自然语言处理(六):词的相似性和类比任务
词的相似性和类比任务
在前面的章节中,我们在一个小的数据集上训练了一个word2vec模型,并使用它为一个输入词寻找语义相似的词。实际上,在大型语料库上预先训练的词向量可以应用于下游的自然语言处理任务,为了直观地演示大型语料库中预训练词向量的语义,让我们将预训练词向量应用到词的相似性和类比任务中。
文章内容来自李沐大神的《动手学深度学习》并加以我的理解,感兴趣可以去https://zh-v2.d2l.ai/查看完整书籍
文章目录
- 词的相似性和类比任务
- 加载预训练词向量
- 应用预训练词向量
- 词相似度
- 词类比
加载预训练词向量
以下列出维度为50、100和300的预训练GloVe嵌入,可从GloVe网站下载。预训练的fastText嵌入有多种语言。这里我们使用可以从fastText网站下载300维度的英文版本(“wiki.en”)。
import os
import torch
from torch import nn
from d2l import torch as d2l
#@save
d2l.DATA_HUB['glove.6b.50d'] = (d2l.DATA_URL + 'glove.6B.50d.zip','0b8703943ccdb6eb788e6f091b8946e82231bc4d')#@save
d2l.DATA_HUB['glove.6b.100d'] = (d2l.DATA_URL + 'glove.6B.100d.zip','cd43bfb07e44e6f27cbcc7bc9ae3d80284fdaf5a')#@save
d2l.DATA_HUB['glove.42b.300d'] = (d2l.DATA_URL + 'glove.42B.300d.zip','b5116e234e9eb9076672cfeabf5469f3eec904fa')#@save
d2l.DATA_HUB['wiki.en'] = (d2l.DATA_URL + 'wiki.en.zip','c1816da3821ae9f43899be655002f6c723e91b88')
为了加载这些预训练的GloVe和fastText嵌入,我们定义了以下TokenEmbedding类。
#@save
class TokenEmbedding:"""GloVe嵌入"""def __init__(self, embedding_name):self.idx_to_token, self.idx_to_vec = self._load_embedding(embedding_name)self.unknown_idx = 0self.token_to_idx = {token: idx for idx, token inenumerate(self.idx_to_token)}def _load_embedding(self, embedding_name):idx_to_token, idx_to_vec = ['<unk>'], []data_dir = d2l.download_extract(embedding_name)# GloVe网站:https://nlp.stanford.edu/projects/glove/# fastText网站:https://fasttext.cc/with open(os.path.join(data_dir, 'vec.txt'), 'r') as f:for line in f:elems = line.rstrip().split(' ')token, elems = elems[0], [float(elem) for elem in elems[1:]]# 跳过标题信息,例如fastText中的首行if len(elems) > 1:idx_to_token.append(token)idx_to_vec.append(elems)idx_to_vec = [[0] * len(idx_to_vec[0])] + idx_to_vecreturn idx_to_token, torch.tensor(idx_to_vec)def __getitem__(self, tokens):indices = [self.token_to_idx.get(token, self.unknown_idx)for token in tokens]vecs = self.idx_to_vec[torch.tensor(indices)]return vecsdef __len__(self):return len(self.idx_to_token)
下面我们加载50维GloVe嵌入(在维基百科的子集上预训练)。创建TokenEmbedding实例时,如果尚未下载指定的嵌入文件,则必须下载该文件。
glove_6b50d = TokenEmbedding('glove.6b.50d')
输出词表大小。词表包含400000个词(词元)和一个特殊的未知词元。
len(glove_6b50d)

我们可以得到词表中一个单词的索引,反之亦然。
glove_6b50d.token_to_idx['beautiful'], glove_6b50d.idx_to_token[3367]

应用预训练词向量
使用加载的GloVe向量,我们将通过下面的词相似性和类比任务中来展示词向量的语义。
词相似度
为了根据词向量之间的余弦相似性为输入词查找语义相似的词,我们实现了以下knn( k k k近邻)函数。
def knn(W, x, k):# 增加1e-9以获得数值稳定性cos = torch.mv(W, x.reshape(-1,)) / (torch.sqrt(torch.sum(W * W, axis=1) + 1e-9) *torch.sqrt((x * x).sum()))_, topk = torch.topk(cos, k=k)return topk, [cos[int(i)] for i in topk]
然后,我们使用TokenEmbedding的实例embed中预训练好的词向量来搜索相似的词。
def get_similar_tokens(query_token, k, embed):topk, cos = knn(embed.idx_to_vec, embed[[query_token]], k + 1)for i, c in zip(topk[1:], cos[1:]): # 排除输入词print(f'{embed.idx_to_token[int(i)]}:cosine相似度={float(c):.3f}')
glove_6b50d中预训练词向量的词表包含400000个词和一个特殊的未知词元。排除输入词和未知词元后,我们在词表中找到与“chip”一词语义最相似的三个词。
get_similar_tokens('chip', 3, glove_6b50d)

下面输出与“baby”和“beautiful”相似的词。
get_similar_tokens('baby', 3, glove_6b50d)

get_similar_tokens('beautiful', 3, glove_6b50d)

词类比
除了找到相似的词,我们还可以将词向量应用到词类比任务中。 例如,“man” : “woman” :: “son” : “daughter”是一个词的类比。 “man”是对“woman”的类比,“son”是对“daughter”的类比。 具体来说,词类比任务可以定义为: 对于单词类比 a : b : c : d a:b:c:d a:b:c:d,给出前三个词 a a a、 b b b和 c c c,找到 d d d。 用 v e c ( w ) vec(w) vec(w)表示词 w w w的向量, 为了完成这个类比,我们将找到一个词, 其向量与 v e c ( c ) + v e c ( b ) − v e c ( a ) vec(c)+vec(b)-vec(a) vec(c)+vec(b)−vec(a)的结果最相似。
def get_analogy(token_a, token_b, token_c, embed):vecs = embed[[token_a, token_b, token_c]]x = vecs[1] - vecs[0] + vecs[2]topk, cos = knn(embed.idx_to_vec, x, 1)return embed.idx_to_token[int(topk[0])] # 删除未知词
让我们使用加载的词向量来验证“male-female”类比。
get_analogy('man', 'woman', 'son', glove_6b50d)

下面完成一个“首都-国家”的类比: “beijing” : “china” :: “tokyo” : “japan”。 这说明了预训练词向量中的语义。
get_analogy('beijing', 'china', 'tokyo', glove_6b50d)

另外,对于“bad” : “worst” :: “big” : “biggest”等“形容词-形容词最高级”的比喻,预训练词向量可以捕捉到句法信息。
get_analogy('bad', 'worst', 'big', glove_6b50d)

为了演示在预训练词向量中捕捉到的过去式概念,我们可以使用“现在式-过去式”的类比来测试句法:“do” : “did” :: “go” : “went”。
get_analogy('do', 'did', 'go', glove_6b50d)

相关文章:
自然语言处理(六):词的相似性和类比任务
词的相似性和类比任务 在前面的章节中,我们在一个小的数据集上训练了一个word2vec模型,并使用它为一个输入词寻找语义相似的词。实际上,在大型语料库上预先训练的词向量可以应用于下游的自然语言处理任务,为了直观地演示大型语料…...

安防监控视频平台EasyCVR视频汇聚平台定制项目增加AI智能算法详细介绍
安防视频集中存储EasyCVR视频汇聚平台,可支持海量视频的轻量化接入与汇聚管理。平台能提供视频存储磁盘阵列、视频监控直播、视频轮播、视频录像、云存储、回放与检索、智能告警、服务器集群、语音对讲、云台控制、电子地图、平台级联、H.265自动转码等功能。为了便…...

VB个人邮件处理系统设计与实现
简述 当今世界电子邮件已经是网络生活中不可或缺的,相信每个认知网络的人都会有一个或多个自己的电子邮箱,人们通过电子邮件进行通信和交流,许多商家和组织机构也用电子邮件进行各种商业活动和业务联系,毫无疑问,电子邮件已经逐渐开始取代普通的信件,成为为主流的信件交流…...
第一章辩证唯物论,考点七思维导图
逻辑框架 考点七思维导图:...
)
Python入门教程 - 基本函数(四)
目录 一、什么是函数 二、自定义函数并使用它 一、什么是函数 前面我们学习了像input()、print()、type()等等,他们都是函数。这些其实是由Python内部帮我们定义好的。我们直接用就可以了。 关于函数,除了用内部定义好的,我们也可以自己定…...
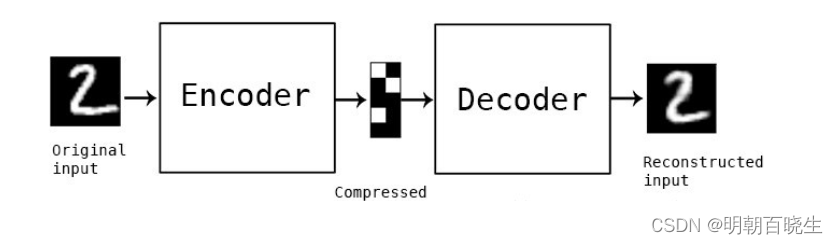
[PyTorch][chapter 53][Auto Encoder 实战]
前言: 结合手写数字识别的例子,实现以下AutoEncoder ae.py: 实现autoEncoder 网络 main.py: 加载手写数字数据集,以及训练,验证,测试网络。 左图:原图像 右图:重构图像 ----main----- 每轮训…...

Springboot常用方法参数注解及示例
文章目录 Springboot常用方法参数注解及示例一、RequestParam: 从URL查询参数中提取数据。二、PathVariable: 从URL路径中提取数据。三、RequestBody: 从请求体中提取数据,并映射到对象。四、RequestHeader: 从请求头中…...
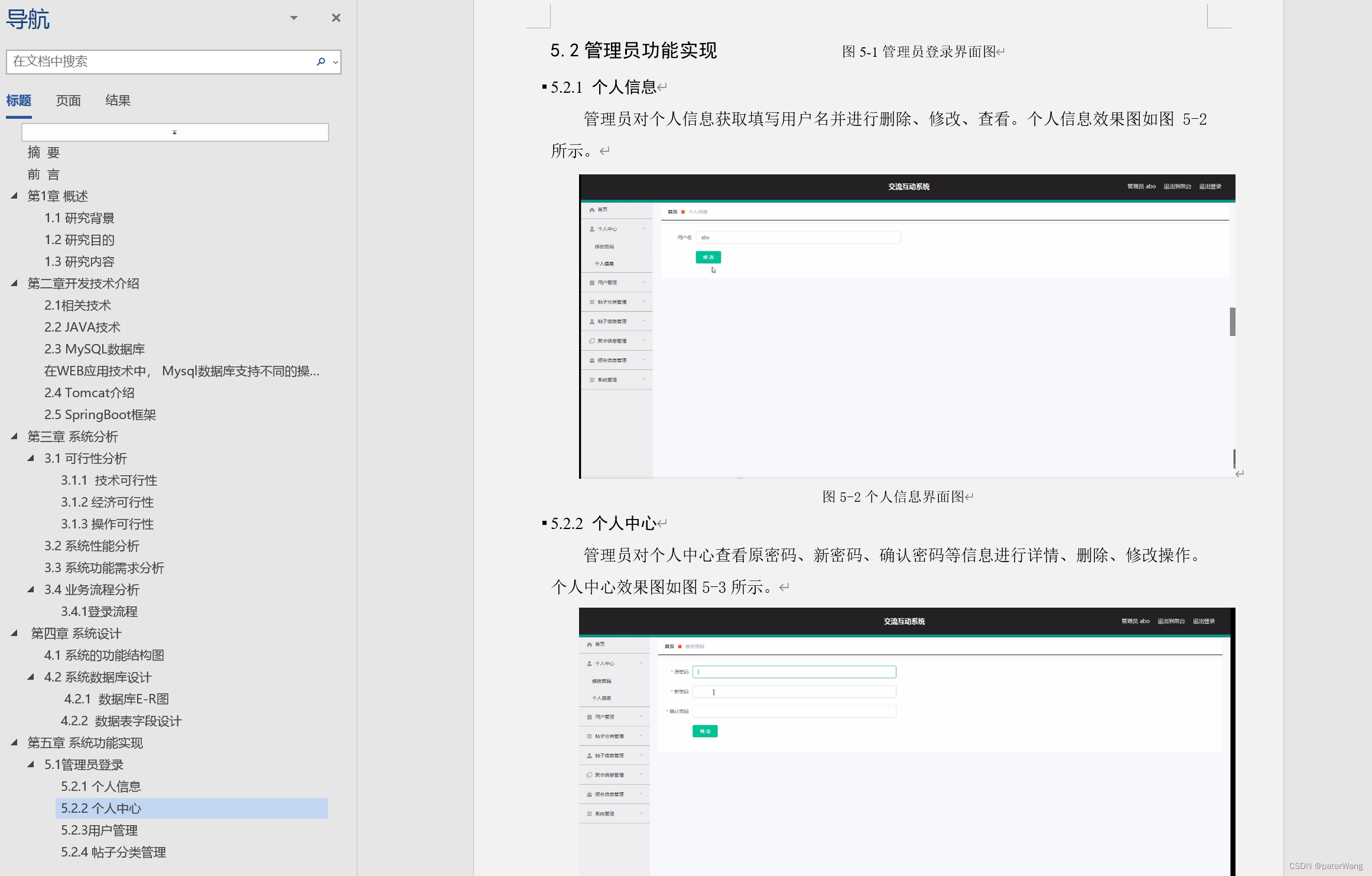
基于java+springboot+vue的交流互动系统-lw
系统介绍: 随着现在网络的快速发展,网上管理系统也逐渐快速发展起来,网上管理模式很快融入到了许多企业的之中,随之就产生了“交流互动系统”,这样就让交流互动系统更加方便简单。 对于本交流互动系统的设计来说&a…...

使用candump+grep查看CAN报文
在Linux系统中观察看CAN报文,我们一般使用candump,但是有时候会发现总线上CAN报文太多,例如开启了好几个PDO,这就导致想看的报文被夹杂到报文的海洋里,然后再去找,非常麻烦。 candump也提供了只观察某个报…...

Vue中el-table表格的拖拽排序
el-table实现拖拽 element-ui 表格没有拖拽排序的功能,只能使用sortable.js插件实现拖拽排序,当然也可以应用到其他的组件里面,用法类似,这里只说表格。 实现步骤: 1、安装sortable.js npm install sortablejs --s…...
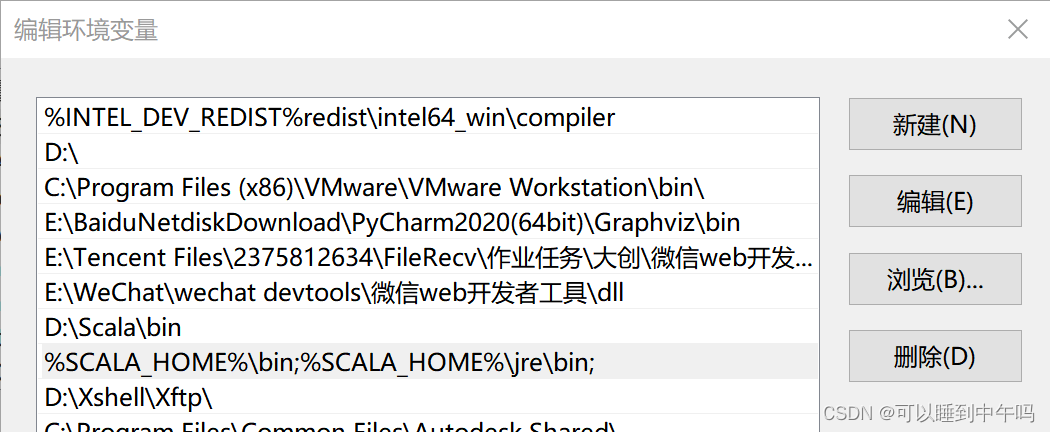
配置环境变量的作用
配置环境变量的作用 一般运行过程:寻找QQ.exe所在的目录,输入QQ.exe配置环境变量:把QQ所在的路径配给操作系统Path, 在任何路径下都能运行QQ.exe 举例: 定义变量:SCALA_HOME SCALA_HOME、JAVA_HOME 等这…...
Mysql的page,索引,Explain Type等基本常识
Mysql的基本问题 Mysql 为什么建议使用自增id? 因为id(主键)是自增的话,那么在有序的保存用户数据到页中的时候,可以天然的保存,并且是在聚集索引(id)中的叶子节点可以很好的减少插…...

【业务功能篇95】web中的重定向与转发
web接口的返回值: 转发: return “/reg” 跳转到reg的html页面 重定向 return “redirect:/login.html” 重定向重新发起请求路径是 login.html 比如我们写的接口 requestmap("/login.html")的的这个请求地址,重新请求 …...

IP对讲终端SV-6005带一路2×15W或1*30W立体声做广播使用
IP对讲终端SV-6005双按键是一款采用了ARMDSP架构,接收网络音频流,实时解码播放;配置了麦克风输入和扬声器输出,SV-6005带两路寻呼按键,可实现对讲、广播等功能,作为网络数字广播的播放终端,主要…...
ES6 新特性
🎄欢迎来到边境矢梦的csdn博文🎄 🎄本文主要梳理前端技术的JavaScript的知识点ES6 新特性文件上传下载🎄 🌈我是边境矢梦,一个正在为秋招和算法竞赛做准备的学生🌈 🎆喜欢的朋友可以…...

grafana用lark发告警python3接口
1.先在lark群聊里面创建机器人,并获取机器人链接。 2.后台运行下面python3脚本。 3.在grafana添加告警通道,设置告警。 # !/usr/bin/env python # _*_ coding: utf-8 _*_from flask import Flask, request,jsonify #import smtplib #from email.mime.te…...
Java 中数据结构HashSet的用法
Java HashSet HashSet 基于 HashMap 来实现的,是一个不允许有重复元素的集合。 HashSet 允许有 null 值。 HashSet 是无序的,即不会记录插入的顺序。 HashSet 不是线程安全的, 如果多个线程尝试同时修改 HashSet,则最终结果是…...

vue3下的密码输入框(antdesignvue)
参考:vue下的密码输入框 注意:这是个半成品,有些问题(input输入框加了文字间距letter-spaceing,会导致输入到第6位的时候会往后窜出来一个空白框、光标位置页会在数字前面),建议不采用下面这种方式,用另外的(画六个input框更方便) 效果预览 实现思路 制作6个小的正方…...
鸿鹄企业工程项目管理系统 Spring Cloud+Spring Boot+前后端分离构建工程项目管理系统源代码
鸿鹄工程项目管理系统 Spring CloudSpring BootMybatisVueElementUI前后端分离构建工程项目管理系统 1. 项目背景 一、随着公司的快速发展,企业人员和经营规模不断壮大。为了提高工程管理效率、减轻劳动强度、提高信息处理速度和准确性,公司对内部工程管…...
【爬虫】5.5 Selenium 爬取Ajax网页数据
目录 AJAX 简介 任务目标 创建Ajax网站 创建服务器程序 编写爬虫程序 AJAX 简介 AJAX(Asynchronous JavaScript And XML,异步 JavaScript 及 XML) Asynchronous 一种创建交互式、快速动态网页应用的网页开发技术通过在后台与服务器进行…...

如何用Poppins解决多语言字体兼容性难题:从实战应用到技术架构
如何用Poppins解决多语言字体兼容性难题:从实战应用到技术架构 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 当你的产品需要同时支持拉丁文和天城体文字时&#x…...

211本科985硕拿下淘天AI二面!全程无代码,这面试题火了!
本文分享了作者在淘天AI应用开发二面中的面试经历,全程不到60分钟,没有手撕代码,也没有问常规Java八股。面试主要围绕自我介绍、AI相关问题、工程与安全问题、项目提问以及反问环节展开。AI相关问题涉及对AI的看法、常用AI工具等;…...

Python之streamjam包语法、参数和实际应用案例
Python StreamJam 包完整使用指南 一、StreamJam 包核心概述 StreamJam 是 Python 中一款轻量级、高性能的流式数据处理工具包,专为实时数据流、增量数据处理、管道式数据转换、异步/同步流处理设计,核心定位是替代复杂的大数据框架(如Spark、…...

基于DSP与SC1083 ADC的光纤远程数据采集系统设计实战
1. 项目概述:当DSP遇上高速光缆,如何构建一个“快、准、稳”的远程数据采集系统在工业自动化、电力监测、超声无损检测这些领域,我们经常需要面对一个头疼的问题:如何把现场传感器采集到的大量、高速、有时甚至是微弱的模拟信号&a…...

达梦数据库-收缩数据库表空间步骤及示例记录总结
1达梦数据库-收缩数据库表空间步骤及示例记录总结 注:收缩表空间,如果空闲空间都在尾部,可以直接收缩成功,如果尾部不空闲,中部空闲,则需要移走使用尾部的表后再收缩,生产环境,如果…...

Boss-Key终极指南:一键隐藏窗口保护办公隐私的完整解决方案
Boss-Key终极指南:一键隐藏窗口保护办公隐私的完整解决方案 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 你是否曾在办公室里…...

【本地大模型】告别网络延迟与数据泄露:为什么测试团队需要本地部署大模型?
导语 AI辅助测试已经从“锦上添花”变成了“基础设施”。越来越多的测试团队在日常工作中依赖大语言模型生成测试用例、分析缺陷日志、编写自动化脚本。然而,当你的测试用例描述中包含生产环境的接口参数,当你把核心业务逻辑输入云端对话框时——你真的清楚这些数据去向何方…...

PDF补丁丁完全指南:免费开源PDF工具箱的7个高效使用技巧
PDF补丁丁完全指南:免费开源PDF工具箱的7个高效使用技巧 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https://…...

独立开发者如何借助Taotoken低成本试验多种大模型效果
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何借助Taotoken低成本试验多种大模型效果 对于独立开发者或小微团队而言,在创意验证或产品原型阶段&#…...

EXCEL文件展示MLP的计算过程
MLP 实现步骤(共 5 步) 步骤 1:输入层数据准备 在表格中输入两个特征值 x1、x2,作为 MLP 的输入。本次使用:x10.5,x20.8步骤 2:设置网络参数(权重 偏置) 手动设置输入层…...