Storm学习之使用官方Docker镜像快速搭建Storm运行环境
文章目录
- 0.前言
- 搭建完的效果
- 1.教程
- 1.1.docker 安装 zookeeper
- 1.2. 安装 storm nimbus
- 1.3.docker 安装 supervisor
- 1.4.docker 安装 storm-ui
- 1.5.查看已经启动的容器
- 1.6.提交topology到 storm集群
- 2.总结
- 3.参考文档
0.前言
Apache Storm 官方也出了Docker 镜像 https://hub.docker.com/_/storm/
本文我们就基于官方镜像搭建一个 Apache Storm 2.4 版本的运行环境,供大家后续学习。
有问题可以参考issue 解决,我的安装过程一路都很顺畅。所以基本上没有看下面是我的详细操作和截图。
可以说网上的乱七八糟的教程不如官方文档来的实在。
如果想用虚拟机搭建,请参考我的上一篇文章《Centos7搭建Apache Storm 集群运行环境》
搭建完的效果
Storm UI虽然是Storm 的非必须组件,但是是非常有用,基本上离不开的组件,它可以展示很多信息,对我们平时排查问题很有帮助,
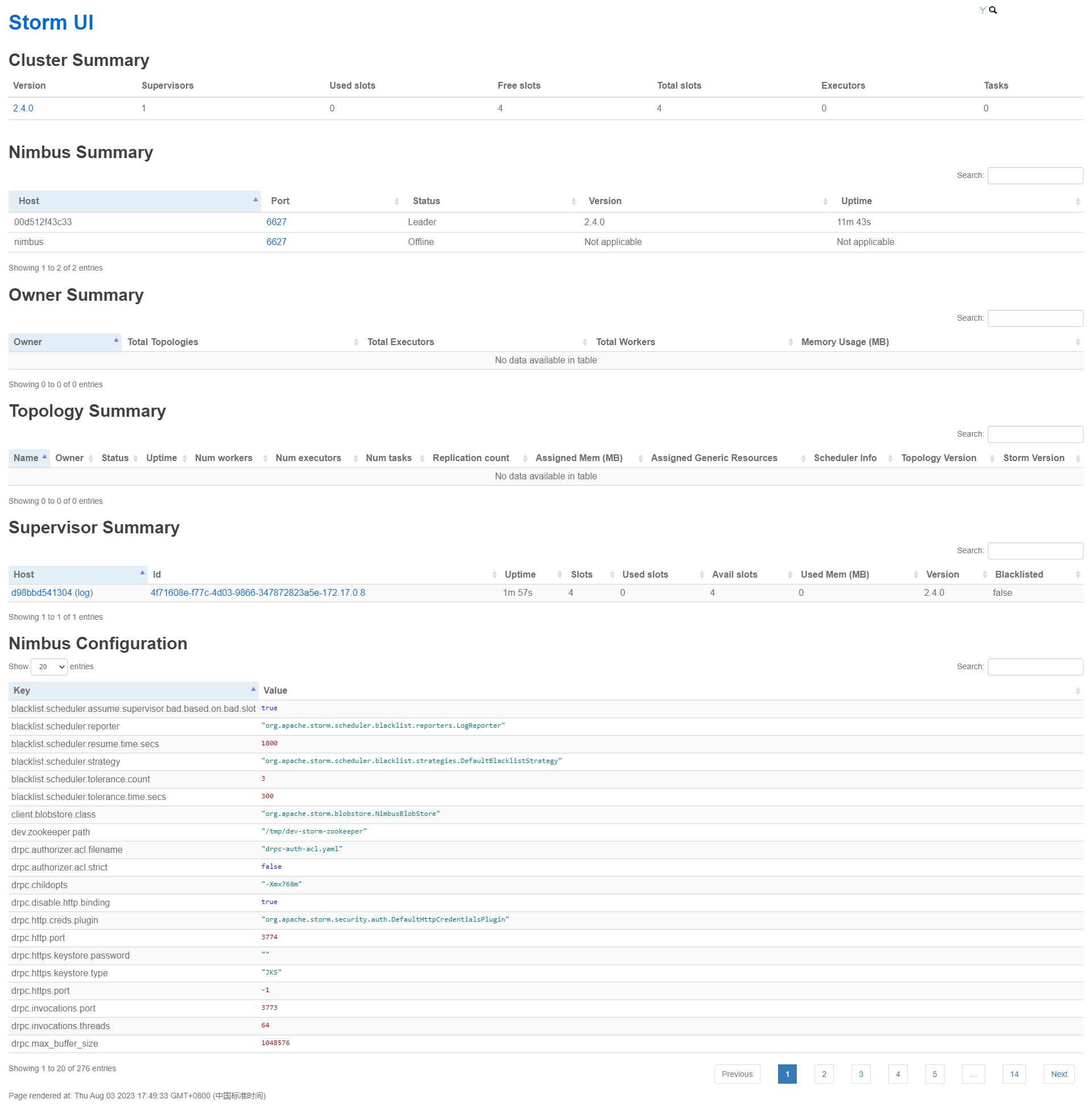
-
拓扑列表:显示当前在Storm集群中运行的所有拓扑的列表。每个拓扑通常会显示其名称、ID、状态和所属的用户。
-
拓扑摘要:提供了关于选定拓扑的详细信息,包括拓扑的名称、ID、状态、拓扑图和组件列表。还可能包括拓扑的启动时间、运行时长和错误信息。
-
组件视图:显示了拓扑中的各个组件及其实例的信息。对于每个组件,它通常会显示组件的ID、类型、输入输出流以及处理该组件的工作进程和任务数量。
-
工作进程视图:提供有关工作进程的详细信息,包括工作进程的ID、主机名、端口号、启动时间、堆内存使用情况、线程数等。
-
任务视图:显示有关任务的信息,包括任务的ID、工作进程、组件、执行状态、错误信息等。可以查看每个任务的日志和统计数据。
-
错误视图:列出了拓扑中发生的任何错误或异常。这包括组件的失败、任务的错误、工作进程的故障等。通常会显示错误的时间戳、类型和详细描述。
-
日志视图:显示了拓扑中各个组件和任务的日志输出。可以查看实时日志或按时间范围过滤日志。
-
统计视图:提供了关于拓扑的性能统计数据。这可能包括拓扑的吞吐量、处理延迟、执行时间、错误计数等指标的图表或表格。
-
配置视图:显示了拓扑的配置参数和属性。可以查看拓扑使用的配置文件以及运行时配置的值。
-
集群概述:提供了有关整个Storm集群的概览信息,包括集群状态、拓扑数量、工作进程数量、任务数量等。
请注意,具体的Storm UI页面内容可能会根据不同的版本和配置有所变化,上述内容仅为一般情况下的解释。
1.教程
1.1.docker 安装 zookeeper
我们选择最新版本的zookeeper
$ docker run -itd --restart always --name ice-zookeeper zookeeper
1.2. 安装 storm nimbus
创建一个名为ice-nimbus的容器,并在其中运行Storm的Nimbus组件。该容器将与一个名为ice-zookeeper的Zookeeper容器相链接,以便Storm Nimbus可以与Zookeeper进行通信。
这一步耗时稍微较长,需要下载镜像。
$ docker run -itd --restart always --name ice-nimbus --link ice-zookeeper:zookeeper storm storm nimbus
1.3.docker 安装 supervisor
创建一个名为ice-supervisor的容器,并在其中运行Storm的Supervisor组件。该容器将与一个名为ice-zookeeper的Zookeeper容器和一个名为ice-nimbus的Nimbus容器相链接,以便Storm Supervisor可以与Zookeeper和Nimbus进行通信。通过--restart always选项,当容器退出时,Docker将自动重新启动该容器,确保Supervisor组件一直处于运行状态。
$ docker run -d --restart always --name ice-supervisor --link ice-zookeeper:zookeeper --link ice-nimbus:nimbus storm storm supervisor

1.4.docker 安装 storm-ui
$ docker run -d -p 8980:8080 --restart always --name ui --link ice-nimbus:nimbus storm storm ui

1.5.查看已经启动的容器
docker ps -a

1.6.提交topology到 storm集群
$ docker run --link ice-nimbus:nimbus -it --rm -v $(pwd)/topology.jar:/topology.jar storm storm jar /topology.jar org.apache.storm.starter.WordCountTopology topology

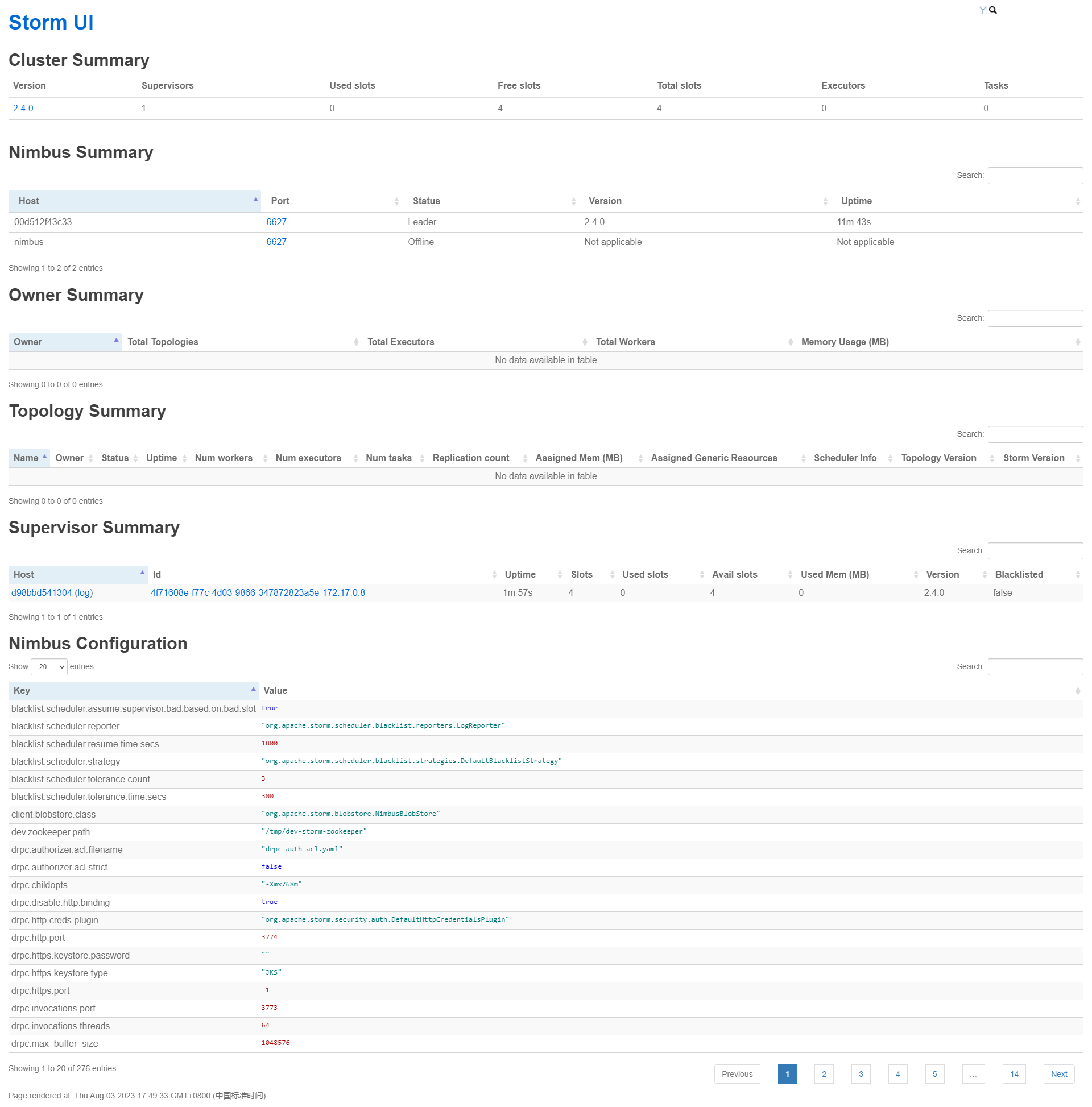
我们可以在StormUI的最后面看到 Nimbus配置参数:
-
worker.profiler.enabled: 是否启用工作进程的性能分析器。在给定的配置中,该值为false,表示禁用性能分析器。 -
worker.profiler.command: 用于启动性能分析器的命令。在给定的配置中,命令为"flight.bash"。 -
worker.profiler.childopts: 传递给性能分析器的JVM参数。在给定的配置中,参数为"-XX:+UnlockCommercialFeatures -XX:+FlightRecorder",用于解锁商业特性并启用Flight Recorder。 -
worker.metrics: 工作进程的度量指标配置。提供了一组度量指标的名称和相应的类。在给定的配置中,包括CGroup内存使用、CGroup内存限制、CGroup CPU使用、CGroup CPU保证等度量指标。 -
worker.max.timeout.secs: 工作进程的最大超时时间,以秒为单位。在给定的配置中,超时时间为600秒。 -
worker.log.level.reset.poll.secs: 重新设置工作进程日志级别的轮询间隔,以秒为单位。在给定的配置中,轮询间隔为30秒。 -
worker.heartbeat.frequency.secs: 工作进程发送心跳的频率,以秒为单位。在给定的配置中,心跳频率为1秒。 -
worker.heap.memory.mb: 工作进程的堆内存大小,以MB为单位。在给定的配置中,堆内存大小为768MB。 -
worker.gc.childopts: 传递给垃圾收集器的JVM参数。在给定的配置中,参数为空字符串,表示没有额外的垃圾收集器参数。 -
worker.childopts: 工作进程的启动选项,包括JVM参数。在给定的配置中,包括一些JVM参数,例如堆内存大小、GC日志的输出路径和格式、堆外内存溢出时的堆转储等。 -
ui.port: Storm UI的端口号。在给定的配置中,端口号为8080。 -
ui.childopts: Storm UI的启动选项,包括JVM参数。在给定的配置中,只指定了最大堆内存大小为768MB。 -
topology.workers: 拓扑的工作进程数。在给定的配置中,工作进程数为1,表示拓扑将在一个工作进程中执行。 -
topology.worker.shared.thread.pool.size: 拓扑工作进程共享线程池的大小。在给定的配置中,线程池大小为4。 -
topology.worker.receiver.thread.count: 拓扑工作进程接收器线程的数量。在给定的配置中,接收器线程数为1。 -
topology.worker.max.heap.size.mb: 拓扑工作进程的最大堆内存大小,以MB为单位。在给定的配置中,最大堆内存大小为768MB。 -
topology.worker.logwriter.childopts: 拓扑工作进程日志写入器的启动选项,包括JVM参数。在给定的配置中,只指定了最大堆内存大小为64MB。 -
topology.tuple.serializer: 拓扑元组的序列化器。在给定的配置中,序列化器为"org.apache.storm.serialization.types.ListDelegateSerializer"。 -
topology.trident.batch.emit.interval.millis: Trident拓扑批量发射间隔的时间间隔,以毫秒为单位。在给定的配置中,间隔为500毫秒。 -
topology.transfer.buffer.size: 拓扑传输缓冲区的大小。在给定的配置中,缓冲区大小为1000。 -
topology.transfer.batch.size: 拓扑传输批量大小。在给定的配置中,批量大小为1。 -
topology.stats.sample.rate: 拓扑配置项解释: -
worker.profiler.enabled: 是否启用工作进程的性能分析器。在给定的配置中,该值为false,表示禁用性能分析器。 -
worker.profiler.command: 用于启动性能分析器的命令。在给定的配置中,命令为"flight.bash"。 -
worker.profiler.childopts: 传递给性能分析器的JVM参数。在给定的配置中,参数为"-XX:+UnlockCommercialFeatures -XX:+FlightRecorder",用于解锁商业特性并启用Flight Recorder。 -
worker.metrics: 工作进程的度量指标配置。提供了一组度量指标的名称和相应的类。在给定的配置中,包括CGroup内存使用、CGroup内存限制、CGroup CPU使用、CGroup CPU保证等度量指标。 -
worker.max.timeout.secs: 工作进程的最大超时时间,以秒为单位。在给定的配置中,超时时间为600秒。 -
worker.log.level.reset.poll.secs: 重新设置工作进程日志级别的轮询间隔,以秒为单位。在给定的配置中,轮询间隔为30秒。 -
worker.heartbeat.frequency.secs: 工作进程发送心跳的频率,以秒为单位。在给定的配置中,心跳频率为1秒。 -
worker.heap.memory.mb: 工作进程的堆内存大小,以MB为单位。在给定的配置中,堆内存大小为768MB。 -
worker.gc.childopts: 传递给垃圾收集器的JVM参数。在给定的配置中,参数为空字符串,表示没有额外的垃圾收集器参数。 -
worker.childopts: 工作进程的启动选项,包括JVM参数。在给定的配置中,包括一些JVM参数,例如堆内存大小、GC日志的输出路径和格式、堆外内存溢出时的堆转储等。 -
ui.port: Storm UI的端口号。在给定的配置中,端口号为8080。 -
ui.childopts: Storm UI的启动选项,包括JVM参数。在给定的配置中,只指定了最大堆内存大小为768MB。 -
topology.workers: 拓扑的工作进程数。在给定的配置中,工作进程数为1,表示拓扑将在一个工作进程中执行。 -
topology.worker.shared.thread.pool.size: 拓扑工作进程共享线程池的大小。在给定的配置中,线程池大小为4。 -
topology.worker.receiver.thread.count: 拓扑工作进程接收器线程的数量。在给定的配置中,接收器线程数为1。 -
topology.worker.max.heap.size.mb: 拓扑工作进程的最大堆内存大小,以MB为单位。在给定的配置中,最大堆内存大小为768MB。 -
topology.worker.logwriter.childopts: 拓扑工作进程日志写入器的启动选项,包括JVM参数。在给定的配置中,只指定了最大堆内存大小为64MB。 -
topology.tuple.serializer: 拓扑元组的序列化器。在给定的配置中,序列化器为"org.apache.storm.serialization.types.ListDelegateSerializer"。 -
topology.trident.batch.emit.interval.millis: Trident拓扑批量发射间隔的时间间隔,以毫秒为单位。在给定的配置中,间隔为500毫秒。 -
topology.transfer.buffer.size: 拓扑传输缓冲区的大小。在给定的配置中,缓冲区大小为1000。 -
topology.transfer.batch.size: 拓扑传输批量大小。在给定的配置中,批量大小为1。 -
topology.stats.sample.rate: 拓扑统计信息的
2.总结
本次我们将storm 使用docker 搭建了运行环境,下个章节,我们使用这个运行环境来运行我们拓扑。写一个最简单的 world count。本次我们就先到这里,大家如果需要继续可以开始写拓扑,尝试自己提交运行。
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;public class WordCountTopology {public static void main(String[] args) {// 创建TopologyBuilder实例TopologyBuilder builder = new TopologyBuilder();// 定义spout(数据源)和bolt(数据处理器)的名称和任务并行度builder.setSpout("word-reader", new WordReaderSpout(), 1);builder.setBolt("word-normalizer", new WordNormalizerBolt(), 2).shuffleGrouping("word-reader");builder.setBolt("word-counter", new WordCounterBolt(), 2).fieldsGrouping("word-normalizer", new Fields("word"));// 创建配置对象并设置一些参数Config config = new Config();config.put("inputFile", "input.txt");config.setDebug(true);// 在本地模式下运行拓扑LocalCluster cluster = new LocalCluster();cluster.submitTopology("word-count-topology", config, builder.createTopology());// 等待一段时间后停止拓扑Utils.sleep(5000);cluster.killTopology("word-count-topology");cluster.shutdown();}
}
3.参考文档
- docker hub storm https://hub.docker.com/_/storm
- Storm 社区 https://github.com/31z4/storm-docker
相关文章:
Storm学习之使用官方Docker镜像快速搭建Storm运行环境
文章目录 0.前言搭建完的效果 1.教程1.1.docker 安装 zookeeper1.2. 安装 storm nimbus1.3.docker 安装 supervisor1.4.docker 安装 storm-ui1.5.查看已经启动的容器1.6.提交topology到 storm集群 2.总结3.参考文档 0.前言 Apache Storm 官方也出了Docker 镜像 https://hub.do…...

【GTest学习】
1. GTest简介: GTest 就是 Google Test, 它是一个免费开源的测试框架, 用于编写测试用 C语言编写的程序(C 程序也能用, 但是需要用 C编译器编译)。gtest的官方网站是:http://code.google.com/p/googletest/ 2.GTest下载与环境搭建: GTest 下…...

[JAVAee]网络通信基础
目录 IP地址 端口号 网络协议 五元组 TCP/IP五层模型 网络互连之间的目的就是为了相互通信,传输数据,是可以不同进程间的基于网络的数据传输. 而IP就可以确定网络通信的双方. IP地址 IP地址主要用于定位标识网络主机或其他网络设备的网络地址.(就像快递的收货地址一般…...

【HDFS】BlockManager#checkRedundancy方法详解
BlockManager#checkRedundancy这个方法只有一处调用点, 就是FSNamesystem#finalizeINodeFileUnderConstruction方法。 TODO:补充FSNamesystem#finalizeINodeFileUnderConstruction方法的调用点。 checkRedundancy方法的参数的BlockCollection对象bc,解释一下,INodeFile类是…...
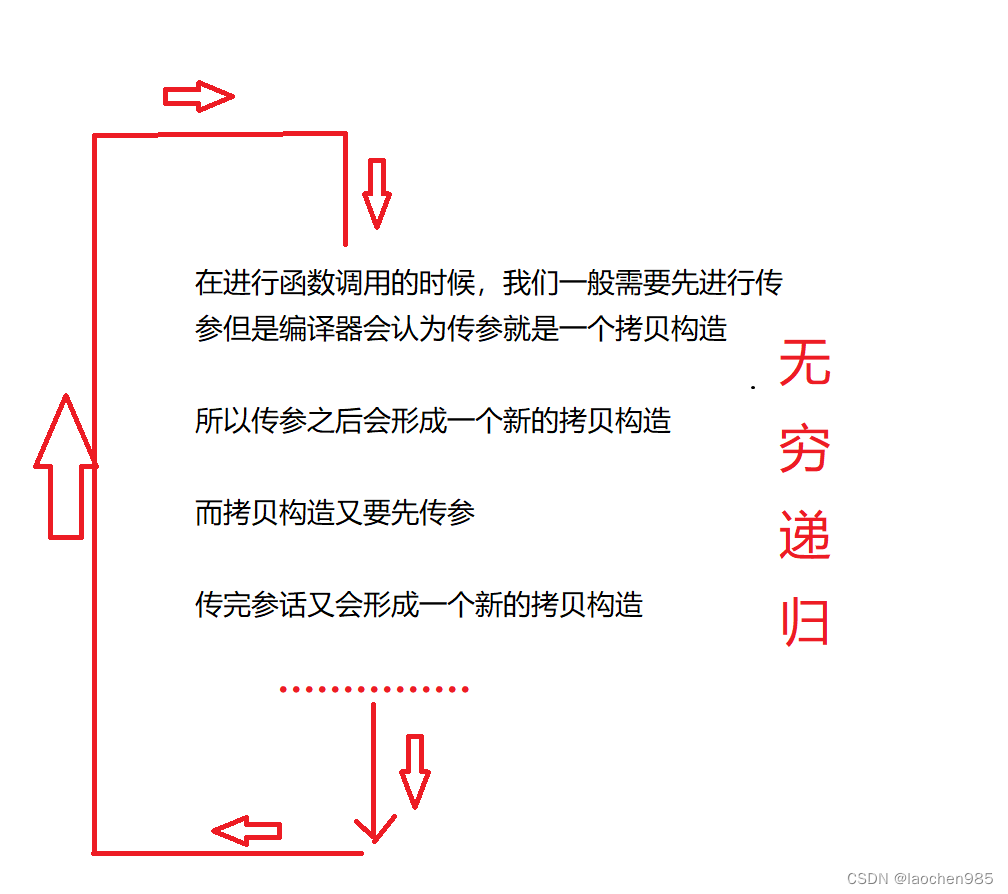
c++ 拷贝构造
我们思考一下这个问题: 观察以下代码,在运行的时候会崩溃 想一想为什么 #include<iostream> using namespace std;//栈类 typedef int DataType; class Stack { public://默认构造:Stack(size_t capacity 3){_array (DataType*)ma…...
-Directives)
MISRA 2012学习笔记(1)-Directives
文章目录 说明Directives2 编译与构建Dir 2.1 3 需求可追溯性Dir 3.1 4 代码设计Dir 4.1Dir 4.2Dir 4.3Dir 4.4Dir 4.5Dir 4.6Dir 4.7Dir 4.8Dir 4.9Dir 4.10Dir 4.11Dir 4.12Dir 4.13 说明 以下等级一般分为三种,建议,必要,强制 建议&#…...
)
升级node版本后vue2的项目node-sass、sass-loader安装报错(14.x升级到16.x)
node升级到16.x版本后,对应的node-sass需要升级到^6.0.0,此时sass-loader的版本需要升级到10.2.0以上 ,具体对应版本规则可参考链接: https://github.com/webpack-contrib/sass-loader/releases?page3 vue2通过vue/cli创建的项目࿰…...

深入理解CSS选择器:选择正确的方式掌控样式与布局
文章目录 CSS 概括CSS 选择器元素选择器(Element Selector)类选择器(Class Selector)ID 选择器(ID Selector)通用选择器(Universal Selector)属性选择器(Attribute Selec…...

qt设置控件的风格样式
设置tablewidget ui.tableWidget_MaterialLibrary->setStyleSheet("QTableView {""color:#DCDCDC;""background-color: #444444;""border: 1px solid #242424;""alternate-background-color:#525252;""gridline-co…...
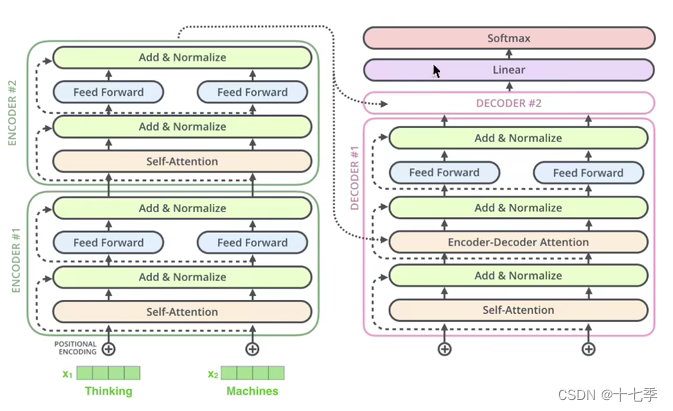
简单易懂的Transformer学习笔记
1. 整体概述 2. Encoder 2.1 Embedding 2.2 位置编码 2.2.1 为什么需要位置编码 2.2.2 位置编码公式 2.2.3 为什么位置编码可行 2.3 注意力机制 2.3.1 基本注意力机制 2.3.2 在Trm中是如何操作的 2.3.3 多头注意力机制 2.4 残差网络 2.5 Batch Normal & Layer Narmal 2.…...

C语言经典小游戏之三子棋(超详解释+源码)
“纵有疾风来,人生不言弃,风乍起,合当奋意向此生。” 今天我们一起来学习一下三子棋小游戏用C语言怎么写出来? 三子棋小游戏 1.游戏规则介绍2.游戏准备3.游戏的实现3.1生成菜单3.2游戏的具体实现3.2.1初始化棋盘3.2.2打印棋盘3.2…...
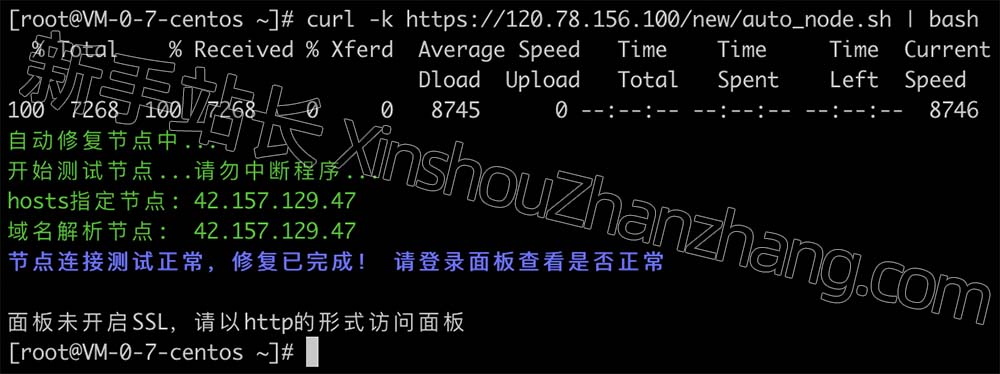
宝塔Linux面板点击SSL闪退打不开?怎么解决?
宝塔Linux面板点击SSL证书闪退如何解决?旧版本的宝塔Linux面板确实存在这种情况,如何解决?升级你的宝塔Linux面板即可。新手站长分享宝塔面板SSL闪退的解决方法: 宝塔面板点击SSL证书闪退解决方法 问题:宝塔Linux面板…...

Problem: 6953. 判断是否能拆分数组
Problem: 6953. 判断是否能拆分数组 文章目录 思路解题方法复杂度Code 思路 针对题目中的以下目标,可以转换寻求数组中是否存在前后两个元素之和>m的情况,如果存在则返回ture,如果不存在则返回false。能这样转换的原因是,如果…...

MobiSys 2023 | 多用户心跳监测的双重成形声学感知
注1:本文系“无线感知论文速递”系列之一,致力于简洁清晰完整地介绍、解读无线感知领域最新的顶会/顶刊论文(包括但不限于 Nature/Science及其子刊; MobiCom, Sigcom, MobiSys, NSDI, SenSys, Ubicomp; JSAC, 雷达学报 等)。本次介绍的论文是:<<MobiSys’23,Multi-User A…...
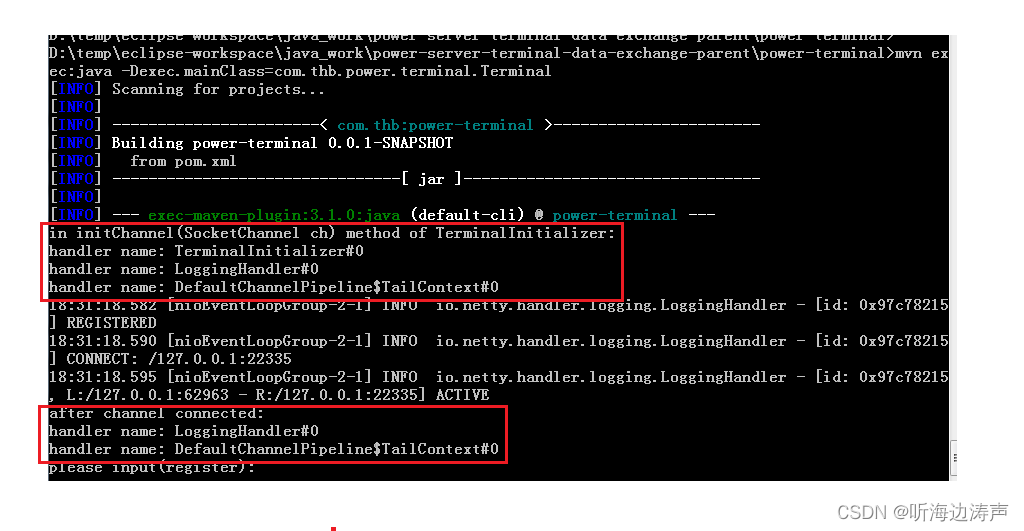
Netty:ChannelInitializer添加到ChannelPipeline完成任务以后会自动删除自己
说明 io.netty.channel.ChannelInitializer是一个特殊的ChannelInboundHandler。它的主要作用是向 Channel对应的ChannelPipeline中增加ChannelHandler。执行完ChannelInitializer的initChannel(C ch)函数以后,ChannelInitializer就会从ChannelPipeline自动删除自己…...

【VUE】项目本地开启https访问模式(vite4)
在实际开发中,有时候需要项目以https形式进行页面访问/调试,下面介绍下非vue-cli创建的vue项目如何开启https 环境 vue: ^3.2.47vite: ^4.1.4 根据官方文档:开发服务器选项 | Vite 官方中文文档 ps:首次操作,不要被类…...

【状态估计】一维粒子滤波研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

设计模式-迭代器模式在Java中使用示例
场景 为开发一套销售管理系统,在对该系统进行分析和设计时,发现经常需要对系统中的商品数据、客户数据等进行遍历, 为了复用这些遍历代码,开发人员设计了一个抽象的数据集合类AbstractObjectList,而将存储商品和客户…...

Maven入职学习
一、什么是Maven? 概念: Maven是一种框架。它可以用作依赖管理工具、构建工具。 它可以管理jar包的规模、jar包的来源、jar包之间的依赖关系。 它的用途就是管理规模庞大的jar包,脱离IDE环境执行构建操作。 具体使用: 工作机…...
【多音音频测试信号】具有指定采样率和样本数的多音信号,生成多音信号的相位降低波峰因数研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

重构暗黑3操作逻辑:D3KeyHelper颠覆式辅助工具的三阶价值验证
重构暗黑3操作逻辑:D3KeyHelper颠覆式辅助工具的三阶价值验证 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper 在快节奏的暗黑破坏神3战斗…...

Swift-All部署教程:快速搭建多模型推理与微调环境
Swift-All部署教程:快速搭建多模型推理与微调环境 1. 从零开始:为什么你需要Swift-All? 如果你正在研究大模型,或者想把大模型用在实际项目里,大概率会遇到这几个头疼的问题: 模型太多,下载太…...

缓存穿透的解决方式?—布隆过滤器
在技术领域,我们常常被那些闪耀的、可见的成果所吸引。今天,这个焦点无疑是大语言模型技术。它们的流畅对话、惊人的创造力,让我们得以一窥未来的轮廓。然而,作为在企业一线构建、部署和维护复杂系统的实践者,我们深知…...

hadoop+Spark+django基于Spark的影视作品排行榜数据分析和可视化
前言 本研究基于 Spark 框架,构建了一套与可视化系统,旨在为影视行业相关方提供有力支持。研究结合了网络爬虫、Spark 框架、Vue 和 Echarts 等技术,并采用文献研究法展开。 在数据采集阶段,使用 Python 爬虫从多个数据源获取…...

Atlas800T A2上部署Qwen2.5-Omni-7B音频模型:从驱动安装到vllm-ascend服务启动的保姆级避坑记录
Atlas800T A2服务器部署Qwen2.5-Omni-7B音频模型全流程实战指南 在昇腾Atlas800T A2服务器上部署多模态大模型Qwen2.5-Omni-7B,对于需要处理音频转文字任务的开发者而言,既是技术挑战也是效率提升的关键一步。本文将带你从零开始,逐步完成从硬…...

Z-Image Turbo在工业设计中的应用:产品概念图生成
Z-Image Turbo在工业设计中的应用:产品概念图生成 1. 引言 工业设计师的日常工作中,最耗时但又最关键的环节是什么?答案往往是概念图的创作和渲染。传统的工作流程中,设计师需要先手绘草图,然后在专业软件中建模、渲…...

LingBot-Depth案例分享:修复SLAM生成的稀疏深度,效果实测
LingBot-Depth案例分享:修复SLAM生成的稀疏深度,效果实测 1. 引言:SLAM深度修复的挑战 在机器人导航和增强现实应用中,SLAM(同步定位与地图构建)系统生成的深度图往往存在一个显著问题:稀疏性…...

旧手机秒变电脑摄像头:DroidCam创新应用指南
旧手机秒变电脑摄像头:DroidCam创新应用指南 【免费下载链接】droidcam GNU/Linux/nix client for DroidCam 项目地址: https://gitcode.com/gh_mirrors/dr/droidcam 在远程办公与在线协作日益普及的今天,高质量摄像头成为必备工具。然而专用摄像…...

像素语言·跨维传送门参数详解:Hunyuan-MT-7B引擎温度/长度/对齐策略调优指南
像素语言跨维传送门参数详解:Hunyuan-MT-7B引擎温度/长度/对齐策略调优指南 1. 工具概览与核心价值 像素语言跨维传送门(Pixel Language Portal)是基于Tencent Hunyuan-MT-7B引擎构建的创新翻译工具,它将传统翻译体验重构为16-bit像素冒险风格。不同于…...

忍者像素绘卷微信小程序云开发实践:Serverless生成服务架构
忍者像素绘卷微信小程序云开发实践:Serverless生成服务架构 1. 项目背景与核心价值 忍者像素绘卷是一款基于微信小程序平台的云端图像生成工具,采用Serverless架构实现。它将传统漫画创作与AI技术相结合,为用户提供简单高效的像素艺术创作体…...