参数量仅有50KB的超轻量级unet变种网络egeunet【参数和计算量降低494和160倍】医疗图像分割实践
今天看到一篇挺有意思的文章,做的是跟医疗图像分割相关的工作,但是不像之前看到的一些工作一味地去追求高精度,因为医疗领域本身就是一个相对特殊的行业,对于模型产生的结果的精确性要求是很高的,带来的是参数量级的庞大,之所以觉得这篇论文挺有意思的就是因为这里的主要的点在于超轻量级但是并没有导致精度大幅下降。
官方论文地址在这里,如下所示:

可见刚发表不久。

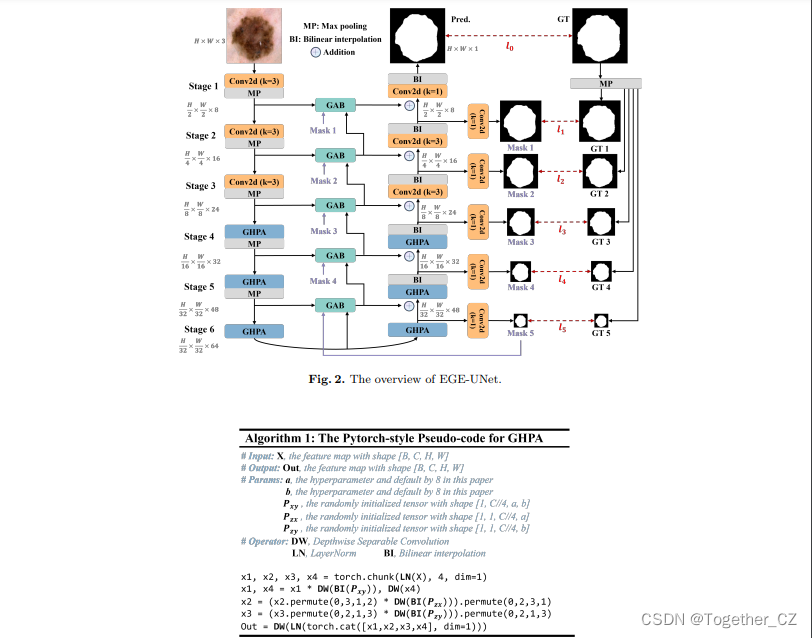
EGE-UNet融合了两个主要模块:
Group multi-axis Hadamard Product Attention module (GHPA)
Group Aggregation Bridge module (GAB)
GHPA 利用哈达玛积注意力机制(HPA),通过将输入特征进行分组,对不同轴进行 HPA 操作,从多个视角提取病变信息。
GAB 通过分组聚合将不同规模的高级语义特征和低级细节特征以及解码器生成的掩码进行融合,从而有效提取多尺度信息,
通过融合上述两个模块提出了EGE-UNet模型实现了在参数和计算复杂度极低的情况下优秀的分割性能。
EGE-UNet的设计沿用了 U 形架构,包括对称的编码器-解码器部分。编码器由六个 stage 组成,各阶段的通道数量为{8, 16, 24, 32, 48, 64}。前三个阶段采用了普通卷积,而后三个阶段使用提出的 GHPA 来从多视角提取表征信息。
EGE-UNet 在编码器和解码器之间的每个阶段都集成了GAB。此外,模型还利用深监督生成不同规模的掩膜预测,这些预测用于损失函数并作为 GAB 的输入之一。通过这些高级模块的集成,EGE-UNet 在比先前的方法提升了分割性能的同时,显著减少了参数和计算负载。
进一步详情可以自行研读发表的论文。
这里我也是初步了解了一下,主要是想要实际使用一下这个超轻量级的网络,因为我觉得这种类型的网络在现实工作里的意义更大,大参数量高精度模型固然很好,但是并未所有的工业或者是医疗场景里面的设备都具备那么高的算力能够支撑如此庞大的计算量的,如果能在高度轻量化的网络基础上保持不俗的精度性能的话着实还是很有实际意义的。
官方同时开源了项目,地址在这里,如下所示:

感觉目前的star量很少,估计是了解到的人还不多吧,就让我来带一波热度吧。
从readme来看,作者给出来的实操训练手册可以说是简单到了极致了:

数据集也一并准备好了,地址在这里,如下所示:

自行下载下来即可,体积不大,下载起来应该还是很快的。
下载下载放到项目data目录下面解压缩即可,如下所示:

可以看到:作者同时提供了两组数据集,项目源码默认使用的是isic2017的数据集的。
直接终端执行train.py模块即可,如下所示:

默认300个epoch的迭代计算:

训练完成截图如下所示:

结果默认存储在results目录下。如下所示:
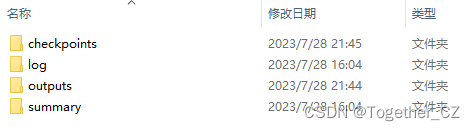
checkpoints目录下存放的是训练得到的模型文件,如下所示:

log目录下存放的是训练日志数据,如下所示:

outputs目录下存放的是实际测试的实例图像可视化结果,如下所示:

官方项目只提供了训练、评估使用的代码,没有提供离线推理可直接使用的代码,但是基于训练和评估部分的代码可以自行开发离线推理的代码,这里我为了能够更加简单的使用开发了专用的可视化系统界面,实例推理效果如下所示:

到这里基本完整的实践就结束了,前面也说过了源码默认使用的是isic2017的数据集,所以后面我又考虑基于isic2018的数据集也开发训练一下模型,只需要修改configs目录下的参数即可,如下所示:
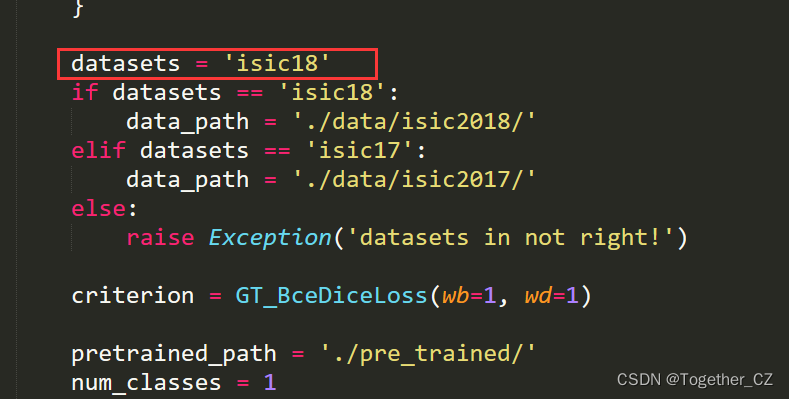
修改后的config_setting模块如下所示:
from torchvision import transforms
from utils import *from datetime import datetimeclass setting_config:"""the config of training setting."""network = 'egeunet'model_config = {'num_classes': 1, 'input_channels': 3, 'c_list': [8,16,24,32,48,64], 'bridge': True,'gt_ds': True,}datasets = 'isic18' if datasets == 'isic18':data_path = './data/isic2018/'elif datasets == 'isic17':data_path = './data/isic2017/'else:raise Exception('datasets in not right!')criterion = GT_BceDiceLoss(wb=1, wd=1)pretrained_path = './pre_trained/'num_classes = 1input_size_h = 256input_size_w = 256input_channels = 3distributed = Falselocal_rank = -1num_workers = 0seed = 42world_size = Nonerank = Noneamp = Falsegpu_id = '0'batch_size = 8epochs = 300work_dir = 'results/' + network + '_' + datasets + '_' + datetime.now().strftime('%A_%d_%B_%Y_%Hh_%Mm_%Ss') + '/'print_interval = 20val_interval = 30save_interval = 100threshold = 0.5train_transformer = transforms.Compose([myNormalize(datasets, train=True),myToTensor(),myRandomHorizontalFlip(p=0.5),myRandomVerticalFlip(p=0.5),myRandomRotation(p=0.5, degree=[0, 360]),myResize(input_size_h, input_size_w)])test_transformer = transforms.Compose([myNormalize(datasets, train=False),myToTensor(),myResize(input_size_h, input_size_w)])opt = 'AdamW'assert opt in ['Adadelta', 'Adagrad', 'Adam', 'AdamW', 'Adamax', 'ASGD', 'RMSprop', 'Rprop', 'SGD'], 'Unsupported optimizer!'if opt == 'Adadelta':lr = 0.01 # default: 1.0 – coefficient that scale delta before it is applied to the parametersrho = 0.9 # default: 0.9 – coefficient used for computing a running average of squared gradientseps = 1e-6 # default: 1e-6 – term added to the denominator to improve numerical stability weight_decay = 0.05 # default: 0 – weight decay (L2 penalty) elif opt == 'Adagrad':lr = 0.01 # default: 0.01 – learning ratelr_decay = 0 # default: 0 – learning rate decayeps = 1e-10 # default: 1e-10 – term added to the denominator to improve numerical stabilityweight_decay = 0.05 # default: 0 – weight decay (L2 penalty)elif opt == 'Adam':lr = 0.001 # default: 1e-3 – learning ratebetas = (0.9, 0.999) # default: (0.9, 0.999) – coefficients used for computing running averages of gradient and its squareeps = 1e-8 # default: 1e-8 – term added to the denominator to improve numerical stability weight_decay = 0.0001 # default: 0 – weight decay (L2 penalty) amsgrad = False # default: False – whether to use the AMSGrad variant of this algorithm from the paper On the Convergence of Adam and Beyondelif opt == 'AdamW':lr = 0.001 # default: 1e-3 – learning ratebetas = (0.9, 0.999) # default: (0.9, 0.999) – coefficients used for computing running averages of gradient and its squareeps = 1e-8 # default: 1e-8 – term added to the denominator to improve numerical stabilityweight_decay = 1e-2 # default: 1e-2 – weight decay coefficientamsgrad = False # default: False – whether to use the AMSGrad variant of this algorithm from the paper On the Convergence of Adam and Beyond elif opt == 'Adamax':lr = 2e-3 # default: 2e-3 – learning ratebetas = (0.9, 0.999) # default: (0.9, 0.999) – coefficients used for computing running averages of gradient and its squareeps = 1e-8 # default: 1e-8 – term added to the denominator to improve numerical stabilityweight_decay = 0 # default: 0 – weight decay (L2 penalty) elif opt == 'ASGD':lr = 0.01 # default: 1e-2 – learning rate lambd = 1e-4 # default: 1e-4 – decay termalpha = 0.75 # default: 0.75 – power for eta updatet0 = 1e6 # default: 1e6 – point at which to start averagingweight_decay = 0 # default: 0 – weight decayelif opt == 'RMSprop':lr = 1e-2 # default: 1e-2 – learning ratemomentum = 0 # default: 0 – momentum factoralpha = 0.99 # default: 0.99 – smoothing constanteps = 1e-8 # default: 1e-8 – term added to the denominator to improve numerical stabilitycentered = False # default: False – if True, compute the centered RMSProp, the gradient is normalized by an estimation of its varianceweight_decay = 0 # default: 0 – weight decay (L2 penalty)elif opt == 'Rprop':lr = 1e-2 # default: 1e-2 – learning rateetas = (0.5, 1.2) # default: (0.5, 1.2) – pair of (etaminus, etaplis), that are multiplicative increase and decrease factorsstep_sizes = (1e-6, 50) # default: (1e-6, 50) – a pair of minimal and maximal allowed step sizes elif opt == 'SGD':lr = 0.01 # – learning ratemomentum = 0.9 # default: 0 – momentum factor weight_decay = 0.05 # default: 0 – weight decay (L2 penalty) dampening = 0 # default: 0 – dampening for momentumnesterov = False # default: False – enables Nesterov momentum sch = 'CosineAnnealingLR'if sch == 'StepLR':step_size = epochs // 5 # – Period of learning rate decay.gamma = 0.5 # – Multiplicative factor of learning rate decay. Default: 0.1last_epoch = -1 # – The index of last epoch. Default: -1.elif sch == 'MultiStepLR':milestones = [60, 120, 150] # – List of epoch indices. Must be increasing.gamma = 0.1 # – Multiplicative factor of learning rate decay. Default: 0.1.last_epoch = -1 # – The index of last epoch. Default: -1.elif sch == 'ExponentialLR':gamma = 0.99 # – Multiplicative factor of learning rate decay.last_epoch = -1 # – The index of last epoch. Default: -1.elif sch == 'CosineAnnealingLR':T_max = 50 # – Maximum number of iterations. Cosine function period.eta_min = 0.00001 # – Minimum learning rate. Default: 0.last_epoch = -1 # – The index of last epoch. Default: -1. elif sch == 'ReduceLROnPlateau':mode = 'min' # – One of min, max. In min mode, lr will be reduced when the quantity monitored has stopped decreasing; in max mode it will be reduced when the quantity monitored has stopped increasing. Default: ‘min’.factor = 0.1 # – Factor by which the learning rate will be reduced. new_lr = lr * factor. Default: 0.1.patience = 10 # – Number of epochs with no improvement after which learning rate will be reduced. For example, if patience = 2, then we will ignore the first 2 epochs with no improvement, and will only decrease the LR after the 3rd epoch if the loss still hasn’t improved then. Default: 10.threshold = 0.0001 # – Threshold for measuring the new optimum, to only focus on significant changes. Default: 1e-4.threshold_mode = 'rel' # – One of rel, abs. In rel mode, dynamic_threshold = best * ( 1 + threshold ) in ‘max’ mode or best * ( 1 - threshold ) in min mode. In abs mode, dynamic_threshold = best + threshold in max mode or best - threshold in min mode. Default: ‘rel’.cooldown = 0 # – Number of epochs to wait before resuming normal operation after lr has been reduced. Default: 0.min_lr = 0 # – A scalar or a list of scalars. A lower bound on the learning rate of all param groups or each group respectively. Default: 0.eps = 1e-08 # – Minimal decay applied to lr. If the difference between new and old lr is smaller than eps, the update is ignored. Default: 1e-8.elif sch == 'CosineAnnealingWarmRestarts':T_0 = 50 # – Number of iterations for the first restart.T_mult = 2 # – A factor increases T_{i} after a restart. Default: 1.eta_min = 1e-6 # – Minimum learning rate. Default: 0.last_epoch = -1 # – The index of last epoch. Default: -1. elif sch == 'WP_MultiStepLR':warm_up_epochs = 10gamma = 0.1milestones = [125, 225]elif sch == 'WP_CosineLR':warm_up_epochs = 20重新训练启动日志输出如下所示:

整体的资源占用可以看到还是很低的,如下所示:

等到模型训练完成后再来看下实际效果,感兴趣的话都可以自己尝试实践一下。后面可以考虑将本文中的超轻量级的模型应用到实际项目开发过程中。
相关文章:
参数量仅有50KB的超轻量级unet变种网络egeunet【参数和计算量降低494和160倍】医疗图像分割实践
今天看到一篇挺有意思的文章,做的是跟医疗图像分割相关的工作,但是不像之前看到的一些工作一味地去追求高精度,因为医疗领域本身就是一个相对特殊的行业,对于模型产生的结果的精确性要求是很高的,带来的是参数量级的庞…...
根据需求动态添加删除一级菜单、二级菜单的设置项)
Android10 Settings系列(三)根据需求动态添加删除一级菜单、二级菜单的设置项
一 、背景 当时遇到定制需求,需要根据实际需要隐藏Settings的菜单项,于是开始了寻找方法 二 、准备工作 在看了一下源码,经过尝试后,确认生效后,就简单说明一下Settings中布局中主要组成元素 Settings中的菜单项是由 PreferenceScreen 和Preference组成的。其中Prefer…...
51单片机——串行口通信
目录 1、51单片机串口通信介绍 2、串行口相关寄存器 2.1 、串行口控制寄存器SCON和PCON 2.1.1 SCON:串行控制寄存器 (可位寻址) 2.1.2 PCON:电源控制寄存器(不可位寻址) 2.2、串行口数据缓冲寄存器SBUF 2.3、从机地址控制…...

洛谷题单 Part 6.7.1 矩阵
应队友要求,开始学线性代数,具体路线是矩阵 → \rightarrow →高斯消元 → \rightarrow →线性基。为多项式做个准备 P3390 【模板】矩阵快速幂 题面 板子,用结构体写的,感觉有点丑,一会儿看看题解有没有写得好看的 …...

Spring中c3p0与dbcp配置
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:jee="http://www.springframework.org/schem…...

Flutter 添加 example流程
一、已有Flutter工程(命令)添加 example 1、cd 工程(flutter_plugin ,是自己创建的)根目录 例: flutter create example 执行命令创建example PS:cd example 后执行flutter doctor 后就可以看到效果 2、如果需要指定iOS/Android 语言,请添加…...

数据治理8种方法
数据治理8种方法 8种方法,分别是:顶层设计法、技术推动法、应用牵引法、标准先行法、监管驱动法、质量管控法、利益驱动法、项目建设法。 事先声明,这些方法论都是向各位大佬学习来的,也有部分是项目中实操得来的,并非…...

大模型成互联网真正蜕变的标志,亦是各种新技术开始衍生的标志
以往,我们看到了以区块链、元宇宙为代表的诸多新物种的出现,但是,它们始终都没有逃脱仅仅只是一个概念和噱头的宿命,它们始终都没有走出一条可持续的发展道路。说到底,它们仅仅只是一个没有实现商业闭环的概念而已&…...
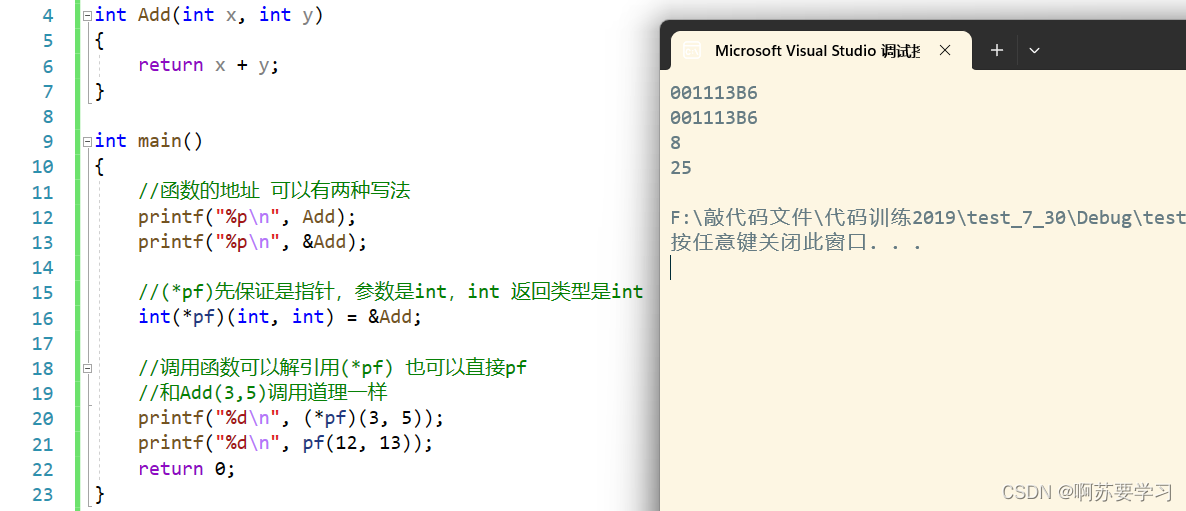
指针进阶详解---C语言
❤博主CSDN:啊苏要学习 ▶专栏分类:C语言◀ C语言的学习,是为我们今后学习其它语言打好基础,C生万物! 开始我们的C语言之旅吧!✈ 目录 前言: 一.字符指针 二.指针数组 三.数组指针 四.数组、指针参数 …...

设计模式思考,简单工厂模式和策略模式的区别?
最近学习了设计模式,学到简单工厂模式和策略模式的时候想,这两个模式不是一样嘛,仔细思考之后发现大体设计思路是一样的,但是细节却有所不一样。 简单工厂模式 简单工厂模式是一种创建型设计模式,它主要涉及对象的创建…...

Java - sh 脚本启动 jar 包等服务 - sh 脚本模板 - 适用于任何类似的服务启动
sh 脚本模板 该模板,每次运行一次都会 kill 掉原来的服务,然后重新启动 jar 包服务 #!/bin/bash# 定义Java进程的名称 APP_NAMEyour-app-name.jar# 定义Java进程的日志文件路径 LOG_PATH/var/log/your-app-name.log# 定义备份日志文件的目录 BACKUP_DI…...

MySQL高级篇第5章(存储引擎)
文章目录 1、查看存储引擎2、设置系统默认的存储引擎3、设置表的存储引擎3.1 创建表时指定存储引擎3.2 修改表的存储引擎 4、引擎介绍4.1 InnoDB 引擎:具备外键支持功能的事务存储引擎4.2 MyISAM 引擎:主要的非事务处理存储引擎4.3 Archive 引擎…...
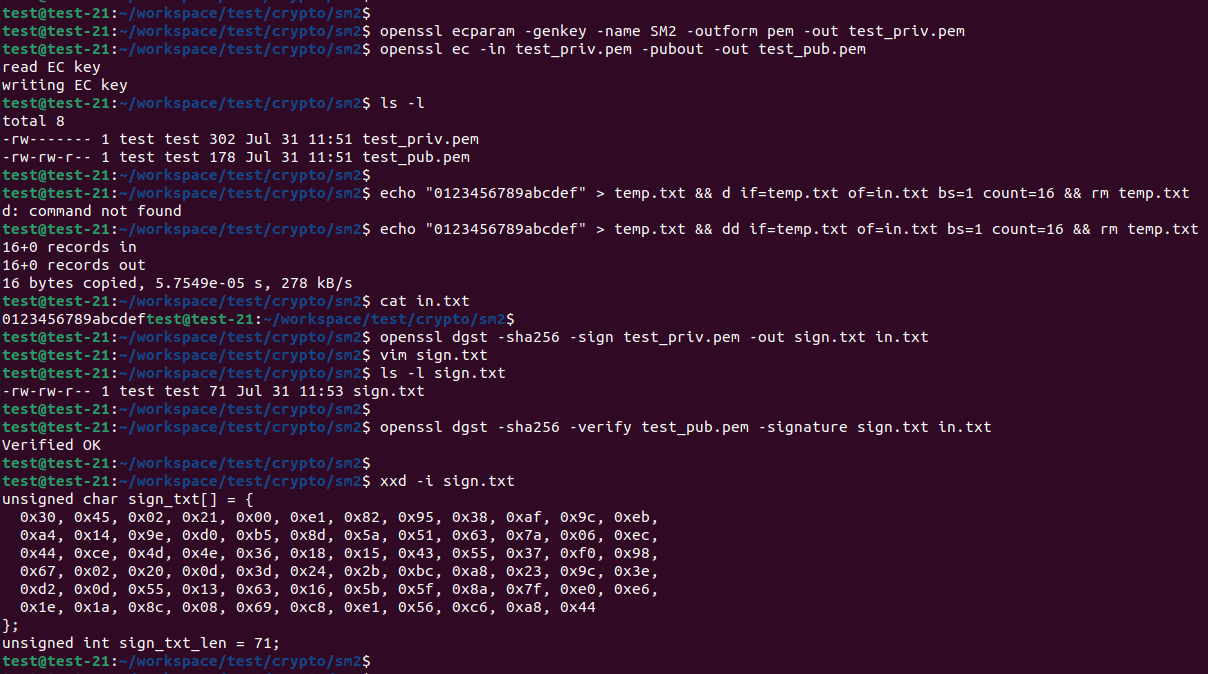
openssl 命令行国密sm2的签名验签操作
快速链接: . 👉👉👉 个人博客笔记导读目录(全部) 👈👈👈 付费专栏-付费课程 【购买须知】: 密码学实践强化训练–【目录】 👈👈👈 生成EC私钥: openssl ecp…...
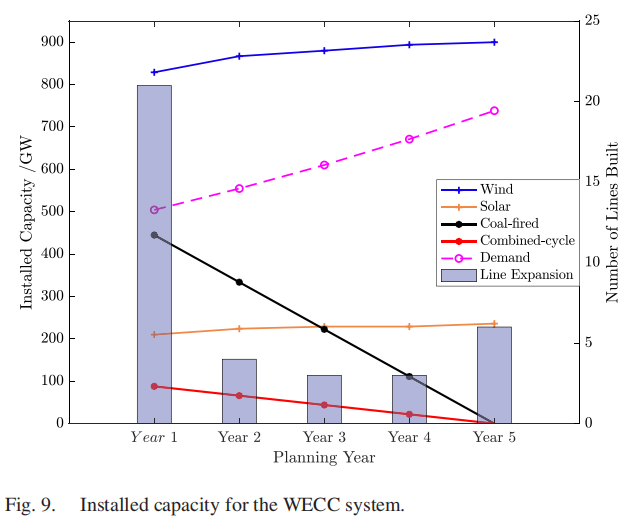
开源代码分享(9)—面向100%清洁能源的发输电系统扩展规划(附matlab代码)
1.背景介绍 1.1摘要 本文提出了一种新颖的建模框架和基于分解的解决策略,将随机规划(SP)和鲁棒优化(RO)相结合,以应对协调中长期电力系统规划中的多重不确定性。从独立系统运营商(ISOÿ…...

为 Google Play 即将推出基于区块链的内容政策做好准备
作者 / Joseph Mills, Group Product Manager, Google Play 作为一个平台,Google Play 一直致力于帮助开发者将创新理念变为现实。Google Play 上托管了许多和区块链相关的应用,我们深知合作伙伴们希望扩展这些应用,并利用 NFT 等代币化数字资…...

查找-多路查找详解篇
多路查找树 多路查找树(Multway Search Tree)是一种高级的树形数据结构,它 允许每个节点有多个子节点(通常大于等于2)。多路查找树的每个节点 可以存储多个关键字和对应的值。分类 2-3树(2-3 Tree&#x…...
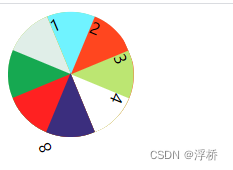
css设置八等分圆
现需要上图样式的布局,我通过两张向右方的图片,通过定位和旋转完成了布局。 问题: 由于是通过旋转获取到的样式,实际的盒子是一个长方形,当鼠标移入对应的箭头时选中的可能是其他盒子,如第一张设计稿可以看…...

「教程」如何使用一套代码在多种程序中接入天气预警API
引言 天气预警的重要性不言而喻,在遭受自然灾害和极端天气时,及时获得预警信息可以拯救生命和减少财产损失。如今,随着科技的进步,开发者和企业可以借助天气预警 API 这款强大的服务,将实时预警信息集成到自己的应用中…...
(MYSQL)数据库服务端的启动与停止,登录与退出
MYSQL服务的启动与停止 方式一:右击左下角win图标——选择计算机管理——选择计算机管理(本地)——选择服务和应用程序——找到mysql(此方法不好用) 方式二:通过管理员身份运行(必须是管理员身…...

数学建模学习(8):单目标和多目标规划
优化问题描述 优化 优化算法是指在满足一定条件下,在众多方案中或者参数中最优方案,或者参数值,以使得某个或者多个功能指标达到最优,或使得系统的某些性能指标达到最大值或者最小值 线性规划 线性规划是指目标函数和约束都是线性的情况 [x,fval]linprog(f,A,b,Aeq,Beq,LB,U…...

深度神经网络非线性行为的分段几何诊断法
1. 这不是又一篇“调库跑通”的深度学习教程——它直指模型失效的根源你有没有遇到过这样的情况:数据质量没问题,网络结构参考了SOTA论文,超参也做了网格搜索,但模型在验证集上就是卡在某个精度上再也上不去?损失曲线看…...

为什么越来越多公司坚持做背调?
很多中小企业都有一个误区:觉得背调“可有可无”、浪费时间、增加成本。但真实职场现状是:不做背调,才是企业最大的隐形成本。现在求职简历美化早已是常态,履历注水、项目造假、隐瞒纠纷、失信记录……肉眼面试根本看不出来。一次…...

ARGUS:视觉中心化多模态推理框架,实现像素级可验证Chain-of-Thought
1. 项目概述:这不是又一个“多模态大模型”,而是一次视觉推理范式的重新校准ARGUS这个名字,乍看像某个军事侦察系统代号,其实它精准指向了当前多模态AI领域最棘手的痛点——视觉信息在推理链中长期处于“失语”状态。你肯定见过这…...

你的 FlashAttention 真的在跑吗?几个简单方法确认
之前有个朋友在昇腾 NPU 上部署模型,按文档开了 --enable-flash-attn,跑起来也没报错。但他总觉得延迟不对——跟之前没开的时候差不多。他问我:怎么确认 FlashAttention 真的生效了?不会是静默降级了吧? 这个问题问得…...
)
ESP32 + SPH0645麦克风:用Python在电脑上实时播放音频的保姆级教程(附避坑指南)
ESP32 SPH0645麦克风:Python服务端实时音频流处理实战指南 在物联网和嵌入式音频处理领域,实时音频流的采集与传输一直是个既基础又关键的挑战。ESP32作为一款性价比极高的Wi-Fi/蓝牙双模芯片,搭配专业级数字麦克风SPH0645,能够构…...
)
为什么你的 Agent 总是跑着跑着就废了?聊聊 Loop 设计里那些坑(文末赠书)
"我的 Agent Demo 跑得挺顺的,一上生产就各种出问题。" 这句话我在不同场合听过太多次了。包括我自己最早写 Agent 的时候也是这样——一个简单的 ReAct 循环,本地测得好好的,放到真实场景里不是上下文爆了就是死循环,偶尔还给你来个"无限重试把 API 额度刷光&…...

pytorch-adapter:让 PyTorch 模型“无缝”跑在昇腾 NPU 上
pytorch-adapter:让 PyTorch 模型“无缝”跑在昇腾 NPU 上 之前帮朋友看 PyTorch 模型适配 CANN 的代码,发现他手写了很多适配层——把自己的 MyModel 一层层翻译成 AscendCL 接口,光写适配层就写了 2,000 行。 我告诉他:不用手…...

深入nRF5340双核通信:拆解LE Audio同步背后的IPC与DPPI机制
深入拆解nRF5340双核通信:LE Audio同步背后的IPC与DPPI实战解析 当你在调试nRF5340的LE Audio应用时,是否遇到过这样的场景:网络核(NET Core)已经收到了完整的音频数据包,但应用核(APP Core)的音频处理却出现了微秒级的延迟&#…...

ngx_http_set_virtual_server
1 定义 ngx_http_set_virtual_server 函数 定义在 ./nginx-1.24.0/src/http/ngx_http_request.cstatic ngx_int_t ngx_http_set_virtual_server(ngx_http_request_t *r, ngx_str_t *host) {ngx_int_t rc;ngx_http_connection_t *hc;ngx_http_core_loc_con…...

飞凌OKMX6ULL-C开发板深度评测:从硬件解析到系统性能实战
1. 开箱与初识:飞凌OKMX6ULL-C开发平台拿到飞凌OKMX6ULL-C开发板的第一印象,是它比我想象中要“工整”不少。核心板(FETMX6ULL-C)和底板通过高可靠性的板对板连接器接插,这种设计在工业级产品中很常见,方便…...