论文阅读《Nougat:Neural Optical Understanding for Academic Documents》
摘要
科学知识主要存储在书籍和科学期刊中,通常以PDF的形式。然而PDF格式会导致语义信息的损失,特别是对于数学表达式。我们提出了Nougat,这是一种视觉transformer模型,它执行OCR任务,用于将科学文档处理成标记语言,并证明了我们的模型在新的科学文档数据集上的有效性。
引言
存储在pdf中的知识,信息提取有难度,其中数学表达式的语义信息会丢失。现有的OCR方法没有办法识别公式。为此,我们引入了Nougat,这是一种基于transformer的模型,能将文档页面的图像转换为格式化的标记文本。这篇论文的主要贡献如下:
1) 发布能够将PDF转换为轻量级标记语言的预训练模型;
2) 我们引入了一个将pdf转为标记语言的pipeline;
3) 我们的方法仅依赖于页面的图像,支持扫描的论文和书籍;
模型
以前的VDU(视觉文档理解)方法要么依赖于第三方OCR工具,要么专注于文档类型,例如:收据、发票或类似表单的文档。最近的研究表明,不需要外部OCR,在VDU中也能实现有竞争力的结果。
如图1所示,我们的模型基于donut构建,是一个encoder-decoder模型,允许端到端的训练。
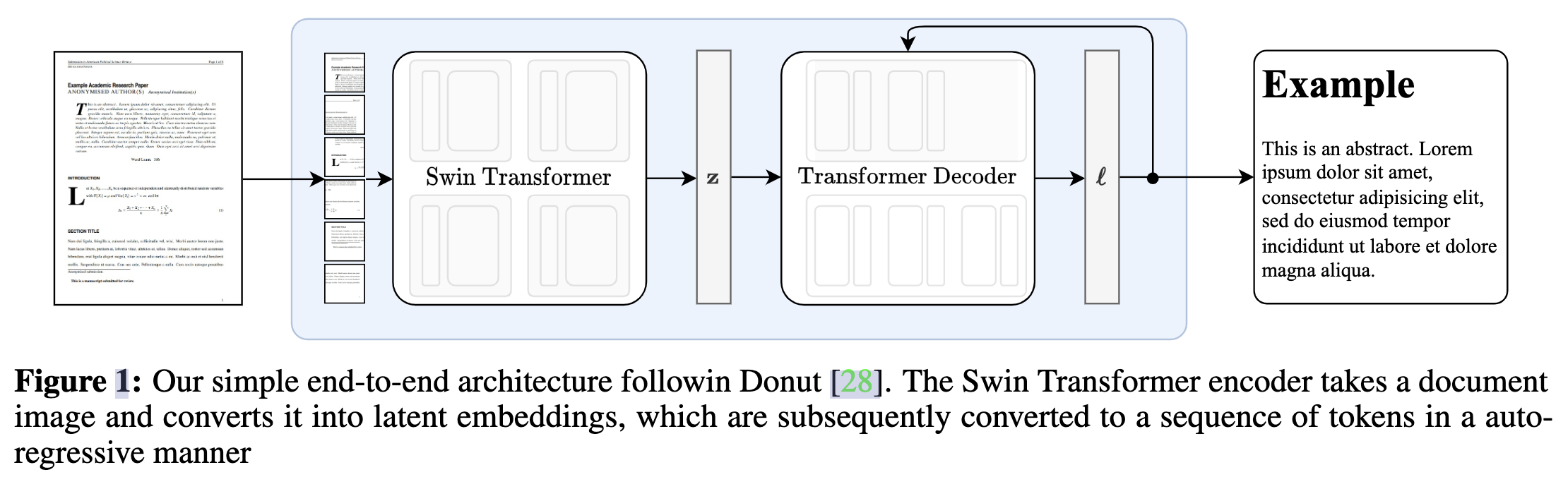
编码器
视觉encoder首先接受一张文档图像,裁剪边距并调整图像大小成固定的尺寸(H,W);如果图像小于矩形,那么增加额外的填充以确保每个图像具有相同的维度。我们使用了Swin Transformer,将图像分为不重叠的固定大小的窗口,然后应用一系列的自注意力层来聚集跨窗口的信息。该模型输出一个embedding patch ,其中d是隐层维度,N是patch的数目。
解码器
使用带有cross-attention的mBART解码器解码,然后生成一系列tokens,最后tokens被投影到vocabulary的大小,产生logits。我们使用作为decoder;
SetUP
我们用96 DPI的分辨率渲染文档图像。由于swin transformer的限制性,我们将input size设置为(896,672);文档图像先resize,然后pad到所需的大小,这种输入大小允许我们使用Swin基础模型架构。我们用预训练的权重初始化了模型,Transformer解码器的最大序列长度是4096。这种相对较大的规模是因为学术研究论文的文本可能是密集的,尤其表格的语法是token密集的。BART解码器是一个10层的decoder-only transformer。整个架构共有350M参数;在推理的时候,文本使用greedy decoding生成的。
训练:使用AdamW优化器训练3个epoch,batch_size是192;初始化学习率是;
数据增强
在图像识别任务中,使用数据增强来提高泛化性是有效的。由于我们的训练集只有学术论文,所以我们需要应用一系列的transformation来模拟扫描文档的缺陷和可变性。这些变换包括:腐蚀,膨胀,高斯噪声,高斯模糊,位图转换,图像压缩,网格失真和弹性变换。每个都有一个固定的概率来应用给给定图像。每个转换的效果如图所示:

在训练过程中,我们会用随机替换token的方式给groud truth增加扰动。
数据
目前没有pdf页面和其对应的source code的成对数据集。因为我们根据arxiv上的开源文章,建立了自己的数据集。对于layout多样性,我们引入了PMC开源非商业数据集的子集。在预训练过程中,也引入了一部分行业文档库数据。
ARXIV
我们从arxiv上收集了174w+的pape,收集其源代码并编译pdf。为了保证格式的一致性,我们首先用latex2html处理源文件,并将他们转为html文件。这一步很重要,因为他们是标准化的并且去掉了歧义,尤其是在数学表达式中。转换过程包括:替换用户定义的宏,添加可选括号,规范化表以及用正确的数字替换引用。然后我们解析html文件,并将他们转换为轻量级标记语言,支持标题,粗体和斜体文本、公式,表等各种元素。这样,我们能保证源代码格式是正确的,方便后续处理。整个过程如图所示:

PMC
我们还处理了来自PMC的文章,其中除了PDF文件之外,还可以获得具有语义信息的XML文件。我们将这些文件解析为与arxiv文章相同的标记语言格式,我们选择使用PMC少得多的文章,因为XML文件并不总是具有丰富的语义信息。通常,方程和表格存储为图像,这些情况检测起来并非易事,这导致我们决定将PMC文字的使用限制在预训练阶段。
IDL
IDL是行业产生的文档集合。这个仅用在预训练阶段,用于教模型基本的OCR;
分页
我们根据pdf的页中断来分割markdown标记,然后将每个pdf页面转为图像,来获得图像-标记pair。在编译过程中,Latex会自动确定pdf的页面中断。由于我们没有重新编译每篇论文的Latex源,我们必须启发式地将源文件拆分为对应不同页面的部分。为了实现这一点,我们使用PDF页面上的嵌入文本和源文本进行匹配。
然而,PDF中的图像和表格可能不对应他们在源代码中的位置。为了解决这个问题,我们在预处理阶段去掉了这些元素。然后将识别的标题和XML文件中的标题进行比较,并根据他们的Levenshtein距离进行匹配。一旦源文档被分成单个页面,删除的图形和表格就会在每个页面的末尾重新插入。
相关文章:
论文阅读《Nougat:Neural Optical Understanding for Academic Documents》
摘要 科学知识主要存储在书籍和科学期刊中,通常以PDF的形式。然而PDF格式会导致语义信息的损失,特别是对于数学表达式。我们提出了Nougat,这是一种视觉transformer模型,它执行OCR任务,用于将科学文档处理成标记语言&a…...

较难的换根dp:P6213 「SWTR-04」Collecting Coins
传送门 前题提要:感觉这道换根dp可以说是集中了换根dp的所有较高难度的操作和思想,以及较高的一些实现细节,可以说能够完全写出这道题才叫真正理解了换根dp,非常值得一做. 首先读完题意,不难发现这道题有很多限制.点的访问次数限制,必须访问某一个点,想要获得最大的贡献,没有…...

Springboot - 15.二级分布式缓存集成-Caffeine
👀中文文档 Caffeine 👀使用Caffeine (本地缓存) 当与Spring Boot结合使用时,Caffeine提供了一个直观且功能强大的二级缓存解决方案。Spring Boot的缓存抽象使得整合Caffeine变得相当简单。以下是如何在Spring Boot…...
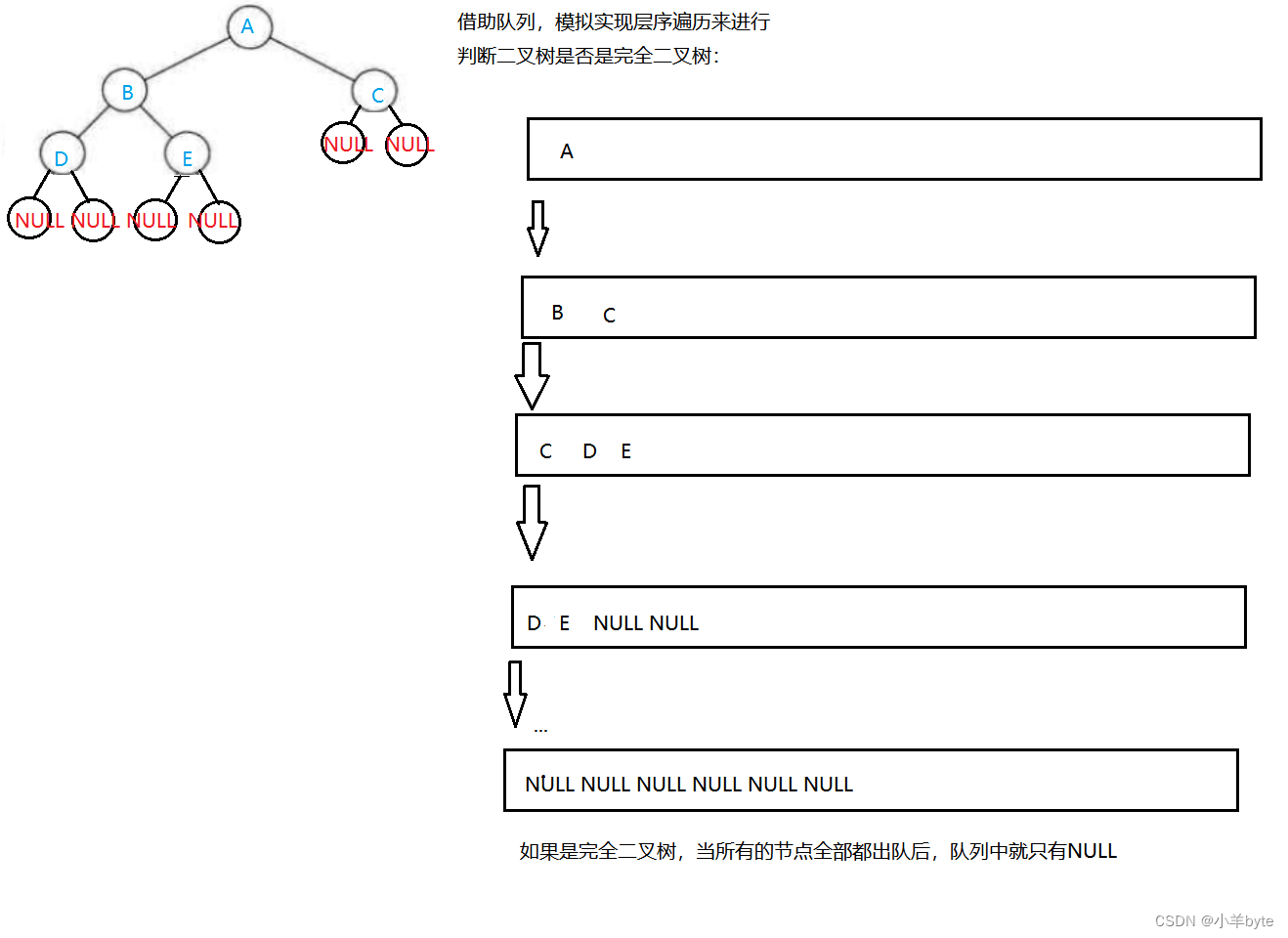
二叉树的介绍及二叉树的链式结构的实现(C语言版)
前言 二叉树是一种特殊的树,它最大的度为2,每个节点至多只有两个子树。它是一种基础的数据结构,后面很多重要的数据结构都是依靠它来进行实现的。了解并且掌握它是很重要的。 目录 1.二叉树的介绍 1.1概念 1.2现实中的二叉树 1.3特殊的二叉…...
不同写法的性能差异
“ 达到相同目的,可以有多种写法,每种写法有性能、可读性方面的区别,本文旨在探讨不同写法之间的性能差异 len(str) vs str "" 本部分参考自: [问个 Go 问题,字符串 len 0 和 字符串 "" ,有啥区别?](https://segmentf…...

Bytebase 2.7.0 - 新增分支(Branching)功能
🚀 新功能 新增支持与 Git 类似的分支(Branching)功能来管理 schema 变更。支持搜索所有历史工单。支持导出审计日志。 🎄 改进 变更数据库工单详情页面全新改版。优化工单搜索体验。SQL 审核规则支持针对不同数据库进行独立配…...

day55 动规.p15 子序列
- 392.判断子序列 cpp class Solution { public: bool isSubsequence(string s, string t) { vector<vector<int>> dp(s.size() 1, vector<int>(t.size() 1, 0)); for (int i 1; i < s.size(); i) { for (int j 1; …...

TypeScript DOM类型的声明
TS DOM类型的声明 lib.dom.d.ts HTMLInputElement <input type"text" change"handleChange" /> const handleChange (evt: Event) > {console.log((evt.target as HTMLInputElement).value); } HTMLElement const div: HTMLDivElement do…...
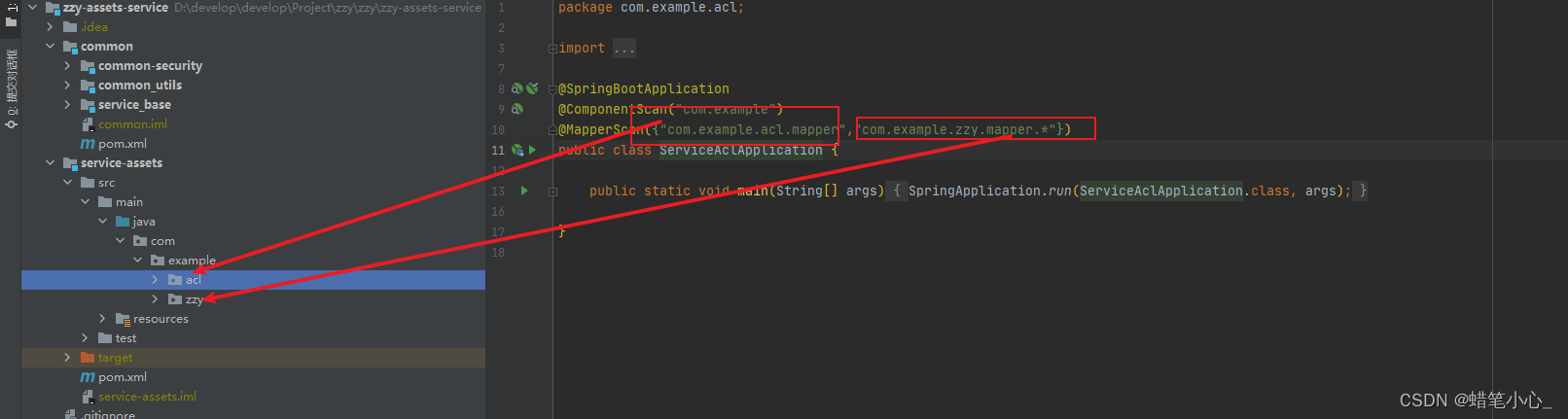
springboot找不到注册的bean
1、错误描述 A component required a bean named ‘fixedAssetsShareMapper’ that could not be found.Action:Consider defining a bean named ‘fixedAssetsShareMapper’ in your configuration.2、问题分析 1、该错误提示表明在你的应用程序中有一个组件(可能…...
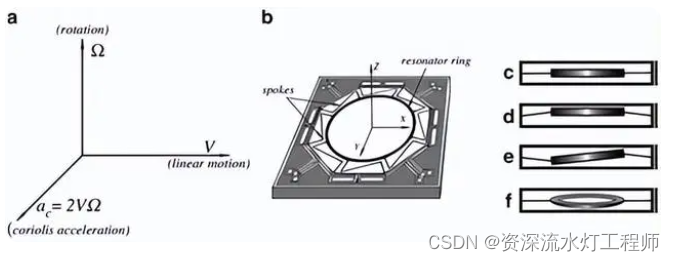
MEMS传感器的原理与构造——单片式硅陀螺仪
一、前言 机械转子式陀螺仪在很长的一段时间内都是唯一的选项,也正是因为它的结构和原理,使其不再适用于现代小型、单体、集成式传感器的设计。常规的机械转子式陀螺仪包括平衡环、支撑轴承、电机和转子等部件,这些部件需要精密加工和…...
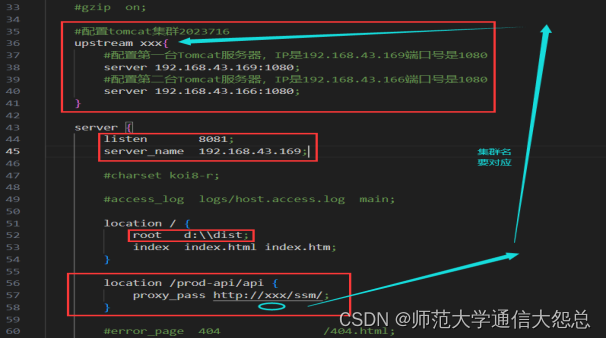
Redis集群服务器
集群简介 试想有一家餐厅,如果顾客人数较少,那么餐厅只需要一个服务员即可,如图1。但是,当顾客人数非常多时,一个服务员是绝对不够的,如图2。此时,餐厅需要雇用更多的服务员来解决大量访问&…...

动态维护直径 || 动态维护树上路径 || 涉及LCA点转序列 || 对欧拉环游序用数据结构维护:1192B
https://www.luogu.com.cn/problem/CF1192B 对于直径的求法,常用dp或两次dfs,但如果要动态维护似乎都不太方面,那么可以维护树上路径最大值。 树上路径为: d e p u d e p v − 2 d e p l c a ( u , v ) dep_udep_v-2\times de…...
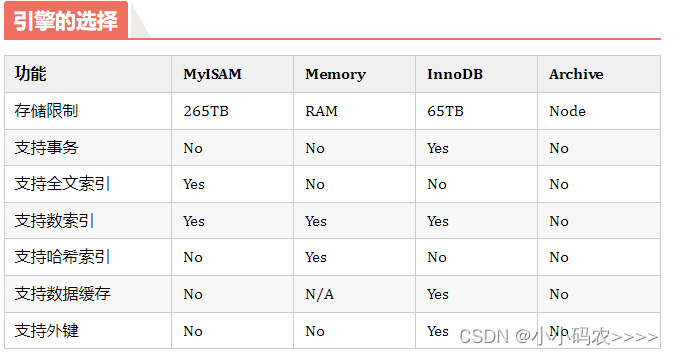
MySQL 存储引擎,你了解几个?
引言 MySQL是一种流行的关系型数据库管理系统(RDBMS),它支持多种不同的数据库引擎。数据库引擎是用于存储、管理和检索数据的核心组件,它们直接影响着数据库的性能、可靠性和功能,接下来本文介绍下一些常见的MySQL数据…...

Java 动态规划 Leetcode 740. 删除并获得点数
题目 对于该题的题目分析,已经代码分析都一并写入到了代码注释中 代码 class Solution {public int deleteAndEarn(int[] nums) {//核心思路://由于我们获得 nums[i] 的点数之后,就必须删除所有等于 nums[i] - 1 和 nums[i] 1 的元素//假设…...

算法通关村十三关-青铜:数字与数学基础问题
1.数字统计专题 统计特定场景下的符号或数字个数等 1.1符号统计 LeetCode1822 数组元素积的符号 https://leetcode.cn/problems/sign-of-the-product-of-an-array/description/ 思路分析 如果将所有的数都乘起来,再判断正负,工作量大,还…...
猜拳游戏小程序源码 大转盘积分游戏小程序源码 积分游戏小程序源码
简介: 猜拳游戏大转盘积分游戏小程序前端模板源码,一共五个静态页面,首页、任务列表、大转盘和猜拳等五个页面 图片:...

【Python】爬虫练习-爬取豆瓣网电影评论用户的观影习惯数据
目录 前言 一、配置环境 1.1、 安装Python 1.2、 安装Requests库和BeautifulSoup库 1.3.、安装Matplotlib 二、登录豆瓣网(重点) 2.1、获取代理 2.2、测试代理ip是否可用 2.3、设置大量请求头随机使用 2.4、登录豆瓣网 三、爬取某一部热门电影…...

webpack基础配置【总结】
webpack打包原理: webpack是一个js应用程序的静态模块打包工具,当webpack处理应用程序时,它的内部构建一个依赖图,此时依赖会映射项目中所需的每个模块,并生成一个或多个bundle包。因此我们会安装配置各种打包规则&…...

typescript 支持与本地调试
typescript 支持与本地调试 typescript 支持与本地调试 前言支持 typescript函数的本地调试 启用 node-terminal 调试invoke localserverless-offline Next Chapter完整示例及文章仓库地址 前言 在上一章节,我们创建了一个 hello world 函数,并把它顺…...

后端面试话术集锦第 十八 篇:JVM面试话术
这是后端面试集锦第十八篇博文——JVM面试话术❗❗❗ 1. 介绍下JVM JVM主要包括:类加载器(class loader)、执行引擎(exection engine)、本地接口(native interface)、运行时数据区(Runtimedata area) 类加载器:加载类文件到内存。Class loader只管加载,只要符合文件…...

【Perplexity AI高手速成指南】:20年AI工程师亲授7大核心技能与3个避坑红线
更多请点击: https://kaifayun.com 第一章:Perplexity AI平台核心架构与能力边界 Perplexity AI 并非传统意义上的开源模型托管平台,而是一个以“答案溯源”为设计哲学的智能问答引擎。其底层融合了多阶段检索增强生成(RAG&#…...

SharpCompress实战:一个方法搞定C#里ZIP压缩打包,附赠RAR/7Z解压和TAR.GZ创建教程
C#压缩解压全能手册:用SharpCompress玩转ZIP/RAR/7Z/TAR.GZ 在开发日志管理系统、文件上传模块或数据备份工具时,文件压缩解压功能就像空气一样不可或缺。但面对ZIP、RAR、7Z、TAR.GZ这些格式各异的压缩包,不少开发者都会陷入API选择的困境。…...

用STM32G431RBT6复刻一个简易示波器+信号发生器:蓝桥杯嵌入式外设综合应用实战
基于STM32G431RBT6的嵌入式示波器与信号发生器开发实战 在嵌入式系统开发领域,将理论知识转化为实际应用能力是每个工程师成长的必经之路。本文将带你使用STM32G431RBT6开发板,从零开始构建一个兼具示波器和信号发生器功能的综合系统。这个项目不仅能够…...

无王无帝定乾坤,来自田间第一人 大道济世安苍生
无王无帝定乾坤来自田间第一人 一、执念 千秋岁月轮转,历朝治乱兴衰,世人始终困于一个执念:天下安定,必靠帝王君临、强权统御。可纵观古今世道,王权更迭往复,霸业起落无常,真正能长久安社稷、润…...

字节会师何恺明!开源连续扩散语言模型Cola DLM
一水 发自 凹非寺量子位 | 公众号 QbitAI大语言模型真的只能走“预测下一个token”的路子吗?继何恺明之后,字节也给出了同样的回答:NO。并且,两边都不约而同地盯上了同一个方向——在连续语义空间中建模语言。更关键的是ÿ…...
)
别再只用Leaflet了!Mapbox GL JS加载本地MVT矢量瓦片保姆级教程(附避坑点)
从Leaflet到Mapbox GL JS:解锁MVT矢量瓦片的进阶玩法 当传统WebGIS开发者第一次看到Mapbox GL JS渲染的矢量瓦片地图时,那种震撼感不亚于从黑白电视切换到4K HDR。Leaflet就像一把可靠的瑞士军刀,而Mapbox GL JS则像一套专业厨房设备——当你…...

STM32 FOC SDK V3.2深度解析:从模块架构到PI整定实战
1. 项目概述:从零到一,理解ST官方FOC SDK的实战价值 如果你正在用STM32做电机控制,尤其是永磁同步电机(PMSM),那么ST官方发布的PMSM FOC SDK(Software Development Kit)绝对是你绕不…...

【亲测免费】 工业自动化+Modbus通讯协议+libmodbus开源库+Windows x64编译教程
工业自动化Modbus通讯协议libmodbus开源库Windows x64编译教程 【下载地址】工业自动化Modbus通讯协议libmodbus开源库Windowsx64编译教程 本资源适用于使用libmodbus开源库进行数据通信过程中的环境搭建过程。由于最新版本的libmodbus并不能通过官网提供的教程实现Windows下的…...

探索商业成功的奥秘:BABOK Guide v3深度解析
探索商业成功的奥秘:BABOK Guide v3深度解析 【下载地址】商业分析知识体系指南BABOKGuidev3 《商业分析知识体系指南(BABOK Guide v3)》是业界权威的商业分析专业标准,深受全球专业人士的认可与信赖。本指南经过严密的共识驱动开…...

3步掌握LRC歌词制作:开源工具的终极实践指南
3步掌握LRC歌词制作:开源工具的终极实践指南 【免费下载链接】lrc-maker 歌词滚动姬|可能是你所能见到的最好用的歌词制作工具 项目地址: https://gitcode.com/gh_mirrors/lr/lrc-maker 还在为制作精准同步的歌词文件而烦恼吗?传统歌词…...