【论文阅读】SCRFD: Sample and Computation 重分配的高效人脸检测
| 原始题目 | Sample and Computation Redistribution for Efficient Face Detection |
|---|---|
| 中文名称 | 采样和计算 重分配的 高效人脸检测 |
| 发表时间 | 2021年5月10日 |
| 平台 | ICLR-2022 |
| 来源 | Imperial College, InsightFace |
| 文章链接 | https://arxiv.org/pdf/2105.04714.pdf |
| 开源代码 | 官方实现:https://github.com/deepinsight/insightface |
摘要
尽管在 非受控(uncontrolled)人脸检测 方面已经取得了巨大的进展,但低计算成本和高精度的 高效人脸检测仍然是一个公开的挑战。本文指出 训练数据采样和计算分布策略(training data sampling and computation distribution strategies)是高效准确的人脸检测的关键。在这些观察的激励下,本文提出了两种简单但有效的方法:
(1) 样本再分配(Sample Redistribution (SR)),根据 benchmark 数据集的统计数据,为最需要的阶段 augments training samples;
(2) 计算重分配(Computation Redistribution (CR)),根据精心定义的搜索方法,在模型的 backbone, neck and head 之间重新分配计算。
在 WIDER FACE 数据集 上进行的大量实验表明,在广泛的计算系统中,所提出的 SCRFD家族 具有最先进的效率-精度权衡。特别是,SCRFD-34GF 比最好的竞争对手 TinaFace 的性能提高了 3.86% (AP at hard set),同时在具有 VGA 分辨率图像的 GPUs 上快了3倍以上。
6. 结论
本文提出一种 sample and computation redistribution 范式,用于高效的人脸检测。结果表明,与当前最先进的方法相比,所提出的 SCRFD 在各种计算模式下的精度和效率权衡有了显著提高。
1. 引言
4. 方法
基于上述对 TinaFace 的分析,以及后续细致的实验,我们在人脸检测设计上提出了以下效率改进:
(1) 以 VGA 分辨率(640) 为界限的测试尺度,
(2) 在 stride 4 的特征图上没有放置 anchor 。
特别地,我们在 stride 8 的特征图上放置了 {16,32} 的 anchors ,在 stride 16 上放置了 {64,128} 的 anchors,在 stride 32 上放置了 {256, 512} 的 anchors。由于我们的测试的 尺度 较小,大多数人脸将在 stride 8 上进行预测。
本文首先研究了 positive training samples 在不同特征图尺度上的再分布(第4.1节)。在给定预定义的计算预算的情况下,探索不同尺度的特征图以及不同组件(即 backbone, neck and head )的计算重分配(第4.2节)。
4.1. Sample Reallocation 样本重分配
stride 8 的特征图在我们的设置中是最重要的。这在 图3 中很明显,我们在 WIDER FACE validation dataset 上绘制了累积的人脸尺度分布。当测试尺度固定为 640 像素时,78.93% 的人脸小于 32 × 32。
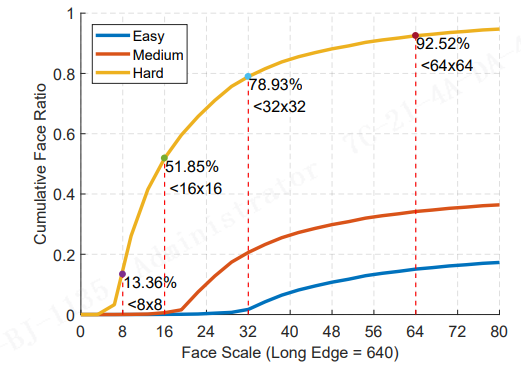
图3。在 WIDER FACE validation dataset (Easy ⊂ Medium ⊂ Hard) 上的累积人脸尺度分布。当长边固定为 640像素 时,大多数 easy faces 大于32×32,大多数 medium faces 大于16 × 16。对于 hard faces ,78.93%的人脸小于32 × 32, 51.85%的人脸小于16×16, 13.36% 的人脸小于8×8。
在 training data augmentation, 从原始图像的短边 集合[0.3,1.0] 中随机大小的方形块被裁剪。为了为 stride 8 生成更多的 positive samples ,我们将随机大小范围从 [0.3,1.0] 扩大到 [0.3,2.0] 。当裁剪框超过原始图像时,平均RGB值 填充缺失的像素。 如图4(a)所示,使用所提出的大裁剪策略后,在 32 的尺度以下有更多的 faces 。此外,即使会有更多非常小的 faces (例如< 4 × 4), 在大裁剪策略下,这些 ground-truth faces 在训练过程中会因 anchor 匹配不成功而被忽略。如图4(b)所示,在 16 的尺度上,一个 epoch 内的 positive anchors 显著增加,从 72.3K 增加到 118.3K,在 32的尺度 上显著增加,从95.9K 增加到 115.1K。通过将更多的 training samples 重新分布到小尺度上,可以更充分地训练 检测 tiny faces 的分支。
就是使用了 大裁剪策略 。
4.2. Computation Redistribution 计算重分配
直接利用 分类网络的 backbone 进行特定尺度的人脸检测可能是次优的。因此,我们采用 网络结构搜索[27] 来重新分配 backbone, neck and head 的计算,以适应各种不同的 flop 计划。将所提出的搜索方法应用于 RetinaNet[18],以ResNet[12]为 backbone ,Path Aggregation Feature Pyramid Network (PAFPN)[21]为 neck ,堆叠的 3 × 3 卷积层为 head 。虽然总体结构很简单,但搜索空间中可能的网络总数是难以处理的。在第一步中,探讨了在固定 neck and head 组件时,backbone 部分(即 stem、C2、C3、C4 和 C5 )内计算的重新分配。基于发现的 backbone 上的优化计算分布,进一步探索了计算在 e backbone, neck and head 的重新分配。通过这两种方式的优化,实现了人脸检测的最终优化网络设计。
看起来这里所谓的计算重新分配就是,通过 NAS 搜出来一个网络架构。
Computation search space reduction
本文的目标是通过 重新分配计算,设计更好的网络来进行高效的人脸检测。给定固定的计算成本,以及 图3 所示的人脸尺度分布,我们从模型的总体中探索计算分布和性能之间的关系。
在 RegNet[27]之后,本文探索了人脸检测器的架构,假设固定的标准网络块(即: basic residual or bottleneck blocks,bottleneck ratio固定为4)。在本例中,人脸检测器的架构包括:
(1) backbone stem ,三个具有 w0 输出通道的 3*3 卷积层 [13],
(2) backbone body ,四个以逐渐 降低的分辨率 运行的阶段,每个阶段由一系列identical 块组成。对于每个阶段 i,自由度包括 块数 did_idi (即网络深度)和块宽度 wiw_iwi (即通道数)。
(3) neck, a multi-scale feature aggregation module by a top-down path and a bottom-up path with nin_ini channels [21],
(4) head ,具有 mmm 块的 hih_ihi 通道,用于预测人脸分数和回归人脸框。
由于 stem 的通道数与 C2 中第一个 residual block 的 block width 相等,因此 stem 的自由度可以合并到 wiw_iwi 中。此外,我们采用了一种共享的 head 设计,用于 三尺度的 feature maps ,并固定 heads 中所有 3×3 卷积层的通道数。因此,在我们的 neck 和 head 设计中,我们将自由度减少到三个:
(1) neck 的输出通道数 n,
(2) head 的输出通道数 h,
(3) 3 × 3 卷积层的数量 m。
我们对 n≤256,h≤256n≤256, h≤256n≤256,h≤256 和 m≤6m≤6m≤6 进行均匀采样( n 和 h 都能被 8 整除)。
backbone 搜索空间有 8 个自由度,有 4 个阶段,每个阶段 i 有 2 个参数: 块的数量 did_idi 和块的宽度 wiw_iwi。遵循 RegNet[27],对 di≤24d_i≤24di≤24 和 wi≤512w_i≤512wi≤512 (wiw_iwi 可被 8 整除) 进行 均匀采样。由于最先进的 backbones 具有越来越大的宽度[27],还将搜索空间缩小到 wi+1≥wiw_{i+1}≥w_iwi+1≥wi 的原则。
通过上面的简化,我们的搜索空间变得更加直接。在搜索空间中重复随机采样,直到在目标复杂度范围内获得 320 个模型,并在 WIDER FACE 训练集上训练每个模型 80 个 epoch。然后,在验证集上测试每个模型的 AP。基于这 320 对 模型统计量(xi,APi)(x_i, AP_i)(xi,APi),其中 xix_ixi 是特定部件 和 APiAP_iAPi 是相应的性能,我们遵循[27]来计算 经验引导(empirical bootstrap) [8],以估计最佳模型可能落在的范围。
最后,为了进一步降低搜索空间的复杂度,我们将网络结构搜索分为以下两个步骤:
- SCRFD1SCRFD_1SCRFD1: 只搜索 backbone 的计算分布,同时将 neck 和 head 的设置固定为默认配置。
- SCRFD2SCRFD_2SCRFD2: 搜索整个人脸检测器(即 backbone, neck and head )的计算分布,backbone 内部的计算分布遵循优化的 SCRFD1SCRFD_1SCRFD1。
这里,我们以约束于 2.5 Gflops 的 SCRFD (SCRFD-2.5GF) 为例来说明我们的两步搜索策略。
Computation redistribution on backbone. 在 backbone 上 计算重新分配
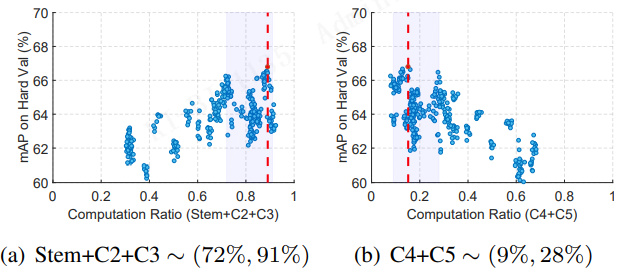
由于 backbone 执行了大量的计算,因此我们首先关注 backbone 的架构,它对确定网络的计算成本和准确性至关重要。对于 SCRFD1-2.5GF,我们将 neck 的输出通道固定为 32,并使用两个具有 96 个输出通道的堆叠的 3 × 3 卷积。由于在 SCRFD1SCRFD_1SCRFD1 算法的整个搜索过程中 neck 和 head 的配置是不变的,因此可以很容易地找到 backbone 的最佳计算分布。如 图5 所示,我们显示了 320 个模型APs(在 WIDER FACE hard 验证集上)的分布 与 backbone 的每个组件(即 stem、C2、C3、C4和C5 )的计算比率的对比。

图5。在 2.5 Gflops 约束下固定 neck and head 的 backbone (stem, C2, C3, C4和C5)上的 计算重分配。对于 backbone 中的每个组件,通过 empirical bootstrap 估计估计最佳模型可能下降的计算比率范围。
在应用 empirical bootstrap [8]后,出现了一个明显的趋势,表明 backbone 计算被重新分配到浅层阶段(即 C2和C3 )。在图6中,我们展示了 backbone 的浅层(即 stem, C2, and C3 )和深层(即 C4 和C5)之间的计算比率。从这些搜索结果中可以看出,大约 80% 的计算被重新分配到浅层阶段。
Computation redistribution on backbone, neck and head.
当我们在 2.5 Gflops 的特定计算约束下找到 backbone 内部的优化计算分布后,我们搜索在 backbone, neck and head 的最佳计算分布。在这一步中,我们只保留随机生成的网络配置,其 骨干网设置遵循 SCRFD1SCRFD_1SCRFD1 的计算分布,如 图5 所示。
现在还有另外三个自由度(即 neck 的输出通道数 n,head 的输出通道数 h,head 的 3 个卷积层数 m)。我们在搜索空间中重复随机抽样,直到我们在目标复杂度范围内获得 320 个合格模型(即 2.5 Gflops )。从 图9 可以看出,大部分的计算分配在 backbone,head 紧随其后,neck 的计算比例最低。图9(d)描述了 2.5 Gflops 约束下的模型架构对比。baseline(ResNet-2.5GF)的网络配置在 表2 中介绍。
通过采用提出的两步计算重分配方法,我们发现大量的 capacity 被分配到浅阶段,导致 AP 在 WIDER FACE hard 验证集上从 74.47% 提高到 77.87%。
Higher compute regimes and mobile regime. 更高的计算状态和移动状态。
除了 2.5 Gflops的复杂度限制外,我们还使用相同的两步计算重分配方法来探索更高计算 状态(regimes)例如 10 Gflops 和 34 Gflops )和 低计算状态(例如0.5 Gflops)的网络结构优化。图7 和 图8 显示了不同计算约束下的计算重分配和优化后的网络结构。
我们最终的体系架构与 baseline 网络有着几乎相同的 flops。从这些重分配结果中,我们可以得出以下结论:
(1) 更多的计算分配在 backbone 上,neck and head 的计算被压缩
(2) 由于在 WIDER FACE 上的特定 scale 分布,2.5 Gflops、10 Gflops 和 34 Gflops 的浅阶段分配了更多的 capacity
(3) 对于高计算状态(例如 34 Gflops),所探索的结构利用了 bottleneck residual block ,我们观察到在浅阶段有显著的深度缩放,而不是宽度缩放。缩放宽度受制于过拟合,因为参数增加较大 [1]。相比之下,缩放深度,特别是在早期的层中,与缩放宽度相比,引入的参数更少
(4) 对于移动端(0.5 Gflops),将深层阶段的有限容量(例如 C5 )分配给深层阶段捕获的判别特征,可以有利于 top-down neck pathway 对浅层 small face 的检测。
说了这么半天,就是 SCRFD 的架构是通过 NAS 搜出来的。
5. 实验
略
参考:人脸检测:SCRFD论文解析
相关文章:
【论文阅读】SCRFD: Sample and Computation 重分配的高效人脸检测
原始题目Sample and Computation Redistribution for Efficient Face Detection中文名称采样和计算 重分配的 高效人脸检测发表时间2021年5月10日平台ICLR-2022来源Imperial College, InsightFace文章链接https://arxiv.org/pdf/2105.04714.pdf开源代码官方实现&…...

Debezium报错处理系列之四十七:Read only connection requires GTID_MODE to be ON
Debezium报错处理系列之四十七:Caused by: java.lang.UnsupportedOperationException: Read only connection requires GTID_MODE to be ON 一、完整报错二、错误原因三、错误解决方法Debezium报错处理系列一:The db history topic is missing. Debezium报错处理系列二:Make…...
类型数据类型的精度的学习)
关于float(b)类型数据类型的精度的学习
Questions: 将表中的某字段类型设计成float(2)后,向其插入数据93.5后,最好结果却变成了90?这是为什么? 关于这个问题 官方帮助文档(Oracle Online Help )的说明如下: FLOAT(b) specifies a floa…...

哪种类型的网络安全风险需要进行渗透测试?
网络在给我们带来无限方便的同时,也隐藏着无数危机。2022年网络攻击造成的损失创下新的历史记录,根据Cybersecurity Ventures最新发布的“2022年网络犯罪报告”,预计2023年网络犯罪将给全世界造成8万亿美元的损失。同时在市场和以网络安全法为…...
ur3+robotiq ft sensor+robotiq 2f 140配置gazebo仿真环境
ur3robotiq ft sensorrobotiq 2f 140配置gazebo仿真环境 搭建环境: ubuntu: 20.04 ros: Nonetic sensor: robotiq_ft300 gripper: robotiq_2f_140_gripper UR: UR3 通过上一篇博客配置好ur3、力传感器和robotiq夹爪的rviz仿真环境后,现在来配置一下对…...

Vue3后台管理系统(四)SVG图标
目录 一、安装 vite-plugin-svg-icons 二、创建图标文件夹 三、main.ts 引入注册脚本 四、vite.config.ts 插件配置 五、TypeScript支持 六、组件封装 七、使用 Element Plus 图标库往往满足不了实际开发需求,可以引用和使用第三方例如 iconfont 的图标&…...
)
【收集】2023年顶会accepted papers list(NeurIPS/CVPR/ICML/ICLR/ECCV/AAAI/IJCAI/WWW...)
from: https://blog.csdn.net/lijinde07/article/details/128024833 顺便看看 评审意见是怎样的 Accepted papers list(2022.11.24) AAAI 2023 :录取结果已出 **ICLR 2023 ** :https://openreview.net/group?idICLR…...

空闲态LTE到NR重选优先级介绍
SIB24消息包含小区重选时5G邻区信息(NR neighbor cell information for cell reselection)。 终端注册在LTE网络,如果网络不上报SIB24消息,则终端不会重选到5G网络。 针对这种网络不上报SIB24的场景,终端可以做特殊处理,强制执行LTE到5G的重选流程。 终端网络制式设置为不…...
数据结构与算法:Map和Set的使用
1.搜索树 1.定义 二叉搜索树又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树: 若它的左子树不为空,则左子树上所有节点的值都小于根节点的值若它的右子树不为空,则右子树上所有节点的值都大于根节点的值它的左右子…...
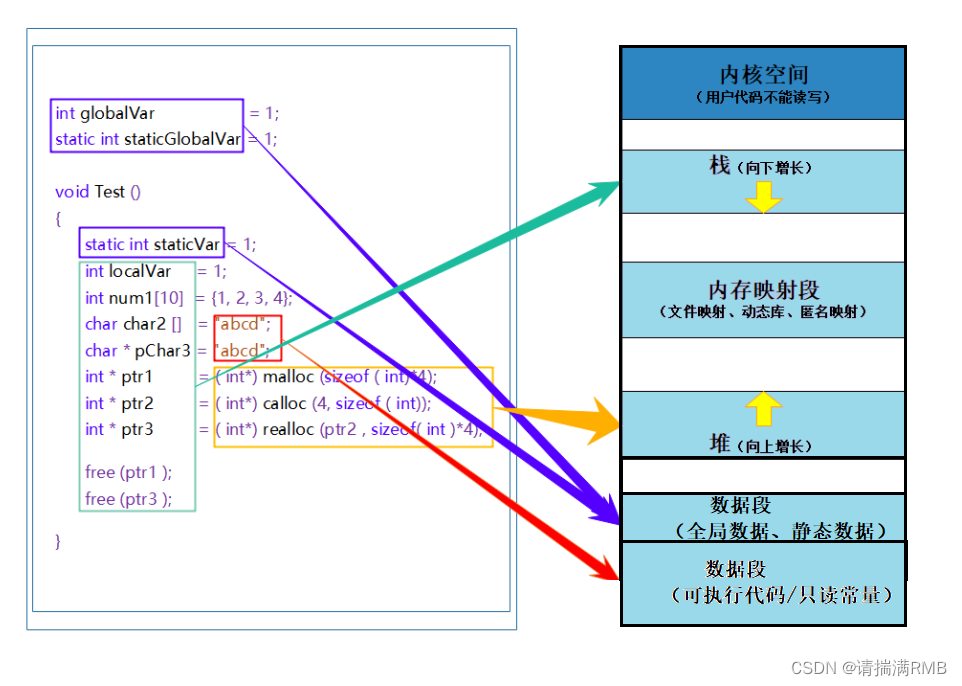
C语言——动态内存管理
目录0. 思维导图:1. 为什么存在动态内存分配2. 动态内存函数介绍2.1 malloc和free2.2 calloc2.3 realloc3. 常见的动态内存错误3.1 对NULL指针的解引用操作3.2 对动态内存开辟的空间越界访问3.3 对非动态开辟内存使用free释放3.4 使用free释放一块动态开辟内存的一部…...

Docker安装Grafana
文章目录Grafana介绍拉取镜像准备相关挂载目录及文件启动容器访问测试添加 Prometheus 数据源常见问题看板配置Grafana介绍 上篇博客介绍了prometheus的安装: Docker部署Prometheus 在获取应用或基础设施运行状态、资源使用情况,以及服务运行状态等直观…...
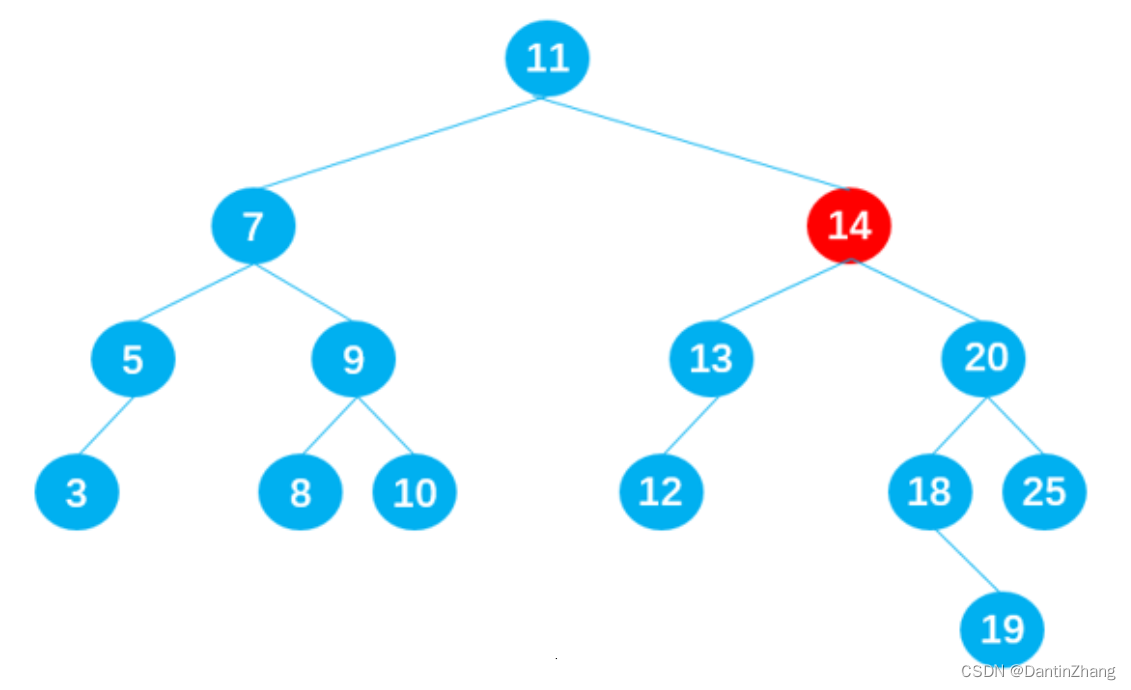
数据结构(四):树、二叉树、二叉搜索树
数据结构(四)一、树1.树结构2.树的常用术语二、二叉树1.什么是二叉树2.二叉树的数据存储(1)使用数组存储(2)使用链表存储三、二叉搜索树1.这是什么东西2.封装二叉搜索树:结构搭建3. insert插入节…...
)
040、动态规划基本技巧(labuladong)
动态规划基本技巧 一、动态规划解题套路框架 基于labuladong的算法网站,动态规划解题套路框架; 1、基本介绍 基本套路框架: 动态规划问题的一般形式是求最值;核心如下: 穷举;明确base case;…...

html笔记(一)
一、html简介 什么是HTML? Hyper Text Markup Language 超文本标记语言 超文本?超级文本,例如流媒体,声音、视频、图片等。 标记语言?这种语言是由大量的标签组成。 任何一个标签都有开始标签和结束标签&…...

索引的情况
select * from A left join B on A.c B.c where A.employee_id 3 1.一句sql中 是可能走多次索引的,具体的 一般 表连接 ,或者说生成临时表的时候,会走索引 然后条件过滤的时候也会走索引,具体的 还是要具体分析 2.表连接 字段…...
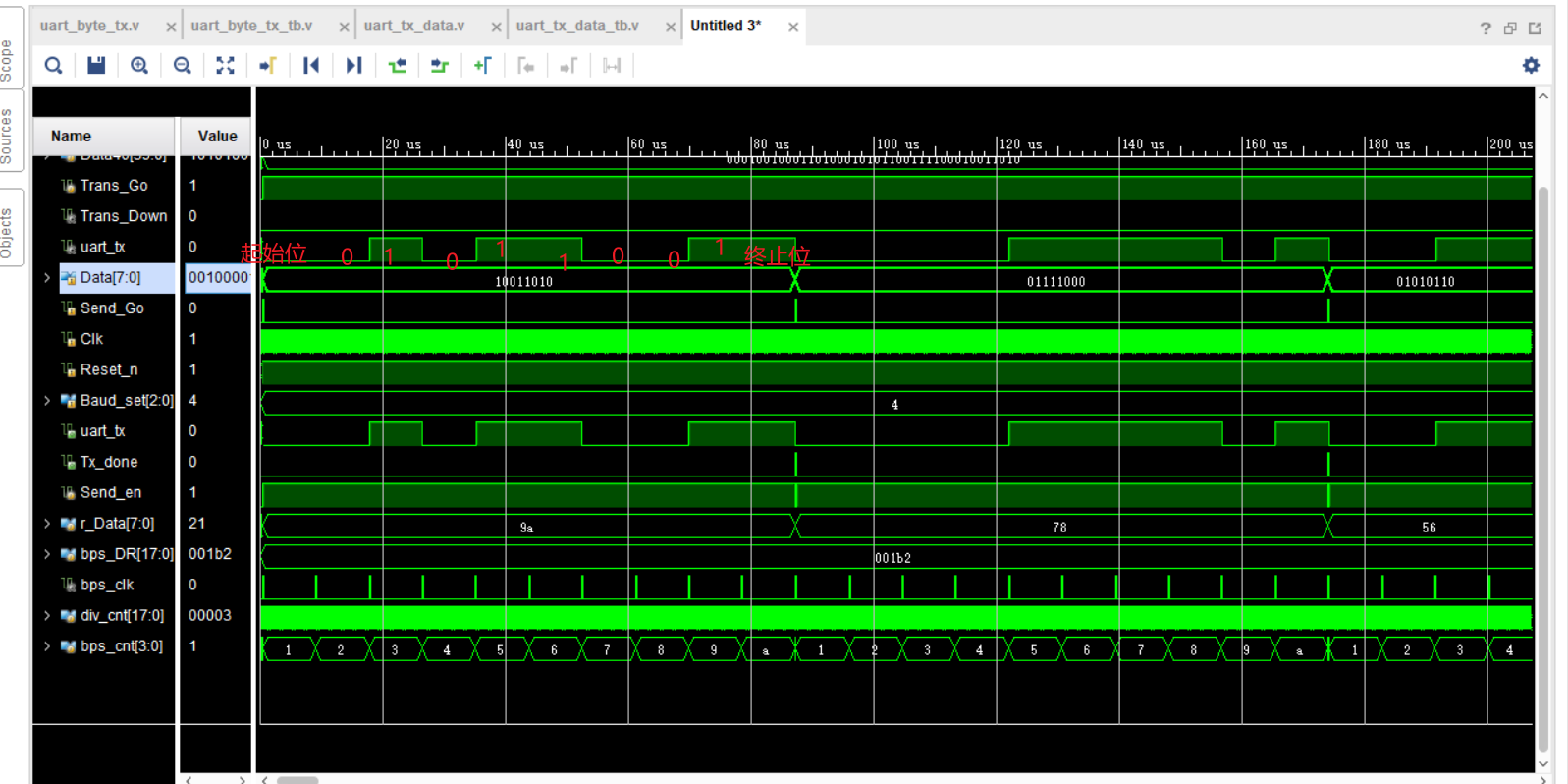
Verilog 学习第五节(串口发送部分)
小梅哥串口部分学习part1 串口通信发送原理串口通信发送的Verilog设计与调试串口发送应用之发送数据串口发送应用之采用状态机实现多字节数据发送串口通信发送原理 1:串口通信模块设计的目的是用来发送数据的,因此需要有一个数据输入端口 2:…...

破解遗留系统快速重构的5步心法(附实例)
前两天和一个架构师朋友闲聊,说到了 「重构」 这个话题,他们公司早年间上线的项目系统,因一直没专人在演进过程中为代码质量负责,导致现在代码越来越混乱,逐渐堆积成“屎山”,目前的维护成本已远高于重新开…...
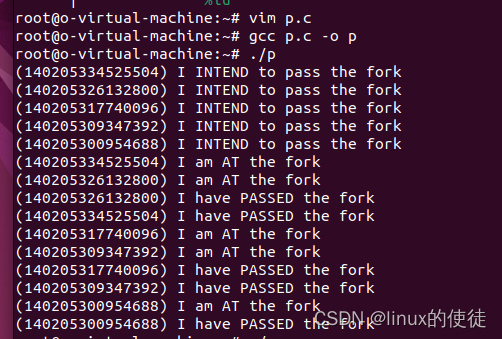
信号量(上)实验
实验1:解决订票终端的临界区管理 订票终端是解决冲突问题,所以信号量的值是1 #include <stdio.h> #include <pthread.h> #include <unistd.h> #include <semaphore.h> int ticketAmout 2; // 票的数量: 全局变量 sem_t mutex…...
阿里5年,一个女工对软件测试的理解
成为一个优秀的测试工程师需要具备哪些知识和经验? 针对这个问题,可以直接拆分以下三个小问题来详细说明: 1、优秀软件测试工程师的标准是什么? 2、一个合格的测试工程师需要具备哪些专业知识? 3、一个合格的测试工程…...

前端练习项目
30 Web Projects 30 多个带有 HTML、CSS 和 JavaScript 的 Web 项目,由 Packt Publishing 提供 https://github.com/PacktPublishing/30-Web-Projects-with-HTML-CSS-and-JavaScript Small projects https://github.com/WebDevVikramChoudhary/small_projects_for_…...

收藏干货|2026 版企业 AI 落地实操指南,程序员小白入门避坑必备
如今人工智能早已脱离概念炒作阶段,全面扎根企业实际业务场景,成为技术从业者与企业管理者无法回避的发展课题。各行各业都加速布局AI赛道,行业心态也从初期观望试探,彻底转变为实打实的落地攻坚。 不少企业高层主动牵头统筹AI规划…...

ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍
ComfyUI-WD14-Tagger:3分钟实现AI智能图像标签提取,效率提升10倍 【免费下载链接】ComfyUI-WD14-Tagger A ComfyUI extension allowing for the interrogation of booru tags from images. 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-WD14-…...

天文时序数据分析:机器学习评估、半监督学习与无监督方法实战
1. 项目概述:当机器学习遇见星空 处理海量的天文时序数据,比如来自Kepler、TESS这些“巡天巨眼”的光变曲线,早已不是靠人眼一张张图去翻的时代了。数据量太大,噪声复杂,信号微弱,传统方法常常力不从心。这…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...

为什么你明明很努力,领导却总看不到?问题出在这
许多测试同行在深夜加班排查Bug时,在凌晨赶写自动化脚本时,在对着海量数据做性能分析时,内心都会浮现一个共同的困惑:我明明已经这么拼了,为什么在领导眼里,我依然是个“找茬的”,而不是“创造价…...

ncmdumpGUI终极指南:深度解析网易云音乐NCM加密文件转换技术
ncmdumpGUI终极指南:深度解析网易云音乐NCM加密文件转换技术 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI ncmdumpGUI是一款专为Windows平台设计…...

如何快速无损转换B站m4s视频:完整工具使用指南
如何快速无损转换B站m4s视频:完整工具使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他设备…...

告别繁琐审核!实测AI Agent如何重塑复杂非结构化票据与合同处理流程?
摘要:在企业数字化转型步入深水区的2026年,处理复杂非结构化票据与合同已成为横亘在财务、法务部门面前的“最后一公里”难题。传统RPA因UI变动易崩溃、主流智能体因缺乏API适配而无法落地,导致大量业务仍依赖低效的人工操作。本文由「企服AI…...

Python到Android的魔法之旅:5步将你的代码变成移动应用
Python到Android的魔法之旅:5步将你的代码变成移动应用 【免费下载链接】python-for-android Turn your Python application into an Android APK 项目地址: https://gitcode.com/gh_mirrors/py/python-for-android 想象一下,你花了几个月时间精心…...

5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南
5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专为Windows设计的鼠…...