大数据岗位秋招面试八股文总结(不定时更新)
HIVE面试题
内部表和外部表的区别
未被external修饰的是内部表,被external修饰的是外部表;
内部表数据由Hive自身管理,外部表由HDFS管理;
删除内部表会直接删除元数据及存储数据,删除外部表,仅仅会删除元数据,数据文件不会删除。
分区和分桶的区别
分区是按照分区字段在HDFS上建立子文件夹,分区内的数据存放在子文件夹内,查询时不需要全局扫描,只扫描对应分区文件夹的数据。
而分桶是按分桶字段对数据取hash值,值相同的放在同一个分桶文件里,分桶生成的是分桶文件,分区对应的是子文件夹;
分区和分桶最大的区别是:
首先,分桶是随机的分割数据,分区是非随机的分割数据,分桶是按照分桶字段取哈希函数,相对比较均匀;分区表按照分区字段的值进行分割,容易产生数据倾斜。
其次,分桶对应的是不同的文件,分区对应的是HDFS上的目录,桶表对应的是目录里的文件。
hive的文件存储格式
- TextFile:hive的默认存储格式,行存储,数据不做压缩,需结合GZip/BZip2压缩;加载数据速度最快,但磁盘开销较大,查询效率较低
- SequenceFile:行存储,压缩文件可分割和合并;查询效率较高,但存储空间消耗较大。
- RcFile:数据按行分块,每块再按照列存储;查询效率较高,压缩快,快速列存取,存储空间较小;(不支持implala查询引擎)
- OrcFile:数据按行分块,每块再按列存储;压缩快,快速列存取,效率比RcFile更快,是Rcfile的改良;(不支持impala查询引擎)
- Parquet:列存储;相对于RC格式,压缩比较低,查询效率较低(但是支持impala、Presto等查询引擎及Spark计算引擎,支持Hadoop生态中其它组件的结合)
附加:Hive压缩格式:gzib,bzip2,lzo,snappy,其中snappy的压缩比和压缩速度及解压缩速度最快(我司用parquet存储+snappy压缩格式)
Hive执行一段sql后会经过什么步骤
- 语法解析:将sql语句转换为抽象的语法树
- 语义解析:遍历语法树,抽象出查询的基本组成单元QueryBlock
- 生成逻辑执行计划:遍历QueryBlock,生成操作树
- 优化逻辑执行计划:
- 生成物理执行计划:遍历操作树,编译成MR任务
- 优化物理执行计划:对MR任务进行转换,生成最终执行计划
HiveSQL调优
- 尽量减少使用distinct,改用group by ,distinct 只使用一个reduce处理,一个Reduce处理数据量太大,容易产生数据倾斜
- null值容易产生数据倾斜,可以对null值先过滤处理,然后再与其它数据union,也可以对null值采用字符串+拼接随机数字的方式,让null值数据分散在不同的reduce处理
- 对于多次查询使用的sql,通过with语法放到内存中,多次使用减少重复计算
- 多个union all 的情况下,放在最后再使用group by 操作,这样减少MR作业数
- 列裁剪,编写sql时只查询需要的列,多使用分区信息
- in/exists 改成left semi join 更高效
Hive小文件是如何产生的原因、影响和解决方案
- 产生原因:
1.动态分区插入数据,产生大量的小文件,从而导致map数量剧增。
2.reduce数量越多,小文件也越多(reduce的个数和输出文件是对应的)。
3.数据源本身就包含大量的小文件。
- 过多小文件问题的影响
1.从Hive的角度看,小文件会开很多map,一个map开一个JVM去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重影响性能。
2.在HDFS中,每个小文件对象约占150byte,如果小文件过多会占用大量内存,这样NameNode内存容量严重制约了集群的扩展。
- 小文件问题的解决方案
从小文件产生的途经就可以从源头上控制小文件数量
1.使用ORC或Parquet格式作为表存储格式,不要用textfile,在一定程度上可以减少小文件。
2.减少reduce的数量(可以使用参数进行控制)。
3.少用动态分区,用时记得按distribute by分区。
4.使用hadoop archive命令把小文件进行归档。
5.开启map端小文件合并
Hive参数调优
- 合理控制Map和Reduce数量
Map: 合并小文件,减少map个数:set hive.merge.mapredfiles = true; --开启小文件合并增加map个数:当文件很小,小于128M,但是数据量有几千万行,放到一个map中执行很慢,可以通过自定义map个数增加map数:set mapred.map.tasks=10;
Reduce: reduce的个数设定极大影响任务执行效率,不指定reduce个数的情况下,Hive会根据默认配置计算reduce个数.
reduce个数的计算公式:Min(每个job最大reduce数,总输入数据量/每个reduce处理的数据量)
hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,默认为1000^3=1G)
hive.exec.reducers.max(每个任务最大的reduce数,默认为999)
手动指定reduce个数:set mapred.reduce.tasks = 15;
哪些情况下不管数据量多的,不管如何配置参数,只有一个reduce?
1.没使用group by, select count()
2.用了order by
3.有笛卡尔集
(这些情况都是全局的)
- 开启本地执行: set hive.exec.mode.local.auto=truel; 数据量较小的查询直接在本地节点查询
- 开启fetch执行:set hive.fetch.task.conversion=more; 一些全局查询、字段查询、limit查找都不走mapRecuce
- 开启map端聚合:set hive.map.aggr = true;
- 有数据倾斜时进行负载均衡:set hive.groupby.skewindata = true;
- 开启并行执行:
set hive.exec.parallel=true; //打开任务并行执行
set hive.exec.parallel.thread.number=16; //同一个sql允许最大并行度,默认为8。
- JVM的重用:
- 开启推测执行:因为程序Bug、负载不均衡或者资源分布不均等原因,会造成同一个作业的多个任务之间运行速度不一致,有些任务的运行速度可能明显慢于其他任务(比如一个作业的某个任务进度只有50%,而其他所有任务已经运行完毕),则这些任务会拖慢作业的整体执行进度。为了避免这种情况发生,Hadoop采用了推测执行(Speculative Execution)机制,它根据一定的法则推测出“拖后腿”的任务,并为这样的任务启动一个备份任务,让该任务与原始任务同时处理同一份数据,并最终选用最先成功运行完成任务的计算结果作为最终结果。
数据倾斜怎么解决
- 空值引发的数据倾斜
解决方案:
第一种:可以直接不让null值参与join操作,即不让null值有shuffle阶段
第二种:因为null值参与shuffle时的hash结果是一样的,那么我们可以给null值随机赋值,这样它们的hash结果就不一样,就会进到不同的reduce中:
- 不同数据类型引发的数据倾斜
解决方案:
如果key字段既有string类型也有int类型,默认的hash就都会按int类型来分配,那我们直接把int类型都转为string就好了,这样key字段都为string,hash时就按照string类型分配了:
- 不可拆分大文件引发的数据倾斜
解决方案:
这种数据倾斜问题没有什么好的解决方案,只能将使用GZIP压缩等不支持文件分割的文件转为bzip和zip等支持文件分割的压缩方式。
所以,我们在对文件进行压缩时,为避免因不可拆分大文件而引发数据读取的倾斜,在数据压缩的时候可以采用bzip2和Zip等支持文件分割的压缩算法。
- 数据膨胀引发的数据倾斜
解决方案:
在Hive中可以通过参数 hive.new.job.grouping.set.cardinality 配置的方式自动控制作业的拆解,该参数默认值是30。表示针对grouping sets/rollups/cubes这类多维聚合的操作,如果最后拆解的键组合大于该值,会启用新的任务去处理大于该值之外的组合。如果在处理数据时,某个分组聚合的列有较大的倾斜,可以适当调小该值。
- 表连接时引发的数据倾斜
解决方案:
通常做法是将倾斜的数据存到分布式缓存中,分发到各个Map任务所在节点。在Map阶段完成join操作,即MapJoin,这避免了 Shuffle,从而避免了数据倾斜。
- 确实无法减少数据量引发的数据倾斜
解决方案:
这类问题最直接的方式就是调整reduce所执行的内存大小。
调整reduce的内存大小使用mapreduce.reduce.memory.mb这个配置。
Spark面试题
Spark的执行原理流程:
SparkContext向资源管理器注册并申请资源 ---->
资源管理器根据资源情况分配Executor,然后启动Executor -->
Executor启动后发送心跳至资源管理器 --->
SparkContext根据RDD之间依赖关系构建DAG运行图 --->
然后将DAG图分解成多个Stage --->
把Stage发送给StageScheduler -->
每个stage包含一个或多个task任务,StageScheduler将Task发放给Executor运行,同时SparkContext将应用程序代码发给Executor --->
Task在Executor上运行,运行完毕释放所有资源
Stage划分依据:Stage划分的依据是宽依赖,遇到窄依赖就加入本stage,遇到宽依赖进行Stage切分;
何时产生宽依赖:reduceByKey, groupByKey等算子,会导致宽依赖的产生。
Spark on Yarn Yarn-cluster模式和Yarn-client 模式的区别:
Yarn-Cluster模式下,Driver运行在Application Master上,Application Master 同时负责从Yarn申请资源并监督作业的运行情况,用户提交作业之后,客户端就可以关闭,作业会继续在Yarn上运行。
Yarn-clinet模式下,Driver是运行在客户端,Applicatiion Master仅仅向Yarn请求Executor,然后有client跟containner通信调度工作,所以client不能关闭。
Job、Stage、task的概念:
- Spark中的数据都是抽象为RDD的,RDD分为transformation算子和action算子,转换算子不会被真正执行,只有遇到行动算子时,任务才会被执行,提交一个Job,每遇到有一个Action算子,生成一个job;
- 每个Job包含一个或多个Stage,而Stage是由RDD之间的宽窄依赖决定的,遇到宽依赖就会进行shuffle,进行Stage的拆分,遇到窄依赖就加入到该Stage中
- Stage继续往下拆解就是Task,Task是Spark执行的最小单元,Task的数量其实就是Stage的并行度
Spark的shuffle 和 Hadoop的shuffle的联系和区别:
联系:两者都是将Mapper端的输出数据按key进行Partition,不同的Partition送到不同的reduce进行处理;Spark中的很多计算是作为MR计算框架的一种优化实现。
区别:
- 从逻辑角度来看:
shuffle 就是一个GroupByKey的过程,两者没有本质区别。只是MR有多次排序,Spark尽量避免了MR shuffle中的多余的排序
- 从实现角度看:
MR将处理流程划分出明显的几个阶段:map,splil,merge,shuffle,sort,reduce等,每个阶段各司其职,按串行的方式实现每个阶段的功能;
在Spark中,没有这样功能明确的阶段,只有不同的Stage和一系列的transformation操作,所以splil,merge,aggregate等操作都包含着Transformation中
- 从数据流角度看:
Mr 只能从一个map stage接受数据,Spark可以从多个Map stage shuffle数据(宽依赖,可以有多个数据源)
- 从数据粒度角度:
Spark的粒度更细,可以更及时的获取到record 与HashMap中相同的records进行合并
- 从性能优化角度:
Spark考虑的更全面,Spark针对不同类型的操作、不同类型的参数,会使用不同类型的shuffle
- 哪些算子涉及到shuffle操作?
sortBykey,groupBykey、reduceBykey、join、countBykey、cogroup等聚合操作的算子
Spark的资源参数调优
num-executors --执行器个数
executor-memory --每个Executor的内存大小 (一般 所有Executor的总内存占用量不要超过 Yarn 的内存资源的 50%)
executor-cores --每个Executor的并行执行的task个数 (一般情况下总核数不要超过 Yarn 队列中 Cores 总数量的 50%。)
driver-memory --driver内存大小,一般默认1g
spark.default.parallelizm: --每个Stage的默认Task数量
Spark数据倾斜 shuffle操作问题解决
原理:数据倾斜就是进行shuffle的时候,必须将各个节点上相同的key拉取到某个节点上的一个task来进行处理,此时如果某个key对应的数据量特别大的话,就会发生数据倾斜。
数据倾斜问题发现和定位:通过spark web ui 来查看当前运行的stage各个task分配的数据量, 从而进一步确定是不是task分配的数据不均匀导致了数据倾斜,知道数据倾斜发生在哪个stage之后,我们就需要根据stage划分原理,推算出来发生倾斜的那个stage对应代码中的哪一部分,这部分代码中肯定会有一个shuffle类型的算子,通过countByKey查看各个key的分布.
数据倾斜的解决方案
- 过滤少数导致倾斜的key
- 提高shuffle操作的并行度
- 如果是聚合类算子,使用局部聚合和全聚合的方式。
方案实现思路:这个方案的核心实现思路就是进行两阶段聚合。第一次是局部聚合,先给每个key都打上一个随机数,比如10以内的随机数,此时原先一样的key就变成不一样的了,比如(hello, 1) (hello, 1) (hello, 1) (hello, 1),就会变成(1_hello, 1) (1_hello, 1) (2_hello, 1) (2_hello, 1)。接着对打上随机数后的数据,执行reduceByKey等聚合操作,进行局部聚合,那么局部聚合结果,就会变成了(1_hello, 2) (2_hello, 2)。然后将各个key的前缀给去掉,就会变成(hello,2)(hello,2),再次进行全局聚合操作,就可以得到最终结果了,比如(hello, 4)。
- 如果是join类型的算子,则使用随机前缀和扩容RDD进行join(因为是由于RDD中有大量的key导致数据倾斜的)
方案实现思路:将含有较多倾斜key的RDD扩大多倍,与相对分布均匀的RDD配一个随机数。
为什么Spark比Hive(MR)执行快?
- Spark和MapReduce的计算都发生在内存中,区别在于:MapReduce通常需要将计算的中间结果写入磁盘,然后还要读取磁盘,从而导致了频繁的磁盘IO。Spark则不需要将计算的中间结果写入磁盘,这得益于Spark的RDD和DAG(有向无环图),其中DAG记录了job的stage以及在job执行过程中父RDD和子RDD之间的依赖关系。中间结果能够以RDD的形式存放在内存中,且能够从DAG中恢复,大大减少了磁盘IO。
- Spark vs MapReduce Shuffle的不同Spark和MapReduce在计算过程中通常都不可避免的会进行Shuffle,两者至少有一点不同:MapReduce在Shuffle时需要花费大量时间进行排序,排序在MapReduce的Shuffle中似乎是不可避免的; Spark在Shuffle时则只有部分场景才需要排序,支持基于Hash的分布式聚合,更加省时;
- MapReduce采用了多进程模型,而Spark采用了多线程模型。多进程模型的好处是便于细粒度控制每个任务占用的资源,但每次任务的启动都会消耗一定的启动时间。就是说MapReduce的Map Task和Reduce Task是进程级别的,而Spark Task则是基于线程模型的,就是说mapreduce 中的 map 和 reduce 都是 jvm 进程,每次启动都需要重新申请资源,消耗了不必要的时间。Spark则是通过复用线程池中的线程来减少启动、关闭task所需要的开销。
简述Spark的宽窄依赖,以及Spark如何划分stage,每个stage又根据什么决定task个数?
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖。
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
Stage是如何划分的呢?
根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
每个stage又根据什么决定task个数?
Stage是一个TaskSet,将Stage根据分区数划分成一个个的Task。
相关文章:
)
大数据岗位秋招面试八股文总结(不定时更新)
HIVE面试题 内部表和外部表的区别 未被external修饰的是内部表,被external修饰的是外部表; 内部表数据由Hive自身管理,外部表由HDFS管理; 删除内部表会直接删除元数据及存储数据,删除外部表,仅仅会删除…...

MATLAB高分辨率图片
把背景调黑,把曲线调黄,把grid调白,调调字体字号的操作 close all a0:0.1:10; noise2*rand(1,length(a)); bsin(a)sin(3*a)noise;plot(a,b,y,linewidth,2); ylim([-3 4]) %y轴范围 set(gca,xgrid,on,ygrid,on,gridlinestyle,-,Grid…...

Spring Clould 消息队列 - RabbitMQ
视频地址:微服务(SpringCloudRabbitMQDockerRedis搜索分布式) 初识MQ-同步通讯的优缺点(P61,P62) 同步和异步通讯 微服务间通讯有同步和异步两种方式: 同步通讯:就像打电话&…...
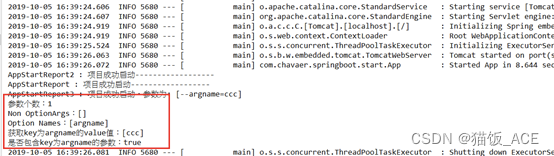
【SpringBoot】中的ApplicationRunner接口 和 CommandLineRunner接口
1. ApplicationRunner接口 用法: 类型: 接口 方法: 只定义了一个run方法 使用场景: springBoot项目启动时,若想在启动之后直接执行某一段代码,就可以用 ApplicationRunner这个接口,并实现接口…...

微信小程序前后端开发快速入门(完结篇)
这篇是微信小程序前后端快速入门完结篇了,今天利用之前学习过的所有知识做一个新的项目「群登记助手v1.0」小程序。 整体技术架构:小程序原生前端小程序云开发。 经历了前面教程的学习,大家有了一定的基础,所以本次分享重心主要是…...

【Linux】进程间通信之消息队列
文章目录 消息队列的概念消息队列的出队特点消息队列函数接口获取消息队列向消息队列发送消息接收消息操作消息队列的接口 代码演示ipcs命令 消息队列的概念 消息队列提供进程间数据块传输的方法,传输的每一个数据块都认为是有类型的,不同的数据块是有优…...

一次Linux中的木马病毒解决经历(6379端口---newinit.sh)
病毒入侵解决方案 情景 最近几天一直CPU100%,也没有注意看到了以为正常的服务调用,直到腾讯给发了邮件警告说我的服务器正在入侵其他服务器的6379端口,我就是正常的使用不可能去入侵别人的系统的,这是违法的. 排查 既然入侵6379端口,就怀疑是通过我的Redis服务进入的我的系统…...

ProtoBuf
文章目录 1.认识 ProtoBuf2. 安装ProtoBuf3. 快速上手 ProtoBuf4. proto3 语法5. probuf 实战6. 总结 1.认识 ProtoBuf 在认识 啥是 ProtoBuf 之前我们先来 回顾一下 (或 了解 一下 啥是 序列化) 序列化概念回顾 : 图一 : 回顾 序列化 ,下面…...
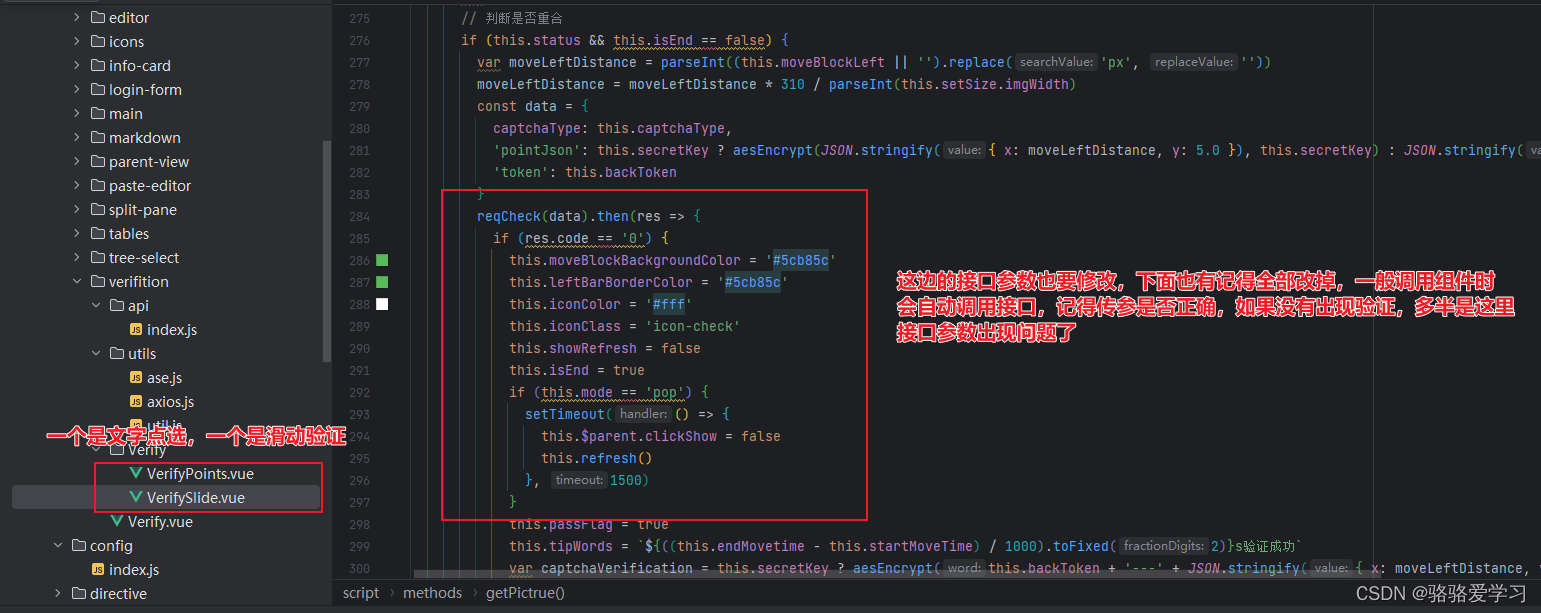
AJ-Captcha行为验证在vue中的使用
项目场景: 提示:这里简述项目相关背景: 项目场景:由原先的验证码校验升级为行为验证校验 使用方法 提示:参考文档: 参考文档:vue使用AJ-Captcha文档 gitee地址:AJ-Captcha &…...
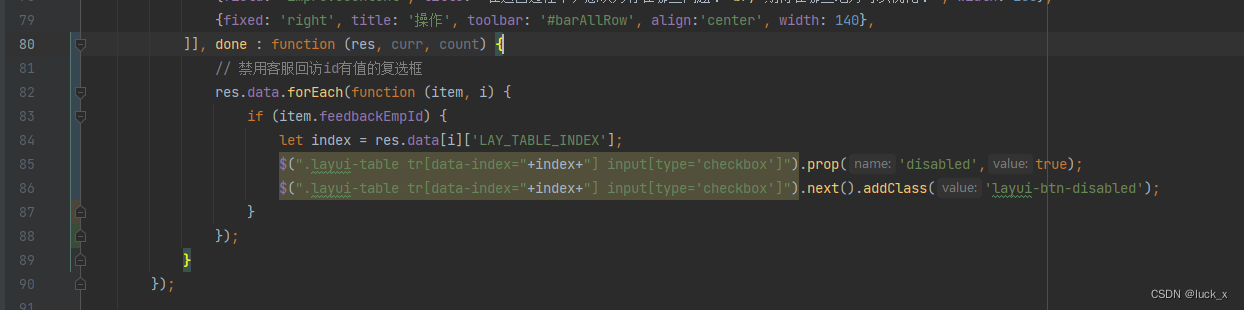
Layui列表复选框根据条件禁用
// 禁用客服回访id有值的复选框res.data.forEach(function (item, i) {if (item.feedbackEmpId) {let index res.data[i][LAY_TABLE_INDEX];$(".layui-table tr[data-index"index"] input[typecheckbox]").prop(disabled,true);$(".layui-table tr[d…...
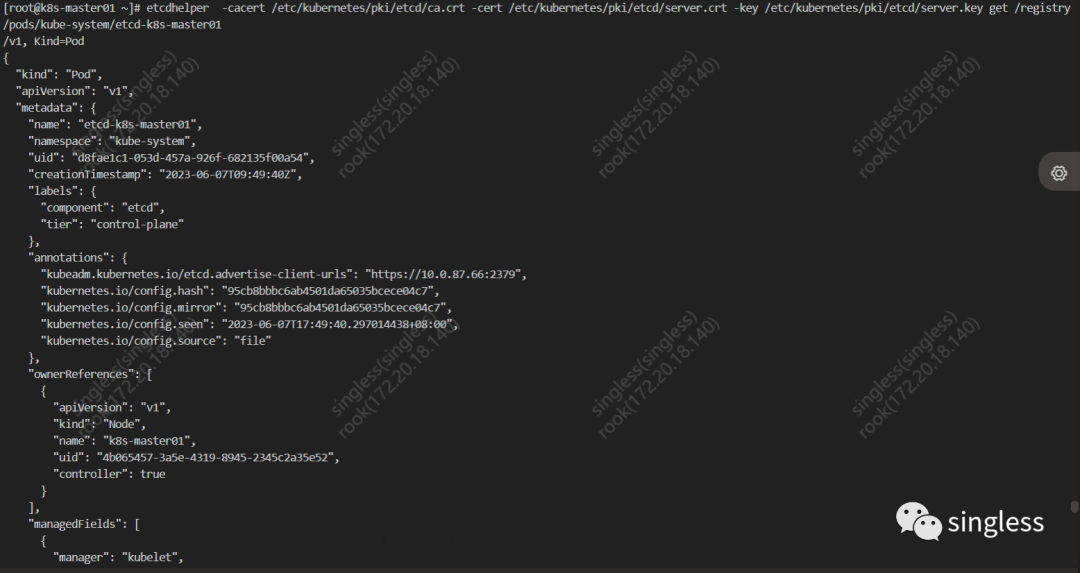
K8S核心组件etcd详解(下)
1 k8s如何使用etcd 在k8s中所有对象的manifest都需要保存到某个地方,这样他们的manifest在api server重启和失败的时候才不会丢失。 只有api server能访问etcd,其它组件只能间接访问etcd的好处是 增强乐观锁系统及验证系统的健壮性 方便后续存储的替换…...
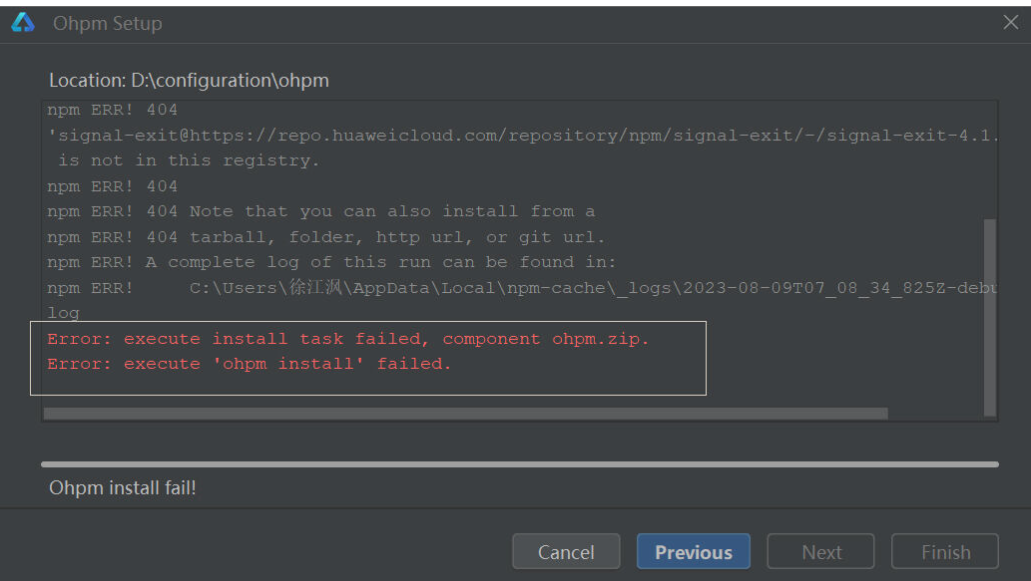
【HarmonyOS】【DevEco Studio】ohpm安装失败该如何解决?
【关键词】 HarmonyOS、DevEco Studio、ohpm安装失败 【问题背景及解决方案】 最近遇到很多DevEco Studio安装ohpm失败的问题,下面给大家介绍几种出现的问题以及解决方案: 1、ohpm not set up,报错截图如下: 解决方案&…...
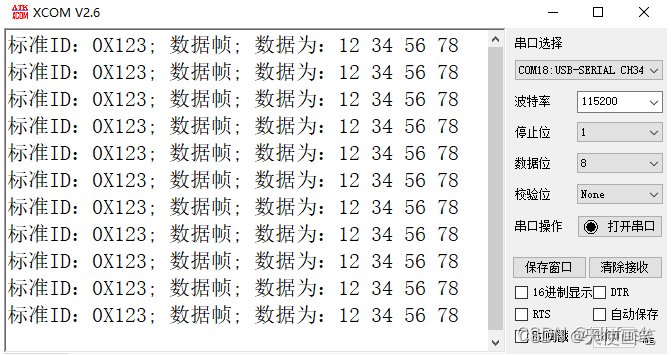
STM32 cubemx CAN
接收用到的结构体如下:CAN概念: 全称Controller Area Network,是一种半双工,异步通讯。 物理层: 闭环:允许总线最长40m,最高速1Mbps,规定总线两端各有一个120Ω电阻,闭环…...
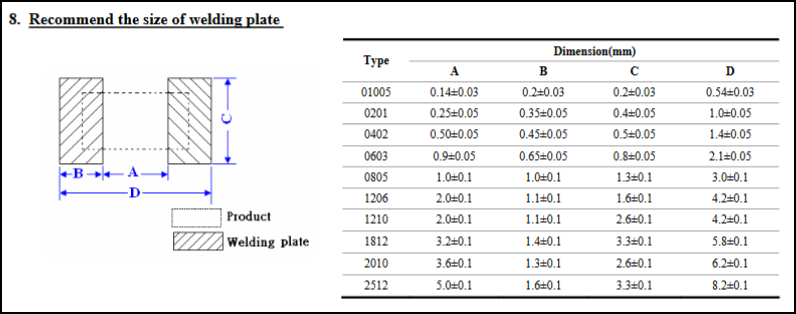
贴片电阻封装尺寸及焊盘尺寸
1、贴片电阻封装尺寸 有英制和公制之分,英制的单位是inch,公制的单位是m;(m、cm、mm只是进制不同) 通常说的都是英制,比如0603指的是inch单位下的0.06inch和0.03inch; 下图有inch和mm的对照、…...
软考笔记——9.软件工程
软件工程的基本原理:用分阶段的生命周期计划严格管理、坚持进行阶段评审、实现严格的产品控制、采用现代程序设计技术、结果应能清除的审查、开发小组的人员应少而精、承认不断改进软件工程事件的必要性。 软件工程的基本要素:方法、工具、过程 软件生…...
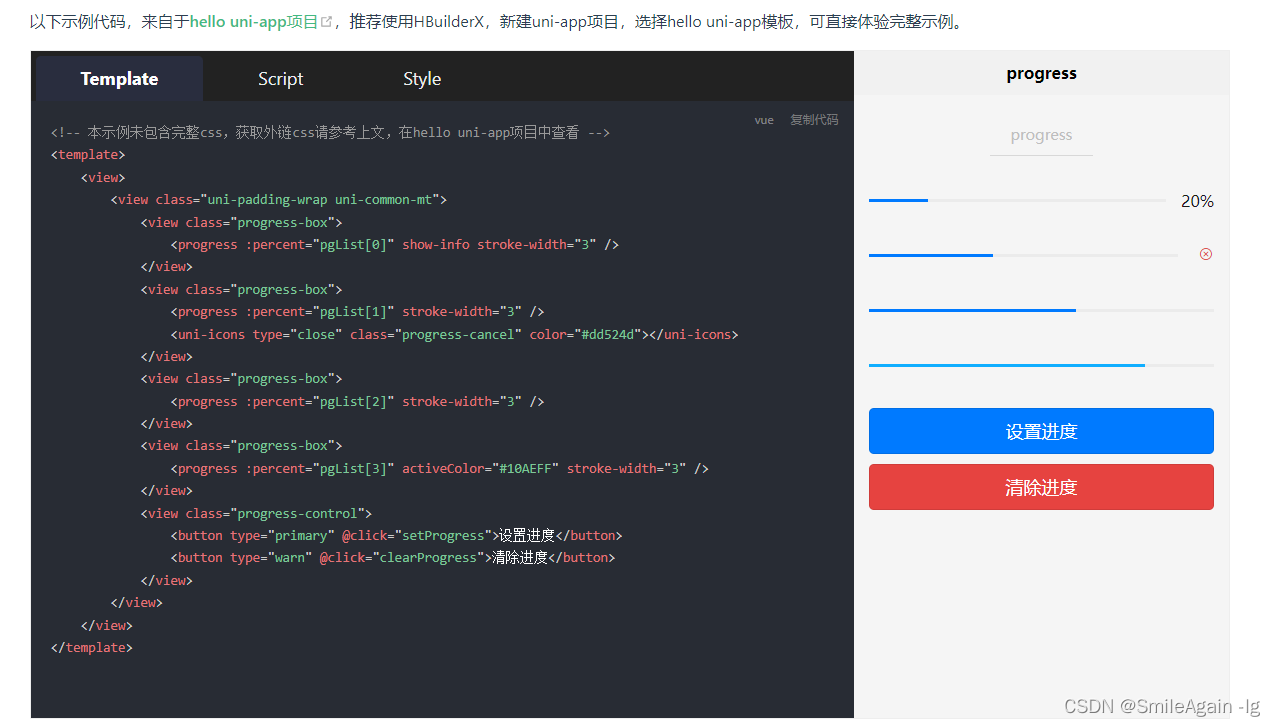
uniapp小程序实现上传图片功能,并显示上传进度
效果图: 实现方法: 一、通过uni.chooseMedia(OBJECT)方法,拍摄或从手机相册中选择图片或视频。 官方文档链接: https://uniapp.dcloud.net.cn/api/media/video.html#choosemedia uni.chooseMedia({count: 9,mediaType: [image,video],so…...

基于物理场的动态模式分解(piDMD)研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

Docker部署rabbitmq遇到的问题 Stats in management UI are disabled on this node
1. Stats in management UI are disabled on this node #进入rabbitmq容器 docker exec -it {rabbitmq容器名称或者id} /bin/bash#进入容器后,cd到以下路径 cd /etc/rabbitmq/conf.d/#修改 management_agent.disable_metrics_collector false echo management_age…...

Python搭建http文件服务器实现手机电脑文件传输功能
第一种代码的界面如下:(有缺点,中文乱码) # !/usr/bin/env python3 # -*- coding:utf-8 _*-"""Simple HTTP Server With Upload. python -V3.6 This module builds on http.server by implementing the standard G…...

微信小程序实现拖拽的小球
目录 前言 js 获取微信小程序中获取系统信息 触摸移动事件的处理函数 触摸结束事件的处理函数 用于监听页面滚动事件 全局参数 html CSS 前言 小程序开发提供了丰富的API和事件处理函数,使得开发者可以方便地实现各种交互功能。其中,拖拽功能…...

别再让树莓派吃灰了!用腾讯云轻量服务器+frp,5分钟搞定远程SSH和VNC访问
树莓派远程访问实战:5分钟解锁SSH与VNC的轻量级方案 每次打开抽屉看到积灰的树莓派,总有种辜负了这片单板计算机潜力的愧疚感。其实只需一台基础配置的云服务器,就能让闲置设备变身24小时在线的开发工作站。本文将用最简步骤实现:…...

PowerToys中文汉化终极指南:3步快速实现Windows效率工具完全本地化
PowerToys中文汉化终极指南:3步快速实现Windows效率工具完全本地化 【免费下载链接】PowerToys-CN PowerToys Simplified Chinese Translation 微软增强工具箱 自制汉化 项目地址: https://gitcode.com/gh_mirrors/po/PowerToys-CN 你是否曾因PowerToys的英文…...

基于视觉大模型的桌面自动化:Screen Vision技能实现AI操控电脑
1. 项目概述:让AI成为你的“数字双手” 你有没有想过,有一天你可以像指挥一个真人助手一样,用自然语言告诉AI:“帮我把桌面上的那个PDF文件拖到‘已处理’文件夹里”,或者“打开浏览器,搜索一下今天北京的…...

基于MCP协议的学术成果商业化AI管道:从论文到商业机会的自动化桥梁
1. 项目概述:从象牙塔到市场的自动化桥梁看到apifyforge/academic-commercialization-pipeline-mcp这个项目标题,我的第一反应是:终于有人把学术界和产业界之间那道无形的墙,用代码给砌出了一条自动化通道。这个项目本质上是一个“…...
)
【AI 越强越离不开工具】:2026 年大模型开发者必备的工具链全景实战(附代码 + 架构图)
前言 目录 前言 一、核心悖论:为什么 AI 越强大,反而越依赖工具? 二、核心拆解:从 Tool 到 Skill 到 Agent,工具链的三层进化逻辑 三、2026 年 AI 工具链全景架构图 四、四大核心工具模块实战(附可直…...

给视觉开发新手的保姆级教程:在Ubuntu上从下载源码到成功运行Demo,搞定OpenCV 3环境搭建
给视觉开发新手的保姆级教程:在Ubuntu上从下载源码到成功运行Demo,搞定OpenCV 3环境搭建 第一次在Ubuntu上搭建OpenCV开发环境,对很多视觉开发新手来说可能是个令人望而生畏的任务。命令行操作、编译工具链、环境配置……这些术语听起来就让人…...

PCL2启动器游戏启动失败的终极解决方案:3步快速修复指南
PCL2启动器游戏启动失败的终极解决方案:3步快速修复指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL Plain Craft Launcher 2(PCL2)…...

5分钟快速上手:FigmaCN免费中文界面插件终极指南
5分钟快速上手:FigmaCN免费中文界面插件终极指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?想要专注于设计创意却被语言障碍…...

【Gemini JavaScript开发支持终极指南】:20年谷歌AI工程师亲授7大避坑法则与实时调试秘技
更多请点击: https://intelliparadigm.com 第一章:Gemini JavaScript开发支持概览 Gemini API 的 JavaScript 集成能力 Google Gemini 提供了官方 Node.js SDK( google/generative-ai),支持在服务端与浏览器环境中调…...

Matlab ode45求解微分方程保姆级教程:从单变量到多智能体系统,附完整代码
Matlab ode45求解微分方程:从单变量到多智能体系统的工程实践 微分方程是描述动态系统演化的核心数学工具,而Matlab的ode45求解器则是工程师和科研人员最常用的数值求解利器。本文将带你从最基础的单个微分方程求解出发,逐步深入到多智能体系…...