【计算机视觉】BLIP:源代码示例demo(含源代码)
文章目录
- 一、Image Captioning
- 二、VQA
- 三、Feature Extraction
- 四、Image-Text Matching
一、Image Captioning
首先配置代码:
import sys
if 'google.colab' in sys.modules:print('Running in Colab.')!pip3 install transformers==4.15.0 timm==0.4.12 fairscale==0.4.4!git clone https://github.com/salesforce/BLIP%cd BLIP
这段代码用于在Google Colab环境中进行设置。代码首先检查是否在Google Colab环境中运行(‘google.colab’ in sys.modules)。如果是在Colab环境中运行,它会继续使用pip3安装特定版本的Python包。然后,它通过git clone命令克隆名为"BLIP"的GitHub代码仓库。最后,代码使用%cd命令将当前工作目录更改为"BLIP"代码仓库的目录。
这段代码的目的是在Google Colab中设置必要的环境,以便在"BLIP"代码仓库中继续执行其他相关代码。
from PIL import Image
import requests
import torch
from torchvision import transforms
from torchvision.transforms.functional import InterpolationModedevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def load_demo_image(image_size,device):img_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg' raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB') w,h = raw_image.sizedisplay(raw_image.resize((w//5,h//5)))transform = transforms.Compose([transforms.Resize((image_size,image_size),interpolation=InterpolationMode.BICUBIC),transforms.ToTensor(),transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))]) image = transform(raw_image).unsqueeze(0).to(device) return image
这段代码用于加载演示图像并进行预处理,以便用于后续的计算机视觉任务。让我们逐行解读代码:
-
from PIL import Image: 导入PIL库中的Image模块,用于图像处理。
-
import requests: 导入requests库,用于从网络上获取图像。
-
import torch: 导入PyTorch库,用于深度学习任务。
-
from torchvision import transforms: 从torchvision库中导入transforms模块,用于图像预处理。
-
from torchvision.transforms.functional import InterpolationMode: 从torchvision.transforms.functional模块中导入InterpolationMode,用于指定图像的插值方式。
-
device = torch.device(‘cuda’ if torch.cuda.is_available() else ‘cpu’): 判断是否有可用的GPU,如果有则将device设置为cuda,否则设置为cpu。后续计算会在这个设备上执行。
-
def load_demo_image(image_size, device):: 定义了一个名为load_demo_image的函数,该函数接受图像大小image_size和计算设备device作为输入参数。
-
img_url = ‘https://storage.googleapis.com/sfr-vision-language-research/BLIP/demo.jpg’: 定义了演示图像的URL。
-
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert(‘RGB’): 从给定的URL下载原始图像,并使用PIL库中的Image模块打开和转换图像格式为RGB。
-
w, h = raw_image.size: 获取原始图像的宽度和高度。
-
display(raw_image.resize((w//5, h//5))): 使用display函数显示缩小后的原始图像。
-
transform = transforms.Compose([…]): 定义一个图像预处理的变换链,包括图像大小调整、图像转换为张量、以及归一化等操作。
-
image = transform(raw_image).unsqueeze(0).to(device): 对原始图像进行预处理,并将其转换为张量。使用unsqueeze(0)将图像张量的维度从 [C, H, W] 调整为 [1, C, H, W],以匹配网络模型的输入形状。最后,将处理后的图像张量移动到之前设定的计算设备上。
-
return image: 返回预处理后的图像张量。
这段代码的作用是加载演示图像,并将其预处理成适合用于后续计算机视觉任务的张量数据。在函数调用时,您需要传入所需的图像大小和计算设备,然后可以使用返回的图像张量进行计算机视觉模型的推理和分析。
from models.blip import blip_decoderimage_size = 384
image = load_demo_image(image_size=image_size, device=device)model_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_capfilt_large.pth'model = blip_decoder(pretrained=model_url, image_size=image_size, vit='base')
model.eval()
model = model.to(device)with torch.no_grad():# beam searchcaption = model.generate(image, sample=False, num_beams=3, max_length=20, min_length=5) # nucleus sampling# caption = model.generate(image, sample=True, top_p=0.9, max_length=20, min_length=5) print('caption: '+caption[0])
-
from models.blip import blip_decoder: 导入自定义的blip_decoder模型,这是"BLIP"模型的解码部分。
-
image_size = 384: 定义图像大小为384x384像素。
-
image = load_demo_image(image_size=image_size, device=device): 使用之前定义的load_demo_image函数加载演示图像,并对图像进行预处理,以适应模型的输入要求。image是经过预处理后的图像张量。
-
model_url = ‘https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_capfilt_large.pth’: 定义了预训练模型的URL。
-
model = blip_decoder(pretrained=model_url, image_size=image_size, vit=‘base’): 使用blip_decoder模型的构造函数创建模型实例。此处的pretrained参数指定了预训练模型的URL,image_size参数指定了图像大小,vit参数指定了使用哪个ViT(Vision Transformer)模型,这里选择了base版本。
-
model.eval(): 将模型设置为评估模式,这会关闭一些在训练时启用的特定功能,如Dropout。
-
model = model.to(device): 将模型移动到之前设定的计算设备上。
-
with torch.no_grad():: 使用torch.no_grad()上下文管理器,以确保在推理时不会计算梯度。
-
caption = model.generate(image, sample=False, num_beams=3, max_length=20, min_length=5): 使用model.generate()方法生成图像的描述。这里使用了beam search方法来搜索最佳的描述。sample=False表示不使用采样方法,而是使用beam search。num_beams=3表示beam search时使用3个束(beam)。max_length=20表示生成的描述最长为20个词,min_length=5表示生成的描述最短为5个词。
-
print('caption: '+caption[0]): 输出生成的图像描述。
这段代码的作用是使用预训练的"BLIP"模型对加载的图像进行描述生成。它使用beam search方法在模型中进行推理,并输出生成的图像描述。您可以尝试使用不同的采样方法或调整其他参数,来观察生成描述的变化。
输出结果为:

load checkpoint from https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model*_base_caption.pth
caption: a woman sitting on the beach with a dog
二、VQA
from models.blip_vqa import blip_vqaimage_size = 480
image = load_demo_image(image_size=image_size, device=device) model_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_vqa_capfilt_large.pth'model = blip_vqa(pretrained=model_url, image_size=image_size, vit='base')
model.eval()
model = model.to(device)question = 'where is the woman sitting?'with torch.no_grad():answer = model(image, question, train=False, inference='generate') print('answer: '+answer[0])
-
from models.blip_vqa import blip_vqa: 导入自定义的blip_vqa模型,这是"BLIP"模型的视觉问答部分。
-
image_size = 480: 定义图像大小为480x480像素。
-
image = load_demo_image(image_size=image_size, device=device): 使用之前定义的load_demo_image函数加载演示图像,并对图像进行预处理,以适应模型的输入要求。image是经过预处理后的图像张量。
-
model_url = ‘https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_vqa_capfilt_large.pth’: 定义了视觉问答模型的预训练模型的URL。
-
model = blip_vqa(pretrained=model_url, image_size=image_size, vit=‘base’): 使用blip_vqa模型的构造函数创建模型实例。此处的pretrained参数指定了预训练模型的URL,image_size参数指定了图像大小,vit参数指定了使用哪个ViT(Vision Transformer)模型,这里选择了base版本。
-
model.eval(): 将模型设置为评估模式,这会关闭一些在训练时启用的特定功能,如Dropout。
-
model = model.to(device): 将模型移动到之前设定的计算设备上。
-
question = ‘where is the woman sitting?’: 定义了一个视觉问答问题,这里的问题是"where is the woman sitting?"。
-
with torch.no_grad():: 使用torch.no_grad()上下文管理器,以确保在推理时不会计算梯度。
-
answer = model(image, question, train=False, inference=‘generate’): 使用模型的__call__方法进行推理,输入图像和问题,以生成回答。train=False表示在推理过程中不使用训练模式。inference='generate’表示使用生成式推理方法,而不是提供答案的训练模式。
-
print('answer: '+answer[0]): 输出生成的回答。
这段代码的作用是使用预训练的"BLIP"模型进行视觉问答,根据给定的问题对加载的图像进行回答生成。它使用生成式推理方法来生成回答。您可以尝试提供不同的问题,来观察模型生成的回答。
输出结果:

load checkpoint from https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model*_vqa.pth
answer: on beach
三、Feature Extraction
from models.blip import blip_feature_extractorimage_size = 224
image = load_demo_image(image_size=image_size, device=device) model_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base.pth'model = blip_feature_extractor(pretrained=model_url, image_size=image_size, vit='base')
model.eval()
model = model.to(device)caption = 'a woman sitting on the beach with a dog'multimodal_feature = model(image, caption, mode='multimodal')[0,0]
image_feature = model(image, caption, mode='image')[0,0]
text_feature = model(image, caption, mode='text')[0,0]
输出结果为:

load checkpoint from https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base.pth
四、Image-Text Matching
from models.blip_itm import blip_itmimage_size = 384
image = load_demo_image(image_size=image_size,device=device)model_url = 'https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_retrieval_coco.pth'model = blip_itm(pretrained=model_url, image_size=image_size, vit='base')
model.eval()
model = model.to(device='cpu')caption = 'a woman sitting on the beach with a dog'print('text: %s' %caption)itm_output = model(image,caption,match_head='itm')
itm_score = torch.nn.functional.softmax(itm_output,dim=1)[:,1]
print('The image and text is matched with a probability of %.4f'%itm_score)itc_score = model(image,caption,match_head='itc')
print('The image feature and text feature has a cosine similarity of %.4f'%itc_score)
输出结果为:

load checkpoint from https://storage.googleapis.com/sfr-vision-language-research/BLIP/models/model_base_retrieval_coco.pth
text: a woman sitting on the beach with a dog
The image and text is matched with a probability of 0.9960
The image feature and text feature has a cosine similarity of 0.5262
相关文章:
【计算机视觉】BLIP:源代码示例demo(含源代码)
文章目录 一、Image Captioning二、VQA三、Feature Extraction四、Image-Text Matching 一、Image Captioning 首先配置代码: import sys if google.colab in sys.modules:print(Running in Colab.)!pip3 install transformers4.15.0 timm0.4.12 fairscale0.4.4!g…...

TWILIGHT靶场详解
TWILIGHT靶场详解 下载地址:https://download.vulnhub.com/sunset/twilight.7z 这是一个比较简单的靶场,拿到IP后我们扫描发现开启了超级多的端口 其实这些端口一点用都没有,在我的方法中 但是也有不同的方法可以拿权限,就需要…...

【案例】--GPT衍生应用案例
目录 一、前言二、GPT实现智能问答架构2.1、基本的GPT实现智能问答架构2.2、可应用的GPT实现智能问答架构1、语义转换2、相似度关键字矩阵3、ES中搜索相似度关键字矩阵三、后续一、前言 GPT,全称Generative Pre-trained Transformer ,中文名可译作生成式预训练Transformer。…...

Sip网络音频对讲广播模块, sip网络寻呼话筒音频模块
Sip网络音频对讲广播模块, sip网络寻呼话筒音频模块 一、模块介绍 SV-2101VP和 SV-2103VP网络音频对讲广播模块 是一款通用的独立SIP音频功能模块,可以轻松地嵌入到OEM产品中。该模块对来自网络的SIP协议及RTP音频流进行编解码。 该模块支持多种网络协议…...
)
leetcode1219. 黄金矿工(java)
黄金矿工 leetcode1219. 黄金矿工题目描述回溯算法代码 回溯算法 leetcode1219. 黄金矿工 难度: 中等 eetcode 1219 黄金矿工 题目描述 你要开发一座金矿,地质勘测学家已经探明了这座金矿中的资源分布,并用大小为 m * n 的网格 grid 进行了标注。每个单元…...

Svelte框架入门
关键词 前端框架、编译器、响应式、模板 介绍 Svelte /svelt/ adj. 苗条的;线条清晰的;和蔼的 Svelte是一个前端组件框架,就像它的英文名字一样,Svelte的目标是打造一个更高性能的响应性前端框架。 Svelte类似于React和Vue框架&am…...
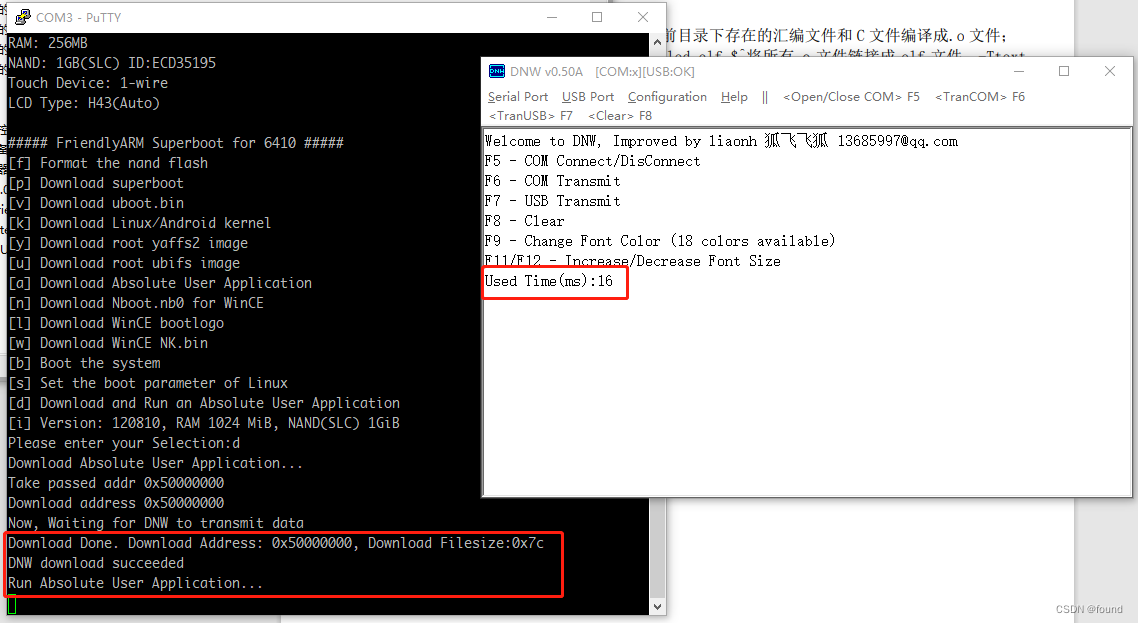
在linux中进行arm交叉编译体验tiny6410裸机程序开发流程
在某鱼上找了一个友善之臂的Tiny6410开发板用来体验一下嵌入式开发。这次先体验一下裸机程序的开发流程,由于这个开发板比较老旧了,官方文档有很多过期的内容,所以记录一下整个过程。 1. 交叉编译器安装 按照光盘A中的文档《04- Tiny6410 L…...
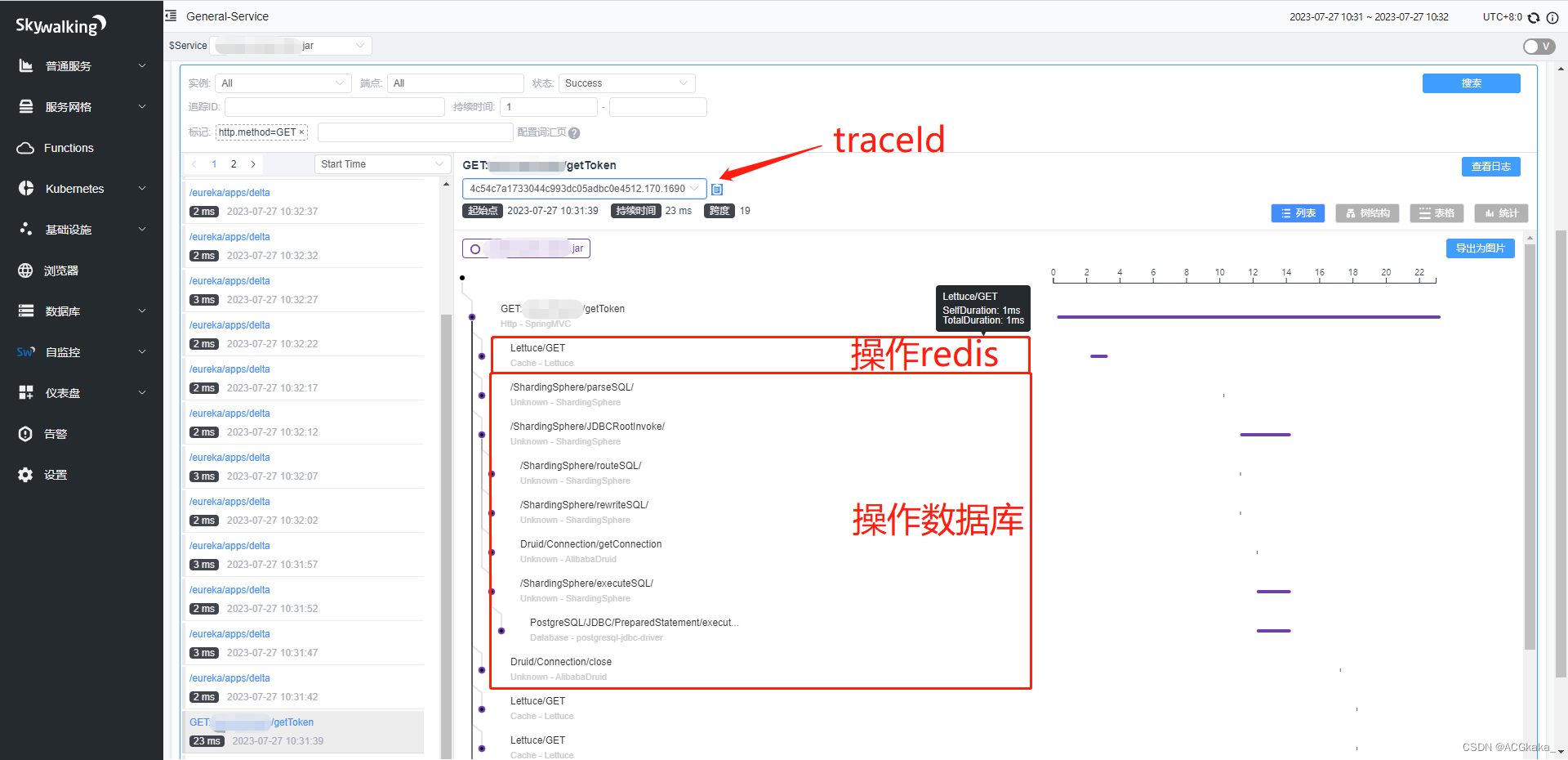
SpringBoot实战(二十三)集成 SkyWalking
目录 一、简介二、拉取镜像并部署1.拉取镜像2.运行skywalking-oap容器3.运行skywalking-ui容器4.访问页面 三、下载解压 agent1.下载2.解压 四、创建 skywalking-demo 项目1.Maven依赖2.application.yml3.DemoController.java 五、构建启动脚本1.startup.bat2.执行启动脚本3.发…...
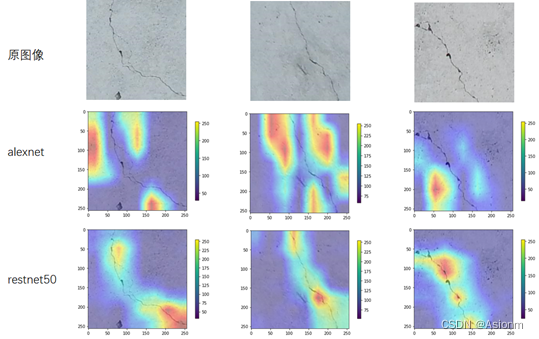
深度学习实践——卷积神经网络实践:裂缝识别
深度学习实践——卷积神经网络实践:裂缝识别 系列实验 深度学习实践——卷积神经网络实践:裂缝识别 深度学习实践——循环神经网络实践 深度学习实践——模型部署优化实践 深度学习实践——模型推理优化练习 深度学习实践——卷积神经网络实践ÿ…...
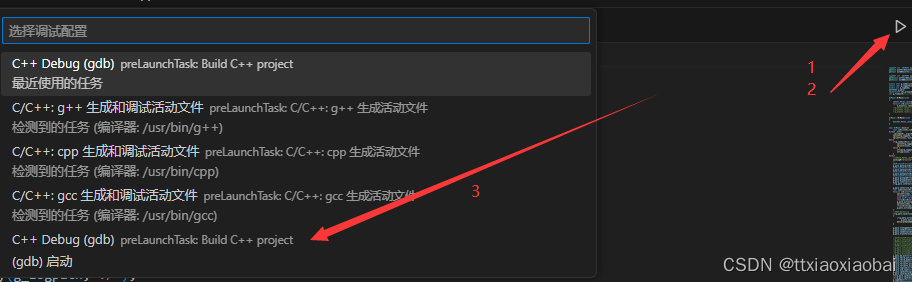
linux | vscode | makefile | c++编译和调试
简单介绍环境: vscode 、centos、 gcc、g、makefile 简单来说就是,写好项目然后再自己写makefile脚本实现编译。所以看这篇博客的用户需要了解gcc编译的一些常用命令以及makefile语法。在网上看了很多教程,以及官网也看了很多次,最…...

Spring | Bean 作用域和生命周期
一、通过一个案例来看 Bean 作用域的问题 Spring 是用来读取和存储 Bean,因此在 Spring 中 Bean 是最核心的操作资源,所以接下来我们深入学习⼀下 Bean 对象 假设现在有⼀个公共的 Bean,提供给 A 用户和 B 用户使用,然而在使用的…...
)
培训(c++题解)
题目描述 某培训机构的学员有如下信息: 姓名(字符串)年龄(周岁,整数)去年 NOIP 成绩(整数,且保证是 5 的倍数) 经过为期一年的培训,所有同学的成绩都有所提…...
ansible-playbook编写 lnmp 剧本
ansible-playbook编写 lnmp 剧本 vim /opt/lnmp/lnmp.yaml执行剧本 ansible-playbook lnmp.yaml...

需求太多处理不过来?MoSCoW模型帮你
一、MoSCoW模型是什么 MoSCoW模型 是在项目管理、软件开发中使用的一种排序优先级的方法,以便开发人员、产品经理、客户对每个需求交付的重要性达成共识。 MoSCoW是一个首字母缩略词,代表: M(Must have):…...
Vue 3:玩一下web前端技术(六)
前言 本章内容为VUE请求后端技术与相关技术讨论。 上一篇文章地址: Vue 3:玩一下web前端技术(五)_Lion King的博客-CSDN博客 下一篇文章地址: Vue 3:玩一下web前端技术(七)_Lio…...

【点云处理教程】00计算机视觉的Open3D简介
一、说明 Open3D 是一个开源库,使开发人员能够处理 3D 数据。它提供了一组用于 3D 数据处理、可视化和机器学习任务的工具。该库支持各种数据格式,例如 .ply、.obj、.stl 和 .xyz,并允许用户创建自定义数据结构并在程序中访问它们。 Open3D 广…...
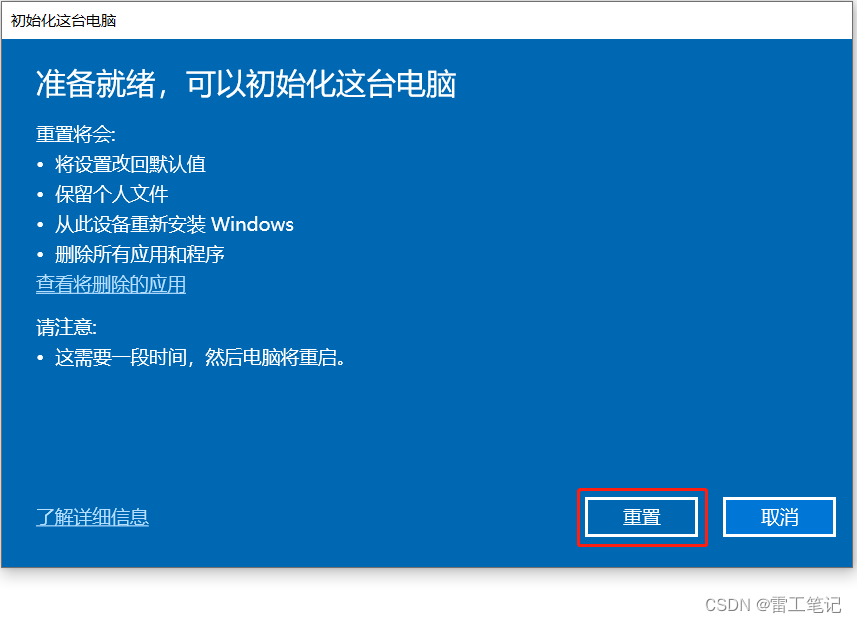
Windows10系统还原操作
哈喽,大家好,我是雷工! 复制了下虚拟机的Win10系统,但其中有一些软件,想实现类似手机的格式化出厂操作,下面记录Windows10系统的还原操作。 一、系统环境: 虚拟机内的Windows10,64…...
基础)
Django学习笔记-模板(Template)基础
使用模块可以很方便的执行一些数据操作,然后根据传入的数据直接在模板html文件中进行处理。 1.Django中的模板配置 Django的模板引擎在sttings.py文件中: TEMPLATES [{# 模板引擎,默认为django模板BACKEND: django.template.backends.dja…...

使用 NVM(Node Version Manager)管理 Node.js 版本
使用 NVM(Node Version Manager)管理 Node.js 版本 步骤一:安装 NVM NVM 是一个用于安装和管理不同版本的 Node.js 的工具。首先,你需要确保你的系统上已经安装了 NVM。可以通过以下命令检查 NVM 是否已经安装: nvm …...

(文章复现)梯级水光互补系统最大化可消纳电量期望短期优化调度模型matlab代码
参考文献: [1]罗彬,陈永灿,刘昭伟等.梯级水光互补系统最大化可消纳电量期望短期优化调度模型[J].电力系统自动化,2023,47(10):66-75. 1.基本原理 1.1 目标函数 考虑光伏出力的不确定性,以梯级水光互补系统的可消纳电量期望最大为目标,函数…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...

第三幕 御酒掺土,江山为祭
金牌监制,您这一刀改得极其精准,直接把整部戏的格局从“江湖恩怨”拉升到了“家国博弈”的层面!确实,如果只谈慈悲,唐三藏只是个高僧;但如果加上李世民的重托和大唐的国运,他就是一个背负着沉重…...

Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能
Redis沙盒体验:在浏览器中零门槛掌握NoSQL核心技能 【免费下载链接】try.redis A demonstration of the Redis database. 项目地址: https://gitcode.com/gh_mirrors/tr/try.redis 当你第一次听说Redis时,是否被那些晦涩的技术术语吓退࿱…...

Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器
Onekey终极指南:如何5分钟快速获取Steam游戏清单的免费神器 【免费下载链接】Onekey Onekey Steam Depot Manifest Downloader 项目地址: https://gitcode.com/gh_mirrors/one/Onekey 还在为复杂的Steam游戏清单下载而头疼吗?想要备份游戏资源却不…...
:支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离)
Claude本地化部署终极方案(企业级容器化全栈手册):支持Anthropic API兼容、流式响应、模型热切换与RBAC权限隔离
更多请点击: https://codechina.net 第一章:Claude本地化部署的架构全景与企业级价值定位 Claude本地化部署并非简单地将模型权重下载后运行,而是一套融合推理引擎优化、安全沙箱隔离、API网关治理与可观测性集成的端到端架构体系。其核心目…...

长期使用Taotoken聚合服务对项目月度账单的可预测性提升
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用Taotoken聚合服务对项目月度账单的可预测性提升 在AI驱动的项目开发与运营中,成本控制与预算规划是团队管理者…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

【Lindy营销自动化工作流终极指南】:20年实战验证的7大反脆弱性设计原则,92%企业漏掉的关键衰减阈值
更多请点击: https://intelliparadigm.com 第一章:Lindy营销自动化工作流的基本范式与历史验证 Lindy效应指出,一个事物的预期剩余寿命与其当前年龄成正比——在营销自动化领域,Lindy范式体现为:经时间检验仍被广泛采…...

java项目011-ssm 宠物医院系统
java项目011-ssm 宠物医院系统 是一款基于springspringmvcmybatis的宠物系统, 包含界面布局、医生信息管理、客户信息管理、宠物管理、浏览管理、 诊断管理、医生管理、用户管理 其中医生管理、用户管理只能管理员有权限进行操作。 采用spingboot方式启动 运行截图...

告别手动预约:i茅台自动预约系统5分钟部署指南
告别手动预约:i茅台自动预约系统5分钟部署指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://gitcode…...