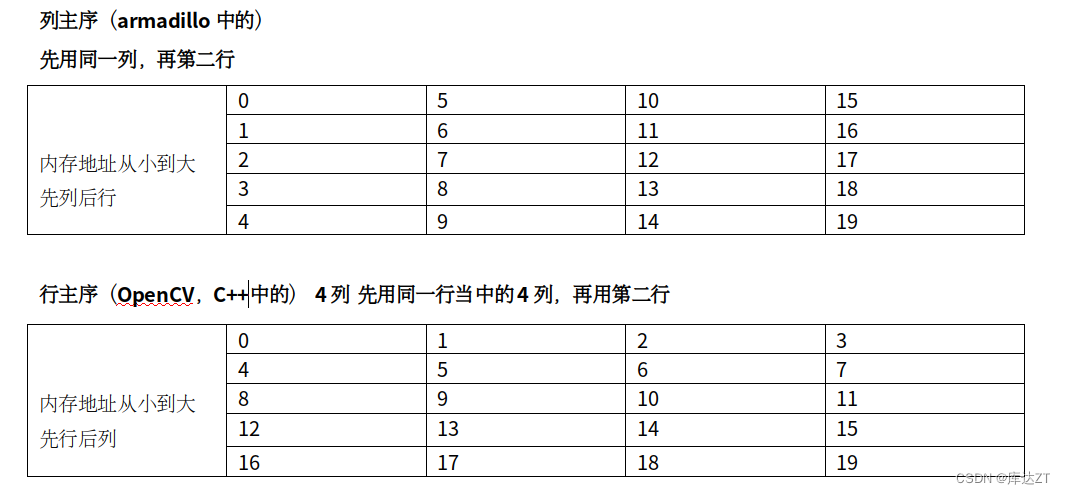
从零构建深度学习推理框架-1 简介和Tensor
源代码作者:https://github.com/zjhellofss 本文仅作为个人学习心得领悟 ,将原作品提炼,更加适合新手 什么是推理框架? 深度学习推理框架用于对已训练完成的神经网络进行预测,也就是说,能够将深度训练框…...

使用WGCLOUD监测安卓(Android)设备的运行状态
WGCLOUD是一款开源运维监控软件,除了能监控各种服务器、主机、进程应用、端口、接口、docker容器、日志、数据等资源 WGCLOUD还可以监测安卓设备,比如安卓手机、安卓设备等 我们只要下载对应的安卓客户端,部署运行即可,如下是下…...
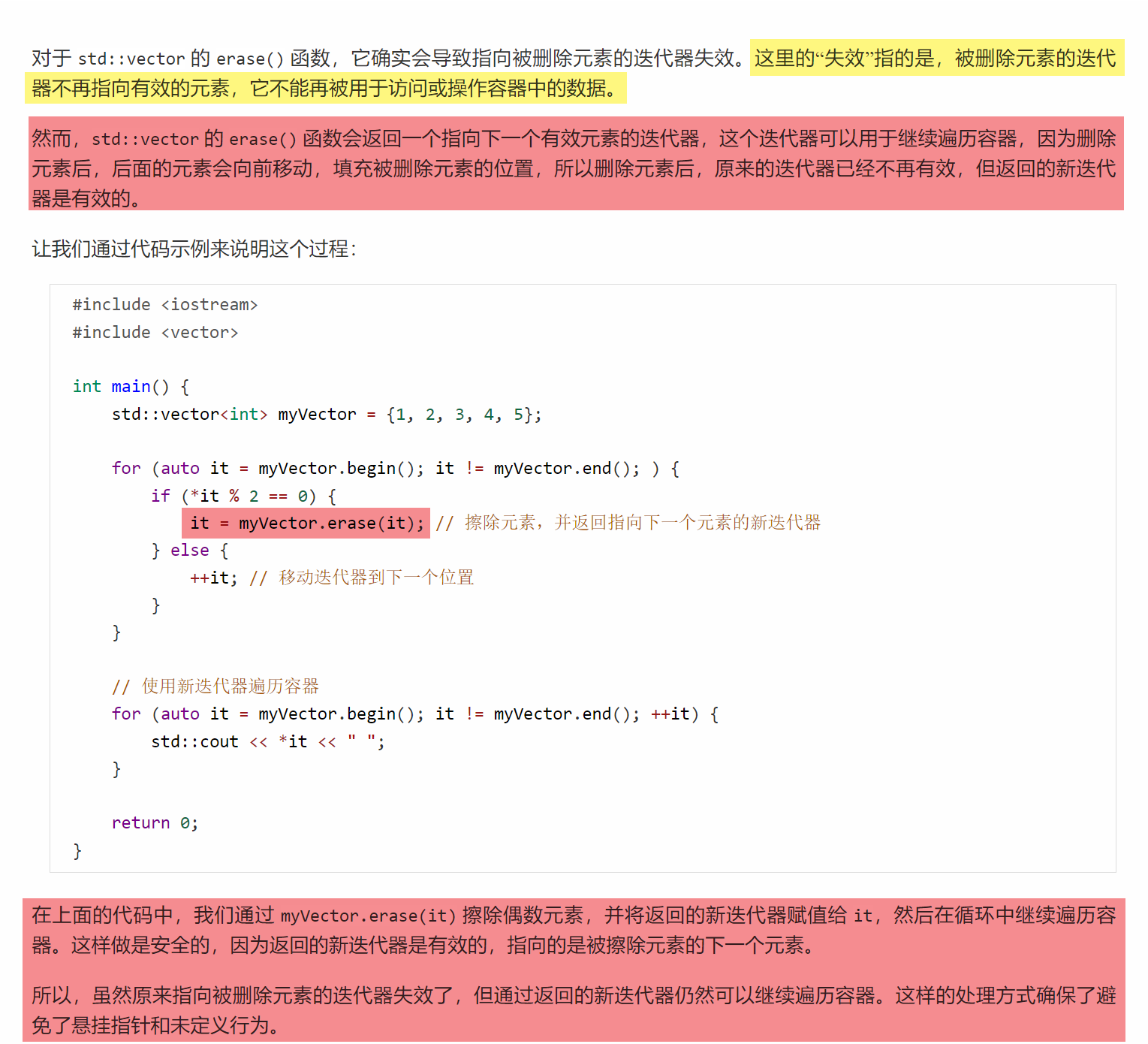
C++笔记之迭代器失效问题处理
C笔记之迭代器失效问题处理 code review! 参考博文:CSTL迭代器失效的几种情况总结 文章目录 C笔记之迭代器失效问题处理一.使用返回新迭代器的插入和删除操作二.对std::vector 来说,擦除(erase)元素会导致迭代器失效 一.使用返回…...

Tomcat的startup.bat文件出现闪退问题
对于双击Tomcat的startup.bat文件出现闪退问题,您提供的分析是正确的。主要原因是Tomcat需要Java Development Kit (JDK)的支持,而如果没有正确配置JAVA_HOME环境变量,Tomcat将无法找到JDK并启动,从而导致闪退。 以下是解决该问题…...

JAVA8-lambda表达式8:在设计模式-模板方法中的应用
传送门 JAVA8-lambda表达式1:什么是lambda表达式 JAVA8-lambda表达式2:常用的集合类api JAVA8-lambda表达式3:并行流,提升效率的利器? JAVA8-lambda表达式4:Optional用法 java8-lambda表达式5…...

React之组件间通信
React之组件间通信 组件通信: 简单讲就是组件之间的传值,包括state、函数等 1、父子组件通信 父组件给子组件传值 核心:1、自定义属性;2、props 父组件中: 自定义属性传值 import Header from /components/Headerconst Home ()…...
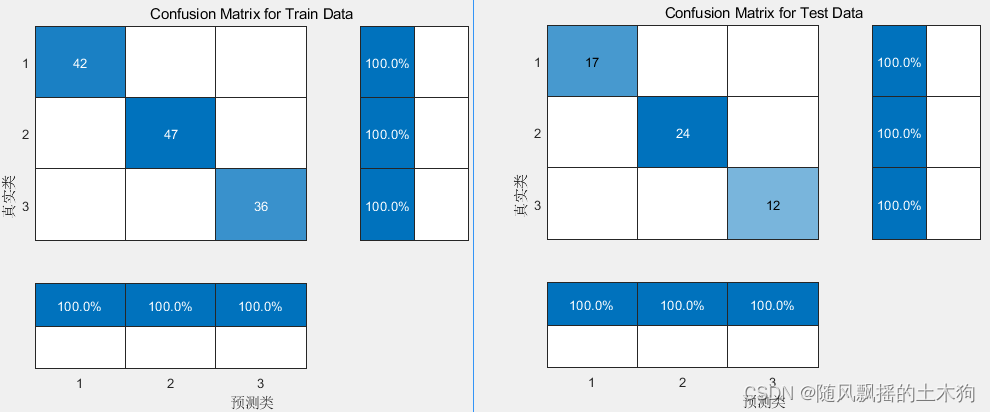
【MATLAB第58期】基于MATLAB的PCA-Kmeans、PCA-LVQ与BP神经网络分类预测模型对比
【MATLAB第58期】基于MATLAB的PCA-Kmeans、PCA-LVQ与BP神经网络分类预测模型对比 一、数据介绍 基于UCI葡萄酒数据集进行葡萄酒分类及产地预测 共包含178组样本数据,来源于三个葡萄酒产地,每组数据包含产地标签及13种化学元素含量,即已知类…...
CF1833 A-E
A题 题目链接:https://codeforces.com/problemset/problem/1833/A 基本思路:for循环遍历字符串s,依次截取字符串s的子串str,并保存到集合中,最后输出集合内元素的数目即可 AC代码: #include <iostrea…...

【深度学习】【Image Inpainting】Generative Image Inpainting with Contextual Attention
Generative Image Inpainting with Contextual Attention DeepFillv1 (CVPR’2018) 论文:https://arxiv.org/abs/1801.07892 论文代码:https://github.com/JiahuiYu/generative_inpainting 论文摘录 文章目录 效果一览摘要介绍论文贡献相关工作Image…...
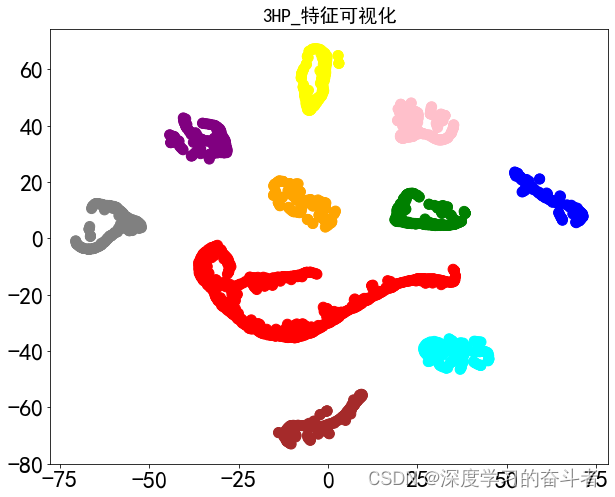
二维深度卷积网络模型下的轴承故障诊断
1.数据集 使用凯斯西储大学轴承数据集,一共有4种负载下采集的数据,每种负载下有10种 故障状态:三种不同尺寸下的内圈故障、三种不同尺寸下的外圈故障、三种不同尺寸下的滚动体故障和一种正常状态 2.模型(二维CNN) 使…...

redis突然变慢问题定位
CPU 相关:使用复杂度过高命令、O(N)的这个N,数据的持久化,都与耗费过多的 CPU 资源有关 内存相关:bigkey 内存的申请和释放、数据过期、数据淘汰、碎片整理、内存大页、内存写时复制都与内存息息相关 磁盘…...
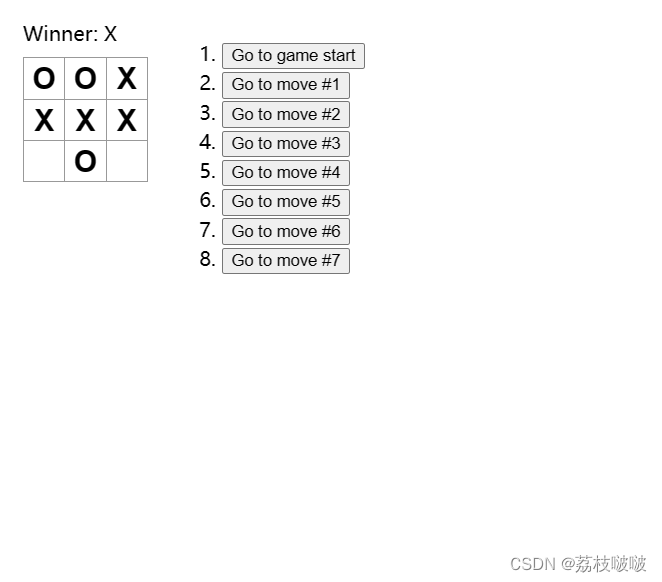
React井字棋游戏官方示例
在本篇技术博客中,我们将介绍一个React官方示例:井字棋游戏。我们将逐步讲解代码实现,包括游戏的组件结构、状态管理、胜者判定以及历史记录功能。让我们一起开始吧! 项目概览 在这个井字棋游戏中,我们有以下组件&am…...

CPU压力测试
工具环境:python3运行环境:SOC端内部测试用途:给SOC的CPU单个核以及MEM加压文件说明以及主要用法:""" CPU Loader """import os import sys import time import math import signal import argpars…...

第 3 篇:让 Agent 学会分工,LangGraph 构建多 Agent系统
系列简介:从零搭建一个多 Agent AI 助手,覆盖原理、实现、部署全链路。不讲空话,每篇都有可运行的代码。 项目地址:https://github.com/CodeMomentYY/LangGraph-Agent 本篇目标:用 LangGraph 搭建一个多 Agent 协作系统…...

终极FileBrowser上手指南:10分钟掌握Web文件管理神器
终极FileBrowser上手指南:10分钟掌握Web文件管理神器 【免费下载链接】filebrowser 📂 Web File Browser 项目地址: https://gitcode.com/gh_mirrors/fi/filebrowser FileBrowser是一个功能强大的Web文件管理器,让你能够通过浏览器界面…...

LimboAI在Godot 4中实现可维护游戏AI的工程化方案
1. 这不是又一个“AI行为树”教程——LimboAI在Godot 4里真正解决的是什么问题? 你有没有在Godot 4里写过这样的AI逻辑:一个巡逻的守卫,发现玩家后追击,进入攻击距离就挥剑,被击中后后退、喊话、短暂硬直,…...

洛雪音乐音源完全指南:一键解锁全网高品质音乐资源
洛雪音乐音源完全指南:一键解锁全网高品质音乐资源 【免费下载链接】lxmusic- lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/gh_mirrors/lx/lxmusic- 你是否厌倦了在多个音乐平台间切换,只为寻找一首心仪的歌曲?…...

嵌入式Linux入门首选:STM32MP157开发板核心优势与学习路径全解析
1. 项目概述:从“学什么”到“用什么学”的抉择每当有朋友或刚入行的新人问我,想入门嵌入式Linux,该从哪块板子开始,我的回答几乎总是绕不开STM32MP157。这听起来像是一个厂商的“标准答案”,但背后是我踩过无数坑、对…...

如何高效使用Gofile下载器:从单文件到批量下载的完整指南
如何高效使用Gofile下载器:从单文件到批量下载的完整指南 【免费下载链接】gofile-downloader Download files from https://gofile.io 项目地址: https://gitcode.com/gh_mirrors/go/gofile-downloader Gofile下载器是一款专门用于从Gofile.io平台下载文件的…...

终极指南:如何用calendar.js轻松实现农历公历智能转换
终极指南:如何用calendar.js轻松实现农历公历智能转换 【免费下载链接】calendar.js 中国农历(阴阳历)和西元阳历即公历互转JavaScript库 项目地址: https://gitcode.com/gh_mirrors/ca/calendar.js 想要在你的Web应用中添加中国传统文…...

windows下vs 2015 libtorrent库的配置,vs2015下-boost-openssl-libtorrent的配置
libtorrent依赖OpenSSL和boost库,首先要编译Openssl和boost库。 1、安装ActivePerl,下载地址:网上找。 安装完后配置环境变量(一般安装成功后,环境变量就已经配置好了,如果没有配置自己配置环境变量): …...

ArrayList 扩容机制详解
ArrayList 扩容机制详解 ArrayList 是 Java 用得最多的 List,底层是动态数组。理解扩容机制能避免一些性能问题。 1. 底层结构 transient Object[] elementData; private int size;// 默认初始容量 private static final int DEFAULT_CAPACITY 10;注意:…...