基于springboot跟redis实现的排行榜功能(实战)
概述
前段时间,做了一个世界杯竞猜积分排行榜。对世界杯64场球赛胜负平进行猜测,猜对+1分,错误+0分,一人一场只能猜一次。 1.展示前一百名列表。 2.展示个人排名(如:张三,您当前的排名106579)。 一.redis sorts sets简介 Sorted Sets数据类型就像是set和hash的混合。与sets一样,Sorted Sets是唯一的,不重复的字符串组成。可以说Sorted Sets也是Sets的一种。 Sorted Sets是通过Skip List(跳跃表)和hash Table(哈希表)的双端口数据结构实现的,因此每次添加元素时,Redis都会执行O(log(N))操作。所以当我们要求排序的时候,Redis根本不需要做任何工作了,早已经全部排好序了。元素的分数可以随时更新。 二.springboot 中使用RedisTemplate 本文主要通过redisTemplate来操作redis,当然也可以使用redis-client,看个人喜好.
详细
详细
一、运行效果

分析
一开始打算直接使用mysql数据库来做,遇到一个问题,每个人的分数都会变化,如何能够获取到个人的排名呢?数据库可以通过分数进行row_num排序,但是这个方法需要进行全表扫描,当参与的人数达到10000的时候查询就非常慢了。
redis的排行榜功能就完美锲合了这个需求。来看看我是怎么实现的吧。
二、实现过程
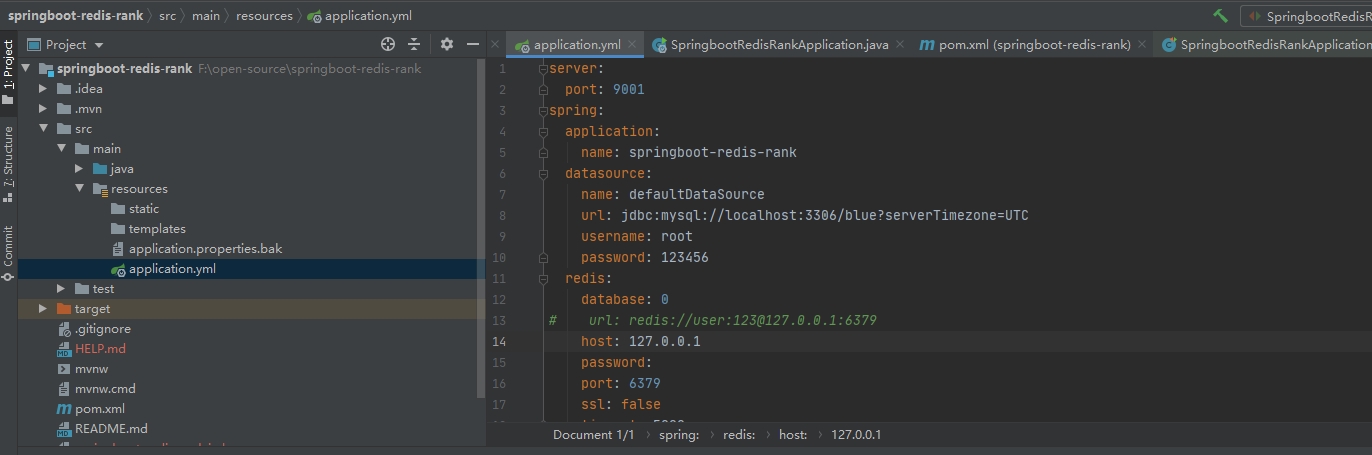
①、在本机开启了一个单点的redis,配置文件如下
: springboot-redis-rank : : defaultDataSource : jdbc:mysql://localhost:3306/blue?serverTimezone=UTC : root : 123456 : : : 127.0.0.1 : : : : 5000
②、Maven依赖引入如下
<parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.0.4.RELEASE</version>
</parent><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId></dependency>
</dependencies>③、代码实现
1.注入redis,将key声明为常量SCORE_RANK
@Autowiredprivate StringRedisTemplate redisTemplate;public static final String SCORE_RANK = "score_rank";2.新增默认排行数据
/*** 批量新增*/@Testpublic void batchAdd() {Set<ZSetOperations.TypedTuple<String>> tuples = new HashSet<>();long start = System.currentTimeMillis();for (int i = 0; i < 100000; i++) {DefaultTypedTuple<String> tuple = new DefaultTypedTuple<>("张三" + i, 1D + i);tuples.add(tuple);}System.out.println("循环时间:" +( System.currentTimeMillis() - start));Long num = redisTemplate.opsForZSet().add(SCORE_RANK, tuples);System.out.println("批量新增时间:" +(System.currentTimeMillis() - start));System.out.println("受影响行数:" + num);}//输出
循环时间:56
批量新增时间:1015
受影响行数:1000003.获取前10名(根据分数倒序)
/*** 获取排行列表*/@Testpublic void list() {Set<String> range = redisTemplate.opsForZSet().reverseRange(SCORE_RANK, 0, 10);System.out.println("获取到的排行列表:" + JSON.toJSONString(range));Set<ZSetOperations.TypedTuple<String>> rangeWithScores = redisTemplate.opsForZSet().reverseRangeWithScores(SCORE_RANK, 0, 10);System.out.println("获取到的排行和分数列表:" + JSON.toJSONString(rangeWithScores));}//输出
获取到的排行列表:["张三99999","张三99998","张三99997","张三99996","张三99995","张三99994","张三99993","张三99992","张三99991","张三99990","张三99989"]
获取到的排行和分数列表:[{"score":100000.0,"value":"张三99999"},{"score":99999.0,"value":"张三99998"},{"score":99998.0,"value":"张三99997"},{"score":99997.0,"value":"张三99996"},{"score":99996.0,"value":"张三99995"},{"score":99995.0,"value":"张三99994"},{"score":99994.0,"value":"张三99993"},{"score":99993.0,"value":"张三99992"},{"score":99992.0,"value":"张三99991"},{"score":99991.0,"value":"张三99990"},{"score":99990.0,"value":"张三99989"}]4.新增李四的分数
/*** 单个新增*/@Testpublic void add() {redisTemplate.opsForZSet().add(SCORE_RANK, "李四", 8899);}5.获取李四单人的排行
/*** 获取单个的排行*/@Testpublic void find(){Long rankNum = redisTemplate.opsForZSet().reverseRank(SCORE_RANK, "李四");System.out.println("李四的个人排名:" + rankNum);Double score = redisTemplate.opsForZSet().score(SCORE_RANK, "李四");System.out.println("李四的分数:" + score);}//输出
李四的个人排名:91101
李四的分数:8899.06.统计分数之间有多少人
/*** 统计两个分数之间的人数*/@Testpublic void count(){Long count = redisTemplate.opsForZSet().count(SCORE_RANK, 8001, 9000);System.out.println("统计8001-9000之间的人数:" + count);}//输出
统计8001-9000之间的人数:10017.获取集合的基数(数量大小)
/*** 获取整个集合的基数(数量大小)*/@Testpublic void zCard(){Long aLong = redisTemplate.opsForZSet().zCard(SCORE_RANK);System.out.println("集合的基数为:" + aLong);}//输出
集合的基数为:1000018.使用加法操作分数
/*** 使用加法操作分数*/@Testpublic void incrementScore(){Double score = redisTemplate.opsForZSet().incrementScore(SCORE_RANK, "李四", 1000);System.out.println("李四分数+1000后:" + score);}//输出
李四分数+1000后:9899.0四.归纳
在以上测试类中我们使用了redis的那些功能呢?在以上的例子中我们使用了单个新增,批量新增,获取前十,获取单人排名这些操作,但是redisTemplate还提供了更多的方法。
新增or更新
有三种方式,一种是单个,一种是批量,对分数使用加法(如果不存在,则从0开始加)。
//单个新增or更新
Boolean add(K key, V value, double score);
//批量新增or更新
Long add(K key, Set<TypedTuple<V>> tuples);
//使用加法操作分数
Double incrementScore(K key, V value, double delta);删除
删除提供了三种方式:通过key/values删除,通过排名区间删除,通过分数区间删除。
//通过key/value删除
Long remove(K key, Object... values);//通过排名区间删除
Long removeRange(K key, long start, long end);//通过分数区间删除
Long removeRangeByScore(K key, double min, double max);查
1.列表查询:分为两大类,正序和逆序。以下只列表正序的,逆序的只需在方法前加上reverse即可:
//通过排名区间获取列表值集合
Set<V> range(K key, long start, long end);//通过排名区间获取列表值和分数集合
Set<TypedTuple<V>> rangeWithScores(K key, long start, long end);//通过分数区间获取列表值集合
Set<V> rangeByScore(K key, double min, double max);//通过分数区间获取列表值和分数集合
Set<TypedTuple<V>> rangeByScoreWithScores(K key, double min, double max);//通过Range对象删选再获取集合排行
Set<V> rangeByLex(K key, Range range);//通过Range对象删选再获取limit数量的集合排行
Set<V> rangeByLex(K key, Range range, Limit limit);2.单人查询
可获取单人排行,和通过key/value获取分数。以下只列表正序的,逆序的只需在方法前加上reverse即可:
//获取个人排行
Long rank(K key, Object o);//获取个人分数
Double score(K key, Object o);统计
统计分数区间的人数,统计集合基数。
//统计分数区间的人数Long count(K key, double min, double max);//统计集合基数Long zCard(K key);三、项目结构图
四、补充
以上就是redis中使用排行榜功能的一些例子,和对redis的操作方法了。redis不仅仅只是作为缓存,它更是数据库,提供了许多的功能,我们都可以好好的利用。
在这里我使用redis来实现了世界杯积分排行的展示,无论是在批量更新或是获取个人排行等方便,都有着很高效率,也降低了对数据库操作的压力,达到了很好的效果。
相关文章:
基于springboot跟redis实现的排行榜功能(实战)
概述 前段时间,做了一个世界杯竞猜积分排行榜。对世界杯64场球赛胜负平进行猜测,猜对1分,错误0分,一人一场只能猜一次。 1.展示前一百名列表。 2.展示个人排名(如:张三,您当前的排名106579)。 一.redis so…...

Mongodb常见操作命令
一、登录相关以及启动 启动服务mongodb: cd /usr/local/mongodb/bin ./mongod -f /data/mongodb/mongodb1.conf./mongod -f /data/mongodb/mongodb2.conf./mongod -f /data/mongodb/mongodb3.conf 登录mongodb数据库(mongodb默认端口:27017࿰…...
springcloud-nacos简述
Spring Cloud alibaba: nacos服务注册中心,配置中心 服务注册中心 1.项目父工程添加springcloudalibaba依赖 <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-alibaba-dependencies</artifactId><ve…...
【SpringSecurity】十二、集成JWT搭配Redis实现退出登录
文章目录 1、登出的实现思路2、集成Redis3、认证成功处理器4、退出成功处理器5、修改token校验过滤器6、调试 1、登出的实现思路 这是目前的token实现图: 因为JWT的无状态,服务端无法在使用过程中主动废止某个 token,或者更改 token 的权限…...

Docker进入容器出现bash: vi: command not found
🎈1 参考文档 docker基础容器中bash: vi: command not found问题解决 | 你邻座的怪同学-CSDN 🔍2 问题描述 在使用 Docker 容器时,有时候里边没有安装vim,敲vim命令时提示说:vim: command not found。 这个时候就需要…...

Linux_6_文件查找与打包压缩
目录 文件查找与打包压缩1文件查找1.1 locate1.2 find1.2.1 指定搜索目录层级1.2.2对每个目录先处理目录内的文件,再处理目录本身1.2.3根据文件名和inode查找1.2.4 根据属主、属组查找1.2.5根据文件类型查找1.2.6空文件或目录1.2.7组合条件1.2.8 排除日录1.2.9根据文…...

JavaWeb_LeadNews_Day9-Redis实现用户行为
JavaWeb_LeadNews_Day9-Redis实现用户行为 网关配置点赞阅读不喜欢关注收藏文章详情-行为数据回显来源Gitee 网关配置 nacos: leadnews-app-gateway # 用户行为微服务 - id: leadnews-behavioruri: lb://leadnews-behaviorpredicates:- Path/behavior/**filters:- StripPrefi…...

IntelliJ IDEA2021.3.1 使用 MybatisCodeHelperPro插件
一、 下载 下载破解后的 MybatisCodeHelperPro 的 V3.2.2版本 V3.2.2-CSDN 或者 V3.2.2-Gitee 二、 应用 将下载下来的Zip文件 放到电脑上的某个位置 (最好放在Idea 管理插件的 plugins 下) 然后自从搜索 Idea如何从磁盘中应用插件 三、激活 由于已经破解过了 但是还是需要激活…...
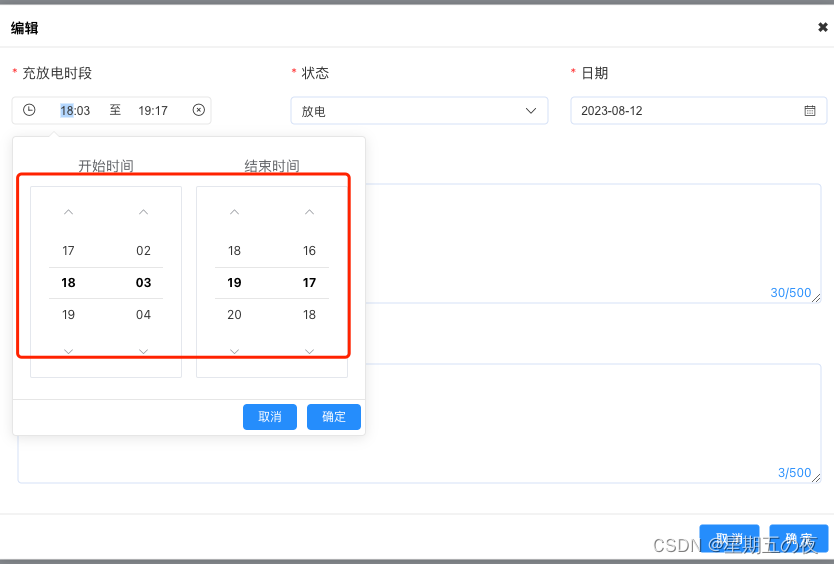
el-date-picker 等 点击无反应不回显问题解决
如上图,编辑回显正常,但是时间控件在拖动过程中时间不会跟随改变。 解决办法: <el-date-picker input"onInput()" ...><el-input input"onInput()" ...>js中onInput() {this.$forceUpdate();},...
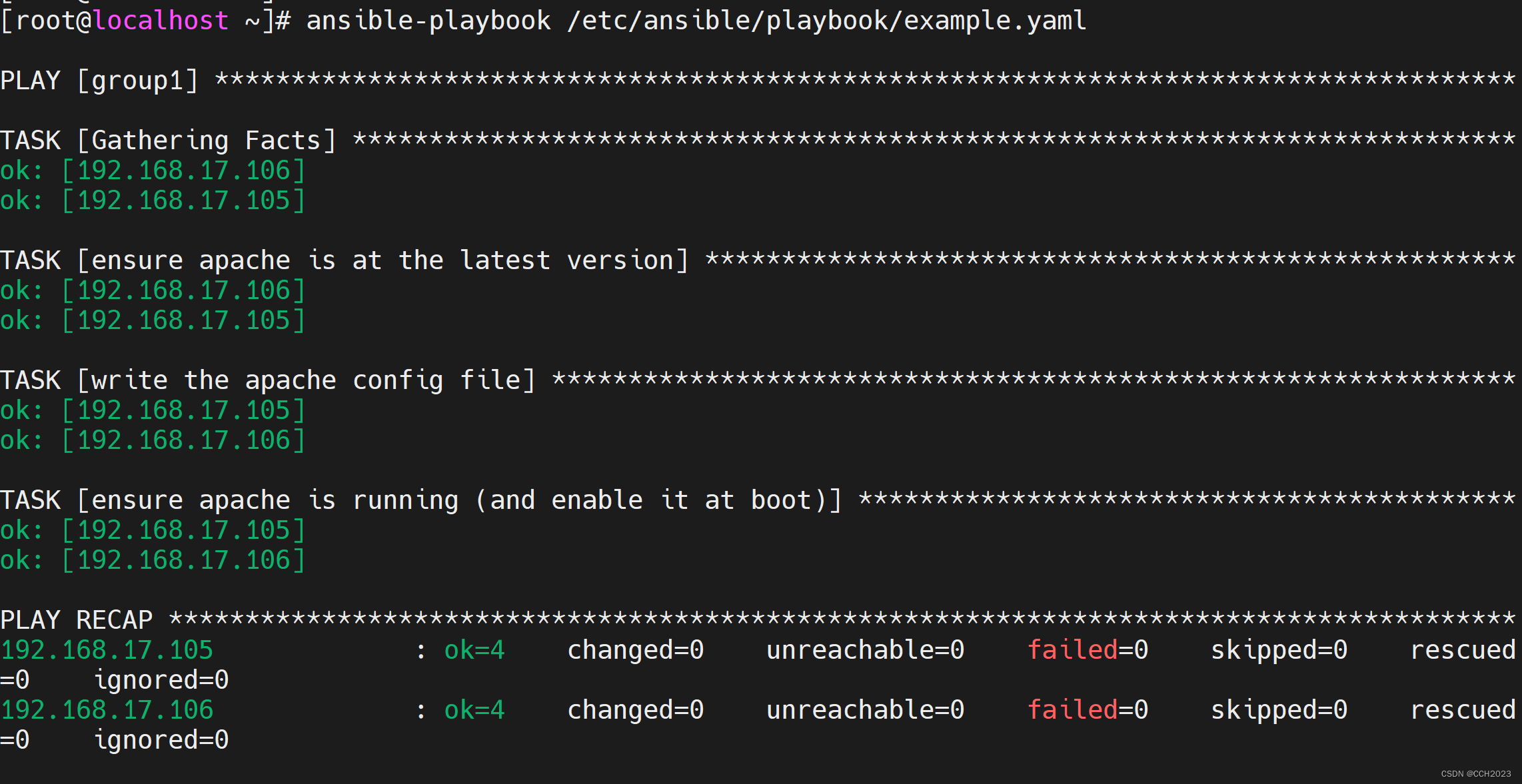
Ansible学习笔记12
playbook: playbook(剧本):是ansible用于配置、部署和管理被控节点的剧本,用于Ansible操作的编排。 使用的是yaml格式,(saltstack、elk、docker、docker-compose、k8s都会使用到yaml格式。&am…...

sqlmap中文文档
这是 sqlmap -hh的翻译,后续可能会对参数进行详细的示例 sqlmap 普通选项 -h, --help # 显示基本帮助信息并退出 -hh # 详细帮助信息 --versino # 版本 -v # 日志详细级别 0-60:只显示python错误以及严重的信息。1:同时显示基本信…...
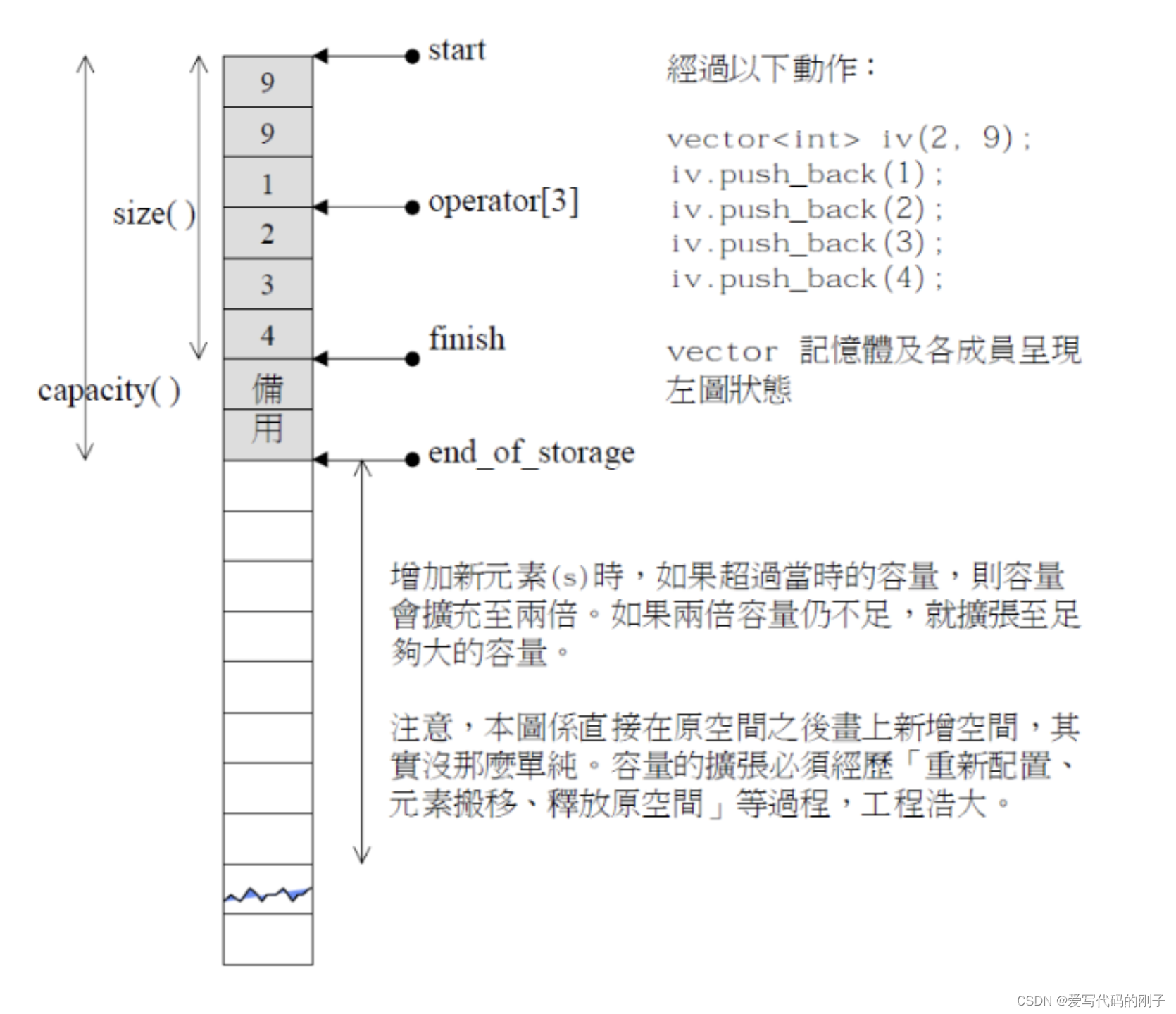
【C++模拟实现】vector的模拟实现
【C模拟实现】vector的模拟实现 目录 【C模拟实现】vector的模拟实现vector模拟实现的标准代码vector模拟实现中的要点insert和erase会涉及到迭代器失效的问题vector深度剖析关于模版template< class InputIterator >使用memcpy拷贝问题 作者:爱写代码的刚子 …...
go学习part21(3)redis连接池
连接池 1.介绍 每次使用数据就就建立链接再关闭可以,但是如果有大量客户端频繁请求连接,大量创建连接和关闭会非常耗费资源。 所以就建立一个连接池,里面存放几个不关闭的连接,谁要用就分配给谁。 说明:通过Golang 对 Redis操…...
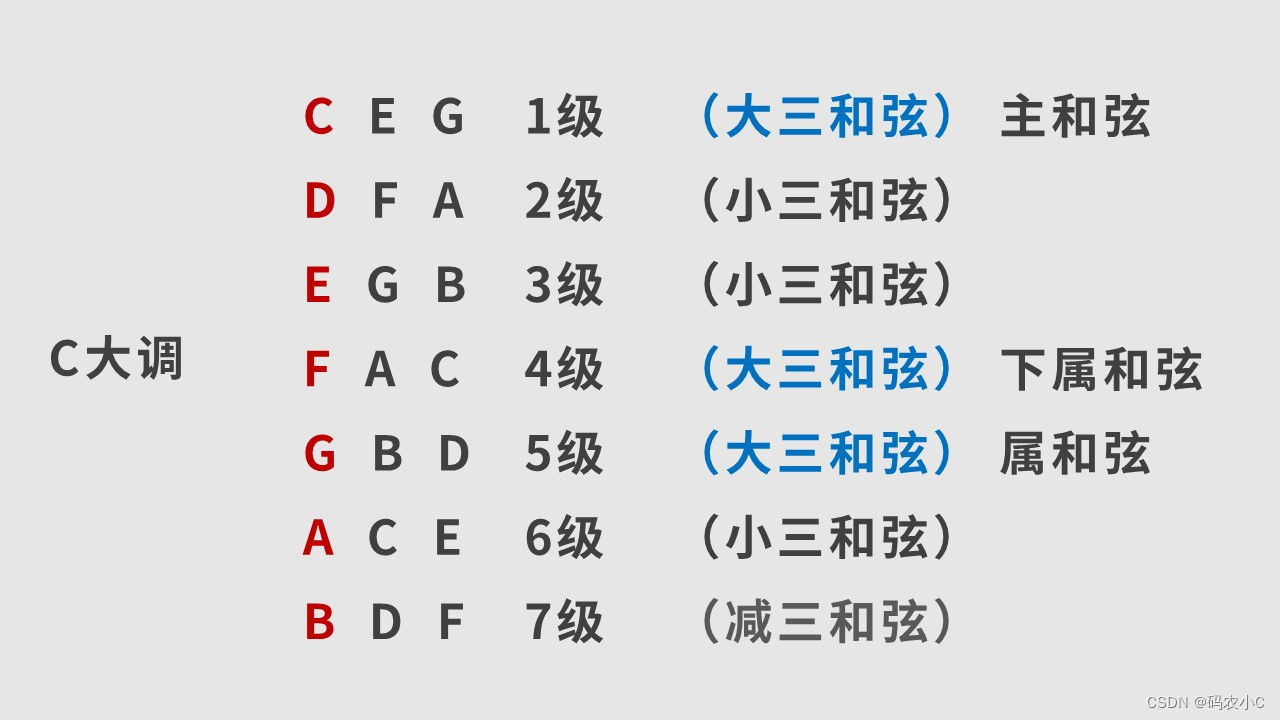
乐理-笔记
乐理笔记整理 1、前言2、认识钢琴键盘及音名3、升降号、还原号4、如何区分同一音名的不同键?5、各类音符时值的关系6、歌曲拍号7、拍号的强弱规律8、歌曲速度(BPM)9、附点音符10、三连音12、唱名与简谱数字13、自然大调(白键&…...

java八股文面试[数据库]——B树和B+树的区别
B树是一种树状数据结构,它能够存储数据、对其进行排序并允许以O(logn)的时间复杂度进行查找、顺序读取、插入和删除等操作。 1、B树的特性 B树中允许一个结点中包含多个key,可以是3个、4个、5个甚至更多,并不确定,需要看具体的实…...
2、Nginx 安装
文章目录 2、Nginx 安装2.1 官网下载2.2 安装 nginx2.2.1 第一步2.2.2 第二步2.2.3 第三步,安装 nginx2.2.4 第四步,修改防火漆规则 【尚硅谷】尚硅谷Nginx教程由浅入深 志不强者智不达;言不信者行不果。 2、Nginx 安装 2.1 官网下载 nginx…...

最适合 AI 的 Python Web 框架
迷途小书童的 Note 读完需要 4分钟 速读仅需 2 分钟 1 简介 本文将介绍 Gradio 库,它是 Python 的一个 web 框架,可以帮助我们快速构建交互式 AI 应用。我们将了解 Gradio 的应用场景、基本原理、功能介绍,并通过一个代码示例来演示如何使用 …...

算法通关村第十八关——回溯
回溯很大感觉就是多重递归,在递归的题目中,例如斐波那契数列,只需要考虑当前情况以及他的子情况。而在回溯中,要进行很多次递归,并且要对条件进行处理。 LeetCode257:给你一个二叉树的根节点root,按任意顺序ÿ…...
使用kafka还在依赖Zookeeper,kraft模式了解下
Kafka的Kraft模式 概述 Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。其核心组件包含Producer、Broker、Consumer,以及依赖的Zookeeper集群。其中Zookeeper集群是Kafka用来负责集群元数据的管理、控制器…...
【100天精通Python】Day52:Python 数据分析_Numpy入门基础与数组操作
目录 1 NumPy 基础概述 1.1 NumPy的主要特点和功能 1.2 NumPy 安装和导入 2 Numpy 数组 2.1 创建NumPy数组 2.2 数组的形状和维度 2.3 数组的数据类型 2.4 访问和修改数组元素 3 数组操作 3.1 数组运算 3.2 数学函数 3.3 统计函数 4 数组形状操作 4.1 重塑数组形…...
)
从STM32迁移到普冉PY32F003:UART代码移植保姆级教程(附HAL库对比)
从STM32到普冉PY32F003的UART代码迁移实战指南 1. 国产MCU替代浪潮下的技术选择 近年来,半导体行业的供应链波动促使更多工程师将目光投向国产MCU解决方案。普冉PY32F003系列作为Cortex-M0内核的代表产品,以48MHz主频、64KB Flash和8KB RAM的配置&#x…...

ARMv8 HFGITR_EL2寄存器解析与虚拟化指令陷阱控制
1. AArch64 HFGITR_EL2寄存器架构解析HFGITR_EL2(Hypervisor Fine-Grained Instruction Trap Register)是ARMv8架构中专门用于指令级陷阱控制的系统寄存器,属于虚拟化扩展的重要组成部分。这个64位寄存器通过位映射机制实现对特定AArch64指令…...

ARM架构CONSTRAINED UNPREDICTABLE行为解析与应对
1. ARM架构中的CONSTRAINED UNPREDICTABLE行为解析在处理器架构设计中,UNPREDICTABLE行为通常指架构规范未明确定义的执行结果,可能导致不可预期的系统状态。ARM架构通过引入CONSTRAINED UNPREDICTABLE机制,将这类行为限制在特定范围内&#…...

对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比 Token Plan 与按量计费在 Taotoken 平台上的成本体感差异 对于个人开发者或项目管理者而言,在接入大模型服务时&a…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

保姆级教程:在Ubuntu上配置Frida环境,搞定Android App的IO重定向与签名绕过
在Ubuntu上构建Android逆向工程环境:Frida实战与IO重定向技术解析 对于习惯Linux环境的安全研究人员而言,Windows-centric的逆向工具链往往带来诸多不便。本文将系统性地介绍如何在Ubuntu上搭建完整的Android逆向环境,并深入探讨如何利用Frid…...

圈复杂度>12=技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露
更多请点击: https://codechina.net 第一章:圈复杂度>12技术债炸弹?DeepSeek静态分析实战:从17.8→3.2的重构路径全披露 当函数圈复杂度(Cyclomatic Complexity)持续高于12,它不再是…...

如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南
如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南 【免费下载链接】GASShooter Advanced FPS/TPS Sample Project for Unreal Engine 4s GameplayAbilitySystem plugin 项目地址: https://gitcode.com/gh_mirrors/ga/GASShooter GASShooter是Un…...
)
嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(3)
接前一篇文章:嵌入式Linux驱动开发 —— 从DTS到代码的桥梁与简单OF系列API(2) 节点查找 API:如何在设备树中定位目标节点 有了数据结构基础,现在我们可以开始讲具体的API了。第一步是找到你要操作的节点。就像你想操…...