Elasticsearch 中的向量搜索:设计背后的基本原理
作者:ADRIEN GRAND
实现向量数据库有不同的方法,它们有不同的权衡。 在本博客中,你将详细了解如何将向量搜索集成到 Elastisearch 中以及我们所做的权衡。
你有兴趣了解 Elasticsearch 用于向量搜索的特性以及设计是什么样子吗? 一如既往,设计决策有利有弊。 本博客旨在详细介绍我们如何选择在 Elasticsearch 中构建向量搜索。
向量搜索通过 Apache Lucene 集成到 Elasticsearch 中
首先是有关 Lucene 的一些背景知识:Lucene 将数据组织成定期合并的不可变段。 添加更多文档需要添加更多段。 修改现有文档需要自动添加更多段并将这些文档的先前版本标记为已删除。 段内的每个文档都由文档 ID 标识,文档 ID 是该文档在段内的索引,类似于数组的索引。 这种方法的动机是管理倒排索引,倒排索引不擅长就地修改,但可以有效地合并。
除了倒排索引之外,Lucene 还支持存储字段(文档存储)、文档值(列式存储)、术语向量(每个文档的倒排索引)以及段中的多维点。 向量已以相同的方式集成:
- 新向量在索引时缓冲到内存中。
- 当超出索引时间缓冲区的大小或必须使更改可见时,这些内存中的缓冲区将被序列化为段的一部分。
- 分段会在后台定期合并在一起,以控制分段总数并限制每个分段的整体搜索时间开销。 由于它们是段的一部分,因此向量也需要合并。
- 搜索必须组合索引中所有段的顶部向量命中(top vector hits)。
- 对向量的搜索必须查看实时文档集,以便排除 token 为已删除的文档。
上面的系统是由 Lucene 的工作方式驱动的。
Lucene 目前使用分层可导航小世界 (Hierachical Navigable Small World - HNSW) 算法来索引向量。 在较高层次上,HNSW 将向量组织成一个图表(graph),其中相似的向量可能会连接起来。 HNSW 是向量搜索的热门选择,因为它相当简单,在向量搜索算法的比较基准上表现良好,并且支持增量插入。 Lucene 对 HNSW 的实现遵循 Lucene 将数据保留在磁盘上并依靠页面缓存来加速对频繁访问的数据的访问的准则。
近似向量搜索通过 knn 部分在 Elasticsearch 的 _search API 中公开。 使用此功能将直接利用 Lucene 的向量搜索功能。 向量还集成在 Elasticsearch 的脚本 API 中,允许执行精确的强力搜索(exact brute force search),或利用向量进行重新评分。
现在让我们深入探讨通过 Apache Lucene 集成向量搜索的优缺点。
缺点
利用 Apache Lucene 进行向量搜索的主要缺点是 Lucene 将向量与段联系起来。 然而,正如我们稍后将在 “优点” 部分中看到的,将向量与段联系起来也是实现高效预过滤、高效混合搜索和可见性一致性等主要功能的原因。
合并需要重新计算 HNSW 图
段合并需要采用 N 个输入段(默认合并策略通常为 10 个),并将它们合并为单个段。 Lucene 当前从没有删除的最大输入段创建 HNSW 图的副本,然后将来自其他段的向量添加到此 HNSW 图。 与在索引的生命周期内就地改变单个 HNSW 图相比,这种方法会产生索引时间开销,因为段是合并的。
搜索需要合并多个细分的结果
由于索引由多个段组成,因此搜索需要计算每个段上的 top-k 向量,然后将这些每个段的 top-k 命中合并为全局 top-k 命中。 通过并行搜索段可以减轻对延迟的影响,但与搜索单个 HNSW 图相比,这种方法仍然会产生一些开销。
RAM 需要随着数据集的大小进行扩展以保持最佳性能
遍历 HNSW 图会产生大量随机访问。 为了高效执行,数据集应适合页面缓存,这需要根据所管理的向量数据集的大小调整 RAM 的大小。 除了 HNSW 之外,还存在其他用于向量搜索的算法,它们具有更适合磁盘的访问模式,但它们也有其他缺点,例如更高的查询延迟或更差的召回率。
优点
数据集可以扩展到超出 RAM 总大小
由于数据存储在磁盘上,Elasticsearch 将允许数据集大于本地主机上可用的 RAM 总量,并且随着页面缓存中可容纳的 HNSW 数据比例的降低,性能将会下降。 如上一节所述,注重性能的用户需要根据数据集的大小来调整 RAM 大小,以保持最佳性能。
无锁搜索
就地更新数据结构的系统通常需要加锁,以保证并发索引和搜索下的线程安全。 Lucene 基于段的索引从不需要在搜索时锁定,即使在并发索引的情况下也是如此。 相反,索引所组成的段集会定期以原子方式更新。
支持增量更改
可以随时添加、删除或更新新向量。 其他一些近似最近邻搜索算法需要提供整个向量数据集。 然后,一旦提供了所有向量,就执行索引训练步骤。 对于这些其他算法,对向量数据集的任何重大更新都需要再次完成训练步骤,这可能会导致计算成本高昂。
与其他数据结构的可见性一致性
在如此低的级别集成到 Lucene 的一个好处是,在查看索引的时间点视图时,我们可以与其他开箱即用的数据结构保持一致。 如果你执行文档更新以更新其向量和某些其他关键字字段,则并发搜索保证会看到向量字段的旧值和关键字字段的旧值 - 如果时间点 视图是在更新之前创建的,或者是向量场的新值和关键字字段的新值(如果时间点视图是在更新之后创建的)。 同样,对于删除,如果文档被标记为已删除,那么包括向量存储在内的所有数据结构都将忽略它,或者如果它们对删除之前创建的时间点视图进行操作,则它们将看到它。
增量快照
向量是段的一部分,这一事实有助于快照通过利用两个后续快照通常共享其大部分段(尤其是较大的段)的事实来保持增量。 使用就地更改的单个 HNSW 图不可能实现增量快照。
过滤和混合支持
直接集成到 Lucene 中还可以与其他 Lucene 功能高效集成,例如使用任意 Lucene 过滤器预过滤向量搜索或将来自向量查询的命中与来自传统全文查询的命中组合起来。
通过拥有自己的与段关联的 HNSW 图,并且其中节点由文档 ID 索引,Lucene 可以就如何最好地预过滤向量搜索做出有趣的决定:要么通过线性扫描与过滤器匹配的文档(如果有选择性), 或者通过遍历图并仅考虑与过滤器匹配的节点作为 top-k 向量的候选节点。
与其他功能的兼容性
由于向量存储与任何其他 Lucene 数据结构一样,因此许多功能与向量和向量搜索自动兼容,包括:
- 聚合
- 文档级安全性
- 字段级安全
- 索引排序
- 通过脚本访问向量(例如,从 script_score 查询或重新排序)
展望未来:索引和搜索分离
正如另一篇博客中所讨论的,Elasticsearch 的未来版本将在不同的实例上运行索引和搜索工作负载。 该实现本质上看起来就像你不断在索引节点上创建快照并在搜索节点上恢复它们。 这将有助于防止向量索引的高成本影响搜索。 使用单个共享 HNSW 图而不是多个段来实现索引和搜索的这种分离是不可能的,除非每次需要在新搜索中反映更改时通过网络发送完整的 HNSW 图。
结论
总的来说,Elasticsearch 提供了出色的向量搜索功能,并与其他 Elasticsearch 功能集成:
- 向量搜索可以通过任何支持的过滤器进行预过滤,包括最复杂的过滤器。
- 向量命中可以与任意查询的命中相结合。
- 向量搜索与聚合、文档级安全性、字段级安全性、索引排序等兼容。
- 包含向量的索引仍然遵循与其他索引相同的语义,包括 _refresh、_flush 和 _snapshot API。 它们还将支持无状态 Elasticsearch 中索引和搜索的分离。
这是以一些索引时间和搜索时间开销为代价完成的。 也就是说,向量搜索通常仍然以数十或数百毫秒的数量级运行,并且比强力精确搜索快得多。 更一般地说,与现有比较基准*中的其他向量存储相比,索引时间和搜索时间开销似乎都是可控的(查找 “luceneknn” 行)。 我们还相信,通过将向量搜索与其他功能相结合,可以释放向量搜索的许多价值。 此外,我们建议你查看 KNN 搜索调整指南,其中列出了许多有助于减轻上述缺点的负面影响的措施。
我希望你喜欢这个博客。 如果你有疑问,请随时通过讨论与我们联系。 你可以随意在现有部署中尝试向量搜索,或者在 Elastic Cloud 上免费试用 Elasticsearch Service(始终具有最新版本的 Elasticsearch)。
*在撰写本文时,这些基准测试尚未利用向量化。 有关向量化的更多信息,请阅读此博客。
本文中描述的任何特性或功能的发布和时间安排均由 Elastic 自行决定。 当前不可用的任何特性或功能可能无法按时交付或根本无法交付。
原文:Vector search in Elasticsearch: The rationale behind the design — Elastic Search Labs
相关文章:
Elasticsearch 中的向量搜索:设计背后的基本原理
作者:ADRIEN GRAND 实现向量数据库有不同的方法,它们有不同的权衡。 在本博客中,你将详细了解如何将向量搜索集成到 Elastisearch 中以及我们所做的权衡。 你有兴趣了解 Elasticsearch 用于向量搜索的特性以及设计是什么样子吗? …...

Jquery会议室布局含门入口和投影位置调整,并自动截图
一、关于下载 1、文章中罗列了主要代码,如需使用,请前往CSDN下载进行下载,包中包含所有文件素材,开箱即用 2、下载链接:https://download.csdn.net/download/zlxls/88305636 二、有这么一个需求 1、会场进行布局&a…...
)
高精度乘法模板(fft)
正常高精度复杂度是o(n^2),fft复杂度o(nlogn) #define int long long//__int128 2^127-1(GCC) #define PII pair<int,int> #define f first #define s second using namespace std; const int inf 0x3f3f3f3f3f3f3f3f, N 3e5 5, mod 1e9 7; const doubl…...

C# 现状简单说明
文章目录 环境框架图形界面后端游戏 环境 .net framework 老版本.net版本,只能在windows环境下运行 .net core 新版.net版本。可以跨linux,mac平台运行 框架 图形界面 Winfrom 很老的图形界面。特点是丑,但是能用,学起来快 WPF 使用Xaml…...
)
el-table滚动加载、懒加载(自定义指令)
我们在实际工作中会遇到这样的问题: 应客户要求,某一个列表不允许分页。但是不分页的话,如果遇到大量的数据加载,不但后端响应速度变慢,前端的渲染效率也会降低,页面出现明显的卡顿。 那如何解决这个问题…...
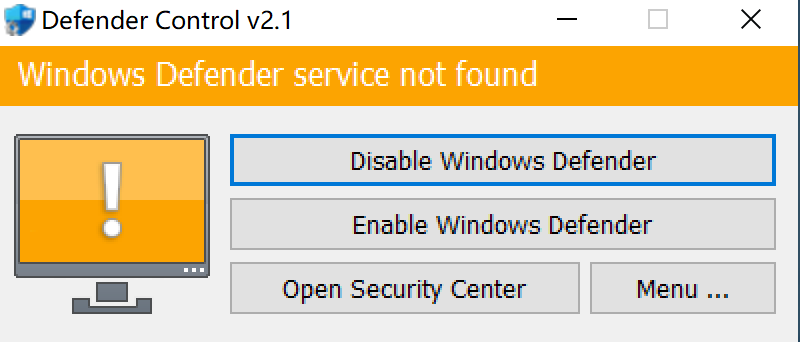
不关闭Tamper Protection(篡改保护)下强制卸载Windows Defender和安全中心所有组件
个人博客: xzajyjs.cn 背景介绍 由于微软不再更新arm版本的win10系统,因此只能通过安装insider preview的镜像来使用。而能找到的win10 on arm最新版镜像在安装之后由于内核版本过期,无法打开Windows安全中心面板了,提示如下: 尝…...

从一到无穷大 #13 How does Lindorm TSDB solve the high cardinality problem?
本作品采用知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议进行许可。 本作品 (李兆龙 博文, 由 李兆龙 创作),由 李兆龙 确认,转载请注明版权。 文章目录 引言优势挑战系统架构细节/优化存储引擎索引写入查询 经验Ablation Study总结 引言 …...

三维模型OBJ格式轻量化的纹理压缩和质量关系分析
三维模型OBJ格式轻量化的纹理压缩和质量关系分析 三维模型的OBJ格式通常包含纹理信息,而对纹理进行轻量化压缩可以减小文件大小和提高加载性能。然而,在进行纹理压缩时需要权衡压缩比率和保持质量之间的关系,并根据具体应用场景选择合适的压缩…...

【每日一题】54. 螺旋矩阵
54. 螺旋矩阵 - 力扣(LeetCode) 给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。 示例 1: 输入:matrix [[1,2,3],[4,5,6],[7,8,9]] 输出:[1,2,3,6,9,8,7,4,5…...
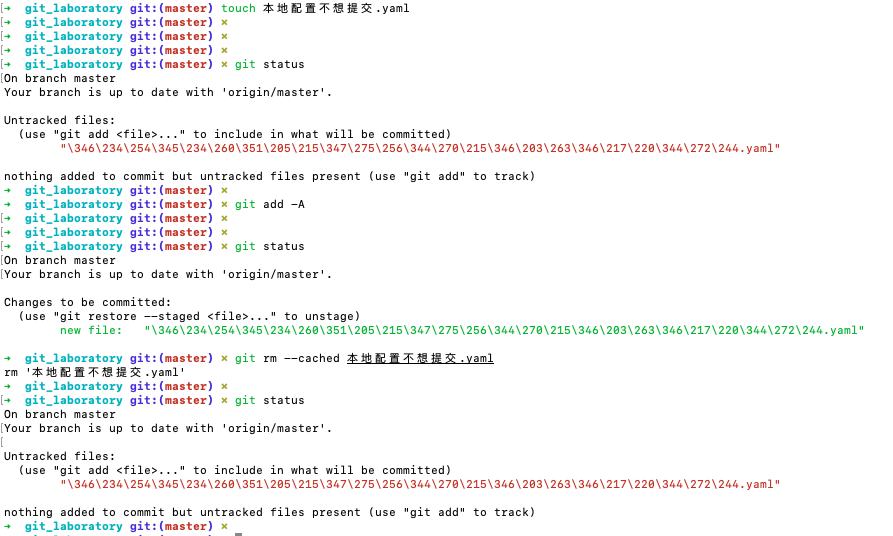
git:一些撤销操作
参考自 如何撤销 Git 操作?[1] 一、撤销提交 git revert HEAD 撤销上次提交. (会在当前提交后面,新增一次提交,抵消掉上一次提交导致的所有变化,所有记录都会保留) 二、撤销某次merge git merge --abort 三、替换上一次提交 git commit --ame…...

leetcode 209. 长度最小的子数组
题目链接:leetcode 209 1.题目 给定一个含有 n 个正整数的数组和一个正整数 target 。 找出该数组中满足其总和大于等于 target 的长度最小的 连续子数组 [numsl, numsl1, …, numsr-1, numsr] ,并返回其长度。如果不存在符合条件的子数组,…...

《rk3399:各显示接口的dts配置》
这里写目录标题 一、前言二、平台支持的显示接口三、两个VOP支持的最大输出分辨率四、VOPL的dts配置五、VOPB的dts配置六、display_subsystem的配置七、backlight 背光配置八、针对eDP接口的配置 以firefly为例8.1 原生配置8.2 启用eDP屏接口配置九、针对MIPI接口屏的配置 以fi…...

Python数据分析-Pandas
Pandas 个人笔迹,建议不看 import pandas as pd import numpy as npSeries类型 spd.Series([1,3,5,np.nan,6,8],index[a,b,c,d,e]) print(s) # 默认0-n-1,否则用index数组作行标 s.index s.value # array() s[a] &g…...

golang 多线程管理 -- chatGpt
提问: 用golang写一个启动函数 start(n) 和对应的停止函数stopAll(),. start函数功能:启动n个线程,线程循环打印日志,stopAll()函数功能:停止start启动的线程 以下是一个示例的Golang代码,其中包括 start…...

【Math】导数、梯度、雅可比矩阵、黑塞矩阵
导数、梯度、雅可比矩阵、黑塞矩阵都是与求导相关的一些概念,比较容易混淆,本文主要是对它们的使用场景和定义进行区分。 首先需要先明确一些函数的叫法(是否多元,以粗体和非粗体进行区分): 一元函数&…...

【C语言】——调试技巧
目录 编辑 ①前言 1.什么是Bug? 2.什么是调试? 2.1调试的基本步骤 2.2Release与Debug 3.常用快捷键 4.如何写出好的代码 4.1常见的coding技巧 👉assert() 👉const() const修饰指针: ①前言 调试是每个程序员都…...
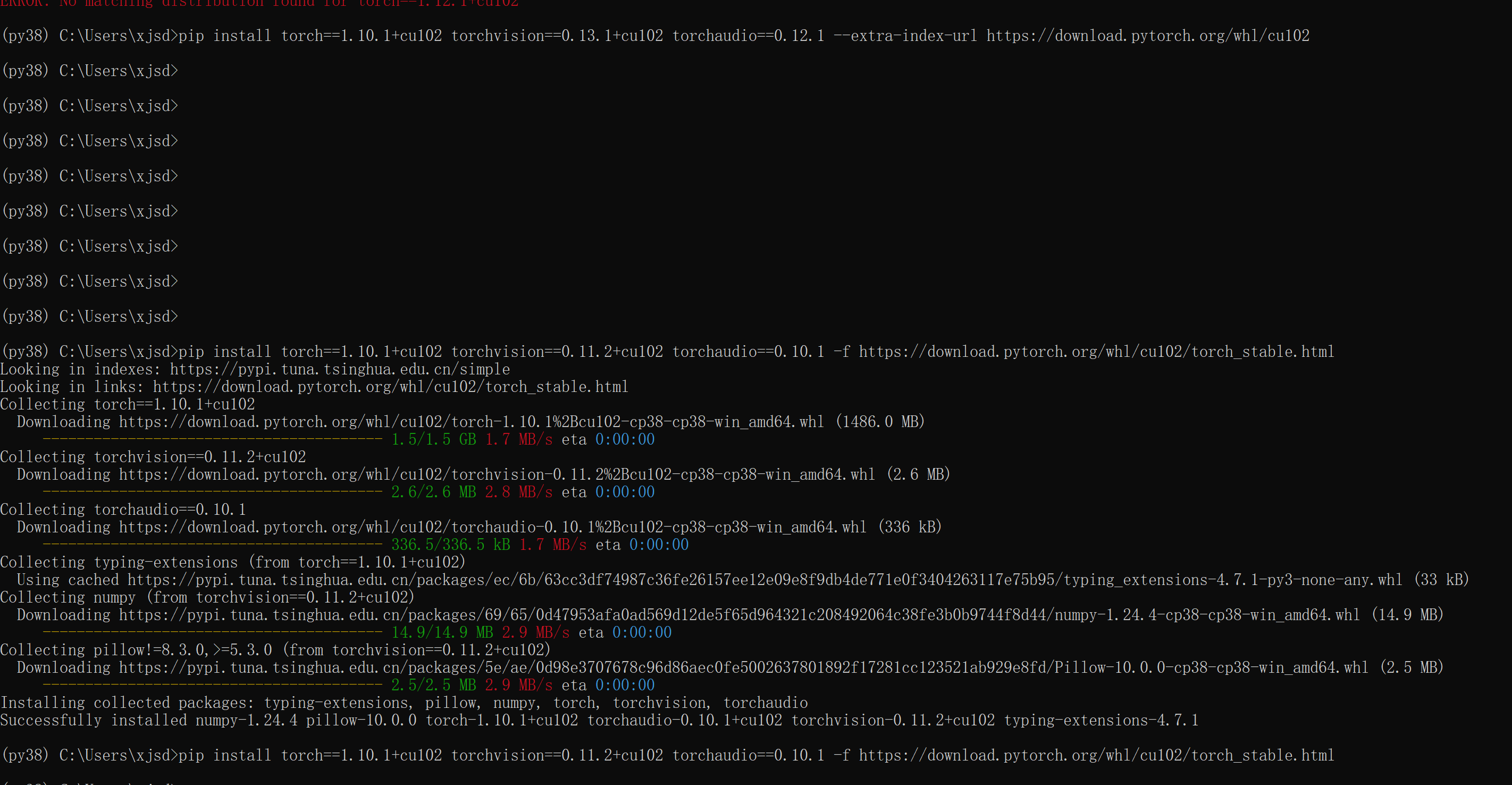
【Python】pytorch,CUDA是否可用,查看显卡显存剩余容量
CUDA可用,共有 1 个GPU设备可用。 当前使用的GPU设备索引:0 当前使用的GPU设备名称:NVIDIA T1000 GPU显存总量:4.00 GB 已使用的GPU显存:0.00 GB 剩余GPU显存:4.00 GB PyTorch版本:1.10.1cu102 …...

React16入门到入土
搭建环境 默认你已经安装好 node.js 安装 react 脚手架 学习的过程中,我们采用React官方出的脚手架工具 create-react-app npm install -g create-react-app如果提示没有权限,win 用户可以管理员打开终端,mac 用户 可以在前面加上 sudo …...
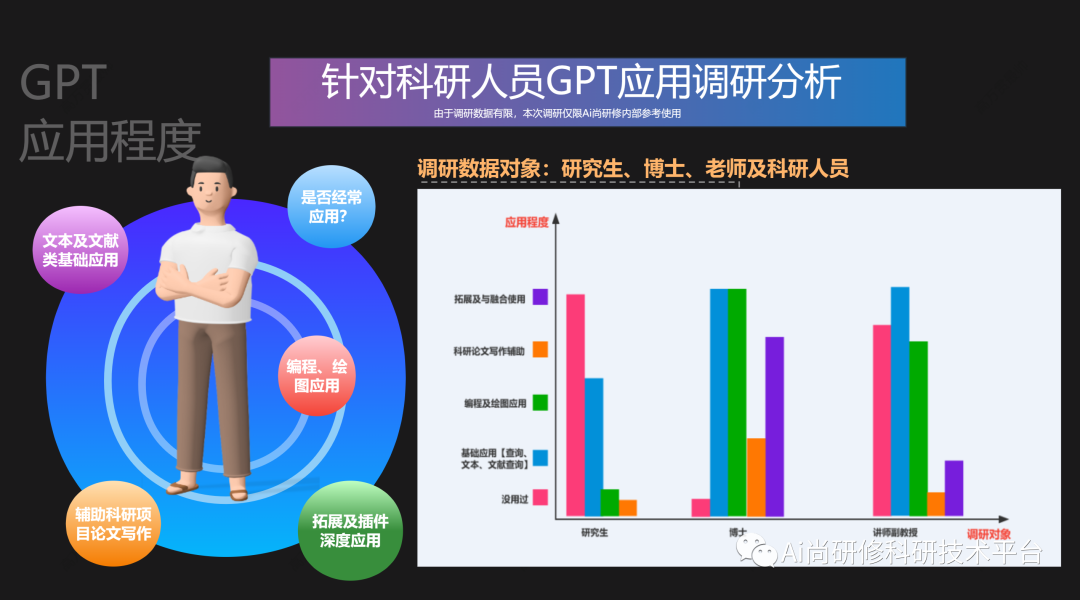
【GPT引领前沿】GPT4技术与AI绘图
推荐阅读: 1、遥感云大数据在灾害、水体与湿地领域典型案例实践及GPT模型应用 2、GPT模型支持下的Python-GEE遥感云大数据分析、管理与可视化技术 GPT对于每个科研人员已经成为不可或缺的辅助工具,不同的研究领域和项目具有不同的需求。例如在科研编程…...

【LeetCode】19. 删除链表的倒数第 N 个结点
19. 删除链表的倒数第 N 个结点(中等) 方法:快慢指针 思路 为了找到倒数第 n 个节点,我们应该先找到最后一个节点,然后从它开始往前数 n-1 个节点就是要删除的节点。 对于一般情况:设置 fast 和 slow 两个…...

从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界
从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界 在计算机科学中,浮点数的表示和处理是一个既基础又关键的话题。对于从事系统编程、性能优化或逆向工程的开发者来说,理解浮点数在内存中的实际存储形式不仅能帮…...

YimMenu终极配置指南:从零开始掌握GTA V高级菜单工具
YimMenu终极配置指南:从零开始掌握GTA V高级菜单工具 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMe…...

基于PIR传感器与LIFX智能灯泡的物联网运动感应照明系统实战
1. 项目概述与核心价值如果你对智能家居自动化感兴趣,并且想亲手打造一个既实用又有趣的照明项目,那么这个基于Adafruit FunHouse和LIFX智能灯泡的运动感应照明系统,绝对是一个绝佳的起点。它不仅仅是一个“开灯关灯”的简单触发器࿰…...

JetBrains IDE试用期重置终极指南:3种简单方法实现30天无限续杯
JetBrains IDE试用期重置终极指南:3种简单方法实现30天无限续杯 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 你是否在使用IntelliJ IDEA、PyCharm、WebStorm等JetBrains IDE时遇到过试用期突然结束…...

告别标题栏!在RK3568 Buildroot固件上,让你的Qt应用开机全屏显示的保姆级教程
RK3568嵌入式全屏实战:从Weston配置到Qt应用独占显示的完整指南 在嵌入式Linux系统开发中,GUI应用的全屏显示往往成为工程师面临的第一个"拦路虎"。当你在RK3568平台上精心开发的Qt应用启动后,却发现屏幕顶部顽固地挂着Weston窗口管…...

Vim-ai插件深度指南:在Vim中无缝集成AI提升开发效率
1. 项目概述:当Vim遇上AI,一场编辑器生产力的革命如果你和我一样,是个在终端里泡了十多年的老Vim用户,那你一定经历过这样的场景:面对一个复杂的函数重构,手指在键盘上飞舞,:s、%s、宏录制轮番上…...

基于CLUE与加速度计的鸡蛋坠落实验:从传感器数据到缓冲设计优化
1. 项目概述:用传感器数据为物理实验“上保险” 鸡蛋坠落实验,一个听起来就充满童年乐趣和“悲剧”风险的经典物理项目。它的核心挑战在于,如何设计一个缓冲装置,让一枚脆弱的生鸡蛋从高处坠落而不破裂。传统上,我们依…...

SoC片上系统:从架构原理到选型实战的深度解析
1. 项目概述:从“黑盒子”到“智慧核心”的认知跃迁在电子产品的世界里,我们常常惊叹于一部智能手机的纤薄与强大,它既能流畅播放高清视频,又能处理复杂的游戏画面,还能实时连接网络、定位导航。这一切的背后ÿ…...

ESP32接入ChatGPT API:构建本地化AIoT智能交互终端
1. 项目概述:当ESP32遇见ChatGPT,开启本地化智能交互新玩法最近在捣鼓ESP32开发板,总想着给它加点“智能”的料。传统的物联网项目,比如温湿度监测、远程控制开关,虽然实用,但总觉得少了点“灵魂”。直到我…...

汽车该多久换一代
汽车该多久换一代 买车的人其实不怕四年换代,怕的是刚提车半年就被新款打成旧款。李想这句话能引起讨论,原因也在这里:车企说的是研发验证周期,车主感受到的是价格、配置和二手残值。 汽车确实没法完全照着手机节奏跑。手机坏了可…...