小白的第一个RNN(情感分析模型)
平台:window10,python3.11.4,pycharm
框架:keras
编写日期:20230903
数据集:英语,自编,训练集和测试集分别有4个样本,标签有积极和消极两种
环境搭建
新建文件夹,进入目录
创建虚拟环境
virtualenv venv激活虚拟环境
venv\Scripts\activate安装依赖库
pip install tensorflow代码编写
目录下创建main.py,进入pycharm打开文件夹,编写代码
包引入
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import SimpleRNN, Dense数据集处理
# 训练集
train_texts = ['I love this movie','This is the worst film I have ever seen.','An enjoyable and thought-provoking experience.',"I think it is boring"]train_labels = np.array([1, 0, 1, 0]) # 0代表消极,1代表积极# 测试集
test_texts = ["What a waste of my time","One of the best movies I've seen in a long time","Amazing acting!","This movie look awful"]
test_labels = np.array([0, 1, 1, 0])# 构建分词器
tokenizer = Tokenizer(num_words=100)
# 用训练集与测试集训练分词器
tokenizer.fit_on_texts(train_texts + test_texts)
# 数据集序列化,将文本转成数字,便于机器处理
train_sequences = tokenizer.texts_to_sequences(train_texts)
test_sequences = tokenizer.texts_to_sequences(test_texts)
# 数据填充到20,超过的就截断,post:在末尾填充
# 由于每个训练文本有不同的单词数,需要统一
train_data = pad_sequences(train_sequences, maxlen=20, padding='post')
test_data = pad_sequences(test_sequences, maxlen=20, padding='post')模型搭建和训练
# 创建一个线性模型容器
model = Sequential()
#添加RNN层,神经元数量为100,输入数据形状为(20,1)
model.add(SimpleRNN(100, input_shape=(20, 1)))
# 添加1个输出,激活函数为sigmoid的全连接层
model.add(Dense(1, activation='sigmoid'))
# 优化器:Adam,损失计算方法:二元交叉熵,评估依据:准确率
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# 输出模型结构
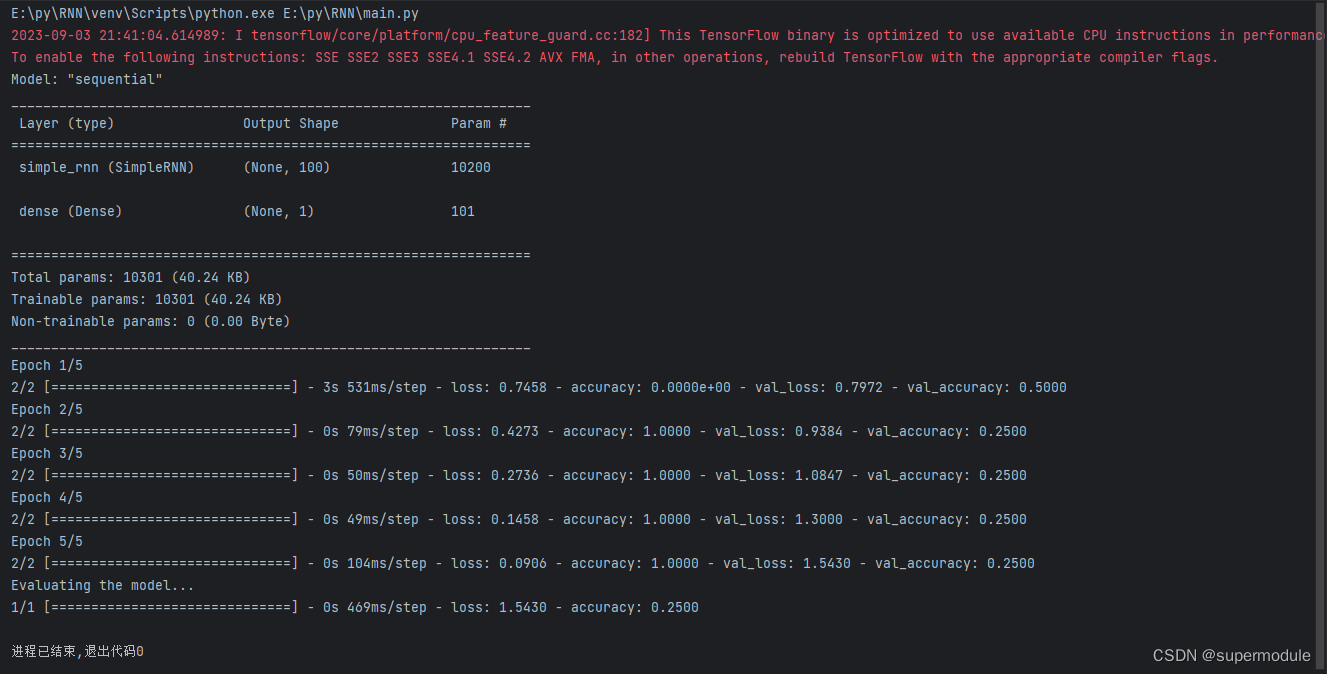
model.summary()
#训练模型,训练5轮,每次训练2个样本
model.fit(train_data, train_labels, epochs=5, batch_size=2, validation_data=(test_data, test_labels))
模型评估
# 打印评估信息
print('Evaluating the model...')
#进行评估
model.evaluate(test_data, test_labels)所有代码集合
import numpy as np
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from keras.models import Sequential
from keras.layers import SimpleRNN, Densetrain_texts = ['I love this movie','This is the worst film I have ever seen.','An enjoyable and thought-provoking experience.',"I think it is boring"]
train_labels = np.array([1, 0, 1, 0])test_texts = ["What a waste of my time","One of the best movies I've seen in a long time","Amazing acting!","This movie look awful"]
test_labels = np.array([0, 1, 1, 0])tokenizer = Tokenizer(num_words=1000)
tokenizer.fit_on_texts(train_texts + test_texts)train_sequences = tokenizer.texts_to_sequences(train_texts)
test_sequences = tokenizer.texts_to_sequences(test_texts)train_data = pad_sequences(train_sequences, maxlen=20, padding='post')
test_data = pad_sequences(test_sequences, maxlen=20, padding='post')model = Sequential()
model.add(SimpleRNN(100, input_shape=(20, 1)))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
model.summary()model.fit(train_data, train_labels, epochs=5, batch_size=2, validation_data=(test_data, test_labels))print('Evaluating the model...')
model.evaluate(test_data, test_labels)
运行图片截取
文件目录
控制台
相关文章:
小白的第一个RNN(情感分析模型)
平台:window10,python3.11.4,pycharm 框架:keras 编写日期:20230903 数据集:英语,自编,训练集和测试集分别有4个样本,标签有积极和消极两种 环境搭建 新建文件夹&am…...

华为云 存在部支持迁移的外键解决方法
DRS 检测出源端存在不支持的外键引用操作 MySQL、GaussDB(for MySQL)为源的全量增量或增量迁移、同步场景,以及MySQL、GaussDB(for MySQL)为源灾备场景 表1 源端存在不支持的外键引用操作 预检查项 源端存在不支持的外键引用操作。 描述 同步对象中存在包含CASC…...

C# winform控件和对象双向数据绑定
实现目的: 控件和对象双向数据绑定 实现结果: 1. 对象值 -> 控件值 2. 控件值 -> 对象值 using System; using System.Windows.Forms;namespace ControlDataBind {public partial class MainForm : Form{People people new People();public Mai…...

达梦8 在CentOS 系统下静默安装
确认系统参数 [rootlocalhost ~]# ulimit -a core file size (blocks, -c) unlimited data seg size (kbytes, -d) unlimited【1048576(即 1GB)以上或 unlimited】 scheduling priority (-e) 0 file size (blocks, -f) unlimite…...

flink k8s sink到kafka报错 Failed to get metadata for topics
可能出现的3种报错 -- 报错1 Failed to get metadata for topics [...]. org.apache.kafka.common.errors.TimeoutException: Call-- 报错2 Caused by: org.apache.kafka.common.errors.TimeoutException: Timed out waiting to send the call. Call: fetchMetadata Heartbe…...

利用大模型MoritzLaurer/mDeBERTa-v3-base-xnli-multilingual-nli-2mil7实现零样本分类
概念 1、零样本分类:在没有样本标签的情况下对文本进行分类。 2、nli:(Natural Language Inference),自然语言推理 3、xnli:(Cross-Lingual Natural Language Inference) ,是一种数据集,支持15种语言,数据集包含10个领域,每个领…...

代码随想录二刷day07
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、力扣454. 四数相加 II二、力扣383. 赎金信三、力扣15. 三数之和四、力扣18. 四数之和 前言 提示:这里可以添加本文要记录的大概内容࿱…...

点云从入门到精通技术详解100篇-点云的泊松曲面重建方法
目录 前言 相关理论 2.1三维点云 2.2体素滤波 2.3隐式曲面重建 泊松曲面重建及改进...

【STM32】学习笔记(串口通信)
串口通信 通信接口硬件电路电平标准USARTUSART框图 通信接口 串口是一种应用十分广泛的通讯接口,串口成本低、容易使用、通信线路简单,可实现两个设备的互相通信 单片机的串口可以使单片机与单片机、单片机与电脑、单片机与各式各样的模块互相通信&#…...

【Unity3D赛车游戏优化篇】新【八】汽车实现镜头的流畅跟随,以及不同角度的切换
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:Uni…...
)
webpack5 (四)
react-cli 中配置 开发环境 const path require(path) const EslintWebpackPlugin require(eslint-webpack-plugin) const HtmlWebpackPlugin require(html-webpack-plugin) const ReactRefreshWebpackPlugin require(pmmmwh/react-refresh-webpack-plugin); //封装处理样…...
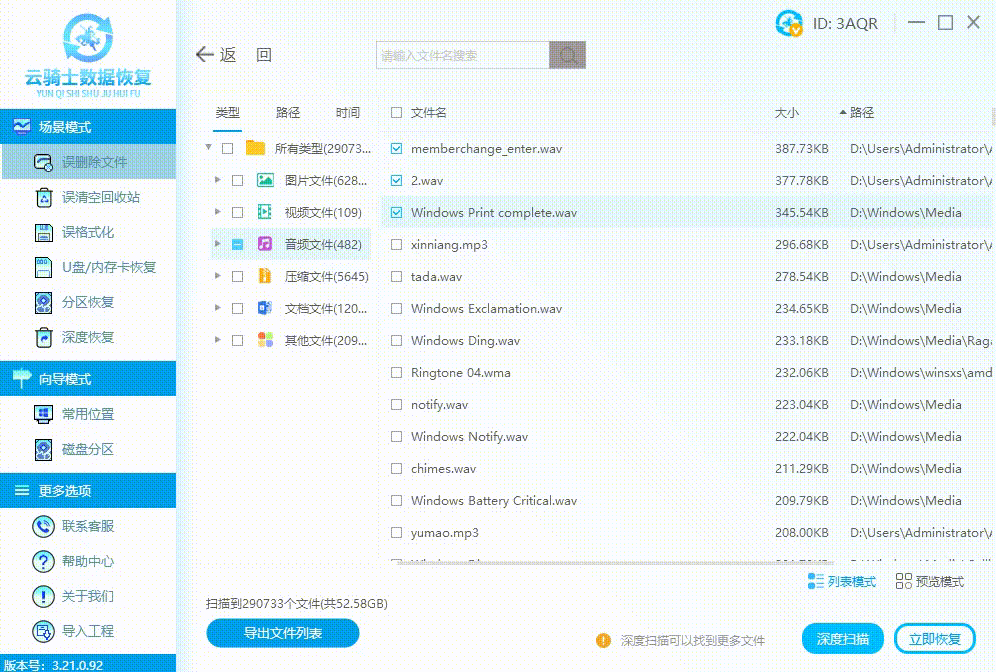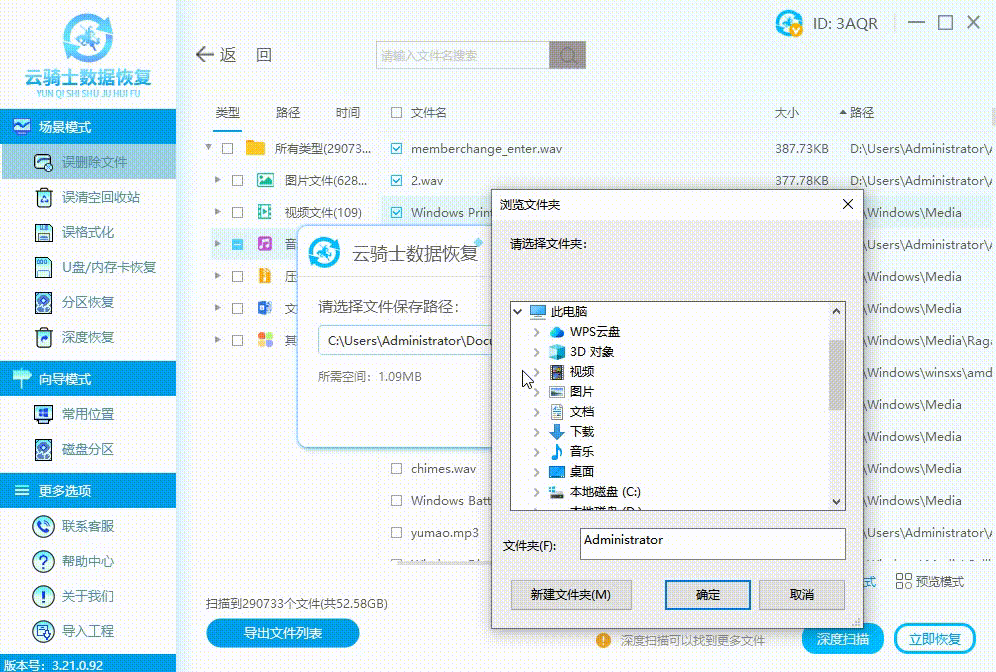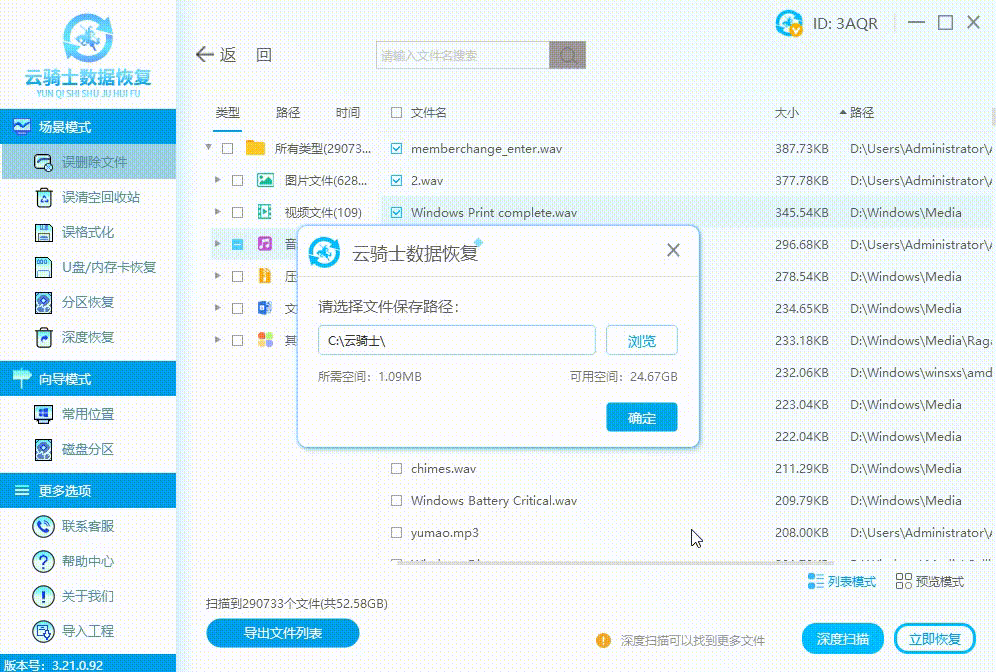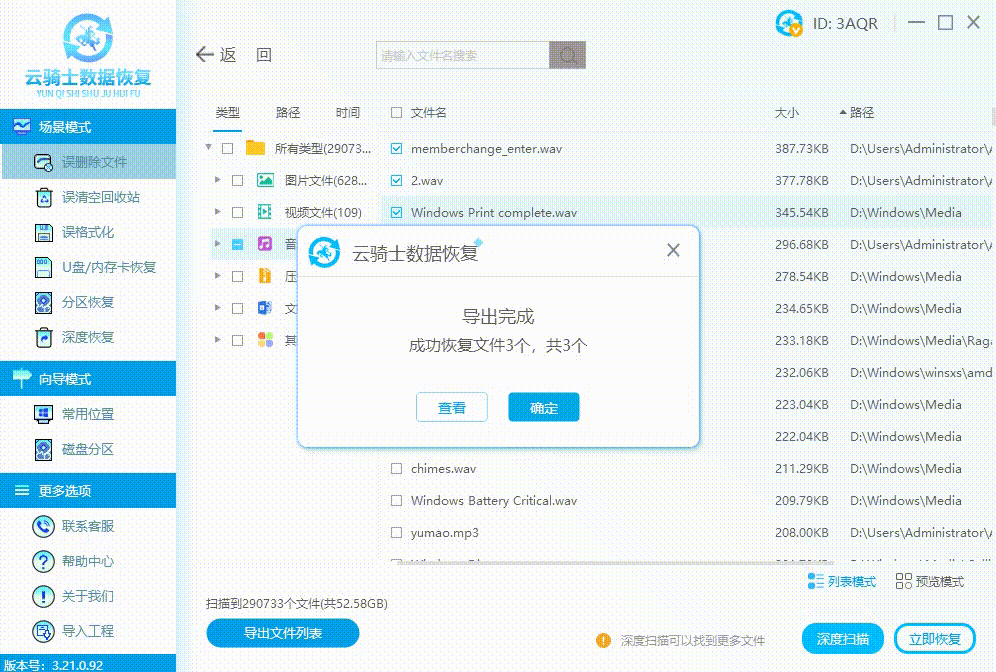
电脑硬盘数据恢复一般需要收费多少钱
随着电子信息时代的发展,个人和企业对电脑硬盘中存储的数据越发重视。然而,由于各种原因,硬盘数据丢失的情况屡见不鲜。如果您正陷入这样的困境,您可能会好奇恢复失去的数据需要花费多少钱。本文将为您介绍电脑硬盘数据恢复的一般…...

服务运营 | MSOR文章精选:远程医疗服务中的统计与运筹(二)
作者信息:王畅,陈盈鑫 编者按 在上一期中,我们分享了与远程医疗中运营管理问题相关的两篇文章。其一发表在《Stochastic Systems》,旨在使用排队论与流体近似的方法解决远程医疗中资源配置的问题;其二发表在《Managem…...
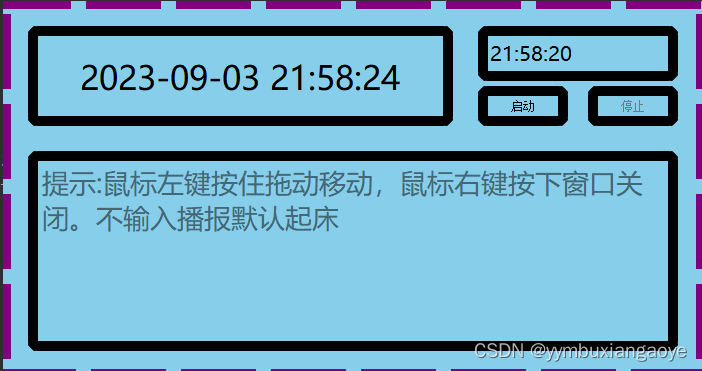
QT(9.3)定时器,绘制事件
作业: 自定义一个闹钟 pro文件: QT core gui texttospeechgreaterThan(QT_MAJOR_VERSION, 4): QT widgetsCONFIG c11# The following define makes your compiler emit warnings if you use # any Qt feature that has been marked deprecat…...

python opencv
保存直播流生存逐个图片 import cv2 from threading import Threadclass ThreadedCamera(object):def __init__(self, source 0):self.capture cv2.VideoCapture(source)self.thread Thread(target self.update, args ())self.thread.daemon Trueself.thread.start()sel…...
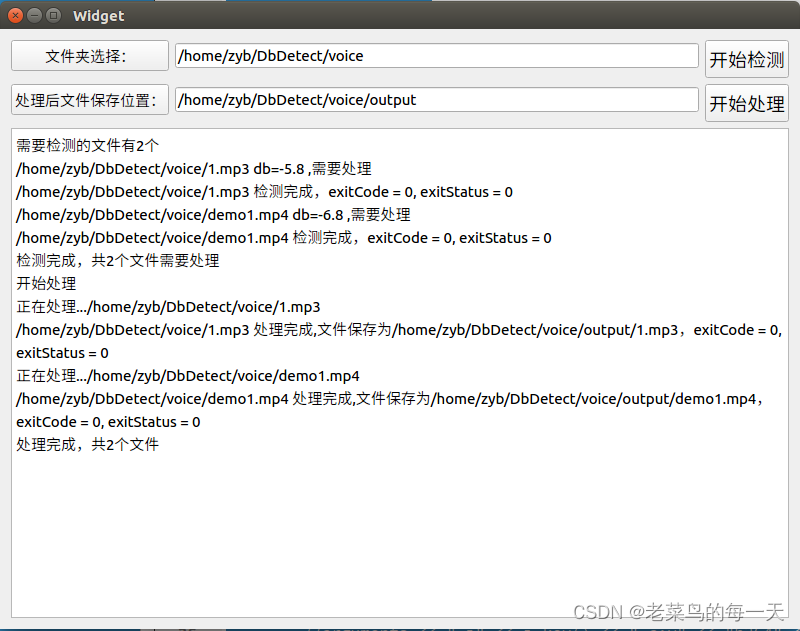
QProcess 调用 ffmpeg来处理音频
项目场景: 在文章 qt 实现音视频的分贝检测系统中,实现的是边播放变解析音频数据来统计音频的分贝大小,并不满足实际项目的需求,有的视频声音正常,有的视频声音就偏低,即使放到最大音量声音也是比较小&…...

“深入探究SpringMVC的工作原理与入门实践“
目录 引言1. 什么是SpringMVC?1.1. 模型1.2. 视图1.3. 控制器 2. SpringMVC的工作流程2.1. 客户端发送请求2.2. DispatcherServlet的处理2.3. 处理器映射器的使用2.4. 处理器的执行2.5. 视图解析器的使用2.6. 视图的渲染 3. SpringMVC的核心组件4. 弹簧MVC总结 引言 SpringMV…...

【Node.js】Node.js安装详细步骤和创建Express项目演示
Node.js是一个开源的、跨平台的JavaScript运行环境,用于在服务器端运行JavaScript代码。它提供了一个简单的API,可以用于开发各种网络和服务器应用程序。 以下是Node.js的安装和使用的详细步骤和代码示例: 1、下载Node.js 访问Node.js官方…...
栈和队列OJ
一、括号的匹配 题目介绍: 思路: 如果 c 是左括号,则入栈 push;否则通过哈希表判断括号对应关系,若 stack 栈顶出栈括号 stack.pop() 与当前遍历括号 c 不对应,则提前返回 false。栈 stack 为空࿱…...

Bootstrap的CSS类积累学习
要看哪个的介绍,搜索关键词就行了。 001-container 这是Bootstrap中定义的一个CSS类,它用于创建一个具有固定宽度的容器。比如,container类将<div>元素包装成一个固定宽度的容器。详情见:https://blog.csdn.net/wenhao_ir…...

终极指南:如何使用Harepacker复活版轻松打造你的MapleStory游戏世界
终极指南:如何使用Harepacker复活版轻松打造你的MapleStory游戏世界 【免费下载链接】Harepacker-resurrected All in one .wz file/map editor for MapleStory game files 项目地址: https://gitcode.com/gh_mirrors/ha/Harepacker-resurrected 想要个性化修…...
算法搞定复杂环境强化学习)
告别DDPG训练不稳定!用SAC(软性演员-评论家)算法搞定复杂环境强化学习
告别DDPG训练不稳定!用SAC(软性演员-评论家)算法搞定复杂环境强化学习 在机器人控制、自动驾驶仿真等连续控制任务中,强化学习算法的稳定性往往决定了项目成败。许多工程师都经历过这样的困境:使用DDPG(深度…...

mat-chem-sim-pred开发者指南:如何贡献新的科学计算算子
mat-chem-sim-pred开发者指南:如何贡献新的科学计算算子 【免费下载链接】mat-chem-sim-pred 面向工业领域,聚焦计算仿真、预测两大核心场景,构建面向流程工业"机理数据"双轮驱动的领域计算层,推动AI for Science在材料…...

前端工程化实战:代码规范、兼容性、调试与项目整合
前言学完 HTML 和 CSS 的核心知识后,如何写出规范、可维护、兼容性好的代码,并高效地调试和构建项目,是很多初学者的薄弱环节。本篇整合 代码书写规范、浏览器兼容性处理、Chrome DevTools 调试技巧、项目目录结构 以及 前端学习路径 等实用技…...

北京昌平浇筑阁楼测评:天顺诚达施工优但服务待提升,适合这类
本次测评聚焦于北京昌平区浇筑阁楼领域,旨在为对该服务感兴趣的人群提供客观、真实的数据和信息,帮助大家了解各相关企业的实际情况。参与本次测评的企业为北京天顺诚达建筑工程有限公司。需要声明的是,本次测评均基于真实数据与体验…...

Desktop Postflop:免费开源的德州扑克GTO求解器完整指南
Desktop Postflop:免费开源的德州扑克GTO求解器完整指南 【免费下载链接】desktop-postflop [Development suspended] Advanced open-source Texas Holdem GTO solver with optimized performance 项目地址: https://gitcode.com/gh_mirrors/de/desktop-postflop …...

MC/DC覆盖率:从原理到实战,破解100%覆盖率的迷思与挑战
1. 项目概述:当“完美”成为负担在软件测试领域,尤其是对安全关键系统(比如航空航天、汽车电子、医疗设备)的验证,我们常常听到一个词:100%覆盖率。这听起来像是一个终极目标,一个完美的终点。但…...

终极指南:使用免费开源工具SMUDebugTool解锁AMD Ryzen处理器全部性能 [特殊字符]
终极指南:使用免费开源工具SMUDebugTool解锁AMD Ryzen处理器全部性能 🚀 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power T…...

告别盲目添加LOCAL_LDFLAGS:深入理解Android NDK链接错误与libutils的正确引用姿势
深入解析Android NDK链接错误:从libutils引用看系统库的正确使用姿势 当你在Android NDK开发中遇到undefined symbol错误时,第一反应可能是寻找快速解决方案。网上常见的建议是添加-Wl,--unresolved-symbolsignore-all来绕过链接器检查,但这就…...

AI时代测试人员如何转型
某老板:开发已经用AI提升了数倍的效率与产出,那测试呢?如果测试在AI时代掉队了,那是不是不需要测试了?某测试人员:我折腾了大半个月的AI,AI根本没办法给测试人员提效,它就像个弱智一…...