探索 GPTCache|GPT-4 将开启多模态 AI 时代,GPTCache + Milvus 带来省钱秘籍

世界正处于数字化的浪潮中,为了更好理解和分析大量数据,人们对于人工智能(AI)解决方案的需求呈爆炸式增长。
此前,OpenAI 推出基于 GPT-3.5 模型的智能对话机器人 ChatGPT,在自然语言处理(NLP)领域掀起了新一轮的技术革命,引发了大家对大语言模型(LLM)的关注。同时,越来越多人希望使用大模型处理多模态数据,大家对于更高级的大型 AI 模型的呼声越来越高。
根据 OpenAI 发布的信息,科技界万众期待的 GPT-4 模型支持视觉输入,能够实现更强大的功能,将 GPT-4(https://openai.com/gpt-4) 与图像生成模型相结合可发挥巨大潜力。为了帮助大家更好地为这场科技革命做好准备,Zilliz 隆重推出 GPTCache——基于 Milvus 向量数据库的语义缓存,旨在帮助企业在搭建创新型多模态 AI 应用过程中降本增效。
多模态 AI 应用通过整合多种感知和通信模式,例如语音、视觉、语言和手势等,能够更智能地理解人类交互和环境,从而生成更准确细致的响应。多模态 AI 应用领域和行业包括:医疗保健、教育、娱乐、交通等,具体应用场景包括:Siri 和 Alexa 等虚拟助手、自动驾驶汽车、分析医学图像和患者数据的医疗诊断工具等。
本文将深入介绍 GPTCache,并探讨如何使用 GPTCache 与 Milvus 提供更好的多模态场景用户体验。

01.
多模态 AI 应用的语义缓存
在大多数情况下,实现多模态 AI 应用需要使用大模型。但是处理和调用模型耗时耗钱,这时候我们就可以使用 GPTCache:在请求大模型之前,先尝试在缓存中寻找答案。GPTCache 能够加速整个问答过程,并有助于降低运行大模型时的成本。
探索 GPTCache 语义缓存
语义缓存以结构化的方式存储和检索特定语义信息、概念和知识,使用语义缓存可以帮助 AI 系统更好理解和响应查询或请求。语义缓存的使用原理就是在缓存中预先获取常见或历史问题的答案。这样一来,信息访问会更快速,也有助于提高 AI 应用的性能和效率。
GPTCache 项目专为大模型相关的应用开发,可减少大模型的请求次数和响应时间,从而降低开销和提高效率。GPTCache 是基于语义缓存的理念设计的,用于存储历史提问和对应的模型回复,同时还接入了 Milvus 用于相似向量检索。GPTCache 包含以下几个重要组件:
LLM 适配器:负责确保 GPTCache 能够与各种大模型无缝协作。
上下文管理器:使系统能够在不同阶段灵活处理各种数据。
向量生成器:将数据转换为向量,以便支持更高效的数据存储和语义搜索。
缓存管理器:存储所有向量和其他有价值的数据。其中,Milvus 不仅能够支持大规模数据的存储,还有助于加速和提高向量相似性搜索的性能。
相似度评估器:负责评估从缓存中检索获得的潜在答案是否能够满足用户需求。
预处理器及后置处理器:帮助处理输入或输出的数据。
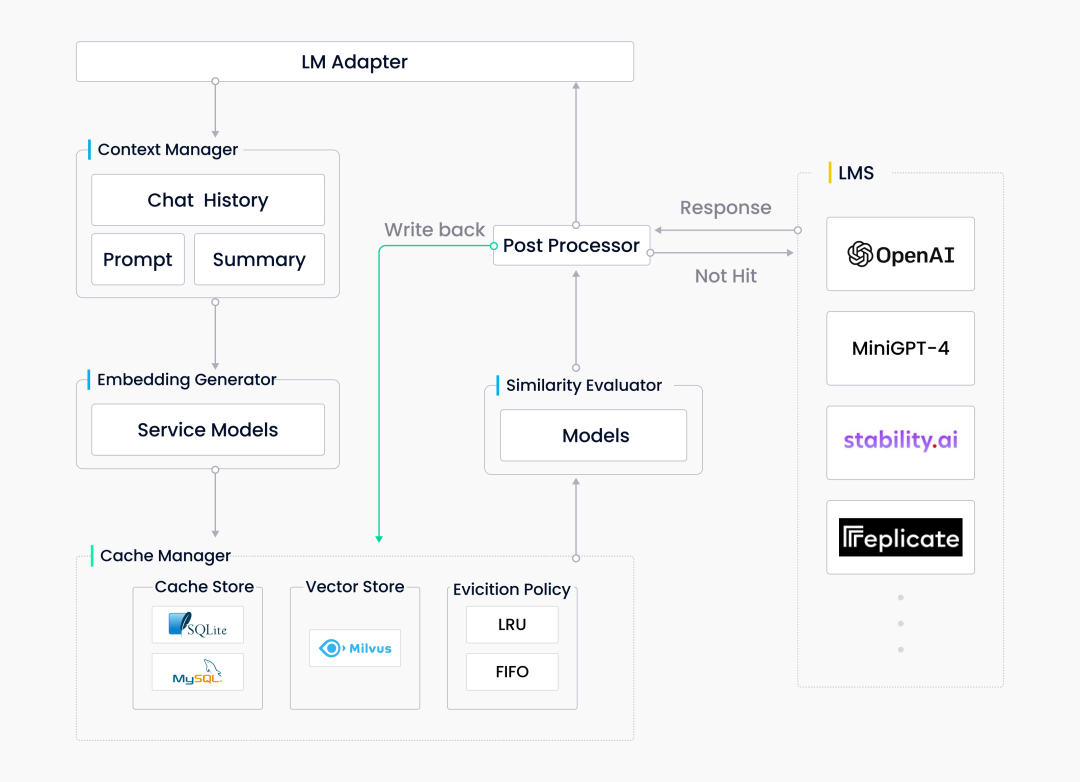
GPTCache 架构
以下代码片段展示了如何在 GPTCache 中配置不同模块和初始化缓存。
from gptcache import cache
from gptcache.manager import get_data_manager, CacheBase, VectorBase, ObjectBase
from gptcache.processor.pre import get_prompt
from gptcache.processor.post import temperature_softmax
from gptcache.embedding import Onnx
from gptcache.similarity_evaluation.distance import SearchDistanceEvaluationonnx = Onnx()
cache_base = CacheBase('sqlite')
vector_base = VectorBase('milvus',host='localhost',port='19530',dimension=onnx.dimension)
object_base = ObjectBase('local', path='./objects')
data_manager = get_data_manager(cache_base, vector_base, object_base)cache.init(pre_embedding_func=get_prompt, # Pre-processembedding_func=onnx.to_embeddings, # Embedding generatordata_manager=data_manager, # Cache managersimilarity_evaluation=SearchDistanceEvaluation() # Evaluatorpost_process_messages_func=temperature_softmax # Post-process)使用向量数据库缓存语义数据
语义缓存中最重要的组成部分就是向量数据库。具体而言,GPTCache 的向量生成器将数据转换为 向量以进行向量存储和语义搜索。向量数据库(如:Milvus)不仅支持大规模数据存储,还有助于加速和提高向量相似性检索的性能。
预训练的多模态模型通过学习,能够在同一特征空间中以向量的形式代表各种类型的输入数据。多模态模型还可以捕捉其他数据模态所提供的互补信息。这种模式使系统能够以统一的方式分析不同模态的数据,并通过语义搜索实现更精确和高效的数据处理。向量数据库借助向量相似性算法实现对多模态输入数据的语义检索。与传统的数据库存储原生数据不同,向量数据库能够管理由非结构化数据转化而来的高维向量数据。因此,向量数据库非常适合处理拥有多种数据类型的多模态 AI 应用。
使用 Milvus 的好处
Milvus 生态系统提供了有效的数据库监控、数据迁移和数据量估算工具。如果不想要花时间和精力维护 Milvus,也可以选择 Milvus 的云原生服务——Zilliz Cloud。以下是一些选择 Milvus 向量数据库的好处:
高效存储和检索
Milvus 专为存储和检索大规模向量数据而设计。此外,向量是深度学习模型所使用的“通用语言”。Milvus 可以轻松处理向量,提升多模态应用数据访问效率,缩短回答响应时间,优化用户体验。
高度灵活、可扩展
随着 AI 应用处理的数据量爆炸式增长,我们需要可扩展的解决方案。通过整合 Milvus,系统可以无缝地扩展以满足日益增长的需求。此外,Milvus 还提供了广泛的功能,可以提高多模态 AI 应用的整体灵活性和功能性。
高性能、高可用
Milvus 同时支持向量与标量数据,拥有多种索引选择,还提供了混合搜索等功能,能够满足多种业务需求。使用 Milvus,多模态 AI 应用可以更快速、更方便地处理各种类型的输入数据。Milvus 超高的检索性能可以帮助确保AI应用的效果和性能。
易用性
Milvus 提供多样的本地部署选项,包括使用 pip 快速启动 Milvus。您甚至还可以选择 Zilliz Cloud 云服务,快速启动和扩展 Milvus 实例。此外,Milvus 支持多种语言的 SDK,包括 Python、Java 和 Go(其他更多语言正在开发中),方便用户集成到现有的应用中。Milvus 还提供 Restful API,用户可以更轻松地与服务器进行交互。
可靠性
因出色的性能和高度可扩展性,Milvus 成为了最受欢迎的向量数据库。Milvus 拥有 1000 多家企业级用户,且配备活跃的开源社区。作为 LF AI&Data 基金会的毕业项目,Milvus 的可靠性也具备极大的保障,因此,Milvus 是高效管理大规模结构化和非结构化数据的首选解决方案。
打破缓存限制,增加输出多样性
想要提供全面有效的解决方案,满足广泛的用户需求,就需要多模态 AI 应用能够生成多种不同类型输出数据。多样的输出数据有助于提升用户体验、加强 AI 系统的整体功能性,如虚拟助手、聊天机器人、语音识别系统等应用就更依赖输出数据的多样性了。
虽然语义缓存是检索数据的有效方式,但它可能会限制响应的多样性。这是因为语义缓存会优先考虑缓存中的答案,而减少从大模型中生成新的响应。所以,使用语义缓存的 AI 系统会十分依赖先前已经存储在缓存中的数据和信息,很有可能会不断召回并输出相同或十分类似的答案,有损于内容生成的创造性。
为了解决这个问题,我们可以利用机器学习中的温度(temperature)参数。温度参数可以控制响应的随机性和多样性。温度参数值设置得越高,生成的答案越随机。参数值设置得越低,生成内容越一致。我们可以通过调节温度参数值来打破缓存限制,从而使我们的 AI 应用提供更全面有效的解决方案,满足更广泛的用户需求。
GPTCache 中的温度参数
为了平衡响应的随机性和一致性,并满足用户偏好或应用需求,在多模态 AI 应用中选择适当的温度参数值至关重要。GPTCache 保留了机器学习中温度参数的概念,在使用 GPTCache 时,可以选择以下 3 个选项来调节温度:
a. 从多个候选答案中随机选择
在深度学习中,对模型最后全连接层的输出使用 softmax 激活函数是一种常见的技术,其中涉及到了温度参数。GPTCache 类似地使用 softmax 函数将候选答案的相似性得分转换为概率列表。得分越高,被选为最终答案的可能性就越大。温度控制可能性分布的尖锐度,更高的温度意味着得分较高的答案更可能被选中。GPTCache 中的后处理器 “temperature_softmax” 遵循此算法,给定候选答案与相应的得分或置信度,选择一个最终答案。
from gptcache.processor.post import temperature_softmaxmessages = ["message 1", "message 2", "message 3"]
scores = [0.9, 0.5, 0.1]
answer = temperature_softmax(messages, scores, temperature=0.5)b. 调整概率跳过缓存,直接调用模型
第 2 种选项是通过温度参数,调整以下行为的概率:直接调用大模型而不搜索缓存。温度越高,越有可能跳过缓存,反之亦然。以下示例展示了如何使用 temperature_softmax 参数来通过温度控制是否跳过搜索缓存。
from gptcache.processor.post import temperature_softmaxdef skip_cache(temperature):if 0 < temperature < 2:cache_skip_options = [True, False]prob_cache_skip = [0, 1]cache_skip = temperature_softmax(messages=cache_skip_options,scores=prob_cache_skip,temperature=temperature))elif temperature >= 2:cache_skip = Trueelse: # temperature <= 0cache_skip = Falsereturn cache_skipc. 编辑缓存结果
使用小模型或一些工具来编辑回答。选择这个选项的前提是需要有一个编辑器,具备转换输出数据的能力。
02.
多模态应用
越来越多人已经不满足于仅依赖 GPT-3.5 驱动的 ChatGPT,大家希望通过 GPT-4 搭建自己的多模态应用——与多种数据模态交互,包括文本、视觉图片和音频等。随着 AI 技术的发展,GPTCache 和 Milvus 成为了构建创新型智能多模态系统的解决方案。以下几个例子展示了不同场景中如何使用 GPTCache 和 Milvus 搭建多模态 AI 应用。
文本到图像:生成图像
AI 生成图像一直是热门话题,指的是使用预训练的文本-图像多模态模型,基于文本描述或说明生成图像。近年来,这项技术取得了长足的进步。图像生成模型已经可以生成栩栩如生的图像,甚至肉眼很难与人类拍摄的照片区分开来。
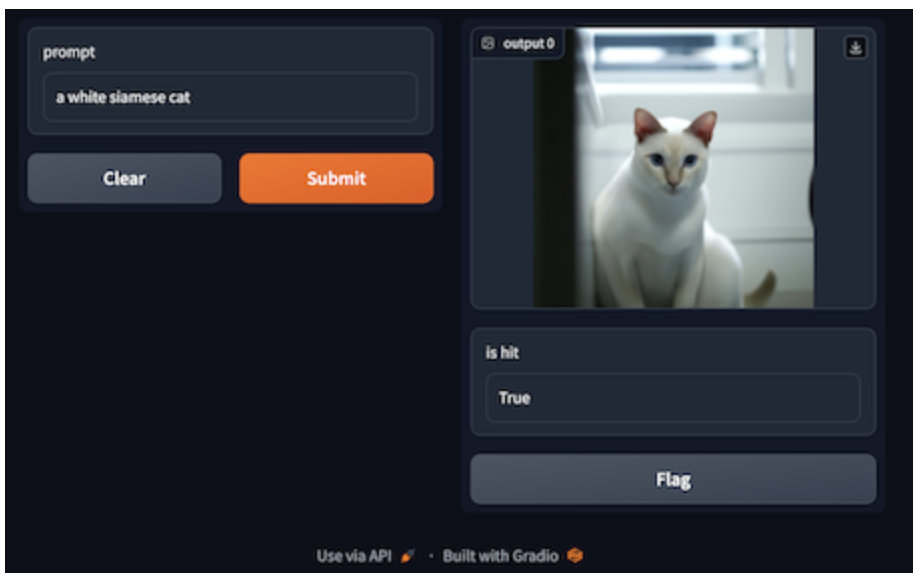
文本提示:一只白色暹罗猫
生成图像需要使用文本提示作为输入,而借助 GPTCache 和 Milvus 的语义搜索功能,图像生成会变得更加容易。系统可以使用 Milvus 检测缓存中存储的相似提示文本,并从缓存中获得相应的图像。如果缓存中没有令人满意的结果,GPTCache 则会调用图像生成模型。随后,模型生成的图像和文本将保存在 GPTCache,从而丰富缓存的数据库。其中,向量生成器会将文本提示转换为向量,并存储在 Milvus 中,以便于检索。
下面的示例代码调用了 GPTCache 适配的 OpenAI 服务,并要求系统根据给定的文本“一只白色暹罗猫”生成图像。我们可以通过 temperature 和 top_k两个参数来控制生成图像的多样性。temperature 参数的默认值是 0.0,如果将其调整到0.8,那么每次即使输入同样的文本,但是获得不同生成图像的可能性会增加。
from gptcache.adapter import openaicache.set_openai_key()response = openai.Image.create(prompt="a white siamese cat",temperature=0.8, # optional, defaults to 0.0.top_k=10 # optional, defaults to 5 if temperature>0.0 else 1.)GPTCache 目前已经内置了适配器,可以接入大多数流行的图像生成模型或服务,包括 OpenAI 图像生成服务(https://platform.openai.com/docs/guides/images/introduction)、Stability.AI API(https://stability.ai/blog/api-platform-for-stability-ai)、HuggingFace Stable Diffusions(https://huggingface.co/spaces/stabilityai/stable-diffusion)。
图像到文本:图像描述生成
图像描述生成是指为图像生成文本描述,这一过程通常会使用预训练的图像-文本多模态模型。通过这种技术,机器能够理解图像的内容并用自然语言描述和解释图像。我们还可以在聊天机器人中加入图像描述生成的能力,从而优化用户体验,将视觉交互和对话无缝衔接起来。
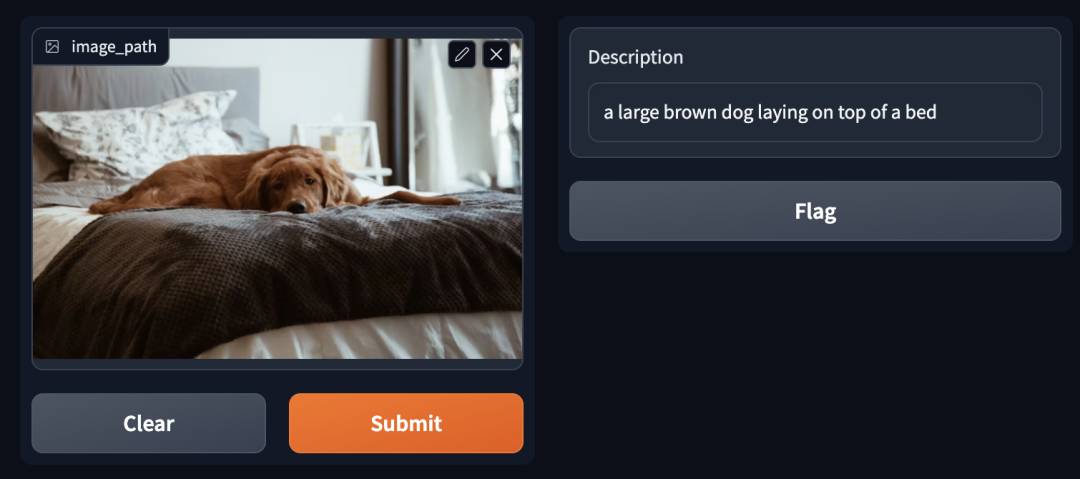
图像描述:棕色的大狗躺在床上
在图像描述生成的应用中,GPTCache 会先在缓存中扫描一遍,查找与输入图像相似的图像。然后,为了保证返回的文本描述质量,评估器会额外判断输入图像和从缓存中检索的图像或文本描述之间的相关性或相似性。评估图像相似性时,系统会使用预训练的视觉模型,如 ResNet 或ViT 等将图像转换成向量。
此外,像 CLIP 这样的文本-图像多模态模型,也可以用于直接衡量图像和文本之间的相似性。如果缓存中没有匹配项,那么系统会利用多模态模型为输入的图像生成新的文本描述。随后,GPTCache 会将生成的文本及相应的图像存储在缓存中。其中,图像和文本都会被转化为向量保存在 Milvus 中。
GPTCache 目前已经适配了主流的图像描述生成服务,例如 Replicate BLIP(https://replicate.com/salesforce/blip)和 MiniGPT-4(https://minigpt-4.github.io/)等。后续,GPTCache 将支持更多图像-文本模型和服务以及本地多模态模型。
音频到文本:语音转录
音频到文本,也称为语音转录,是指将音频内容(如录制的对话、会议或讲座)转换为书面形式的文本。这种技术能够帮助听障人士或者更喜欢阅读文字的人理解信息。用户可以将转录成文字的音频内容放入 ChatGPT 进行提问,或者尝试用其他方式更好利用语音转录的文本!
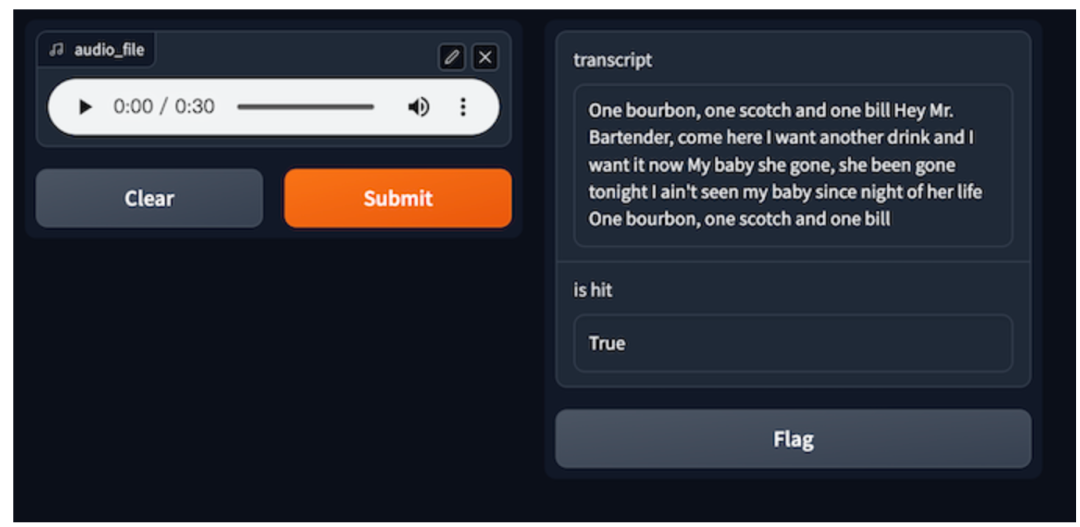
音频文件:一杯波本威士忌,一杯苏格兰威士忌,一份账单(One bourbon, one scotch, one bill)
语音转录的初始输入数据通常是音频文件。语音转录的第一步是将每个输入的音频文件转化为音频向量 。第二步,系统利用 Milvus 进行相似性搜索,从缓存中检索潜在的相似音频。如果在评估后找不到相似的答案时,系统会调用自动语音识别(ASR)模型或服务。ASR 模型生成的音频和转录文本都会存储在 GPTCache 缓存中。其中,音频数据会转化为向量存储在 Milvus 中。由于 Milvus 具有高扩展性,如果音频数量不断增加,Milvus 也能够灵活扩展以适应需求。
使用 GPTCache 和 Milvus 后,ASR 调用次数大幅降低,很大程度提高了音频转路的速度和效率。GPTCache 教程中的语音到文本教程(https://gptcache.readthedocs.io/en/latest/bootcamp/openai/speech_to_text.html)提供了实例代码,展示如何使用 GPTCache、Milvus 和 OpenAI 的 Speech to text 模型进行语音转录。
03.
总结
多模态 AI 模型越来越受欢迎,可以更全面地分析和理解复杂数据。Milvus 可以处理非结构化数据,因此是构建和扩展多模态 AI 应用的理想解决方案。在 GPTCache 中添加更多功能,例如会话管理、上下文感知和服务器,能够进一步增强多模态 AI 应用的能力,使多模态 AI 模型发挥更多潜在作用,满足更多场景需求。更多关于多模态 AI 应用的文章,请关注 GPTCache Bootcamp(https://github.com/zilliztech/GPTCache/tree/main/docs/bootcamp)。
🌟「寻找 AIGC 时代的 CVP 实践之星」 专题活动即将启动!
Zilliz 将联合国内头部大模型厂商一同甄选应用场景, 由双方提供向量数据库与大模型顶级技术专家为用户赋能,一同打磨应用,提升落地效果,赋能业务本身。
如果你的应用也适合 CVP 框架,且正为应用落地和实际效果发愁,可直接申请参与活动,获得最专业的帮助和指导!联系邮箱为 business@zilliz.com。
本文作者

顾梦佳
Zilliz 高级算法工程师
推荐阅读

《我决定给 ChatGPT 做个缓存层 >>> Hello GPTCache》

《GPTCache:LLM 应用必备的【省省省】利器》

相关文章:
探索 GPTCache|GPT-4 将开启多模态 AI 时代,GPTCache + Milvus 带来省钱秘籍
世界正处于数字化的浪潮中,为了更好理解和分析大量数据,人们对于人工智能(AI)解决方案的需求呈爆炸式增长。 此前,OpenAI 推出基于 GPT-3.5 模型的智能对话机器人 ChatGPT,在自然语言处理(NLP&a…...

纯css实现登录表单动效
效果图: 代码展示 // 我这边用的是elementUI表单校验,更改的样式。 <el-form:model"form":rules"rules"ref"fromList":hide-required-asterisk"true"><el-form-item prop"account"><…...
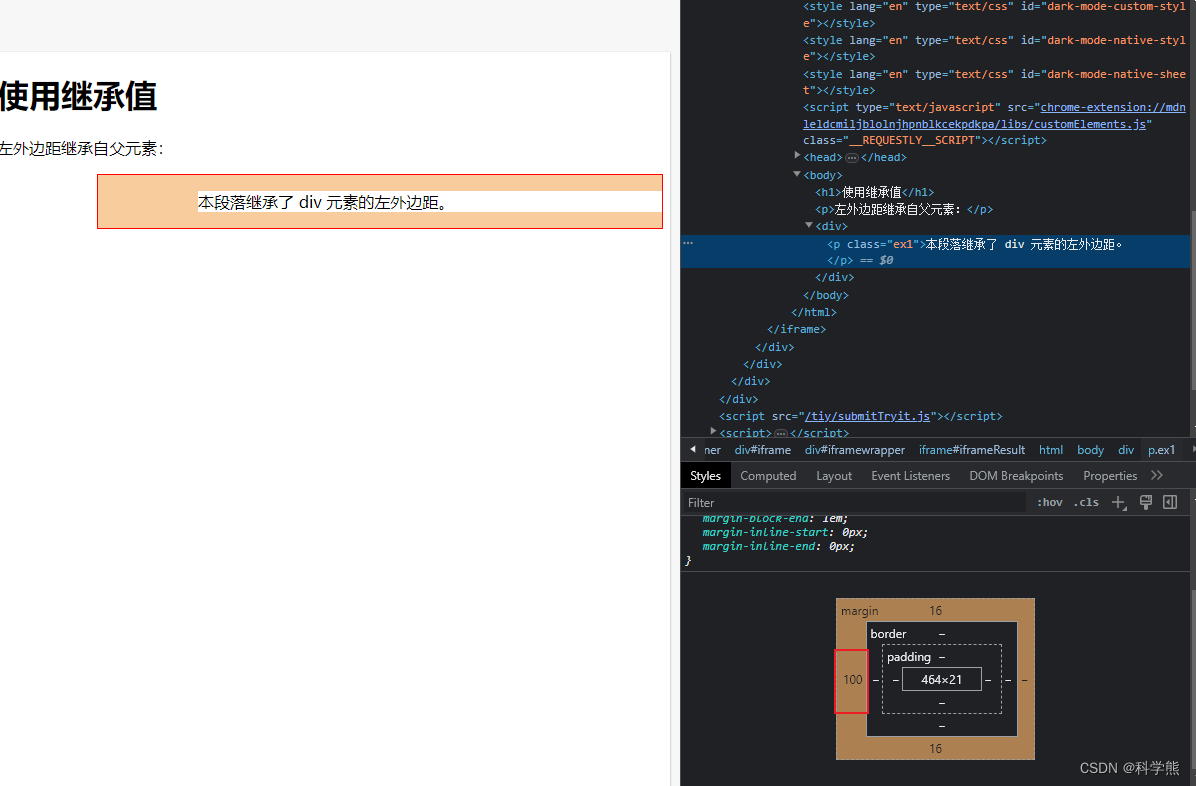
【css】外边距margin
外边距中有一个属性值比较有意思:inherit 值,继承父类的属性。 <!DOCTYPE html> <html> <head> <style> div {border: 1px solid red;margin-left: 100px; }p.ex1 {margin-left: inherit; } </style> </head> <…...

Cpp8 — 二叉搜索树
二叉搜索树(搜索二叉树、二叉排序树) 二叉搜索树又称二叉排序树,它要么是一棵空树,要么是具有以下性质的二叉树: 1.若它的左子树不为空,则左子树上所有节点的值都小于根节点的值 2.若它的右子树不为空&…...
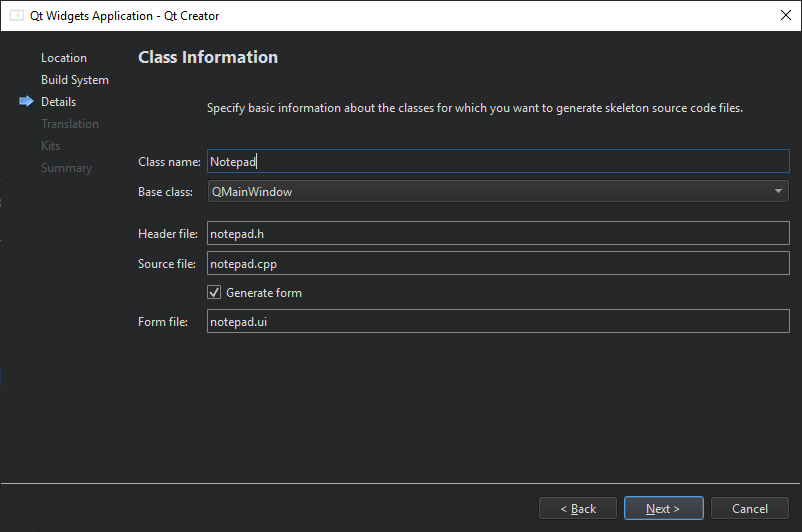
【实操教程】如何开始用Qt Widgets编程?(一)
Qt 是目前最先进、最完整的跨平台C开发工具。它不仅完全实现了一次编写,所有平台无差别运行,更提供了几乎所有开发过程中需要用到的工具。如今,Qt已被运用于超过70个行业、数千家企业,支持数百万设备及应用。 在本文中࿰…...
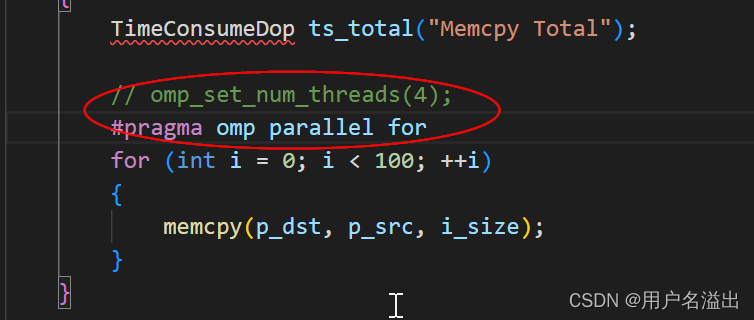
openmp和avx配置
实际场景: 项目中数据拷贝慢(使用的是memcpy),希望能加速拷贝,所以尝试了使用avx的流方式,和openmp方式处理 问题1: 调用avx是报错 error: inlining failed in call to always_inline ‘__m512…...

18 个JS优化技巧,可以解决 90% 的屎山代码!!!
文章目录 18 个JS优化技巧,可以解决 90% 的屎山代码!!!1.箭头函数2.解构赋值变量3.使用模版字面量进行字符拼接4.使用展开运算符进行数组和对象操作5.简化循环6.简化判断7.使用对象解构和默认参数简化函数参数8.使用函数式编程概念…...
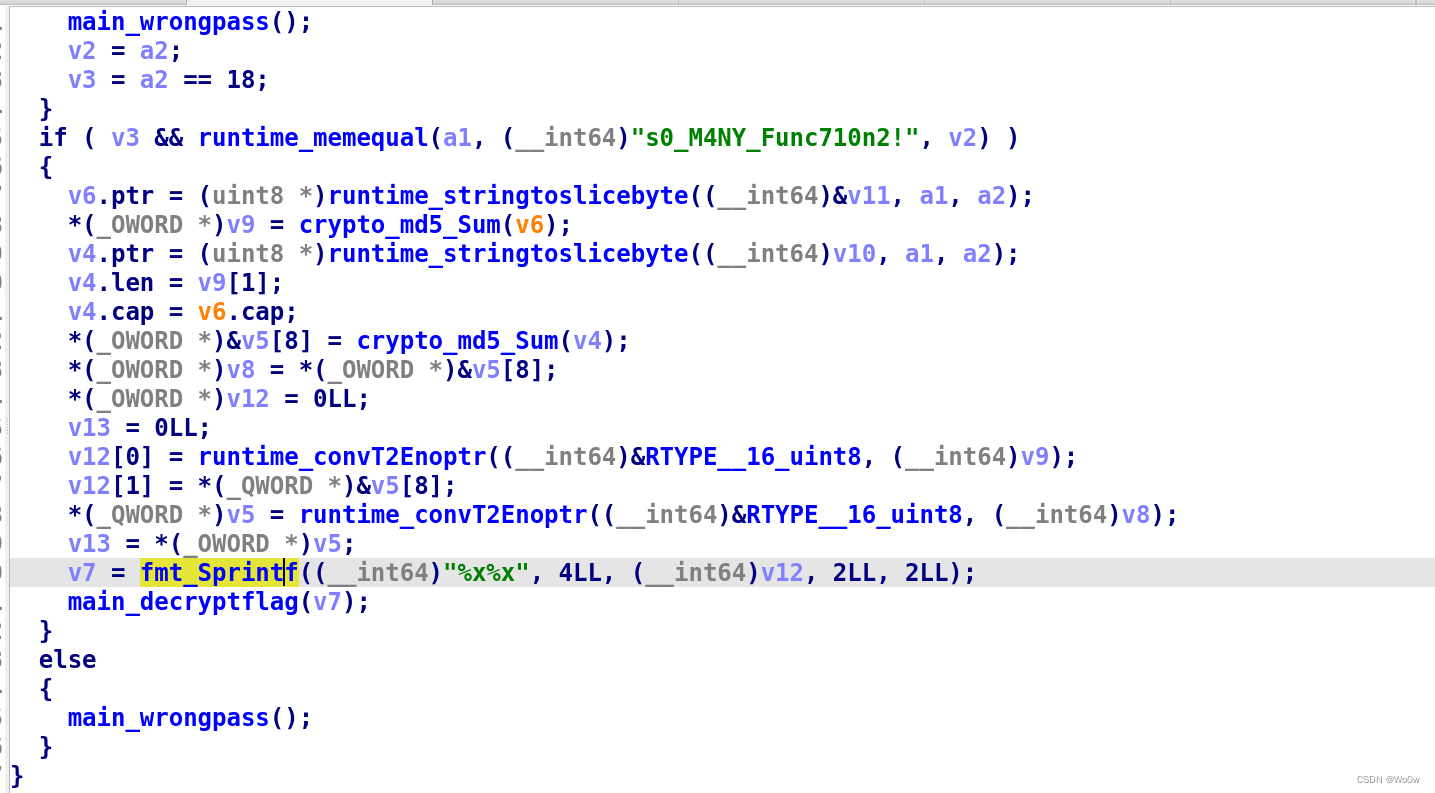
go逆向符号恢复
前言 之前一直没怎么重视,结果发现每次遇到go的题都是一筹莫展,刷几道题练习一下吧 准备 go语言写的程序一般都被strip去掉符号了,而且ida没有相关的签名文件,没办法完成函数名的识别与字符串的定位,所以第一步通常…...
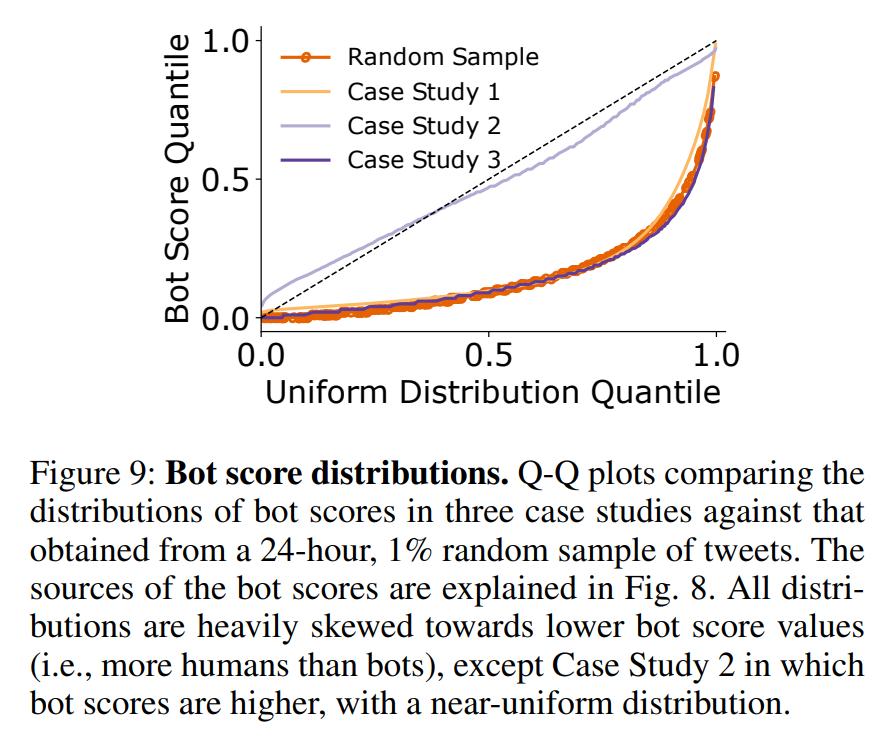
论文阅读- Uncovering Coordinated Networks on Social Media:Methods and Case Studies
链接:https://arxiv.org/pdf/2001.05658.pdf 目录 摘要: 引言 Methods Case Study 1: Account Handle Sharing Coordination Detection 分析 Case Study 2: Image Coordination Coordination Detection Analysis Case Study 3: Hashtag Sequen…...

应急响应-Linux
应急响应-Linux 1.关键目录 /etc/passwd 记录用户信息 /etc/shadow 保存用户密码(hash) /etc/crontab 定时任务文件 /etc/anacrontab 异步定时任务文件 /etc/rc.d/rc.local 开机启动项 /var/log/btmp …...
利用spinal的伴生对象简化集成rtl代码过程
一 参考 SpinalHDL——集成你的RTL代码 (qq.com)https://mp.weixin.qq.com/s?__biz=Mzg5NjQyMzQwMQ==&mid=2247484852&idx=1&sn=d074279cdc0d58eb5dc73ca68271eee8&chksm=c0000132f77788249838570187495e34cc12ab40e8f8f5ec8f65414ec84b3ece2d17f0d4c4f8&…...

C# Blazor 学习笔记(7):组件嵌套开发
文章目录 前言相关资料组件嵌套组件模板RenderFragment 意义传统前端样式组件化css 前言 我们在组件化一共有三个目的。 不用写CSS不用写html不用写交互逻辑 简单来说就是Java常说的约定大于配置。我们只需要必须的参数即可,其它的都按照默认配置。我们不需要关系…...
DAY1,C高级(命令,Linux的文件系统,软、硬链接文件)
1.创建链接文件; 文件系统中的每个文件都与唯一的 inode 相关联,inode 存储了文件的元数据和数据块的地址,文件名与 inode 之间的链接关系称为硬链接或软链接。 硬链接文件的创建: ln 被链接文件的绝对路径 硬链接文件的绝对…...

Race竞争型漏洞
目录 Race竞争介绍 实验环境配置 安装Cookiecutter 创建基于Django框架的项目 选择配置 创建数据库 加载到环境变量里 数据库的生成 创建一个超级用户(superuser) 启动一个本地开发服务器 配置文件 Race竞争介绍 竞争型漏洞(Race Co…...
基于 FFlogs API 快速实现的 logs 颜色查询小爬虫
文章目录 找到接口解析响应需要平均颜色和过本次数? 找到接口 首先试了一下爬虫,发现和wow一样官网上有暴露的 API,链接在:FFlogs v1 API 文档链接 通过查询官方提供的 API 接口得知: user_name 角色名字 api_key …...
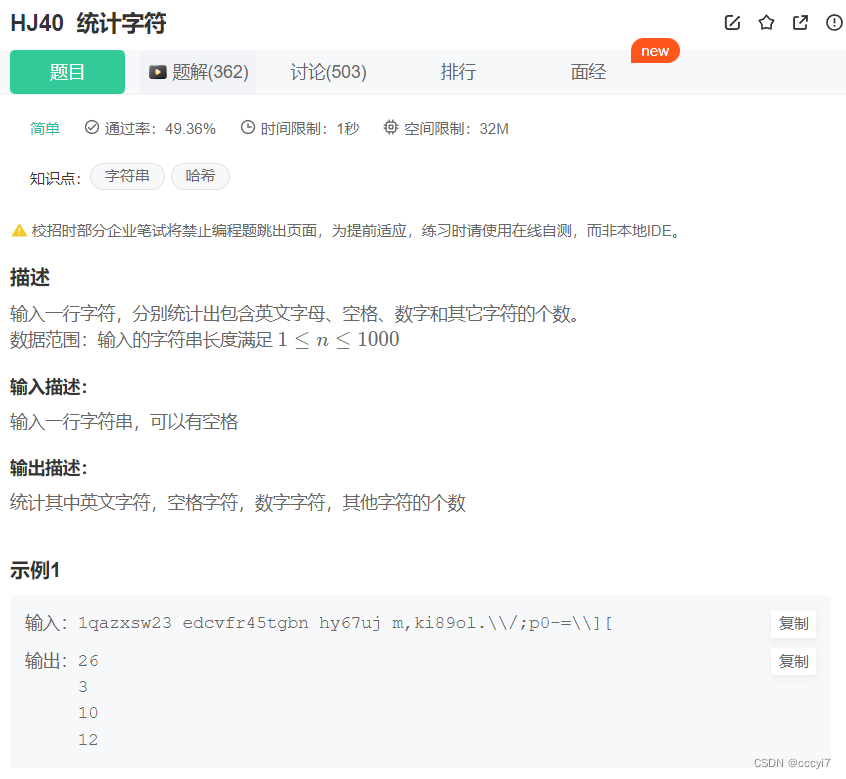
【牛客】统计字符
⭐️ 题目描述 🌟 OJ链接:HJ40 统计字符 ps: 判断字符可以直接使用头文件自带的函数。 函数作用iscntrl判断是否为控制字符isspace判断是否为空白字符(空格、换页’\f’、换行’\n’、回车’\r’、制表符’\t)isdigi…...
测试|Junit相关内容
测试|Junit相关内容 文章目录 测试|Junit相关内容0.Junit说明1.Junit注解TestDisabledBeforeAll和AfterAllBeforeEach和AfterEach 2.Junit参数化单参数多参数(多种/多组)CSV获取参数(支持多种)CSV文件获取参数(支持多种…...

19-2.vuex
目录 1 安装 2 挂载 2.1 vue2写法 2.2 vue3写法 3 state 3.1 声明数据 3.2 使用数据 3.3 处理数据 4 mutations 4.1 基本使用 4.2 传递参数 4.3 mutations中不能写异步的代码 5 actions 5.1 基本使用 5.2 传递参数 6 getters Vuex是做全局数据…...

微信小程序 选择年和月以及回显 使用picker-view组件
<!--选择年月--><view bindtap"pickCalendar">{{year}}年{{month}}月</view><picker-view wx:if"{{open}}" class"fixed-select" indicator-style"height: 50px;" style"width: 100%; height: 300px;"…...
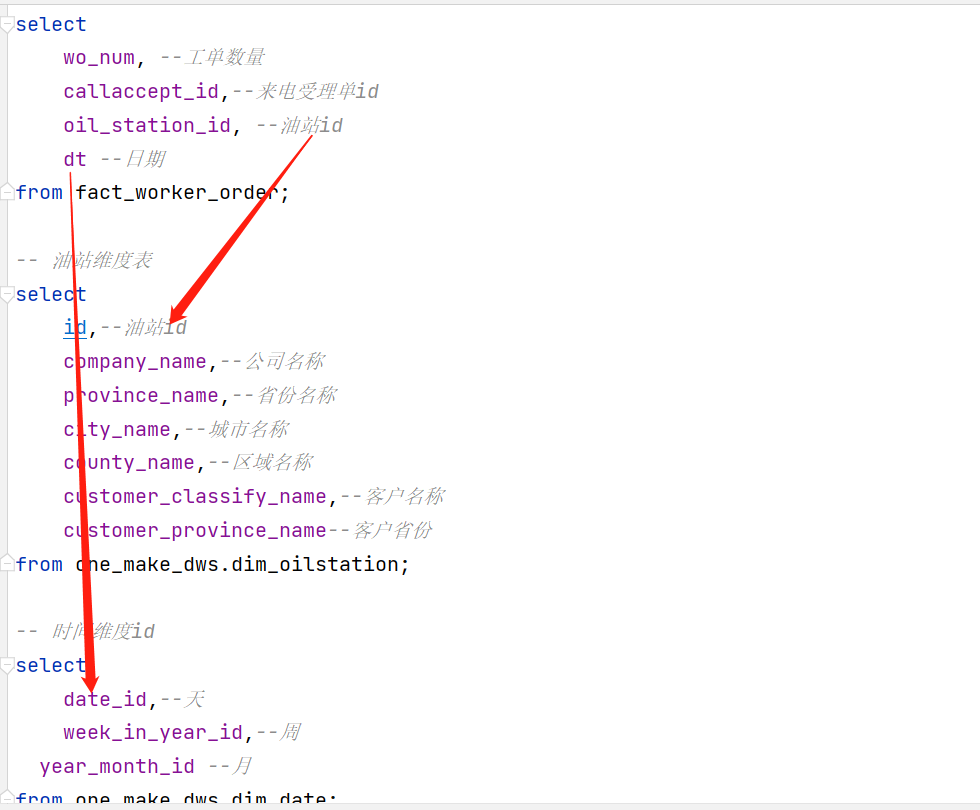
助力工业物联网,工业大数据之ST层的设计【二十五】
文章目录 04:ST层的设计05:服务域:工单主题分析06:服务域:工单主题实现 04:ST层的设计 目标:掌握ST层的设计 路径 step1:功能step2:来源step3:需求 实施 功…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...
到底在‘看’什么?)
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?
从社交关系到分子结构:图解GCN(图卷积网络)到底在‘看’什么?想象一下,你刚搬到一个新社区,想快速了解周围的邻居。最直接的方式是什么?不是挨家挨户敲门,而是通过社区活动认识几位关…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

写论文的神助攻!好用的AI写作辅助软件,逻辑清晰质量高
作为一名刚完成毕业论文的过来人,我太懂写论文的痛苦了 —— 选题迷茫、文献浩如烟海、框架混乱、逻辑不清、反复修改、查重降重反复折腾... 直到我发现了这套 AI 写作工具组合,简直是论文写作的 "开挂神器",效率直接拉满ÿ…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...

defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 [特殊字符]
defx.nvim 安装与配置完全教程:从零开始搭建高效文件管理系统 🚀 【免费下载链接】defx.nvim :file_folder: The dark powered file explorer implementation for neovim/Vim8 项目地址: https://gitcode.com/gh_mirrors/de/defx.nvim defx.nvim …...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验
Windows安卓应用安装终极指南:5分钟快速配置跨平台应用体验 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为在Windows电脑上无法直接安装安卓应用而烦…...

还在手动触发Lindy子任务?这6个隐藏API+3个低代码集成技巧,今天就能上线全自动流水线
更多请点击: https://kaifayun.com 第一章:Lindy多步骤任务自动化的价值与演进路径 Lindy效应指出,一项技术的预期剩余寿命与其当前已存在时间正相关;在自动化领域,Lindy原则催生了对“经久验证、语义稳定、可组合性强…...