《Effects of Graph Convolutions in Multi-layer Networks》阅读笔记
一.文章概述
本文研究了在XOR-CSBM数据模型的多层网络的第一层以上时,图卷积能力的基本极限,并为它们在数据中信号的不同状态下的性能提供了理论保证。在合成数据和真实世界数据上的实验表明a.卷积的数量是决定网络性能的一个更重要的因素,而不是网络中的层的数量。b.只要放置相同数量的卷积层,只要不在第一层,任何放置组合能实现相似的性能增强。c.当图相对稀疏的时候,多个图卷积是有利的。
注意,本文研究的重点是比较图卷积与不利用关系信息的传统MLP的优点和局限性。作者的设置不受异配性问题的影响,且不考虑过平滑发生的情况。
二.预备知识
数据模型
令 n n n表示数据点的数量, d d d表示特征维度。定义伯努利随机变量 ε 1 , … , ε n ∼ Ber ( 1 / 2 ) \varepsilon_1, \ldots, \varepsilon_n \sim \operatorname{Ber}(1 / 2) ε1,…,εn∼Ber(1/2)和 η 1 , … , η n ∼ Ber ( 1 / 2 ) \eta_1, \ldots, \eta_n \sim \operatorname{Ber}(1 / 2) η1,…,ηn∼Ber(1/2)。定义两个类别 C b = { i ∈ [ n ] ∣ ε i = b } C_b=\left\{i \in[n] \mid \varepsilon_i=b\right\} Cb={i∈[n]∣εi=b},其中 b ∈ { 0 , 1 } b \in\{0,1\} b∈{0,1}。
令 μ \boldsymbol{\mu} μ和 ν \boldsymbol{\nu} ν表示 R d \mathbb{R}^d Rd中的固定向量,其满足 ∥ μ ∥ 2 = ∥ ν ∥ 2 \|\boldsymbol{\mu}\|_2=\|\boldsymbol{\nu}\|_2 ∥μ∥2=∥ν∥2 和 ⟨ μ , ν ⟩ = 0 \langle\boldsymbol{\mu}, \boldsymbol{\nu}\rangle=0 ⟨μ,ν⟩=0(即 μ \boldsymbol{\mu} μ和 ν \boldsymbol{\nu} ν正交)。令 X ∈ R n × d \mathbf{X} \in \mathbb{R}^{n \times d} X∈Rn×d为数据矩阵,其中每行 X i ∈ R d \mathbf{X}_i \in \mathbb{R}^d Xi∈Rd是一个独立的高斯随机向量分布 X i ∼ N ( ( 2 η i − 1 ) ( ( 1 − ε i ) μ + ε i ν ) , σ 2 ) \mathbf{X}_i \sim \mathcal{N}\left(\left(2 \eta_i-1\right)\left(\left(1-\varepsilon_i\right) \boldsymbol{\mu}+\varepsilon_i \boldsymbol{\nu}\right), \sigma^2\right) Xi∼N((2ηi−1)((1−εi)μ+εiν),σ2)。用 X ∼ XOR − GMM ( n , d , μ , ν , σ 2 ) \mathbf{X} \sim \operatorname{XOR}-\operatorname{GMM}\left(n, d, \boldsymbol{\mu}, \boldsymbol{\nu}, \sigma^2\right) X∼XOR−GMM(n,d,μ,ν,σ2)表示从该数据模型中采样的数据。
令 A = ( a i j ) i , j ∈ [ n ] \mathbf{A}=\left(a_{i j}\right)_{i, j \in[n]} A=(aij)i,j∈[n]表示对应于图(含自环的无向图)信息的邻接矩阵,该矩阵是从一个标准的对称双块随机块模型(symmetric two-block stochastic block model)中采样的,该模块的参数为 p p p和 q q q,其中 p p p表示块内边概率, q q q表示块间边概率。作者将 SBM ( n , p , q ) \operatorname{SBM}(n, p, q) SBM(n,p,q)与 XOR − GMM ( n , d , μ , ν , σ 2 ) \operatorname{XOR}-\operatorname{GMM}\left(n, d, \boldsymbol{\mu}, \boldsymbol{\nu}, \sigma^2\right) XOR−GMM(n,d,μ,ν,σ2)耦合在一起,即若 ε i = ε j \varepsilon_i=\varepsilon_j εi=εj,则 a i j ∼ Ber ( p ) a_{i j} \sim \operatorname{Ber}(p) aij∼Ber(p),否则 a i j ∼ Ber ( q ) a_{i j} \sim \operatorname{Ber}(q) aij∼Ber(q)。
至此,可得定义的数据模型 ( A , X ) = ( { a i j } i , j ∈ [ n ] , { X i } i ∈ [ n ] ) (\mathbf{A}, \mathbf{X})=\left(\left\{a_{i j}\right\}_{i, j \in[n]},\left\{\mathbf{X}_i\right\}_{i \in[n]}\right) (A,X)=({aij}i,j∈[n],{Xi}i∈[n]),即 ( A , X ) ∼ XOR − CSBM ( n , d , μ , ν , σ 2 , p , q ) (\mathbf{A}, \mathbf{X}) \sim \operatorname{XOR}-\operatorname{CSBM}\left(n, d, \boldsymbol{\mu}, \boldsymbol{\nu}, \sigma^2, p, q\right) (A,X)∼XOR−CSBM(n,d,μ,ν,σ2,p,q)。
令 D \mathbf{D} D表示邻接矩阵对应的度矩阵, N i = { j ∈ [ n ] ∣ a i j = 1 } N_i=\left\{j \in[n] \mid a_{i j}=1\right\} Ni={j∈[n]∣aij=1}表示节点 i i i的邻居集。
网络架构
作者的分析聚焦于带ReLU激活的MLP架构, L L L层网络定义如下:
H ( 0 ) = X f ( l ) ( X ) = ( D − 1 A ) k l H ( l − 1 ) W ( l ) + b ( l ) H ( l ) = ReLU ( f ( l ) ( X ) ) y ^ = φ ( f ( L ) ( X ) ) . \begin{aligned} & \mathbf{H}^{(0)}=\mathbf{X} \\ & f^{(l)}(\mathbf{X})=\left(\mathbf{D}^{-1} \mathbf{A}\right)^{k_l} \mathbf{H}^{(l-1)} \mathbf{W}^{(l)}+\mathbf{b}^{(l)} \\ & \mathbf{H}^{(l)}=\operatorname{ReLU}\left(f^{(l)}(\mathbf{X})\right) \\ & \hat{\mathbf{y}}=\varphi\left(f^{(L)}(\mathbf{X})\right) . \end{aligned} H(0)=Xf(l)(X)=(D−1A)klH(l−1)W(l)+b(l)H(l)=ReLU(f(l)(X))y^=φ(f(L)(X)).
其中 l ∈ [ L ] l \in [L] l∈[L], φ ( x ) = sigmoid ( x ) = \varphi(x)=\operatorname{sigmoid}(x)= φ(x)=sigmoid(x)= 1 1 + e − x \frac{1}{1+e^{-x}} 1+e−x1,最后一层的输出表示为 y ^ = { y ^ i } i ∈ [ n ] \hat{\mathbf{y}}=\left\{\hat{y}_i\right\}_{i \in[n]} y^={y^i}i∈[n]。 D − 1 A \mathbf{D}^{-1} \mathbf{A} D−1A表示正则化的邻接矩阵, k l k_l kl表示层 l l l中的图卷积数量。对于给定数据集 ( X , y ) (\mathbf{X}, \mathbf{y}) (X,y),采用二进制交叉熵来进行优化:
ℓ θ ( A , X ) = − 1 n ∑ i ∈ [ n ] y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) \ell_\theta(\mathbf{A}, \mathbf{X})=-\frac{1}{n} \sum_{i \in[n]} y_i \log \left(\hat{y}_i\right)+\left(1-y_i\right) \log \left(1-\hat{y}_i\right) ℓθ(A,X)=−n1i∈[n]∑yilog(y^i)+(1−yi)log(1−y^i)
三.理论分析结果
设置Baselines
作者设置了一个没有图信息的对比baseline。作者用用混合模型的均值与数据点数 n n n之间的距离来表征XOR-GMM数据模型的分类阈值。令 Φ ( ⋅ ) \Phi(\cdot) Φ(⋅) 表示标准高斯的累积分布函数。
重要结论:若两个类的特征均值相距不超过 O ( σ ) O(\sigma) O(σ),那么在压倒性的概率下,有常数比例的点被错误分类。
通过图卷积进行改进
本节阐述了图卷积在多层卷积中的影响。
重要结论:多层模型中将图卷积放置在第一层会损害分类精度,下图(a)展示的的便是第一层中没有图卷积的网络,可见不同类别的数据并不是线性可分的,对其进行图卷积后,两个类的均值会坍缩到同一点,如图(b)。然后,在最后一层使用图卷积则不同,由于输入由线性可分的转换特征组成,图卷积有助于分类任务。

图卷积的放置
多层网络分类能力的提高取决于卷积的数量,而不取决于卷积放置的位置。对于XOR-CSBM数据模型,在任何组合中在第二层和/或第三层之间放置相同数量的卷积,可以在分类任务中实现与上节相似的改进。
四.实验
本节通过实验证明第四节中的结论。
合成数据集
图卷积的位置并不重要,只要它不在第一层,(a)和(b)表明对于在第二层或第三层中有一个图卷积的所有网络,以及在第二层和第三层之间的任何组合中有两个图卷积的所有网络,性能是相互相似的。
在图是dense的情况下,两个图卷积并不比一个图卷积获得显著的优势。(参见图©和图(d))

真实世界数据集
作者在论文引用网络Cora、Citeseer和Pubmed上进行实验,得到结论为:
- 利用图的网络比不使用关系信息的传统MLP表现得明显更好。
- 在任何层中具有一个图卷积的所有网络都实现了相互相似的性能,并且在任何位置组合中具有两个图卷积的所有网络都实现了相互相似的性能。

相关文章:
《Effects of Graph Convolutions in Multi-layer Networks》阅读笔记
一.文章概述 本文研究了在XOR-CSBM数据模型的多层网络的第一层以上时,图卷积能力的基本极限,并为它们在数据中信号的不同状态下的性能提供了理论保证。在合成数据和真实世界数据上的实验表明a.卷积的数量是决定网络性能的一个更重要的因素,而…...

低代码助力传统制造业数字化转型策略
随着制造强国战略逐步实施,制造行业数字化逐渐进入快车道。提高生产管理的敏捷性、加强产品的全生命周期质量管理是企业数字化转型的核心诉求,也是需要思考的核心价值。就当下传统制造业的核心问题来看,低代码是最佳解决方案,那为…...

什么叫做云计算
什么叫做云计算 相信大多数人对云计算或者是云服务的认识还停留在仅仅听过这个名词,但是对其真正的定义或者意义还不甚了解的层面。甚至有些技术人员,如果日常的业务不涉及到云服务,可能对其也只是一知半解的程度。首先云计算准确的讲只是云服…...

springboot 使用zookeeper实现分布式队列
一.添加ZooKeeper依赖:在pom.xml文件中添加ZooKeeper客户端的依赖项。例如,可以使用Apache Curator作为ZooKeeper客户端库: <dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</…...
地理数据的双重呈现:GIS与数据可视化
前一篇文章带大家了解了GIS与三维GIS的关系,本文就GIS话题带大家一起探讨一下GIS和数据可视化之间的关系。 GIS(地理信息系统)和数据可视化在地理信息科学领域扮演着重要的角色,它们之间密切相关且相互增强。GIS是一种用于采集、…...
- MediaPlayer生命周期)
Android 13 Media框架(3)- MediaPlayer生命周期
上一节了解了MediaPlayer api的使用,这一节就我们将会了解MediaPlayer的生命周期与api使用细节。 1、MediaPlayer生命周期 MediaPlayer.java 一开始有对生命周期的描述,这里对这些内容进行翻译: MediaPlayer 是线程不安全的,创建…...
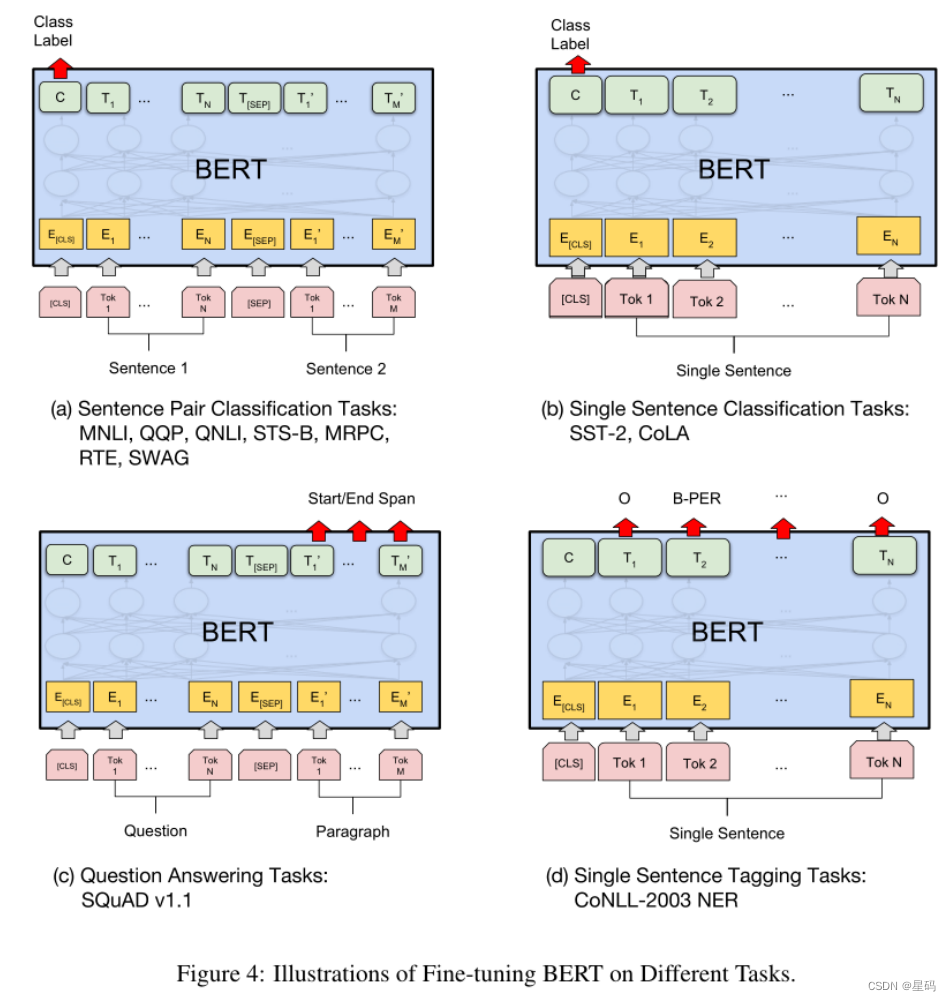
[oneAPI] BERT
[oneAPI] BERT BERT训练过程Masked Language Model(MLM)Next Sentence Prediction(NSP)微调 总结基于oneAPI代码 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517 Intel DevCloud for oneAPI&…...

F1-score解析
报错:valueError: Target is multiclass but average‘binary’. Please choose another average setting, one of 原因:使用from sklearn.metrics import f1_score多类别计算F1-score时报错,改函数的参数即可,如:f1_s…...
windows11下配置vscode中c/c++环境
本文默认已经下载且安装好vscode,主要是解决环境变量配置以及编译task、launch文件的问题。 自己尝试过许多博客,最后还是通过这种方法配置成功了。 Linux(ubuntu 20.04)配置vscode可以直接跳转到配置task、launch文件,不需要下载mingw与配…...

Max Sum
一、题目 Given a sequence a[1],a[2],a[3]…a[n], your job is to calculate the max sum of a sub-sequence. For example, given (6,-1,5,4,-7), the max sum in this sequence is 6 (-1) 5 4 14. Input The first line of the input contains an integer T(1<T<…...
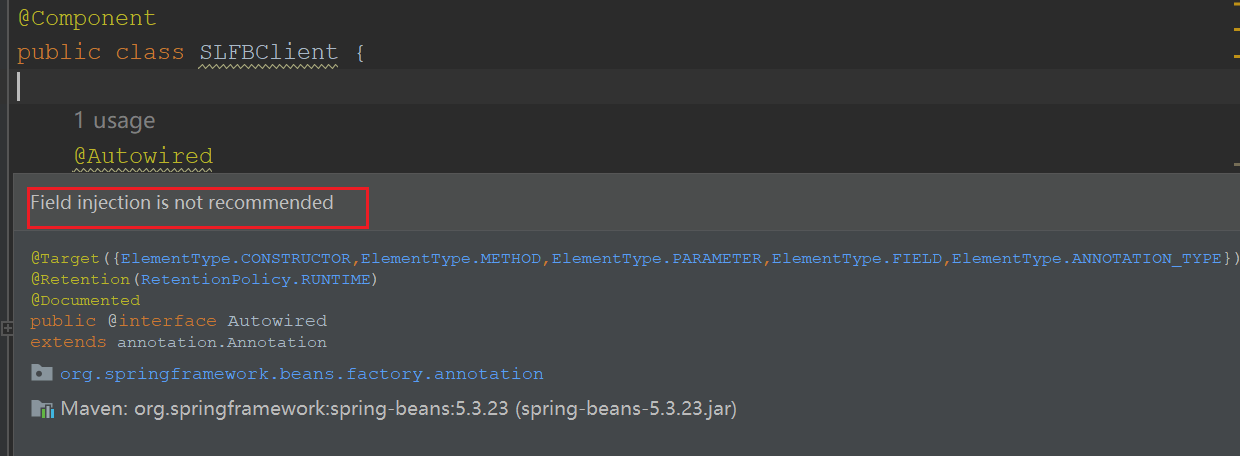
Field injection is not recommended
文章目录 1. 引言2. 不推荐使用Autowired的原因3. Spring提供了三种主要的依赖注入方式3.1. 构造函数注入(Constructor Injection)3.2. Setter方法注入(Setter Injection)3.3. 字段注入(Field Injection) 4…...
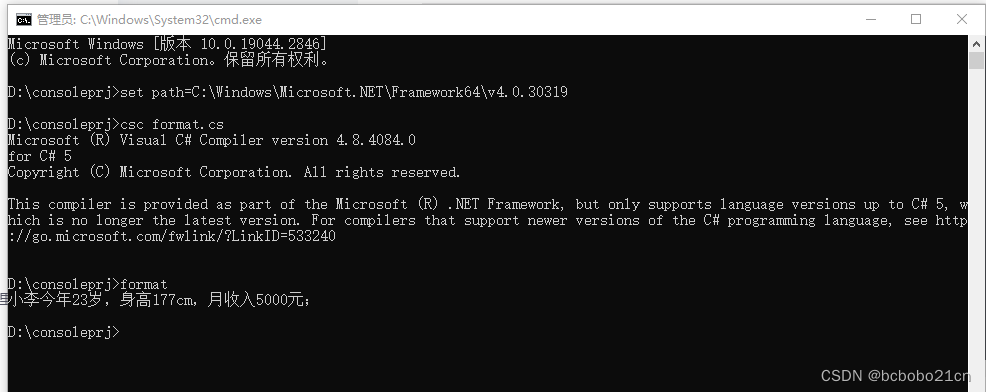
C#字符串占位符替换
using System;namespace myprog {class test{static void Main(string[] args){string str1 string.Format("{0}今年{1}岁,身高{2}cm,月收入{3}元;", "小李", 23, 177, 5000);Console.WriteLine(str1);Console.ReadKey(…...
ChatGPT等人工智能编写文章的内容今后将成为常态
BuzzFeed股价上涨200%可能标志着“转向人工智能”媒体趋势的开始。 周四,一份内部备忘录被华尔街日报透露BuzzFeed正计划使用ChatGPT聊天机器人-风格文本合成技术来自OpenAI,用于创建个性化盘问和将来可能的其他内容。消息传出后,BuzzFeed的…...
)
【Sklearn】基于梯度提升树算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于梯度提升树算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理 梯度提升树(Gradient Boosting Trees)是一种集成学习方法,用于解决分类和回归问题。它通过将多个弱学习器(通常…...

什么叫做云计算?
相信大多数人对云计算或者是云服务的认识还停留在仅仅听过这个名词,但是对其真正的定义或者意义还不甚了解的层面。甚至有些技术人员,如果日常的业务不涉及到云服务,可能对其也只是一知半解的程度。首先云计算准确的讲只是云服务中的一部分&a…...

深度学习Batch Normalization
批标准化(Batch Normalization,简称BN)是一种用于深度神经网络的技术,它的主要目的是解决深度学习模型训练过程中的内部协变量偏移问题。简单来说,当我们在训练深度神经网络时,每一层的输入分布都可能会随着…...

el-table实现懒加载(el-table-infinite-scroll)
2023.8.15今天我学习了用el-table对大量的数据进行懒加载。 效果如下: 1.首先安装: npm install --save el-table-infinite-scroll2 2.全局引入: import ElTableInfiniteScroll from "el-table-infinite-scroll";// 懒加载 V…...

vueRouter回顾
关于vueRouter的两种路由模式 “history” 模式使用正常的 URL 格式,例如 https://example.com/path。“hash” 模式将路由信息添加到 URL 的哈希部分(#)后面,例如 https://example.com/#/path。 1、history模式:没有…...

大规模无人机集群算法flocking(蜂群)
matlab2016b正常运行...
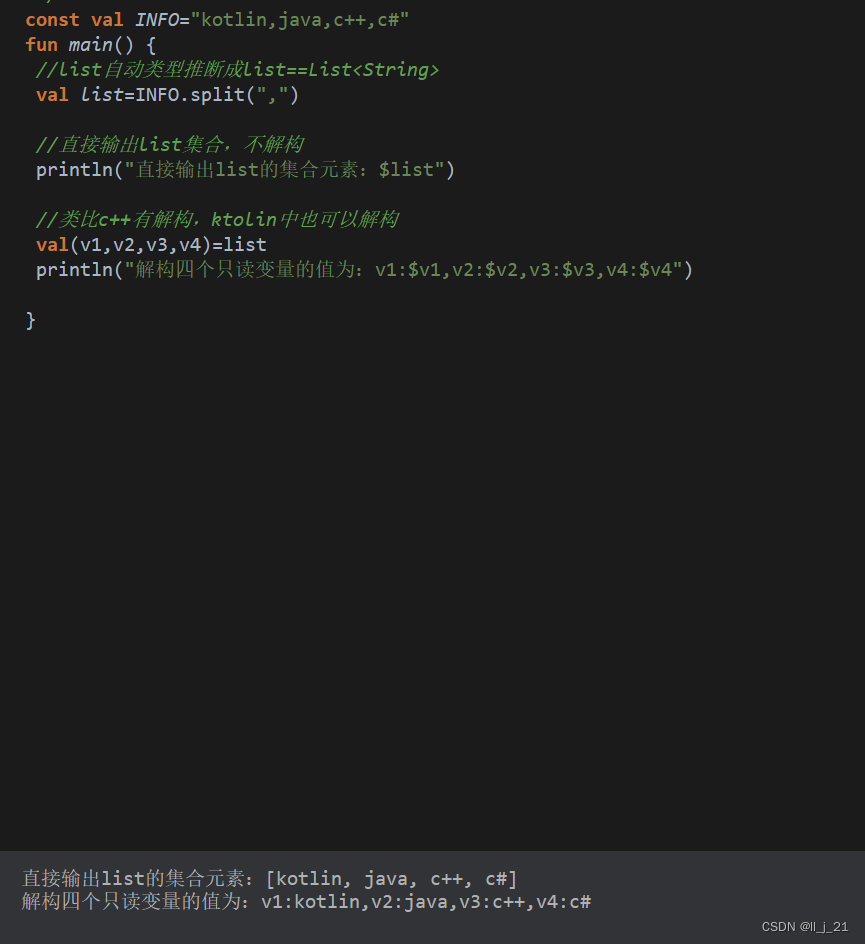
【第三阶段】kotlin语言的split
const val INFO"kotlin,java,c,c#" fun main() {//list自动类型推断成listList<String>val listINFO.split(",")//直接输出list集合,不解构println("直接输出list的集合元素:$list")//类比c有解构,ktoli…...
)
Navicat Premium连不上SQL Server?别慌,先检查这两个最容易忽略的配置(附驱动安装)
Navicat Premium连接SQL Server的实战排错指南:从报错到畅通的完整解决方案 第一次用Navicat Premium连接SQL Server数据库时,那种期待又忐忑的心情我太熟悉了。明明按照教程一步步填写了IP、端口、用户名和密码,点击"测试连接"后却…...

手把手教你把Windows虚拟内存文件pagefile.sys从C盘挪走,给SSD系统盘腾出几十G空间
彻底解放C盘空间:Windows虚拟内存文件迁移全指南 你是否遇到过这样的场景:刚装完系统时C盘还剩下大半空间,用着用着却突然弹出"磁盘空间不足"的警告?打开资源管理器一看,一个名为pagefile.sys的"巨无霸…...

深圳连续模五金冲压件
在深圳这座充满活力与创新的城市,五金冲压件行业发展得如火如荼。连续模五金冲压件作为其中的重要组成部分,广泛应用于各个领域。今天,我们就来深入了解一下深圳的连续模五金冲压件市场,并重点推荐深圳市机汇五金制品有限公司&…...
)
从一根线到稳定画面:深入解读HDMI TMDS差分信号的PCB设计要点(阻抗控制与端接电容)
从一根线到稳定画面:深入解读HDMI TMDS差分信号的PCB设计要点(阻抗控制与端接电容) 在4K/8K超高清视频逐渐普及的今天,HDMI接口作为消费电子领域最主流的数字视频传输标准,其信号完整性设计直接决定了最终画质表现。许…...

graph-autofusion:算子自动融合框架,让模型性能提升30%
前言 算子融合就像把多个快递包裹合并成一个,减少送货次数。 你有没有想过,为什么模型推理时,每个算子都要单独读写HBM(High Bandwidth Memory)?明明LayerNorm后面紧跟Add,为什么要分开算&#…...

医疗学术会议直播,和你想的不一样
从大学阶梯教室到五星级酒店宴会厅,从脊柱外科到肿瘤学术年会,VideoTV团队这3年做了30场医疗学术会议直播。有些坑踩过一次就不会再踩,有些坑每次都能遇到新花样。这篇文章不讲大道理,直接说我们在执行层面踩过哪些坑、怎么解决的…...

独立开发者如何利用Taotoken同时管理多个AI项目的模型调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken同时管理多个AI项目的模型调用 对于独立开发者而言,同时维护多个小型产品是常态。每个产品…...

146台储罐+10台喷淋塔,新能源项目为什么认准PPH?
在新能源材料项目的设备选型中,PPH正逐渐变成大多数厂家选择的一种材质。 最近美联新材料的新能源产业化项目,一口气向吉庆订了146台PPH贮罐、10台PPH喷淋塔,今天就借着这个真实项目,来聊一聊,PPH为什么能成成新能源项…...

RoboMaster电调通信协议逆向解析:如何用逻辑分析仪抓包调试CAN总线数据
RoboMaster电调通信协议逆向解析:如何用逻辑分析仪抓包调试CAN总线数据 当电机突然停止响应,或是反馈数据出现异常时,大多数开发者会陷入反复检查代码的循环。但真正的解决方案往往隐藏在那些肉眼不可见的CAN总线数据流中。本文将带你用逻辑…...

压路机远程监控运维管理平台方案
某压路机设备制造商发现传统的“卖设备售后维修”模式已难以为继。其售出的设备遍布各地工地,由于缺乏远程数据交互手段,制造商总部如同“盲人摸象”:既无法实时掌握设备在工地的具体位置和作业状态,也难以在设备出现电气故障或PL…...