Kotlin基础(十):函数进阶
前言
本文主要讲解kotlin函数,之前系列文章中提到过函数,本文是kotlin函数的进阶内容。
Kotlin文章列表
Kotlin文章列表: 点击此处跳转查看
目录

1.1 函数基本用法
Kotlin 是一种现代的静态类型编程语言,它在函数的定义和使用上有一些特点。以下是 Kotlin 函数的基本用法:
-
函数的定义:
在 Kotlin 中,可以使用关键字fun来定义函数。函数定义的一般语法如下:fun functionName(parameters): returnType {// 函数体 }functionName是函数的名称,根据命名规范使用驼峰命名法。parameters是函数的参数列表,可以包含零个或多个参数。每个参数由参数名和参数类型组成,用逗号分隔。returnType是函数的返回类型,指定函数执行后返回的数据类型。如果函数不返回任何值,可以使用Unit类型或省略返回类型。
-
函数的调用:
定义函数后,可以通过函数名称和传递的参数来调用函数。调用函数时,传递的参数必须与函数定义中的参数类型和顺序相匹配。val result = functionName(argument1, argument2, ...) -
函数的返回值:
函数可以有返回值,返回值的类型在函数定义中指定。使用return关键字将结果返回给调用者。fun addNumbers(a: Int, b: Int): Int {return a + b }在上面的示例中,
addNumbers函数接收两个整数类型的参数并返回它们的和。 -
默认参数:
Kotlin 允许在函数定义中为参数设置默认值。这意味着在调用函数时可以省略具有默认值的参数。fun greet(name: String = "Guest") {println("Hello, $name!") }在上述示例中,
greet函数有一个默认参数name,如果调用时不提供参数,将使用默认值 “Guest”。 -
可变数量的参数:
Kotlin 支持可变数量的参数,也称为可变参数。在函数定义中,可以指定最后一个参数为可变参数,它可以接收零个或多个值。fun printNumbers(vararg numbers: Int) {for (number in numbers) {println(number)} }在上述示例中,
printNumbers函数接收可变数量的整数参数,并在循环中逐个打印出来。
这些是 Kotlin 函数的基本用法。除此之外,Kotlin 还支持高阶函数、扩展函数、Lambda 表达式等功能,可以进一步扩展函数的灵活性和表达能力。
1.2 使用中缀标记法调用函数
在 Kotlin 中,你可以使用中缀标记法(Infix Notation)来调用特定的函数。中缀标记法允许我们省略点和括号,并且可以更加简洁地调用某些特定类型的函数。为了能够使用中缀标记法,需要满足以下条件:
- 这个函数必须是一个成员函数或扩展函数。
- 这个函数必须只有一个参数。
- 这个函数必须使用
infix修饰符进行标记。
使用中缀标记法调用函数的语法如下:
infix fun ReceiverType.functionName(parameter: ParameterType): ReturnType {// 函数体
}
其中:
ReceiverType: 函数的接收者类型,可以是类的类型或者扩展函数的接收者类型。functionName: 函数的名称。ParameterType: 函数的参数类型。ReturnType: 函数的返回类型。函数体: 函数的实际逻辑操作。
在中缀标记法中,可以省略点和括号,并且可以更加直观地表达函数调用。以下是一个示例:
class Person(val name: String) {infix fun says(message: String) {println("$name says: $message")}
}fun main() {val person = Person("Alice")person says "Hello, Kotlin!" // 使用中缀标记法调用函数
}
在上面的例子中,我们定义了一个 Person 类,其中有一个 says 函数。由于这个函数使用了 infix 修饰符,并且只有一个参数,我们可以在调用时省略点和括号,直接使用中缀标记法来调用该函数。
输出结果为:
Alice says: Hello, Kotlin!
中缀标记法通常用于表示某种关联或操作,使得代码更加简洁易读。但要注意,不是所有的函数都适合使用中缀标记法,应该根据场景和语义来判断是否使用该特性。
1.3 单表达式函数
在 Kotlin 中,你可以使用可变参数(Variable Number of Arguments)来允许函数接受不定数量的参数。可变参数使得函数能够接受任意数量的相同类型的参数,而无需显式地定义一个数组或列表来传递参数。在函数定义中使用 vararg 关键字即可实现可变参数。
可变参数的语法如下:
fun functionName(vararg parameterName: Type): ReturnType {// 函数体
}
其中:
functionName: 函数的名称。parameterName: 可变参数的名称,它被声明为vararg类型,后面跟着参数类型Type。ReturnType: 函数的返回类型。函数体: 可变参数在函数体内可以当作数组来使用。
下面是一个简单的例子,演示了如何使用可变参数来计算一组数字的总和:
fun sum(vararg numbers: Int): Int {var total = 0for (number in numbers) {total += number}return total
}
你可以使用这个函数来传递任意数量的整数参数,它们将会被作为数组在函数体内处理,并返回它们的总和。例如:
val result1 = sum(1, 2, 3) // 结果为 6
val result2 = sum(10, 20, 30, 40, 50) // 结果为 150
val result3 = sum(5) // 结果为 5需要注意的是,可变参数只能在函数参数列表的末尾使用,并且在同一个函数中只能有一个可变参数。如果函数需要接受不同类型的参数或多个可变参数,可以使用命名参数或重载函数的方式来处理。
1.4 函数参数和返回值
1.4.1 可变参数
在 Kotlin 中,可变参数(Variable Number of Arguments)允许函数接受不定数量的相同类型参数。可变参数使得函数能够接受任意数量的参数,而无需事先指定参数的数量。在函数定义中使用 vararg 关键字即可实现可变参数。
可变参数的语法如下:
fun functionName(vararg parameterName: Type): ReturnType {// 函数体
}其中:
functionName: 函数的名称。parameterName: 可变参数的名称,它被声明为vararg类型,后面跟着参数类型Type。ReturnType: 函数的返回类型。函数体: 可变参数在函数体内可以当作数组来使用。
下面是一个简单的例子,演示了如何使用可变参数来计算一组数字的总和:
fun sum(vararg numbers: Int): Int {var total = 0for (number in numbers) {total += number}return total
}你可以使用这个函数来传递任意数量的整数参数,它们将会被作为数组在函数体内处理,并返回它们的总和。例如:
val result1 = sum(1, 2, 3) // 结果为 6
val result2 = sum(10, 20, 30, 40, 50) // 结果为 150
val result3 = sum(5) // 结果为 5需要注意的是,可变参数只能在函数参数列表的末尾使用,并且在同一个函数中只能有一个可变参数。如果函数需要接受不同类型的参数或多个可变参数,可以使用命名参数或重载函数的方式来处理。
1.4.2 返回值类型
在 Kotlin 中,函数的返回值类型用于指定函数在执行完毕后将会返回的值的类型。在函数定义中,通过在函数名称后使用冒号(:)来声明返回值类型。返回值类型可以是 Kotlin 中的任意类型,包括基本数据类型(如 Int、Boolean、Double 等)和自定义的类类型。
函数的返回值类型的语法如下:
fun functionName(parameters): ReturnType {// 函数体return value // 返回值必须与 ReturnType 类型相符
}其中:
functionName: 函数的名称。parameters: 函数的参数列表,如果没有参数则可以省略。ReturnType: 函数的返回值类型。函数体: 函数的实际逻辑操作。return value: 使用return关键字来返回一个与ReturnType类型相符的值。
以下是一些返回值类型的例子:
fun add(a: Int, b: Int): Int {return a + b
}fun isPositive(number: Int): Boolean {return number > 0
}fun greet(name: String): String {return "Hello, $name!"
}在上面的例子中:
add函数接收两个整数参数a和b,返回它们的和,因此返回值类型是Int。isPositive函数接收一个整数参数number,判断该数字是否为正数,返回布尔值,因此返回值类型是Boolean。greet函数接收一个字符串参数name,返回一个拼接了问候语的字符串,因此返回值类型是String。
如果函数体只有一个表达式,还可以使用单表达式函数的简写方式,如下所示:
fun add(a: Int, b: Int) = a + b
fun isPositive(number: Int) = number > 0
fun greet(name: String) = "Hello, $name!"在这种情况下,返回值类型会被自动推断出来,无需显式声明。
1.5 函数的范围
1.5.1 局部函数
在Kotlin中,局部函数是指在函数内部定义的函数。它们的作用范围仅限于包含它们的函数内部,无法从外部进行访问。局部函数通常用于将一些具体功能划分为更小的逻辑单元,提高代码的可读性和可维护性。
局部函数在生活中的一个例子是,在一个购物应用中,有一个函数用于计算订单的总价格。而在这个函数内部,你可能会定义一个局部函数来计算折扣金额,以便更好地组织代码。
下面是使用局部函数的步骤和示例代码:
fun calculateTotalPrice(items: List<Item>, discount: Double): Double {fun calculateDiscountedPrice(price: Double): Double {// 局部函数用于计算折扣后的价格return price * (1 - discount)}var totalPrice = 0.0for (item in items) {totalPrice += calculateDiscountedPrice(item.price)}return totalPrice
}在上面的示例中,calculateTotalPrice函数接受一个List类型的items参数和一个discount参数,它首先定义了一个局部函数calculateDiscountedPrice来计算折扣后的价格。然后,它遍历items列表,并将每个物品的折扣后价格累加到totalPrice变量中。最后,返回总价格。
这个例子中,局部函数calculateDiscountedPrice只在calculateTotalPrice函数内部可见,无法从外部进行访问。这种封装性使得代码更加清晰和可维护。
局部函数的底层原理是,它们在编译时被编译成包含外部函数的内部类或者静态方法。这样可以确保局部函数的作用范围仅限于外部函数内部。
局部函数的优点包括:
- 提高代码的可读性和可维护性:通过将复杂逻辑拆分为更小的逻辑单元,代码更易于理解和调试。
- 封装性:局部函数只在外部函数内部可见,可以避免污染外部命名空间,提高代码的安全性。
使用局部函数时需要注意以下几点:
- 局部函数只能在定义它们的函数内部调用,无法从外部访问。
- 局部函数不能被声明为顶层函数或类的成员函数。
局部函数适用于需要在一个函数内部封装一些具体功能的情况,尤其是这些功能只在该函数内部使用,并且不需要从外部进行访问。例如,计算总价、处理某个特定功能的逻辑等。
1.5.2 成员函数
在Kotlin中,成员函数是指定义在类或对象内部的函数。它们是与类或对象关联的函数,可以通过类或对象进行调用。成员函数用于封装特定功能,并可以访问类或对象的属性和其他成员。
成员函数在生活中的一个例子是,在一个学生类中,有一个函数用于计算学生的平均成绩。这个函数是类的一部分,它可以访问学生对象的成绩属性并进行计算。
下面是使用成员函数的步骤和示例代码:
class Student(val name: String) {private val scores = mutableListOf<Int>() // 学生成绩列表fun addScore(score: Int) {scores.add(score)}fun calculateAverageScore(): Double {var sum = 0for (score in scores) {sum += score}return sum.toDouble() / scores.size}
}fun main() {val student = Student("Alice")student.addScore(90)student.addScore(85)student.addScore(95)val averageScore = student.calculateAverageScore()println("Average score of ${student.name}: $averageScore")
}在上面的示例中,我们定义了一个Student类,它包含一个成员函数addScore用于向学生成绩列表中添加分数,并且还定义了一个成员函数calculateAverageScore用于计算平均分。在main函数中,我们创建了一个名为student的学生对象,添加了一些分数,并通过调用calculateAverageScore函数来计算平均分。
成员函数的底层原理是,它们被编译成与类或对象关联的普通函数,并且可以访问类或对象的成员变量和其他成员函数。
成员函数的优点包括:
- 封装性:成员函数可以访问类或对象的属性和其他成员,实现了相关功能的封装。
- 代码组织:成员函数将相关的功能组织在一起,提高了代码的可读性和可维护性。
使用成员函数时需要注意以下几点:
- 成员函数必须在类或对象内部进行定义。
- 成员函数可以访问类或对象的属性和其他成员。
成员函数适用于需要在类或对象内部封装特定功能的情况,特别是这些功能与类或对象的状态和属性密切相关。
1.6 泛型函数
1.6.1 泛型函数简介
在Kotlin中,泛型函数是指能够处理多种类型的函数。它们使用类型参数来表示可以灵活指定的类型,以便在函数内部进行通用的操作。泛型函数的作用是提高代码的重用性和灵活性。
下面是使用泛型函数的步骤和示例代码:
class Contact(val name: String, val phone: String)fun <T> findContactByName(contacts: List<T>, name: String): T? {for (contact in contacts) {if (contact is Contact && contact.name == name) {return contact}}return null
}fun main() {val contacts = listOf(Contact("Alice", "123456"),Contact("Bob", "789012"),Contact("Charlie", "345678"))val contact = findContactByName(contacts, "Bob")if (contact != null) {println("Phone number of ${contact.name}: ${contact.phone}")} else {println("Contact not found.")}
}在上面的示例中,我们定义了一个泛型函数findContactByName,它接受一个类型参数T和一个联系人列表contacts,以及一个要查找的姓名name。在函数内部,我们遍历联系人列表,并根据联系人的类型和姓名进行匹配查找。最后,返回匹配到的联系人或者null。
在main函数中,我们创建了一个联系人列表contacts,并通过调用findContactByName函数来查找姓名为"Bob"的联系人。如果找到了对应的联系人,则打印其姓名和电话号码;如果没有找到,则打印"Contact not found."。
泛型函数的底层原理是,在编译时会进行类型擦除,将泛型函数的代码生成为实际类型的函数。通过类型参数的擦除,可以在运行时处理不同类型的对象。
泛型函数的优点包括:
- 代码重用性:泛型函数可以适用于多种类型,提高了代码的重用性。
- 灵活性:泛型函数可以根据不同的类型进行通用操作,增加了代码的灵活性。
使用泛型函数时需要注意以下几点:
- 在泛型函数内部,对类型参数的操作受到一些限制,因为无法确定类型参数的具体类型。
- 需要在调用泛型函数时指定类型参数的具体类型。
泛型函数适用于需要在不同类型上执行相似操作的情况,特别是在代码中存在重复逻辑,并且需要处理不同类型的数据。
1.6.2 kotlin泛型函数在Android中使用
Kotlin 泛型函数在 Android 开发中非常常见,特别是在处理集合、列表、适配器等数据类型时。泛型函数能够让我们写出更通用和灵活的代码,使得在不同类型的数据上都能使用相同的逻辑。
以下是在 Android 中使用 Kotlin 泛型函数的一些常见场景:
- 在 RecyclerView 适配器中使用泛型函数:
class MyAdapter<T>(private val dataList: List<T>) : RecyclerView.Adapter<MyViewHolder<T>>() {override fun onCreateViewHolder(parent: ViewGroup, viewType: Int): MyViewHolder<T> {// 创建 ViewHolder}override fun onBindViewHolder(holder: MyViewHolder<T>, position: Int) {// 绑定数据到 ViewHolderval item = dataList[position]holder.bind(item)}override fun getItemCount(): Int {return dataList.size}
}class MyViewHolder<T>(private val itemView: View) : RecyclerView.ViewHolder(itemView) {fun bind(data: T) {// 绑定数据}
}
在这个例子中,我们定义了一个泛型适配器 MyAdapter,它能够适用于不同类型的数据列表。在 MyAdapter 中使用了泛型类型 T,它表示适配器可以接收任意类型的数据。同时,我们也定义了一个泛型 ViewHolder MyViewHolder,使得 ViewHolder 能够绑定不同类型的数据。
- 使用泛型函数处理集合数据:
fun <T> filterList(list: List<T>, predicate: (T) -> Boolean): List<T> {val filteredList = mutableListOf<T>()for (item in list) {if (predicate(item)) {filteredList.add(item)}}return filteredList
}// 使用泛型函数来过滤整数列表中的偶数
val numbers = listOf(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val evenNumbers = filterList(numbers) { it % 2 == 0 }在这个例子中,我们定义了一个泛型函数 filterList,它接收一个列表和一个谓词函数(predicate),然后返回满足谓词条件的新列表。通过这个泛型函数,我们可以方便地处理不同类型的数据列表,而无需写多个不同的过滤函数。
这只是在 Android 中使用 Kotlin 泛型函数的两个示例,实际上在 Android 开发中还有许多其他场景可以应用泛型函数。总的来说,泛型函数是一种非常有用的特性,它能够提高代码的灵活性和可重用性,使得我们能够更加优雅地处理不同类型的数据。
1.7 内联函数
在Kotlin中,内联函数是指在编译时将函数调用处的代码直接复制到调用处的位置,而不是通过函数调用的方式执行。内联函数的作用是减少函数调用的开销,提高代码的执行效率。
内联函数在生活中的一个例子是,在一个数学计算应用中,有一个函数用于计算两个数的平方和。这个函数可能会被频繁调用,如果每次调用都通过函数调用的方式执行,会带来一定的性能开销。而使用内联函数可以将函数体的代码直接复制到调用处,减少了函数调用的开销。
下面是使用内联函数的步骤和示例代码:
inline fun calculateSumOfSquares(a: Int, b: Int): Int {val squareA = a * aval squareB = b * breturn squareA + squareB
}fun main() {val result = calculateSumOfSquares(3, 4)println("Sum of squares: $result")
}在上面的示例中,我们定义了一个内联函数calculateSumOfSquares,它接受两个整数参数a和b,并计算它们的平方和。在函数调用处,编译器会将函数体的代码直接复制到调用处,而不是通过函数调用的方式执行。
在main函数中,我们调用了calculateSumOfSquares函数,并将结果打印出来。
内联函数的底层原理是,在编译时将函数调用处的代码直接复制到调用处的位置,避免了函数调用的开销。这样可以减少函数调用的开销,并提高代码的执行效率。
内联函数的优点包括:
- 减少函数调用开销:内联函数将函数调用处的代码直接复制到调用处,避免了函数调用的开销,提高了代码的执行效率。
- 灵活性:内联函数可以处理函数参数中的 lambda 表达式,并在调用处进行优化。
使用内联函数时需要注意以下几点:
- 内联函数可能会增加生成的字节码大小,因为代码会被复制到调用处,可能导致编译后的字节码变大。
- 内联函数不适用于函数体过大的情况,因为过大的函数体会导致生成的字节码过大,反而会降低性能。
内联函数适用于需要频繁调用的函数,并且函数体较小的情况。它可以减少函数调用的开销,提高代码的执行效率。
1.7.1 让Lambda表达式内联进函数
在Kotlin中,让Lambda表达式内联进函数是指在编译时将Lambda表达式的代码直接复制到函数调用处,而不是通过函数调用的方式执行Lambda表达式。这样可以减少Lambda表达式的函数调用开销,提高代码的执行效率。
下面是使用让Lambda表达式内联进函数的步骤和示例代码:
data class Student(val name: String, val score: Int)inline fun filterPassingStudents(students: List<Student>, predicate: (Student) -> Boolean): List<Student> {val passingStudents = mutableListOf<Student>()for (student in students) {if (predicate(student)) {passingStudents.add(student)}}return passingStudents
}fun main() {val students = listOf(Student("Alice", 80),Student("Bob", 90),Student("Charlie", 70))val passingStudents = filterPassingStudents(students) { it.score >= 75 }println("Passing students: $passingStudents")
}
在上面的示例中,我们定义了一个让Lambda表达式内联进函数的函数filterPassingStudents,它接受一个学生列表students和一个Lambda表达式predicate,用于判断学生是否及格。在函数调用处,编译器会将Lambda表达式的代码直接复制到调用处,而不是通过函数调用的方式执行。
在main函数中,我们创建了一个学生列表students,并通过调用filterPassingStudents函数来筛选出及格的学生。Lambda表达式{ it.score >= 75 }用于判断学生的分数是否大于等于75。最后,将筛选出的及格学生打印出来。
让Lambda表达式内联进函数的底层原理和优缺点与内联函数相似,即在编译时将Lambda表达式的代码直接复制到函数调用处,减少了函数调用的开销。优点包括提高代码执行效率,减少函数调用开销;缺点包括增加生成的字节码大小。使用时需要注意Lambda表达式的函数体大小,避免过大的函数体导致生成的字节码过大。
让Lambda表达式内联进函数适用于需要频繁调用的函数,并且Lambda表达式的函数体较小的情况。它可以减少Lambda表达式的函数调用开销,提高代码的执行效率。
1.7.2 内联部分Lambda表达式
在Kotlin中,内联部分Lambda表达式是指在函数调用时将Lambda表达式的一部分代码内联进函数,而将另一部分代码作为参数传递。这样可以减少部分Lambda表达式的函数调用开销,提高代码的执行效率。
下面是使用内联部分Lambda表达式的步骤和示例代码:
inline fun executeAsyncTask(crossinline task: () -> Unit, onComplete: () -> Unit) {// 执行异步任务// ...task() // 将任务的一部分代码内联进函数// ...onComplete() // 执行回调函数的另一部分代码
}fun main() {val task = {// 异步任务的代码println("Executing async task...")}val onComplete = {// 回调函数的代码println("Async task completed.")}executeAsyncTask(task, onComplete)
}
在上面的示例中,我们定义了一个内联部分Lambda表达式的函数executeAsyncTask,它接受一个任务的Lambda表达式task和一个完成回调的Lambda表达式onComplete。在函数内部,我们首先执行异步任务的一部分代码(即将task内联进函数),然后执行回调函数的另一部分代码(即onComplete)。
在main函数中,我们创建了一个任务的Lambda表达式task,其中包含异步任务的代码。我们还创建了一个完成回调的Lambda表达式onComplete,其中包含回调函数的代码。最后,我们调用executeAsyncTask函数,并将task和onComplete作为参数传递。
内联部分Lambda表达式的底层原理和优缺点与内联函数相似,即在编译时将Lambda表达式的一部分代码内联进函数。优点包括减少Lambda表达式的函数调用开销,提高代码执行效率;缺点包括增加生成的字节码大小。使用时需要注意Lambda表达式的函数体大小,避免过大的函数体导致生成的字节码过大。
内联部分Lambda表达式适用于需要频繁调用的函数,并且Lambda表达式的一部分代码较小的情况。它可以减少Lambda表达式的函数调用开销,提高代码的执行效率。
1.7.3 非局部返回(Non-localreturn)
在Kotlin中,内联函数非局部返回是指在内联函数中,可以使用return语句直接从内联函数外部返回,而不仅仅是从内联函数内部返回。这种特性允许在内联函数中进行非局部的控制流程操作,例如从调用内联函数的位置直接返回到调用者的位置。
下面是使用内联函数非局部返回的步骤和示例代码:
inline fun performOperation(numbers: List<Int>, operation: (Int) -> Boolean): Boolean {numbers.forEach {if (operation(it)) {return true // 使用非局部返回直接返回到调用者的位置}}return false
}fun main() {val numbers = listOf(1, 2, 3, 4, 5)val result = performOperation(numbers) {if (it == 3) {return@performOperation true // 使用标签限定返回到调用者的位置}false}println("Result: $result")
}在上面的示例中,我们定义了一个内联函数performOperation,它接受一个整数列表numbers和一个操作的Lambda表达式operation。在函数内部,我们使用forEach函数遍历列表中的每个元素,如果操作满足条件,则使用非局部返回直接返回到调用者的位置。
在main函数中,我们创建了一个整数列表numbers,并调用performOperation函数来查找是否存在满足条件的元素。在Lambda表达式中,我们使用return@performOperation标签限定了非局部返回的位置。如果列表中存在值为3的元素,则返回true,否则返回false。最后,将结果打印出来。
内联函数非局部返回的底层原理是在编译时通过内联将非局部返回的位置信息嵌入到代码中,使得在满足条件时直接返回到调用者的位置。这样可以减少不必要的迭代操作,提高代码执行效率。
内联函数非局部返回的优点是可以简化代码结构,避免额外的迭代操作,并提高代码执行效率。然而,过度使用非局部返回可能导致代码的可读性和维护性降低,因此需要谨慎使用。
使用内联函数非局部返回时需要注意以下几点:
- 使用标签限定返回的位置:在Lambda表达式中使用标签限定非局部返回的位置,确保返回到调用者的正确位置。
- 慎重使用:过度使用非局部返回可能导致代码难以理解和维护,只在需要提高代码执行效率时使用。
内联函数非局部返回适用于需要在内联函数中进行非局部控制流程操作的场景,例如在迭代操作中查找满足条件的元素并立即返回。
1.7.4 实体化的类型参数(Reifiedtypeparameter)
在Kotlin中,内联函数实体化的类型参数(reified type parameter)是指在内联函数中声明的类型参数,可以在运行时访问和操作其实际类型信息。这种特性使得我们可以在内联函数中使用类型参数进行具体的运行时操作,而不仅仅局限于编译时的类型擦除。
内联函数实体化的类型参数例子:在一个数据转换的应用中,有一个内联函数用于将一个类型的数据转换为另一个类型的数据。使用内联函数实体化的类型参数可以在函数内部获取和操作转换前后的实际类型信息。
下面是使用内联函数实体化的类型参数的步骤和示例代码:
inline fun <reified T> convertData(data: Any): T? {if (data is T) {return data // 返回转换后的数据}return null
}fun main() {val strData = "Hello, World!"val intData = 10val convertedStr = convertData<String>(strData)val convertedInt = convertData<Int>(intData)println("Converted String: $convertedStr")println("Converted Int: $convertedInt")
}在上面的示例中,我们定义了一个内联函数convertData,它接受一个任意类型的数据data和一个实体化的类型参数T。在函数内部,我们使用is操作符检查data是否是类型T的实例,如果是,则返回转换后的数据,否则返回null。
在main函数中,我们分别将一个字符串类型的数据strData和一个整数类型的数据intData传递给convertData函数,并指定要转换的目标类型为String和Int。然后,将转换后的结果打印出来。
内联函数实体化的类型参数的底层原理是在编译时通过内联将类型参数的实际类型信息嵌入到代码中,使得在运行时可以访问和操作该类型信息。这样可以实现在内联函数中对类型参数进行具体的运行时操作。
内联函数实体化的类型参数的优点是可以在内联函数内部访问和操作类型参数的实际类型信息,提供了更灵活的运行时操作。缺点是会增加编译后的代码大小。
在使用内联函数实体化的类型参数时,需要注意以下几点:
- 使用关键字
reified:在类型参数声明前使用reified关键字标记,表示要进行实体化的类型参数。 - 仅限于内联函数:内联函数实体化的类型参数只能用于内联函数中。
- 类型擦除的限制:内联函数实体化的类型参数只能获取和操作具体的非泛型类型信息,无法获取和操作泛型类型的实际类型信息。
内联函数实体化的类型参数适用于需要在内联函数中访问和操作类型参数的实际类型信息的场景,例如类型转换、类型检查等。
1.7.5 内联属性
在Kotlin中,内联函数的内联属性是指在内联函数中声明的属性,它们的访问器会在编译时直接嵌入到调用它们的地方,而不是通过函数调用的方式进行访问。这种特性可以提高代码的执行效率,减少函数调用的开销。
内联函数的内联属性的例子:在一个计算属性的应用中,有一个内联函数用于计算某个属性的值。使用内联属性可以直接在调用它的地方获取属性的值,而无需通过函数调用。
下面是使用内联函数的内联属性的步骤和示例代码:
inline class User(val name: String) {val formattedName: Stringget() = "Hello, $name" // 内联属性的访问器会在编译时嵌入到调用它的地方inline fun greet() {println(formattedName) // 直接访问内联属性,无需函数调用}
}fun main() {val user = User("Alice")user.greet()
}在上面的示例中,我们定义了一个内联类User,它有一个属性name和一个内联属性formattedName。在formattedName的访问器中,我们使用字符串模板将name格式化为一个问候语。在greet函数中,我们直接访问内联属性formattedName,无需通过函数调用。
在main函数中,我们创建了一个User对象,并调用greet函数打印问候语。
内联函数的内联属性的底层原理是在编译时将属性的访问器嵌入到调用它的地方,而不是通过函数调用的方式进行访问。这样可以减少函数调用的开销,提高代码的执行效率。
内联函数的内联属性的优点是可以减少函数调用的开销,提高代码的执行效率。缺点是会增加编译后的代码大小。
在使用内联函数的内联属性时,需要注意以下几点:
- 内联属性只能用于内联函数中:内联属性只能在内联函数内部声明和使用。
- 注意编译后的代码大小:内联属性会增加编译后的代码大小,因此在使用时需要权衡代码的执行效率和代码大小的关系。
内联函数的内联属性适用于需要在内联函数中声明和使用属性,并希望减少函数调用开销的场景。
1.7.6 kotlin内联函数在Android中使用
Kotlin 内联函数在 Android 开发中是一种常见的优化技术。内联函数在编译时会将函数调用处的代码拷贝到调用处,避免了函数调用的开销,从而提高了性能。这在 Android 中尤其有用,因为 Android 应用通常需要频繁调用许多小函数,内联函数能够在一定程度上减少函数调用带来的性能损耗。
在 Android 开发中,我们可以使用内联函数来优化高阶函数(Higher-order Functions)和 Lambda 表达式的调用。高阶函数和 Lambda 表达式通常涉及匿名函数的创建和调用,而这些匿名函数在运行时会导致额外的开销,内联函数能够帮助我们避免这些开销。
以下是一个在 Android 中使用内联函数的示例:
inline fun measureTime(block: () -> Unit) {val startTime = System.currentTimeMillis()block()val endTime = System.currentTimeMillis()val executionTime = endTime - startTimeLog.d("TAG", "Execution time: $executionTime milliseconds")
}// 在 Android 中调用内联函数
fun someExpensiveOperation() {measureTime {// 这里是一些耗时的操作for (i in 1..1000000) {// 一些计算或其他操作}}
}
在这个例子中,我们定义了一个内联函数 measureTime,它接收一个无参数的 Lambda 表达式作为参数。在 measureTime 函数内部,我们记录了 Lambda 表达式的执行时间,并将其打印出来。
然后,在 someExpensiveOperation 函数中,我们调用了 measureTime 内联函数,并在 Lambda 表达式中执行一些耗时的操作。由于 measureTime 是内联函数,函数调用的代码将会被拷贝到调用处,这样就避免了函数调用的开销,从而减少了性能损耗。
另外一个案例:假设你有一个应用程序,其中有一个用于执行网络请求的类 NetworkClient。在这个类中,你可能有一个通用的方法来执行网络请求,如下所示:
class NetworkClient {fun <T> makeRequest(url: String, onSuccess: (response: T) -> Unit, onError: (error: Throwable) -> Unit) {// 在这里执行网络请求,然后调用回调函数// 成功时调用 onSuccess,传递响应数据// 失败时调用 onError,传递错误信息}
}
在上面的代码中,makeRequest 方法是一个高阶函数,它接收一个 url 参数,以及两个回调函数 onSuccess 和 onError,用于处理网络请求成功和失败的情况。
如果你在应用程序的多个地方使用了这个网络请求方法,可能会导致在每次调用时都会创建匿名的 Lambda 表达式,从而产生额外的对象创建和函数调用的开销。为了优化性能,我们可以使用内联函数来避免这个问题。
首先,我们将 makeRequest 方法声明为内联函数:
inline fun <T> NetworkClient.makeRequest(url: String, crossinline onSuccess: (response: T) -> Unit, crossinline onError: (error: Throwable) -> Unit) {// 在这里执行网络请求,然后调用回调函数// 成功时调用 onSuccess,传递响应数据// 失败时调用 onError,传递错误信息
}
接着,我们使用 crossinline 修饰符来标记回调函数,以便在内联函数中使用它们。
现在,在应用程序中调用网络请求方法时,我们可以使用内联函数来优化性能:
val networkClient = NetworkClient()networkClient.makeRequest("https://example.com/data",onSuccess = { response ->// 处理成功响应},onError = { error ->// 处理错误情况}
)由于 makeRequest 方法是内联函数,Lambda 表达式中的代码将会被拷贝到调用处,避免了函数调用的开销。这样就提高了性能,同时保持了代码的简洁性和可读性。
1.8 高阶函数
1.8.1 高阶函数的简介
在 Kotlin 中,高阶函数(Higher-order Functions)是一种特殊的函数,它们可以接收一个或多个函数作为参数,也可以返回一个函数。高阶函数使得函数可以像其他类型的值一样被传递和操作,从而使代码更加灵活和简洁。
在 Kotlin 中,我们可以使用 lambda 表达式来表示函数,并将其作为参数传递给高阶函数。高阶函数的声明和使用方式与普通函数类似,只是在函数的参数或返回值中包含了函数类型。
以下是一个简单的示例,展示了如何定义和使用一个高阶函数:
// 高阶函数,接收一个函数作为参数,并执行该函数
fun calculate(a: Int, b: Int, operation: (Int, Int) -> Int): Int {return operation(a, b)
}// Lambda 表达式,表示一个加法操作
val add: (Int, Int) -> Int = { x, y -> x + y }// Lambda 表达式,表示一个乘法操作
val multiply: (Int, Int) -> Int = { x, y -> x * y }fun main() {val resultAdd = calculate(10, 5, add) // 调用高阶函数,执行加法操作,结果为 15val resultMultiply = calculate(10, 5, multiply) // 调用高阶函数,执行乘法操作,结果为 50println("Addition result: $resultAdd")println("Multiplication result: $resultMultiply")
}在上面的示例中,我们定义了一个高阶函数 calculate,它接收两个整数 a 和 b,还有一个函数参数 operation,该参数表示一个接收两个整数并返回一个整数的函数。在 calculate 函数中,我们将 operation 参数作为函数调用,传递实际的计算操作。
然后,我们定义了两个 lambda 表达式 add 和 multiply,分别表示加法和乘法操作。最后,在 main 函数中,我们调用了 calculate 高阶函数,并传递了 add 和 multiply lambda 表达式作为参数,执行了不同的计算操作。
通过高阶函数和 lambda 表达式的组合,我们可以编写更具表达力和灵活性的代码,从而使得 Kotlin 中的函数更加强大和易于使用。在 Android 开发中,高阶函数常用于处理集合数据、异步操作和回调处理等场景。
1.8.2 kotlin高阶函数在Android中的使用
在 Android 开发中,Kotlin 高阶函数被广泛用于处理异步操作、集合数据以及 UI 事件的回调处理等场景。使用高阶函数可以使代码更加简洁、灵活,并提高代码的可读性和维护性。下面列举几个在 Android 中使用 Kotlin 高阶函数的常见情况:
- 异步操作和回调处理:
在 Android 开发中,经常需要进行异步操作,比如网络请求或数据库查询。通常我们使用回调方式来处理异步操作的结果。使用高阶函数,可以简化回调的处理过程。
fun doAsyncOperation(callback: (result: String) -> Unit) {// 模拟异步操作,这里使用延迟 2 秒模拟耗时操作Handler(Looper.getMainLooper()).postDelayed({callback("Async operation result")}, 2000)
}// 在 Activity 中调用异步操作并处理结果
fun performAsyncOperation() {doAsyncOperation { result ->// 处理异步操作的结果textView.text = result}
}
在上面的例子中,doAsyncOperation 是一个模拟异步操作的高阶函数,它接收一个回调函数 callback,在操作完成后通过该回调函数传递结果。在 performAsyncOperation 方法中,我们调用 doAsyncOperation 并传递一个 lambda 表达式作为回调处理结果。
- 集合数据的处理:
在 Android 中,经常需要对集合数据进行过滤、映射、排序等操作。使用高阶函数可以使这些操作更加简洁和优雅。
data class Item(val name: String, val price: Double)// 过滤价格大于 50 的商品
fun filterExpensiveItems(items: List<Item>): List<Item> {return items.filter { it.price > 50 }
}// 映射商品列表为商品名称列表
fun mapItemNames(items: List<Item>): List<String> {return items.map { it.name }
}// 对商品列表按价格进行排序
fun sortItemsByPrice(items: List<Item>): List<Item> {return items.sortedBy { it.price }
}// 在 Activity 中使用高阶函数处理商品列表
val itemList = listOf(Item("Item1", 30.0), Item("Item2", 60.0), Item("Item3", 40.0))val expensiveItems = filterExpensiveItems(itemList)
val itemNames = mapItemNames(itemList)
val sortedItems = sortItemsByPrice(itemList)
在上面的例子中,我们定义了几个高阶函数来处理商品列表。filterExpensiveItems 函数过滤价格大于 50 的商品,mapItemNames 函数映射商品列表为商品名称列表,sortItemsByPrice 函数对商品列表按价格进行排序。在 Activity 中,我们可以直接调用这些高阶函数来处理商品列表。
- 线程切换和异步任务管理:
在 Android 中,经常需要在主线程和后台线程之间切换,以及管理多个异步任务的执行。使用高阶函数可以简化线程切换和异步任务管理的操作。
// 将代码块在主线程执行
fun runOnUiThread(action: () -> Unit) {Handler(Looper.getMainLooper()).post {action()}
}// 在后台线程执行代码块
fun runOnBackgroundThread(action: () -> Unit) {Thread {action()}.start()
}// 在 Activity 中使用高阶函数进行线程切换
runOnBackgroundThread {// 在后台线程执行耗时操作// ...// 切换回主线程更新 UIrunOnUiThread {textView.text = "Task completed"}
}
在上面的例子中,我们定义了两个高阶函数 runOnUiThread 和 runOnBackgroundThread,用于在主线程和后台线程执行代码块。在 Activity 中,我们可以使用这些高阶函数来简化线程切换的操作。
相关文章:
Kotlin基础(十):函数进阶
前言 本文主要讲解kotlin函数,之前系列文章中提到过函数,本文是kotlin函数的进阶内容。 Kotlin文章列表 Kotlin文章列表: 点击此处跳转查看 目录 1.1 函数基本用法 Kotlin 是一种现代的静态类型编程语言,它在函数的定义和使用上有一些特点…...

计算机视觉(四)神经网络与典型的机器学习步骤
文章目录 神经网络生物神经元人工神经元激活函数导数 人工神经网络“层”的通俗理解 前馈神经网络Delta学习规则前馈神经网络的目标函数梯度下降输出层权重改变量 误差方向传播算法误差传播迭代公式简单的BP算例随机梯度下降(SGD)Mini-batch Gradient De…...
使用easyui的tree组件实现给角色快捷分配权限功能
这篇文章主要介绍怎么实现角色权限的快捷分配功能,不需要像大多数项目的授权一样,使用类似穿梭框的组件来授权。 具体实现:通过菜单树的勾选和取消勾选来给角色分配权限,在这之前,需要得到角色的菜单树,角色…...

Postman打不开/黄屏/一直转圈/Windows
环境背景 内网环境Postman-win64-8.11.1-Setup.exe 问题描述 电脑重启后,打开Postman后,出现加载弹窗:Preparing your workspaces…This might take a few minutes; 等待数分钟后,还是没有反应,于是关闭…...

使用SVM模型完成分类任务
SVM,即支持向量机(Support Vector Machine),是一种常见的机器学习算法,用于分类和回归分析。SVM的基本思想是将数据集映射到高维空间中,在该空间中找到一个最优的超平面,将不同类别的数据点分开…...

计算机毕设 深度学习实现行人重识别 - python opencv yolo Reid
文章目录 0 前言1 课题背景2 效果展示3 行人检测4 行人重识别5 其他工具6 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉…...

开发经验分享之:import引入包和@Autowired注入类有什么区别
大家好,我是三叔,很高兴这期又和大家见面了,一个奋斗在互联网的打工人。 import 和 Autowired 想必大家在 Java 开发中使用频率最多的关键字之一了把,这篇博客将解释这两个概念的区别和作用,帮助你更好地理解它们在Ja…...

MySQL和Oracle区别
由于SQL Server不常用,所以这里只针对MySQL数据库和Oracle数据库的区别 (1) 对事务的提交 MySQL默认是自动提交,而Oracle默认不自动提交,需要用户手动提交,需要在写commit;指令或者点击commit按钮 (2) 分页查询 MySQL是直接在SQL…...

QT--day6(人脸识别、图像处理)
人脸识别: /***********************************************************************************头文件****************************************************************************************/#ifndef WIDGET_H #define WIDGET_H#include <QWidget>…...

深度学习:常用优化器Optimizer简介
深度学习:常用优化器Optimizer简介 随机梯度下降SGD带动量的随机梯度下降SGD-MomentumSGDWAdamAdamW 随机梯度下降SGD 梯度下降算法是使权重参数沿着整个训练集的梯度方向下降,但往往深度学习的训练集规模很大,计算整个训练集的梯度需要很大…...

【算法心得】二维dp的状态转移狂练
LCS: LCS变式:使两个字符串变成一样的,删除的和最小 https://leetcode.cn/problems/minimum-ascii-delete-sum-for-two-strings/ 建表 m ∗ n m*n m∗n or ( m 1 ) ∗ ( n 1 ) (m1)*(n1) (m1)∗(n1)? 感觉 ( m 1 ) ∗ ( n …...
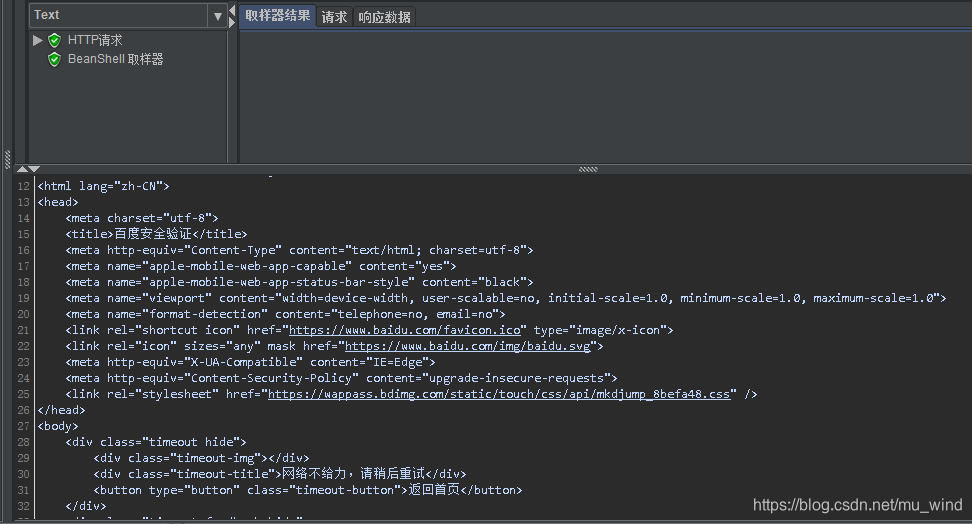
JMeter常用内置对象:vars、ctx、prev
在前文 Beanshell Sampler 与 Beanshell 断言 中,初步阐述了JMeter beanshell的使用,接下来归集整理了JMeter beanshell 中常用的内置对象及其使用。 注:示例使用JMeter版本为5.1 1. vars 如 API 文档 所言,这是定义变量的类&a…...
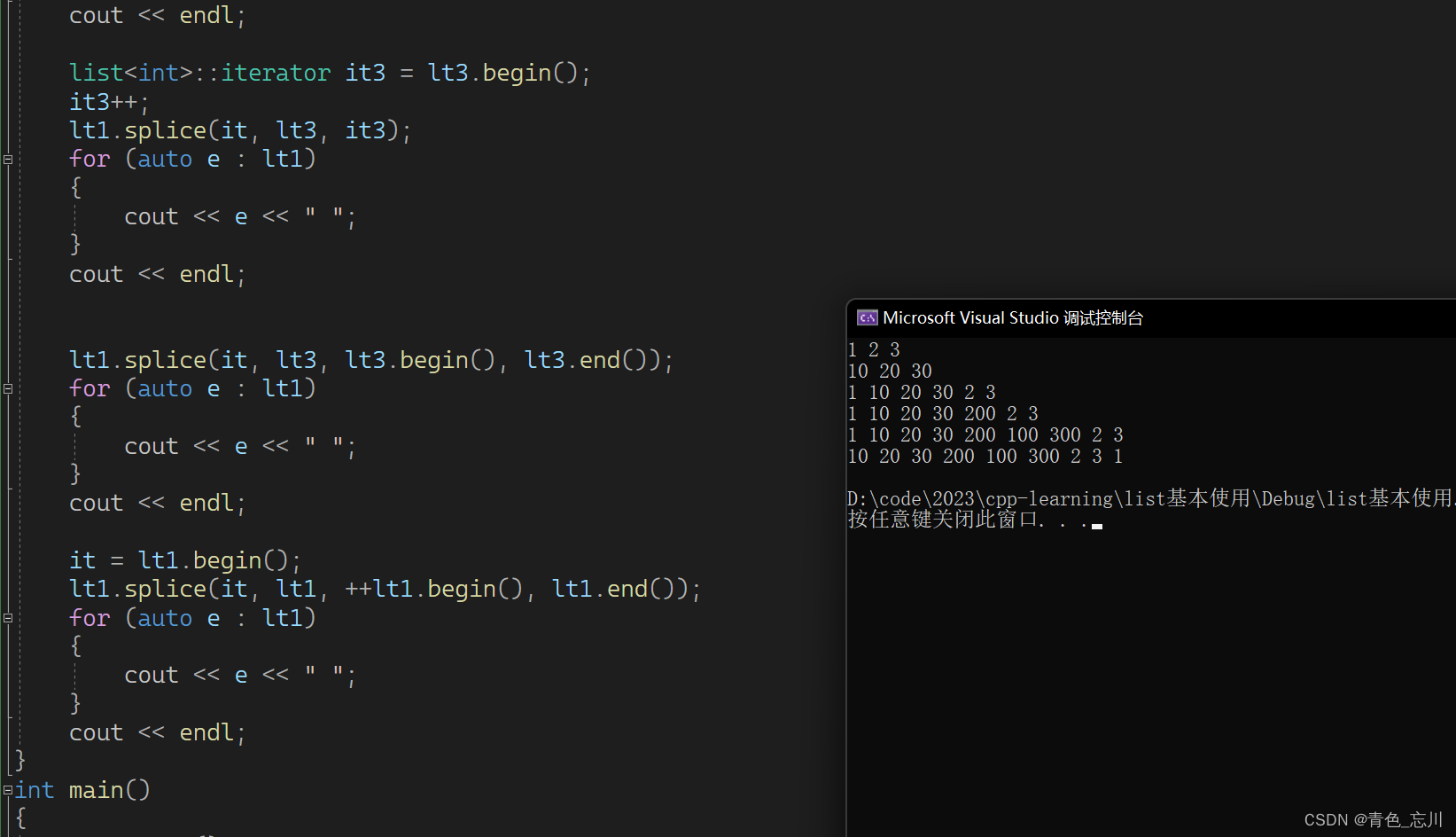
【C++从0到王者】第十四站:list基本使用及其介绍
文章目录 一、list基本介绍二、list基本使用1.尾插头插接口使用2.insert接口使用3.查找某个值所在的位置4.erase接口使用以及迭代器失效5.reverse6.sort7.merge8.unique9.remove11.splice 三、list基本使用完整代码 一、list基本介绍 如下所示,是库里面对list的基本…...

正则表达式、常用的正则
文章目录 正则表达式字符含意义RegExp函数RegExp属性RegExp对象方法RegExp构造函数的第二个参数 常用的正则例子只包含数字(包括正数、负数、零)只包含中英文数字及键盘上的特殊字符校验密码是否符合规则的正则校验http或者https端口号的正则只校验端口号…...
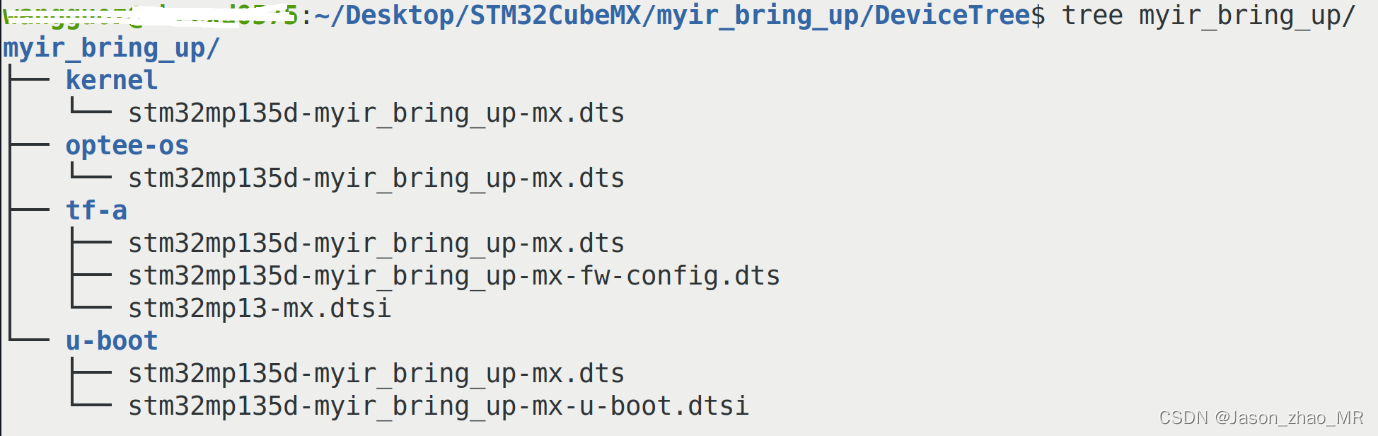
ST官方基于米尔STM32MP135开发板培训课程(一)
本文将以Myirtech的MYD-YF13X以及STM32MP135F-DK为例,讲解如何使用STM32CubeMX结合Developer package实现最小系统启动。 1.开发准备 1.1 Developer package准备 a.Developer package下载: https://www.st.com/en/embedded-software/stm32mp1dev.ht…...
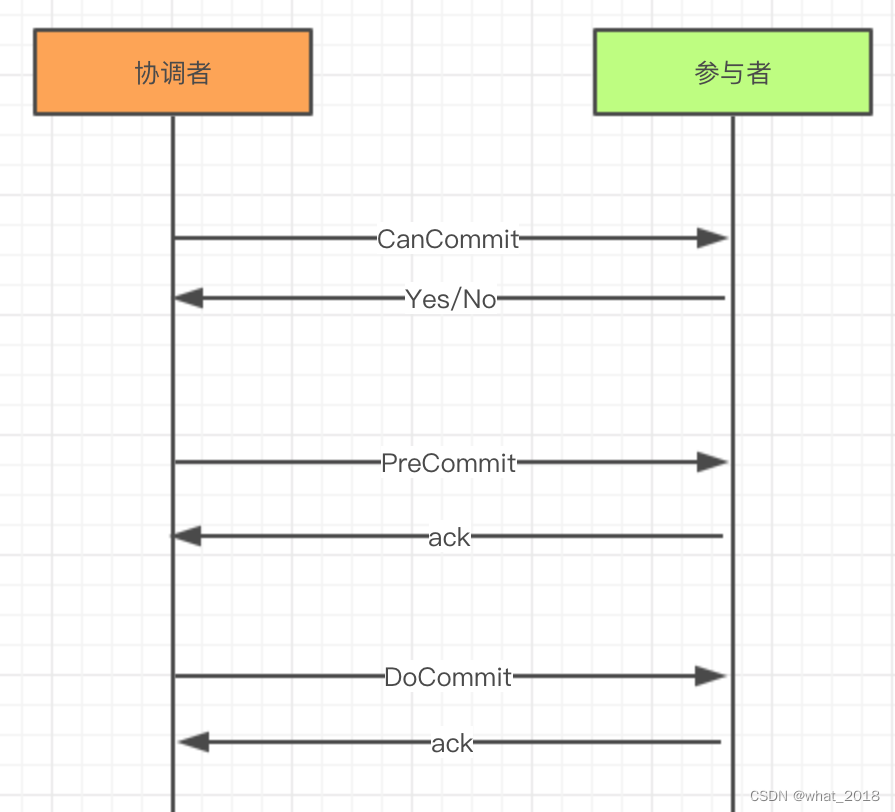
组件(lvs,keeplive,orm,mysql,分布式事务)
lvs LVS 已经集成到Linux内核系统中,ipvsadm 是 LVS 的命令行管理工具。 目前有三种 IP 负载均衡技术( VS/NAT 网络地址转换 、VS/TUN IP 隧道技术实现虚拟服务器 和 VS/DR 直接路由); 八种调度算法:轮询 …...

《视觉SLAM十四讲》报错信息和解决方案
文章目录 ch4-Sophus编译报错ch5/imageBasics安装opencv4.x报错ch5/joinMap/CMakeLists.txt编译报错ch5/joinMap-pcl_viewer map.pcd报错 ch4-Sophus编译报错 报错信息: error: lvalue required as left operand of assignmentunit_complex_.real() 1.;^~ error:…...

golang 设置http请求代理
tinypoxy 搭建http代理服务可参考:tinyproxy搭建http代理_wangxiaoangg的博客-CSDN博客 需求背景: 项目需要访问一国外服务接口,地址被墙。购买香港ecs服务器,并在上面搭建http代理服务。 一 使用http和https代理 func main() {pr…...
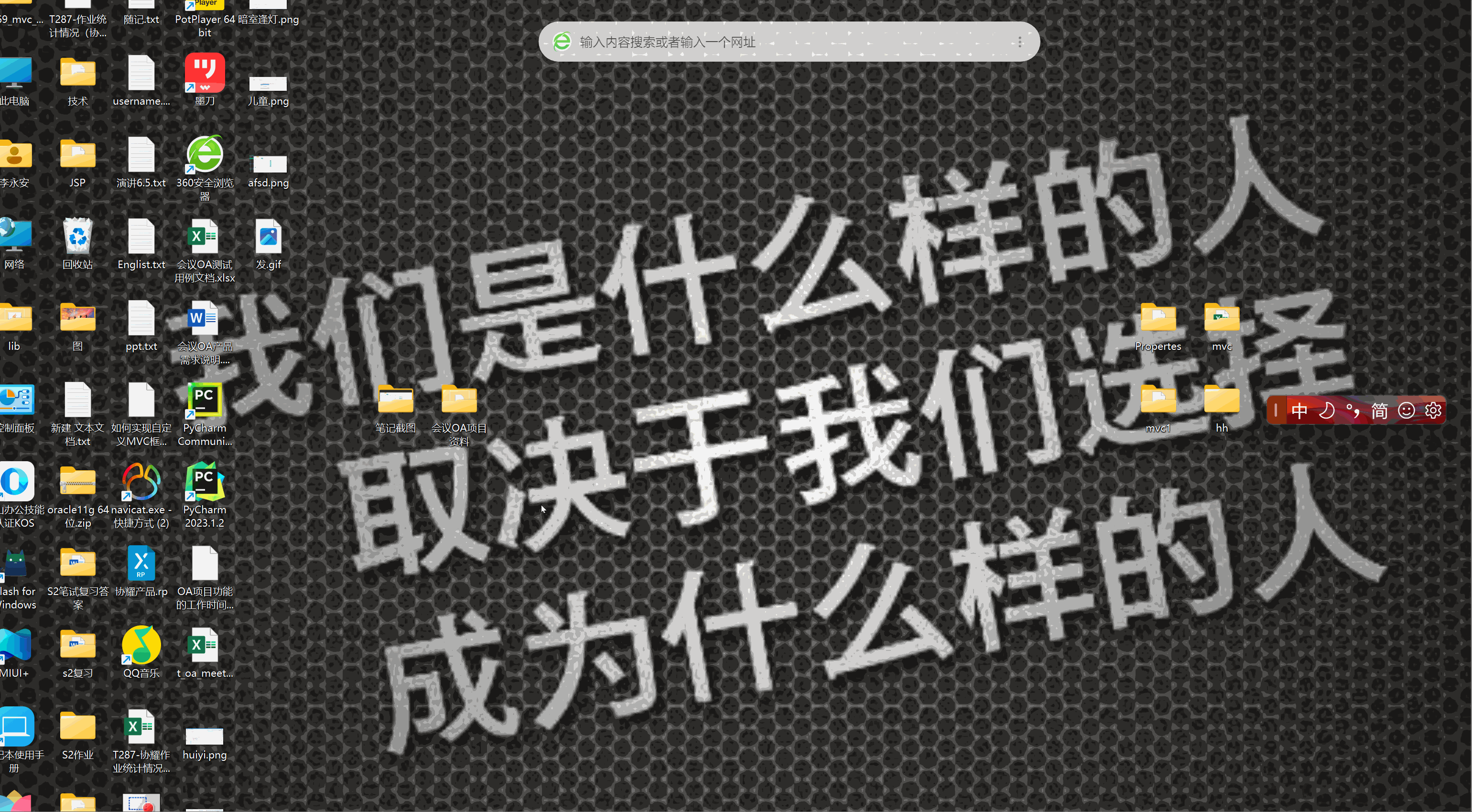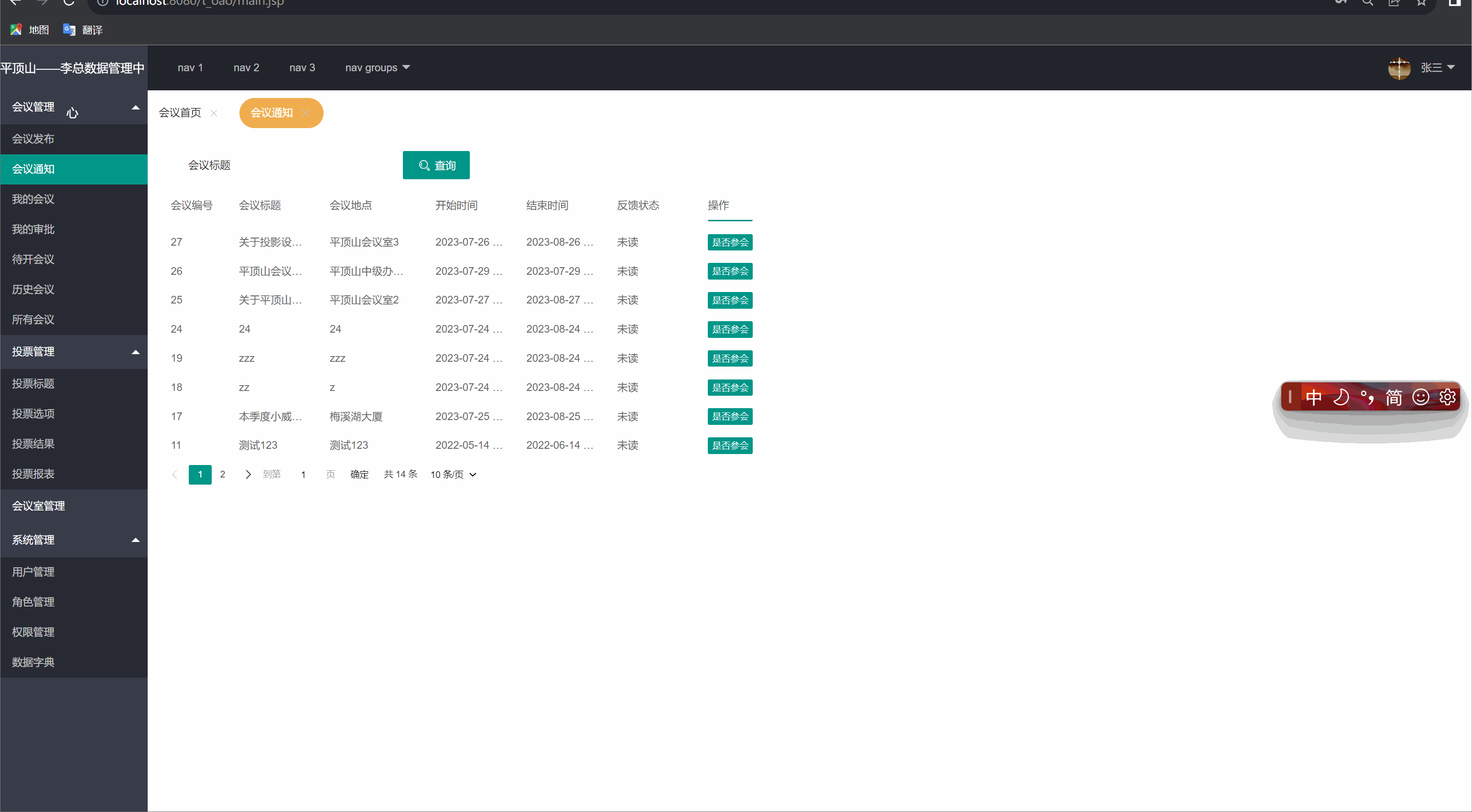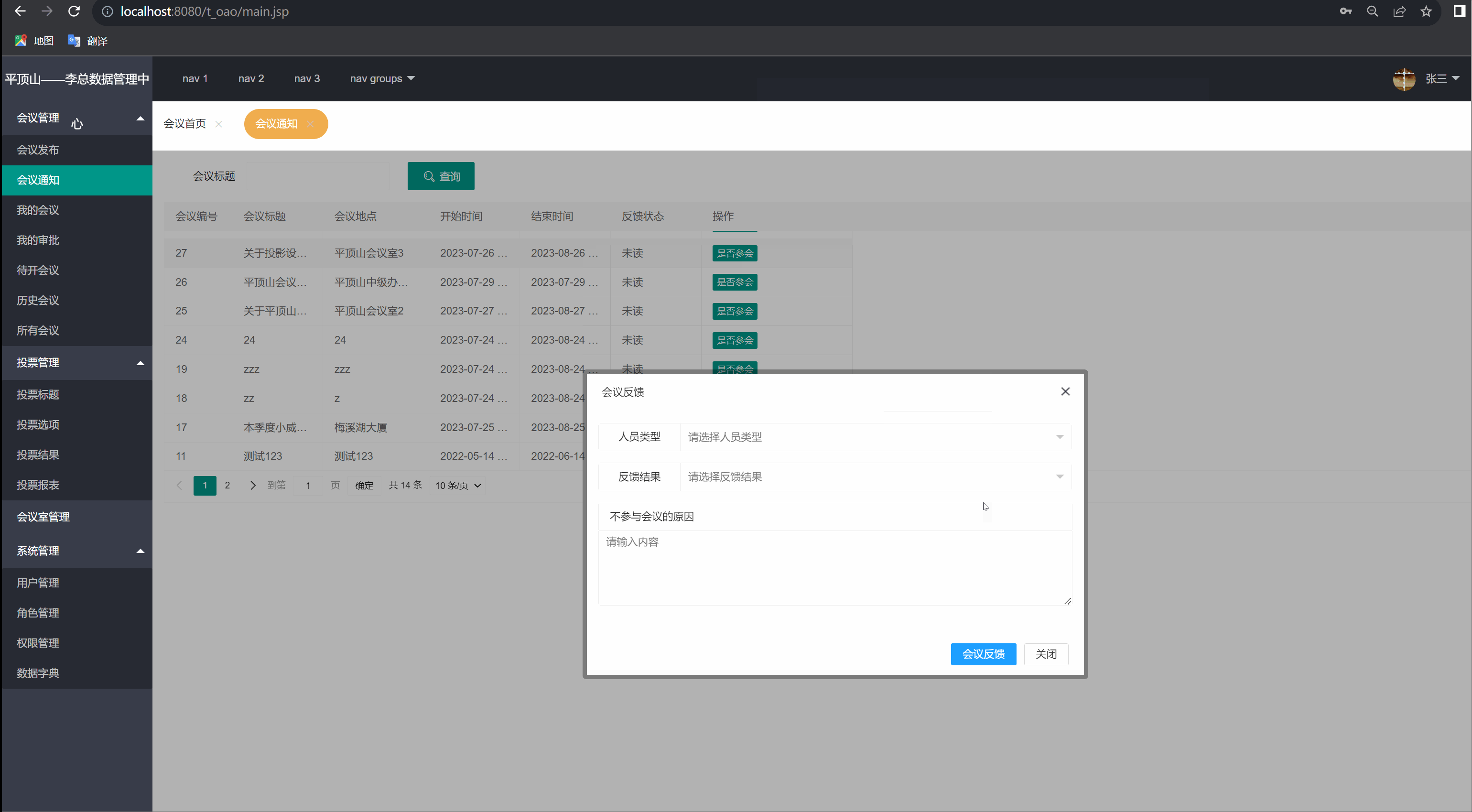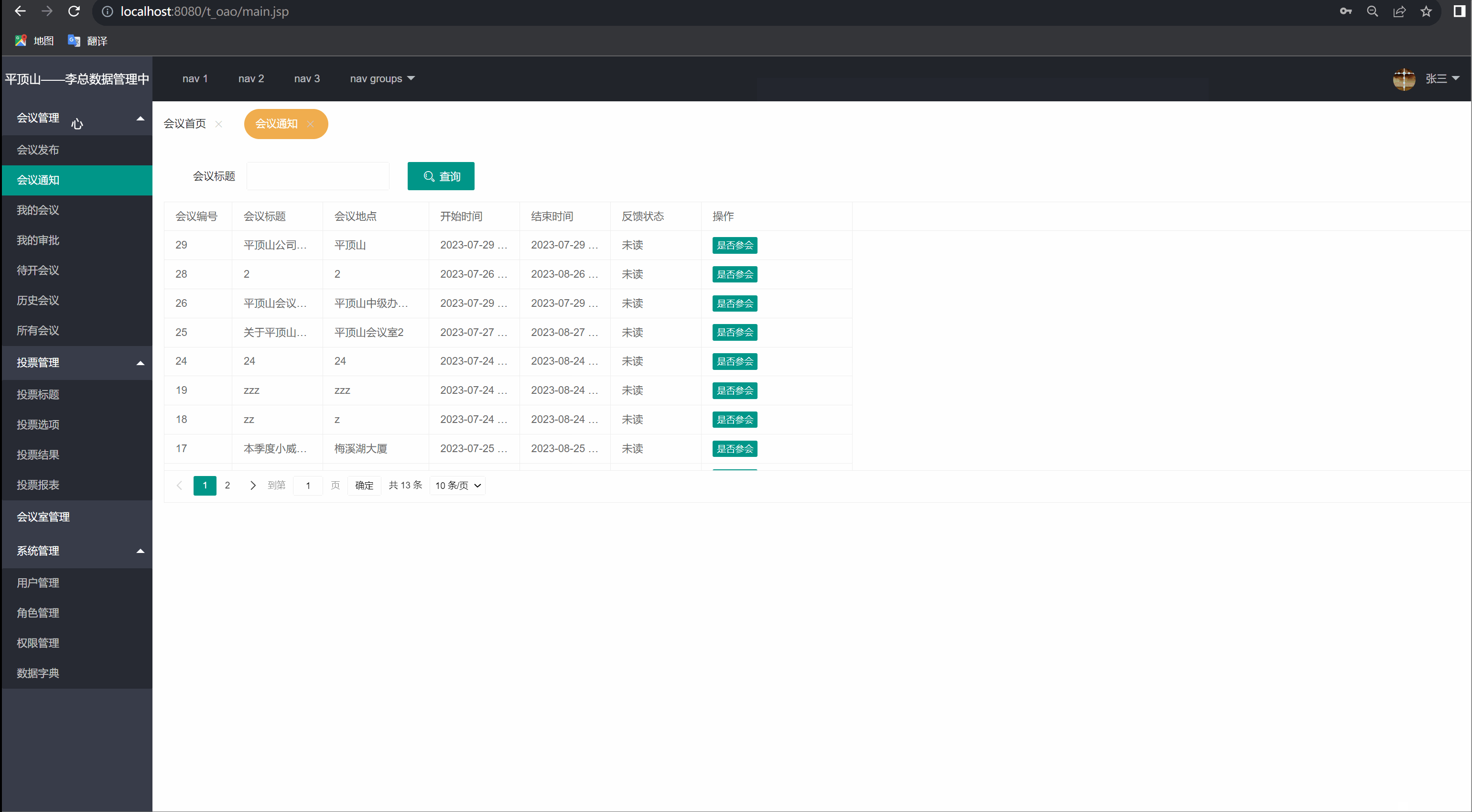
我的会议(会议通知)
前言: 我们在实现了发布会议功能,我的会议功能的基础上,继续来实现会议通知的功能。 4.1实现的特色功能: 当有会议要参加时,通过查询会议通知可以知道会议的内容,以及当前会议状态(未读) 4.2思路…...

css实现水平居中
代码示例 <div class"box"><div class"box1"></div> </div>1.弹性布局:(推荐) display:flex; 这些要添加在父级的,是父级的属性 //父级添加display:flex; //父级添加jus…...

米尔RK3576开发板评测:工业AI与边缘计算的性能甜点方案
1. 项目概述:当RK3576遇上米尔开发板,工业AI的新选择最近在嵌入式圈子里,瑞芯微的RK3576这颗SoC讨论热度挺高。作为一枚常年混迹在工控、边缘计算和AIoT项目里的老工程师,我对这类新平台的发布总是格外敏感。米尔电子作为国内老牌…...

Android应用安全左移实践:Kiuwan SAST集成与漏洞修复指南
1. 项目概述:为什么Android应用安全需要“左移”?在移动应用开发这个行当里干了十几年,我见过太多团队在安全问题上“亡羊补牢”的场景。往往是应用上线后,被安全团队或第三方扫描工具揪出一堆高危漏洞,然后整个团队进…...

使用VSCode无法登录Codex解决方法
登录时提示:Token exchange failed: token endpoint returned status 403 Forbidden: Country, region, or territory not supported确保魔法工具的连接模式是支持应用的,有的是只支持网站,切换成支持应用模式即可解决此问题。...

异步复位同步释放:数字电路设计的核心技巧与工程实践
1. 项目概述:一个看似简单却暗藏玄机的设计技巧在数字电路设计,尤其是FPGA和ASIC开发中,复位信号的处理是确保系统从确定状态启动和稳定运行的第一道,也是最重要的一道防线。我们经常听到“异步复位,同步释放”这个设计…...

书匠策AI官网www.shujiangce.com:期刊论文从“渡劫“到“躺赢“,中间只差这一个工具
家人们,今天不讲课,今天带你们"开箱"一个我私藏很久的论文神器。 先说结论——书匠策AI( 官网直达:www.shujiangce.com) 的期刊论文功能,是我今年用过最"懂科研人"的AI工具ÿ…...

3步完成Android Studio中文界面配置:告别英文困扰,提升开发效率
3步完成Android Studio中文界面配置:告别英文困扰,提升开发效率 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack…...

如何在Mac上免费一键解锁CrossOver游戏兼容性:CXPatcher完全指南
如何在Mac上免费一键解锁CrossOver游戏兼容性:CXPatcher完全指南 【免费下载链接】CXPatcher A patcher to upgrade Crossover dependencies and improve compatibility 项目地址: https://gitcode.com/gh_mirrors/cx/CXPatcher 想在Mac上流畅运行Windows游戏…...

从芯片选型到PCB布线:手把手拆解基于Zynq-7100的10Gbps雷达数据采集卡硬件设计
从芯片选型到PCB布线:Zynq-7100雷达数据采集卡硬件设计实战 在高速数据采集领域,10Gbps量级的实时信号处理对硬件设计提出了严苛挑战。当我们面对雷达回波、医学影像或工业检测等场景时,传统采集方案往往在吞吐量、延迟和同步精度上捉襟见肘。…...

3步零编程定制你的Windows系统:Windhawk终极指南
3步零编程定制你的Windows系统:Windhawk终极指南 【免费下载链接】windhawk The customization marketplace for Windows programs: https://windhawk.net/ 项目地址: https://gitcode.com/gh_mirrors/wi/windhawk 想要个性化Windows界面却不懂编程ÿ…...

syncpack 迁移指南:从 v13 到 v14 的完整步骤与注意事项
syncpack 迁移指南:从 v13 到 v14 的完整步骤与注意事项 【免费下载链接】syncpack Consistent dependency versions in large JavaScript Monorepos. 项目地址: https://gitcode.com/gh_mirrors/sy/syncpack syncpack 是一款专为大型 JavaScript Monorepo 设…...