[oneAPI] BERT
[oneAPI] BERT
- BERT
- 训练过程
- Masked Language Model(MLM)
- Next Sentence Prediction(NSP)
- 微调
- 总结
- 基于oneAPI代码
比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel® DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
BERT
BERT全称是Bidirectional Encoder Representations from Transformers,是google最新提出的NLP预训练方法,在大型文本语料库(如维基百科)上训练通用的“语言理解”模型,然后将该模型用于我们关心的下游NLP任务(如分类、阅读理解)。
BERT优于以前的方法,因为它是用于预训练NLP的第一个无监督,深度双向系统,从名字我们能看出该模型两个核心特质:依赖于Transformer以及双向。它直接颠覆了人们对Pretrained model的理解。尽管Bert模型有多得骇人听闻的参数,但是我们可以直接借助迁移学习的想法使用已经预训练好的模型参数,并根据自己的实际任务进行微调(fine-tuning)。论文的结果表明,与单向语言模型相比,双向训练的语言模型可以把握更深的语言上下文信息。
BERT 的思想其实很大程度上来源于 CBOW 模型,如果从准确率上说改进的话,BERT 利用更深的模型,以及海量的语料,得到的 embedding 表示,来做下游任务时的准确率是要比 word2vec 高不少的。实际上,这也离不开模型的“加码”以及数据的“巨大加码”。再从方法的意义角度来说,BERT 的重要意义在于给大量的 NLP 任务提供了一个泛化能力很强的预训练模型,而仅仅使用 word2vec 产生的词向量表示,不仅能够完成的任务比 BERT 少了很多,而且很多时候直接利用 word2vec 产生的词向量表示给下游任务提供信息,下游任务的表现不一定会很好,甚至会比较差。
训练过程
BERT 使用 Transformer,这是一种注意力机制,可以学习文本中单词(或sub-word)之间的上下文关系。Transformer 包括两个独立的机制——一个读取文本输入的Encoder和一个为任务生成预测的Decoder。由于 BERT 的目标是生成语言模型,因此只需要Encoder。
与顺序读取文本输入(从左到右/从右到左)的单向(directional)模型相反,Transformer 的Encoder一次读取整个单词序列。因此它被认为是双向(bi-directional)的,尽管更准确地说它是非定向的(non- irectional)。这个特性允许模型根据单词的所有上下文来学习单词在上下文中的embedding。
在训练语言模型时,首先要定义预测目标。许多模型预测序列中的下一个单词, 例如“The child came home from ___”。这是一种从本质上限制上下文学习的单向方法。
为了克服这个问题,BERT是如何做预训练的呢?有两个任务:一是 Masked Language Model(MLM);二是 Next Sentence Prediction(NSP)。在训练BERT的时候,这两个任务是同时训练的。所以,BERT的损失函数是把这两个任务的损失函数加起来的,是一个多任务训练
Masked Language Model(MLM)
为了解决只能利用单向信息的问题,BERT使用的是Mask语言模型而不是普通的语言模型。Mask语言模型有点类似与完形填空——给定一个句子,把其中某个词遮挡起来,让人猜测可能的词。这里会随机的Mask掉15%的词,然后让BERT来预测这些Mask的词,通过调整模型的参数使得模型预测正确的概率尽可能大,这等价于交叉熵的损失函数。这样的Transformer在编码一个词的时候必须参考上下文的信息。
但是这有一个问题:在Pretraining Mask LM时会出现特殊的Token [MASK],但是在后面的fine-tuning时却不会出现,这会出现Mismatch的问题。因此BERT中,如果某个Token在被选中的15%个Token里,则按照下面的方式随机的执行:
- 80%的概率替换成[MASK],比如my dog is hairy → my dog is [MASK]
- 10%的概率替换成随机的一个词,比如my dog is hairy → my dog is apple
- 10%的概率替换成它本身,比如my dog is hairy → my dog is hairy
这样做的好处是,BERT并不知道[MASK]替换的是哪一个词,而且任何一个词都有可能是被替换掉的,比如它看到的apple可能是被替换的词。这样强迫模型在编码当前时刻的时候不能太依赖于当前的词,而要考虑它的上下文,甚至更加上下文进行”纠错”。比如上面的例子模型在编码apple是根据上下文my dog is应该把apple(部分)编码成hairy的语义而不是apple的语义。
Next Sentence Prediction(NSP)
Next Sentence Prediction是更关注于两个句子之间的关系。与Masked Language Model任务相比,Next Sentence Prediction更简单些。
在BERT训练过程中,模型的输入是一对句子<sentence1,sentence2>,并学习预测sentence2是否是原始文档中的sentence1的后续句子。在训练期间,50% 的输入是一对连续句子,而另外 50% 的输入是从语料库中随机选择的不连续句子。
为了帮助模型区分训练中的两个句子是否是顺序的,输入在进入模型之前按以下方式处理:
- 在第一个句子的开头插入一个 [CLS] 标记,在每个句子的末尾插入一个 [SEP] 标记。
- 词语的embedding中加入表示句子 A 或句子 B 的句子embedding。
- 加入类似Transformer中的Positional Embedding。
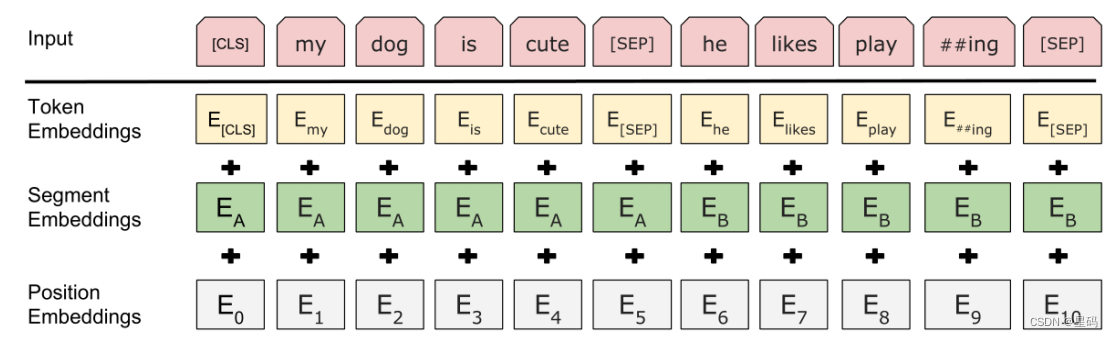
BERT的输入部分是个线性序列,两个句子通过分隔符 [SEP] 分割,最前面和最后增加两个标识符号。每个单词有三个embedding:位置信息position embedding,这是因为NLP中单词顺序是很重要的特征,需要在这里对位置信息进行编码;单词token embedding,这个就是我们之前一直提到的单词embedding;第三个是句子segment embedding,因为前面提到训练数据都是由两个句子构成的,那么每个句子有个句子整体的embedding项对应给每个单词。把单词对应的三个embedding叠加,就形成了Bert的输入。
BERT 模型通过对 MLM 任务和 NSP 任务进行联合训练,使模型输出的每个字/词的向量表示都能尽可能全面、准确地刻画输入文本(单句或语句对)的整体信息,为后续的微调任务提供更好的模型参数初始值。
微调
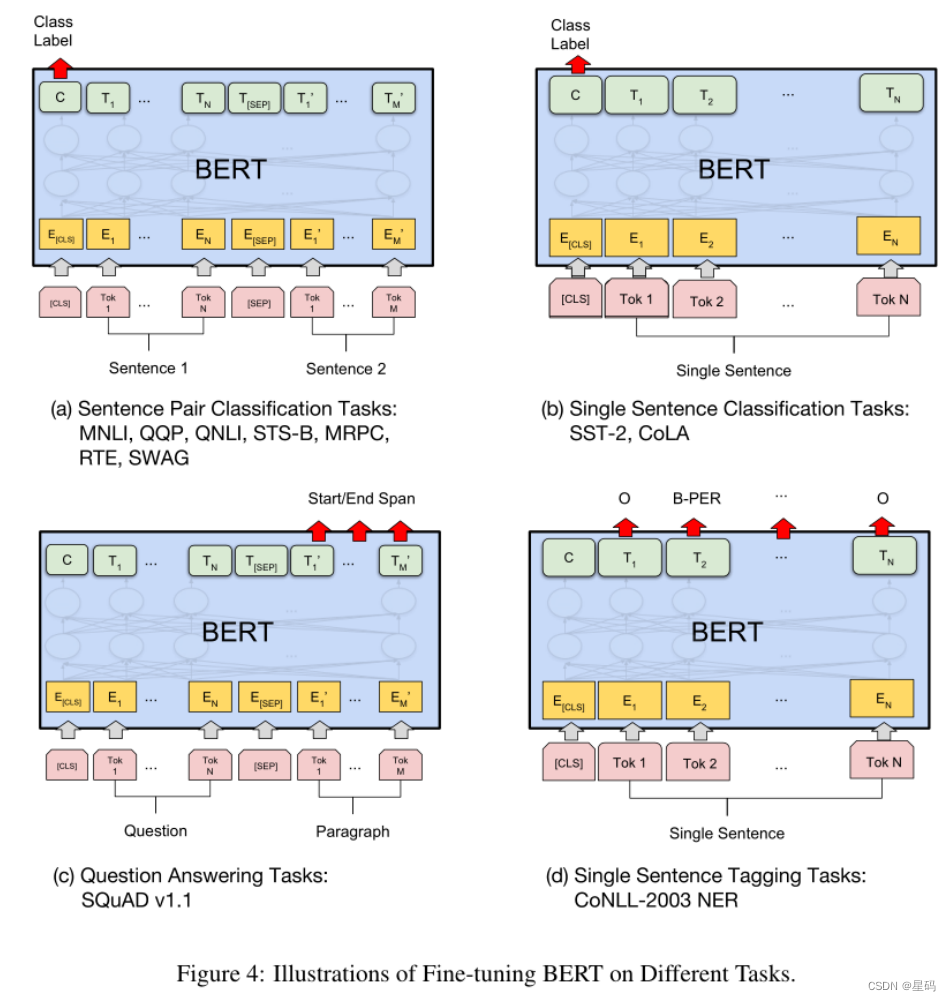
BERT 在下游任务中经过微小的改动(Fine-tuning),比如增加网络层,就可以用于各种各样的语言任务。
与 NSP 任务类似,通过在 [CLS] 标记的 Transformer 输出顶部添加分类层,就可以完成诸如情感分析之类的分类任务。在问答任务(例如 SQuAD v1.1)中,会收到一个关于文本序列的问题,并需要在序列中标记答案。使用 BERT,可以通过学习标记答案开始和结束的两个额外向量来训练问答模型。在命名实体识别 (NER) 中,接收文本序列,并需要标记文本中出现的各种类型的实体(人、组织、日期等)。使用 BERT,可以通过将每个标记的输出向量输入到预测 NER 标签的分类层来训练 NER 模型。
总结
从模型或者方法角度看,BERT借鉴了ELMo,GPT及CBOW,主要提出了 MLM 及 NSP 两种训练方法,但是这里NSP任务基本不影响大局,而MLM明显借鉴了CBOW的思想。BERT是两阶段模型,第一阶段双向语言模型预训练,第二阶段采用具体任务Fine-tuning或者做特征集成。BERT最大的亮点在于效果好及普适性强,几乎所有NLP任务都可以套用BERT这种两阶段解决思路,而且效果应该会有明显提升。
本质上预训练是通过设计好一个网络结构来做语言模型任务,然后把大量甚至是无穷尽的无标注的自然语言文本利用起来,预训练任务把大量语言学知识抽取出来编码到网络结构中,当手头任务带有标注信息的数据有限时,这些先验的语言学特征当然会对手头任务有极大的特征补充作用,因为当数据有限的时候,很多语言学现象是覆盖不到的,泛化能力就弱,集成尽量通用的语言学知识自然会加强模型的泛化能力。如何引入先验的语言学知识其实一直是NLP尤其是深度学习场景下的NLP的主要目标之一,不过一直没有太好的解决办法,而ELMo/GPT/BERT的这种两阶段模式看起来无疑是解决这个问题自然又简洁的方法,这也是这些方法的主要价值所在。
基于oneAPI代码
import intel_extension_for_pytorch as ipexoptimizer = torch.optim.AdamW(optimizer_grouped_parameters, lr=lr)#调用套件,改进模型的优化器
model, optimizer = ipex.optimize(model, optimizer=optimizer)
相关文章:
[oneAPI] BERT
[oneAPI] BERT BERT训练过程Masked Language Model(MLM)Next Sentence Prediction(NSP)微调 总结基于oneAPI代码 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517 Intel DevCloud for oneAPI&…...

F1-score解析
报错:valueError: Target is multiclass but average‘binary’. Please choose another average setting, one of 原因:使用from sklearn.metrics import f1_score多类别计算F1-score时报错,改函数的参数即可,如:f1_s…...
windows11下配置vscode中c/c++环境
本文默认已经下载且安装好vscode,主要是解决环境变量配置以及编译task、launch文件的问题。 自己尝试过许多博客,最后还是通过这种方法配置成功了。 Linux(ubuntu 20.04)配置vscode可以直接跳转到配置task、launch文件,不需要下载mingw与配…...

Max Sum
一、题目 Given a sequence a[1],a[2],a[3]…a[n], your job is to calculate the max sum of a sub-sequence. For example, given (6,-1,5,4,-7), the max sum in this sequence is 6 (-1) 5 4 14. Input The first line of the input contains an integer T(1<T<…...
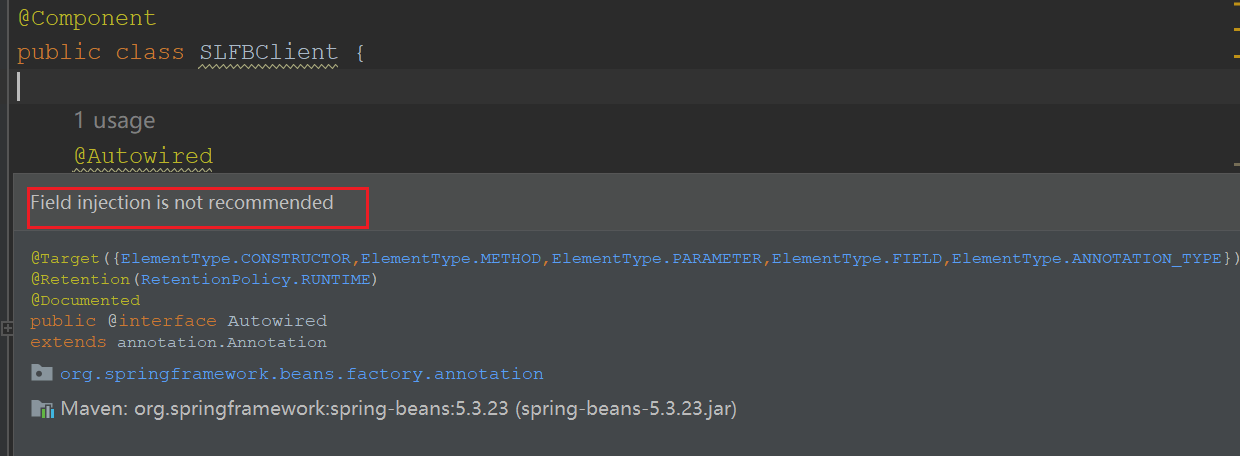
Field injection is not recommended
文章目录 1. 引言2. 不推荐使用Autowired的原因3. Spring提供了三种主要的依赖注入方式3.1. 构造函数注入(Constructor Injection)3.2. Setter方法注入(Setter Injection)3.3. 字段注入(Field Injection) 4…...
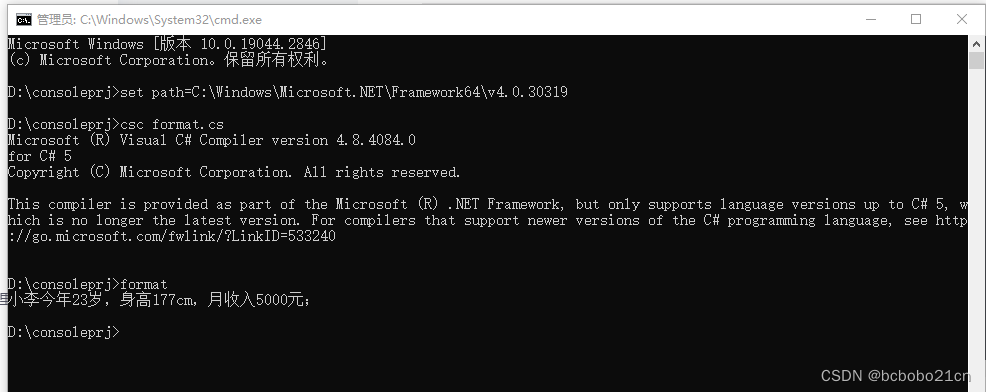
C#字符串占位符替换
using System;namespace myprog {class test{static void Main(string[] args){string str1 string.Format("{0}今年{1}岁,身高{2}cm,月收入{3}元;", "小李", 23, 177, 5000);Console.WriteLine(str1);Console.ReadKey(…...
ChatGPT等人工智能编写文章的内容今后将成为常态
BuzzFeed股价上涨200%可能标志着“转向人工智能”媒体趋势的开始。 周四,一份内部备忘录被华尔街日报透露BuzzFeed正计划使用ChatGPT聊天机器人-风格文本合成技术来自OpenAI,用于创建个性化盘问和将来可能的其他内容。消息传出后,BuzzFeed的…...
)
【Sklearn】基于梯度提升树算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于梯度提升树算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理 梯度提升树(Gradient Boosting Trees)是一种集成学习方法,用于解决分类和回归问题。它通过将多个弱学习器(通常…...

什么叫做云计算?
相信大多数人对云计算或者是云服务的认识还停留在仅仅听过这个名词,但是对其真正的定义或者意义还不甚了解的层面。甚至有些技术人员,如果日常的业务不涉及到云服务,可能对其也只是一知半解的程度。首先云计算准确的讲只是云服务中的一部分&a…...

深度学习Batch Normalization
批标准化(Batch Normalization,简称BN)是一种用于深度神经网络的技术,它的主要目的是解决深度学习模型训练过程中的内部协变量偏移问题。简单来说,当我们在训练深度神经网络时,每一层的输入分布都可能会随着…...

el-table实现懒加载(el-table-infinite-scroll)
2023.8.15今天我学习了用el-table对大量的数据进行懒加载。 效果如下: 1.首先安装: npm install --save el-table-infinite-scroll2 2.全局引入: import ElTableInfiniteScroll from "el-table-infinite-scroll";// 懒加载 V…...

vueRouter回顾
关于vueRouter的两种路由模式 “history” 模式使用正常的 URL 格式,例如 https://example.com/path。“hash” 模式将路由信息添加到 URL 的哈希部分(#)后面,例如 https://example.com/#/path。 1、history模式:没有…...

大规模无人机集群算法flocking(蜂群)
matlab2016b正常运行...
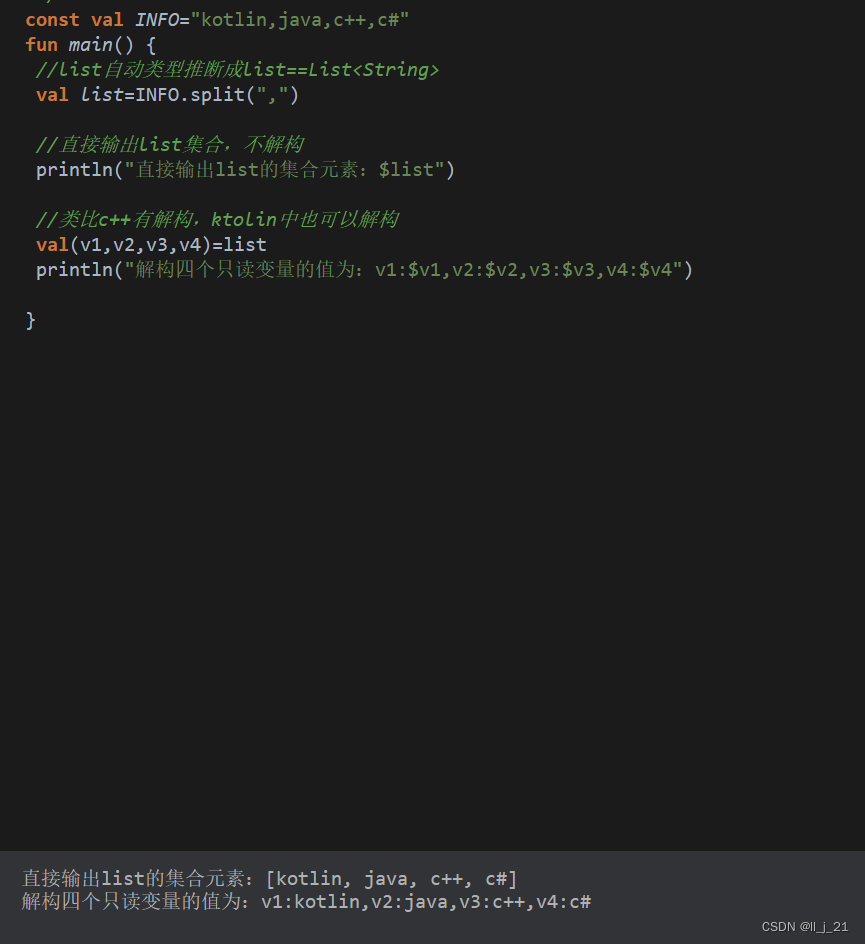
【第三阶段】kotlin语言的split
const val INFO"kotlin,java,c,c#" fun main() {//list自动类型推断成listList<String>val listINFO.split(",")//直接输出list集合,不解构println("直接输出list的集合元素:$list")//类比c有解构,ktoli…...
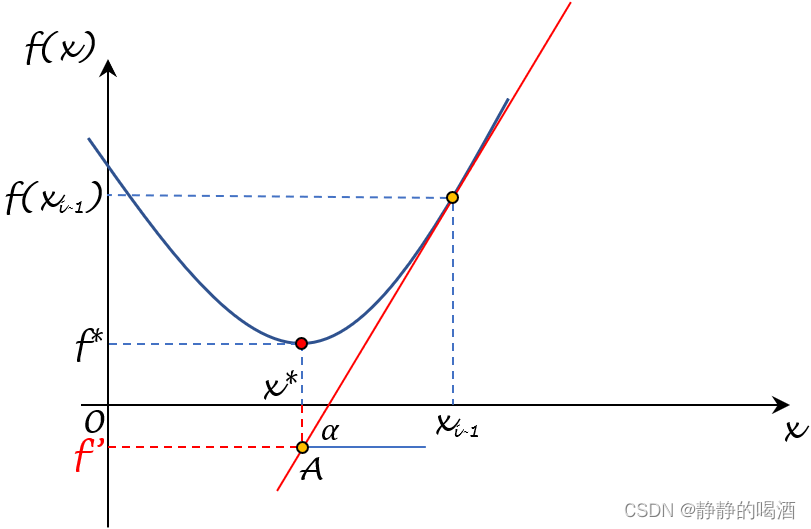
机器学习笔记值优化算法(十四)梯度下降法在凸函数上的收敛性
机器学习笔记之优化算法——梯度下降法在凸函数上的收敛性 引言回顾:收敛速度:次线性收敛二次上界引理 梯度下降法在凸函数上的收敛性收敛性定理介绍证明过程 引言 本节将介绍梯度下降法在凸函数上的收敛性。 回顾: 收敛速度:次…...
iphone拷贝照片中间带E自动去重软件,以及java程序如何打包成jar和exe
文章目录 一、前提二、问题描述三、原始处理方式四、程序处理4.1 java程序如何打包exe4.1.1 首先打包jar4.1.2 开始生成exe4.1.3 软件使用方式 4.2 更换图标4.2.1 更换swing的打包jar图标4.2.2 更换exe图标 4.3 如何使生成的exe在没有java环境的电脑上运行4.3.1 Inno Setup打包…...

不同分类器对数据的处理
"""基于鸢尾花的不同分类器的效果比对:step1:准备数据;提取数据的特征向量X,Y将Y数据采用LabelEncoder转化为数值型数据;step2:将提取的特征向量X,Y进行拆分(训练集与测试集)step3:构建不同分类器并设置参数,例如:…...

十面骰子、
十面骰子(一): v 有一个十面的骰子,每一面分别为1-10,不断投掷骰子,投10000次,统计每一面1-10出现的次数或概率. v 提示:可用rand()产生1-10之间的随机数,再统计1-10出现的机会,存放于数组里,…...
IDE的下载和使用
IDE 文章目录 IDEJETBRAIN JETBRAIN 官网下载对应的ide 激活方式 dxm的电脑已经把这个脚本下载下来了,脚本是macjihuo 以后就不用买了...

华为OD机试真题【字母组合】
1、题目描述 【字母组合】 数字0、1、2、3、4、5、6、7、8、9分别关联 a~z 26个英文字母。 0 关联 “a”,”b”,”c” 1 关联 “d”,”e”,”f” 2 关联 “g”,”h”,”i” 3 关联 “j”,”k”,”l” 4 关联 “m”,”n”,”o” 5 关联 “p”,”q”,”r” 6 关联 “s”,”t” 7…...
)
机器学习---监督学习入门实验全攻略(小白友好版)
新晋码农一枚,小编会定期整理一些写的比较好的代码和知识点,作为自己的学习笔记,试着做一下批注和补充,转载或者参考他人文献会标明出处,非商用,如有侵权会删改!欢迎大家斧正和讨论!…...

RAG + Agent = 王炸组合:知识增强型Agent详解
完整版合集、面试题库、项目实战,全网同名【图解 AI 系列】前几篇文章我们讲了Agent的核心能力:调用工具、记忆系统、规划能力、多Agent协作。但有一个问题一直没解决:Agent的知识从哪来? 大模型的知识是训练时学到的,…...

Steam协议逆向实战:NetHook2与SteamKit2协同分析
1. 这不是“抓包”,而是逆向理解Steam通信协议的起点很多人第一次听说“NetHook2 SteamKit2”组合时,下意识会把它等同于Wireshark抓HTTP流量——点开Steam客户端,随便点个好友头像,抓一堆TCP包,然后对着十六进制窗口…...

MQTTClient技术深度解析:嵌入式物联网通信的高性能解决方案
MQTTClient技术深度解析:嵌入式物联网通信的高性能解决方案 【免费下载链接】mqttclient A high-performance, high-stability, cross-platform MQTT client, developed based on the socket API, can be used on embedded devices (FreeRTOS / LiteOS / RT-Thread …...

谷歌“反重力”工具更新强行替换软件,用户恢复工作困难重重!
谷歌“反重力”工具更新强行替换软件,用户恢复工作困难重重!2026年5月21日,原本打算用“反重力”工具工作的用户,遭遇了谷歌的意外安排。前一天,谷歌在2026年I/O开发者大会上推出“反重力”工具新版本,将其…...
)
树莓派Zero 2W + 0.96寸OLED屏保姆级接线与配置教程(附I2C开启与Python库安装)
树莓派Zero 2W与0.96寸OLED屏从接线到显示的完整实战指南 第一次拿到树莓派Zero 2W和0.96寸OLED屏时,那种既兴奋又忐忑的心情我至今记得——这么小的板子真能驱动屏幕吗?接线会不会烧毁设备?经过多次实践和踩坑,我整理出这份真正适…...

从 0 到 1 搭建 RuoyiOffice:30 分钟跑通后端+前端+移动端
从 0 到 1 搭建 RuoyiOffice:30 分钟跑通后端前端移动端 🌐 演示地址:http://ruoyioffice.com | 📦 源码1:https://gitcode.com/zhouzhongyan/ruoyi-office-vben.git | 📦 源码2:https://gitcod…...

AI辅助编程:发展现状、效率评估与未来展望
引言:AI如何重塑编程范式? 在过去的几年里,人工智能(AI)正以前所未有的速度渗透到软件开发的各个角落。从最初的代码补全工具,到如今能够理解复杂需求、生成完整函数甚至设计系统架构的智能体,AI辅助编程已经从科幻概念演变为开发者日常工作中不可或缺的“副驾驶”。它…...

Rust-Bio 生物信息学库入门指南:5个简单步骤快速上手
Rust-Bio 生物信息学库入门指南:5个简单步骤快速上手 【免费下载链接】rust-bio This library provides implementations of many algorithms and data structures that are useful for bioinformatics. All provided implementations are rigorously tested via co…...

AI部署风险评估:94%准确率为何引发生产灾难
1. 这不是AI的失败,是风险认知体系的塌方 “94%准确率”——这个数字像一枚镀金勋章,挂在每个技术团队的功劳簿上。它出现在季度汇报PPT第一页,写进投资人尽调材料的核心指标栏,甚至被印在内部庆功蛋糕的奶油裱花里。可当这枚勋章…...