分布式-分布式存储笔记
读写分离
什么时候需要读写分离
互联网大部分业务场景都是读多写少的,读和写的请求对比可能差了不止一个数量级。为了不让数据库的读成为业务瓶颈,同时也为了保证写库的成功率,一般会采用读写分离的技术来保证。
读写分离的实现是把访问的压力从主库转移到从库。分离读库和写库操作,从 CRUD 的角度,主数据库处理新增、修改、删除等事务性操作,从数据库处理 SELECT 查询操作。实现上,可以有一主一从,一个主库配置一个从库;也可以一主多从,一个主库配置多个从库,读操作通过多个从库进行,支撑更高的读并发压力。
MySQL 主从复制技术
binlog 日志
MySQL InnoDB 引擎的主从复制,是通过二进制日志 binlog 来实现。除了数据查询语句 select 以外,binlog 日志记录了其他各类数据写入操作,包括 DDL 和 DML 语句。
binlog 有三种格式:Statement、Row 及 Mixed。
-
Statement 格式,基于 SQL 语句的复制。binlog 会记录每一条修改数据的 SQL 操作,从库拿到后在本地进行回放就可以了。
-
Row 格式,基于行信息复制。以行为维度,记录每一行数据修改的细节,不记录执行 SQL 语句的上下文相关的信息,仅记录行数据的修改。假设有一个批量更新操作,会以行记录的形式来保存二进制文件,这样可能会产生大量的日志内容。
-
Mixed 格式,混合模式复制。是 Statement 与 Row 的结合,在这种方式下,不同的 SQL 操作会区别对待。比如一般的数据操作使用 row 格式保存,有些表结构的变更语句,使用 statement 来记录。
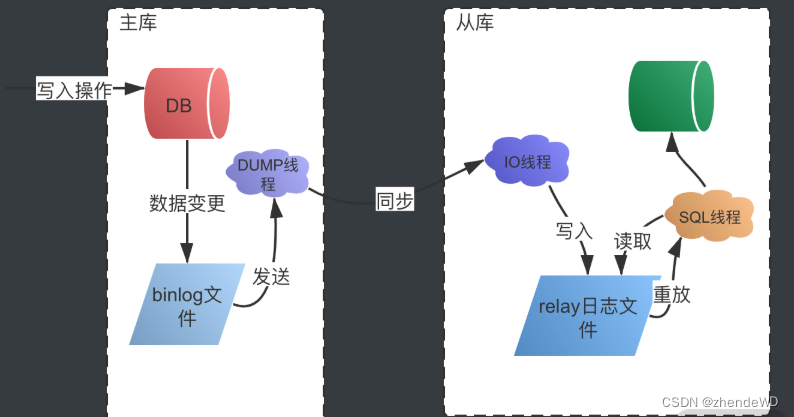
主从复制过程
- 主库将变更写入 binlog 日志,从库连接到主库之后,主库会创建一个log dump 线程,用于发送 bin log 的内容。
- 从库开启同步以后,会创建一个 IO 线程用来连接主库,请求主库中更新的 bin log,I/O 线程接收到主库 binlog dump 进程发来的更新之后,保存在本地 relay 日志中。
- 接着从库中有一个 SQL 线程负责读取 relay log 中的内容,同步到数据库存储中,也就是在自己本地进行回放,最终保证主从数据的一致性。
读写分离要注意的问题
主从复制下的延时问题
主库和从库是两个不同的数据源,主从复制过程会存在一个延时。当主库有数据写入之后,同时写入 binlog 日志文件中,然后从库通过 binlog 文件同步数据,额外执行日志同步和写入操作会有一定时间的延迟。特别是在高并发场景下,刚写入主库的数据是不能马上在从库读取的,要等待几十毫秒或者上百毫秒以后才可以。
在某些对一致性要求较高的业务场景中,这种主从导致的延迟会引起一些业务问题,比如订单支付,付款已经完成,主库数据更新了,从库还没有,这时候去从库读数据,会出现订单未支付的情况,在业务中是不能接受的。
解决方法
- 敏感业务强制读主库。业务需要写库后实时读数据的可以通过强制读主库来解决。
- 关键业务不进行读写分离。对一致性不敏感的业务可以进行读写分离(电商中的订单评论、个人信息等)。对一致性要求比较高的业务不进行读写分离,避免延迟导致的问题(比如金融支付)。
主从复制如何避免丢数据
假设在数据库主从同步时,主库宕机,并且数据还没有同步到从库,就会出现数据丢失和不一致的情况。
MySQL 数据库主从复制有异步复制、半同步复制和全同步复制的方式。
- 异步复制。主库在接受并处理客户端的写入请求时,直接返回执行结果,不关心从库同步是否成功,这样就会存在上面说的问题,主库崩溃以后,可能有部分操作没有同步到从库,出现数据丢失问题。
- 半同步复制。主库需要等待至少一个从库完成同步之后,才完成写操作。主库在执行完客户端提交的事务后,从库将日志写入自己本地的 relay log 之后,会返回一个响应结果给主库,主库确认从库已经同步完成,才会结束本次写操作。相对于异步复制,半同步复制提高了数据的安全性,避免了主库崩溃出现的数据丢失,但是同时也增加了主库写操作的耗时。
- 全同步复制。是在多从库的情况下,当主库执行完一个事务,需要等待所有的从库都同步完成以后,才完成本次写操作。全同步复制需要等待所有从库执行完对应的事务,所以整体性能是最差的。
分库分表
背景
数据规模飞速增长,传统的单库单表架构不足以支撑业务发展,存在性能瓶颈。
读写的数据量限制
数据库的数据量增大会直接影响读写的性能,比如一次查询操作,扫描 5 万条数据和 500 万条数据,查询速度肯定是不同的。
MySQL 单库和单表的数据量限制,和不同的服务器配置,以及不同结构的数据存储有关,并没有一个确切的数字。这里参考阿里巴巴的《Java 开发手册》中数据库部分的建表规约:
单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
避免过度设计。分库分表虽然可以提高性能,但盲目地进行分库分表只会增加系统的复杂度。
数据库连接限制
数据库的连接是有限制的,不能无限制创建,比如 MySQL 中可以使用 max_connections 查看默认的最大连接数,当访问连接数过多时,就会导致连接失败。以电商为例,假设存储没有进行分库,用户、商品、订单和交易,所有的业务请求都访问同一个数据库,产生的连接数是非常可观的,可能导致数据库无法支持业务请求。
如果不进行数据库拆分,大量数据访问都集中在单台机器上,对磁盘 IO、CPU 负载等都会产生很大的压力,并且直接影响业务操作的性能。
分库分表原理
垂直切分
一般是按照业务和功能的维度进行拆分,把数据分别放到不同的数据库中。
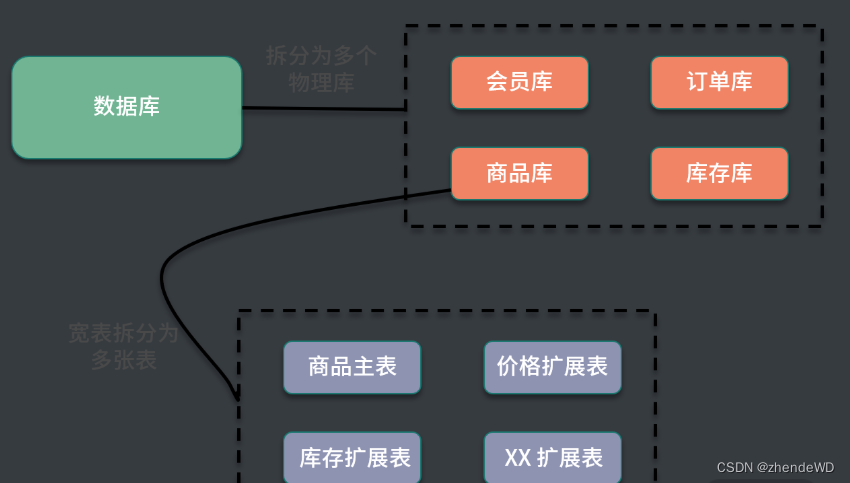
垂直分库:
针对的是一个系统中对不同的业务进行拆分。
根据业务维度进行数据的分离,剥离为多个数据库。比如电商网站早期,商品数据、会员数据、订单数据都是集中在一个数据库中,随着业务的发展,单库处理能力已成为瓶颈,这个时候就需要进行相关的优化,进行业务维度的拆分,分离出会员数据库、商品数据库和订单数据库等。
垂直分表:
针对业务上的字段比较多的大表进行的。
一般是把业务宽表中比较独立的字段,或者不常用的字段拆分到单独的数据表中。比如早期的商品表中,可能包含了商品信息、价格、库存等,可以拆分出来价格扩展表、库存扩展表等。
水平切分
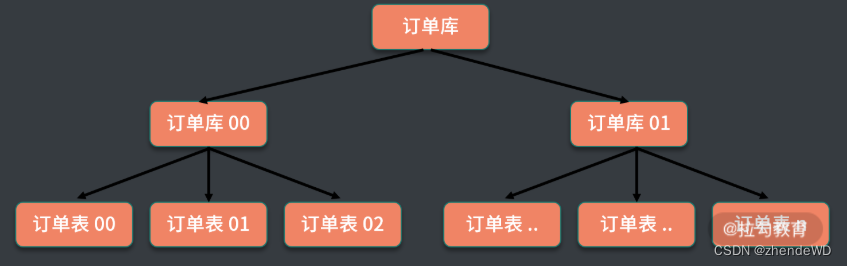
把相同的表结构分散到不同的数据库和不同的数据表中,避免访问集中的单个数据库或者单张数据表,具体的分库和分表规则,一般是通过业务主键,进行哈希取模操作。
例如,电商业务中的订单信息访问频繁,可以将订单表分散到多个数据库中,实现分库;在每个数据库中,继续进行拆分到多个数据表中,实现分表。路由策略可以使用订单 ID 或者用户 ID,进行取模运算,路由到不同的数据库和数据表中。
分库分表后引入的问题
分布式事务问题
对业务进行分库之后,同一个操作会分散到多个数据库中,涉及跨库执行 SQL 语句,也就出现了分布式事务问题。
比如数据库拆分后,订单和库存在两个库中,一个下单减库存的操作,就涉及跨库事务。可以使用分布式事务中间件,实现 TCC 等事务模型;也可以使用基于本地消息表的分布式事务实现。
跨库关联查询问题
分库分表后,跨库和跨表的查询操作实现起来会比较复杂,性能也无法保证。在实际开发中,针对这种需要跨库访问的业务场景,一般会使用额外的存储,比如维护一份文件索引。另一个方案是通过合理的数据库字段冗余,避免出现跨库查询。
跨库跨表的合并和排序问题
分库分表以后,数据分散存储到不同的数据库和表中,如果查询指定数据列表,或者需要对数据列表进行排序时,就变得异常复杂,则需要在内存中进行处理,整体性能会比较差,一般来说,会限制这类型的操作。
分库分表中间件实现
业务中实现分库分表,需要自己去实现路由规则,实现跨库合并排序等操作,具有一定的开发成本,可以考虑使用开源的分库分表中间件。这里比较推荐 Apache ShardingSphere,另外也可以参考淘宝的 TDDL 等。
ShardingSphere 的前身是当当开源的 Sharding-JDBC,目前更名为 ShardingSphere,并且已经加入 Apache 基金会。ShardingSphere 在 Sharding-JDBC 的基础上,额外提供了 Sharding-Proxy,以及正在规划中的 Sharding-Sidecar。其中 Sharding-JDBC 用来实现分库分表,另外也添加了对分布式事务等的支持。 ShardingSphere 的具体应用《ShardingSphere 用户手册》。
TDDL(Taobao Distributed Data Layer)是淘宝团队开发的数据库中间件,用于解决分库分表场景下的访问路由,TDDL 在淘宝大规模应用 TDDL 项目
存储拆分后,解决唯一主键问题
在单库单表时,业务 ID 可以依赖数据库的自增主键实现,存储拆分到了多处,如何解决主键。
生成主键方案
使用单独的自增数据表。
存储拆分以后,创建一张单点的数据表,比如现在需要生成订单 ID,我们创建下面一张数据表:
CREATE TABLE IF NOT EXISTS `order_sequence`(`order_id` INT UNSIGNED AUTO_INCREMENT,PRIMARY KEY ( `order_id` ))ENGINE=InnoDB DEFAULT CHARSET=utf8;
当每次需要生成唯一 ID 时,就去对应的这张数据表里新增一条记录,使用返回的自增主键 ID 作为业务 ID。
问题
- 性能无法保证,在并发比较高的情况下,如果通过这样的数据表来创建自增 ID,生成主键很容易成为性能瓶颈。
- 存在单点故障,如果生成自增 ID 的数据库挂掉,那么会直接影响创建功能。
使用 UUID 能否实现
生成一个 UUID:
public String getUUID(){UUID uuid=UUID.randomUUID();return uuid.toString();}
问题:
- UUID 作为数据库主键太长了,会导致比较大的存储开销。
- UUID 是无序的,如果使用 UUID 作为主键,会降低数据库的写入性能。
以 MySQL 为例,MySQL 建议使用自增 ID 作为主键,我们知道 MySQL InnoDB 引擎支持索引,底层数据结构是 B+ 树,如果主键为自增 ID 的话,那么 MySQL 可以按照磁盘的顺序去写入;如果主键是非自增 ID,在写入时需要增加很多额外的数据移动,将每次插入的数据放到合适的位置上,导致出现页分裂,降低数据写入的性能。
基于 Snowflake 算法
Snowflake 是 Twitter 开源的分布式 ID 生成算法,由 64 位的二进制数字组成,一共分为 4 部分.

其中:
- 第 1 位默认不使用,作为符号位,总是 0,保证数值是正数;
- 41 位时间戳,表示毫秒数,我们计算一下,41 位数字可以表示 241 毫秒,换算成年,结果是 69 年多一点,一般来说,这个数字足够在业务中使用了;
- 10 位工作机器 ID,支持 210 也就是 1024 个节点;
- 12 位序列号,作为当前时间戳和机器下的流水号,每个节点每毫秒内支持 212 的区间,也就是 4096 个 ID,换算成秒,相当于可以允许 409 万的 QPS,如果在这个区间内超出了 4096,则等待至下一毫秒计算。
Twitter 给出了 Snowflake 算法的示例,具体实现应用了大量的位运算,可以点击具体的代码库查看。
Snowflake 算法可以作为一个单独的服务,部署在多台机器上,产生的 ID 是趋势递增的,不需要依赖数据库等第三方系统,并且性能非常高,理论上 409 万的 QPS 是一个非常可观的数字,可以满足大部分业务场景,其中的机器 ID 部分,可以根据业务特点来分配,比较灵活。
不足
存在时钟回拨问题
服务器的本地时钟并不是绝对准确的,在一些业务场景中,比如在电商的整点抢购中,为了防止不同用户访问的服务器时间不同,则需要保持服务器时间的同步。为了确保时间准确,会通过 NTP 的机制来进行校对,NTP(Network Time Protocol)指的是网络时间协议,用来同步网络中各个计算机的时间。
如果服务器在同步 NTP 时出现不一致,出现时钟回拨,那么 SnowFlake 在计算中可能出现重复 ID。除了 NTP 同步,闰秒也会导致服务器出现时钟回拨,不过时钟回拨是小概率事件,在并发比较低的情况下一般可以忽略。时钟回拨问题,可以进行延迟等待,直到服务器时间追上来为止。
数据库维护区间分配
淘宝的 TDDL 等数据库中间件使用的主键生成策略。基于数据库维护自增ID区间,结合内存分配的策略。
步骤
- 首先在数据库中创建 sequence 表,其中的每一行,用于记录某个业务主键当前已经被占用的 ID 区间的最大值。
sequence 表的主要字段是 name 和 value,其中 name 是当前业务序列的名称,value 存储已经分配出去的 ID 最大值。
CREATE TABLE `sequence` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Id',`name` varchar(64) NOT NULL COMMENT 'sequence name',`value` bigint(32) NOT NULL COMMENT 'sequence current value',PRIMARY KEY (`id`),UNIQUE KEY `unique_name` (`name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
- 接下来插入一条行记录,当需要获取主键时,每台服务器主机从数据表中取对应的 ID 区间缓存在本地,同时更新 sequence 表中的 value 最大值记录。
现在我们新建一条记录,比如设置一条 order 更新的规则,插入一行记录如下:
INSERT INTO sequence (name,value) values('order_sequence',1000);i
当服务器在获取主键增长区段时,首先访问对应数据库的 sequence 表,更新对应的记录,占用一个对应的区间。比如我们这里设置步长为 200,原先的 value 值为 1000,更新后的 value 就变为了 1200。
- 取到对应的 ID 区间后,在服务器内部进行分配,涉及的并发问题可以依赖乐观锁等机制解决。
有了对应的 ID 增长区间,在本地就可以使用 AtomicInteger 等方式进行 ID 分配。
不同的机器在相同时间内分配出去的 ID 可能不同,这种方式生成的唯一 ID,不保证严格的时间序递增,但是可以保证整体的趋势递增,在实际生产中有比较多的应用。
为了防止单点故障,sequence 表所在的数据库,通常会配置多个从库,实现高可用。
除了上面的几种方案,实际开发中还可以应用 Redis 作为解决方案,即通过 Redis Incr 命令来实现。
分库分表以后扩容
业务场景
设计电商网站的订单数据库模块,经过对业务增长的估算,预估三年后,数据规模可能达到 6000 万,每日订单数会超过 10 万。
- 存储实现,订单作为电商业务的核心数据,应该尽量避免数据丢失,并且对数据一致性有强要求,肯定是选择支持事务的关系型数据库,比如使用 MySQL 及 InnoDB 存储引擎。
- 数据库的高可用,订单数据是典型读多写少的数据,不仅要面向消费者端的读请求,内部也有很多上下游关联的业务模块在调用,针对订单进行数据查询的调用量会非常大。基于这一点,我们在业务中配置基于主从复制的读写分离,并且设置多个从库,提高数据安全。
- 数据规模,6000 万的数据量,显然超出了单表的承受范围,参考《阿里巴巴 Java 开发手册》中「单表行数超过 500 万行」进行分表的建议,此时需要考虑进行分库分表,那么如何设计路由规则和拆分方案呢?接下来会对此展开讨论。
路由规则与扩容方案
3 种路由规则:对主键进行哈希取模、基于数据范围进行路由、结合哈希和数据范围的分库分表规则。
1. 哈希取模的方式
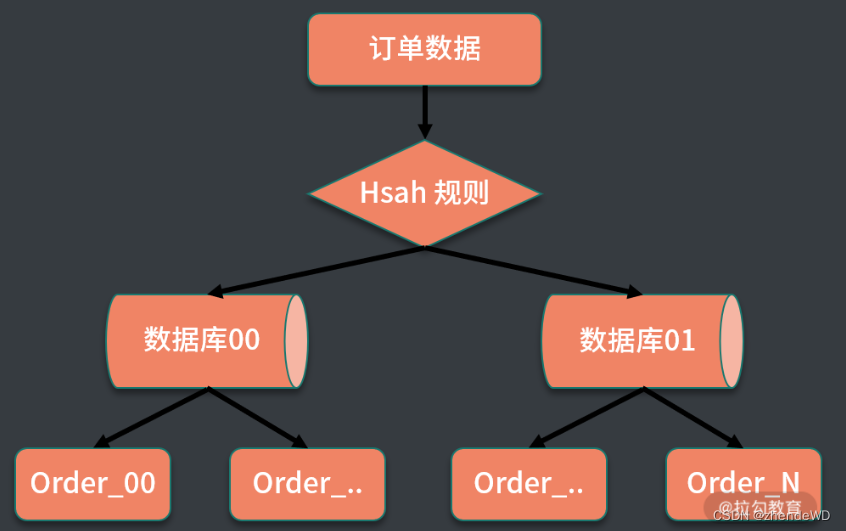
根据不同的业务主键输入,对数据库进行取模,得到插入数据的位置。
6000 万的数据规模,按照单表承载百万数量级来拆分,拆分成 64 张表,进一步可以把 64 张表拆分到两个数据库中,每个库中配置 32 张表。
当新订单创建时,首先生成订单 ID,对数据库个数取模,计算对应访问的数据库;接下来对数据表取模,计算路由到的数据表,当处理查询操作时,也通过同样的规则处理,这样就实现了通过订单 ID 定位到具体数据表。
优点是数据拆分比较均匀。
缺点是不利于后面的扩容。
假设订单增长速度超出预估,数据规模很快达到了几亿的数量级,原先的数据表已经不满足性能要求,数据库需要继续进行拆分。
数据库拆分以后,订单库和表的数量都需要调整,路由规则也需要调整,为了适配新的分库分表规则,保证数据的读写正常,要进行数据迁移,具体的操作,可以分为停机迁移和不停机迁移两种方式。
- 停机迁移
停机迁移的方式比较简单,比如我们在使用一些网站或者应用时,经常会收到某段时间内暂停服务的通知,一般是在这段时间内,完成数据迁移,将历史数据按照新的规则重新分配到新的存储中,然后切换服务。
- 不停机迁移
动态扩容,依赖业务上的双写操作实现,需要同时处理存量和增量数据,并且做好各种数据校验。
数据库扩容方式有基于原有存储增加节点和重新部署一套新的数据库两种策略。
重新部署新的数据库存储的步骤:
- 创建一套新的订单数据库;
- 在某个时间点上,将历史数据按照新的路由规则分配到新的数据库中;
- 在旧数据库的操作中开启双写,同时写入到两个数据库;
- 用新的读写服务逐步替代旧服务,同步进行数据不一致校验,最后完成全面切流。
2. 基于数据范围进行拆分
根据特定的字段进行划分不同区间,对订单表进行拆分中,如果基于数据范围路由,可以按照订单 ID 进行范围的划分。
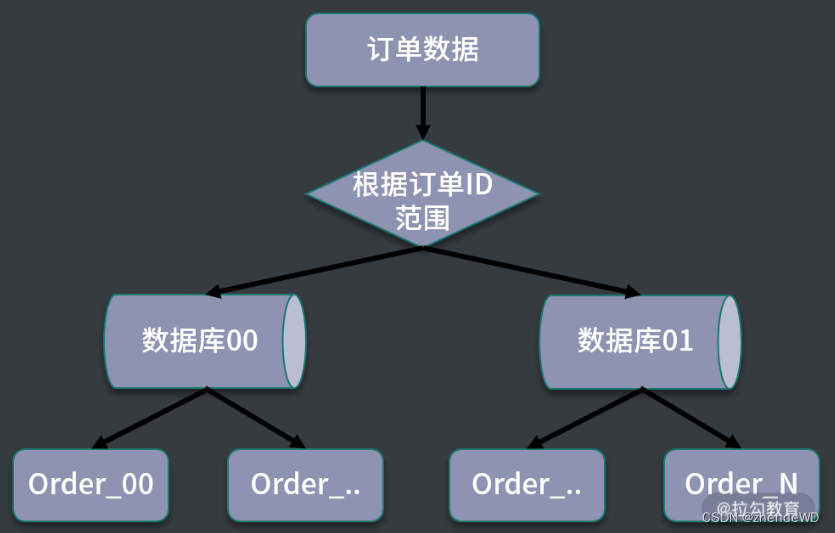
同样是拆分成 64 张数据表,可以把订单 ID 在 3000万 以下的数据划分到第一个订单库,3000 万以上的数据划分到第二个订单库,在每个数据库中,继续按照每张表 100万 的范围进行划分。
基于数据范围进行路由的规则,当进行扩容时,可以直接增加新的存储,将新生成的数据区间映射到新添加的存储节点中,不需要进行节点之间的调整,也不需要迁移历史数据。
缺点是数据访问不均匀。按照这种规则,另外一个数据库在很长一段时间内都得不到应用,导致数据节点负荷不均,在极端情况下,当前热点库可能出现性能瓶颈,无法发挥分库分表带来的性能优势。
3. 结合数据范围和哈希取模
设计这样的一个路由规则,首先对订单 ID 进行哈希取模,然后对取模后的数据再次进行范围分区。
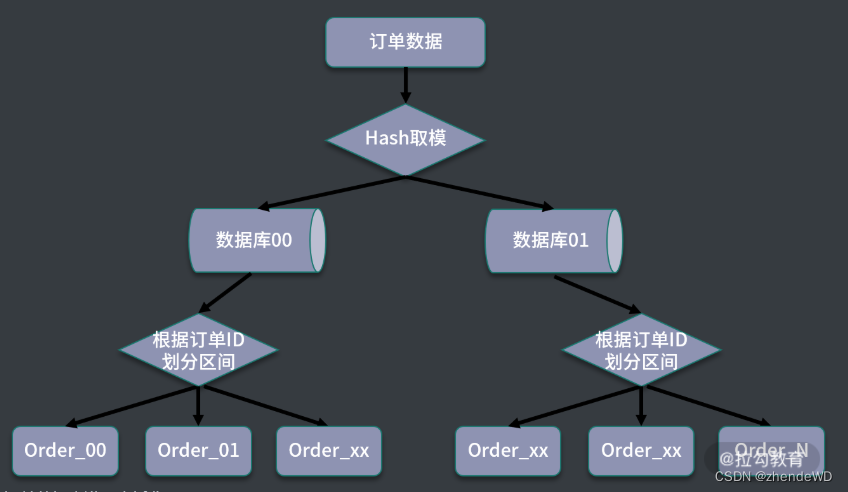
通过哈希取模结合数据区间的方式,可以比较好地平衡两种路由方案的优缺点。当数据写入时,首先通过一次取模,计算出一个数据库,然后使用订单 ID 的范围,进行二次计算,将数据分散到不同的数据表中。
避免了单纯基于数据范围可能出现的热点存储,并且在后期扩展时,可以直接增加对应的扩展表,避免了复杂的数据迁移工作。
NoSQL 数据库
对比关系型数据库
关系型数据库通过关系模型来组织数据,在关系型数据库当中一个表就是一个模型,一个关系数据库可以包含多个表,不同数据表之间的联系反映了关系约束。
关系型数据库对事务支持较好,支持 SQL 规范中的各种复杂查询,比如 join、union 等操作。正是由于对 SQL 规范的支持,也使得关系型数据库对扩展不友好,比较难进行分布式下的集群部署。
NoSQL 数据库特性
- 良好的扩展性,容易通过集群部署
关系型数据库在进行扩展时,要考虑到如何分库分表、扩容等,各种实现方案都比较重,对业务侵入较大。NoSQL 数据库去掉了关系型数据库的关系特性,对集群友好,这样就非常容易扩展。
- 读写性能高,支持大数据量
关系型数据库对一致性的要求较高,数据表的结构复杂,读写的性能要低于非关系型数据库。另外一方面,部分 NoSQL 数据库采用全内存实现,更适合一些高并发的访问场景。
- 不限制表结构,灵活的数据模型
应用关系型数据库,需要通过 DML 语句创建表结构,数据表创建以后,增删字段需要重新修改表结构。如果使用 NoSQL,一般不需要事先为数据建立存储结构和字段,可以存储各种自定义的数据。
关系型数据库和非关系型数据库是相辅相成的。从性能的角度来讲,NoSQL 数据库的性能优于关系型数据库,从持久化角度,关系型数据库优于 NoSQL 数据库。
NoSQL 数据库一般提供弱一致性的保证,实现最终一致性,CP 模型, NoSQL 关注的是 AP 模型,同时应用 NoSQL 和关系型数据库,可以满足高性能的基础上,同时保证数据可靠性。
NoSQL 数据库应用
Key-Value 数据库
Key-Value 存储就是 Map 结构,支持高性能的通过 Key 定位和存储。通常用来实现缓存等应用,典型的有 Redis 和 Memcached。
从性能的角度,为了提高读写效率,Redis 在最开始的版本中一直使用单线程模型,避免上下文切换和线程竞争资源,并且采用了 IO 多路复用的技术,提升了性能,另外在最近的版本更新中,Redis也开始支持多线程处理。
从存储结构的角度,Redis 支持多种数据结构,有丰富的应用场景,并且针对不同的数据规模等,Redis 采取多种内存优化方式,尽量减少内存占用。比如,List 结构内部有压缩列表和双向链表两种实现,在数据规模较小时采用 ZipList 实现,特别是在新的版本更新中,又添加了 QuickList 的实现,减少内存的消耗。
从高可用的角度,作为一个内存数据库,Redis实现了AOF和RDB的数据持久化机制,另外,Redis支持了多种集群方式,包括主从同步,Sentinel和Redis Cluster等机制,提高了整体的数据安全和高可用保障。
文档型数据库
文档型数据库可以存储结构化的文档,比如 JSON 或者 XML,从这个角度上看,文档型数据库比较接近关系型数据库。但是对比关系型数据库,文档性数据库中不需要预先定义表结构,并且可以支持文档之间的嵌套,典型的比如 MongoDB,这一点和关系型数据库有很大的不同。
以 MongoDB 为例,采用了基于 JSON 扩展的 BSON 存储结构,可以进行自我描述,这种灵活的文档类型,特别适合应用在内容管理系统等业务中。MongoDB 还具备非常优秀的扩展能力,对分片等集群部署的支持非常全面,可以快速扩展集群规模。
列存储数据库
列式数据库被用来存储海量数据,比如 Cassandra、HBase 等,特点是大数据量下读写速度较快、可扩展性强,更容易进行分布式部署。
以 HBase 为例,HBase 支持海量数据的读写,特别是写入操作,可以支持 TB 级的数据量。列式数据库通常不支持事务和各种索引优化,比如 HBase 使用 LSM 树组织数据,对比 MySQL 的 B+ 树,在高并发写入时有更好的性能。
图形数据库
在一些特定的应用场景可以应用特殊的数据库,比如图形数据库。社交网络中的用户关系可以使用图来存储,于是诞生了一些图形数据库,可以方便地操作图结构的相关算法,比如最短路径、关系查找等。
ElasticSearch 索引
ElasticSearch 简介
Lucene 是一个开源的全文检索引擎类库,支持各种分词以及搜索相关的实现,可以极大地简化搜索开发的成本,但 Lucene 只是一个工具包,在实际项目中进行二次开发。
ElasticSearch 是一个基于 Lucene 的分布式全文检索框架,在 Lucene 类库的基础上实现,可以避免直接基于 Lucene 开发,这一点和 Java 中 Netty 对 IO/NIO 的封装有些类似。
ElasticSearch 开放了一系列的 RESTful API,基于这些 API,可以快捷地实现各种搜索功能。除了搜索相关的功能,ElasticSearch 还对分布式场景下的应用有特别好的支持,包括良好的扩展性,可以扩展到上百台服务器的集群规模,以及近似实时分析的索引实现。这些特点,使得 ElasticSearch 在各类搜索场景、大数据分析等业务中广泛应用。
ElasticSearch 应用
ElasticSearch 对搜索的支持非常好,但是和 NoSQL 数据库一样,对事务、一致性等的支持较低。
常见的数据库-索引-缓存系统架构图:
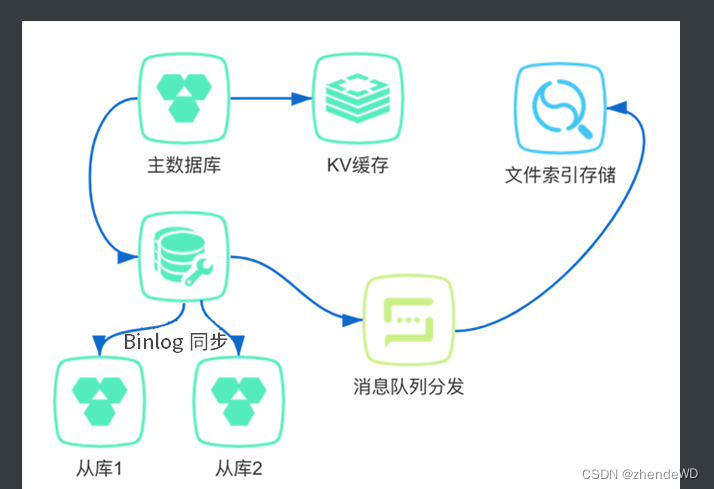
ElasticSearch 一般是作为持久性数据库的辅助存储,是和 SQL & NoSQL 数据库一起使用,对外提供索引查询功能。关系型数据库保证数据更新的准确性,在关系型数据库更新以后,通过 binlog 同步结合消息队列分发的方式,来更新文件索引,提供一致性保证。
ELK stack
ElasticSearch 是由 Elastic 公司创建的,除了 ElasticSearch,Elastic 公司还有另外两款产品,分别是 Logstash 及 Kibana 开源项目,这三个开源项目组合在一起称为 ELK stack。
在 ELK 技术栈中,ElasticSearch 用于数据分析和检索,Logstash 用于日志收集,Kibana 用于界面的展示,ELK 可以用于快速查询数据并可视化分析,在日志处理、大数据等领域有非常广泛的应用。
索引是如何建立的
ElasticSearch 存储的单元是索引,关系型数据库是按照关系表的形式组织数据,大部分 NoSQL 数据库是 K-Value 的键值对方式。
ElasticSearch 索引的实现基于 Lucene,使用倒排索引的结构,倒排索引的引入,使得 ElasticSearch 可以非常高效地实现各种文件索引。倒排索引不光是在 ElasticSearch 等组件中应用,它还是百度等搜索引擎实现的底层技术之一。在搜索引擎中,索引的建立需要经过网页爬取、信息采集、分词、索引创建的过程,不过在 ElasticSearch 内部存储的实现中,数据的写入可以对比搜索引擎对网页的抓取和信息采集的过程,只需要关注分词和索引的创建。
分词和索引
分词是在索引建立中特别重要的一个环节,分词的策略会直接影响索引结果。Lucene 提供了多种分词器,分词器是一个可插拔的组件,包括内置的标准分词器, 也可以引入对中文支持较好的 IKAnalyze 中文分词器等。
假设我们在 ElasticSearch 中新增了两个文档,每个文档包含如下内容:
- 文档1,Jerry and Tom are good friends.
- 文档2,Good friends should help each other.
英文是有单词的,单词之间通过空格进行拆分,所以对英文的分词相对容易,比如上面的内容,可以直接对字符串按照空格拆分,得到分词后的数组。
Jerry / / and / / Tom / / are / / good / / friends / . Good / / friends / / should / / help / / each / / other / .
一般来说,中文分词用得比较多的策略是基于字典的最长字符串匹配方式,这种策略可以覆盖大多数场景,不过还是有一小部分天然存在歧义的文档是无法处理的。比如「学生会组织各种活动」,按照最长串匹配的方式,可以切分成“学生会/组织各种活动”,但实际要表达的可能是“学生/会/组织各种活动”。
建立索引
索引存储的结构是倒排索引,倒排索引是相对于正排索引来说的,倒排索引描述了一个映射关系,包括文档中分词后的结果,以及分别包含这些单词的文档列表。
索引描述的其实就是关键词和文档的关系,正排索引就是“文档—关键词”的格式,倒排索引则相反,是“关键词—文档”的格式。可以看到,当需要使用关键词进行检索时,使用倒排索引才能实现快速检索的目的。
针对上面的分词示例,我们简单起见,统一为小写,把分词之后的单词组成一个不重复的分词列表,为了更好地进行查找,可以按照字典序排序。
and,are,each,friends,good,help,jerry,other,should,tom
比如,其中“friends”在文档 1 和文档 2 中都出现了,“Tom”和“Jerry”只在文档 1 中出现了 1 次,其他的单词也进行同样地处理,于是我们可以构建下面的倒排索引:
| 分词 | 文档列表 |
|---|---|
| … | … |
| friends | 文档 1,文档 2 |
| good | 文档 1,文档 2 |
| jerry | 文档 1, |
| tom | 文档 1 |
| … | 以下省略 |
具体到数据结构的实现,可以通过实现一个字典树,也就是 Trie 树,对字典树进行扩展,额外存储对应的数据块地址,定位到具体的数据位置。
对比 B+ 树
严格地说,这两类索引是不能在一起比较的,B+ 树描述的是索引的数据结构,而倒排索引是通过索引的组织形式来命名的。比如我们上面的例子中,倒排指的是关键词和文档列表的结构关系。
对于数据库来说,索引的作用是提高数据查询的性能,考虑到磁盘寻址的特性,选择了 B+ 树作为索引的实现结构,可以更好地实现通过主键以及通过区间范围查找的要求。
对于倒排索引,则是对应具体的应用场景,在搜索中是通过一些关键词,定位到具体的文档。所以倒排索引实现的是根据关键词,也就是分词的结果,去查找文档,或者不同的网页。
相关文章:
分布式-分布式存储笔记
读写分离 什么时候需要读写分离 互联网大部分业务场景都是读多写少的,读和写的请求对比可能差了不止一个数量级。为了不让数据库的读成为业务瓶颈,同时也为了保证写库的成功率,一般会采用读写分离的技术来保证。 读写分离的实现是把访问的压…...
第十三届蓝桥杯国赛 C++ C 组 Java A 组 C 组 Python C 组 E 题——斐波那契数组(三语言代码AC)
目录1.斐波那契数组1.题目描述2.输入格式3.输出格式4.样例输入5.样例输出6.数据范围7.原题链接2.解题思路3.Ac_code1.Java2.C3.Python1.斐波那契数组 1.题目描述 如果数组 A(a0,a1,⋯.an−1)A(a_0,a_1,⋯.a_{n-1})A(a0,a1,⋯.an−1)满足以下条件, 就说它是一个斐波那契…...
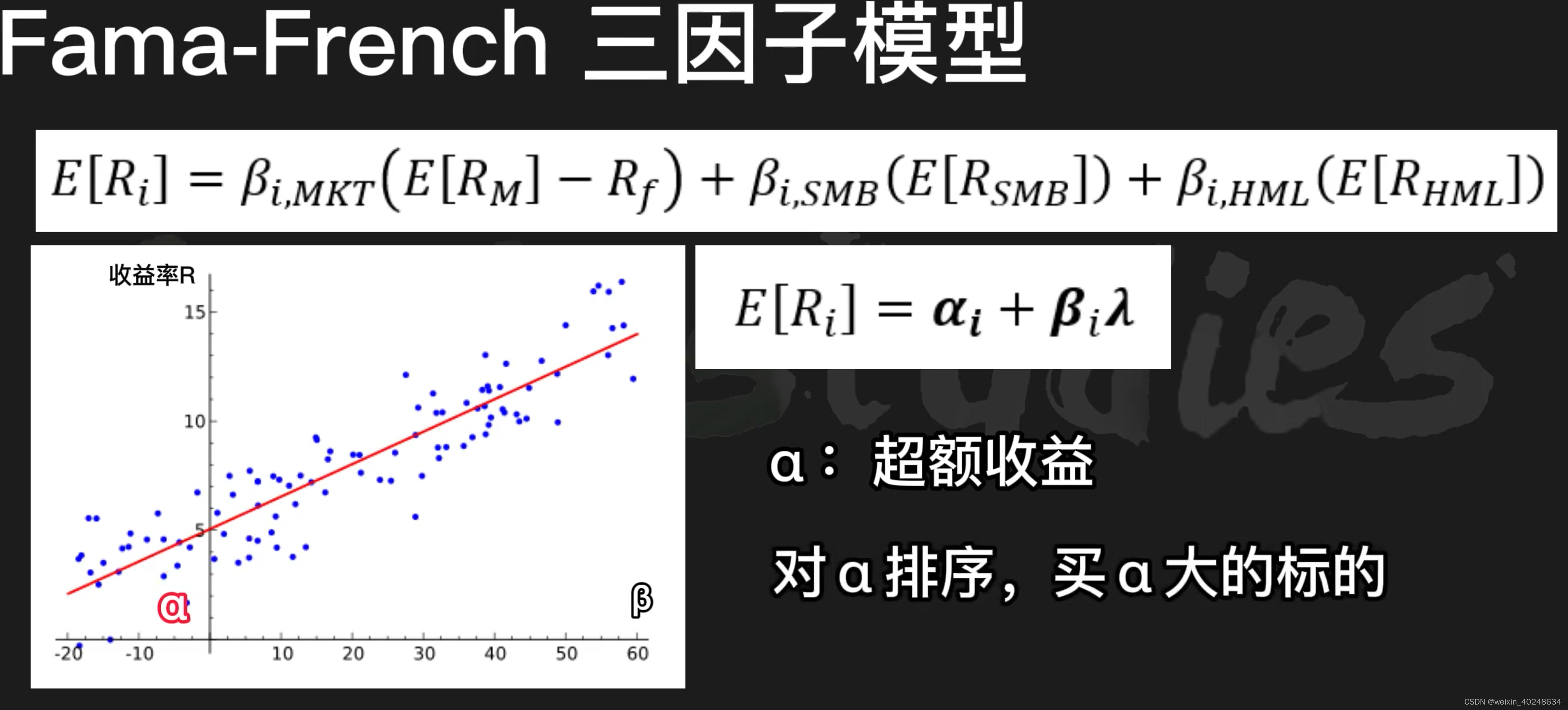
多因子模型(MFM)
多因子模型(Muiti-Factor M: MFM)因子投资基础CAPM (资本资产定价模型)APT套利定价理论截面数据 & 时间序列数据 & 面板数据定价误差 α\alphaαalpha 出现的原因线性多因子模型Fama-French三因子模型三因子的计算公式利用alpha大小进行购买股票…...

django项目实战一(django+bootstrap实现增删改查)
目录 一、创建django项目 二、修改默认配置 三、配置数据库连接 四、创建表结构 五、在app当中创建静态文件 六、页面实战-部门管理 1、实现一个部门列表页面 2、实现新增部门页面 3、实现删除部门 4、实现部门编辑功能 七、模版的继承 1、创建模板layout.html 1&…...
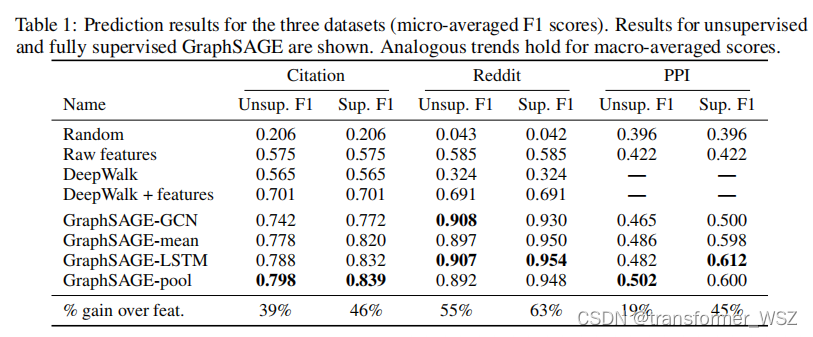
graphsage解读
传统的图方法都是直推式(transductive)的,学习到的是结构固定的图模型,一旦有新的节点加入,便需要重新训练整个图网络,泛化性不强。GraphSAGE是归纳式(inductive)的,它学习一种映射:通过采样和聚合邻居节点…...
一文带你读懂Dockerfile
目录 一、概述 二、DockerFile构建过程解析 (一)Dockerfile内容基础知识 (二)Docker执行Dockerfile的大致流程 (三)总结 三、DockerFile常用保留字指令 四、案例 (一)自定义…...
用python实现对AES加密的视频数据流解密
密码学中的高级加密标准(Advanced Encryption Standard,AES),又称Rijndael加密法。 在做网络爬虫的时候,会遇到经过AES加密的数据,可以使用python来进行解密。 在做爬虫的时候,通常可以找到一个key,这个key是一个十六进制的一串字符,这传字符是解密的关键。所以对于…...

网络高可用方案
目录 1. 网络高可用 2. 高可用方案设计 2.1 方案一 堆叠 ha负载均衡模式 2.2 方案二 OSPF ha负载均衡模式 3. 高可用保障 1. 网络高可用 网络高可用,是指对于网络的核心部分或设备在设计上考虑冗余和备份,减少单点故障对整个网络的影响。其设计应…...

简单的认识 Vue(vue-cli安装、node安装、开发者工具)
Vue1、Vue 与其他框架的对比及特点1.1 Vue.js 是什么1.2 作者1.3 作用1.4 Vue 与其他框架的对比2、安装 Vue 的方法2.1 CDN 引入2.2 脚手架工具2.3 vue 开发者工具安装3、创建第一个实例4、理解 Vue 的 MVVM 模式5、数据双向绑定5.1 感受响应式实验总结1、Vue 与其他框架的对比…...
如何写一个 things3 client
Things3[1] 是一款苹果生态内的任务管理软件,是一家德国公司做的,非常好用。我前后尝试了众多任务管理软件,最终选定 things3,以后有机会会写文章介绍我是如何用 things3 来管理我的日常任务。本文主要介绍欧神写的 tli[2] 工具来…...

人工智能原理复习 | 命题逻辑和谓词演算
文章目录 一、前言二、命题逻辑三、谓词逻辑CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 数理逻辑思想的起源:莱布尼茨之梦。古典数理逻辑主要包括两部分:命题逻辑和谓词逻辑,命题逻辑又是谓词逻辑的一种简单情形。 逻辑研究的基本内容: 语法。语言部分:基…...
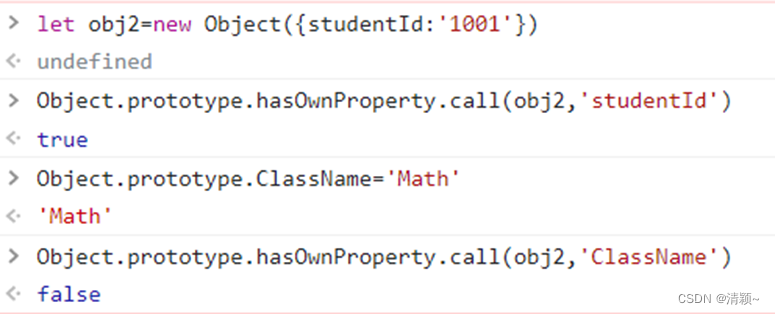
前端基础面试题:如何判断对象是否具有某属性?遍历数组的方法有哪些?
一、如何判断对象具有某属性? 如:let obj{name:zhangsan,age:21} 有以下方法 ( property 为属性名的变量,实际上是key,键名): 1. property in obj 效果如图: in 运算符 2. Reflect.has(obj, property)…...
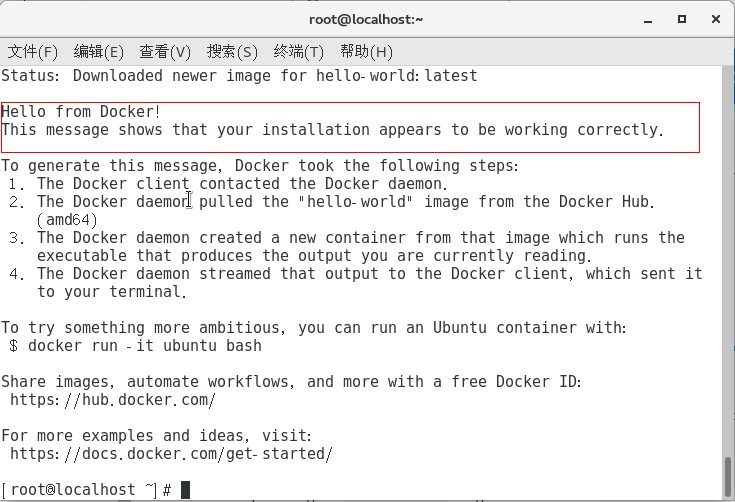
Docker入门和安装教程
一、Docker入门简介 Docker 是一个基于GO语言开发的开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化。 容器是完全使用沙箱机制,相互之间不会…...
有了java基础,迅速学完Python并做了一份笔记-全套Python,建议收藏
面向过程Python简介Python和Java的解释方式对比Java:源代码 -> 编译成class -> Jvm解释运行Python:源代码 -> Python解释器解释运行我经常和身边的Java开发者开玩笑说:“Java真变态,别的语言都是要么直接编译要么直接解释…...
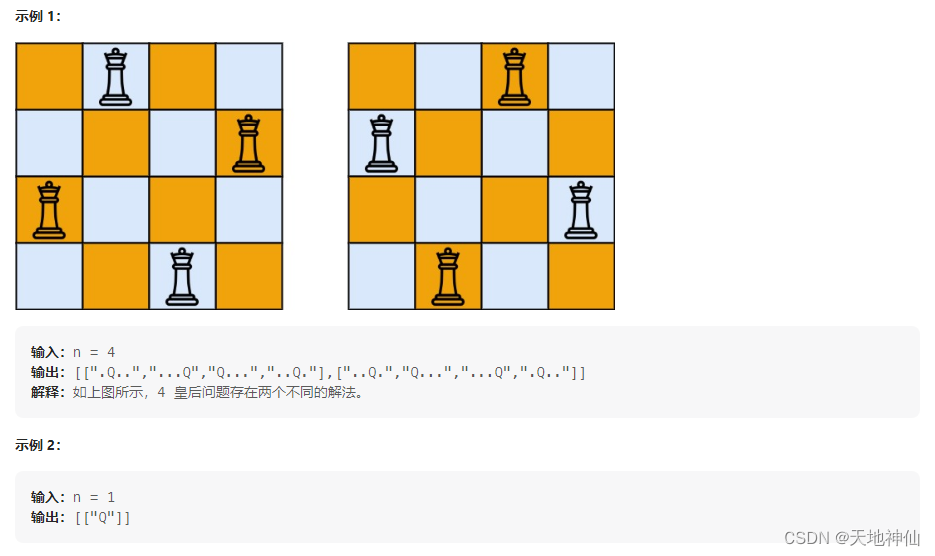
LeetCode——51. N 皇后
一、题目 按照国际象棋的规则,皇后可以攻击与之处在同一行或同一列或同一斜线上的棋子。 n 皇后问题 研究的是如何将 n 个皇后放置在 nn 的棋盘上,并且使皇后彼此之间不能相互攻击。 给你一个整数 n ,返回所有不同的 n 皇后问题 的解决方案…...

jQuery基本操作
学习目标: 会使用基本选择器获取元素 会使用层次选择器获取元素 会使用属性选择器获取元素 会使用过滤选择器获取元素 学习内容: 1.回顾jQuery语法结构 语法 $(selector).action; 工厂函数$():将DOM对象转化为jQuery对象。 选择器 sele…...
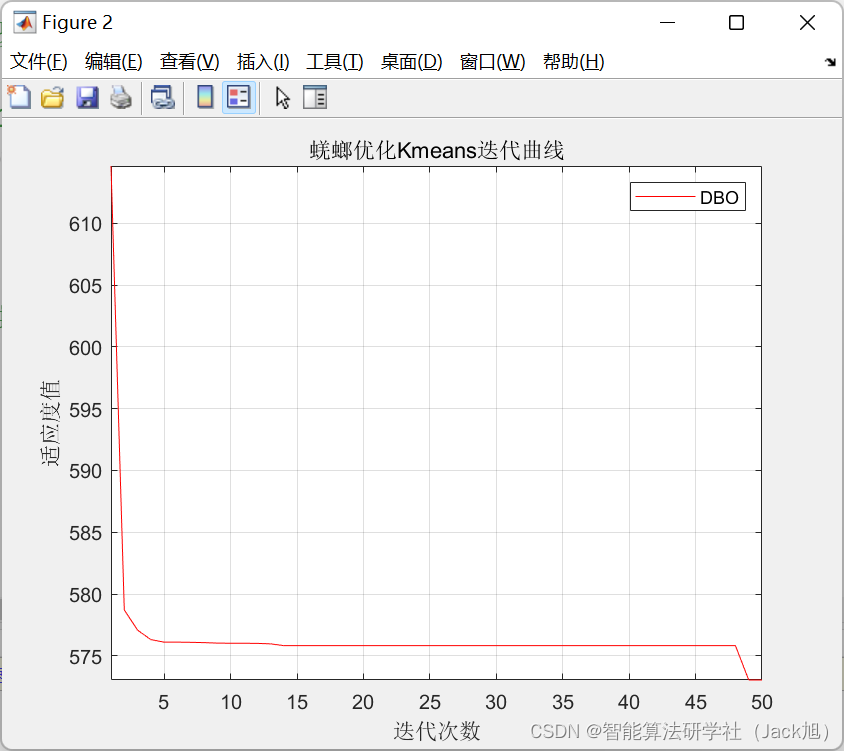
基于蜣螂算法优化Kmeans图像分割-附代码
基于蜣螂优化Kmeans图像分割算法 - 附代码 文章目录基于蜣螂优化Kmeans图像分割算法 - 附代码1.Kmeans原理2.基于蜣螂算法的Kmeans聚类3.算法实验结果4.Matlab代码摘要:基于蜣螂优化Kmeans图像分割算法。1.Kmeans原理 K-Means算法是一种无监督分类算法,…...
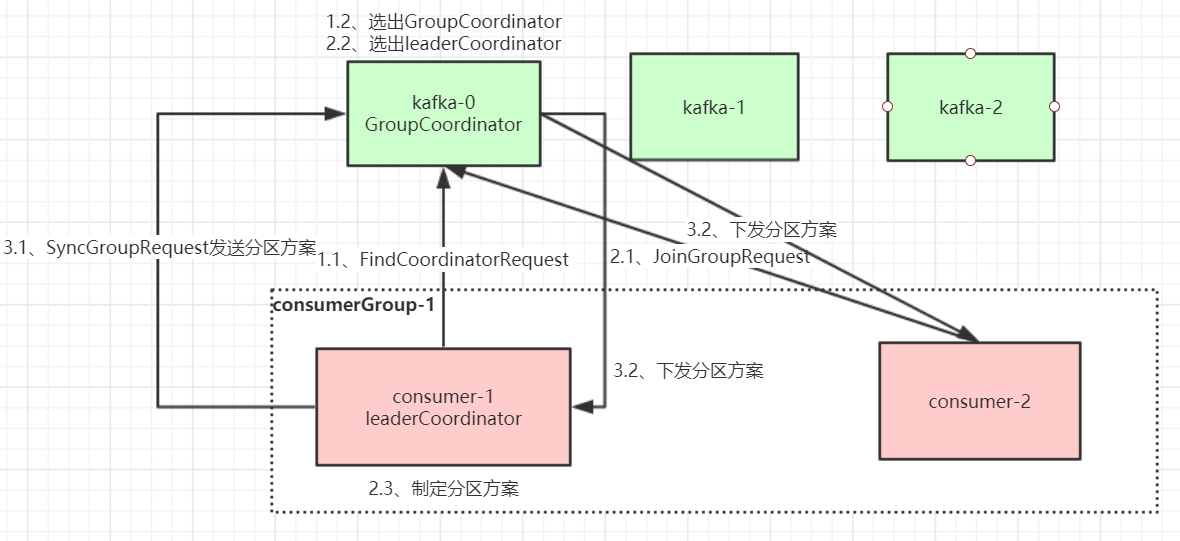
第二章 Kafka设计原理详解
第二章 Kafka设计原理详解 1、Kafka核心总控制器Controller 在 Kafka 集群中会有一个或者多个 broker,其中有一个 broker 会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。 当某个分区的 leader…...

《NFL橄榄球》:费城老鹰·橄榄1号位
费城老鹰(英语:Philadelphia Eagles)是美国橄榄球联盟在宾夕法尼亚州费城的一支球队。1933年在国家橄榄球联盟扩编时与匹兹堡钢人和辛辛那提红人一起加入;1943年赛季因二次大战的缘故,和匹兹堡钢人作短暂的合并。 在20…...
【人工智能AI】四、NoSQL进阶《NoSQL 企业级基础入门与进阶实战》
帮我写一篇介绍NoSQL的技术文章,文章的标题是《四、NoSQL进阶》,不少于3000字。帮我细化到三级目录,使用markdown格式。这篇文章的目录是: 四、NoSQL 进阶 4.1 NoSQL 高可用 4.2 NoSQL 数据安全 4.3 NoSQL 性能优化 4.4 总结 四、…...

16.为什么 Fragment 相比额外包一层 div 更优?
在 React 里,只要你写过几行组件,很容易掉进一个老毛病:“反正组件要有一个根节点,那我就随手包一层 <div> 吧。”一开始看不出问题,但项目一大,你会发现:DOM 结构被一堆没意义的 <div…...

18.children 这个 props 的意义何在?该怎样正确使用?
在 React 里,children 是一个非常特殊、非常常用的 prop, 它专门用来接收:写在组件标签中间的那一部分内容。你可以把它理解为:组件外层负责搭“外壳”,children 负责装进这个壳里的“内容物”。一、children 到底是什…...

ESP32开发板变身万能协议分析仪
1. ESP32开发板的隐藏潜力:从物联网到万能协议分析仪当大多数人拿到ESP32开发板时,第一反应都是用它来做物联网项目。确实,这款集成了Wi-Fi和蓝牙功能的微控制器在智能家居、远程监控等领域表现出色。但今天我要告诉你的是,ESP32的…...

03_Neo4j知识体系之5.x与2026.x新特性和版本演进
03_Neo4j知识体系之5.x与2026.x新特性和版本演进 体系 版本演进层:Neo4j 5.x LTS、2025/2026 日历化版本、Cypher 5 与 Cypher 25、Autonomous Clustering、Ops Manager、Vector Indexes、AI 能力关联能力:与升级迁移路径、集群扩容、Fabric 联邦查询、差…...

手把手教你用RFSoC ZU47DR的DAC/ADC:从单音信号到1200MHz宽带调制的避坑实践
手把手教你用RFSoC ZU47DR的DAC/ADC:从单音信号到1200MHz宽带调制的避坑实践 当一块开发板的价格抵得上半辆家用轿车时,每个操作步骤都值得反复推敲。这就是RFSoC ZU47DR给我的第一印象——强大到令人兴奋,复杂到让人却步。作为赛灵思第三代射…...
注解与反射)
JAVA重点基础、进阶知识及易错点总结(35)注解与反射
🚀 Java 巩固进阶 第 35 天 主题:注解与反射结合 —— 让注解"活"起来📅 进度概览:继昨天学习注解定义之后,今天进入 注解的核心应用场景:注解 反射。单独的注解只是"标签"ÿ…...

拆解Clonezilla镜像:除了partclone,你还需要知道的底层原理与工具链
拆解Clonezilla镜像:从分卷压缩到文件系统的技术全景解析 当我们需要从Clonezilla备份中提取单个文件时,传统方法往往要求完整恢复整个镜像——这种"全有或全无"的方式在存储资源有限的情况下显得尤为笨重。本文将带您深入Clonezilla镜像的底层…...

d3d8to9:Direct3D 8到9的API转换解决方案及技术实现
d3d8to9:Direct3D 8到9的API转换解决方案及技术实现 【免费下载链接】d3d8to9 A D3D8 pseudo-driver which converts API calls and bytecode shaders to equivalent D3D9 ones. 项目地址: https://gitcode.com/gh_mirrors/d3/d3d8to9 诊断D3D8游戏兼容性问题…...

ZenTimings终极指南:解锁AMD Ryzen内存性能的完整解决方案
ZenTimings终极指南:解锁AMD Ryzen内存性能的完整解决方案 【免费下载链接】ZenTimings 项目地址: https://gitcode.com/gh_mirrors/ze/ZenTimings ZenTimings是一款专为AMD Ryzen平台设计的专业内存时序监控与优化工具,能够帮助用户深入了解和调…...

利用快马平台快速将notepad++笔记构思转化为可交互网页应用原型
今天想和大家分享一个特别实用的开发经验——如何用InsCode(快马)平台快速把Notepad里的笔记构思变成可交互的网页应用。作为一个经常用Notepad写代码片段和笔记的人,我一直在寻找能快速验证想法的工具,直到发现了这个平台。 为什么选择网页应用原型 N…...