Spark与Flink的区别
分析&回答
(1)设计理念
1、Spark的技术理念是使用微批来模拟流的计算,基于Micro-batch,数据流以时间为单位被切分为一个个批次,通过分布式数据集RDD进行批量处理,是一种伪实时。
2、Flink是基于事件驱动的,是面向流的处理框架, Flink基于每个事件一行一行地流式处理,是真正的流式计算. 另外他也可以基于流来模拟批进行计算实现批处理。
(2)架构方面
1、Spark在运行时的主要角色包括:Master、Worker、Driver、Executor。
2、Flink 在运行时主要包含:Jobmanager、Taskmanager和Slot。
(3)任务调度
1、Spark Streaming 连续不断的生成微小的数据批次,构建有向无环图DAG,根据DAG中的action操作形成job,每个job有根据窄宽依赖生成多个stage。
2、Flink 根据用户提交的代码生成 StreamGraph,经过优化生成 JobGraph,然后提交给 JobManager进行处理,JobManager 会根据 JobGraph 生成 ExecutionGraph,ExecutionGraph 是 Flink 调度最核心的数据结构,JobManager 根据 ExecutionGraph 对 Job 进行调度。
(4)时间机制
1、Spark Streaming 支持的时间机制有限,只支持处理时间。使用processing time模拟event time必然会有误差, 如果产生数据堆积的话,误差则更明显。
2、flink支持三种时间机制:事件时间,注入时间,处理时间,同时支持 watermark 机制处理迟到的数据,说明Flink在处理乱序大实时数据的时候,更有优势。
(5)容错机制
1、SparkStreaming的容错机制是基于RDD的容错机制,会将经常用的RDD或者对宽依赖加Checkpoint。利用SparkStreaming的direct方式与Kafka可以保证数据输入源的,处理过程,输出过程符合exactly once。
2、Flink 则使用两阶段提交协议来保证exactly once。
(6)吞吐量与延迟
1、spark是基于微批的,而且流水线优化做的很好,所以说他的吞入量是最大的,但是付出了延迟的代价,它的延迟是秒级;
2、而Flink是基于事件的,消息逐条处理,而且他的容错机制很轻量级,所以他能在兼顾高吞吐量的同时又有很低的延迟,它的延迟能够达到毫秒级;
喵呜面试助手:一站式解决面试问题,你可以搜索微信小程序 [喵呜面试助手] 或关注 [喵呜刷题] -> 面试助手 免费刷题。如有好的面试知识或技巧期待您的共享!
相关文章:

Spark与Flink的区别
分析&回答 (1)设计理念 1、Spark的技术理念是使用微批来模拟流的计算,基于Micro-batch,数据流以时间为单位被切分为一个个批次,通过分布式数据集RDD进行批量处理,是一种伪实时。 2、Flink是基于事件驱动的,是面向流的处理框架, Flink基于…...
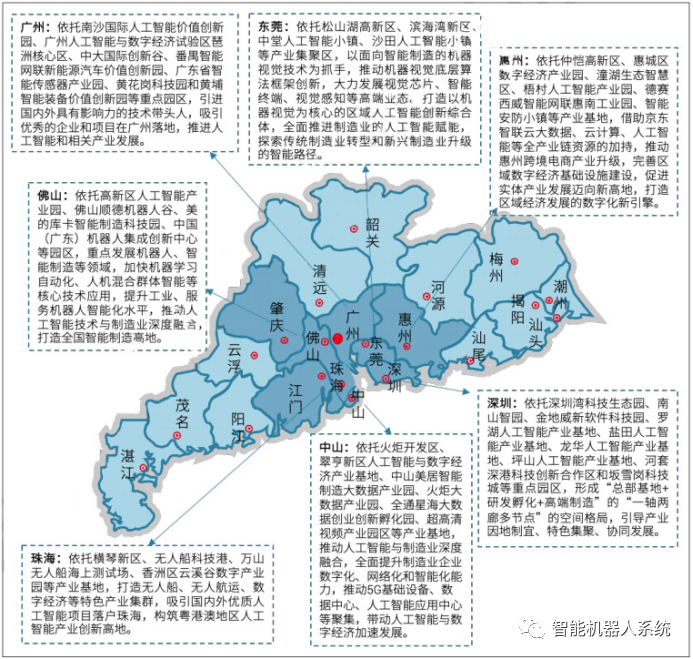
未来智造:珠三角引领人工智能产业集群
原创 | 文 BFT机器人 产业集群是指产业或产业群体在地理位置上集聚的现象,产业集群的研究对拉动区域经济发展,提高区域产业竞争力具有重要意义。 从我国人工智能产业集群形成及区域布局来看,我国人工智能产业发展主要集聚在京津冀、长三角、…...

【Unity db】sqlite
背景 最近使用unity,需要用到sqlite,记录下使用过程 需要的动态库 Mono.Data.Sqlite.dll,这个文件下载参考下面链接 SqliteConnection的Close和Open 连接的概念: 在数据库编程中,连接是一个重要的概念,…...
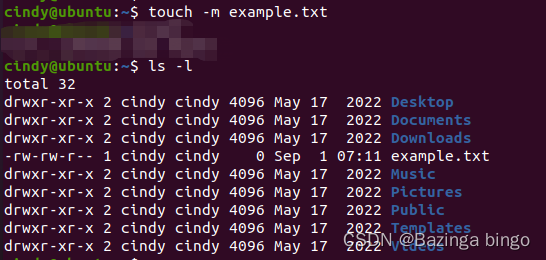
Linux 指令心法(四)`touch` 创建一个新的空文件
文章目录 命令的概述和用途命令的用法命令行选项和参数的详细说明命令的示例命令的注意事项或提示 命令的概述和用途 touch 是一个用于在 Linux 和 Unix 系统中创建空文件或更改现有文件的访问和修改时间的命令。如果指定的文件不存在,touch会创建一个新的空文件&a…...
分类算法系列②:KNN算法
目录 KNN算法 1、简介 2、原理分析 数学原理 相关公式及其过程分析 距离度量 k值选择 分类决策规则 3、API 4、⭐案例实践 4.1、分析 4.2、代码 5、K-近邻算法总结 🍃作者介绍:准大三网络工程专业在读,努力学习Java,涉…...

12. 微积分 - 梯度积分
Hi,大家好。我是茶桁。 上一节课,我们讲了方向导数,并且在最后留了个小尾巴,是什么呢?就是梯度。 我们再来回看一下但是的这个式子: [ f x f y...

Large Language Models and Knowledge Graphs: Opportunities and Challenges
本文是LLM系列的文章,针对《Large Language Models and Knowledge Graphs: Opportunities and Challenges》的翻译。 大语言模型和知识图谱:机会与挑战 摘要1 引言2 社区内的共同辩论点3 机会和愿景4 关键研究主题和相关挑战5 前景 摘要 大型语言模型&…...

Python操作Excel教程(图文教程,超详细)Python xlwings模块详解,
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:小白零基础《Python入门到精通》 xlwings模块详解 1、快速入门1、打开Excel2、创建工作簿2.1、使用工作簿2.2、操作…...

Java入门
Java导入包 import 主要用于导入在使用类前准备好了Import 关键字可以多次使用,导入多个包Import 关键字可以多次使用,导入多个类如果同一个包中需要大量的类,那么可以使用通配符进行导入如果Import了不同包,相同名称的类&#x…...
深度解析BERT:从理论到Pytorch实战
本文从BERT的基本概念和架构开始,详细讲解了其预训练和微调机制,并通过Python和PyTorch代码示例展示了如何在实际应用中使用这一模型。我们探讨了BERT的核心特点,包括其强大的注意力机制和与其他Transformer架构的差异。 关注TechLead&#x…...
小程序数据导出文件
小程序josn数据生成excel文件 先从下载传送门将xlsx.mini.min.js拷贝下来,新建xlsx.js文件放入小程序项目文件夹下。 const XLSX require(./xlsx)//在需要用的页面中引入// 定义导出 Excel 报表的方法exportData() {const that thislet newData [{time:2021,val…...

hadoop1.2.1伪分布式搭建
0.使用host-only方式 将Windows上的虚拟网卡改成跟Linux上的网卡在同一网段 注意:一定要将widonws上的WMnet1的IP设置和你的虚拟机在同一网段,但是IP不能相同 1.Linux环境配置(windows下面的防火墙也要关闭) 1.1修改主…...

【校招VIP】前端JavaScript语言之跨域
考点介绍: 什么是跨域?浏览器从一个域名的网页去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域。跨域是前端校招的一个重要考点,在面试过程中经常遇到,需要着重掌握。本期分享的前端算法考点之…...

mysql调优小计
1.选择最合适的字段属性:类型、⻓度、是否允许NULL等;尽量把字段设为not null,⼀⾯查询时对⽐是否为null; 2.要尽量避免全表扫描,⾸先应考虑在 where 及 order by 涉及的列上建⽴索引。 3.应尽量避免在 where ⼦句中对…...

AI:04-基于机器学习的蘑菇分类
蘑菇是一类广泛分布的真菌,其中许多种类具有重要的食用和药用价值,但也存在着一些有毒蘑菇。因此,准确地区分可食用和有毒的蘑菇对于保障人们的食品安全和健康至关重要。本研究旨在基于机器学习技术开发一种蘑菇分类系统,以实现对蘑菇的自动分类和识别。通过构建合适的数据…...
算法——排序
排序 下面的代码会用到宏定义,因为再C中没有swap交换函数,所以对于swap的宏定义代码如下: #define swap(a, b) {\__typeof(a) __a a; a b; b __a;\ } 稳定排序: 1.插入排序: 插入排序会将数组,分位两个部…...
leetCode动态规划“不同路径II”
迷宫问题是比较经典的算法问题,一般可以用动态规划、回溯等方法进行解题,这道题目是我昨晚不同路径这道题趁热打铁继续做的,思路与原题差不多,只是有需要注意细节的地方,那么话不多说,直接上coding和解析&a…...

100天精通Python(可视化篇)——第99天:Pyecharts绘制多种炫酷K线图参数说明+代码实战
文章目录 专栏导读一、K线图介绍1. 说明2. 应用场景 二、配置说明三、K线图实战1. 普通k线图2. 添加辅助线3. k线图鼠标缩放4. 添加数据缩放滑块5. K线周期图表 书籍推荐 专栏导读 🔥🔥本文已收录于《100天精通Python从入门到就业》:本专栏专…...

哈希表与有序表
哈希表与有序表 Set结构 key Map结构 key-value 哈希表 哈希表的时间复杂度都是常数项级别的,但常数较大 增删改查的时间都是常数级别的,与数据量无关 当哈希表存储的值是基础数据类型(Integer - int),哈希表中内…...

什么时候使用RPA?如何使用RPA?需要什么样的硬件支持?需要安装哪些软件?
RPA(Robotic Process Automation)是一种用于自动化执行重复性任务的技术,它可以帮助企业提高工作效率,降低人力成本,并减少人为错误。RPA适用于各种行业和场景,例如财务、人力资源、客户服务、IT运维等。 …...
)
【ACM出版、往届已稳定EI检索】第二届大数据与智慧医学国际学术会议(BDIMed 2026)
第二届大数据与智慧医学国际学术会议(BDIMed 2026)将于2026年6月26-28日在中国重庆市举行。 随着科技与医疗的交汇不断演变,BDIMed 2026将为与会者提供一个知识分享、挑战讨论及促进合作的平台。我们荣幸地邀请您参加此次盛会,会…...

MTK手机用上高通QC快充,背后多出的那颗‘xmusb350’芯片到底在忙啥?
MTK手机为何需要外挂xmusb350芯片实现高通QC快充? 当你在电商平台搜索"支持QC快充的MTK手机"时,可能会发现一个有趣的现象:采用联发科处理器的机型在充电模块描述中,常会特别标注"搭载独立QC协议芯片"。这背后…...

智慧工业轮胎X光图像金属与结构缺陷检测数据集VOC+YOLO格式896张11类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件)图片数量(jpg文件个数):896标注数量(xml文件个数):896标注数量(txt文件个数):896标注类别数&…...

【计算机毕业设计】基于Springboot的工作流程管理系统设计与实现+万字文档
博主介绍:✌全网粉丝3W,csdn特邀作者、CSDN新星计划导师、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌ 技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、…...

从账单明细看 Taotoken 按 Token 计费模式带来的成本控制优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单明细看 Taotoken 按 Token 计费模式带来的成本控制优势 1. 成本感知的起点:账单明细结构 对于使用大模型 API 的…...

程序员的写作技巧:如何写出受欢迎的技术博客
在软件测试行业快速发展的今天,技术博客不仅是知识沉淀的载体,更是测试从业者提升个人影响力、拓展职业边界的重要途径。一篇受欢迎的技术博客,能让你的经验被更多人看见,甚至成为行业内的标杆。那么,软件测试从业者该…...

如何为多个并行项目设置Taotoken Token Plan以优化成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为多个并行项目设置Taotoken Token Plan以优化成本 应用场景类,同时进行多个AI应用实验或开发的个人或团队&#x…...

终极浏览器资源嗅探指南:解锁网页媒体捕获的完整方案
终极浏览器资源嗅探指南:解锁网页媒体捕获的完整方案 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 在数字内容无处不在的今天&#x…...

拆解两款低压MOS芯片:4606和8205A,实测驱动电压低至0.7V,低压电路神器?
4606与8205A低压MOS芯片深度评测:0.7V驱动的电路革新实践 在低压电路设计领域,工程师们始终面临一个核心挑战:如何在有限电压下实现高效功率控制。传统MOS管通常需要较高的栅极驱动电压(普遍在2V以上),这限…...

AI率总超标?2026年AI论文平台排行榜权威发布,轻松定稿不是梦!
写论文效率低、熬夜赶稿、查重总不通过?别慌!2026 年最新 AI 论文写作工具合集来了,覆盖选题、大纲、初稿、润色、降重、格式、文献引用全流程,帮你精准匹配最适合的学术助手,彻底告别论文内耗!Ἴ…...