Java类集框架(二)
目录
1.Map(常用子类 HashMap,LinkedHashMap,HashTable,TreeMap)
2.Map的输出(Map.Entry,iterator,foreach)
3.数据结构 - 栈(Stack)
4.数据结构 - 队列(Queue)
5.属性类Properties
5.Collections工具类
1.Map(常用子类 HashMap,LinkedHashMap,HashTable,TreeMap)
Map最大的特点就是二元偶对象(存储的结构是 key = value),比如说存放的可以是学生+成绩,如:黄小龙 = 60 。并且Map与Collection集合在操作上的不同是,Map中文是地图,最大的作用是用以查找数据,而Collection最主要用以输出数据
| 方法 | 描述 |
|---|---|
| public void put(K key, V value) | 将指定的键值对添加到Map中 |
| public V get(Object key) | 返回与指定键关联的值 |
| public Set<Map.Entry<K, V>> entrySet() | 返回Map中包含的所有键值对的Set集合 |
| public V remove(Object key) | 从Map中移除指定键及其关联的值 |
| public boolean containsKey(Object key) | 如果Map中包含指定键,则返回true;否则返回false |
1.HashMap(散列Map)子类
案例代码HashMap的创建:
package Example1813;import java.util.HashMap;
import java.util.Map;public class javaDemo {public static void main(String[] args) {Map<String,Integer> map = new HashMap<String,Integer>();map.put("王",12);map.put("张",6);map.put("黄",2);map.put("何",8);
// 输入存在null的数据map.put("只有key",null);map.put(null,2);map.put(null,null);System.out.println(map);}
}
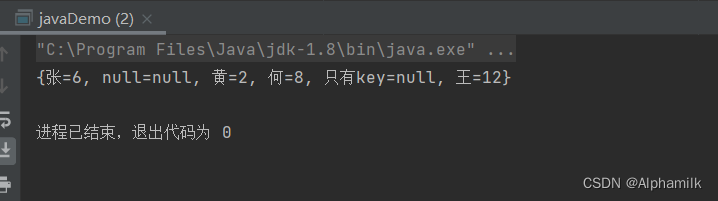
- 由于是Hash散列,所以存储的数据是混乱无序的,如果按照顺序输入数据可能会被打乱,所以为了解决这个问题如同Set的HashSet一样引入了LinkedHashMap
- HashMap允许放入的数据存在空值(NULL)
2.LinkedHashMap子类
有序型Map,通过放入的顺序保证输出的顺序
案例代码:成绩查询系统
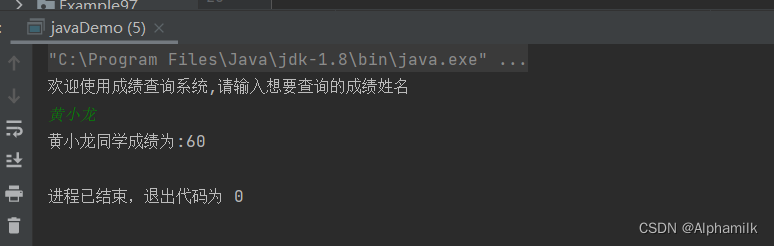
package Ecample1814;import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Scanner;public class javaDemo {public static void main(String[] args) {Map<String,Integer> map = new LinkedHashMap<>();map.put("黄小龙",60);map.put("张春蛋",62);map.put("王二",73);map.put("王包",77);map.put("陈色",78);System.out.println("欢迎使用成绩查询系统,请输入想要查询的成绩姓名");Scanner scan = new Scanner(System.in);String temp = scan.next();if (map.containsKey(temp)){System.out.println(temp+"同学成绩为:"+ map.get(temp));}else System.out.println("无查询对象");}
}
3.HashTable子类
HashTable,也是无序的存放,但是其中不能存放空值否则会报错
案例代码:
package Example1816;import java.util.Hashtable;
import java.util.Map;public class javaDemo {public static void main(String[] args) {Map<String,String> hashtable= new Hashtable<>();hashtable.put("科目1","驾驶知识考试");hashtable.put("科目2","道路模拟项目");hashtable.put("科目3","道路模拟驾驶");try {
// 放入空值hashtable.put(null,null);}catch (Exception e){
// 提示异常e.printStackTrace();}System.out.println(hashtable);}
}
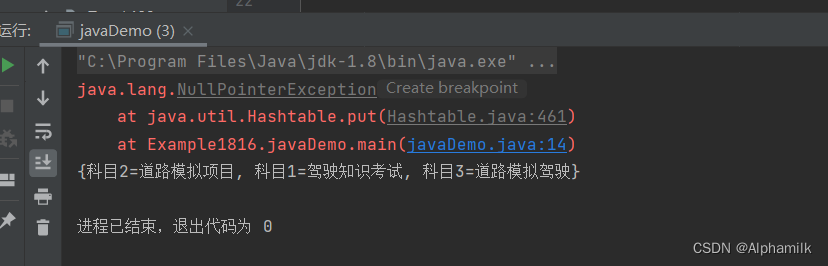
HashTable与HashMap的区别
HashTable属于同步操作(线程安全),并且其中的key和value不允许存放null,否则会抛出异常NullPointerException
HashMap属于异步操作(非线程安全),其中的key或者value可以存放null
4.TreeMap 子类
TreeMap的子类属于是有序的集合类型,它可以根据key进行排序,所以再key一定要有实现Comparable的接口的才能进行排序
String类就实现了Comparable接口
案例代码:按照运动员号数输出所有运动员的比赛时间
package Example1817;import java.util.Hashtable;
import java.util.Map;
import java.util.TreeMap;public class javaDemo {public static void main(String[] args) {Map<String,String> map = new TreeMap<>();map.put("运动员2号","6.32秒");map.put("运动员1号","6.54秒");map.put("运动员4号","6.72秒");map.put("运动员3号","7.02秒");System.out.println(map);}
}

2.Map的输出(Map.Entry与iterator,foreach)
虽然Map主要用于数据的查找,但是有些时候也是需要其中数据的输出。但是在Map的方法中可以发现并不像Collection一样有iterator方法,所以目标放在方法转换方法entrySet(),先将数据转为Set集合类型再通过iterator迭代器进行输出,这就是Map的标准输出
首先介绍Map.Entry内部接口
由于Map中所有保存的对象都是二元偶对象,所以针对此对象的数据标准建立了一个Map.Entry内部接口,该接口可以接收二元偶对象并存在两个方法,getkey()与getvalue();分别获取一个对象的key与value
通过Map.Entry搭配Iterator实现Map的输出案例:
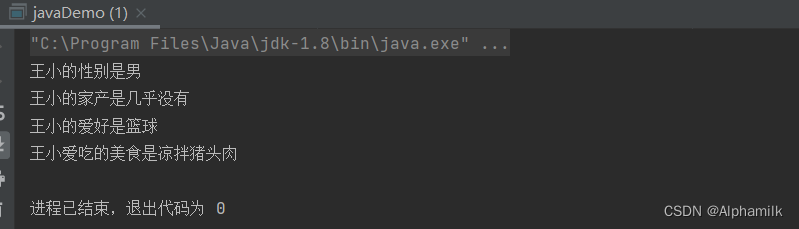
package Example1818;import java.util.Hashtable;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;public class javaDemo {public static void main(String[] args) {Map<String, String> map = new Hashtable<>();map.put("王小的爱好", "篮球");map.put("王小爱吃的美食", "凉拌猪头肉");map.put("王小的性别", "男");map.put("王小的家产", "几乎没有");
// map转为集合SetSet<Map.Entry<String, String>> entrySet = map.entrySet();
// 调用集合Set的iterator方法Iterator<Map.Entry<String, String>> entryIterator = entrySet.iterator();while (entryIterator.hasNext()) {Map.Entry<String,String> temp =entryIterator.next();System.out.println(temp.getKey()+"是"+temp.getValue());}}
}
问1:为什么迭代器的泛型是Iterator<Map.Entry<String,String>>而不是Iterator<String,String>
迭代器的泛型类型应为
Iterator<Map.Entry<String, String>>而不是Iterator<String, String>,因为在遍历Map键值对时,每个键值对都表示一个Map.Entry对象。在Java中,
Map接口的键值对由Map.Entry表示,其在内部定义了两个相关的方法:getKey()和getValue()。因此,当使用迭代器来遍历Map时,需要使用Map.Entry作为泛型参数,并且迭代器的类型应该是Iterator<Map.Entry<String, String>>。通过这种方式,迭代器可以迭代返回
Map.Entry对象(包含键和值),然后可以使用getKey()和getValue()方法分别获取键和值。
3.数据结构 - 栈(Stack)
栈作为一种数据结构其最主要的特点就是"先进后出"
举个最简单例子理解,在古代如果一个人有大量的钱财需要自己存放,那么他可能会挖一个坑,这个坑就理解为栈,首先他先放财物在坑底,然后放石头块,最后放沙子。那有一天他要用到财务的时候,就需要按挖沙子,挖石头块,得到财物的流程,这里可以发现最开始放的财物反而最后才能得到,这就是先进后出
Stack常用的方法:
| 修饰符 | 返回值类型 | 方法名 | 描述 |
|---|---|---|---|
public | void | push() | 将元素推入栈顶。 |
public | E | pop() | 移除并返回栈顶元素。 |
public | E | peek() | 返回栈顶元素但不移除。 |
public | int | search() | 返回元素在栈中的位置,如果不存在则返回 -1。 |
public | boolean | empty() | 检查栈是否为空,为空则返回 true,否则返回 false。 |
案例Stack的创建以及操作方法:
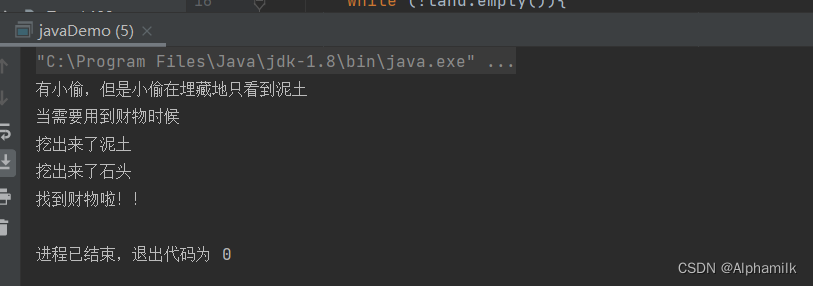
package Example1819;import java.util.Stack;public class javaDemo {public static void main(String[] args) {Stack<String> land = new Stack<>();
// 埋藏财物land.push("财物");land.push("石头");land.push("泥土");System.out.println("有小偷,但是小偷在埋藏地只看到"+land.peek());System.out.println("当需要用到财物时候");
// 开始挖财物while (!land.empty()){String temp;temp = land.pop();if (temp.equals("财物")){System.out.println("找到财物啦!!");}else System.out.println("挖出来了"+temp);}}
}
4.数据结构 - 队列(Queue,Deque)
队列作为一种数据结构其最主要的特点就是“先进先出”
就跟名字的队列一样,就像抢票一样,先到先得
由于在jdk1.6以后为了方便队列的操作将Queue定义为了Deque,此次的变更扩充了许多的方法,以下是Deque的常用方法
| 修饰符 | 返回值类型 | 方法名 | 描述 |
|---|---|---|---|
boolean | void | addFirst(E e) | 将指定元素插入到双端队列的开头位置,如果成功则返回 true,如果队列已满则抛出异常。 |
boolean | void | addLast(E e) | 将指定元素插入到双端队列的末尾位置,如果成功则返回 true,如果队列已满则抛出异常。 |
boolean | boolean | offerFirst(E e) | 将指定元素插入到双端队列的开头位置,如果成功则返回 true,如果队列已满则返回 false。 |
boolean | boolean | offerLast(E e) | 将指定元素插入到双端队列的末尾位置,如果成功则返回 true,如果队列已满则返回 false。 |
E | E | removeFirst() | 移除并返回双端队列的开头元素,如果队列为空则抛出异常。 |
E | E | removeLast() | 移除并返回双端队列的末尾元素,如果队列为空则抛出异常。 |
E | E | pollFirst() | 移除并返回双端队列的开头元素,如果队列为空则返回 null。 |
E | E | pollLast() | 移除并返回双端队列的末尾元素,如果队列为空则返回 null。 |
E | E | peekFirst() | 返回双端队列的开头元素但不移除,如果队列为空则返回 null。 |
E | E | peekLast() | 返回双端队列的末尾元素但不移除,如果队列为空则返回 null。 |
案例代码:
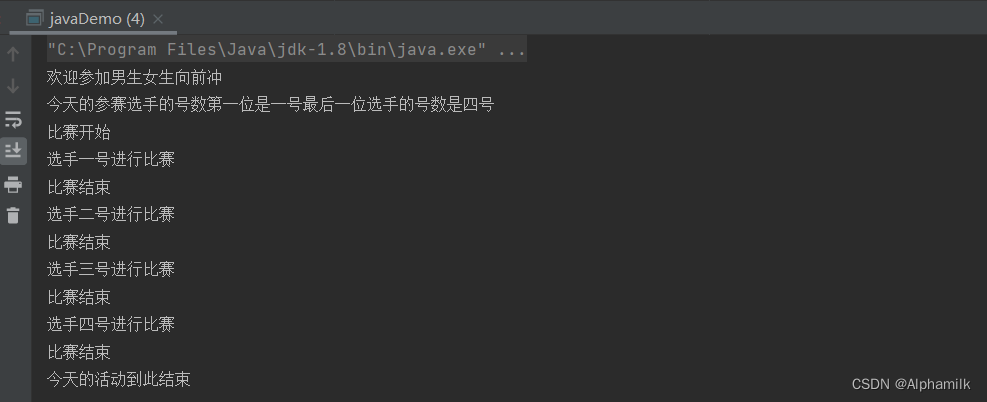
package Example1820;import java.util.Deque;
import java.util.LinkedList;public class javaDemo {public static void main(String[] args) {
// 通过链表接收对象Deque<String> deque = new LinkedList<>();System.out.println("欢迎参加男生女生向前冲");
// 从队尾进行插入,每一位到前一位的后面deque.addLast("一号");deque.addLast("二号");deque.addLast("三号");deque.addLast("四号");System.out.println("今天的参赛选手的号数第一位是"+deque.peekFirst()+"最后一位选手的号数是"+ deque.peekLast());System.out.println("比赛开始");while (!deque.isEmpty()){System.out.println("选手"+deque.pollFirst()+"进行比赛");System.out.println("比赛结束");}System.out.println("今天的活动到此结束");}
}
5.属性类Properties
属性类是专门用以处理字符串的一个类并且是HashTable的子类,但是注意只能对字符串进行操作,同时可以通过输入/输出流进行数据的保存
以下是属性类的常用方法:
| getProperties(String key) | 返回指定键对应的属性值。 |
| getProperties(String key, defaultValue) | 返回指定键对应的属性值,如果键不存在则返回默认值。 |
| setProperties(Properties props) | 将指定的属性集合设置为当前属性集合。 |
| store(OutputStream out, String comments) | 将当前属性集合保存到输出流中。 |
| load(InputStream in) | 从输入流中加载属性集合。 |
设置属性的案例:
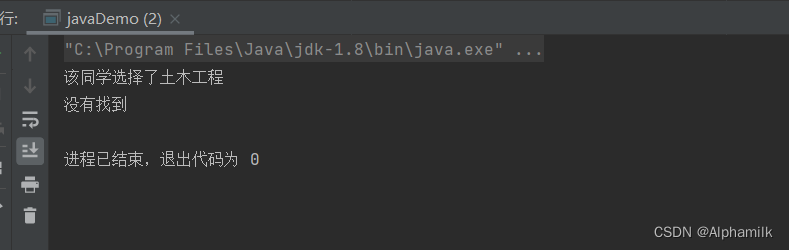
package Example1821;import java.util.Properties;public class javaDemo {public static void main(String[] args) {Properties properties = new Properties();
// 创建属性properties.setProperty("属性的key","属性的value");properties.setProperty("黄小龙","土木工程");properties.setProperty("张小芳","计算机科学技术");properties.setProperty("王洪","道桥设计");properties.setProperty("黄键化","石油开采");
// 获取属性System.out.println("该同学选择了"+properties.getProperty("黄小龙"));System.out.println(properties.getProperty("王孟","没有找到"));}
}
2.通过输入输出流进行文件保存
package Example1822;import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
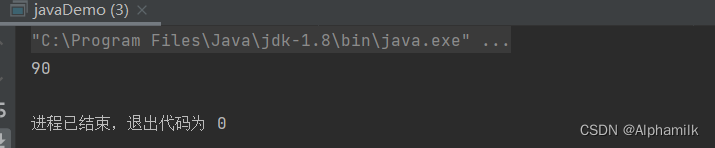
import java.util.Properties;public class javaDemo {public static void main(String[] args)throws Exception {File file = new File("E:"+File.separator+"jiawa"+File.separator+"information.properties");Properties properties = new Properties();
// 填入信息properties.setProperty("www.baidu.com","78");properties.setProperty("www.csdn.com","80");properties.setProperty("www.4399.com","90");properties.setProperty("ww.7k7k","68");
// 通过输出流将信息输出到对应文件中if (file.exists()){properties.store(new FileOutputStream(file),"website and it gets scores");}
// 通过输入流得到信息Properties inproperty = new Properties();inproperty.load(new FileInputStream(file));System.out.println(inproperty.get("www.4399.com"));}
}

5.Collections工具类
该工具类是专门提供的一个集合的工具类,该工具类实现Collection,Map,List,Set等集合接口的数据操作
下面是Collections工具类的常用方法:
| 方法 | 描述 |
|---|---|
addAll(Collection<? super T> c, T... elements) | 将元素数组添加到集合 c 中 |
binarySearch(List<? extends T> list, T key) | 使用二分查找算法在有序列表 list 中查找元素 key 的索引 |
copy(List<? super T> dest, List<? extends T> src) | 将源列表 src 的元素复制到目标列表 dest |
fill(List<? super T> list, T obj) | 使用指定的对象 obj 填充列表 list |
max(Collection<? extends T> coll) | 返回集合 coll 的最大元素 |
min(Collection<? extends T> coll) | 返回集合 coll 的最小元素 |
reverse(List<?> list) | 反转列表 list 中的元素 |
shuffle(List<?> list) | 随机打乱列表 list 中的元素 |
sort(List<T> list) | 对列表 list 进行升序排序 |
swap(List<?> list, int i, int j) | 交换列表 list 中索引为 i 和 j 的元素 |
案例:通过Collections类操作List集合
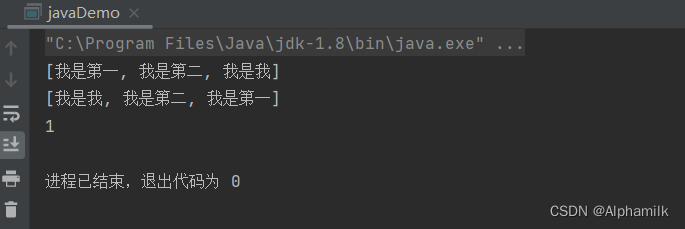
package Example1823;import java.util.ArrayList;
import java.util.Collections;
import java.util.List;public class javaDemo {public static void main(String[] args) {List<String> list = new ArrayList<String>();
// 批量添加信息Collections.addAll(list,"我是第一","我是第二","我是我");System.out.println(list);
// 集合内容反转Collections.reverse(list);System.out.println(list);
// 通过二分法查找System.out.println(Collections.binarySearch(list,"我是第二"));}
}
相关文章:
Java类集框架(二)
目录 1.Map(常用子类 HashMap,LinkedHashMap,HashTable,TreeMap) 2.Map的输出(Map.Entry,iterator,foreach) 3.数据结构 - 栈(Stack) 4.数据结构 - 队列(Q…...

爬虫008_流程控制语句_if_if else_elif_for---python工作笔记026
然后我们再来看一下这里的,判断,可以看到 再看一个判断,这里的布尔类型 第二行有4个空格,python的格式 注意这里,输入的age是字符串,需要转一下才行 int可以写到int(intput("阿斯顿法师打发地方")) 这样也可以...

【随笔】五周年创作纪念日
今天收到了 CSDN 的创作五周年提示,正好前几天(7.31)我也成功申请了 CSDN 博客专家,趁这个机会分享一下这几年写博客的感受吧 机缘 关注我比较久的读者应该知道我是从学传统工科半路出家搞计算机的,这里的经历还是比…...
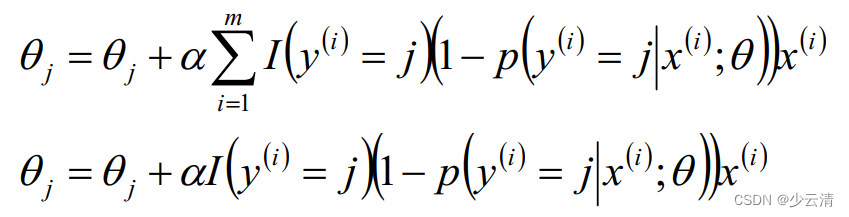
7_分类算法—逻辑回归
文章目录 逻辑回归:1 Logistic回归(二分类问题)1.1 sigmoid函数1.2 Logistic回归及似然函数(求解)1.3 θ参数求解1.4 Logistic回归损失函数1.5 LogisticRegression总结 2 Softmax回归(多分类问题࿰…...
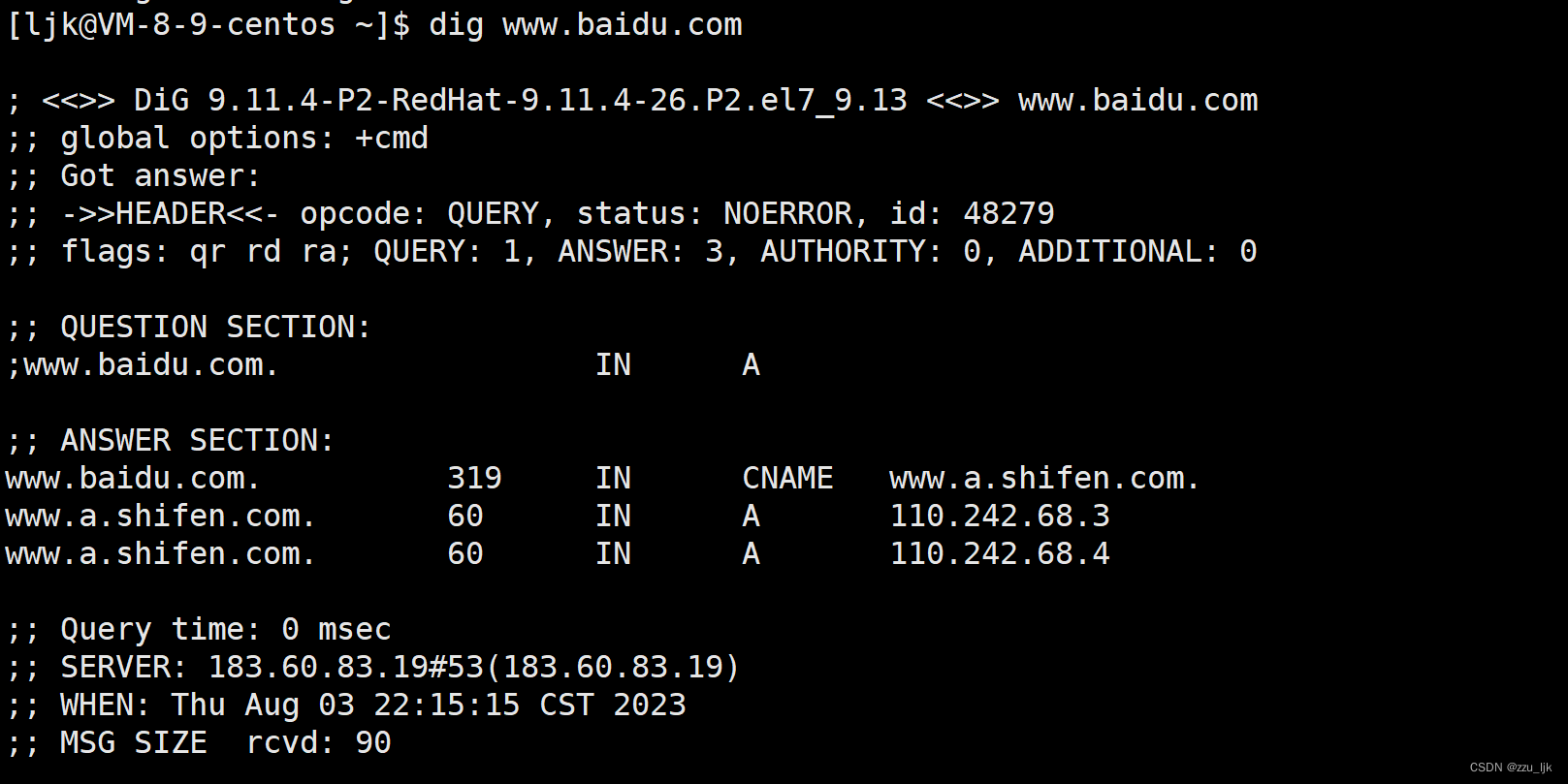
【计算机网络】应用层协议 -- DNS协议
文章目录 1. DNS背景2. 域名简介3. 域名解析过程4. 使用dig查看DNS过程 1. DNS背景 DNS(Domain Name System,域名系统)协议,是一个用来将域名转化为IP地址的应用层协议。 TCP/IP当中通过IP地址和端口号的方式,来确定…...

ES6 - 数组新增的一些常用方法
文章目录 1,Array.from()2,Array.of()3,find(),findIndex(),findLast()和findLastIndex()4,Array.fill()5,keys(),values() 和 entries()6,Array.includes()7,…...
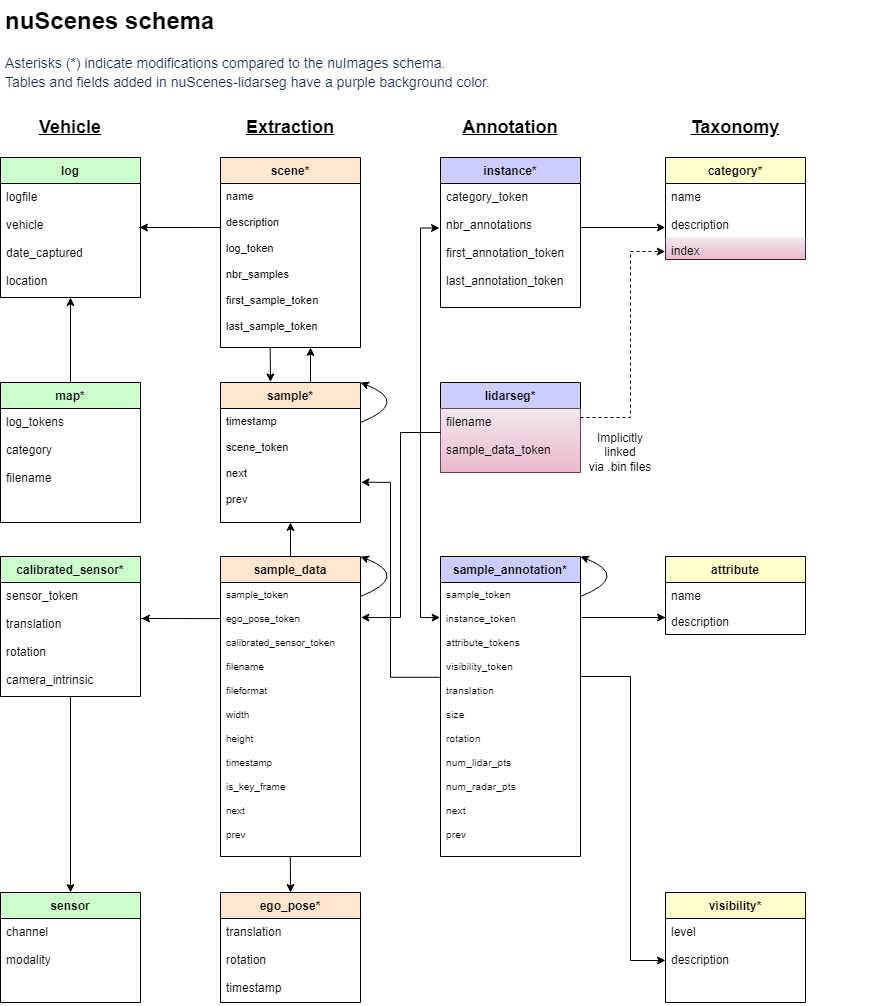
【BEV感知】3-BEV开源数据集
3-BEV开源数据集 1 KITTI1.1 KITTI数据怎么采集?1.2 KITTI数据规模有多大?1.3 KITTI标注了哪些目标?1.4 转换矩阵1.5 标签文件 2 nuScenes2.1 nuScenes Vs KITTI2.2 标注文件 1 KITTI KITTI 1.1 KITTI数据怎么采集? 通过车载相机、激光雷达等传感器采集。 只提供了相机正…...
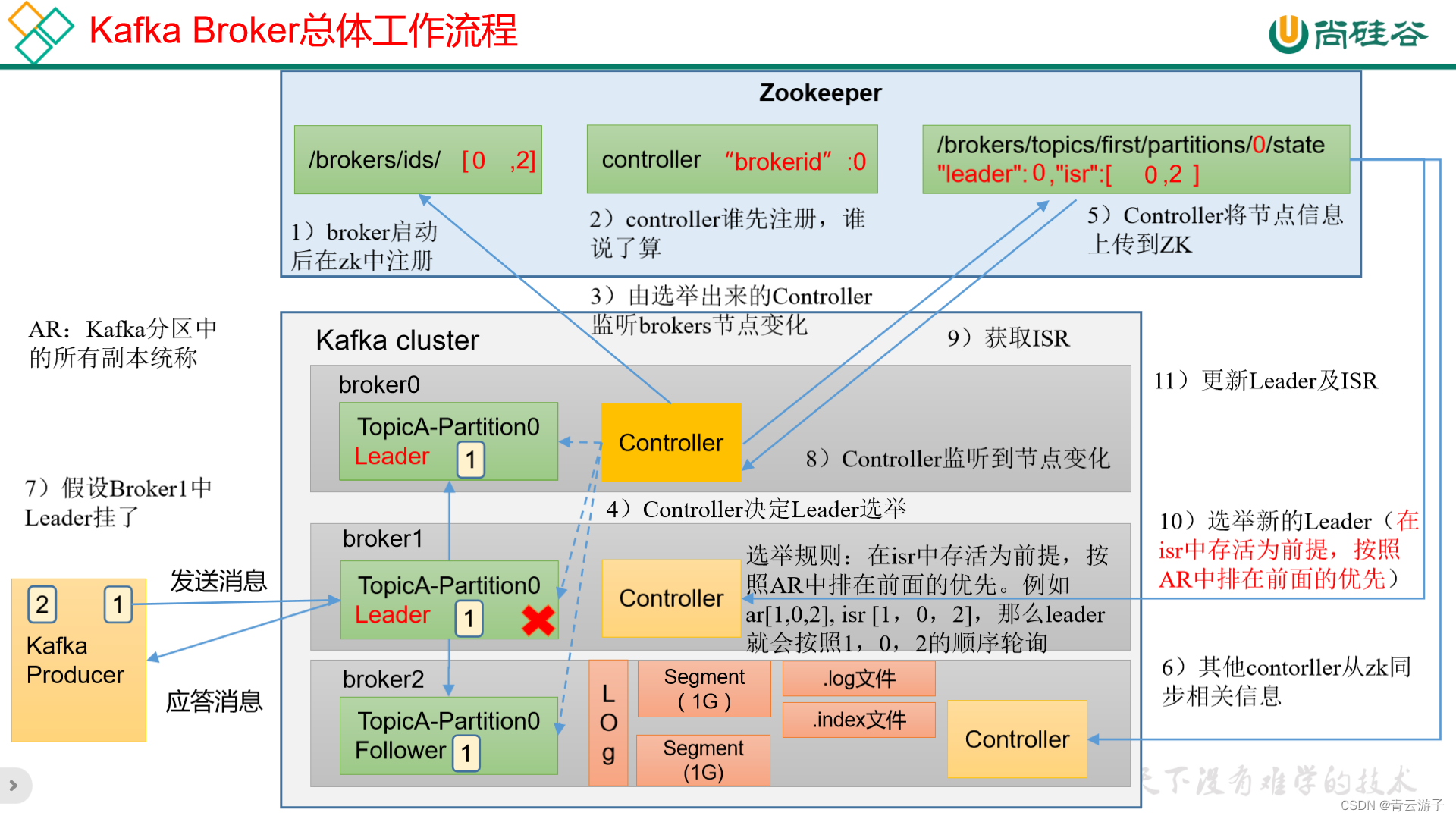
Kafka-Broker工作流程
kafka集群在启动时,会将每个broker节点注册到zookeeper中,每个broker节点都有一个controller,哪个controller先在zookeeper中注册,哪个controller就负责监听brokers节点变化,当有分区的leader挂掉时,contro…...

第八篇-Tesla P40+ChatGLM2+LoRA
部署环境 系统:CentOS-7CPU: 14C28T显卡:Tesla P40 24G驱动: 515CUDA: 11.7cuDNN: 8.9.2.26目的 验证P40部署可行性,只做验证学习lora方式微调创建环境 conda create --name glm-tuning python3.10 conda activate glm-tuning克隆项目 git clone http…...

调用feign返回错误的数据
bug描述: 在一个请求方法中会调用到feign去获取其他的数据。 List<Demo> list aaaFeignApi.getData(personSelectGetParam);在调用的时候,打断点到feign的地方,数据是存在的,并且有15条。但是返回到上面代码的时候数据就…...
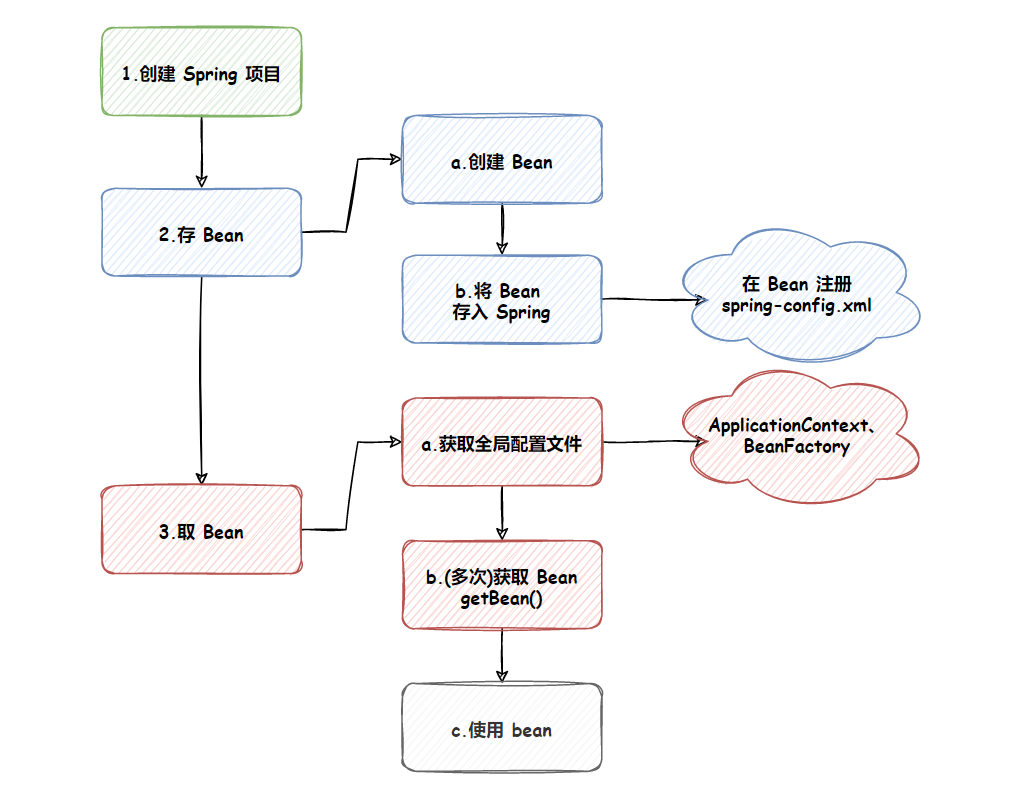
【Spring】(二)从零开始的 Spring 项目搭建与使用
文章目录 前言一、Spring 项目的创建1.1 创建 Maven 项目1.2 添加 Spring 框架支持1.3 添加启动类 二、储存 Bean 对象2.1 创建 Bean2.1 将 Bean 注册到 Spring 容器 三、获取并使用 Bean 对象3.1 获取Spring 上下文3.2 ApplicationContext 和 BeanFactory 的区别3.3 获取指定的…...

redis五种数据类型介绍
、string(字符串) 它师最基本的类型,可以理解为Memcached一模一样的类型,一个key对应一个value。 注意:一个键最大能存储 512MB。 特性:可以包含任何数据,比如jpg图片或者序列化的对象,一个键最大能存储512…...
【JavaEE】Spring Boot - 项目的创建和使用
【JavaEE】Spring Boot 开发要点总结(1) 文章目录 【JavaEE】Spring Boot 开发要点总结(1)1. Spring Boot 的优点2. Spring Boot 项目创建2.1 下载安装插件2.2 创建项目过程2.3 加载项目2.4 启动项目2.5 删除一些没用的文件 3. Sp…...

Git reset、revert用法
reset reset是删除之前的提交记录,所有的提交点都会被清除,我们看下执行前后的git log区别 D:\workspace\android>git log commit 87c1277a57544c53c603b04110e3dde100da8f57 (HEAD -> develop_main) Author: test <test.com> Date: Wed…...

Redis-1
Redis 理论部分 redis 速度快的原因 1、纯内存操作 2、单线程操作,避免了频繁的上下文切换和资源争用问题,多线程需要占用更多的 CPU 资源 3、采用了非阻塞 I/O 多路复用机制 4、提供了非常高效的数据结构,例如双向链表、压缩页表和跳跃…...

【Linux】Linux服务器连接百度网盘:实现上传下载
【Linux】Linux服务器连接百度网盘:实现上传下载 文章目录 【Linux】Linux服务器连接百度网盘:实现上传下载1. 前言2. 具体过程2.1 pip 安装所需包2.2 认证(第一次连接需要认证)2.3 下载所需文件或者目录2.4 其他指令使用2.5 注意…...
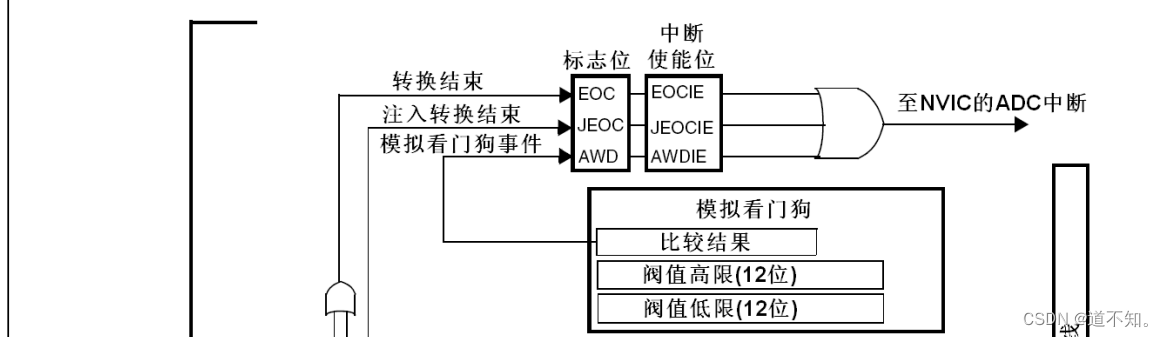
ADC模拟看门狗
如果被ADC转换的模拟电压低于低阀值或高于高阀值,AWD模拟看门狗状态位被设置。阀值位 于ADC_HTR和ADC_LTR寄存器的最低12个有效位中。通过设置ADC_CR1寄存器的AWDIE位 以允许产生相应中断。通过以下函数可以进行配置 void ADC_AnalogWatchdogCmd(ADC_TypeDef* ADCx…...

google谷歌gmail邮箱账号注册手机号无法进行验证怎么办?此电话号码无法用于进行验证 或 此电话号码验证次数太多
谷歌gmail邮箱账号注册手机号无法进行验证怎么办? 使用手机号码注册谷歌gmail邮箱账号时会遇到:此电话号码无法用于进行验证 或 此电话号码验证次数太多。造成注册google谷歌gmail邮箱账号受阻,无法正常完成注册。 谷歌Gmail邮箱账号正确的注册方法与教…...

Spring:IOC技术、Bean、DI
前言 Spring是一个开源的项目,并不是单单的一个技术,发展至今已形成一种开发生态圈。也就是说我们可以完全使用Spring技术完成整个项目的构建、设计与开发。Spring是一个基于IOC和AOP的架构多层j2ee系统的架构。 SpringFramework:Spring框架…...

目标检测与跟踪 (2)- YOLO V8配置与测试
系列文章目录 第一章 目标检测与跟踪 (1)- 机器人视觉与YOLO V8 目标检测与跟踪 (1)- 机器人视觉与YOLO V8_Techblog of HaoWANG的博客-CSDN博客3D物体实时检测、三维目标识别、6D位姿估计一直是机器人视觉领域的核心研究课题&a…...
重构学术文档翻译:PDFMathTranslate如何突破格式保留与公式处理技术瓶颈
重构学术文档翻译:PDFMathTranslate如何突破格式保留与公式处理技术瓶颈 【免费下载链接】PDFMathTranslate PDF scientific paper translation with preserved formats - 基于 AI 完整保留排版的 PDF 文档全文双语翻译,支持 Google/DeepL/Ollama/OpenAI…...

2026网站制作公司到底哪家好?国内主流PC网站建设服务公司排名
2026年1月,最新修订的《网络安全法》正式施行,叠加《网络数据安全管理条例》《个人信息保护法》细则落地,数据合规已成为网站建设的前置准入门槛。据中国互联网协会数据显示,2025年国内中大型企业官网合规整改率仅41.7%࿰…...
)
保姆级教程:用YOLOv8和Python搞定水下模糊图片的目标检测(附完整代码)
水下模糊图像目标检测实战:从YOLOv8模型微调到珊瑚识别系统搭建 水下摄影爱好者常遇到这样的困扰:GoPro拍摄的海洋生物照片总是泛着蓝绿色调,目标轮廓模糊不清。传统图像处理方法往往收效甚微,而深度学习技术为这类问题提供了全新…...

STEP3-VL-10B真实体验:10B参数小模型如何实现92.05分视觉识别?
STEP3-VL-10B真实体验:10B参数小模型如何实现92.05分视觉识别? 1. 引言:小身材大能量的视觉识别专家 当我第一次看到STEP3-VL-10B在MMBench英文视觉识别测试中拿到92.05分时,第一反应是怀疑数据是否有误。毕竟这个成绩不仅远超同…...

PowerToys中文版:三步搞定Windows效率工具的完全汉化体验
PowerToys中文版:三步搞定Windows效率工具的完全汉化体验 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是否曾经因为PowerToys的英文界面…...

一些常见颜色汇总
1 1.1 CVPR2024:Koala序号示例RGBHEX1(244, 204, 204)#F4CCCC2(207, 226, 243)#CFE2F33(252, 229, 205)#FCE5CD序号示例RGBHEX1(217,217,217)#D9D9D92(252,229,205)#FCE5CD 2 2.1 AAAI2025:Stable Mean Teacher for Semi-supervised Video Action Detection序号示例…...

DAMOYOLO-S数据库联动应用:检测结果自动化存储与查询
DAMOYOLO-S数据库联动应用:检测结果自动化存储与查询 你有没有遇到过这样的场景?一个智能安防摄像头,每天24小时不间断地运行,DAMOYOLO-S模型在里面兢兢业业地识别着每一个经过的人和车。但问题是,这些宝贵的检测结果…...
)
GEE实战:手把手教你用Sentinel-2数据计算植被覆盖度(附完整代码与避坑指南)
GEE实战:从零到一掌握Sentinel-2植被覆盖度计算全流程 清晨的阳光透过实验室的窗户洒在桌面上,一位生态学研究生正盯着电脑屏幕发愁——导师要求她在一周内完成研究区域的植被覆盖度分析,但GEE平台上那些晦涩的代码和突如其来的报错信息让她手…...

24小时无人值守:OpenClaw+Phi-3-vision-128k-instruct自动化监控系统
24小时无人值守:OpenClawPhi-3-vision-128k-instruct自动化监控系统 1. 为什么需要自动化监控系统 去年我负责一个内部数据看板项目时,经常遇到凌晨突发故障却无人值守的情况。直到第二天上班才发现问题,损失了宝贵的响应时间。传统监控工具…...

如何快速集成Socket.IO-Client-Swift与SwiftUI:构建现代化实时iOS应用的完整指南
如何快速集成Socket.IO-Client-Swift与SwiftUI:构建现代化实时iOS应用的完整指南 【免费下载链接】socket.io-client-swift 项目地址: https://gitcode.com/gh_mirrors/so/socket.io-client-swift Socket.IO-Client-Swift是一款功能强大的iOS/OS X实时通信库…...