深入探讨梯度下降:优化机器学习的关键步骤(二)
文章目录
- 🍀引言
- 🍀eta参数的调节
- 🍀sklearn中的梯度下降
🍀引言
承接上篇,这篇主要有两个重点,一个是eta参数的调解;一个是在sklearn中实现梯度下降
在梯度下降算法中,学习率(通常用符号η表示,也称为步长或学习速率)的选择非常重要,因为它直接影响了算法的性能和收敛速度。学习率控制了每次迭代中模型参数更新的幅度。以下是学习率(η)的重要性:
-
收敛速度:学习率决定了模型在每次迭代中移动多远。如果学习率过大,模型可能会在参数空间中来回摇摆,导致不稳定的收敛或甚至发散。如果学习率过小,模型将收敛得很慢,需要更多的迭代次数才能达到最优解。因此,选择合适的学习率可以加速收敛速度。
-
稳定性:过大的学习率可能会导致梯度下降算法不稳定,甚至无法收敛。过小的学习率可以使算法更加稳定,但可能需要更多的迭代次数才能达到最优解。因此,合适的学习率可以在稳定性和收敛速度之间取得平衡。
-
避免局部最小值:选择不同的学习率可能会导致模型陷入不同的局部最小值。通过尝试不同的学习率,您可以更有可能找到全局最小值,而不是被困在局部最小值中。
-
调优:学习率通常需要调优。您可以尝试不同的学习率值,并监视损失函数的收敛情况。通常,您可以使用学习率衰减策略,逐渐降低学习率以改善收敛性能。
-
批量大小:学习率的选择也与批量大小有关。通常,小批量梯度下降(Mini-batch Gradient Descent)使用比大批量梯度下降更大的学习率,因为小批量可以提供更稳定的梯度估计。
总之,学习率是梯度下降算法中的关键超参数之一,它需要仔细选择和调整,以在训练过程中实现最佳性能和收敛性。不同的问题和数据集可能需要不同的学习率,因此在实践中,通常需要进行实验和调优来找到最佳的学习率值。
🍀eta参数的调节
在上代码前我们需要知道,如果eta的值过小会造成什么样的结果
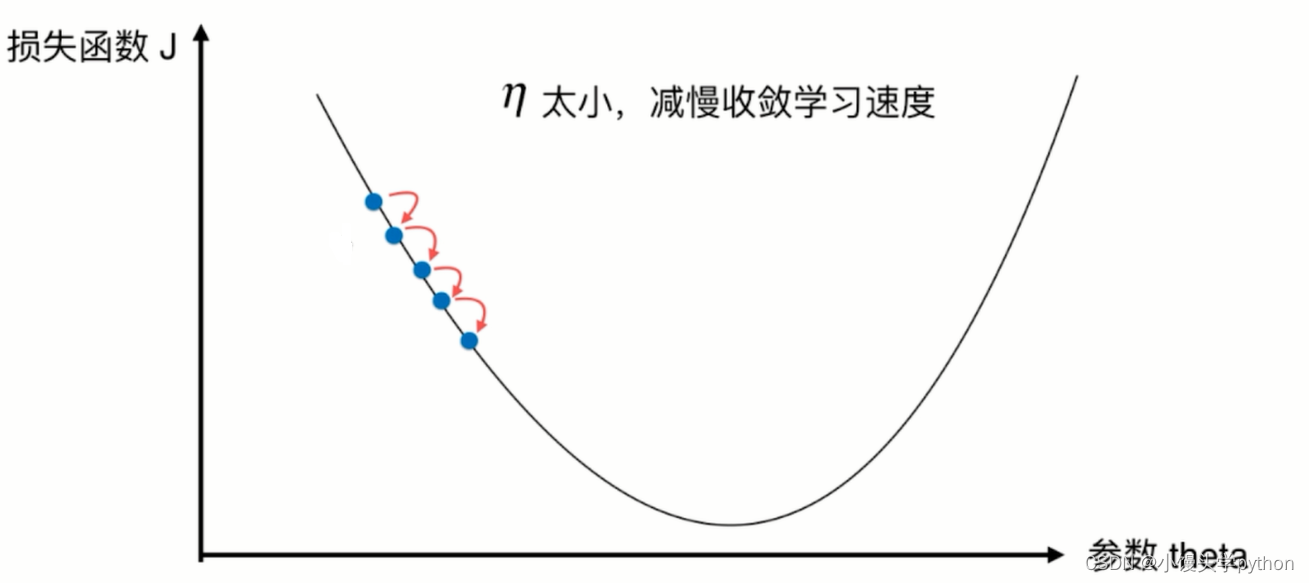
反之如果过大呢
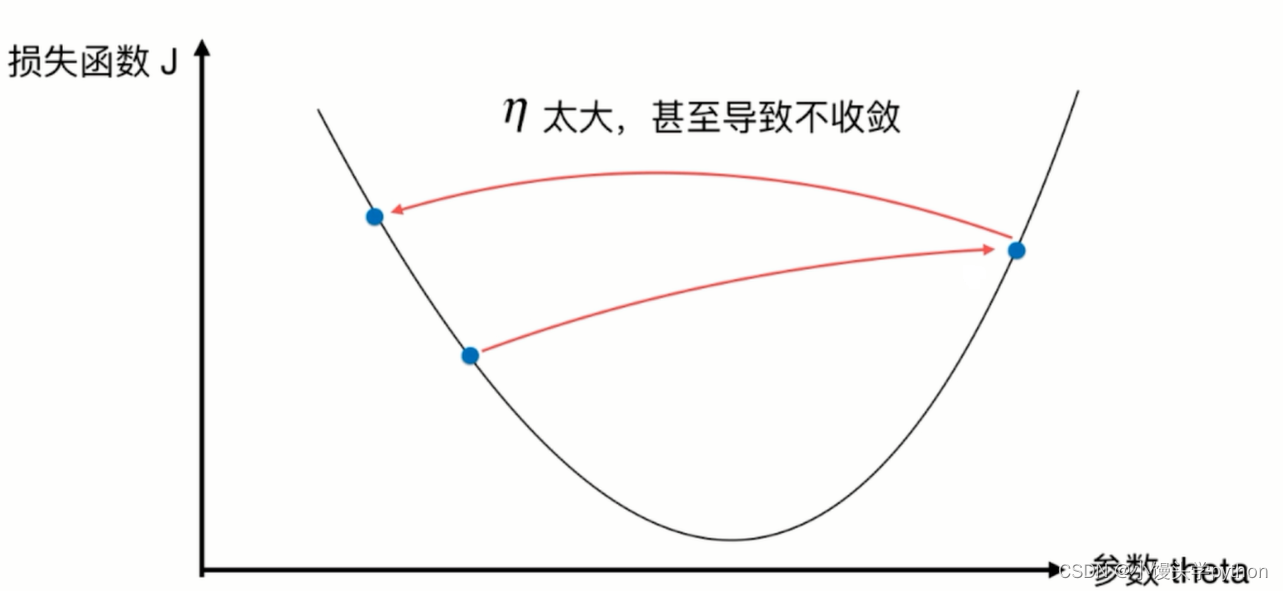
可见,eta过大过小都会影响效率,所以一个合适的eta对于寻找最优有着至关重要的作用
在上篇的学习中我们已经初步完成的代码,这篇我们将其封装一下
首先需要定义两个函数,一个用来返回thera的历史列表,一个则将其绘制出来
def gradient_descent(eta,initial_theta,epsilon = 1e-8):theta = initial_thetatheta_history = [initial_theta]def dj(theta): return 2*(theta-2.5) # 传入theta,求theta点对应的导数def j(theta):return (theta-2.5)**2-1 # 传入theta,获得目标函数的对应值while True:gradient = dj(theta)last_theta = thetatheta = theta-gradient*eta theta_history.append(theta)if np.abs(j(theta)-j(last_theta))<epsilon:breakreturn theta_historydef plot_gradient(theta_history):plt.plot(plt_x,plt_y)plt.plot(theta_history,[(i-2.5)**2-1 for i in theta_history],color='r',marker='+')plt.show()
其实就是上篇代码的整合罢了
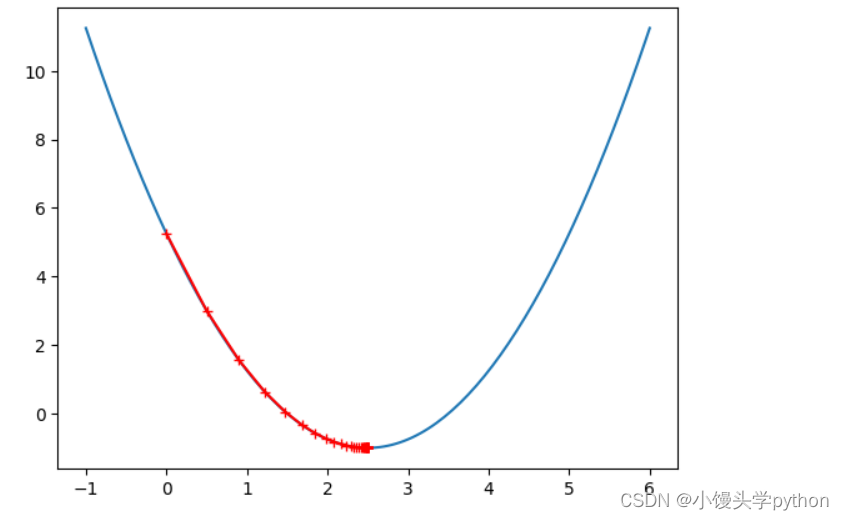
之后我们需要进行简单的调参了,这里我们分别采用0.1、0.01、0.9,这三个参数进行调节
eta = 0.1
theta =0.0
plot_gradient(gradient_descent(eta,theta))
len(theta_history)
运行结果如下
eta = 0.01
theta =0.0
plot_gradient(gradient_descent(eta,theta))
len(theta_history)
运行结果如下

eta = 0.9
theta =0.0
plot_gradient(gradient_descent(eta,theta))
len(theta_history)
运行结果如下
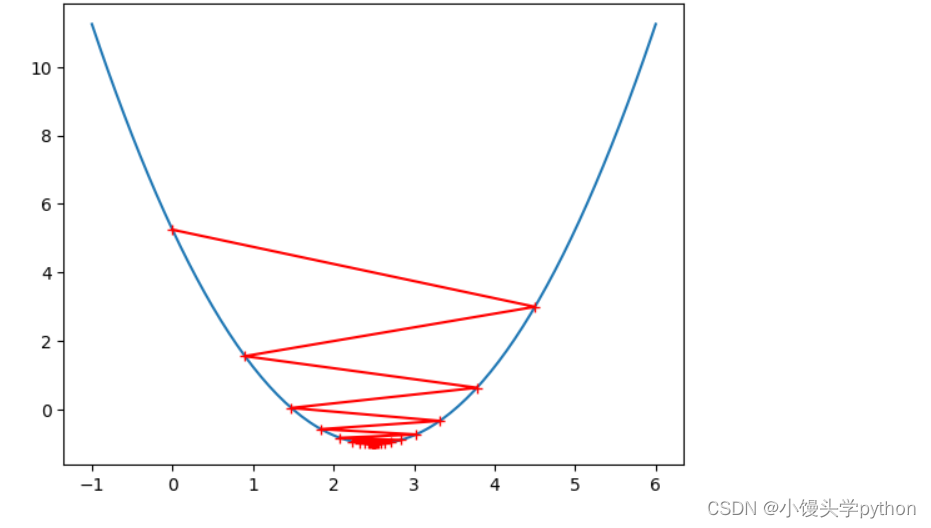
这三张图与之前的提示很像吧,可见调参的重要性
如果我们将eta改为1.0呢,那么会发生什么
eta = 1.0
theta =0.0
plot_gradient(gradient_descent(eta,theta))
len(theta_history)
运行结果如下
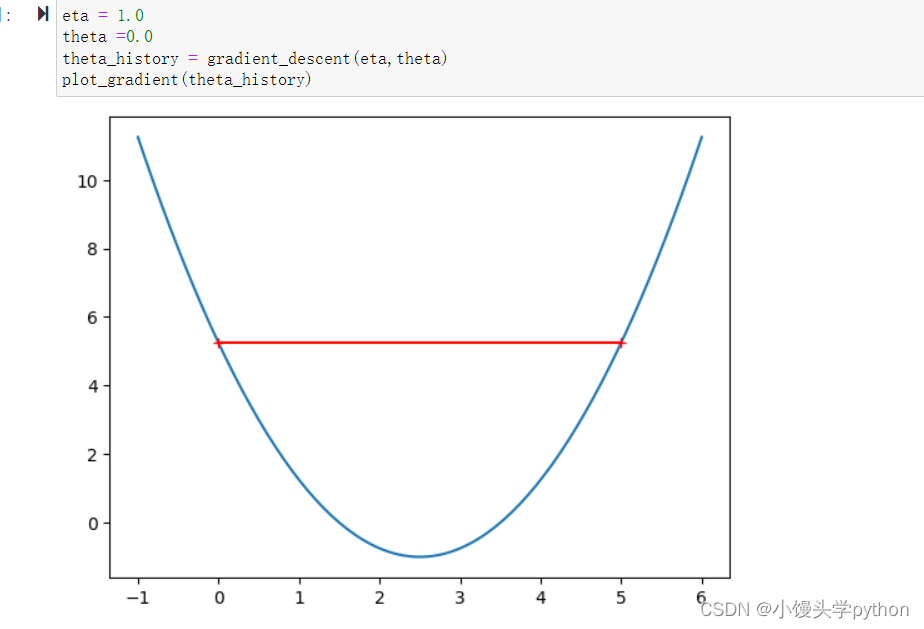
那改为1.1呢
eta = 1.1
theta =0.0
plot_gradient(gradient_descent(eta,theta))
len(theta_history)
运行结果如下
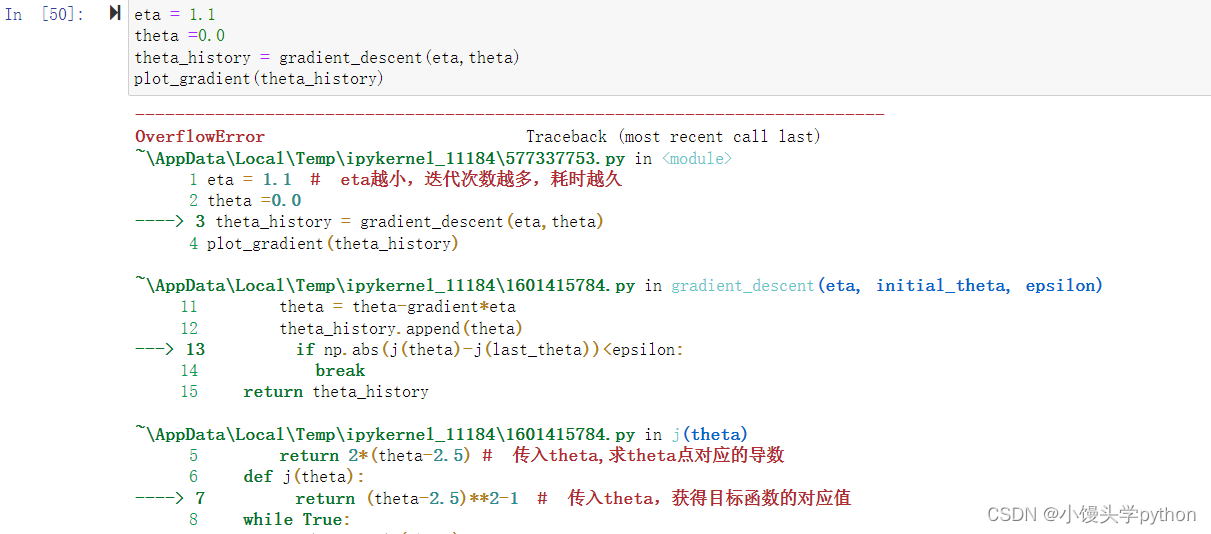
我们从图可以清楚的看到,当eta为1.1的时候是嗷嗷增大的,这种情况我们需要采用异常处理来限制一下,避免报错,处理的方式是限制循环的最大值,且可以在expect中设置inf(正无穷)
def gradient_descent(eta,initial_theta,n_iters=1e3,epsilon = 1e-8):theta = initial_thetatheta_history = [initial_theta]i_iter = 1def dj(theta): try:return 2*(theta-2.5) # 传入theta,求theta点对应的导数except:return float('inf')def j(theta):return (theta-2.5)**2-1 # 传入theta,获得目标函数的对应值while i_iter<=n_iters:gradient = dj(theta)last_theta = thetatheta = theta-gradient*eta theta_history.append(theta)if np.abs(j(theta)-j(last_theta))<epsilon:breaki_iter+=1return theta_historydef plot_gradient(theta_history):plt.plot(plt_x,plt_y)plt.plot(theta_history,[(i-2.5)**2-1 for i in theta_history],color='r',marker='+')plt.show()
注意:inf表示正无穷大
🍀sklearn中的梯度下降
这里我们还是以波士顿房价为例子
首先导入需要的库
from sklearn.datasets import load_boston
from sklearn.linear_model import SGDRegressor
之后取一部分的数据
boston = load_boston()
X = boston.data
y = boston.target
X = X[y<50]
y = y[y<50]
然后进行数据归一化
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,y)
std = StandardScaler()
std.fit(X_train)
X_train_std=std.transform(X_train)
X_test_std=std.transform(X_test)
sgd_reg = SGDRegressor()
sgd_reg.fit(X_train_std,y_train)
最后取得score
sgd_reg.score(X_test_std,y_test)
运行结果如下


挑战与创造都是很痛苦的,但是很充实。
相关文章:
深入探讨梯度下降:优化机器学习的关键步骤(二)
文章目录 🍀引言🍀eta参数的调节🍀sklearn中的梯度下降 🍀引言 承接上篇,这篇主要有两个重点,一个是eta参数的调解;一个是在sklearn中实现梯度下降 在梯度下降算法中,学习率…...

高频算法面试题
合并两个有序数组 const merge (nums1, nums2) > {let p1 0;let p2 0;const result [];let cur;while (p1 < nums1.length || p2 < nums2.length) {if (p1 nums1.length) {cur nums2[p2];} else if (p2 nums2.length) {cur nums1[p1];} else if (nums1[p1] &…...
Hive-启动与操作(2)
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 个人主页:beixi 本文章收录于专栏(点击传送):【大数据学习】 💓💓持续更新中,感谢各位前辈朋友们支持…...

css transition 指南
css transition 指南 在本文中,我们将深入了解 CSS transition,以及如何使用它们来创建丰富、精美的动画。 基本原理 我们创建动画时通常需要一些动画相关的 CSS。 下面是一个按钮在悬停时移动但没有动画的示例: <button class"…...

LeetCode 面试题 02.05. 链表求和
文章目录 一、题目二、C# 题解 一、题目 给定两个用链表表示的整数,每个节点包含一个数位。 这些数位是反向存放的,也就是个位排在链表首部。 编写函数对这两个整数求和,并用链表形式返回结果。 点击此处跳转题目。 示例: 输入&a…...

一米脸书营销软件
功能优势 JOIN ADVANTAGE HOME PAGE MARKETING 公共主页营销 可同时对多个账户公共主页评论,点赞等 可批量邀请多个好友对Facebook公共主页进行评论点赞等,也可批量登录小号对自己公共主页进行点赞。 GROUP MARKETING 小组营销 可批量针对不同账户进行…...
vue 根据数值判断颜色
1.首先style样式给两种颜色 用:class 三元运算符判断出一种颜色 第一步:在style里边设置两种颜色 .green{color: green; } .orange{color: orangered; }在取数据的标签 里边 判断一种颜色 :class"item.quote.current >0 ?orange: green"<van-gri…...

Hugging Face 实战系列 总目录
PyTorch 深度学习 开发环境搭建 全教程 Transformer:《Attention is all you need》 Hugging Face简介 1、Hugging Face实战-系列教程1:Tokenizer分词器(Transformer工具包/自然语言处理) Hungging Face实战-系列教程1:Tokenize…...
国标视频云服务EasyGBS国标视频平台迁移服务器后无法启动的问题解决方法
国标视频云服务EasyGBS支持设备/平台通过国标GB28181协议注册接入,并能实现视频的实时监控直播、录像、检索与回看、语音对讲、云存储、告警、平台级联等功能。平台部署简单、可拓展性强,支持将接入的视频流进行全终端、全平台分发,分发的视频…...

HTML <th> 标签
实例 普通的 HTML 表格,包含两行两列: <table border="1"><tr><th>Company</th><th>Address</th></tr><tr><td>Apple, Inc.</td><td>1 Infinite Loop Cupertino, CA 95014</td></tr…...

HTTP/1.1协议中的响应报文
2023年8月30日,周三下午 目录 概述响应报文示例详述 概述 HTTP/1.1协议的响应报文由以下几个部分组成: 状态行(Status Line)响应头部(Response Headers)空行(Blank Line)响应体&a…...

TDengine函数大全-选择函数
以下内容来自 TDengine 官方文档 及 GitHub 内容 。 以下所有示例基于 TDengine 3.1.0.3 TDengine函数大全 1.数学函数 2.字符串函数 3.转换函数 4.时间和日期函数 5.聚合函数 6.选择函数 7.时序数据库特有函数 8.系统函数 选择函数 TDengine函数大全BOTTOMFIRSTINTERPLASTLAS…...

非关系型数据库Redis的安装
一、关系型数据库与非关系型数据库的区别:---------面试高频率问题 1、首先了解一下 什么是关系型数据库? 关系型数据库最典型的数据结构是表,由二维表及其之间的联系所组成的一个数据组织。 优点: 易于维护:都是使用…...

oracle 创建数据库
查询表空间的命令 select t1.name,t2.name from v$tablespace t1,v$datafile t2 where t1.ts# t2.ts#; CREATE TABLESPACE ORM_342_BETA DATAFILE /app/oracle/oradata/sysware/ORM_342_BETA.DBF size 800M --存储地址 初始大小800M autoextend on nex…...
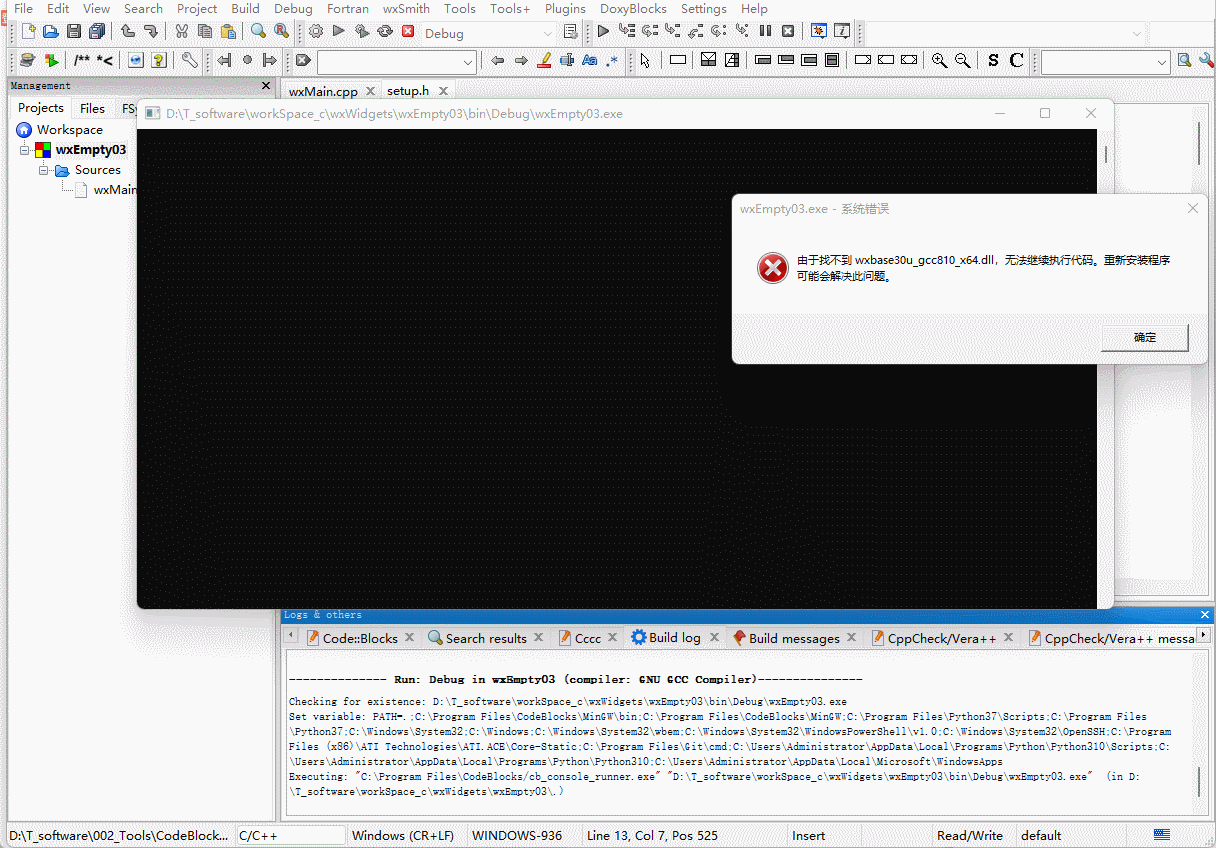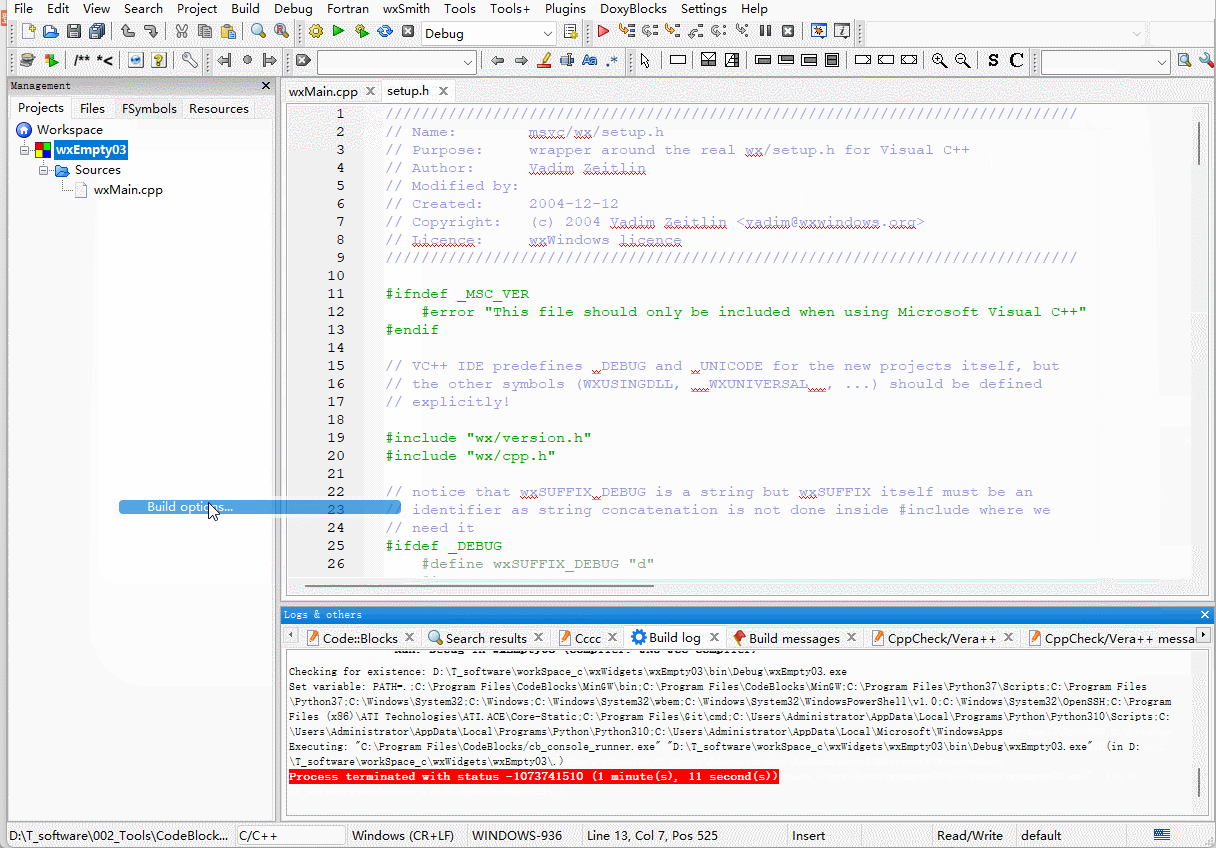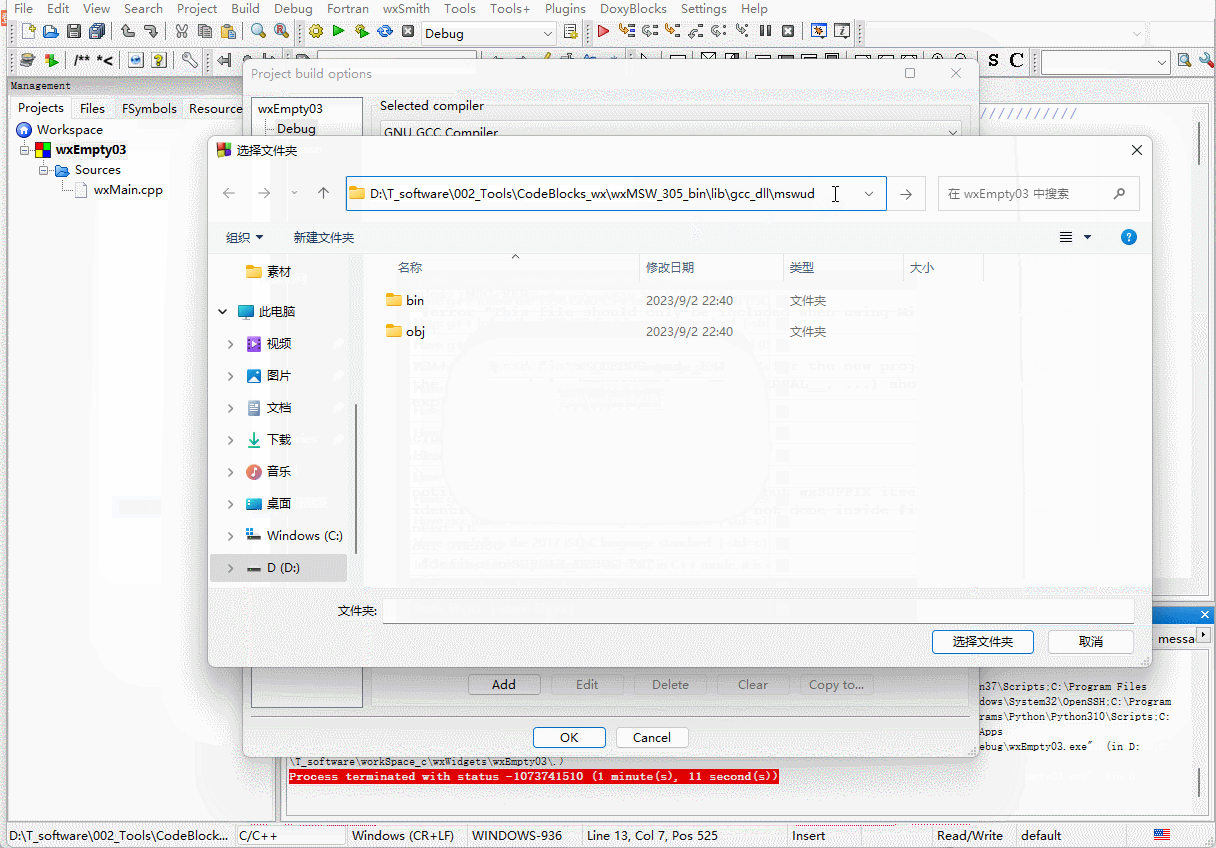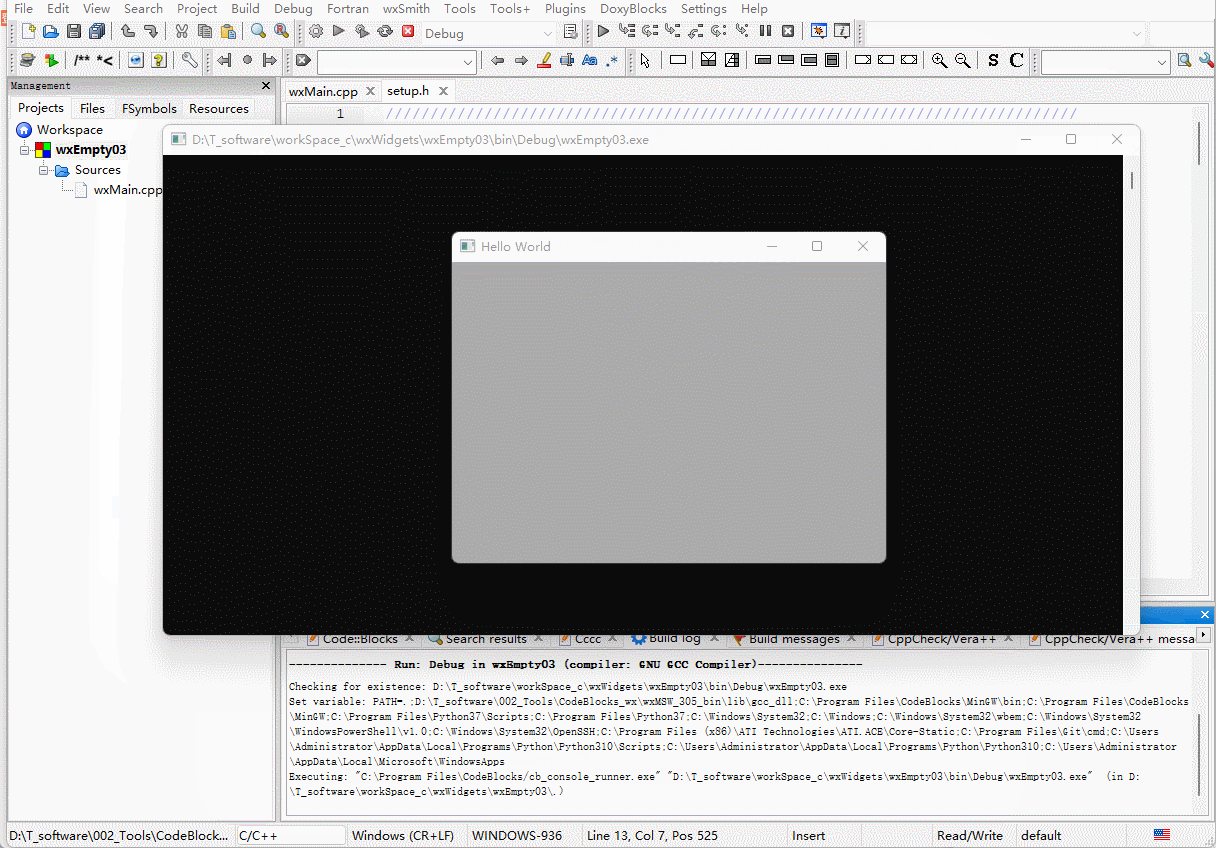
wxWidgets从空项目开始Hello World
前文回顾 接上篇,已经是在CodeBlocks20.03配置了wxWidgets3.0.5,并且能够通过项目创建导航创建一个新的工程,并且成功运行。 那么上一个是通过CodeBlocks的模板创建的,一进去就已经是2个头文件2个cpp文件,总是感觉缺…...
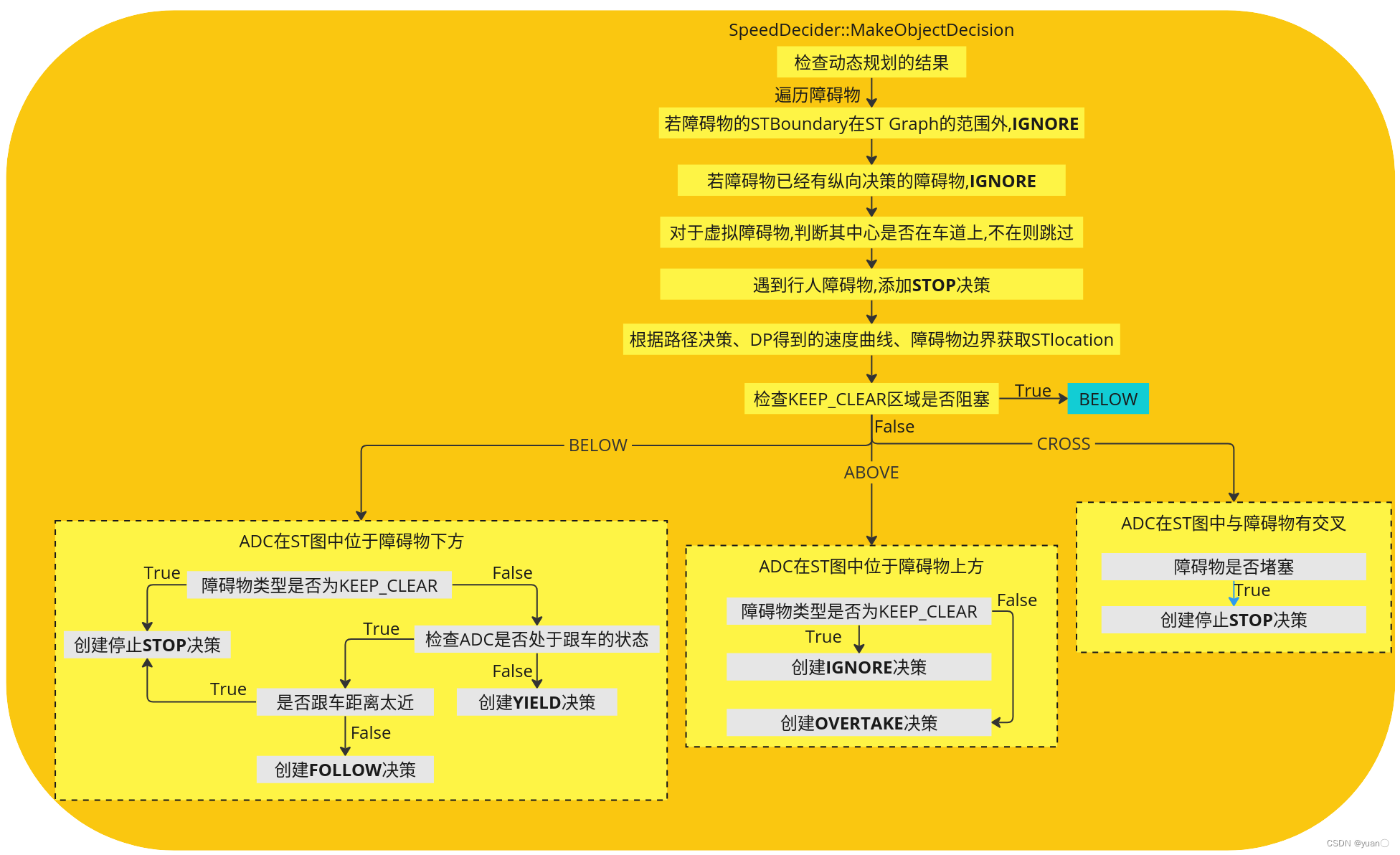
【Apollo学习笔记】——规划模块TASK之SPEED_DECIDER
文章目录 前言SPEED_DECIDER功能简介SPEED_DECIDER相关配置SPEED_DECIDER流程MakeObjectDecisionGetSTLocationCheck类函数CheckKeepClearCrossableCheckStopForPedestrianCheckIsFollowCheckKeepClearBlocked Create类函数 前言 在Apollo星火计划学习笔记——Apollo路径规划算…...
【操作系统】一文快速入门,很适合JAVA后端看
作者简介: 目录 1.概述 2.CPU管理 3.内存管理 4.IO管理 1.概述 操作系统可以看作一个计算机的管理系统,对计算机的硬件资源提供了一套完整的管理解决方案。计算机的硬件组成有五大模块:运算器、控制器、存储器、输入设备、输出设备。操作…...

C++ Primer阅读笔记--allocator类的使用
1--allocator类的使用背景 new 在分配内存时具有一定的局限性,其将内存分配和对象构造组合在一起;当分配一大块内存时,一般希望可以在内存上按需构造对象,这时需要将内存分配和对象构造分离,而定义在头文件 memory 的 …...
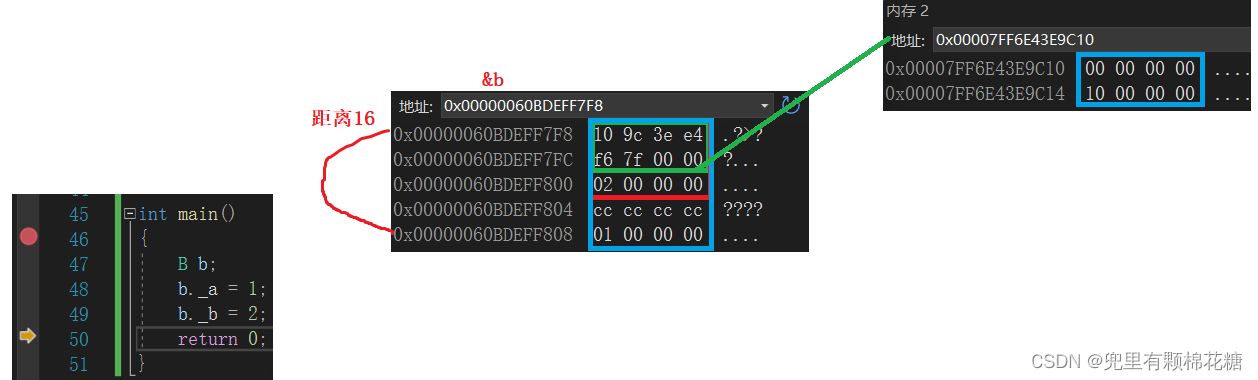
【C++历险记】面向对象|菱形继承及菱形虚拟继承
个人主页:兜里有颗棉花糖💪 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 兜里有颗棉花糖 原创 收录于专栏【C之路】💌 本专栏旨在记录C的学习路线,望对大家有所帮助🙇 希望我们一起努力、成长&…...
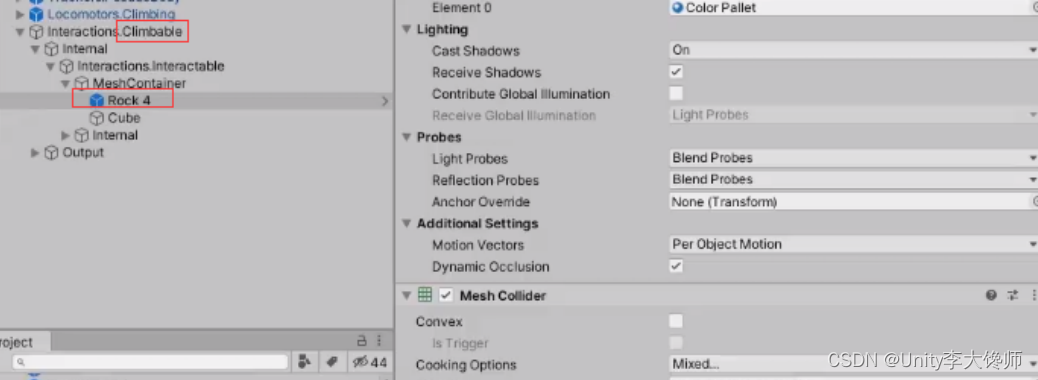
【Locomotor运动模块】攀爬
文章目录 一、攀爬主体“伪身体”1、“伪身体”的设置2、“伪身体”和“真实身体”,为什么同步移动3、“伪身体”和“真实身体”,碰到墙时不同步的原因①现象②原因③解决 二、攀爬1、需要的组件:“伪身体”、Climbing、Climbable及Interacto…...

终极指南:SVGnest如何实现材料利用率提升40%
终极指南:SVGnest如何实现材料利用率提升40% 【免费下载链接】SVGnest An open source vector nesting tool 项目地址: https://gitcode.com/gh_mirrors/sv/SVGnest SVGnest是一款完全免费开源的矢量嵌套工具,专为激光切割、CNC加工和工业设计领域…...

终极指南:如何在3DS上原生运行GBA游戏,告别模拟器卡顿
终极指南:如何在3DS上原生运行GBA游戏,告别模拟器卡顿 【免费下载链接】open_agb_firm open_agb_firm is a bare metal app for running GBA homebrew/games using the 3DS builtin GBA hardware. 项目地址: https://gitcode.com/gh_mirrors/op/open_a…...

技术革新:FModel如何重塑游戏资源逆向工程与创作流程
技术革新:FModel如何重塑游戏资源逆向工程与创作流程 【免费下载链接】FModel Unreal Engine Archives Explorer 项目地址: https://gitcode.com/gh_mirrors/fm/FModel 在游戏开发与内容创作的生态系统中,资源逆向工程长期以来都是一项技术壁垒高…...

为内部知识库问答系统集成稳定的多模型推理能力
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为内部知识库问答系统集成稳定的多模型推理能力 在企业内部,知识库是宝贵的资产,但如何让员工高效地从中获…...

MAXREFDES16 Fresno:工业物联网传感器节点的全栈开发实战
1. 项目概述:从一颗芯片到一个完整的工业物联网节点 如果你在工业自动化、楼宇控制或者环境监测领域工作,一定对“传感器节点”这个概念不陌生。它就像一个前线的侦察兵,负责采集温度、压力、流量、振动等物理世界的信号,然后通过…...

Keil MDK中Flash算法RAM配置的DWORD对齐问题解析
1. 问题现象与背景解析当使用Keil MDK开发环境配合J-LINK或ULINK系列调试器时,在Flash Download配置选项卡中设置Flash算法RAM大小时,可能会遇到"Invalid Number Error: Number must be DWORD Aligned"的错误提示。这个错误通常发生在以下场景…...

Skelerealms:Godot开放世界的数据驱动架构解析
1. 这不是又一个“Godot RPG模板”,而是一套为开放世界量身定制的底层骨架我第一次在GitHub上看到Skelerealms这个仓库时,没点开README就直接关掉了——标题里带“RPG框架”“Godot”“开放世界”的项目,过去三年我至少扫过四十七个ÿ…...

解锁音乐边界:Windows平台下网易云音乐NCM文件格式转换解决方案
解锁音乐边界:Windows平台下网易云音乐NCM文件格式转换解决方案 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 在数字音乐消费日益普及的今天&…...
)
从炼丹炉到生产线:在Linux服务器上为Stable Diffusion部署配置PyTorch环境(驱动+CUDA+Anaconda实战)
从炼丹炉到生产线:Linux服务器部署PyTorch环境全流程指南 引言:为什么需要专业化的AI开发环境? 在AI模型开发领域,我们常常把训练模型比作"炼丹"——需要精准控制各种"火候"参数。而要让这个"炼丹炉&quo…...

RT-Thread全局中断操作:原理、应用与低功耗设计关键
1. 项目概述:为什么需要深入理解全局中断操作?刚接触RT-Thread这类实时操作系统时,很多朋友都会对“全局中断”这个概念感到困惑。尤其是在看到代码里频繁出现的rt_hw_interrupt_disable()和rt_hw_interrupt_enable()这对函数时,心…...