哈希表HashMap(基于vector和list)
C++数据结构与算法实现(目录)
1 什么是HashMap?
我们这里要实现的HashMap接口不会超过标准库的版本(是一个子集)。
HashMap是一种键值对容器(关联容器),又叫字典。
和其他容易一样,它可以对存储的元素进行增删改查操作。
它之所以叫关联容器,是因为它的每个元素都是一对(键 key 和值 value)。
比如:
HashMap h;
h[123] = string("张三");//每个元素包括一个键(123)和值("张三")这种容器可以快速的访问容器中的任何一个元素。
2 为何可以快速访问元素?桶
它之所以能快速的做到这一点,是因为可以快速的知道这个容器里有没有这个元素。
而快速知道容器里有没有这个元素的关键就在于拿到一个key,就知道这个元素会在哪个桶里面。
这里使用一个函数,也叫hash函数,计算key对应的桶:
auto index = hashFunction(key);
HashMap的结构如下图所示:
槽桶是一个vector数组,每个数组里是一个list链表。
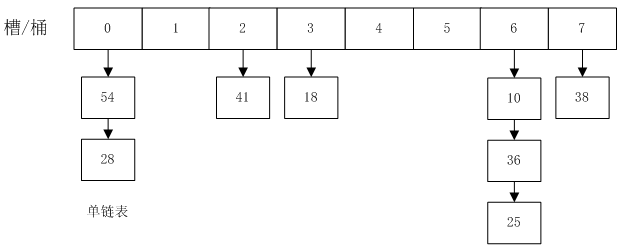
3 冲突与解决
不同的 key 如果都映射到同一个index怎么让同一个桶存两个value呢?
hashFun(key1) == hashFun(key2)
可以使用一个单链表,将相同 hash 值的 key 放到同一个桶里。
4 元素的均匀分布
怎么样设计hashFun使得元素会均匀的落到每个链表里?
使得每个链表里都有大概n/N个元素。其中,n是元素总数,N是槽的个数。是我们需要重点考虑的。
为了解决这个问题,我们要求hashFunction 对每一个key,都能均匀的分散到各个桶里,最简单有效的办法就是将key看成(转换成)整数,对vector 桶的数量求余数,余数作为桶的索引(本文我们就使用这种方法)。
5 再哈希 rehash
如果随着元素数量越来越多,元素都堆积在某一个或几个链表里,其他链表都空着。这样HashMap又退化成链表了:
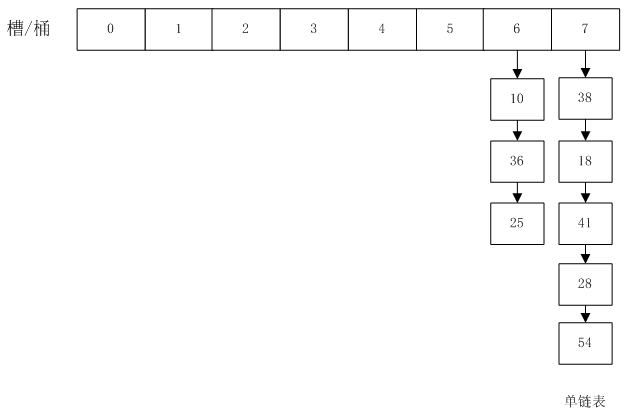
解决了元素的均匀分布之后,我们还会遇到下一个问题。
元素越来越多以后,桶bucket的数量应该要增加,不然每个链表都很长,效率还是会降低。

这时候就要再hash。
判断什么时候应该rehash的机制就是看装载因子load_factor 的大小。
load_factor 来表示现在是不是元素数量已经很多了,如果这个值 大于0.8,就表示每个桶里堆积的元素都比较多了。就要使用更多的桶来存放元素了。
装载因子的计算方法,有个很简单的办法,就是让每个vector里的链表尽量的短。那就是容器元素接近vector元素的数量:
load_factor = n/N
其中,n 是元素总数,N是槽的个数。
比如, n/N > 0.8 ,我们就再 hash 一次。
6 成员函数设计要点
我们将使用vector 和 list 来实现这个容器,让大家感受一下用轮子造轮子到底有多爽。
感受软件复用的力量。
感受抽象的力量。
1) clear
这个函数负责清空元素,回到初始状态,也就是对象被构造出来的状态。
但是,由于我们的HashMap 在初始状态就开辟了8个空间为未来存放元素使用,所以clear会涉及到调用reset。
而 reset需要记得初始化一切数据,包括将容量设置为8.

2) reset
reset是给默认构造函数调用的,其具体行为参考 clear部分的介绍。
同时,reset也会被clear调用。那直接用clear一个函数不就好了吗?实际上是为了代码更容易阅读理解。
reset为了初始化, clear是用户调用的,用户只知道清空容器,并不关心reset。
3) copy
copy函数负责拷贝另一个对象的数据给当前对象。
主要是拷贝构造函数和赋值操作符会调用。
首先,需要先清空当前对象的数据。然后再做深拷贝即可。
4) rehash 再哈希
这个函数是最复杂的,它主要分为如下几个部分:
(1)创建一个新的HashMap对象
(2)新对象的桶数量要翻倍(rehash的主要作用就是横向扩展,让每个list变短)
(3)把原来的元素装到新的HashMap对象里
(4)交换新旧对象的资源实现接管新场所,释放旧空间的目的
5) operator[]
这个函数会添加元素(如果元素不存在的话),而如果此时容器已经比较拥挤了,就是扩容的时机。
4) 其他函数
更多函数设计的实现细节思路,参考下面代码中的注释部分。
C++实现
下面我们将实现一个 key 类型为 int,value 类型为 std::string 的HashMap。
HashMap.h 头文件
#pragma once
#include<string>
#include<list>
#include<memory>
#include<vector>
#include<utility>
using namespace std;
class HashMap
{
public:HashMap(void);~HashMap(void);HashMap(const HashMap& from);HashMap& operator=(const HashMap& from);
public:bool empty(void) const { return m_size == 0; }size_t size(void) const;bool contains(const int& key) const;std::string& operator[](const int& key);void erase(const int& key);
public:using value_type = std::pair<int, std::string>;
public:class iterator{friend class HashMap;public:iterator& operator++(void);//++itrbool operator==(const iterator& itr);bool operator!=(const iterator& itr);value_type& operator*(void);private:iterator(HashMap* hashmap, size_t bucket_index, std::list<value_type>::iterator itr);private:std::list<value_type>::iterator m_itr;size_t m_bucket_index;//-1 for end()HashMap* m_hashmap;};iterator begin(void);iterator end(void);void clear(void);
private:size_t hash(const int& key) const;void copy(const HashMap& from);//装载因子double load_factor(void) const { return (double)m_size / m_bucket_array_length; };void re_hash(void);//扩大容量void reset(void);
private:std::vector<std::list<value_type>> m_bucket_array;size_t m_size = 0;size_t m_bucket_array_length = 8;
};
实现特点:增删改查、迭代器、再哈希、复制控制、基于std::vector、std::list (复用、模块化)
HashMap.cpp 源文件
#include "HashMap.h"
#include <algorithm>
#include <iostream>
#include <cassert>
using namespace std;HashMap::HashMap(void)
{//(1) your code 直接调用reset完成默认开辟8个元素空间cout << "HashMap()" << endl;
}HashMap::~HashMap(void)
{// 析构函数什么也不用做,因为存放数据的容器 vector list 会自动释放其拥有的元素cout << "~HashMap()" << endl;
}HashMap::HashMap(const HashMap& from)
{//(2) your code 直接调用 copy 即可完成拷贝cout << "HashMap(const HashMap &)" << endl;
}HashMap& HashMap::operator=(const HashMap& from)
{//(2) your code 直接调用 copy 即可完成拷贝cout << "HashMap::operator=(const HashMap & from)" << endl;return *this;
}size_t HashMap::size(void) const
{return m_size;
}bool HashMap::contains(const int& key) const
{//(3) your code 通过hash(key) 得到数据如果存在应该在哪个桶里//(4) your code 再到桶里 list 查找有没有这个元素 ,在链表中 线性查找return false;//这里需要改成真正的查找结果
}std::string& HashMap::operator[](const int& key)
{//(5) your code 如果装载因子 大于了 0.8 就 re_hash 扩大容量//通过hash(key) 得到数据如果存在应该在哪个桶里auto index = hash(key);assert(m_bucket_array.size() > index);auto& bucket = m_bucket_array[index];//再到桶里 list 查找有没有这个元素 ,在链表中 线性查找。返回 list<T>::iteratorauto itr = std::find_if(bucket.begin(), bucket.end(), [key](const value_type& value) {return value.first == key;});if (itr == bucket.end()){//(6) your code. key not exist, insert empty std::string as default value//(7) your code. increase the size of current hash map.//(8) your code. return elementstatic string s_bad;//请删除return s_bad;//请重写}else{//(9) your code. return elementstatic string s_bad;//请删除return s_bad;//请重写}
}void HashMap::erase(const int& key)
{auto index = hash(key);auto& bucket = m_bucket_array[index];auto itr = std::find_if(bucket.begin(), bucket.end(), [key](const value_type& value) {return value.first == key;});if (itr == bucket.end()){throw std::runtime_error("erasing not exist key!");}else{--m_size;bucket.erase(itr);}
}HashMap::iterator HashMap::begin(void)
{for (size_t i = 0; i < m_bucket_array_length; i++){if (!m_bucket_array[i].empty()){return HashMap::iterator(this, i, m_bucket_array[i].begin());}}return end();
}HashMap::iterator HashMap::end(void)
{return HashMap::iterator(this, -1, std::list<value_type>::iterator());
}size_t HashMap::hash(const int& key) const
{// 使用key 得到元素在哪个桶里。使用求余数来得到。// 这种算法可以认为是足够简单而且元素会均匀分布在各个桶里的int index = key % m_bucket_array_length;return index;
}void HashMap::clear(void)
{reset();
}void HashMap::copy(const HashMap& from)
{clear();m_bucket_array.resize(from.m_bucket_array_length);for (size_t i = 0; i < m_bucket_array_length; i++){//10 your code. 使用链表的赋值操作符直接拷贝链表}m_size = from.m_size;
}void HashMap::re_hash(void)
{//另起炉灶,新创建一个HashMapHashMap re_hashmap;//将新的炉灶扩大容量re_hashmap.m_bucket_array_length = this->m_bucket_array_length * 2 + 1;//11 your code. 将新的炉灶实际的桶开辟出来//使用迭代器,遍历原来的(this)所有元素,将所有元素拷贝到新的炉灶里for (auto itr = begin(); itr != end(); ++itr){//12 your code. 先根据key获得桶,再把value追加到桶里list的末尾}//交换新旧两个容器的内容,接管新炉灶std::swap(re_hashmap.m_bucket_array, m_bucket_array);//其他成员变量更新this->m_bucket_array_length = re_hashmap.m_bucket_array_length;re_hashmap.m_size = this->m_size;
}void HashMap::reset(void)
{m_size = 0;m_bucket_array.clear();m_bucket_array_length = 8;m_bucket_array.resize(m_bucket_array_length);
}HashMap::iterator& HashMap::iterator::operator++(void)
{//valid itr can always do ++itrauto index = m_hashmap->hash(m_itr->first);auto& bucket = m_hashmap->m_bucket_array[index];++m_itr;//find next list or the end() occorif (m_itr == bucket.end()){for (size_t i = m_bucket_index + 1; i < m_hashmap->m_bucket_array_length; i++){if (!m_hashmap->m_bucket_array[i].empty()){m_bucket_index = i;m_itr = m_hashmap->m_bucket_array[i].begin();return *this;}}m_bucket_index = -1;//end()}return *this;
}bool HashMap::iterator::operator==(const iterator& itr)
{if (itr.m_bucket_index != this->m_bucket_index){return false;}if (itr.m_bucket_index == -1 && this->m_bucket_index == -1){return true;//both end()}else{bool equal = &*(m_itr) == &*(itr.m_itr);return equal;//pointed to the same value address}
}bool HashMap::iterator::operator!=(const iterator& itr)
{bool equal = (*this == itr);return !equal;
}HashMap::value_type& HashMap::iterator::operator*(void)
{return *m_itr;
}HashMap::iterator::iterator(HashMap* hashmap, size_t bucket_index, std::list<value_type>::iterator itr)
{m_hashmap = hashmap;m_itr = itr;m_bucket_index = bucket_index;
}
main.cpp
#include <iostream>
#include "HashMap.h"
#include <cassert>
#include <unordered_map>
#include <set>
using namespace std;//------下面的代码是用来测试你的代码有没有问题的辅助代码,你无需关注------
#include <algorithm>
#include <cstdlib>
#include <iostream>
#include <vector>
#include <utility>
using namespace std;
struct Record { Record(void* ptr1, size_t count1, const char* location1, int line1, bool is) :ptr(ptr1), count(count1), line(line1), is_array(is) { int i = 0; while ((location[i] = location1[i]) && i < 100) { ++i; } }void* ptr; size_t count; char location[100] = { 0 }; int line; bool is_array = false; bool not_use_right_delete = false; }; bool operator==(const Record& lhs, const Record& rhs) { return lhs.ptr == rhs.ptr; }std::vector<Record> myAllocStatistic; void* newFunctionImpl(std::size_t sz, char const* file, int line, bool is) { void* ptr = std::malloc(sz); myAllocStatistic.push_back({ ptr,sz, file, line , is }); return ptr; }void* operator new(std::size_t sz, char const* file, int line) { return newFunctionImpl(sz, file, line, false); }void* operator new [](std::size_t sz, char const* file, int line)
{return newFunctionImpl(sz, file, line, true);
}void operator delete(void* ptr) noexcept { Record item{ ptr, 0, "", 0, false }; auto itr = std::find(myAllocStatistic.begin(), myAllocStatistic.end(), item); if (itr != myAllocStatistic.end()) { auto ind = std::distance(myAllocStatistic.begin(), itr); myAllocStatistic[ind].ptr = nullptr; if (itr->is_array) { myAllocStatistic[ind].not_use_right_delete = true; } else { myAllocStatistic[ind].count = 0; }std::free(ptr); } }void operator delete[](void* ptr) noexcept { Record item{ ptr, 0, "", 0, true }; auto itr = std::find(myAllocStatistic.begin(), myAllocStatistic.end(), item); if (itr != myAllocStatistic.end()) { auto ind = std::distance(myAllocStatistic.begin(), itr); myAllocStatistic[ind].ptr = nullptr; if (!itr->is_array) { myAllocStatistic[ind].not_use_right_delete = true; } else { myAllocStatistic[ind].count = 0; }std::free(ptr); } }
#define new new(__FILE__, __LINE__)
struct MyStruct { void ReportMemoryLeak() { std::cout << "Memory leak report: " << std::endl; bool leak = false; for (auto& i : myAllocStatistic) { if (i.count != 0) { leak = true; std::cout << "leak count " << i.count << " Byte" << ", file " << i.location << ", line " << i.line; if (i.not_use_right_delete) { cout << ", not use right delete. "; } cout << std::endl; } }if (!leak) { cout << "No memory leak." << endl; } }~MyStruct() { ReportMemoryLeak(); } }; static MyStruct my; void check_do(bool b, int line = __LINE__) { if (b) { cout << "line:" << line << " Pass" << endl; } else { cout << "line:" << line << " Ohh! not passed!!!!!!!!!!!!!!!!!!!!!!!!!!!" << " " << endl; exit(0); } }
#define check(msg) check_do(msg, __LINE__);
//------上面的代码是用来测试你的代码有没有问题的辅助代码,你无需关注------int main()
{//create insert find{HashMap students;check(students.empty());check(students.size() == 0);int id = 123;check(students.contains(id) == false);std::string name("zhangsan");students[id] = name;check(!students.empty());check(students.size() == 1);check(students.contains(id));check(students[id] == name);}//modify value{HashMap students;int id = 123;std::string name("zhangsan");students[id] = name;std::string name2("lisi");students[id] = name2;check(students[id] == name2);check(students.size() == 1);}//erase{HashMap students;int id = 123;std::string name("zhangsan");students[id] = name;students.erase(id);check(!students.contains(id));check(students.size() == 0);}//clear value{HashMap students;int id = 123;std::string name("zhangsan");students[id] = name;std::string name2("lisi");students[id] = name2;check(students[id] == name2);check(students.size() == 1);students.clear();check(students.size() == 0);students.clear();}//copy{HashMap students;int id = 123;std::string name("zhangsan");students[id] = name;HashMap students2(students);//copy constructorcheck(students.contains(id));check(students.size() == 1);students[456] = "lisi";check(students.contains(456));check(!students2.contains(456));students2[789] = "wanger";check(!students.contains(789));check(students2.contains(789));check(students.size() == 2);check(students2.size() == 2);}//assignment{HashMap students;int id = 123;std::string name("zhangsan");students[id] = name;students[456] = "lisi";HashMap students2;students2 = students;check(students2.contains(id));check(students2.contains(456));check(students.size() == 2);}//iteratorconst int total = 50;{int id_creator = 1;HashMap students;std::string name("zhangsan");for (int i = 1; i <= total; ++i){students[id_creator++] = name + std::to_string(i);}check(students.size() == total);std::multiset<int> all_keys;for (auto& item : students){all_keys.insert(item.first);cout << item.first << " " << item.second << endl;}int i = 1;for (auto item : all_keys){assert(item == i++);}check(i == total + 1);students.clear();for (int i = 1; i <= total; ++i){students[i] = std::to_string(i);}check(students.contains(1));check(students.contains(total));check(students[1] == "1");check(students[total] == to_string(total));check(students.size() == total);}
}
输出如下:
HashMap()
line:30 Pass
line:31 Pass
line:33 Pass
line:36 Pass
line:37 Pass
line:38 Pass
line:39 Pass
~HashMap()
HashMap()
line:49 Pass
line:50 Pass
~HashMap()
HashMap()
line:59 Pass
line:60 Pass
~HashMap()
HashMap()
line:70 Pass
line:71 Pass
line:73 Pass
~HashMap()
HashMap()
HashMap(const HashMap &)
line:83 Pass
line:84 Pass
line:86 Pass
line:87 Pass
line:89 Pass
line:90 Pass
line:91 Pass
line:92 Pass
~HashMap()
~HashMap()
HashMap()
HashMap()
HashMap::operator=(const HashMap & from)
line:103 Pass
line:104 Pass
line:105 Pass
~HashMap()
~HashMap()
HashMap()
HashMap()
~HashMap()
HashMap()
~HashMap()
HashMap()
~HashMap()
line:117 Pass
1 zhangsan1
2 zhangsan2
3 zhangsan3
4 zhangsan4
5 zhangsan5
6 zhangsan6
7 zhangsan7
8 zhangsan8
9 zhangsan9
10 zhangsan10
11 zhangsan11
12 zhangsan12
13 zhangsan13
14 zhangsan14
15 zhangsan15
16 zhangsan16
17 zhangsan17
18 zhangsan18
19 zhangsan19
20 zhangsan20
21 zhangsan21
22 zhangsan22
23 zhangsan23
24 zhangsan24
25 zhangsan25
26 zhangsan26
27 zhangsan27
28 zhangsan28
29 zhangsan29
30 zhangsan30
31 zhangsan31
32 zhangsan32
33 zhangsan33
34 zhangsan34
35 zhangsan35
36 zhangsan36
37 zhangsan37
38 zhangsan38
39 zhangsan39
40 zhangsan40
41 zhangsan41
42 zhangsan42
43 zhangsan43
44 zhangsan44
45 zhangsan45
46 zhangsan46
47 zhangsan47
48 zhangsan48
49 zhangsan49
50 zhangsan50
line:129 Pass
HashMap()
~HashMap()
HashMap()
~HashMap()
HashMap()
~HashMap()
line:135 Pass
line:136 Pass
line:137 Pass
line:138 Pass
line:139 Pass
~HashMap()
Memory leak report:
No memory leak.项目下载:start file
链接:百度网盘 请输入提取码
提取码:1234
加油吧!
期待你的pass
答案在此
哈希表HashMap(基于vector和list)(答案)_C++开发者的博客-CSDN博客
相关文章:
哈希表HashMap(基于vector和list)
C数据结构与算法实现(目录) 1 什么是HashMap? 我们这里要实现的HashMap接口不会超过标准库的版本(是一个子集)。 HashMap是一种键值对容器(关联容器),又叫字典。 和其他容易一样…...

go中的函数
demo1:函数的几种定义方式 package mainimport ("errors""fmt" )/* 函数的用法 跟其他语言的区别:支持多个返回值*///函数定义方法1 func add(a, b int) int {return a b }//函数定义方法2 func add2(a, b int) (sun int) {sun a breturn s…...

小试 InsCode AI 创作助手
个人理解: 自ChatGPT新版现世,一直被视面替代人工工作的世大挑战,各类人工智能语言生成工目层出不穷,也在不断影响着我们日常的工作和生活 小试CSDN的InsCode AI: - 基本概念查询方便,与个人了解&…...

粉丝经验分享:13:00 开始的面试,13:06 就结束了,问题真是变态
🌷🍁 博主猫头虎(🐅🐾)带您 Go to New World✨🍁 🦄 博客首页——🐅🐾猫头虎的博客🎐 🐳 《面试题大全专栏》 🦕 文章图文…...

SASS的@规则
1,import sass扩展了import导入,对于css,import导入在页面加载的时候去下载导入的外部文件,而sass的导入,在编译成css文件的时候就将外部的sass文件导入合并编译成一个css文件。 他支持同时导入多个文件;…...
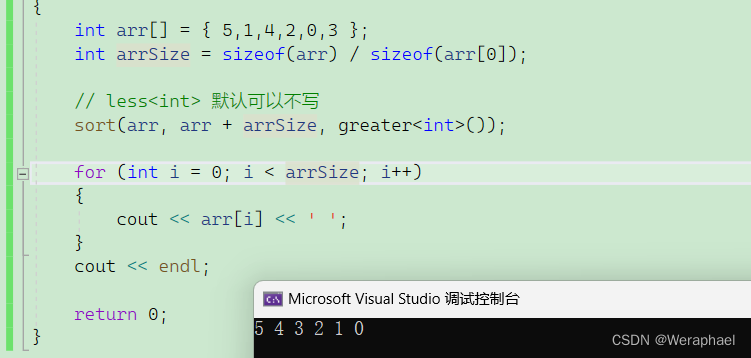
【C++初阶】模拟实现优先级队列priority_queue
👦个人主页:Weraphael ✍🏻作者简介:目前学习C和算法 ✈️专栏:C航路 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞…...

如何为你的公司选择正确的AIGC解决方案?
如何为你的公司选择正确的AIGC解决方案? 摘要引言词汇解释(详细版本)详细介绍1. 确定需求2. 考虑技术能力3. 评估可行性4. 比较不同供应商 代码快及其注释注意事项知识总结 博主 默语带您 Go to New World. ✍ 个人主页—— 默语 的博客&…...

Windows下将nginx等可执行文件添加为服务
Windows下将nginx等可执行文件添加为服务 为什么将可执行文件添加为服务?将可执行文件添加为服务的步骤步骤 1:下载和安装 Nginx步骤 2:添加为服务方法一:使用 Windows 自带的 sc 命令方法二:使用 NSSM(Non…...

视觉SLAM14讲笔记-第4讲-李群与李代数
李代数的引出: 在优化问题中去解一个旋转矩阵,可能会有一些阻碍,因为它对加法导数不是很友好(旋转矩阵加上一个微小偏移量可能就不是一个旋转矩阵),因为旋转矩阵本身还有一些约束条件,那样再求…...
浅析Redis(1)
一.Redis的含义 Redis可以用来作数据库,缓存,流引擎,消息队列。redis只有在分布式系统中才能充分的发挥作用,如果是单机程序,直接通过变量来存储数据是更优的选择。那我们知道进程之间是有隔离性的,那么re…...

【每日一题】2337. 移动片段得到字符串
【每日一题】2337. 移动片段得到字符串 2337. 移动片段得到字符串题目描述解题思路 2337. 移动片段得到字符串 题目描述 给你两个字符串 start 和 target ,长度均为 n 。每个字符串 仅 由字符 ‘L’、‘R’ 和 ‘_’ 组成,其中: 字符 ‘L’…...
MySQL 数据库常用命令大全(详细)
文章目录 1. MySQL命令2. MySQL基础命令3. MySQL命令简介4. MySQL常用命令4.1 MySQL准备篇4.1.1 启动和停止MySQL服务4.1.2 修改MySQL账户密码4.1.3 MySQL的登陆和退出4.1.4 查看MySQL版本 4.2 DDL篇(数据定义)4.2.1 查询数据库4.2.2 创建数据库4.2.3 使…...

中国移动加大布局长三角,打造算力产业新高地
8月27日,以“数实融合算启未来”为主题的2023长三角算力发展大会在苏州举办,大会启动了长三角算力调度枢纽,携手各界推动算力产业高质量发展。 会上,移动云作为第一批算力资源提供方,与苏州市公共算力服务平台签订算力…...

话费、加油卡、视频会员等充值接口如何对接?
现在很多商家企业等发现与用户保持粘性是越来越难了,大多数的用户活跃度都很差,到底该怎么做才能改善这种情况呢? 那么我们需要做的就是投其所好,在与用户保持粘性的app或者积分商城中投入大家感兴趣的物品或者虚拟产品ÿ…...

服务器重启MongoDB无法启动
文章目录 服务器重启MongoDB无法启动背景规划实施 总结 服务器重启MongoDB无法启动 背景 数据库服务器的CPU接近告警值了,需要添加CPU资源,于是乎就在恰当的时间对服务器进行关机,待添加完资源后开机,这样就完成了CPU资源的添加…...

深度刨析数据在内存中的存储
✨博客主页:小钱编程成长记 🎈博客专栏:进阶C语言 深度刨析数据在内存中的存储 1.数据类型介绍1.1 类型的基本归类 2.整形在内存中的存储2.1 原码、反码、补码2.2 大小端介绍 3.浮点型在内存中的存储3.1 一个例子3.2 浮点数的存储规则3.3指数…...
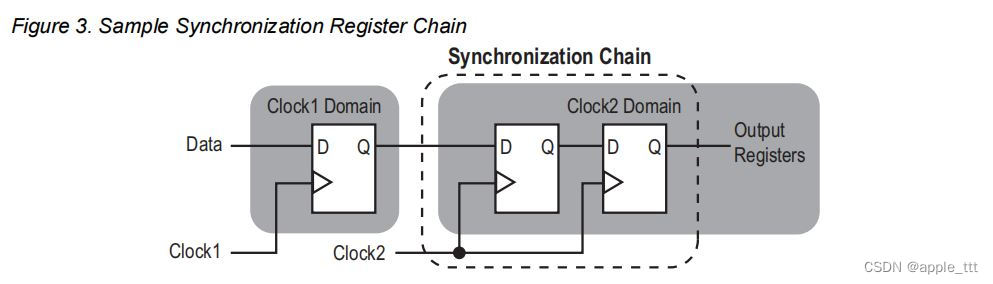
理解FPGA中的亚稳态
一、前言 大家应该经常能听说到亚稳态这个词,亚稳态主要是指触发器的输出在一段时间内不能达到一个确定的状态,过了这段时间触发器的输出随机选择输出0/1,这是我们在设计时需要避免的。本文主要讲述了FPGA中的亚稳态问题,可以帮助…...

Leetcode86. 分隔链表
给你一个链表的头节点 head 和一个特定值 x ,请你对链表进行分隔,使得所有 小于 x 的节点都出现在 大于或等于 x 的节点之前。 你应当 保留 两个分区中每个节点的初始相对位置。 力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台…...

如何处理 Flink 作业中的数据倾斜问题?
分析&回答 什么是数据倾斜? 由于数据分布不均匀,造成数据大量的集中到一点,造成数据热点。 举例:一个 Flink 作业包含 200 个 Task 节点,其中有 199 个节点可以在很短的时间内完成计算。但是有一个节点执行时间…...
cobbler自动化安装CentOS、windows和ubuntu
环境介绍 同时玩cobbler3.3和cobbler2.8.5 cobbler3.3 系统CentOS8.3 VMware虚拟机 桥接到物理网络 IP: 192.168.1.33 cobbler2.8.5 系统CentOS7.9 VMWare虚拟机 桥接到物理网络 IP:192.168.1.33 安装cobbler3.3 yum源修改 cat /etc/yum.repo.d/Cento…...
,3大未公开API接口实测报告)
别再手动复制粘贴了!ChatGPT原生PPT导出功能已上线(仅限Enterprise Tier),3大未公开API接口实测报告
更多请点击: https://intelliparadigm.com 第一章:ChatGPT原生PPT导出功能的架构演进与企业级定位 ChatGPT原生PPT导出功能并非简单集成第三方渲染库,而是OpenAI在模型服务层、内容生成中间件与文档编排引擎三者深度协同下构建的端到端能力。…...

5分钟快速获取微信数据库密钥:Sharp-dumpkey完整指南
5分钟快速获取微信数据库密钥:Sharp-dumpkey完整指南 【免费下载链接】Sharp-dumpkey 基于C#实现的获取微信数据库密钥的小工具 项目地址: https://gitcode.com/gh_mirrors/sh/Sharp-dumpkey 当你的微信聊天记录被加密锁定,无法备份或迁移时&…...
)
【限时解密】金融级Java代码审查SOP:Gemini+自定义规则包+合规检查矩阵(ISO 27001/等保2.0双认证适配版)
更多请点击: https://codechina.net 第一章:Gemini Java代码审查的核心价值与金融级适配逻辑 在高并发、强一致性、零容忍故障的金融系统中,Java代码质量直接关联资金安全、监管合规与交易连续性。Gemini并非通用AI辅助工具,而是…...

Win10 64 位专用 OpenClaw 小龙虾 AI 小白一键部署教程
适配系统:Windows10 64 位核心亮点:免命令行、免手动配置环境、解压即可安装,运行依赖全部内置,全程可视化操作,新手也能一次性顺利部署 2026 热门开源 AI 智能体专属优化:针对 Win10 系统定制适配…...
)
收藏!大模型算法工程师11个方向及2026年前景深度解析(小白程序员进阶必看)
本文深度剖析大模型算法工程师的11个核心方向,包括推理训练、Agentic Search、Agent/Tool Use等,并按梯队划分其发展前景。重点分析了各方向的技术难点与未来趋势,如开放域推理奖励设计、长链路推理稳定性、多模态后训练等。文章强调RL训练能…...

Taotoken多模型聚合能力在内容生成场景中的灵活应用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Taotoken多模型聚合能力在内容生成场景中的灵活应用 对于新媒体运营和内容创作者而言,内容生成是核心工作之一。不同的…...

Photoshop到URP的法线验证闭环:跨引擎法线贴图精准调试指南
1. 这不是个“一键生成法线”的玩具,而是一套跨引擎、跨工作流的材质验证闭环你有没有遇到过这样的情况:在 Photoshop 里辛苦调出一张完美的 Normal Map,导入 Unity 后却发现高光方向反了、边缘发灰、贴图在 Decal 上拉伸变形,甚至…...

SAP 和 Legacy 系统之间的平面文件集成,GUI_DOWNLOAD 的实战设计
很多 SAP 项目里,系统集成并不总是从 API、RFC、OData 或 Event Mesh 开始。相当多的老系统仍然依赖一个最朴素的接口形态,固定格式的文本文件。财务共享平台要一份物料清单,仓储系统要一份当天新增物料,历史的生产执行系统只认 .txt 或 .csv,这时 ABAP 报表把 SAP 表里的…...

如何用elan终极解决Lean版本管理难题:完整开发者指南
如何用elan终极解决Lean版本管理难题:完整开发者指南 【免费下载链接】elan The Lean version manager 项目地址: https://gitcode.com/gh_mirrors/el/elan 在Lean定理证明器的开发过程中,你是否遇到过这样的困境:项目A需要Lean 4.0.0…...

Raw Accel深度解析:从零掌握Windows内核级鼠标加速的终极指南
Raw Accel深度解析:从零掌握Windows内核级鼠标加速的终极指南 【免费下载链接】rawaccel kernel mode mouse accel 项目地址: https://gitcode.com/gh_mirrors/ra/rawaccel 你是否厌倦了Windows默认鼠标加速的不稳定表现?是否在游戏中苦苦寻找更精…...