分布式 - 消息队列Kafka:Kafka消费者和消费者组
文章目录
- 1. Kafka 消费者是什么?
- 2. Kafka 消费者组的概念?
- 3. Kafka 消费者和消费者组有什么关系?
- 4. Kafka 多个消费者如何同时消费一个分区?
1. Kafka 消费者是什么?
消费者负责订阅Kafka中的主题,并且从订阅的主题上拉取消息。与其他一些消息中间件不同的是:在Kafka的消费理念中还有一层消费组的概念,每个消费者都有一个对应的消费组。当消息发布到主题后,只会被投递给订阅它的每个消费组中的一个消费者。
2. Kafka 消费者组的概念?
假设我们有一个应用程序,它从一个Kafka主题读取消息,在对这些消息做一些验证后再把它们保存起来。应用程序需要创建一个消费者对象,订阅主题并开始接收消息、验证消息和保存结果。但过了一阵子,生产者向主题写入消息的速度超过了应用程序验证数据的速度,这时候该怎么办呢?如果只使用单个消费者来处理消息,那么应用程序会远远跟不上消息生成的速度。显然,此时很有必要对消费者进行横向伸缩。就像多个生产者可以向相同的主题写入消息一样,也可以让多个消费者从同一个主题读取消息。
Kafka消费者从属于消费者群组。一个群组里的消费者订阅的是同一个主题,每个消费者负责读取这个主题的部分消息。
① 假设主题T1有4个分区,我们创建了消费者C1,它是群组G1中唯一的消费者,用于订阅主题T1。消费者C1将收到主题T1全部4个分区的消息。
② 如果在群组G1里新增一个消费者C2,那么每个消费者将接收到两个分区的消息。假设消费者C1接收分区0和分区2的消息,消费者C2接收分区1和分区3的消息。
③ 如果群组G1有4个消费者,那么每个消费者将可以分配到一个分区。
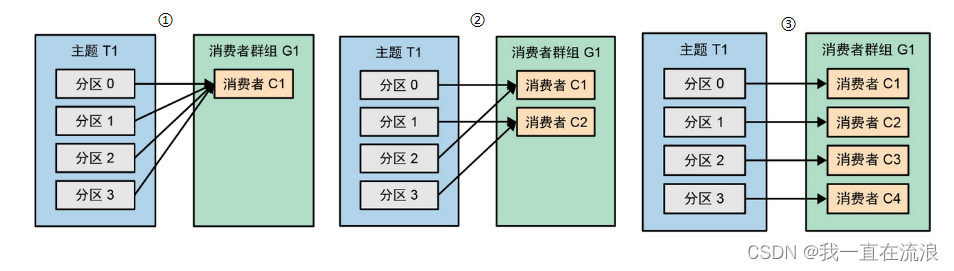
④ 如果向群组里添加更多的消费者,以致超过了主题的分区数量,那么就会有一部分消费者处于空闲状态,不会接收到任何消息。
向群组里添加消费者是横向扩展数据处理能力的主要方式。Kafka消费者经常需要执行一些高延迟的操作,比如把数据写到数据库或用数据做一些比较耗时的计算。在这些情况下,单个消费者无法跟上数据生成的速度,因此可以增加更多的消费者来分担负载,让每个消费者只处理部分分区的消息,这是横向扩展消费者的主要方式。于是,我们可以为主题创建大量的分区,当负载急剧增长时,可以加入更多的消费者。不过需要注意的是,不要让消费者的数量超过主题分区的数量,因为多余的消费者只会被闲置。
⑤ 除了通过增加消费者数量来横向伸缩单个应用程序,我们还经常遇到多个应用程序从同一个主题读取数据的情况。实际上,Kafka的一个主要设计目标是让Kafka主题里的数据能够满足企业各种应用场景的需求。在这些应用场景中,我们希望每一个应用程序都能获取到所有的消息,而不只是其中的一部分。只要保证每个应用程序都有自己的消费者群组就可以让它们获取到所有的消息。不同于传统的消息系统,横向伸缩消费者和消费者群组并不会导致Kafka性能下降。
在之前的例子中,如果新增一个只包含一个消费者的群组G2,那么这个消费者将接收到主题T1的所有消息,与群组G1之间互不影响。群组G2可以增加更多的消费者,每个消费者会读取若干个分区,就像群组G1里的消费者那样。作为整体来说,群组G2还是会收到所有消息,不管有没有其他群组存在。
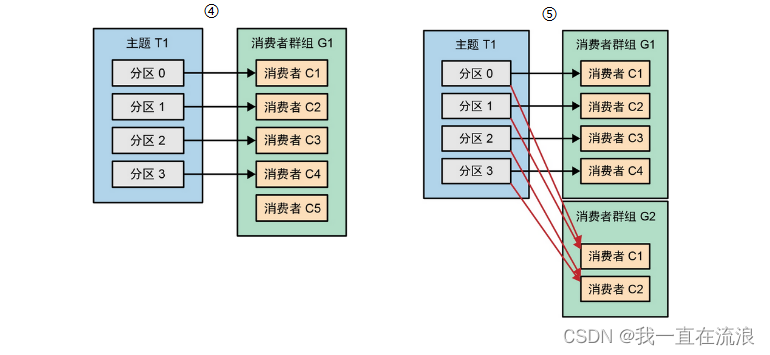
总的来说,就是为每一个需要获取主题全部消息的应用程序创建一个消费者群组,然后向群组里添加更多的消费者来扩展读取能力和处理能力,让群组里的每个消费者只处理一部分消息。
3. Kafka 消费者和消费者组有什么关系?
消费者组是一个逻辑上的概念,它将旗下的消费者归为一类,每一个消费者只属于一个消费者组。每一个消费组都会有一个固定的名称,消费者在进行消费前需要指定其所属消费者组的名称,这个可以通过消费者客户端参数group.id来配置,默认值为空字符串。 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由同一个消费者组内的一个消费者来消费。
消费者组的作用是实现负载均衡和容错性,因为每个消费者只能读取主题中的一部分消息,而消费者组中的所有消费者共同读取整个主题中的所有消息。
4. Kafka 多个消费者如何同时消费一个分区?
Kafka 中的每个分区只能被一个消费者消费,如果多个Kafka消费者要同时消费相同主题下相同分区的数据,需要将它们放到不同的消费者组中。在Kafka中,一个消费者组中的每个消费者会消费主题下不同分区的消息,而不同消费者组中的消费者则可以同时消费相同分区的数据。这样可以实现多个消费者同时消费相同分区的数据,提高消费效率和可靠性。同时,Kafka还提供了一些负载均衡策略,可以根据消费者组中消费者的数量和消费能力来自动分配Partition,以实现更好的负载均衡。
相关文章:
分布式 - 消息队列Kafka:Kafka消费者和消费者组
文章目录 1. Kafka 消费者是什么?2. Kafka 消费者组的概念?3. Kafka 消费者和消费者组有什么关系?4. Kafka 多个消费者如何同时消费一个分区? 1. Kafka 消费者是什么? 消费者负责订阅Kafka中的主题,并且从…...

feign调用和被调用者字段名称不对应解决
如果您在使用Feign时,尝试使用SerializedName("id")或JsonAlias("id")修饰字段,但仍然无法正常生效,可能是由于以下原因: Feign不会直接使用Gson库进行序列化和反序列化,而是使用了默认的Jackson库…...
【UE4 RTS】07-Camera Boundaries
前言 本篇实现的效果是当CameraPawn移动到地图边缘时会被阻挡。 效果 步骤 1. 打开项目设置,在“引擎-碰撞”中,点击“新建Object通道” 新建通道命名为“MapBoundaries”,然后点击接受 2. 向视口中添加 阻挡体积 调整阻挡体积的缩放 向四…...
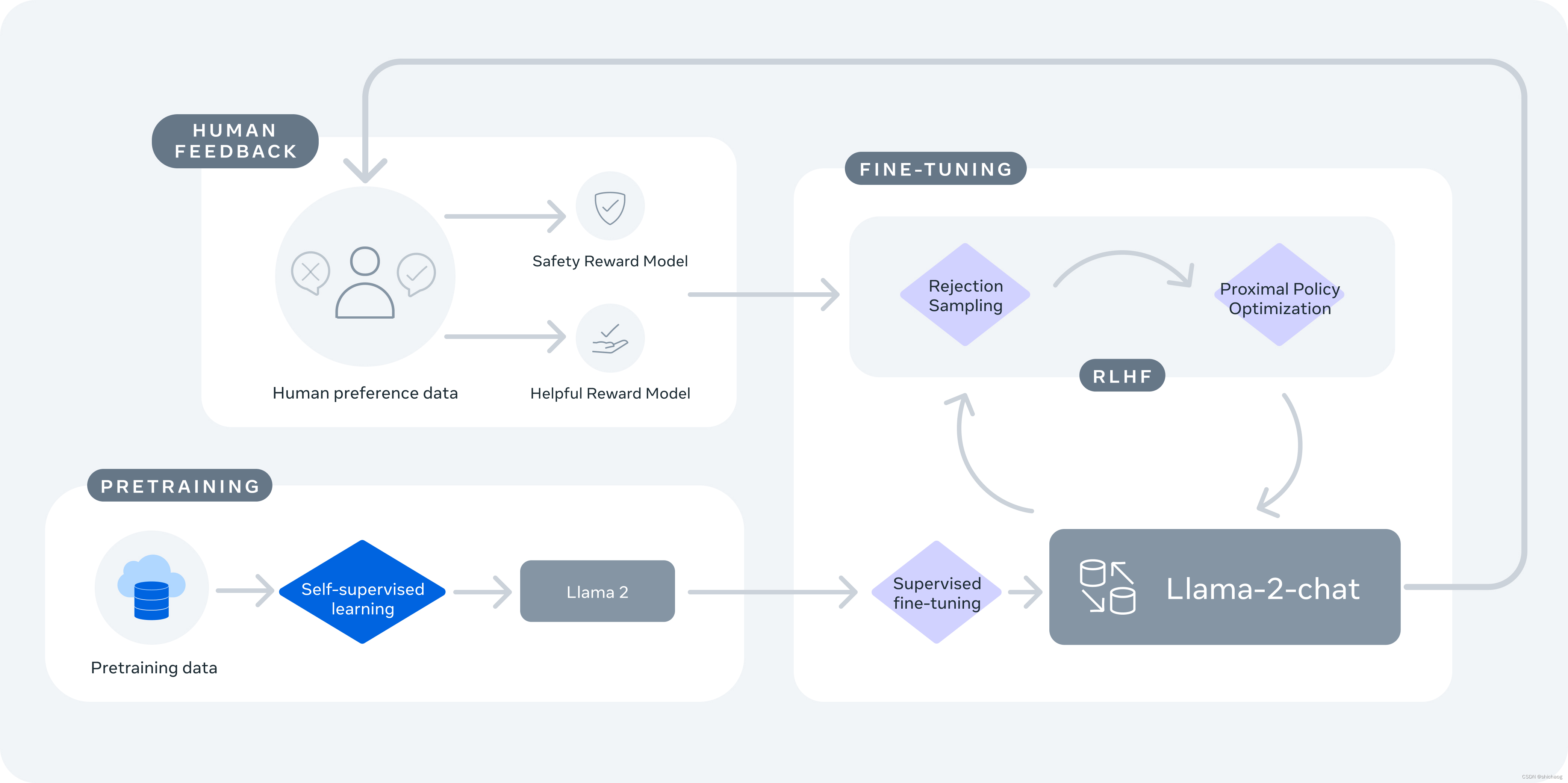
大语言模型之二 GPT发展史简介
得益于数据、模型结构以及并行算力的发展,大语言模型应用现今呈井喷式发展态势,大语言神经网络模型成为了不可忽视的一项技术。 GPT在自然语言处理NLP任务上取得了突破性的进展,扩散模型已经拥有了成为下一代图像生成模型的代表的潜力&#x…...
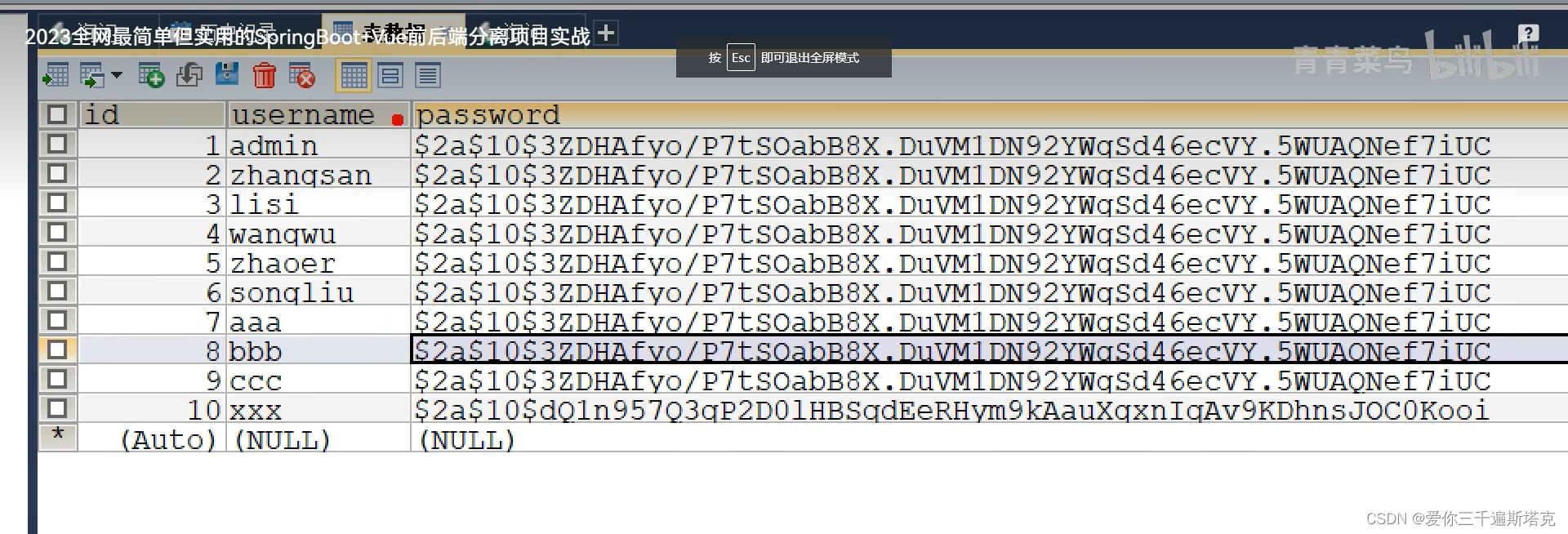
前后端分离------后端创建笔记(09)密码加密网络安全
本文章转载于【SpringBootVue】全网最简单但实用的前后端分离项目实战笔记 - 前端_大菜007的博客-CSDN博客 仅用于学习和讨论,如有侵权请联系 源码:https://gitee.com/green_vegetables/x-admin-project.git 素材:https://pan.baidu.com/s/…...

《Effects of Graph Convolutions in Multi-layer Networks》阅读笔记
一.文章概述 本文研究了在XOR-CSBM数据模型的多层网络的第一层以上时,图卷积能力的基本极限,并为它们在数据中信号的不同状态下的性能提供了理论保证。在合成数据和真实世界数据上的实验表明a.卷积的数量是决定网络性能的一个更重要的因素,而…...

低代码助力传统制造业数字化转型策略
随着制造强国战略逐步实施,制造行业数字化逐渐进入快车道。提高生产管理的敏捷性、加强产品的全生命周期质量管理是企业数字化转型的核心诉求,也是需要思考的核心价值。就当下传统制造业的核心问题来看,低代码是最佳解决方案,那为…...

什么叫做云计算
什么叫做云计算 相信大多数人对云计算或者是云服务的认识还停留在仅仅听过这个名词,但是对其真正的定义或者意义还不甚了解的层面。甚至有些技术人员,如果日常的业务不涉及到云服务,可能对其也只是一知半解的程度。首先云计算准确的讲只是云服…...

springboot 使用zookeeper实现分布式队列
一.添加ZooKeeper依赖:在pom.xml文件中添加ZooKeeper客户端的依赖项。例如,可以使用Apache Curator作为ZooKeeper客户端库: <dependency><groupId>org.apache.curator</groupId><artifactId>curator-framework</…...
地理数据的双重呈现:GIS与数据可视化
前一篇文章带大家了解了GIS与三维GIS的关系,本文就GIS话题带大家一起探讨一下GIS和数据可视化之间的关系。 GIS(地理信息系统)和数据可视化在地理信息科学领域扮演着重要的角色,它们之间密切相关且相互增强。GIS是一种用于采集、…...
- MediaPlayer生命周期)
Android 13 Media框架(3)- MediaPlayer生命周期
上一节了解了MediaPlayer api的使用,这一节就我们将会了解MediaPlayer的生命周期与api使用细节。 1、MediaPlayer生命周期 MediaPlayer.java 一开始有对生命周期的描述,这里对这些内容进行翻译: MediaPlayer 是线程不安全的,创建…...
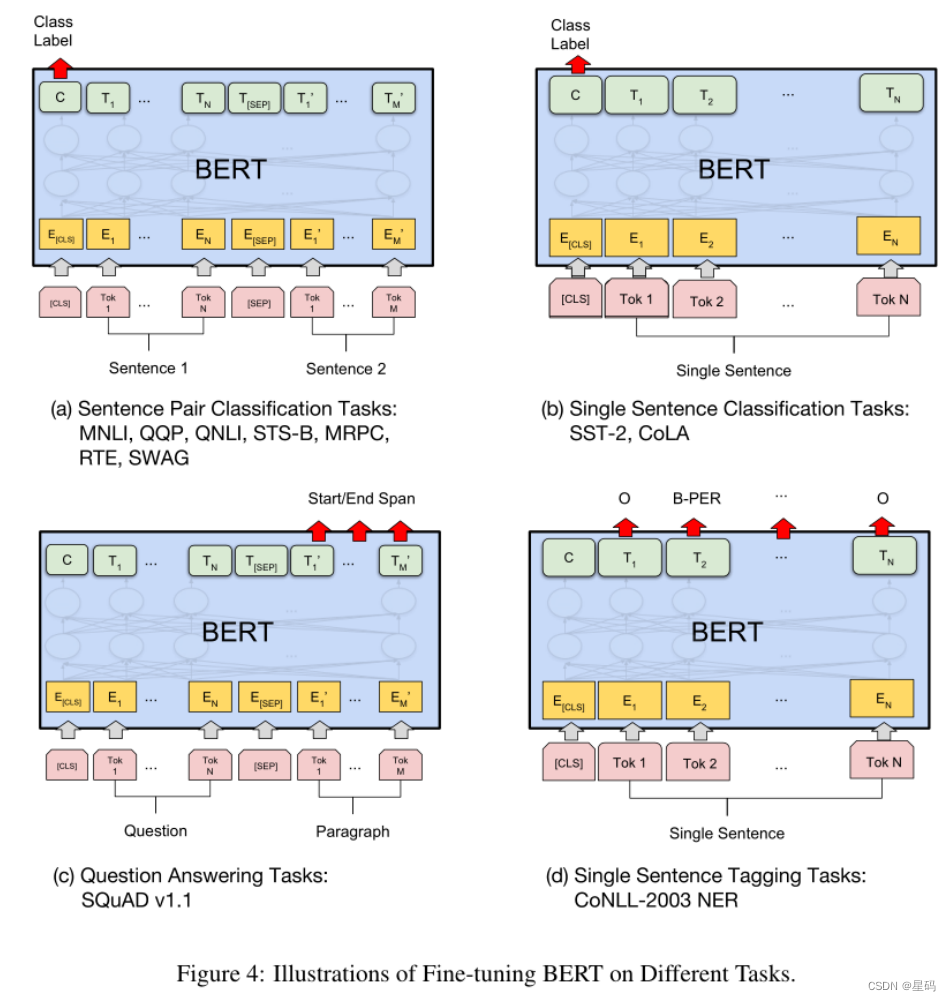
[oneAPI] BERT
[oneAPI] BERT BERT训练过程Masked Language Model(MLM)Next Sentence Prediction(NSP)微调 总结基于oneAPI代码 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517 Intel DevCloud for oneAPI&…...

F1-score解析
报错:valueError: Target is multiclass but average‘binary’. Please choose another average setting, one of 原因:使用from sklearn.metrics import f1_score多类别计算F1-score时报错,改函数的参数即可,如:f1_s…...
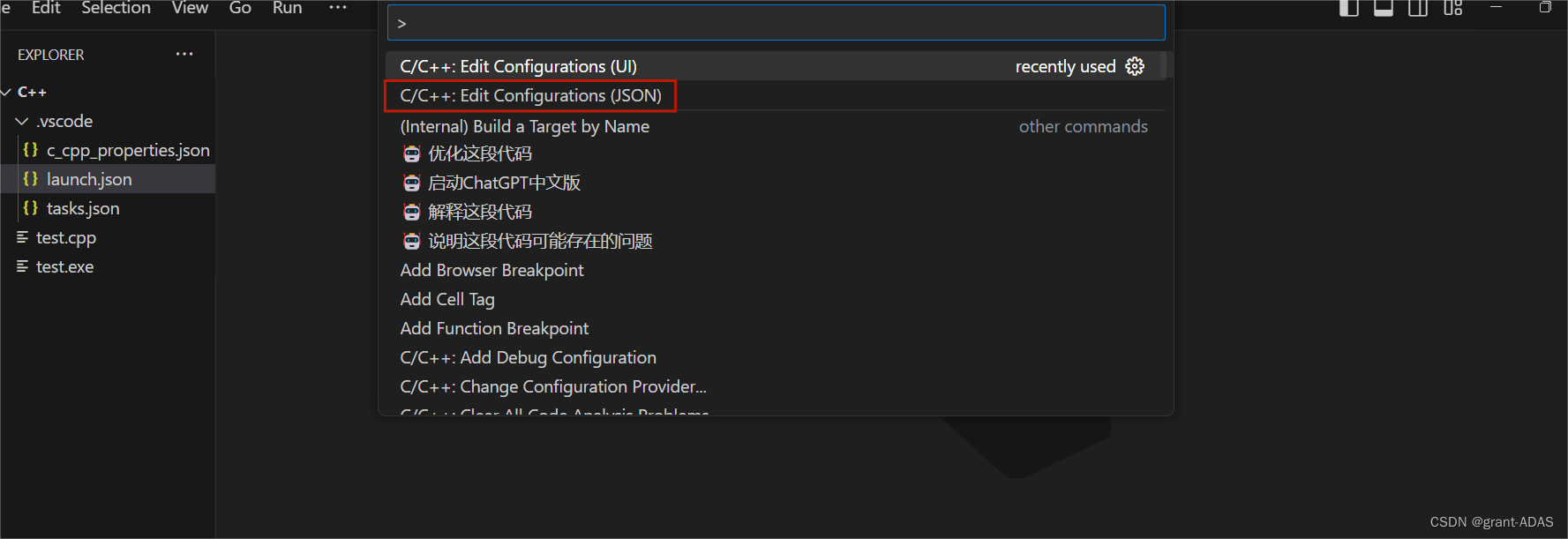
windows11下配置vscode中c/c++环境
本文默认已经下载且安装好vscode,主要是解决环境变量配置以及编译task、launch文件的问题。 自己尝试过许多博客,最后还是通过这种方法配置成功了。 Linux(ubuntu 20.04)配置vscode可以直接跳转到配置task、launch文件,不需要下载mingw与配…...

Max Sum
一、题目 Given a sequence a[1],a[2],a[3]…a[n], your job is to calculate the max sum of a sub-sequence. For example, given (6,-1,5,4,-7), the max sum in this sequence is 6 (-1) 5 4 14. Input The first line of the input contains an integer T(1<T<…...
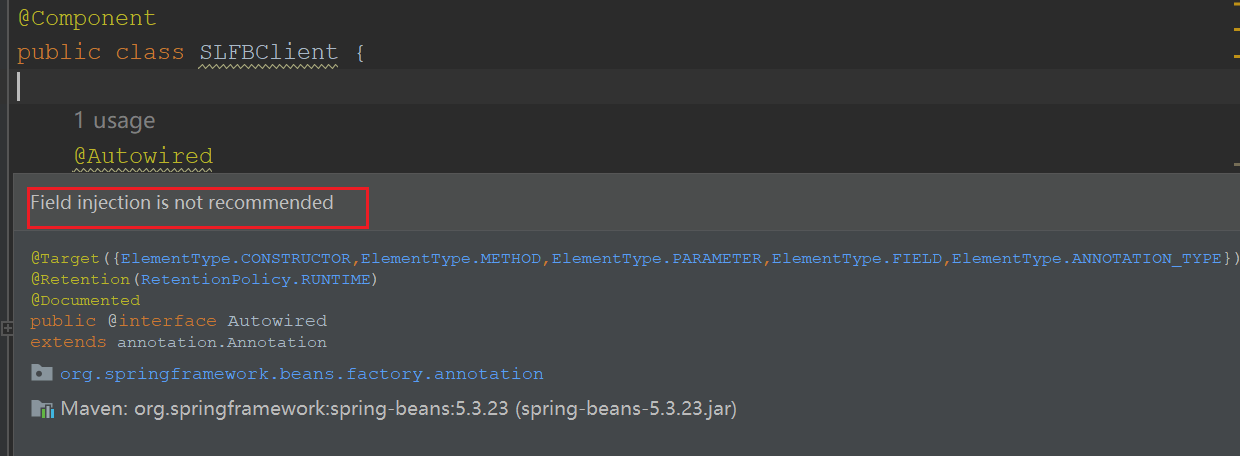
Field injection is not recommended
文章目录 1. 引言2. 不推荐使用Autowired的原因3. Spring提供了三种主要的依赖注入方式3.1. 构造函数注入(Constructor Injection)3.2. Setter方法注入(Setter Injection)3.3. 字段注入(Field Injection) 4…...
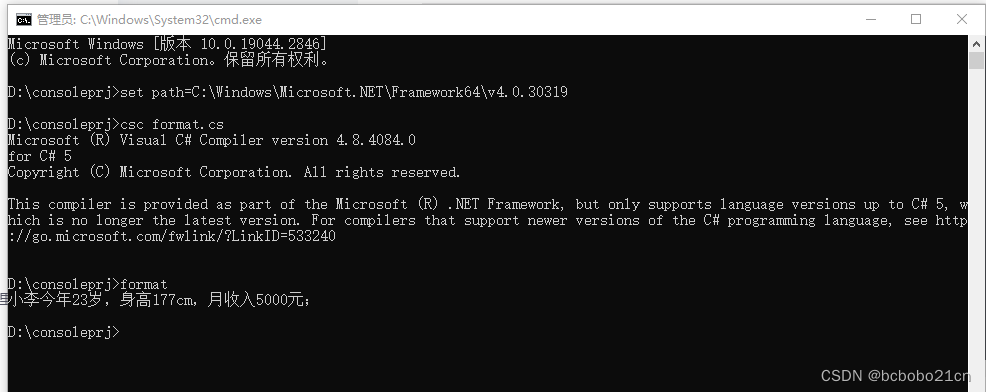
C#字符串占位符替换
using System;namespace myprog {class test{static void Main(string[] args){string str1 string.Format("{0}今年{1}岁,身高{2}cm,月收入{3}元;", "小李", 23, 177, 5000);Console.WriteLine(str1);Console.ReadKey(…...
ChatGPT等人工智能编写文章的内容今后将成为常态
BuzzFeed股价上涨200%可能标志着“转向人工智能”媒体趋势的开始。 周四,一份内部备忘录被华尔街日报透露BuzzFeed正计划使用ChatGPT聊天机器人-风格文本合成技术来自OpenAI,用于创建个性化盘问和将来可能的其他内容。消息传出后,BuzzFeed的…...
)
【Sklearn】基于梯度提升树算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于梯度提升树算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理 梯度提升树(Gradient Boosting Trees)是一种集成学习方法,用于解决分类和回归问题。它通过将多个弱学习器(通常…...

什么叫做云计算?
相信大多数人对云计算或者是云服务的认识还停留在仅仅听过这个名词,但是对其真正的定义或者意义还不甚了解的层面。甚至有些技术人员,如果日常的业务不涉及到云服务,可能对其也只是一知半解的程度。首先云计算准确的讲只是云服务中的一部分&a…...

武林外传十年之约手游官网下载:武林外传十年之约最新官方下载渠道
《武林外传十年之约》又名《武林外传手游》《武林外传怀旧版》《武林外传正版复刻》,由安徽游昕联合忆往游戏运营的正版武侠 MMORPG 手游。1:1 复刻同福客栈、七侠镇、五霸岗、十八里铺等经典场景,完美还原枪豪、剑客、术士、医师四大职业体系࿰…...

别再手动拖拽了!用CodeWave自由布局5分钟搞定一个高还原度后台管理页
5分钟高保真还原设计稿:CodeWave自由布局实战指南 每次拿到设计师发来的Figma稿子,你是不是也经历过这样的痛苦?在传统开发工具里手动调整像素级间距,反复比对色值,调试响应式效果到深夜…上周我接手一个电商后台改版项…...

tinychain实战教程:10步掌握区块链交易验证与挖矿机制
tinychain实战教程:10步掌握区块链交易验证与挖矿机制 【免费下载链接】tinychain A pocket-sized implementation of Bitcoin 项目地址: https://gitcode.com/gh_mirrors/ti/tinychain tinychain是一个轻量级的比特币实现,让你能够快速理解区块链…...

图片批量识别提取信息
图片批量识别提取信息工具,是用aardio写的,调用微信OCR识别图片中的信息,识别正确率非常高,用于提取各类证件和文档,对于在基层村、社区工作的人员是很有帮助的。 喜欢的朋友可以下载试用。分享了「图批量识别提取信息…...

H3CSE 高性能园区网:生成树保护机制
H3CSE 高性能园区网:生成树保护机制一、生成树保护机制1. BPDU保护1.1 边缘端口特点及问题端口基础特性存在的安全隐患1.2 BPDU保护机制核心防护逻辑机制运行优势1.3 BPDU保护配置配置使用规范H3C设备配置命令2. 根桥保护2.1 根桥保护机制2.2 根桥保护配置要求2.3 根…...

【Lovable前端开发实战指南】:20年专家亲授5个让团队抢着用的可维护性设计模式
更多请点击: https://kaifayun.com 第一章:Lovable前端开发的核心理念与可维护性本质 Lovable前端开发并非追求炫酷动效或技术堆砌,而是以人本设计为原点,将开发者体验(DX)与用户界面体验(UX&a…...

Keil µVision TAB显示异常问题分析与解决方案
1. 问题现象与背景分析在Keil Vision集成开发环境中,部分用户遇到了编辑器界面显示异常的问题。具体表现为:当代码中包含TAB字符(制表符)时,屏幕上会出现奇怪的显示错乱,原本应该显示为空白缩进的区域&…...

什么,锐捷极简以太彩光一张网竟然有两幅面孔?
在园区网络的建设中,我们常常面临一个两难选择:教学或办公楼需要大带宽,宿舍或病房楼需要弹性带宽。如果分别建两张网,成本翻倍、运维复杂。 锐捷极简以太彩光方案给出的答案是:一张物理网络,同时融合两种…...

C251编译器变量声明顺序与内存空间指定符详解
1. C251编译器变量声明语法错误解析最近在将8051代码移植到251平台时,遇到一个看似简单却令人困惑的编译错误。当我使用const code int x;这样的变量声明方式时,C251编译器报出了"Error 25: syntax error near int"的错误。这个错误信息看起来…...

王炸!史上最强的智慧园区管理系统,java最新技术栈,支持信创!
一、项目简介本软件是一款面向智慧园区与智慧楼宇的综合管理系统,采用先进的微服务架构(SpringCloud)、JDK 17、Spring Boot 3.2、MySQL、Vue3、Vite 和 UniApp 技术栈,支持小程序、H5、公众号、App 多端适配,前后端分…...