大语言模型之二 GPT发展史简介
得益于数据、模型结构以及并行算力的发展,大语言模型应用现今呈井喷式发展态势,大语言神经网络模型成为了不可忽视的一项技术。
GPT在自然语言处理NLP任务上取得了突破性的进展,扩散模型已经拥有了成为下一代图像生成模型的代表的潜力,它具有精度更高、可扩展性和并行性,无论是质量还是效率均有所提升,Transformer和扩散模型作为AIGC方向的当红选手,主要原因并不是本身效率更高(比如更少的参数得到更好的效果)而是带来了可扩展性和并行性,即大力出奇迹有了可以发力的方法。
关于Transformer及基于pytorch实现的翻译toy例子,参靠博客
自2012年以来的AI浪潮主要有三个重要特性:
- 通用性:一种架构往往可以解决多个问题,同一套模型既能处理文字,也能处理图片
- 能力强大:神经网络和深度学习远远超出了传统方法,可以实现媲美人类的能力,并且在一些特定任务上已经超过人类
- 可扩展性:大力出奇迹,模型越大性能越强(当然应用于大模型的架构也在不断进化)
本篇主要介绍大语言模型2017年及以后的发展史,这一年提出了奠定了当今的大语言模型神经网络结构基础基石,而chatGPT的推出,似乎很可能是AI界的奇点,这一事件极有可能改写人类历史。所以花一篇幅介绍这一技术发展史还是很有意义的。
做大语言模型技术和相关应用的公司和应用都呈现一个井喷的发展态势,从huggingface官网打分链接排行榜可以查看最新的开源大语言模型情况。从当前来看Meta的LlaMA很有可能是第一个最成功的开源商用大语言模型。

LlaMA放到后面再说,先从发展的时间史看大语言模型的发展历史。
发展简短历史
这里以影响力较大的模型为例,因为很多大语言模型都是闭源的,而这些闭源的模型都没有能够超过同期OpenAI的模型,所以不再这里列出了。开源大语言模型最好的目前是LLaMA,这张图中这两种模型的进化史代表整体大语言模的发展史。

2017年谷歌提出的Transformer是针对机器翻译的seq2seq的Encoder-decoder模型,而这一模型正巧被2015年底成立的OpenAI公司看到,当时OpenAI公司联合创始人及首席科学家伊尔亚-苏茨克维看到,从伊尔亚-苏茨克和黄仁勋在GPT-4发布会后第二天的公开对话可以看到,其实OpenAI早就有大模型、大数据实现智能的认知,而Transformer这一架构非常适合大算力计算,所以自然而然的就被OpenAI采用了。
从如今的发展情况来看,OpenAI似乎想把神经网络发展成真正意义上的人工智能,首先是训练文本的神经网络模型,其从网上等各种渠道收集了大量的文本数据,这些文本数据本质上是世界的一种映射,OpenAI是想通过这一层映射关系,让模型理解世界,然后在GPT-4又提出了多模态模型,不仅仅能够处理文本,还可以处理图片,OpenAI的目的是将人类视觉能力赋予模型,让其能够从视觉和文字融合映射的维度去理解世界。
表1:历代GPT的发布时间,参数量以及训练量
| 模型 | 发布时间 | 层数 | 头数 | 词向量长度 | 参数量 | 预训练数据量 |
|---|---|---|---|---|---|---|
| GPT-1 | 2018 年 6 月 | 12 | 12 | 768 | 1.17 亿 | 约 5GB |
| BERT base/large | 2018年10月 | 12/24 | 12/16 | 1.10亿/3.4亿 | ||
| GPT-2 | 2019 年 2 月 | 48 | - | 1600 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 96 | 96 | 12888 | 1,750 亿 | 45TB |
| GPT3.5 | ||||||
| LLaMA | 2023年2月 | 70亿/130亿/330亿/650亿 | 4.5TB | |||
| LLaMA-2 | 2023年7月 | 70亿~700亿 | 6.3TB |
GPT
GPT,即Generative Pre-trained Transformer,是基于2017年Google提出Transformer结构的解码器部分为模型基础结构的一种生成预训练模型。Transformer是Google提出的一种基于自注意力机制的新型神经网络架构,目前自然语言处理方向基本都是采用这一架构,这一架构的有点在于完全摒弃了传统的循环结构,取而代之的是通过注意力机制来计算模型的输入输出的隐含表示。不熟悉Transformer的结构见博客《》一文。
目前已经公布论文的有文本预训练GPT-1,GPT-2,GPT-3,chatGPT,GPT-4是一个多模态模型(截止2023年7月无官宣论文),以及图像预训练iGPT。OpenAI的大语言模型起初也是众多语言模型中的一种,一点也并不显眼直到GPT-3的发布,让业界认知到模型大到一定程度,其记忆性和泛化性可以同时兼顾且达到质变。
GPT 使用 Transformer 的 Decoder 结构,并对 Transformer Decoder 进行了一些改动,原本的 Decoder 包含了两个 Multi-Head Attention 结构,GPT 只保留了 Mask Multi-Head Attention,如下图所示。
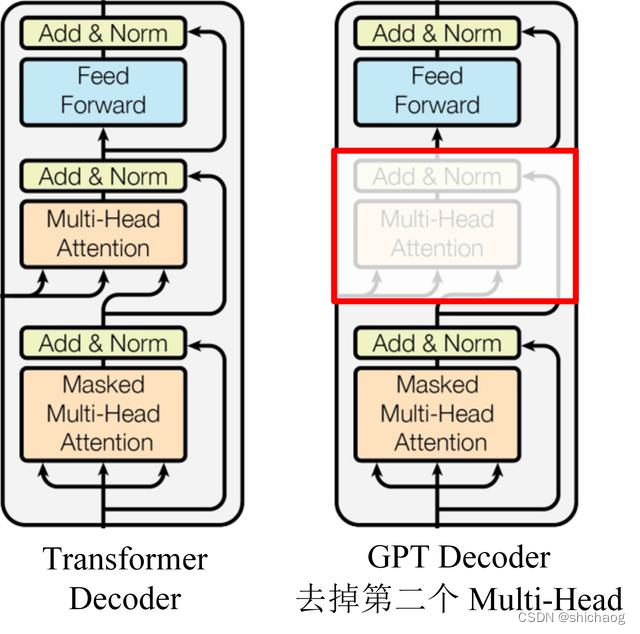
GPT 使用句子序列预测下一个单词,因此要采用 Mask Multi-Head Attention 对单词的下文遮挡,防止信息泄露。例如给定一个句子包含4个单词 [A, B, C, D],GPT 需要利用 A 预测 B,利用 [A, B] 预测 C,利用 [A, B, C] 预测 D。如果利用A 预测B的时候,需要将 [B, C, D] Mask 起来。
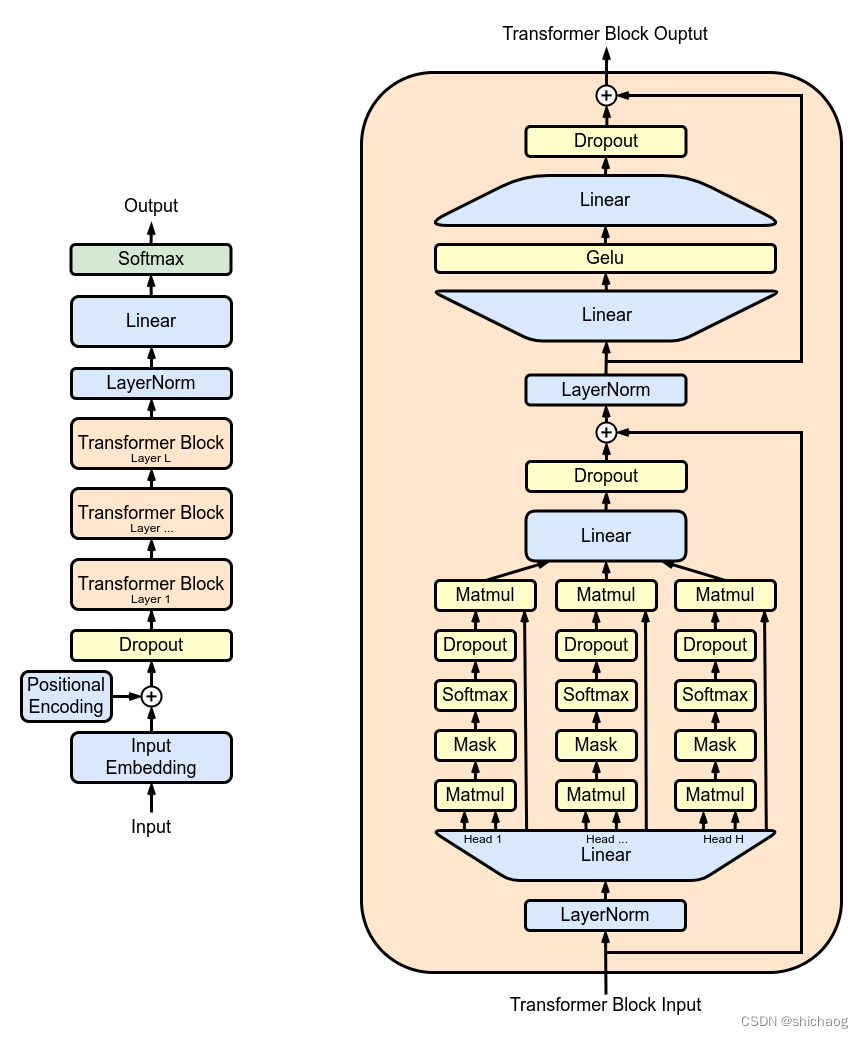
GPT为什么只用 Decoder 部分:语言模型是利用上文预测下一个单词的,因为 Decoder 使用了 Masked Multi Self-Attention 屏蔽了单词的后面内容,所以 Decoder 是现成的语言模型。又因为没有使用 Encoder,所以也就不需要 encoder-decoder attention 了。
GPT 1-3
GPT-1的训练过程是无监督的预训练和有监督的Fine-Tuning,先预训练一个通用的模型,然后在各个子任务上进行微调,减少了传统方法需要针对各个任务定制设计模型的麻烦。
预训练好transformer模型之后,无论子任务怎么变化,模型本身都不再变化,而是调整前面的输入和后面的输出层。
GPT-1和GPT-2模型结构类似,只是GPT-2模型和数据集都更大(表1)。GPT-2提出了多任务训练和zero-shot的概念,“所有的有监督学习都是无监督语言模型的一个子集”的思想,该思想是提示学习(Prompt Learning)的前身。GPT-2生成的新闻足以欺骗大多数人类,达到以假乱真的效果,很多门户网站也命令禁止使用GPT-2生成的新闻。
GPT-3效果远超GPT-2,GPT-3引入few-shot概念,GPT-3引入了一种稀疏自注意力Sparse Transformer的概念,理解成效率更高的自注意力层就可以了,除了能完成常见的NLP任务外,还能写SQL,JavaScript等语言的代码,进行简单的数学运算上也有不错的表现效果。GPT-3的训练使用了情境学习(In-context Learning),它是元学习(Meta-learning)的一种,元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果,相比GPT-2,GPT-3模型和参数都更更大,这也让业界对“大”语言模型的认知从了解提升到了行动阶段。
GPT-3将互联网上几乎所有文本数据作为训练语料,过滤后的训练数据达到5000亿的单词数,其中庞大的维基百科数据仅占0.6%的比例
GPT-3也受到一些非议,因为预训练模型都是通过海量数据在超大参数量级的模型上训练出来的,由于海量的训练数据并没有都经过人工清洗,因而里面会有虚假的、偏见的、无用的、有害的、不合乎人类价值观的、邪恶的训练样本,所以没人可以确保预训练模型不会输出类似的回答,这也就是InstructGPT和ChatGPT的提出动机,论文中用3H概括了它们的优化目标,即High-Quality、Human-like、High-Diversity。
这一阶段OpenAI公布的技术文档如下:
2018 GPT-1《Improving Language Understanding with Unsupervised Learning》 《Improving Language Understanding by Generative Pre-Training》
2019 GPT-2 《Language Models are Unsupervised Multitask Learners》
2020 GPT-3/chatGPT《Language Models are Few-Shot Learners》
2022 InstructGPT(是GPT-4的预热模型,因而又被称为GPT-3.5)《Training language models to follow instructions with human feedback》
BERT
Paper: https://arxiv.org/abs/1810.04805
BERT 全称为Bidirectional Encoder Representation from Transformers(来自Transformers的双向编码表示),谷歌在论文《Pre-traning of Deep Bidirectional Transformers for Language Understanding》中提出的无监督预训练自然语言处理语言模型是近年来自然语言处理领域公认的里程碑模型。
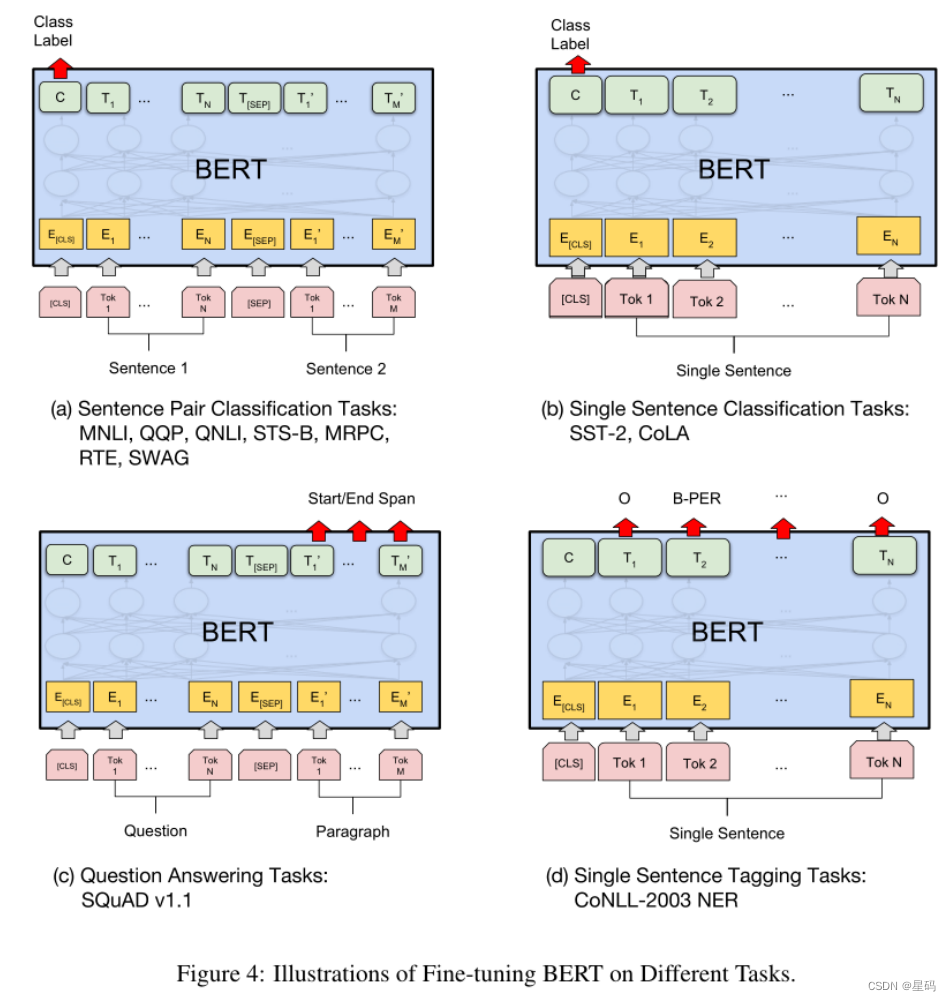
BERT模型是由语言模型预训练模型和使用Fine-tuning 模式解决下游任务组成的自然语言处理模型。当年在11项NLP tasks中取得了state-of-the-art的结果,包括NER、问答等领域的任务。
BERT的创新在于Transformer Decoder(包含Masked Multi-Head Attention)作为提取器,并使用与之配套的掩码训练方法。BERT使用了双编码结构因而不具有文本生成能力,但BERT在对输入文本的编码过程中,利用了每个词的所有上下文信息,与只能使用前序信息提取语义的单向编码器相比,BERT的语义信息提取能力更强。
InstructGPT训练过程简介
这个模型是在GPT-3基础上的,是因为GPT-3的非议而提出的,这源于2022年的一篇paper,后面很多大语言模型,不论开源还是闭源都使用到了RLHF(reinforcement learning from human feedback ),这个模型是在GPT-3基础至少得fine-tune的模型。
SFT和强化学习使得这个模型可以商用。是核心之一,这里简单介绍,详细介绍见下一篇。

完整的训练过程如上图所示,其中左边第一列pretraining就是自监督学习GPT-3模型,InstructGPT中的Instruct提现在后面三个步骤。这也是很多学校里没有财力的实验室博士生在研究的东西,当然很多公司也在研究。有实力的公司是想把这四个部分都掌握在自己的手里。
ChatGPT和InstructGPT在模型结构和训练方式上都一样,它们都使用了指示学习(Instruction Learning)和人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)来指导模型的训练,不同的仅仅是采集数据的方式上有所差异。
自监督学习输出有时是有害的,而完全标注的监督学习成本一定条件下,答案是定的,天花板不高,但是强化学习不是这样,人工不再标注,没有正确答案,只有好于不好的答案,用打分的方式实现;因而强化学习是huggingface中排名靠前的模型必用的技术之一。
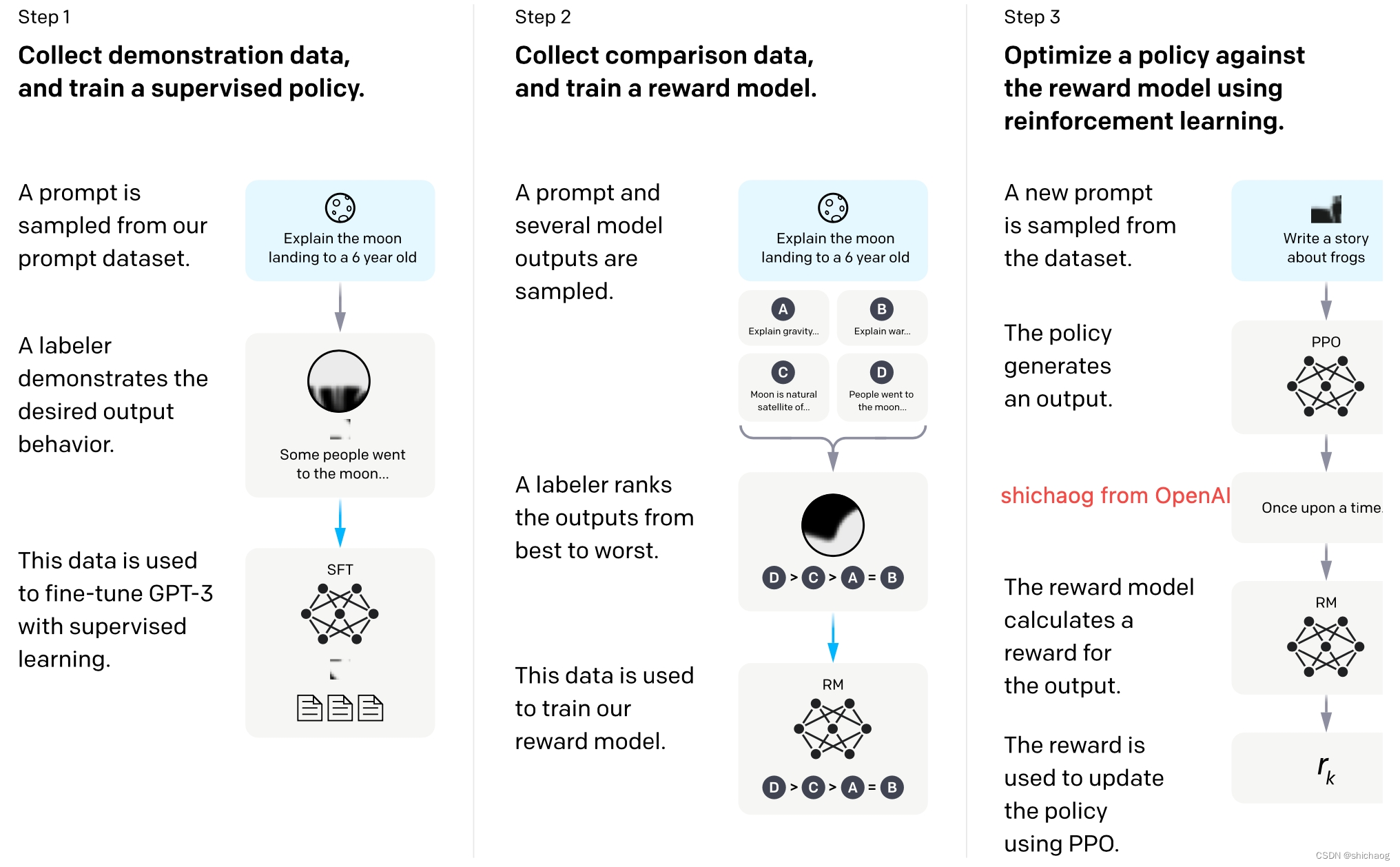
OpenAI公布的fine-tune的过程主要分为三个部分:
1.有监督微调学习(SFT),收集人工编写好的期望模型如何输出的数据集,并使用其来训练一个生成模型(GPT3.5-based)
2.训练奖励模型(RM),收集人工标注的模型多个输出之间的排序数据集。并训练一个奖励模型,以预测用户更喜欢哪个模型输出;
3.基于强化学习(PPO)持续迭代生成模型。使用这个奖励模型作为激励函数,微调监督学习训练出来的生成模型。
其过程如官网给出的下图所示。
模型很重要,数据也很重要,三步微调的数据如下:
需要SFT模型的原因:GPT3模型不一定能够保证根据人的指示、有帮助的、安全的生成答案,需要人工标注数据进行微调。
需要RM模型的原因:标注排序的判别式标注,成本远远低于生成答案的生成式标注。
需要RL模型的原因:在对SFT模型进行微调时,生成的答案分布也会发生变化,会导致RM模型的评分会有偏差,需要用到强化学习。
首先要收集问题集,prompt集:标注人员写出这些问题,写出一些指令,用户提交一些他们想得到答案的问题。先训练一个最基础的模型,给用户试用,同时可以继续收集用户提交的问题。划分数据集时按照用户ID划分,因为同一个用户问题会比较类似,不适合同时出现在训练集和验证集中。
SFT 数据集
GPT-3是一个基于提示学习的生成模型,因而SFT数据集也是由提示-答案对组成的样本,SFT数据一部分来自OpenAI的PlayGround用的,另一部分是OpenAI雇佣的40人标准,并且对这40人进行了培训,很多时候高质量的标注是模型训练的前提,在这个数据集上,标注者的工作内容是根据内容自己编写指示,并且要求编写的指示满足以下三点:
- 简单任务:标注者给出任意一个简单的任务,同时要确保任务的多样性;
- Few-Shot任务:标注者给出一个指示以及该指示的多个查询-应答对;
- 用户相关的:从接口获取用例,然后让标注者根据这些用例编写指示;
13000条数据。标注人员直接根据刚才的问题集里面的问题写答案。通常这一阶段需要数万条高质量的标注数据。
RM数据集
RM数据集用来训练第二步的奖励模型,奖励的目标是要对齐人类评价,通过人工打分的方式来提供这个奖励,因为人工可以对那些有害、无用、偏见等生成的内容打更低的分,这样可以让模型不容易生成那些内容。Instruct GPT/ChatGPT的做法是让模型针对同一个问题生成4~10个答案,然后人工对这些生成的答案从好到差人工排序。33000条数据。标注人员对答案进行排序。
其InstructGPT paper上展示了这一过程是如何进行的。

PPO数据集
强化学习通过奖励(Reward)机制来指导模型训练,奖励机制可以看做传统模型训练机制的损失函数。奖励的计算要比损失函数更灵活和多样(AlphaGO的奖励是对局的胜负),这带来的代价是奖励的计算是不可导的,因此不能直接拿来做反向传播。强化学习的思路是通过对奖励的大量采样来拟合损失函数,从而实现模型的训练。同样人类反馈也是不可导的,那么我们也可以将人工反馈作为强化学习的奖励,基于人类反馈的强化学习便应运而生。
RLHF最早可以追溯到Google在2017年发表的《Deep Reinforcement Learning from Human Preferences》,它通过人工标注作为反馈,提升了强化学习在模拟机器人以及雅达利游戏上的表现效果。
PPO(Proximal Policy Optimization)是一种新型的Policy Gradient算法,该算法对步长十分敏感,但又难以给出合适的步长,子啊训练过程中新旧策略的变化差异如果过大则不利于学习,PPO算法啊提出新的目标函数可以在多个训练步骤实现小批量的更新,解决了Policy Gradient算法中步长难以确定的问题。
InstructGPT的PPO数据集并没有进行标注,均来自GPT-3的用户API。31000条数据。只需要prompt集里面的问题就行,不需要标注。因为这一步的标注是RM模型来打分标注的。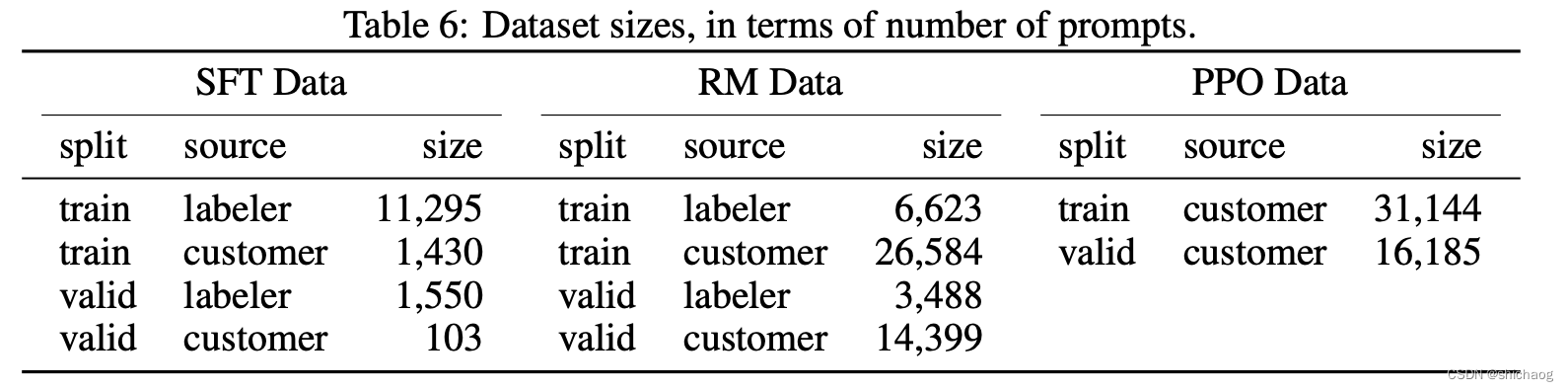
数据集中96%都是英文,其它20多个语种不到4%。从预训练到强化学习的完整过程如下:
GPT-4
为了让神经网络能够更好的理解世界,从而更为智能,视觉能力似乎是不可或缺的能力。
多模态,从文本和图像中学习,可以对文本和图像输入的请求做出响应,图像对神经网络有提升,会让其用处大大扩大,因为人类是视觉动物,人类大脑皮层的三分之一用于视觉处理。
GPT-4相比ChatGPT在很多方面都达到了人类水平,比如GRE、律师、医生等考试上,GPT-4比ChatGPT能更准确的预测下一个词,这意味着模型会有更多的理解力,此外模型还对一些高质量的图片通过强化学习变体进行微调。
Llama开源大语言模型
Meta的Llama源码是开源大语言模型,其主官宣的paper有如下两篇文章,Transformer结构也没有大的变动,但是其LLaMA-13B的性能优于OpenAI的GPT-3(175B),这足足小了十多倍的模型媲美了1750亿参数的模型。
《LLaMA: Open and Efficient Foundation Language Models 》
《Llama 2: Open Foundation and Fine-Tuned Chat Models 》
| 预训练数据集 | 模型参数量 | 模型结构体 | 许可 | 文本长度 | grouped-query attention (GQA) | Tokens | A100-80GB 400W训练 /所需时间 | optimizer | |
|---|---|---|---|---|---|---|---|---|---|
| LLaMA | 4.5TB | 6.3B, 13B,32.5B,62.5B | Auto-regressive transformers | research | 2k | 6.3B,13B /1.0T ;33B,65B / 1.4T | 7B 82,432h 13B 135,168h 33B 530,432h 65B 1,022,362h | AdamW | |
| LLaMA-2/LlaMA-2-chat | 6.3TB(较LLaMA增加40%) | 6.3B, 13B, and 70B | Auto-regressive transformers | research and commercial | 4k | 34B/70B | 2.0T | 7B 184,320h 13B 368,640h 70B 1,720,320h |
LLaMA 65B参数模型使用了2048块A100 GPU经过21天训练得到预训练模型,预训练的过程花费了500万美元左右,
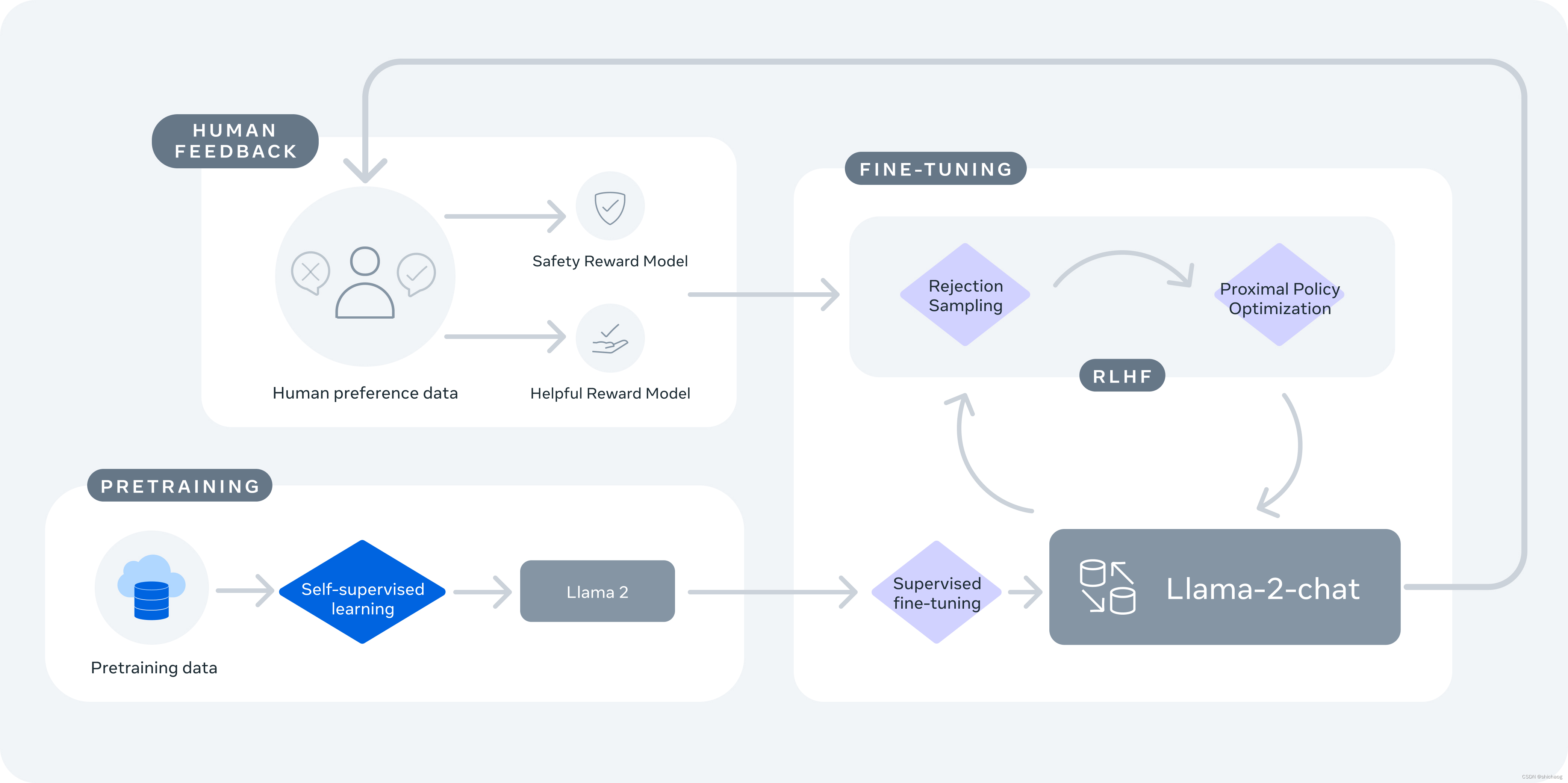
Llama-2先使用公开可获取的文本信息训练,然后使用SFT进行fine tune,然后再用Reinforcement Learning from Human Feedback (RLHF)再refine,RLHF包括rejection sampling and proximal policy optimization (PPO)。
Llama-2-chat使用RLHF(reinforcement learning from human feedback)以确保安全有用的。LlaMA-2-chat是几个月的研究和迭代应用的结果,包括指令调优,RLHF,算力和标注资源。
未来大语言模型的方向
“智能”源于数据、算力以及模型结构。模型的产出物朝着工具化和智能人化两个方向发展。
1.首先是数据,要不了几年,互联网上的公开数据就会被爬完用于模型训练,而新的源源不断的打语言模型产生数据极有可能被爬虫,再输入模型这是否会导致模型陷入自我强化?看来模型本身也需要反大语言模型产出物。
2.基于现有的RLHF架构存着以下问题:
a.fine-tune的过程是封印模型功能的过程,不是无中生有的过程,因而模型的能力还是取决于fine-tune,这会降低NLP的通用任务的性能下降。
b.模型的输出的价值观合规、模型的特定场景;
c.人工标注的成本比较高,InstructGPT强化学习雇佣了40人训练。
3.大模型预训练+微调(Fine-Tune)的形式将会继续存在,但是预训练和微调都会演进,大模型的演进方向在于通用任务处理上,而微调除了针对特定场景,依然还要进一步降低微调的门槛和成本,如LoRA。
Zero-shot Learning | One-shot Learning | Few-shot Learning是因为标注数据有限或成本而提出的学习方法。
4.PPO方法使用的代价函数并不能代表灵活多变的人类偏好,因而这个算法方向相对其它模块,更容易带来突破性进展;
5.RLHF现在的方法倾向于对所有人都有相同偏好的概率输出,但是人的喜好是多样性的,这意味着相同的偏好概率假设并不成立。所以现在生成的答案并不是那么令人赏心悦目。比如一看新闻都是新闻编辑排版决定了观众看到什么,但是头条收集个人偏好之后,每个人看到的事不一样的,即同一条推荐对不同人的概率是不一样的。
6.SFT阶段要训练所有参数(虽然训练时间可以缩短),但这对高学校实验室、创业公司并不友好,2卡或者4卡A100的SFT是需要的,因而基于(LoRA) 等freeze部分参数,只迭代相对较少的参数finetuning会是一个方向;
7.端上PC会local部署模型,大语言模型,图像生成式模型,以及工具类集成AI,因而量化、SIMD、GPU、剪枝等优化方法还是被用于尝试端上部署
8.某种程度上除了记忆性和泛化能力,我个人认为已经具备了初级的知觉、逻辑、意识能力,比如作为三国杀、狼人杀参与游戏,胜利的高于50%,只是是无机物逻辑,但这是一种意识,如果被赋予生存意识(某种程度上是可以的),那也会具备生存意识,超大模型、多模态神经网络将在感知、理解以及通用任务处理上扩展其应用边界,生成式AI工具类应用继续领跑,未来的方向之一是真正意识上的“智人”。
*
相关文章:
大语言模型之二 GPT发展史简介
得益于数据、模型结构以及并行算力的发展,大语言模型应用现今呈井喷式发展态势,大语言神经网络模型成为了不可忽视的一项技术。 GPT在自然语言处理NLP任务上取得了突破性的进展,扩散模型已经拥有了成为下一代图像生成模型的代表的潜力&#x…...
前后端分离------后端创建笔记(09)密码加密网络安全
本文章转载于【SpringBootVue】全网最简单但实用的前后端分离项目实战笔记 - 前端_大菜007的博客-CSDN博客 仅用于学习和讨论,如有侵权请联系 源码:https://gitee.com/green_vegetables/x-admin-project.git 素材:https://pan.baidu.com/s/…...

《Effects of Graph Convolutions in Multi-layer Networks》阅读笔记
一.文章概述 本文研究了在XOR-CSBM数据模型的多层网络的第一层以上时,图卷积能力的基本极限,并为它们在数据中信号的不同状态下的性能提供了理论保证。在合成数据和真实世界数据上的实验表明a.卷积的数量是决定网络性能的一个更重要的因素,而…...

低代码助力传统制造业数字化转型策略
随着制造强国战略逐步实施,制造行业数字化逐渐进入快车道。提高生产管理的敏捷性、加强产品的全生命周期质量管理是企业数字化转型的核心诉求,也是需要思考的核心价值。就当下传统制造业的核心问题来看,低代码是最佳解决方案,那为…...

什么叫做云计算
什么叫做云计算 相信大多数人对云计算或者是云服务的认识还停留在仅仅听过这个名词,但是对其真正的定义或者意义还不甚了解的层面。甚至有些技术人员,如果日常的业务不涉及到云服务,可能对其也只是一知半解的程度。首先云计算准确的讲只是云服…...

springboot 使用zookeeper实现分布式队列
一.添加ZooKeeper依赖:在pom.xml文件中添加ZooKeeper客户端的依赖项。例如,可以使用Apache Curator作为ZooKeeper客户端库: <dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</…...
地理数据的双重呈现:GIS与数据可视化
前一篇文章带大家了解了GIS与三维GIS的关系,本文就GIS话题带大家一起探讨一下GIS和数据可视化之间的关系。 GIS(地理信息系统)和数据可视化在地理信息科学领域扮演着重要的角色,它们之间密切相关且相互增强。GIS是一种用于采集、…...
- MediaPlayer生命周期)
Android 13 Media框架(3)- MediaPlayer生命周期
上一节了解了MediaPlayer api的使用,这一节就我们将会了解MediaPlayer的生命周期与api使用细节。 1、MediaPlayer生命周期 MediaPlayer.java 一开始有对生命周期的描述,这里对这些内容进行翻译: MediaPlayer 是线程不安全的,创建…...
[oneAPI] BERT
[oneAPI] BERT BERT训练过程Masked Language Model(MLM)Next Sentence Prediction(NSP)微调 总结基于oneAPI代码 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517 Intel DevCloud for oneAPI&…...

F1-score解析
报错:valueError: Target is multiclass but average‘binary’. Please choose another average setting, one of 原因:使用from sklearn.metrics import f1_score多类别计算F1-score时报错,改函数的参数即可,如:f1_s…...
windows11下配置vscode中c/c++环境
本文默认已经下载且安装好vscode,主要是解决环境变量配置以及编译task、launch文件的问题。 自己尝试过许多博客,最后还是通过这种方法配置成功了。 Linux(ubuntu 20.04)配置vscode可以直接跳转到配置task、launch文件,不需要下载mingw与配…...

Max Sum
一、题目 Given a sequence a[1],a[2],a[3]…a[n], your job is to calculate the max sum of a sub-sequence. For example, given (6,-1,5,4,-7), the max sum in this sequence is 6 (-1) 5 4 14. Input The first line of the input contains an integer T(1<T<…...
Field injection is not recommended
文章目录 1. 引言2. 不推荐使用Autowired的原因3. Spring提供了三种主要的依赖注入方式3.1. 构造函数注入(Constructor Injection)3.2. Setter方法注入(Setter Injection)3.3. 字段注入(Field Injection) 4…...
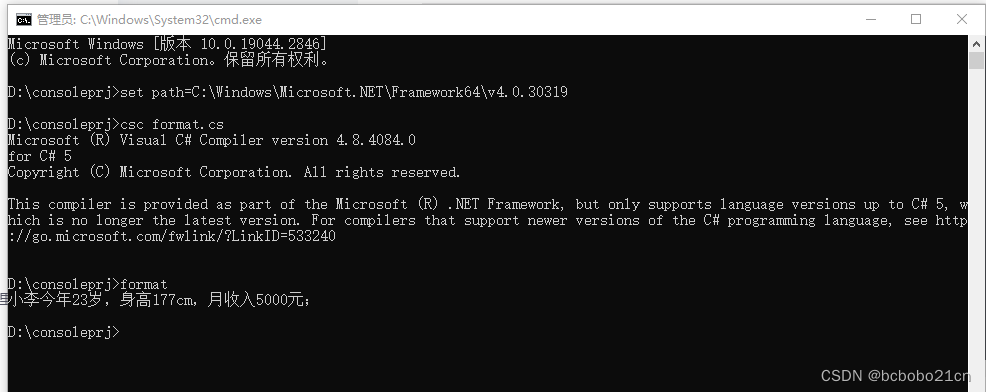
C#字符串占位符替换
using System;namespace myprog {class test{static void Main(string[] args){string str1 string.Format("{0}今年{1}岁,身高{2}cm,月收入{3}元;", "小李", 23, 177, 5000);Console.WriteLine(str1);Console.ReadKey(…...
ChatGPT等人工智能编写文章的内容今后将成为常态
BuzzFeed股价上涨200%可能标志着“转向人工智能”媒体趋势的开始。 周四,一份内部备忘录被华尔街日报透露BuzzFeed正计划使用ChatGPT聊天机器人-风格文本合成技术来自OpenAI,用于创建个性化盘问和将来可能的其他内容。消息传出后,BuzzFeed的…...
)
【Sklearn】基于梯度提升树算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于梯度提升树算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理 梯度提升树(Gradient Boosting Trees)是一种集成学习方法,用于解决分类和回归问题。它通过将多个弱学习器(通常…...

什么叫做云计算?
相信大多数人对云计算或者是云服务的认识还停留在仅仅听过这个名词,但是对其真正的定义或者意义还不甚了解的层面。甚至有些技术人员,如果日常的业务不涉及到云服务,可能对其也只是一知半解的程度。首先云计算准确的讲只是云服务中的一部分&a…...

深度学习Batch Normalization
批标准化(Batch Normalization,简称BN)是一种用于深度神经网络的技术,它的主要目的是解决深度学习模型训练过程中的内部协变量偏移问题。简单来说,当我们在训练深度神经网络时,每一层的输入分布都可能会随着…...

el-table实现懒加载(el-table-infinite-scroll)
2023.8.15今天我学习了用el-table对大量的数据进行懒加载。 效果如下: 1.首先安装: npm install --save el-table-infinite-scroll2 2.全局引入: import ElTableInfiniteScroll from "el-table-infinite-scroll";// 懒加载 V…...

vueRouter回顾
关于vueRouter的两种路由模式 “history” 模式使用正常的 URL 格式,例如 https://example.com/path。“hash” 模式将路由信息添加到 URL 的哈希部分(#)后面,例如 https://example.com/#/path。 1、history模式:没有…...

JS混淆解密实战:Python沙箱还原前端加密逻辑
1. 这不是写个requests就能跑通的爬虫——JS混淆正在成为数据获取的第一道真实门槛“Python爬虫逆向:JS混淆数据解密实战”这个标题里藏着一个被太多人低估的现实:今天你用requests.get(url)拿到的页面,大概率已经不是原始HTML了。它可能是一…...

RV1126B平台I2C驱动ADS1115实战:从硬件接线到应用层代码
1. 项目概述与核心思路最近在折腾瑞芯微RV1126B这块板子,用的是EASY-EAI Nano-TB开发套件。项目里需要接几个传感器和一个小屏幕,I2C总线是绕不开的。虽然Linux内核已经把I2C驱动封装得很好了,但真要在应用层把它用起来、用稳了,特…...

大规模集群中的ksync:性能测试与资源占用优化策略
大规模集群中的ksync:性能测试与资源占用优化策略 【免费下载链接】ksync Sync files between your local system and a kubernetes cluster. 项目地址: https://gitcode.com/gh_mirrors/ks/ksync 在当今云原生开发环境中,Kubernetes文件同步工具…...

如何高效下载QQ音乐资源:5个简单步骤掌握res-downloader嗅探技术
如何高效下载QQ音乐资源:5个简单步骤掌握res-downloader嗅探技术 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

蛋白质基础模型:从AlphaFold2到Chai-1的范式跃迁
1. 项目概述:一场悄然发生的蛋白质结构预测范式迁移最近在实验室跑完第7轮Chai-1的微调任务后,我盯着屏幕上跳出来的pLDDT值曲线,突然意识到:我们正在经历的不是一次工具升级,而是一场底层建模逻辑的彻底重写。标题里提…...

Mythos门控能力:大模型长程推理与反事实推演的工程化落地
1. 项目概述:一次被刻意“锁住”的能力跃迁“TAI #200: Anthropic’s Mythos Capability Step Change and Gated Release”——这个标题里没有一个生僻词,但组合在一起却像一道加密指令。我在AI行业一线摸爬滚打十多年,从早期用TensorFlow手写…...

MinerU实战训练营教程及配套素材
目前实战训练营的所有课程视频和文档都已经更新,如需要学习可访问飞书文档进行查看:https://aicarrier.feishu.cn/wiki/Bv0GwrC26iCp5LkqBjHcM8mjnOe • 相关课程材料也已经上传GitHub repo:https://github.com/opendatalab/mineru-tutorial…...

2026年国内镜像站安全与效率评测:GPT-5.5的真实体验
在国内访问海外大模型,延迟高、连接不稳、支付合规是老生常谈的三座大山。为了完成本次GPT-5.5的全流程实测,我借助库拉AI聚合平台完成了所有调用——该平台支持国内外主流AI模型的统一对接,国内可直连访问,注册用户每日提供可用额…...

AutoGen 框架深度使用指南
AutoGen 框架深度使用指南:从零搭建多智能体协作系统 1. 引入与连接:你为什么需要AutoGen? 1.1 开场:每个开发者都遇到过的痛点 你有没有过这样的经历:用ChatGPT写了一段Python数据分析代码,复制到本地运行报错,再把报错信息粘贴回去让它改,来回折腾5、6次才跑通;要…...

【2026 Q1实测数据】ChatGPT新增“因果推理引擎”准确率提升至89.7%,但83%用户因忽略这4个参数设置导致失效
更多请点击: https://codechina.net 第一章:ChatGPT“因果推理引擎”的架构演进与2026 Q1实测基准 OpenAI于2025年Q4正式将ChatGPT核心推理模块重构为“因果推理引擎”(Causal Reasoning Engine, CRE),其本质是将传统…...