一次PostgreSQL复杂jsonb数据矫正过程分享
背景介绍
想看干货直接看最后的总结,其他流水账可以不看,也可以当故事看。
7月底我司某产品因故需要拉齐现场版本,其中某地版本较低,且曾经做过一些定制内容,升级前也未识别该情况,导致后续持续一个月不断地暴露新问题。因为涉及研发团队更换,交接不充分,代码管理不规范等原因导致的部分定制需求代码升级后丢失的问题暂且不表,今天就来说一下因模板识别错误,导致100多条业务数据的核心json数据混乱,最终导致客户无法正常基于json要素生成word的解决方案,主要是想传递一下json矫正场景的一个排查过程,给自己做个记录供下次遇到类似问题快速学习,另外也给其他有类似诉求的人一个参考思路。
过程
以下服务之间的关系存在精简,不要太在意,主要看思路。
问题
有这么A、B、C、D四个服务
- A服务:互联网部署,可以让用户导入基于指定模板填充的excel内容,然后把excel的内容经过各种关系的组装,最终形成一个json(还有很多其他固定的业务字段有内容,本文主要讲解针对该字段的处理),存入数据库的业务表中,会有摆渡机制将同构的数据摆渡到内网的B服务中。
- B服务:A服务在内网的镜像,数据与A服务基本保持一致。
- C服务:基于B服务的一个基础应用,可将B服务中的json元素进行业务加工,并提供给业务层应用使用。
- D服务:用户可见的应用,可以利用C服务生成指定格式的word文档。
同时A服务中又针对不同业务场景,提供了多套不同的excel模板,互联网用户根据需要使用对应模板填充不同业务数据,内网应用会根据模板类型标记来动态解析json数据,并逐层传递至用户层应用。
此次升级后,A服务中引入了一个缺陷,所有的excel模板,均会按照相同的模板类型A来解析,导致用户一直在用的模板类型B核心数据丢失,进一步导致用户层应用无法正常使用。
虽然我们及时(好像耗时4天找到了问题,是因为新研发改错了代码。毕竟新团队也不熟悉代码,逻辑也比较复杂,所以综合分析时间也还能接受)修复了该缺陷,但这几天已经产生了100多条有效数据(还有几十条我们自己的测试数据),如何矫正成了难题。
解决思路1(让用户搞)
因数据链路存在状态,所以研发提出直接驳回数据,让用户在互联网重新操作一遍,或者系统也提供了逐个记录编辑的功能,让用户把解析错误的数据重新手工填写一下是否可行?
这俩想法都不可行,手工填写的话,100多条数据,每条数据几十个信息项,甚至每条数据里面可能还有几十条子业务数据,让用户手工逐个矫正?我准备跟用户说这个解决方法之前,我都得扇自己两巴掌,最好带着掌印才好面对面跟用户说这个方案,否则我怕他们打我。
退回的话,虽然也给用户增加了不必要的工作量,但听起来还行,只是问题数据已经产生了将近一个月了,数据链路流转到哪儿了?随机抽查了几个,都已经审核了,没法修改了,所以让用户来搞的思路不可行了。
解决思路2(我们来搞)
既然有问题的只是json数据,那我们自己再重新导入一下(还好我机智,感觉到最后可能需要矫正,发现问题不久就找多个用户要来了他们的excel),然后根据规则,把新旧数据做个唯一映射,最后把解析正确的json更新到原来错误的字段里面不就可以了?
说干就干,我登录互联网系统把当时留存的excel导入系统,但不提交(这样就不会摆渡到内网,用完即可删除),然后仅把json数据相关的表数据筛出来,生成insert语句,导入内网(毕竟最终影响用户的是内网)。
然后,到这一步就卡住了,研发说映射条件得想想,想了一段时间,告诉我json中有一个元素存储的是人员名字数组,取第一个应该能对得上,但脚本怎么写呢?上网查吧。
假设:新导入的表为tb1_newdata,原业务表为tb1,json字段名为j_json,正确的json字段值为下列内容(实际内容复杂很多)。
附加条件:每次只允许申报一种非固定支出的耗材种类,且这次出问题的记录里面没有重名的情况(重名的会复杂一些,目前想着是把能匹配上的匹配上,重名的大不了手工找映射关系,增加虚拟字段存映射ID都行)
{"学校编码": "京0156","规模": "大型","市/区": "海淀","法人": "曾书书","班级": {"班级数": 50,"班级列表": [{"编号": "一零一","名称": "一年级一班"}]},"年度预算": {"预算年度": 2023,"预算申报日期": "2023-09-30","申报负责人": [{"随机ID": "011234","姓名": "曾书书"}],"申报组成员": [{"随机ID": "011234","姓名": "曾书书"}, {"随机ID": "011214","姓名": "李老师"},{"随机ID": "015234","姓名": "王老师"}],"固定支出": {"薪资": 1000,"授权费": 5000},"非固定支出": {"本次申报类型": "实验耗材","申报日期": "2023-08-26","耗材": [{"办公用品": {"电子设备更新": 0,"上年压款结算": 0,"汇总日期": "","汇总人": ""}},{ "体育用品": {"教学设备更新": 0,"内训": 0,"外训": 0,"汇总日期": "","汇总人": ""}},{"实验耗材": { // 历史数据这里整组为空,当成“办公用品来解析了”"上年预算": 6000,"上年决算": 6300,"本年预算": 6500,"汇总日期": "2023-08-24","汇总人": "张三","大额清单": [{"序号": 1,"商品A": 1000,"负责人": "李四"},{"序号": 2,"商品B": 1500,"负责人": "王五"},{"序号": 3,"商品A": 800,"负责人": "马六"},]}}]}}
}
-
先备份原表数据(很重要哦),有问题可以随时恢复
create table tb1_bak_20230826 as select * from tb1 where dt_createtime between 'xxx' and 'xxx'; -- 这里其实推荐备份全表,实验表再条件备份,因为我对自己有信心,所以这里就偷懒了 -
再备份一份原表数据(用于试验更新结果,随时会重建)
create table tb1_old as select * from tb1_bak_20230826; -
初步书写映射关系
-- 1、先确认是否可以正确查询结果 select j_json->'年度预算'->'固定支出' from tb1_old limit 1; -- 正确输出“薪资”、“授权费”等 -- 2、确认数组内容是否可正确查询 select j_json->'年度预算'->'非固定支出'->0 from tb1_old limit 1; -- 正确输出耗材整组内容 -- 3、连表查询关联的结果总数 select count(*) from tb1_newdata t1 inner join tb1_old t2 on t1.j_json->'年度预算'->'申报组成员'->0->'姓名' = t2.j_json->'年度预算'->'申报组成员'->0->'姓名'; -- 应该输出128,实际结果只有5条。为啥与预期差这么多? -- 4、根据姓名先检索对应ID select c_bh from tb1_newdata where j_json->'年度预算'->'申报组成员'::text like '%曾书书%'; -- 记录下来ID,并用同样的方式确认旧表里对应记录ID -- 5、分别更换表名使用脚本确认条件字段实际结果 select j_json->'年度预算'->'申报组成员'->0->'姓名' from tb1_newdata where c_bh = '上面的结果'; -- 原因是数组实际内容没有变更,只是位置发生了变化,导致第0个元素不是同一个人了 -
既然相等不起作用,那么我们用包含来判断?
-- 网上查了下 @> 和 <@ 可以用于判断指定元素是否存在于指定数组中,那么开始试验 -- 1、第一次尝试 select * from tb1_newdata t1 inner join tb1_old t2 on t1.j_json->'年度预算'->'申报组成员' @> t2.j_json->'年度预算'->'申报组成员'->0; -- 执行直接报错,提示operator does not exists: boolean -> unknown -- 2、将随机某条结果结果直接拿出来检查,确认是否条件数据提取错误 select j_json->'年度预算'->'申报组成员', j_json->'年度预算'->'申报组成员'->0 from tb1_newdata where c_bh = 'xxx'; -- 结果看起来没啥问题,前者是一个数组,后者是一组元素 -- 3、脱离业务表,单独验证条件是否成立 select '[{"随机ID":"011234","姓名":"曾书书"},{"随机ID":"011214","姓名":"李老师"},{"随机ID":"015234","姓名":"王老师"}]'::jsonb @> '{"随机ID":"011234","姓名":"曾书书"}'::jsonb; -- 结果是f,这为啥不匹配?奇哉!怪哉!脑瓜疼哉! -- 4、不知道怎么突然想起来,前者是数组,后者不是数组,试试加上[]? select '[{"随机ID":"011234","姓名":"曾书书"},{"随机ID":"011214","姓名":"李老师"},{"随机ID":"015234","姓名":"王老师"}]'::jsonb @> '[{"随机ID":"011234","姓名":"曾书书"}]'::jsonb; -- 嘿,您猜怎么着?那叫一个地道!不对,串场了不好意思。 -- 结果竟然由f变成了t。奇哉!怪哉!脑瓜疼哉! -- 虽然但是,我也不想再前后拼接字符串来匹配,何况里面还有个随机的人员ID,两次导入的相同人也是变化的,此路不通 -
那有返回数组指定元素位置的函数吗?
很可惜,我没找到…(可能是我翻阅的资料还不够多,也可能是这种函数投入产出比不高,厂家没做)
解决思路3(还是我们来搞)
这…还能咋搞?总不能写个代码,逐个解析成结构化数据再匹配吧?这也太麻烦了(让人家用户手工重新导入的感觉估计会比我这时候的感觉更糟糕,本来准备excel就费劲,还有一堆其他事儿,你还让我因为非我导致的原因返工?)。
那就继续分析是否还有其他数据项可利用吧。
-
全局搜索“曾书书”
还是只搜到这一组。难道就没有其他地方有这个标记了?再一看,哦,记事本没有循环查找功能,光标就在这一组这里
-
光标挪到最上面,重新查找
盲生他发现了华点,原来还有一组“申报负责人”可以用,里面的这个“张老师”也是可以唯一标记问题记录的(实际业务比举例复杂,确实可以当做唯一标记,举例并没有那么严谨)
-
脚本验证
-- 1、数据匹配(这就简单多了)
select count(*) from tb1_newdata t1 inner join tb1_old t2 on t1.j_json->'年度预算'->'申报负责人'->'姓名' @> t2.j_json->'年度预算'->'申报负责人'->'姓名'; -- 结果为128,数据量对上了。
-- 脚本的一小步,我处理问题的一大步,剩下的就是替换了,谷歌了一下,找到一个函数jsonb_set
-- 2、确认将要更新的内容是否正确
select jsonb_set(t2.j_json, '年度预算,非固定支出,耗材,实验耗材', t1.j_json->'年度预算'->'非固定支出'->'耗材'->'实验耗材'), t1.j_json->'年度预算'->'非固定支出'->'耗材'->'实验耗材', t2.j_json->'年度预算'->'非固定支出'->'耗材'->'实验耗材' from tb1_newdata t1 inner join tb1_old t2 on t1.j_json->'年度预算'->'申报负责人'->'姓名' @> t2.j_json->'年度预算'->'申报负责人'->'姓名'; -- 比对结果,一切正常
-- 3、书写更新脚本
update tb1_old set j_json = tmp.j_json from (
select jsonb_set(t2.j_json, '年度预算,非固定支出,耗材,实验耗材', t1.j_json->'年度预算'->'非固定支出'->'耗材'->'实验耗材'), t2.c_bh from tb1_newdata t1 inner join tb1_old t2 on t1.j_json->'年度预算'->'申报负责人'->'姓名' @> t2.j_json->'年度预算'->'申报负责人'->'姓名'
) tmp on tb1_old.c_bh = tmp.c_bh; -- 受影响行数128行
-- 4、随机抽查,验证结果(为了更直观及快捷的比对,又搜了美化json结果的函数,jsonb_pretty)
select jsonb_pretty(j_json) from tb1_old where c_bh = 'xxx'; -- 结果正确!哇的一声就哭了
但截至目前只是成功矫正了B服务,C服务需要删掉错误数据,重新再怎么触发一下就会自动同步最新数据,这128条数据有可能需要我手工逐个操作一遍,又会是一个大工程。研发已经下班啦,我CC也没搜到当时怎么重新同步的,只能再等研发支持啦,写个笔记就可以回去睡觉啦。
总结
这次我学到了什么呢:
-
->加数字代表取数组的第n个元素;->加文本代表取json的指定对象(结果也是json格式);->>与->的用法一致,只是前者结果是文本,后者依然是json对象
-
jsonb_pretty函数可以美化json结果(注意结果不要直接放到记事本里面,放写字板或其他文本编辑工具,记事本展示结果
-
jsonb_set函数可以置换json中的指定元素
-
@> 操作符是判断左侧元素数组中是否包含右侧元素, >@ 操作符是判断右侧元素数组中是否包含左侧元素。左右两侧均可放多个元素比较,且不区分位置,全部包含即为真,否则为假(但需要判断的那个元素,貌似必须是以数组的形式书写,否则结果永远为假)
-
最后说两句
最后:团队交接,一定不要太匆忙,给一些原团队盘点以及新团队学习的时间呀!而且,新团队刚接手时,可得保障产出质量,不然整体成本增加不说,客户满意度还会下降,还会打击现场人员的升级积极性,得不偿失呀!
最后的最后:其实这篇文章干货不多,例如没找到新的映射关系的话,当前的知识储备针对当前问题依然是无解的,最终可能还得写程序搞定,但运气好找到了唯一映射,运气也是实力的一部分,都要加油哦!
官方手册:http://postgres.cn/docs/11/functions-json.html
相关文章:

一次PostgreSQL复杂jsonb数据矫正过程分享
背景介绍 想看干货直接看最后的总结,其他流水账可以不看,也可以当故事看。 7月底我司某产品因故需要拉齐现场版本,其中某地版本较低,且曾经做过一些定制内容,升级前也未识别该情况,导致后续持续一个月不断…...
如何在App里拉起小程序?
什么是小程序运行时框架? FinClip 的小程序编程模型是分为多个页面,每个页面有自己的 template、CSS 和 JS,实际在运行的时候,业务逻辑的 JS 代码是运行在独立的 JavaScript 引擎中,每个页面的 template 和 CSS 是运行…...
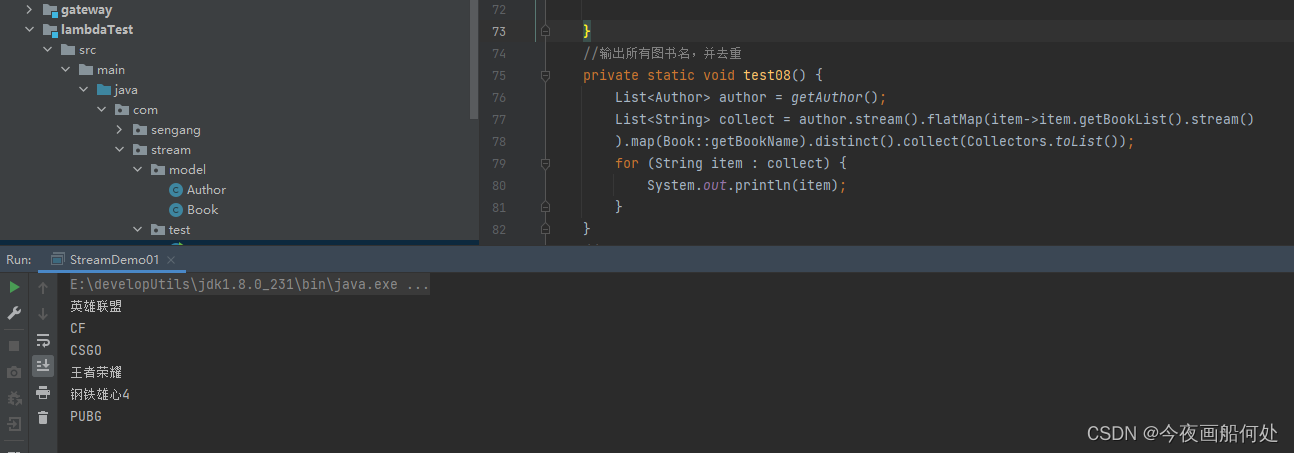
函数式编程-Stream流学习第二节-中间操作
1 Stream流概述 java8使用的是函数式编程模式,如同它的名字一样,它可以用来对集合或者数组进行链状流式操作,让我们更方便的对集合或者数组进行操作。 2 案例准备工作 我们首先创建2个类一个作家类,一个图书类 package com.stream.model;…...
SpringCloud 教程 | 第一篇: 服务的注册与发现(Eureka)
一、spring cloud简介 spring cloud 为开发人员提供了快速构建分布式系统的一些工具,包括配置管理、服务发现、断路器、路由、微代理、事件总线、全局锁、决策竞选、分布式会话等等。它运行环境简单,可以在开发人员的电脑上跑。另外说明spring cloud是基…...

无涯教程-进程 - 组会话控制
在本章中,我们将熟悉进程组,会话和作业控制。 进程组(Process Groups ) - 进程组是一个或多个进程的集合,一个进程组由一个或多个共享相同进程组标识符(PGID)的进程组成。 会话(Sessions) - 它是各种进程组的集合。…...

tomcat高可用和nginx高可用
tomcat高可用和nginx高可用 小白教程,一看就会,一做就成。 1.什么是高可用? 高可用HA(High Availability)是分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计减少系统不能提供服务…...
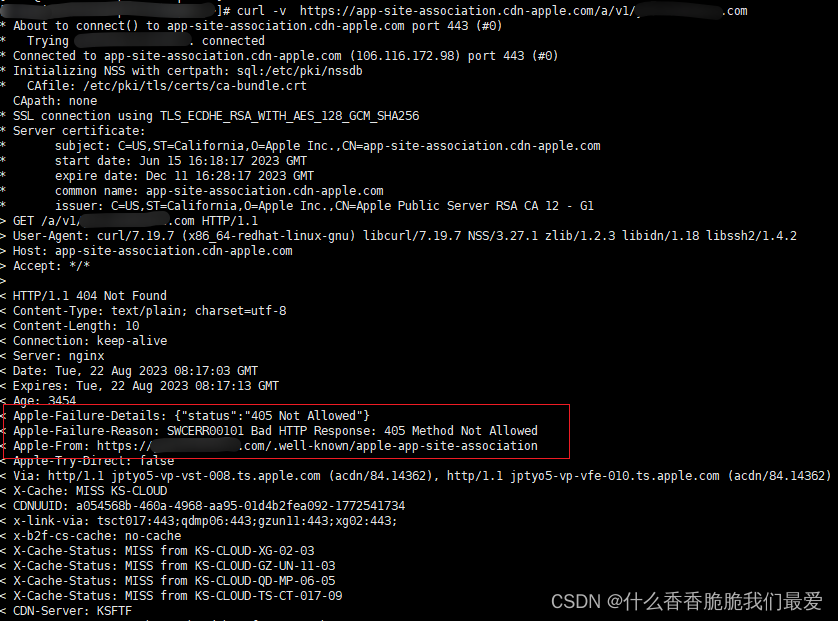
关于ios Universal Links apple-app-site-association文件 Not Found的问题
1. 背景说明 1.1 Universal Links 是什么 Support Universal Links 里面有说到 Universal Links 是什么、注意点、以及如何配置的。简单来说就是 当您支持通用链接时,iOS 用户可以点击指向您网站的链接,并无缝重定向到您安装的应用程序 大白话就是说&am…...

Objectarx MFC 添加ListControl并控制显隐
最主要的是实现一个Button点击将下方的List显示出来,制作成抽屉式菜单工具。 这篇文章是想实现点击工具栏并控制List的显隐。 参照: MFC中实现一个控件的隐藏和显示 【MFC】判断控件是否为隐藏状态 MFC中查找构件使用ID进行控制,这个和WPF&a…...

2023年高教社杯数学建模思路 - 复盘:人力资源安排的最优化模型
文章目录 0 赛题思路1 描述2 问题概括3 建模过程3.1 边界说明3.2 符号约定3.3 分析3.4 模型建立3.5 模型求解 4 模型评价与推广5 实现代码 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 描述 …...
SpringMVC 第二天
第 1 章 ModelAttribute 和 SessionAttribute[ 应 用 ] 1.1ModelAttribute 1.1.1 使用说明 作用: 该注解是 SpringMVC4.3 版本以后新加入的。它可以用于修饰方法和参数。 出现在方法上,表示当前方法会在控制器的方法执行之前,先执行…...

抖音seo短视频矩阵系统源码开发源代码分享--开源-可二开
适用于抖音短视频seo矩阵系统,抖音矩阵系统源码,短视频seo矩阵系统源码,短视频矩阵源码开发,支持二次开发,开源定制,招商加盟SaaS研发等。 功能开发设计 1. AI视频批量剪辑(文字转语音&#x…...

No message found under code ‘-1‘ for locale ‘zh_CN‘.
导出中的报错:No message found under code -1 for locale zh_CN. 报错原因:页面中展示的数据和后端excel中的数据不一致导致 具体原因:...
QtWidgets和QtQuick融合(QML与C++融合)
先放一个界面效果吧! 说明:该演示程序为一个App管理程序,可以将多个App进行吸入管理。 (动画中的RedRect为一个带有QSplashScreen的独立应用程序) 左侧边栏用的是QQuickView进行.qml文件的加载(即QtQuick…...

基于Vue的3D饼图
先看效果: 再看代码: <template><div class"container"><div style"height: 100%;width: 100%;" id"bingtu3D"></div></div></template> <script> import "echarts-liqu…...

Gateway简述
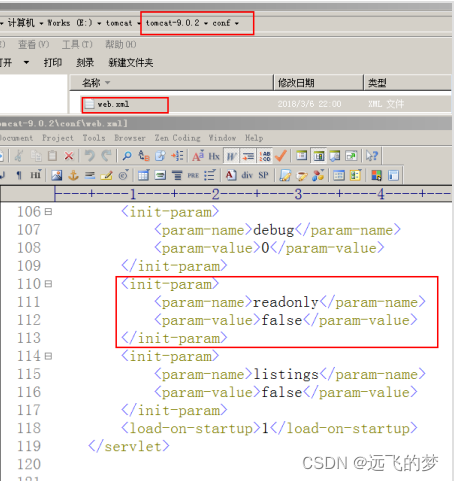
前言 在微服务架构中,一个系统会被拆分为很多个微服务。那么作为客户端调用多个微服务接口的地址。另外微服务架构的请求中,90%的都携带认证信息/用户登录信息,都需要做相关的限制管理,API网关由此应允而生。 这样的架构会存…...
Midjourney API 的对接和使用
“ 阅读本文大概需要 4 分钟。 ” 在人工智能绘图领域,想必大家听说过 Midjourney 的大名吧。 Midjourney 以其出色的绘图能力在业界独树一帜。无需过多复杂的操作,只要简单输入绘图指令,这个神奇的工具就能在瞬间为我们呈现出对应的图像。无…...

01 消息引擎系统
本文是Kafka 核心技术与实战学习笔记 kafka的作用 kafka最经常被提到的作用是是削峰填谷,即解决上下游TPS的错配以及瞬时峰值流量,如果没有消息引擎系统的保护,下游系统的崩溃可能会导致全链路的崩溃。还有一个好处是发送方和接收方的松耦合…...
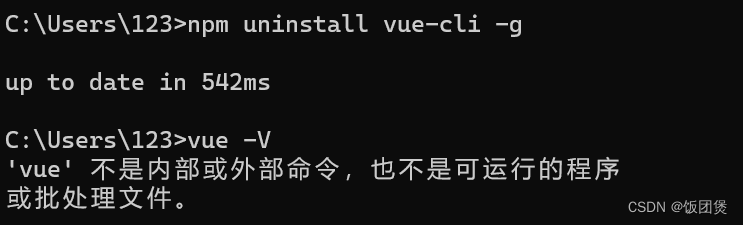
npm 卸载 vuecli后还是存在
运行了npm uninstall vue-cli -g,之后是up to date in,然后vue -V,版本号一直都在,说明没有卸载掉 1、执行全局卸载命令 npm uninstall vue-cli -g 2、删除vue原始文件 查看文件位置,找到文件删掉 where vue 3、再…...

Unity 之利用 localEulerAngle与EulerAngle 控制物体旋转
文章目录 概念讲解localEulerAngle与EulerAngle的区别 概念讲解 欧拉角(Euler Angles)是一种常用于描述物体在三维空间中旋转的方法。它使用三个角度来表示旋转,分别绕物体的三个坐标轴(通常是X、Y和Z轴)进行旋转。这…...
)
从零学算法 (剑指 Offer 13)
地上有一个m行n列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] 。一个机器人从坐标 [0, 0] 的格子开始移动,它每次可以向左、右、上、下移动一格(不能移动到方格外),也不能进入行坐标和列坐标的数位之和大于k的格子。例如&am…...

告别PyTorch依赖:手把手教你用C++ CUDA实现LeNet推理,从Python模型导出到C++部署全流程
从PyTorch到C CUDA:工业级LeNet模型部署全流程实战 在深度学习模型开发中,Python生态提供了丰富的训练工具,但生产环境往往需要高性能的C实现。本文将完整演示如何将PyTorch训练的LeNet模型部署到C CUDA环境,涵盖模型导出、内存管…...

如何永久激活IDM?免费IDM激活脚本终极指南
如何永久激活IDM?免费IDM激活脚本终极指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script 还在为IDM试用期到期而烦恼吗?IDM Activation …...

【电路板】基于matlab模拟电路板激光加工中的热分布【含Matlab源码 15559期】
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

构建企业级AI对话平台:Open WebUI部署架构深度解析
构建企业级AI对话平台:Open WebUI部署架构深度解析 【免费下载链接】open-webui User-friendly AI Interface (Supports Ollama, OpenAI API, ...) 项目地址: https://gitcode.com/GitHub_Trending/op/open-webui 在AI技术快速发展的今天,如何构建…...

PPT怎么转PDF?一键快捷操作与全方位转换方法测评
在日常工作中,我们经常需要将PowerPoint演示文稿转换成PDF格式。无论是为了保证演示文件的兼容性、方便分享给他人,还是用于打印和存档,PPT转PDF都是一项必不可少的技能。本文将为你深入讲解PPT转PDF的多种方法,包括快捷键操作、软…...

你的EEPROM数据丢了吗?基于STM32和AT24CXX的I2C通信稳定性实战调优指南
EEPROM数据可靠性实战:STM32与AT24CXX的I2C通信深度优化 在工业控制、医疗设备和消费电子等领域,EEPROM作为非易失性存储器承担着关键参数存储的重任。但当系统突然断电或遭遇电磁干扰时,工程师们常会遇到数据丢失、校验失败等棘手问题。本文…...

终极小说阅读器:Uncle小说如何一站式解决你的数字阅读需求
终极小说阅读器:Uncle小说如何一站式解决你的数字阅读需求 【免费下载链接】uncle-novel 📖 Uncle小说,PC版,一个全网小说下载器及阅读器,目录解析与书源结合,支持有声小说与文本小说,可下载mob…...

如何用SUMO-RL构建智能交通信号系统:强化学习实战指南
如何用SUMO-RL构建智能交通信号系统:强化学习实战指南 【免费下载链接】sumo-rl Reinforcement Learning environments for Traffic Signal Control with SUMO. Compatible with Gymnasium, PettingZoo, and popular RL libraries. 项目地址: https://gitcode.com…...

Windows平台PDF处理终极方案:告别编译烦恼,三分钟快速部署
Windows平台PDF处理终极方案:告别编译烦恼,三分钟快速部署 【免费下载链接】poppler-windows Download Poppler binaries packaged for Windows with dependencies 项目地址: https://gitcode.com/gh_mirrors/po/poppler-windows 还在为Windows上…...
)
别再乱关防火墙了!ESXi 7.0/8.0 安全开放自定义端口的保姆级教程(附配置文件详解)
ESXi防火墙精细化管控:安全开放自定义端口的工程实践 在虚拟化环境中,ESXi主机作为承载业务系统的核心基础设施,其网络安全防护的重要性不言而喻。许多管理员在面对需要开放非标准端口的场景时,往往陷入两难:要么粗暴关…...