从0探索NLP——神经网络
从0探索NLP——神经网络
1.前言
一提人工智能,最能想到的就是神经网络,但其实神经网络只是深度学习的主要实现方式。
现在主流的NLP相关任务、模型大都是基于深度学习也就是构建神经网络实现的,所以这里讲解一下神经网络以及简单的神经网络结构。
2.概念及业务相关
2.1.分类任务
现在绝大部分的神经网络都用来做分类相关的任务,从整篇文章的类别判断到句子字词的序列标签。分类可以看做是用一条清晰地明确的线把每类样本圈出来,我们叫决策线。
其优势是擅长处理一些线性模型难以解决的线性不可分问题——一般线性模型出来的决策线都是直线,当不同类的样本混乱穿插在一起,一条直线就很难把它们分开。神经网络的决策线是曲线,想怎么弯就怎么弯,可以解决复杂情况下的分类问题。
PS: 其实并不是曲线,实际是将原数据空间A扭曲到一个可以用直线解决问题的空间B,在空间B中依旧是用直线解决的问题,但处于直观的空间A中的我们看见的空间B的直线,就是扭曲的。详见4.1~4.3.
在NLP任务中,文本样本的特征基本都是向量特征——用一连串的数字来描述一段文本,每一位数字都代表文本在一个特定维度上的特征,向量的维度一般会很大,但很可惜每个维度都不具备可解释性。
这些向量特征都是由模型训练输出的,而且文本向量特征的维度一般会很大,如此众多维度的特征很容易形成上述“样本混乱穿插难以直线分割”的问题。所以各种类型的神经网络是解决文本分类问题的首选。
PS: 当然众多的特征也是神经网络能胜任的原因之一,神经网络可以一层一层的分析提取特征。
但是,由于模型总是有误差的,且模型在训练降低误差时对所有样本都是一视同仁的,即便是99.99%的准确率,也不能保证那0.01%的错误不是人一眼就能看出来的问题。所以分类场景还需要结合分类任务所处的流程位置或需求对“准”的定义:
- 当分类任务处于流程末端时,可以直接使用,因为经过前面流程的数据范围过滤、数据处理,输入相对纯净,输出也就相对可信。
- 当分类任务处于流程始端时,不要直接使用,甚至要加确认操作,避免模型的误差传递到后面的流程中。
- 当需求的“准”是“找对”时,也就是“宁缺毋滥”时,一定要梳理规则,在模型判断后做一下规则确认,防止模型犯低级错误。
- 当需求的“准”是“找全”时,也就是“错杀一千也不放过一个”时,可以直接使用。
文本分类包括二分类、多分类和多标签分类,每种分类可以解决不同的需求场景。
2.1.1.二分类
二分类是指将样本集合一分为二,或者说对样本进行是或否的判断——判断文本是否属于/符合某一语料特点,比如:
- 判断留言文本是否是某类问题
- 判断用户评论表述态度是否积极
2.1.2.多分类
顾名思义,二分类是分两类,多分类就是分好几个类,比如:
- 判断输入请求的目的是哪个
- 判断文本内容所属类别
2.1.3.多标签分类
与多分类的区别是,多分类会将文本最终划分到一个唯一的类别上,多标签分类会将文本划分到多个类别上。举个栗子说,发文章时选择的的主题就是多分类,因为文章只能从多个主题中选择一个唯一主题。但关键标签就是多标签分类,因为文章可以选择多个关键标签。
2.2.回归预测
通常情况下不会用神经网络去做回归,虽然分类的本质就是把输出的回归概率映射到类别上,但是常规机器学习的回归模型已经能解决大部分问题了,效率上也不必神经网络差。
PS: 但是,要是常规回归模型的效果不好,倒是可以上网络试试。还是那个原因,神经网络可以捕获更多的特征,具有更强的拟合能力。
常见的场景有:
- 文本评分
- 文本相似度判断
2.3.特征提取
上文多次提到神经网络可以捕获更多的特征,那是否可以用它不做任何解决问题的任务,就做特征选取、降维、升维这些任务呢?答案是,可以的。
3.简单技术与使用
3.1.从感知机到神经网络
基本讲神经网络都是从感知机入手,作为开发人员简单了解神经网络模型的由来有利于后面“激活函数选择”、“参数调节”、“网络选择”等工作,至于神经网络的“梯度下降”、“反向传播”、“非线性变换”等基础知识则放到第4部分,有兴趣的可以选择浏览。
感知机就是简化的人脑神经元数学模型。单个感知机收获一系列输入以及对应的权重,将输入X与对应权重W相乘并加和,加和结果放到阶跃函数中——加和大于一定阈值θ就是输出1,小于则输出0 。感知机模型可以根据训练数据学习到每个权重W,从而具备回归预测、分类等能力。
PS: 为了更好拟合,会引入偏差b
感知机可以并联同时处理同一份输入X,但会有各自独立的权重W和阶跃函数阈值θ。同时感知机也可以串联——一个感知机的输出可以作为另一个感知机的输入,进而构成多层感知机。

当把感知机的阶跃函数变成平滑的非线性的函数就变成了神经元。同理神经元也可以并联串联构成神经网络。

PS :有时面试会问“单层感知机/神经网络”是输入层还是输出层?“
一般情况下,输入层是第0层(可以理解成输入向量,也可以理解成除了接数据嘛也没干的一层神经元),而单独的这层感知机是输出层,就是说我们提到X层神经网络时,默认是不包括输入层在内的。
3.2.激活函数
上文提到感知机到神经元的进化就是阶跃函数到平滑的非线性的函数的进化,这个函数就称为激活函数。激活函数的引入是让神经网络牛的关键:
- 非线性:非线性函数的导数不是常数,而线性函数的导数是常数,使用线性函数网络就退化成单层网络了。
证明见4.2
- 收敛性:激活函数的输出范围一般是有限的(或者一侧有限的),使得网络对于一些比较大的输入也会比较稳定,但同时也会带来梯度消失的问题——即在某些区间(饱和区间)梯度接近于零,使得参数无法继续更新的问题。
3.3.超参数
所谓参数就是网络中各层神经元之间传递的与X相乘的权重W,这些参数一般是先根据一定规则(随机规则)生成,再通过训练集数据学习而来的,不需要我们管。
详细了解见4.4
那什么需要我们管呢?超参数 Hyperparameters,Hyper-这个前缀就是“超过”、“在之上”的意思,没错超参数就是在学习得来的参数之上的参数,他决定了网络用何种方式学习、学到何种程度等重要属性,比如上文提到的激活函数 ,就是标准的重要的超参数。除此之外,还有一些神经网络常用的超参数,当然不同的网络结构还会拥有自己独特超参数或已定一些常用超参数。
3.3.1.隐藏层数 Hidden Layers
设定神经网络隐藏层的层数,大体上层数越多解决问题的潜力就越强,注意是潜力不是能力。因为能否让深层网络发挥应有的提升效果还依赖于激活函数、正则化等参数,所以是潜力。另外过深的网络很容易出现过拟合问题。
3.3.2.隐藏层单元数 Hidden Units:
设定神经网络每层隐藏层的神经元个数,特质和层数设定一样。
这里有个防止过拟合的小概念叫Dropout,指训练开始故意删掉一些单元不训练,防止过拟合
3.3.3. 激活函数 Activation Function
有条件的话当然是针对每层设定专属的激活函数,但一般情况为了方便调节只区分隐藏层和输出层。
输出层激活函数的选择主要取决于任务类型,而隐藏层激活函数的选择主要取决于数据特点了。
常见的激活函数有很多,这里就不对其函数图像函数特性进行分析了,直接说下使用场景和优劣势。对函数细节感兴趣的欢迎私戳。


3.3.4.学习迭代次数 Epoch
神经网络学习数据不是一锤子买卖,而是多轮迭代学习数据逐步减少模型预测值与实际真实值的误差,从这里开始我们就围绕这句话开始介绍剩下的超参数。

既然是多轮迭代(循环)就要有终止条件嘛,这里的终止条件就是误差是否足够小,在学习的过程中,我们期望是误差在每轮结束后有所减小,但有时会出现误差不动了(梯度消失)或者误差在上下振荡(梯度爆炸),所以为了避免模型跳不出循环,要限制他的学习轮数。
这里也有个防止过拟合的小概念叫Early Stopping,顾名思义当连续10轮(或者更多轮)没达到最佳准确值时,可以认为“不再提高”那就不要再学了,防止过拟合。
4.3.5.学习率 Learning Rate
多轮迭代学习数据逐步减少模型预测值与实际真实值的误差,那每次减小多少呢?学习率正是控制减少的幅度。
这里就要简单提一嘴“梯度下降”了,假设模型预测值与实际真实值的误差是一个函数,那我们要逐步减少他就是找他的最低点呗,肉眼肯定一下子能看出函数图像哪里最低,但计算机没有人“多重感知”的能力,他只能老老实实一步一步沿着函数线“下山”的方向走,什么时候函数线抬头向上了,此时就到底了,这就是梯度下降。
详细了解见4.4
那么每一步“走多远”也就是参数下降幅度就显得很关键,不能乱设置,步子小了有可能走到山间小坑里就以为到头了(局部最小),步子大了可能一步跨过山谷这辈子到不了(无法收敛),所以学习率的调节也不是一锤子买卖,需要反复调整。
学习率一般是一个较小的值,手动调节的整策略一般是:
- 损失在减逐步小,那就调大学习率让他收敛更加快。
- 损失有增大迹象,那就调小学习率阻止振荡。
- 减小的策略可以是,记录最佳的准确率,迭代10轮后仍没突破最佳,就学习率减半或者小数点后加个0(十分之一)。
注意是损失(Training Cost)而不是准确率(Accuracy)。
当然,一般网络框架会提供衰减调节,只需要设置就好了,以TensorFlow为例:
- 指数衰减(exponential_decay):常用简单粗暴、满足前期收敛后期精调。
- 分段衰减(piecewise_constant):手动设置,更好精调。需要一定经验。
- 多项式衰减(polynomial_decay):总体效果和指数一样,需要设置一个Power开方系数、Cycle下降后是否重新上升来跳出局部最小。
详细了解见4.7.3
3.3.6.优化器 Optimizer
多轮迭代学习数据逐步减少模型预测值与实际真实值的误差,那每次怎么减小呢?优化器一方面是定义采样以及参数减少的方式,另一方面也是降低学习率调节成本、提高学习效率的关键。
详细了解见4.7.4

3.3.8.批大小 Batch Size
多轮迭代学习数据逐步减少模型预测值与实际真实值的误差,那每次学习多少数据呢?总不能每次都学习全量数据吧,学习会很慢。设置过小,在减少时容易进入局部最优。
-
在使用一阶优化器,也就是梯度家族时,一般batch size设置为几十或者几百。
-
对于二阶优化器,往往要采用大batch size,设置成几千甚至一两万才能发挥出最佳性能。
详细了解见4.7.1
3.3.9. 损失函数 Loss Function
多轮迭代学习数据逐步减少模型预测值与实际真实值的误差,那什么是误差呢?损失函数就是用来计算误差的大小的。选择损失函数就像选择激活函数,需要结合问题和数据特点选择
详细了解见4.5
常见的损失函数,以TensorFlow为例:
- 均方根误差(mean_squared_error):回归问题中最常用的损失函数,下降收敛快。但受噪声影响大。
- 平均绝对误差(absolute_difference):回归问题中想格外增强对噪声样本的健壮性时使用,克服了 均方根的缺点。但收敛比均方根慢,计算很难。
- Huber误差(huber_loss):回归问题中集合均方根和 平均绝对的优点。但是增加了需要手动调的超参数,在sklearn 关于 huber 回归的文档中建议将 其设为1.35 以达到 95% 的有效性。
- sigmoid 交叉熵 (sigmoid_cross_entropy_with_logits):二分类问题首选,使用时注意自己别画蛇添足提前给预测值进行 sigmoid 处理。
- 交叉熵(log_loss):同上,不过这回你可以折腾预测值了。
- softmax 交叉熵(softmax_cross_entropy_with_logits_v2):见softmax 知多分类
- 以上都是框架给你搞好的损失函数,但是标准的损失函数并不合适所有场景,有些实际的背景需要采用自己构造的损失函数。
3.3.10. 权重初始化方法
多轮迭代学习数据逐步减少模型预测值与实际真实值的误差,那第一轮开始前参数是多少呢?
逻辑回归中我们会把权重初始化为0,但是神经网络坚决不能这样,这样会使得头几轮每一层的神经元学到的东西都是一样的。目前常用的有:
- 随机初始化:均值为0,方差为1的高斯分布中采样
- Xavier初始化: 适用于tanh激活函数
- He初始化: 适用于Relu激活函数
3.3.11. 正则化方法 Regularizer
多轮迭代学习数据逐步减少模型预测值与实际真实值的误差,那谁来维护这一过程呢?虽然有迭代次数防止模型沉迷在学习中,但治标不治本,想要根治误差停止下降或振荡就要靠正则化。可以理解为正则化是对学习时思维发散的限制,举一反三固然是好的,但你学个预测鸢尾花天马行空到物种起源是不是有点过分。正则化就是提高泛化能力,防止过拟合。
正则化方法一般也是网络框架提供的,以TensorFlow为例:
- L1(l1_regularizer):在原始的损失函数后面加上一个 L1 正则化项,即所有权值 W 的绝对值的和的平均值,乘以正则化参数。L1正则化会让参数变得稀疏,变相特征选择,且L1不可导。当特征中生效占比小选择L1很好。
- L2(l2_regularizer):在原始的损失函数后面加上一个 L2 正则化项,即所有权值 W 的平方和的开根的平均值,乘以正则化参数。计算简单。当特征中基本都生效且平均,选择L1很好。
详细了解见4.6
3.3.12. 正则化参数
多轮迭代学习数据逐步减少模型预测值与实际真实值的误差,那维护力度要多大呢?有了正则化方法就是有了监督者,但我们也不希望模型被压制的过于刻板没有个性吧,所以就要设置一个参数控制正则化的力度。
3.4.常见问题
3.4.1.欠拟合与过拟合
训练集准确率高,实际应用(测试集)准确率也高是我们想看到的。但有时也不尽人意。
欠拟合就是模型在训练集上准确率就不行,更别说拿到测试集上了。一般解决:
- 考虑下是不是选型上就出了问题
- 增加特征,如高次特征、组合特征。注意有些教程说增加数据可不是说数据量,欠拟合的本质是高偏差,盲目提高数据量并不会解决偏差。
- 尝试减小正则项参数。
- Boosting
主要是过拟合,明明训练集表现不错,到了测试集就拉跨。一般解决有:
- 交叉检验优化超参数
- 特征选择,减少特征数
- 增加训练数据,过拟合就可以考虑增加数据来减小训练测试的gap
- 尝试增大正则项参数。
- Bagging
<警告>前方大量干货,请备好咖啡再看</警告结束加坏笑>
以下内容是我对周志华的《机器学习》和蒋子阳的《TensorFlow深度学习》的笔记
4.基本原理和探讨
4.1.线性和非线性的问题
在机器学习中:
线性模型:
每一个特征Xi相互独立或只受一个权重Wi影响 ,以逻辑回归为例
Logistics=Sigmoid(Linear(X))=11+e−WT×X\mathbf{Logistics}=\mathbf{Sigmoid(\mathbf{Linear(X)})} \\ =\frac{1}{1+e^{-W^T \times X}} Logistics=Sigmoid(Linear(X))=1+e−WT×X1
其中WX就是一个权重矩阵W乘一个特征向量X:
y=WT×X=[w0w1...wn]×[x0x1...xn]\mathbf{y}=\mathbf{W^T}\times\mathbf{X}= \begin{bmatrix} \mathbf{w_{0}} & \mathbf{w_{1}} & ... & \mathbf{w_{n}} \end{bmatrix} \times \begin{bmatrix} \mathbf{x_{0}} \\ \mathbf{x_{1}} \\ ... \\ \mathbf{x_{n}} \end{bmatrix} y=WT×X=[w0w1...wn]×x0x1...xn
可见每一个特征Xi相互独立或只受一个权重Wi影响,当然对于 广义线性模型 (Generalized Linear Models)有更为统计学的定义,这里不详解。
再看一个“线性神经网络”——激活函数是线性函数(Y=kX)的神经网络。假设激活函数是Y=X,网络结构如下:

那么一层神经网络可以看作
Output1=[w00w01w02w03w10w11w12w13w20w21w22w23w30w31w32w33]×[x0x1x2x3]=[x0′x1′x2′x3′]\mathbf{Output_1}= \begin{bmatrix} \mathbf{w_{00}} & \mathbf{w_{01}} & \mathbf{w_{02}} & \mathbf{w_{03}} \\ \mathbf{w_{10}} & \mathbf{w_{11}} & \mathbf{w_{12}} & \mathbf{w_{13}} \\ \mathbf{w_{20}} & \mathbf{w_{21}} & \mathbf{w_{22}} & \mathbf{w_{23}} \\ \mathbf{w_{30}} & \mathbf{w_{31}} & \mathbf{w_{32}} & \mathbf{w_{33}} \\ \end{bmatrix} \times \begin{bmatrix} \mathbf{x_{0}} \\ \mathbf{x_{1}} \\ \mathbf{x_{2}} \\ \mathbf{x_{3}} \end{bmatrix}= \begin{bmatrix} \mathbf{x_{0}^{'}} \\ \mathbf{x_{1}^{'}} \\ \mathbf{x_{2}^{'}} \\ \mathbf{x_{3}^{'}} \end{bmatrix} Output1=w00w10w20w30w01w11w21w31w02w12w22w32w03w13w23w33×x0x1x2x3=x0′x1′x2′x3′
传递到第二层输出就是
Output2=[w00′w01′w02′w0n′w10′w11′w12′w1n′]×[x0′x1′x2′x3′]=[x0′′x1′′]\mathbf{Output_2}= \begin{bmatrix} \mathbf{w_{00}^{'}} & \mathbf{w_{01}^{'}} & \mathbf{w_{02}^{'}} & \mathbf{w_{0n}^{'}} \\ \mathbf{w_{10}^{'}} & \mathbf{w_{11}^{'}} & \mathbf{w_{12}^{'}} & \mathbf{w_{1n}^{'}} \\ \end{bmatrix} \times \begin{bmatrix} \mathbf{x_{0}^{'}} \\ \mathbf{x_{1}^{'}} \\ \mathbf{x_{2}^{'}} \\ \mathbf{x_{3}^{'}} \end{bmatrix}= \begin{bmatrix} \mathbf{x_{0}^{''}} \\ \mathbf{x_{1}^{''}} \end{bmatrix} Output2=[w00′w10′w01′w11′w02′w12′w0n′w1n′]×x0′x1′x2′x3′=[x0′′x1′′]
最后输出。我们将上两层权重矩阵带入,观察可知,只要激活函数是线性函数,多层神经网络的的权重就是矩阵相乘,最后得到一个大矩阵(权重向量)也就是不改变空间的线性变换。所以最终也相当于是“每一个特征Xi相互独立或只受一个权重Wi影响”。
y=[w0′′w1′′]×[x0′′x1′′]=[w0′′w1′′]×[w00′w01′w02′w0n′w10′w11′w12′w1n′]×[w00w01w02w03w10w11w12w13w20w21w22w23w30w31w32w33]×[x0x1x2x3]=WT×X\mathbf{y}= \begin{bmatrix} \mathbf{w_{0}^{''}} & \mathbf{w_{1}^{''}} \end{bmatrix} \times \begin{bmatrix} \mathbf{x_{0}^{''}} \\ \mathbf{x_{1}^{''}} \end{bmatrix} \\ = \begin{bmatrix} \mathbf{w_{0}^{''}} & \mathbf{w_{1}^{''}} \end{bmatrix} \times \begin{bmatrix} \mathbf{w_{00}^{'}} & \mathbf{w_{01}^{'}} & \mathbf{w_{02}^{'}} & \mathbf{w_{0n}^{'}} \\ \mathbf{w_{10}^{'}} & \mathbf{w_{11}^{'}} & \mathbf{w_{12}^{'}} & \mathbf{w_{1n}^{'}} \\ \end{bmatrix} \times \begin{bmatrix} \mathbf{w_{00}} & \mathbf{w_{01}} & \mathbf{w_{02}} & \mathbf{w_{03}} \\ \mathbf{w_{10}} & \mathbf{w_{11}} & \mathbf{w_{12}} & \mathbf{w_{13}} \\ \mathbf{w_{20}} & \mathbf{w_{21}} & \mathbf{w_{22}} & \mathbf{w_{23}} \\ \mathbf{w_{30}} & \mathbf{w_{31}} & \mathbf{w_{32}} & \mathbf{w_{33}} \\ \end{bmatrix} \times \begin{bmatrix} \mathbf{x_{0}} \\ \mathbf{x_{1}} \\ \mathbf{x_{2}} \\ \mathbf{x_{3}} \end{bmatrix} \\ = \mathbf{W^T} \times \mathbf{X} y=[w0′′w1′′]×[x0′′x1′′]=[w0′′w1′′]×[w00′w10′w01′w11′w02′w12′w0n′w1n′]×w00w10w20w30w01w11w21w31w02w12w22w32w03w13w23w33×x0x1x2x3=WT×X
但如果将激活函数换成非线性的,那么层间空间就会进行非线性变换,权重的传递就不能用矩阵相乘表示。
线性分类问题:
能用一条直线(决策边界)区分不同类别的点就是线性可分问题

反之不能用一条直线(决策边界)区分不同类别的点就是非线性可分(线性不可分)问题

在数学领域对于线性的定义:
线性函数:满足可加性和系数可乘性,即如下式。
f(x)+f(y)=f(x+y)a∗f(x)=f(a∗x)\mathbf{f(x)}+\mathbf{f(y)}=\mathbf{f(x+y)} \\ \mathbf{a*f(x)}=\mathbf{f(a*x)} f(x)+f(y)=f(x+y)a∗f(x)=f(a∗x)
线性变换:对向量空间 V到另一个向量空间 W 变换,满足可加性和系数可乘性,就是线性变换。
4.2.如何解决线性不可分问题
这里面存在一个误区,看这样一句话
“神经网络可以解决线性不可分(非线性)问题”
这句话是对的但有的人会不自然的在前面加一个“只有”,解决非线性问题不是神经网络的独门绝技,而是优于其他算法解决方式的独家秘方。
拿逻辑回归举例,逻辑回归中也有梯度下降、也有“sigmoid”,再根据逻辑回归的表达式,以二分类任务为例,我们可以把逻辑回归看作如下图所示的单层单神经元的神经网络加一个阶跃函数(Step Function)。那神经网络和他有什么区别?仅仅是神经网络节点多、层数多?

的确,传统逻辑回归不能解决非线性问题,但当引入了非线性kernel(数据的非线性特征如平方、乘积、三角等)时,逻辑回归也能解决非线性问题。这一点我们通过Tensorflow的playground可以验证:
A Neural Network Playground
上文说到“在二分类中把逻辑回归比作单层单神经元的神经网络。开始验证:
- 首先我们选择分类任务,再挑选一个线性不可分的数据集
- 激活函数选择为Linear(线性函数)
- 选择常规一次特征
- 构建一个单层单神经元的神经网络

执行后发现,确实不可分:

由于线性函数特性,不论并列多少,套多少层,都是线性变换,再多也是无济于事:

可见线性函数情况下无论如何也解决不来线性不可分问题,那看下基本的逻辑回归,即把函数换成Sigmoid:

常规逻辑回归的确解决不了,但当我们把”多个逻辑回归并联“——构建简单神经网络,虽然也迭代了很多次,但至少我们根据常规特征就解决了非线性问题:

最后回到刚刚的设想,当我们在常规逻辑回归引入非线性特征——平方,仅仅不到50次就已经解决问题:

但引入了非线性kernel的逻辑回归能解决所有非线性分类问题吗?显然不是,在Tensorflow的playground中选一个复杂的线性不可分的二分类问题,即便给他足够多的非线性特征也不行。

但,一个并不复杂的神经网络,即便不用全部非线性特征也可以解决复杂的线性不可分的二分类问题。

至此得出结论,比机器学习的优势如下:
-
逻辑回归、决策树等机器学习算法即便引入非线性kernel也只能解决简单的线性不可分问题
-
神经网络结构加上非线性的激活函数使之具有解决线性不可分问题的能力
也就说,逻辑回归、决策树等机器学习算法所有参数的更新是基于相同的式子,也就是所有参数的更新是基于相同的规则。而神经网络每两个神经元之间参数的更新都基于不同式子,也就是每个参数的更新都是用不同的规则。这使得神经网络模型能模拟和挖掘出更多复杂的关系。
最后一个问题:
那么为什么逻辑回归引入非线性kernel就能解决非线性问题?或者说为什么神经网络采用非线性激活函数就能解决线性不可分问题的能力?“非线性”到底做了什么?
4.3.空间变换与矩阵运算
这是一个平平无奇的坐标系,和两个平平无奇的向量小红和小蓝
V⃗小红=[10],V⃗小蓝=[01]\vec{V}_{小红}=\begin{bmatrix} 1 \\ 0 \end{bmatrix}, \vec{V}_{小蓝}=\begin{bmatrix} 0 \\ 1 \end{bmatrix} V小红=[10],V小蓝=[01]

小红和小蓝分别是这个坐标系中代表X轴和Y轴最“基本”的两个向量,用这两个向量可以在这个坐标系中表示任何向量
V⃗1=6V⃗小红+5V⃗小蓝=[65]\vec{V}_{1}=6\vec{V}_{小红}+5\vec{V}_{小蓝}=\begin{bmatrix} 6 \\ 5\end{bmatrix} V1=6V小红+5V小蓝=[65]

但,只有小红和小蓝可以这样为所欲为嘛?显然大红有话要说
V⃗大红=[21]V⃗1=3V⃗大红+2V⃗小蓝=[65]\vec{V}_{大红}=\begin{bmatrix} 2 \\ 1\end{bmatrix} \\ \vec{V}_{1}=3\vec{V}_{大红}+2\vec{V}_{小蓝}=\begin{bmatrix} 6 \\ 5\end{bmatrix} V大红=[21]V1=3V大红+2V小蓝=[65]

而且大红不甘于只表示一个向量这点作为,他要创造一个“世界”,在这个“世界”里他才是最“基本”的向量。于是他以自己为“核心”重新构建了一条X轴,并如愿以偿成为了这个世界代表X轴的最“基本”的向量。并且,在它看来,V1也随之“臣服”变了样子
V⃗大红′=[10],V⃗小蓝′=[01]V⃗1′=3V⃗大红′+2V⃗小蓝′=[32]\vec{V}^{'}_{大红}=\begin{bmatrix} 1 \\ 0\end{bmatrix},\vec{V}^{'}_{小蓝}=\begin{bmatrix} 0 \\ 1\end{bmatrix} \\ \vec{V}^{'}_{1}=3\vec{V}^{'}_{大红}+2\vec{V}^{'}_{小蓝}=\begin{bmatrix} 3 \\ 2\end{bmatrix} V大红′=[10],V小蓝′=[01]V1′=3V大红′+2V小蓝′=[32]

但,理智的小红轻蔑的笑了笑“你不过是沉迷于自己世界的井底之蛙罢了,你并没有逃脱这个世界啊“。确实,大红构建的“世界”是由原来的坐标系变换来的。V1并没有“臣服”不过是大人有大量的改个“称呼”罢了。


大红的这波降智操作称为“空间的线性变换”,他并没有让空间改天换地——一个点相对于另一个点的分布并没有变化。大红不服,于是小红拿出4.1中线性不可分的例子“如果你真的能改变世界,那你能用一条直线,分开这些点嘛?”


大红沉默了,嘟囔到“那谁也办不到……”
“不!”小红说“有人可以办到,那是一股不可描述神秘力量,叫非线性变换,他可以扭曲空间”。
大红的线性变换可以看做是原坐标X,Y通过线性函数到X‘,Y’,即通过变换矩阵改变其分布
{X′=2∗XY′=Y+X\left\{ \begin{aligned} &X^{'}=2*X \\ &Y^{'}=Y+X \end{aligned} \right. {X′=2∗XY′=Y+X
即
[X′Y′]=[2011]×[XY]\begin{bmatrix} X^{'} \\ Y^{'} \end{bmatrix}= \begin{bmatrix} 2 & 0 \\ 1 & 1 \end{bmatrix} \times \begin{bmatrix} X \\ Y \end{bmatrix} \\ [X′Y′]=[2101]×[XY]
而当我们采用如下非线性函数去变换,可以理解成“抓着黄色圆心把平面像手绢一样拎起来,拎着的手绢尖尖点放在原点,手绢边缘甩向右上角”,此时我们很容易找到一条直线把黄色点分出来。
{X′=(X−10)2Y′=(Y−10)2\left\{ \begin{aligned} &X^{'}=(X-10)^2 \\ &Y^{'}=(Y-10)^2 \end{aligned} \right. {X′=(X−10)2Y′=(Y−10)2

神经网络正是通过非线性变换扭曲空间,变换的过程中非线性的幂次、组合各个特征,这里再安利一个网络可视化的Playground:
ConvnetJS
可以构建你想要的网络结构、选择激活函数并观察每一层是如何扭曲空间,使得线性不可分问题迎刃而解。

4.4.梯度下降与反向传播
4.4.1.何为梯度
梯度是一个基于微分的概念——N元函数F在空间区域G内具有一阶连续偏导数,则函数在某点各个偏导数构成的矢量(向量)就是梯度。
这是一个一元二次函数和他的导数(微分)以及辅助线——在x=20处导数值和函数切线。
f(x)=x210g(x)=f′(x)=df(x)dx=x5f(20)=40,g(20)=4,h(a)=4a−40\mathbf{f}(x)=\frac{x^2}{10} \\ \mathbf{g}(x)=\mathbf{f}^{'}(x)=\frac{d\mathbf{f}(x)}{dx}=\frac{x}{5} \\ \mathbf{f}(20)=40,\mathbf{g}(20)=4,\mathbf{h}(a)=4a-40 f(x)=10x2g(x)=f′(x)=dxdf(x)=5xf(20)=40,g(20)=4,h(a)=4a−40

可见一元函数的导数表示函数某点切线的斜率,是一个标量。这时我们将一元二次函数用二元二次函数的方式表示——二元系数为0。求其对x和y的偏导并构成矢量,即梯度。
f(x,y)=x210+0∗y⟨∂f∂x,∂f∂y⟩=(x5,0)\mathbf{f}(x,y)=\frac{x^2}{10}+0*y \\ \langle \frac{\partial \mathbf{f}}{\partial x},\frac{\mathbf{\partial f}}{\partial y} \rangle=(\frac{x}{5},0) f(x,y)=10x2+0∗y⟨∂x∂f,∂y∂f⟩=(5x,0)
之后加入这个空间的x轴和y轴的基向量i和j。在点 (20,40) 处的梯度为 (4,0),即4i。很明显这个向量指向的是函数关于X(因为只与X有关)变化最快的方向。
为了方便观察这里对向量长度做了放大,主要是看方向哈
i⃗=[10],j⃗=[01]\vec{i}=\begin{bmatrix} 1 \\ 0 \end{bmatrix}, \vec{j}=\begin{bmatrix} 0 \\ 1 \end{bmatrix} i=[10],j=[01]

再看一个“真”二元二次函数的某点梯度
f(x,y)=x210+y210\mathbf{f}(x,y)=\frac{x^2}{10}+\frac{y^2}{10} f(x,y)=10x2+10y2

假如我们要攀登山峰,那就要观察此时我们周围最陡峭的方向,沿着那个方向往上爬。梯度的意义就是函数在该点增长最快的方向,则负梯度方向则是下降最快的方向。
4.4.2.梯度下降
回想一下神经网络结构,每一层都有很多权重Wi,我们如何确定的这些权重呢?这里引入一个新名词“损失函数”——损失函数是关于权重Wi、输入Xi和输出Yi的函数用来计算实际输出和正确输出之间的差异。我们调节权重的目的就是要让实际输出尽可能的接近正确输出,即寻找损失函数最小的点。那如何寻找最小的点呢?根据梯度的含义,只要我们沿着负梯度方向,就能一步一步“走向”函数极小值——即梯度下降。
形象一点说,假设损失函数是如下图的一条曲线,我们把这个曲线看做一个山谷,这一天我们接到任务要我们走到谷底,直升机把我们随机扔到了山谷的一个地方,落地后发现周围雾气很大,根本看不见谷底在哪,而我们身上除了一个显示海拔高度的仪器以外什么都没有。我们只能依靠周围的环境判断哪个方向下山更快,之后每走一步都确认一下海拔是不是真的在下降,如果在下降就再接着看看哪个方向下山更快,直到海拔不变或开始上升。

专业一点说,具体的运作方式是,根据一定规则(随机)初始化参数列表W0,根据X 计算实际输出Y0,再计算损失函数在该X、W0、Y0的负梯度方向,沿着该方向按照学习率调整参数至W1,之后不断重复这一流程直到损失函数极小——各一阶偏导接近0。
还拿刚刚“山谷函数”举例,假设初始化位置是x=-9,学习率是0.4,那么我们梯度下降的过程是:
f(x)=x210+sinxg(x)=f′(x)=x5+cosxxnext=xnow−0.4∗g(x)x0=−9,g(x)0=−2.711x1=−7.915547,g(x)1=−1.644x2=−7.257693,g(x)2=−0.889......x8=−6.166115,g(x)0=−0.240x9=−6.070088,g(x)0=−0.236x10=−5.975433,g(x)0=−0.242......x32=−1.308716,g(x)0=−0.002x33=−1.307655,g(x)0=−0.001x34=−1.307088,g(x)0=−0.0007\begin{aligned} \mathbf{f}(x)&=\frac{x^2}{10}+\sin{x} \\ \mathbf{g}(x)=\mathbf{f}^{'}(x)&=\frac{x}{5}+\cos{x} \\ \mathbf{x_{next}}&=\mathbf{x_{now}}-0.4*\mathbf{g}(x) \\ x_{0}=-9, & \mathbf{g}(x)_{0}=−2.711 \\ x_{1}=-7.915547,& \mathbf{g}(x)_{1}=−1.644 \\ x_{2}=-7.257693,& \mathbf{g}(x)_{2}=−0.889 \\ ... & ... \\ x_{8}=-6.166115,& \mathbf{g}(x)_{0}=−0.240 \\ x_{9}=-6.070088,& \mathbf{g}(x)_{0}=−0.236 \\ x_{10}=-5.975433,& \mathbf{g}(x)_{0}=−0.242 \\ ... & ... \\ x_{32}=-1.308716,& \mathbf{g}(x)_{0}=−0.002 \\ x_{33}=-1.307655,& \mathbf{g}(x)_{0}=−0.001 \\ x_{34}=-1.307088,& \mathbf{g}(x)_{0}=−0.0007 \end{aligned} f(x)g(x)=f′(x)xnextx0=−9,x1=−7.915547,x2=−7.257693,...x8=−6.166115,x9=−6.070088,x10=−5.975433,...x32=−1.308716,x33=−1.307655,x34=−1.307088,=10x2+sinx=5x+cosx=xnow−0.4∗g(x)g(x)0=−2.711g(x)1=−1.644g(x)2=−0.889...g(x)0=−0.240g(x)0=−0.236g(x)0=−0.242...g(x)0=−0.002g(x)0=−0.001g(x)0=−0.0007

最后我们以线性回归为例,实际应用梯度下降确定线性回归参数。设数据集大小为 m,回归(预测)函数为一元一次函数 f,损失函数为 J,梯度为▽J。由定义可知 J代表的是预测y值与实际y值差的平方的平均值。
前面的系数 1/2 单纯是为了一会求导消掉平方导出来的系数2
fΘ(x)=Θ1x+Θ0=kx+bJloss(Θ)=12m∑i=1m(fΘ(xi)−yi)2∇Jloss(Θ)=⟨∂J∂b,∂J∂k⟩\mathbf{f}_{\Theta}(x)=\Theta_1x+\Theta_0=kx+b \\ \mathbf{J_{loss}}(\Theta)=\frac{1}{2m}\sum^{m}_{i=1}{(\mathbf{f}_{\Theta}(x_i)-y_i)^2} \\ \nabla\mathbf{J_{loss}}(\Theta)= \langle \frac{\partial J}{\partial b},\frac{\partial J}{\partial k} \rangle \\ fΘ(x)=Θ1x+Θ0=kx+bJloss(Θ)=2m1i=1∑m(fΘ(xi)−yi)2∇Jloss(Θ)=⟨∂b∂J,∂k∂J⟩
其实就是y=kx+b,所以写的易懂一点
由于J是关于X、Y以及参数K、B的函数,也就是说求这两个值不再是常量而是变量之一
∂J∂b=1m∑i=1m(f(xi)−yi)∂f∂b=1m∑i=1m(f(xi)−yi)∂J∂k=1m∑i=1m(f(xi)−yi)∂f∂k=1m∑i=1m(f(xi)−yi)xi\frac{\partial J}{\partial b} = \frac{1}{m}\sum^{m}_{i=1}{(\mathbf{f}(x_i)-y_i)\frac{\partial f}{\partial b}} \\ = \frac{1}{m}\sum^{m}_{i=1}{(\mathbf{f}(x_i)-y_i)} \\ \frac{\partial J}{\partial k} = \frac{1}{m}\sum^{m}_{i=1}{(\mathbf{f}(x_i)-y_i)\frac{\partial f}{\partial k}} \\ = \frac{1}{m}\sum^{m}_{i=1}{(\mathbf{f}(x_i)-y_i)x_i}\\ ∂b∂J=m1i=1∑m(f(xi)−yi)∂b∂f=m1i=1∑m(f(xi)−yi)∂k∂J=m1i=1∑m(f(xi)−yi)∂k∂f=m1i=1∑m(f(xi)−yi)xi
又因为,我们一般都可以把线性方程改成参数矩阵与变量矩阵相乘的形式。那么损失函数中加和的部分也就可以改写成矩阵相乘的形式,方便计算
平方相当于矩阵与自己转置相乘
f(x)=kx+b=[kb]×[x1]Diff(f,y)=∑i=1m(fΘ(xi)−yi)=Xwith1[kb]−y⃗Jloss=12m(Diff(f,y))T(Diff(f,y))∇Jloss=1mXwith1TDiff(f,y)\mathbf{f}(x)=kx+b =\begin{bmatrix} k \\ b \end{bmatrix} \times \begin{bmatrix} x & 1 \end{bmatrix} \\ \mathbf{Diff_{(f,y)}}=\sum^{m}_{i=1}{(\mathbf{f}_{\Theta}(x_i)-y_i)}=X_{with~1}\begin{bmatrix} k \\ b \end{bmatrix}-\vec{y} \\ \mathbf{J_{loss}}=\frac{1}{2m}(\mathbf{Diff_{(f,y)}})^T(\mathbf{Diff_{(f,y)}}) \\ \nabla\mathbf{J_{loss}}=\frac{1}{m}X^T_{with~1}\mathbf{Diff_{(f,y)}} f(x)=kx+b=[kb]×[x1]Diff(f,y)=i=1∑m(fΘ(xi)−yi)=Xwith 1[kb]−yJloss=2m1(Diff(f,y))T(Diff(f,y))∇Jloss=m1Xwith 1TDiff(f,y)
上代码
import numpy as np
import random# 数据集大小
DATASET_SIZE = 20
# 生成数据集
X = np.arange(1, DATASET_SIZE + 1)
Y = np.array([random.randint(max(0, x - 5), min(DATASET_SIZE, x + 5)) for x in X])
# 将原本的X数组变成向量,再把向量变成带个常数1的X矩阵
VEX_X = X.reshape((DATASET_SIZE, 1))
VEC_1 = np.ones((DATASET_SIZE, 1))
MATRIX_X = np.hstack((VEX_X, VEC_1))
# 将原本的Y数组变成向量
VEC_Y = Y.reshape((DATASET_SIZE, 1))
# 定义学习率
ALPHA = 0.01
# 初始化系数矩阵
MATRIX_THETA = np.array([1, 1]).reshape(2, 1)def loss(theta_matrix, x_matrix, y_vec):"""损失函数"""diff = np.dot(x_matrix, theta_matrix) - y_vecreturn (1. / 2 * DATASET_SIZE) * np.dot(np.transpose(diff), diff)def loss_gradient(theta_matrix, x_matrix, y_vec):"""损失函数的梯度"""diff = np.dot(x_matrix, theta_matrix) - y_vecreturn (1. / DATASET_SIZE) * np.dot(np.transpose(x_matrix), diff)# 损失函数的梯度下降
# 初始梯度
gradient = loss_gradient(MATRIX_THETA, MATRIX_X, VEC_Y)
theta = MATRIX_THETA
# 假设认为梯度小于0.00001时就进入谷底了
while not np.all(np.absolute(gradient) <= 1e-5):theta = theta - ALPHA * gradientgradient = loss_gradient(theta, MATRIX_X, VEC_Y)print(theta)
4.4.3.链式法则与网络中的梯度
链式法则就是求复合函数导数的法则,也就是高中学导数时候一句口诀说的“函数套一套,外导乘内导”——当一个关于x的函数f,可以视作关于x的函数g与关于g的函数h的复合时(h套g,g套x),f的导数就等于h关于g的导数乘g关于x的导数。
f(x)=h(g(x))f′(x)=h′(g(x))g′(x)\mathbf{f}(x)=\mathbf{h}(\mathbf{g}(x)) \\ \mathbf{f^{'}}(x)=\mathbf{h^{'}}(\mathbf{g}(x))\mathbf{g^{'}}(x) f(x)=h(g(x))f′(x)=h′(g(x))g′(x)
来看这样一个简单的网络——恒定神经元间的权重为1。

这里以Y对每一层的变量的梯度为例,观察得知,靠近输出Y的层还好,就是一阶偏导,但是越深入网络,Y对变量X的梯度就会被一层一层的偏导套起来。
∂y∂x0′=x1′=2∂y∂x1′=x0′=3∂y∂x0=∂y∂x0′∂x0′∂x0+∂y∂x1′∂x1′∂x0=2∗1+3∗0=2∂y∂x1=∂y∂x0′∂x0′∂x1+∂y∂x1′∂x1′∂x1=2∗1+3∗1=5\begin{aligned} &\frac{\partial y}{\partial x^{'}_0}=x^{'}_1=2 \\ &\frac{\partial y}{\partial x^{'}_1}=x^{'}_0=3 \\ &\frac{\partial y}{\partial x_0}= \frac{\partial y}{\partial x^{'}_0}\frac{\partial x^{'}_0}{\partial x_0}+ \frac{\partial y}{\partial x^{'}_1}\frac{\partial x^{'}_1}{\partial x_0}= 2*1+3*0=2 \\ &\frac{\partial y}{\partial x_1}= \frac{\partial y}{\partial x^{'}_0}\frac{\partial x^{'}_0}{\partial x_1}+ \frac{\partial y}{\partial x^{'}_1}\frac{\partial x^{'}_1}{\partial x_1}= 2*1+3*1=5 &\end{aligned} ∂x0′∂y=x1′=2∂x1′∂y=x0′=3∂x0∂y=∂x0′∂y∂x0∂x0′+∂x1′∂y∂x0∂x1′=2∗1+3∗0=2∂x1∂y=∂x0′∂y∂x1∂x0′+∂x1′∂y∂x1∂x1′=2∗1+3∗1=5
不难看出在计算Y对X的导数时重复计算了Y对**X’**的导数的一部分。
同理对于权重参数W的梯度,当网络结构变得复杂,拥有百万千万个参数的网络,难以想象会有多少冗余的计算。
4.4.4.反向传播提出
实际上,透过上文例子的偏导计算式,我们可以发现这样一个现象“最终输出对第1层求导结果实际上是对第2层求导结果的按照关系的累加”,这个现象可以推广,也就是说每层网络只需要关心临近层的偏导即可,只需计算一次沉淀下来,当最终结果要该层的偏导时,只需要将下层的偏导值累加就好。

简言之梯度计算的结果是逐层由前(输出层)向后(出入层)逐层传播的,也就是反向传播。在深度学习中,通过反向传播来更新每一层的权重,优化结果。
4.4.5.网络参数更新
那么网络的参数是如何利用梯度下降和反向传播更新的呢?具体看一个样例,假设:
-
神经元所在层数是l
-
神经元所在层位置是第i个
-
神经元的输入是in,第l层的第i个神经元的输入是in_l,i’
-
神经元的输出是out,第l层的第i个神经元的输出是out_l,i’,第l层的输出向量是OUTl
-
神经元间的权重是w,由l-1层的第i’到第l层的第i个神经元的权重为w_l,i’,i,第l层的权重矩阵是Wl,关于i的权重矩阵(向量)是Wli
-
神经元的偏差是b,第l层的第i个神经元的偏差是b_l,i’
-
激活函数f是Sigmoid,其导数具有特殊性质
-
损失函数Loss是平方损失函数(详见4.5.2)
inl,i=bl,i+Wl−1,iT×OUT⃗l−1outl,i=f(inl,i)f(x)=11+e−xf′(x)=f(x)(1−f(x))Loss=12(y^−y)2\begin{aligned} & \mathbf{in_{l,i}}=b_{l,i}+W^T_{l-1,i}\times\vec{OUT}_{l-1} \\ & \mathbf{out_{l,i}}=\mathbf{f}(in_{l,i}) \\ & \mathbf{f}(x)=\frac{1}{1+e^{-x}} \\ & \mathbf{f}^{'}(x)=\mathbf{f}(x)(1-\mathbf{f}(x)) \\ & \mathbf{Loss}=\frac{1}{2}(\hat{y}-y)^2 \end{aligned} inl,i=bl,i+Wl−1,iT×OUTl−1outl,i=f(inl,i)f(x)=1+e−x1f′(x)=f(x)(1−f(x))Loss=21(y^−y)2

权重更新的大体流程是
-
计算损失函数对原权重w的梯度g
-
计算学习率α乘g作为权重变化△
-
新权重等于原权重减△
wl,i′,i(new)=wl,i′,i(old)−α∂Loss∂wl,i′,iw^{(new)}_{l,i',i} = w^{(old)}_{l,i',i} - \alpha \frac{\partial \mathbf{Loss}}{\partial w_{l,i',i}} wl,i′,i(new)=wl,i′,i(old)−α∂wl,i′,i∂Loss
对于输出层而言,预测输出与真实输出存在残差。Y尖就是输出层的out,所以有梯度:
∂Loss∂w3,i′,i=∂Loss∂y^∂y^∂in3,i∂in3,i∂w3,i′,i=[12∗2∗(y^−y)][y^∗(1−y^)][out2,i′]=δ3∗out2,i′δ3=y^∗(1−y^)(y^−y)\begin{aligned} \frac{\partial \mathbf{Loss}}{\partial w_{3,i',i}} & = \frac{\partial \mathbf{Loss}}{\partial \hat{y}} \frac{\partial \hat{y}}{\partial in_{3,i}} \frac{\partial in_{3,i}}{\partial w_{3,i',i}} \\ & = [\frac{1}{2}*2*(\hat{y}-y)][\hat{y}*(1-\hat{y})][out_{2,i'}] \\ & = \delta_3*out_{2,i'} \\ \delta_3 & = \hat{y}*(1-\hat{y})(\hat{y}-y) \end{aligned} ∂w3,i′,i∂Lossδ3=∂y^∂Loss∂in3,i∂y^∂w3,i′,i∂in3,i=[21∗2∗(y^−y)][y^∗(1−y^)][out2,i′]=δ3∗out2,i′=y^∗(1−y^)(y^−y)
帮助大家结合链式法则理解一下,Loss并不是直接关于w的简单函数,而是复合函数:
Loss关于Y尖、再Y尖关于in也就是激活函数f、最后in关于w
将其套到整个权重矩阵中就有
∂Loss∂W3=δ3OUT2δ3=∂Loss∂y^f′(IN3)w3(new)=w3(old)−αδ3OUT2T\begin{aligned} \frac{\partial \mathbf{Loss}}{\partial W_{3}} & = \delta_3 OUT_{2} \\ \delta_3 & = \frac{\partial \mathbf{Loss}}{\partial \hat{y}}\mathbf{f}^{'}(IN_3)\\ w^{(new)}_{3} & = w^{(old)}_{3} - \alpha \delta_3 OUT^T_{2} \end{aligned} ∂W3∂Lossδ3w3(new)=δ3OUT2=∂y^∂Lossf′(IN3)=w3(old)−αδ3OUT2T
对于紧接输出层的隐藏层而言,根据链式法则有梯度:
∂Loss∂w2,i′,i=∂Loss∂y^∂y^∂in3∂in3∂out2,i∂out2,i∂in2,i∂in2,i∂w2,i′,i=[∑δ3w3][out2,i∗(1−out2,i)][out1,i′]=δ2∗out1,i′δ2=out2,i∗(1−out2,i)∗∑δ3w3\begin{aligned} \frac{\partial \mathbf{Loss}}{\partial w_{2,i',i}} & = \frac{\partial \mathbf{Loss}}{\partial \hat{y}} \frac{\partial \hat{y}}{\partial in_{3}} \frac{\partial in_{3}}{\partial out_{2,i}} \frac{\partial out_{2,i}}{\partial in_{2,i}} \frac{\partial in_{2,i}}{\partial w_{2,i',i}} \\ & = [\sum{\delta_3 w_{3}}][out_{2,i}*(1-out_{2,i})][out_{1,i'}] \\ & = \delta_2*out_{1,i'} \\ \delta_2 & = out_{2,i}*(1-out_{2,i})*\sum{\delta_3 w_{3}} \end{aligned} ∂w2,i′,i∂Lossδ2=∂y^∂Loss∂in3∂y^∂out2,i∂in3∂in2,i∂out2,i∂w2,i′,i∂in2,i=[∑δ3w3][out2,i∗(1−out2,i)][out1,i′]=δ2∗out1,i′=out2,i∗(1−out2,i)∗∑δ3w3
再帮助大家结合链式法则理解一下:
Loss关于Y尖、再Y尖关于输出层的in也就是激活函数f、再输出层的in关于隐藏层的out、再隐藏层的out关于隐藏层的in也是激活函数f、最后隐藏层的in关于隐藏层的w
将其套到整个权重矩阵中就有
∂Loss∂W2=δ2OUT1δ2=f′(IN2)(W3Tδ3)w3(new)=w3(old)−αδ3OUT2T\begin{aligned} \frac{\partial \mathbf{Loss}}{\partial W_{2}} & = \delta_2 OUT_{1} \\ \delta_2 & = \mathbf{f}^{'}(IN_2)(W^T_3\delta_3)\\ w^{(new)}_{3} & = w^{(old)}_{3} - \alpha \delta_3 OUT^T_{2} \end{aligned} ∂W2∂Lossδ2w3(new)=δ2OUT1=f′(IN2)(W3Tδ3)=w3(old)−αδ3OUT2T
可以发现,隐藏层的权重更新收到输出层梯度部分的“影响”,我们称这部分影响为误差项,后层的误差项反向传播到前层干预权重更新,这就是神经网络“梯度下降+链式法则+反向传播”构成的权重更新。由此可得第L层的权重更新公式
δL={f′(INL)(WL+1TδL+1)L:HiddenLayerf′(INL)∂Loss∂y^L:OutLayerWL(new)=WL(old)−αδLOUTL−1TBL(new)=BL(old)−αδL\begin{aligned} \delta_L &= \Bigg\{ \begin{aligned} &\mathbf{f}^{'}(IN_L)(W^T_{L+1} \delta_{L+1}) & L:HiddenLayer\\ &\mathbf{f}^{'}(IN_L)\frac{\partial \mathbf{Loss}}{\partial \hat{y}} & L:OutLayer\\ \end{aligned} \\ W^{(new)}_{L} & = W^{(old)}_{L} - \alpha \delta_L OUT^T_{L-1} \\ B^{(new)}_{L} & = B^{(old)}_{L} - \alpha \delta_L \end{aligned} δLWL(new)BL(new)={f′(INL)(WL+1TδL+1)f′(INL)∂y^∂LossL:HiddenLayerL:OutLayer=WL(old)−αδLOUTL−1T=BL(old)−αδL
4.4.6.梯度消失与爆炸
在梯度误差反向传播的的过程中,传递的误差项是以乘积而非加和的形式作用到上层误差项的。众所周知,指数也好乘积也好都是不好惹的家伙,翻脸比翻书还快。
以Sigmoid为例,其导数范围是0到0.25,就拿0.25来说吧,在5层网络中会发生什么?0.25乘5次是0.0009,如此小的数在计算时,暂且不谈double范围对其精度的影响,单说哪怕它精度完整保留对权重的影响也是微乎其微。假若误差传递更小、层更深时,权重甚至会停止更新,让深层网络退化成只有后几层在学习的浅层网络,这就是梯度消失。
反之,当传的参数项过大(至少大于一),那传递时也会越乘越大,各层需要更新很大的权重直到算法发散为止,这就是梯度爆炸。
通常,梯度消失是因为没有正确选择激活函数,或者网络初始化的权重过小导致的。
而梯度爆炸则是初始化的权重过大导致的。
所以在误差项传播的过程中,通常还会引入另一个处理——正则化处理。
4.5.损失函数
损失函数是优化网络参数的重要
-
分类任务:二分类、多分类,多用交叉熵损失函数
-
回归任务:多用绝对值损失函数、平方损失函数、Huber损失函数
4.5.1.交叉熵损失函数
这里就不从“信息熵 —> 条件熵 —> 交叉熵”这个路子介绍了,有关熵的知识不止适用于神经网络,有机会单开一期。这里就以“解决二分类问题中预测和真实的关系”为例引出交叉熵,再推广。
在二分类中存在下面的式子,当预测为正值时的概率为Y尖,那对应也表示为负值的概率为1-Y尖
这里的正负指的是二分类中的两类样本——正样本1、负样本0
{P(y=1∣x)=y^P(y=0∣x)=1−y^\bigg\{ \begin{aligned} & \mathbf{P}(y=1|x)=\hat{y} \\ & \mathbf{P}(y=0|x)=1-\hat{y} \end{aligned} {P(y=1∣x)=y^P(y=0∣x)=1−y^
那么,我们可以引入真实值Y来定义下式来表示
P(y∣x)=y^y∗(1−y^)1−y\mathbf{P}(y|x)=\hat{y}^{y}*(1-\hat{y})^{1-y} P(y∣x)=y^y∗(1−y^)1−y
很好理解,当真实值为1时保留前项,前项就是预测为1的概率。为0时保留后项,后项就是预测为0的概率。
当然其真实含义是预测值正确命中真实值的程度,“P结果越大,预测越准”——假如真实是1,那要想没误差,预测就应该也是1,也就是上式结果是1,预测的越远离1,上式结果就越小。同理,假如真实是0,那预测就应该也是0,上式结果还是1,预测的越远离0,上式结果还是越小。
但是前文说了,我们在优化函数时是梯度下降,也就是损失值越小越准才对,那我们就对上式取个负,翻过来。
Loss=−P(y∣x)=−y^y∗(1−y^)1−y\mathbf{Loss}=-\mathbf{P}(y|x)=-\hat{y}^{y}*(1-\hat{y})^{1-y} Loss=−P(y∣x)=−y^y∗(1−y^)1−y
再根据前文说的,梯度是求导,然而上式函数乘法的导不好求,指数函数的导也不好求,那需要做个变换让他指数不见,乘项变加项。显然对数函数可以一战。
Loss=−logP(y∣x)=−[ylogy^+(1−y)log(1−y^)]=−∑class=01yclasslogy^class\begin{aligned} \mathbf{Loss} & = -\log\mathbf{P}(y|x)=-[y\log\hat{y}+(1-y)\log(1-\hat{y})] \\ & = -\sum^{1}_{class=0}{y_{class}\log\hat{y}_{class}} \end{aligned} Loss=−logP(y∣x)=−[ylogy^+(1−y)log(1−y^)]=−class=0∑1yclasslogy^class
最后的求和式中Y尖当然还是预测为Class的概率哈,但是Y表示的是真实是否命中Class,命中就是1不命中就是0,推广到多分类就是:
Loss=−∑class=0nyclasslogy^class\mathbf{Loss} = -\sum^{n}_{class=0}{y_{class}\log\hat{y}_{class}} Loss=−class=0∑nyclasslogy^class
4.5.2.平方损失函数
在回归问题中最直观的度量损失,莫过于残差——Y减Y尖,残差的绝对值越小,损失越小。直接来绝对值损失函数:
Loss=∑i=1m∣y^i−yi∣\mathbf{Loss} = \sum^{m}_{i=1}{|\hat{y}_{i}-y_i|} Loss=i=1∑m∣y^i−yi∣
但是这个函数有个致命问题,梯度要求导,但当Y等于Y尖时也就是残差绝对值为0时这函数就不可导了!那如何解决绝对值在特殊点不可导,还能保持绝对值(非负值)性质呢?最直接的方式就是平方,于是有了平方损失(最小二乘损失),也就是4.4.2中举例子的函数。
Loss=∑i=1m12(y^i−yi)2\mathbf{Loss} = \sum^{m}_{i=1}{\frac{1}{2}(\hat{y}_{i}-y_i)^2} Loss=i=1∑m21(y^i−yi)2
这个函数的优点就是求导后变成了一次项并与系数抵消,但也有缺点,就是平方会扩大残差使得模型对其的“惩罚”就越大,鲁棒性较低。
4.5.3.Huber损失函数
那有没有什么办法把平方损失函数的缺点也干掉呢?简单啊,缝合绝对值损失函数和平方损失函数,取其精华去其糟粕。
Loss=∑i=1m{12(y^i−yi)2∣y^i−yi∣≤δ∣y^i−yi∣∣y^i−yi∣>δ\mathbf{Loss} = \sum^{m}_{i=1} \Bigg\{ \begin{aligned} & \frac{1}{2}(\hat{y}_{i}-y_i)^2 & |\hat{y}_{i}-y_i| \leq \delta\\ & |\hat{y}_{i}-y_i| & |\hat{y}_{i}-y_i| > \delta \end{aligned} Loss=i=1∑m{21(y^i−yi)2∣y^i−yi∣∣y^i−yi∣≤δ∣y^i−yi∣>δ
设计一个阈值,上文说残差越大平方后放大就越恐怖,那残差小于一定阈值应该和绝对值也差不了多少,或者说在可以接受的放大程度以内,用平方既能求导也能不存在过分放大。同理大于阈值就用绝对值,因为有残差不存在为0,也就不存在不可导,而且还不会过分放大。完美。
4.6.正则化
在4.4.6中简单说明了神经网络反向传播过程中会出现的两个问题——梯度消失和梯度爆炸。那么该怎么解决这些问题呢?正所谓擒贼先擒王,误差项的万恶之源就是由损失函数来的,所以在计算损失函数时,往往会在函数后面加上一个正则化项(也有叫范数项的),该项的前面还会有个正则化系数来控制其对损失函数的影响程度。
Loss(reg)=Loss(src)+ηR(w)\mathbf{Loss^{(reg)}}=\mathbf{Loss^{(src)}}+\eta\mathbf{R}(w) Loss(reg)=Loss(src)+ηR(w)
正则化有L1正则化和L2正则化。这里暂不对其数学含义进行推导,没啥可针对问题改进的了,一般都封装在框架中动不了。这里指通过图像的方式看看正则化都干了点啥。
4.6.1.L1正则化
L1正则化是将权重矩阵中各个权重的绝对值加和。
Loss(reg)=Loss(src)+η∑∣w∣\mathbf{Loss^{(reg)}}=\mathbf{Loss^{(src)}}+\eta\sum{|w|} Loss(reg)=Loss(src)+η∑∣w∣
假设Loss是与W1和W2两个权重有关的,想一下4.4.1中的二元函数的三维图像——一个真正的地势图,我们要在下降中一步一步跨过等高线,找到地势最低的点。假设横纵轴为W1和W2

而L1正则化就是W1和W2的绝对值和,函数图像就是

这个菱形也是个等值线,也就是下方两个红点会等值正则到尖尖的红点上。
可见这个菱形总有一个尖尖在“地势”相对较低的地方,而尖尖点的值有一个特点,就是会有一个轴的值为0,所以L1正则化可以产生一个稀疏效果,相当于特征选择,一定程度上可以防止过拟合。
4.6.2.L2正则化
L2正则化是将权重矩阵中各个权重的平方加和,最后再根号。
Loss(reg)=Loss(src)+η∑w2\mathbf{Loss^{(reg)}}=\mathbf{Loss^{(src)}}+\eta\sqrt{\sum{w^2}} Loss(reg)=Loss(src)+η∑w2
图就不画了,W1和W2的平方和开根就是圆嘛,把菱形换成圆形,则总有与W1和W2等值线相切的地方是“地势”相对较低的地方。那既然是相切的点,那大概率不是轴上的点——也就不会有一个轴的值为0,都有值,就没有特征选择效果。
但是L2正则化一定程度上也可以防止过拟合,它的原理是切点处的各个轴的值都比轴交点的值小,也就是同等Loss下W1和W2都选比较小的,这样其抗噪声能力就很强,也就是泛化性很强。
无奖众筹一个能化3维空间下多个函数图像的在线工具,这里没有3D的图,感觉差点直观性
4.7.学习率
4.7.1.梯度下降对样本的选取
上文介绍了如何根据损失函数、通过梯度下降、按照学习率更新权重参数。
(w,b)new=(w,b)old−ΔwΔw=α∇(w,b)Jloss(w,b)\begin{aligned} (w,b)^{new} &= (w,b)^{old} - \Delta w \\ \Delta w &= \alpha \nabla_{(w,b)}\mathbf{J_{loss}}(w,b) \end{aligned} (w,b)newΔw=(w,b)old−Δw=α∇(w,b)Jloss(w,b)
但这只是根据一条数据更新权重的流程,网络是如何学习整个训练集的呢?首先多条样本的权重更新肯定是取平均啦——每条样本计算出来的W相加除样本数m。问题是取多少样本来训练?
为了表示方便下面简写梯度表示
∇(w,b)Jloss(w,b)⟼∇JΘ\nabla_{(w,b)}\mathbf{J_{loss}}(w,b) \longmapsto \nabla \mathbf{J}\Theta ∇(w,b)Jloss(w,b)⟼∇JΘ
批量梯度下降 Batch GD
首先,最简单粗暴的就是“我全都要”,用整个训练集学习。但深度学习或者说神经网络的一个意义就是容易捕捉大量数据中的复杂特征,如果把大量数据全拿来算一次只为了更新一次权重,未免性能也太差了。但好处是可以防止进入局部最优(详见4.7.2)。
Δw=αm∑i=1m∇(w,b)J(Θ,xi,yi)\Delta w = \frac{\alpha}{m} \sum^{m}_{i=1}{\nabla_{(w,b)}\mathbf{J}( \Theta,x^i,y^i)} Δw=mαi=1∑m∇(w,b)J(Θ,xi,yi)
随机梯度下降 Stochastic GD
在另一个极端,不是样本全算慢嘛,那我只随机算一个就快了吧——即随机梯度下降。必然,只算一条肯定很快,但是这种下降方法必然会一叶障目,导致结果进入局部最优。
Δw=α∇J(Θ,xi,yi),mi=rand(1,m)\Delta w = \alpha \nabla\mathbf{J}( \Theta,x^{i},y^i) ,mi=rand(1,m) Δw=α∇J(Θ,xi,yi),mi=rand(1,m)
小批梯度下降 Mini-batch GD
所以我们一般会折中以上两种方法,取样本中的一小批来计算,既能保证保证训练速度,又能保证收敛后的准确率。唯一唯一的问题就只剩下不好调节的学习率了。
Δw=αn∑k=1n∇J(Θ,xi,yi),n∈(1,m),i=rand(1,m)\Delta w = \frac{\alpha}{n} \sum^{n}_{k=1}{ \nabla\mathbf{J}( \Theta,x^{i},y^i)} ,n \in (1,m),i=rand(1,m) Δw=nαk=1∑n∇J(Θ,xi,yi),n∈(1,m),i=rand(1,m)
4.7.2.学习率与局部最小
学习率的意义不必多言,但为什么说他难调节呢?还拿4.4.2中的“函数下山”为例,在4.4.2里为了解释梯度下降避免了一些小问题,看一下假如我们被扔在函数山的右侧而不是左侧会发生什么呢?


步子小了我们会进入一个局部的小山谷,即损失局部最优
步子大了我们会错过谷底,回去也没用,即损失发散/振荡/不收敛
所以先择一个合适的学习率,需要通过不断观察网络的收敛情况和收敛速度来制定。那我都神经网络了,还没有个什么方式自动调节学习率嘛?
4.7.3.衰减学习率
4.7.4.自调节学习率
> 动量优化法
自调节的起源就要从把物理学的动量/冲量/惯性思想引入开始。还说“函数下山”,假如下山的不是我们,而是一个小球会发生什么呢?
我们人的步子是均匀的(固定等长的),是匀速下降的,但假如是小球从右侧滚下的话,在重力加速度的作用下会越滚越快,在到达“局部山谷”时又拥有很大的动量(惯性)并不会被拦住,而是飞出去,但是飞不过“全局山谷”最终停在最低处。

这就是动量优化法——在梯度方向不变的维度上更新的越来越快,在梯度方向改变的维度上更新变慢。当然这一优化不仅仅解决了下降幅度自调节的问题,还解决了当不同参数(方向)上梯度差异大时,按照平均梯度下降效率慢的问题。如图:

W1方向明显比W2方向下降快,那么更多的倾向W1肯定会收敛的更快。图中蓝色线就是老老实实的梯度下降,红色线就是动量优化下的梯度下降。
> Momentum
经典的动量优化法就是Momentum,其原理就是在参数更新是保留一定的之前的更新的方向——使用上一次更新的一部分加这次的梯度作为这次的更新。
Δw=mnew=μmold+α∇JΘ\Delta w = m^{new} = \mu m^{old} + \alpha \nabla\mathbf{J}\Theta Δw=mnew=μmold+α∇JΘ
> NAG(Nesterov Accelerated Gradient)
我们继续看上面小球滚落的图,假如小球初始在左侧一定的位置上下落,这个位置恰好积攒足够的动量冲过最低点,那么小球依旧会最终停在局部最低。
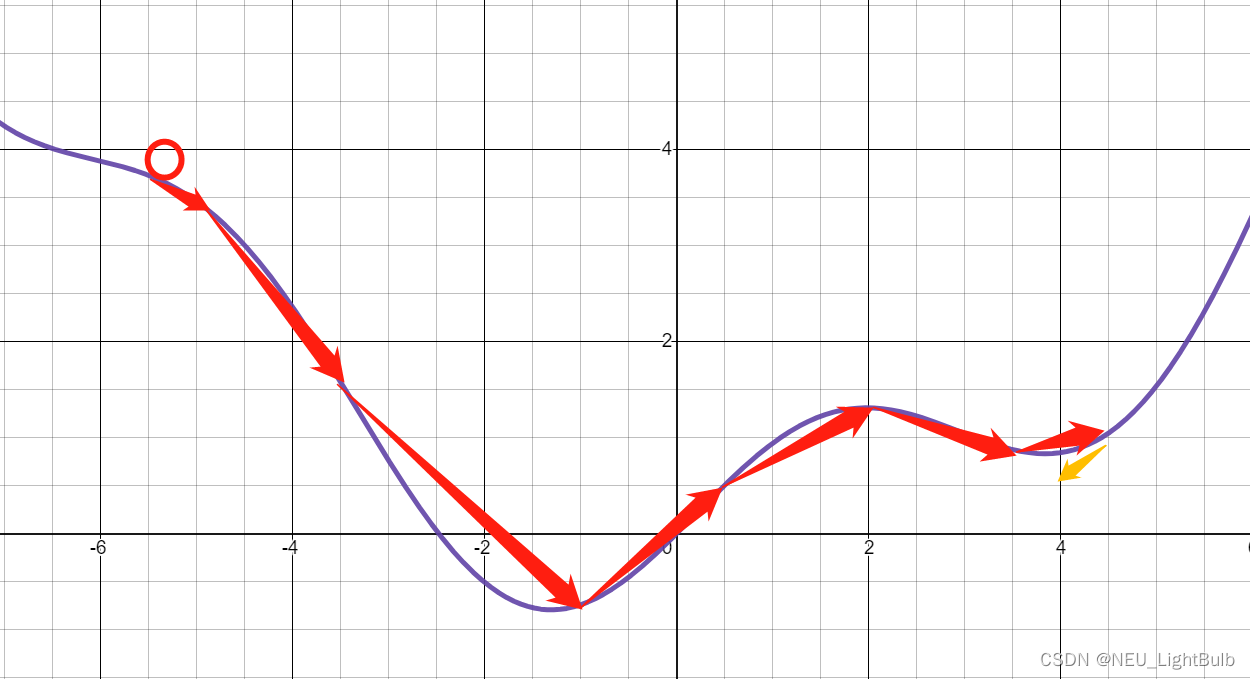
是对Momentum的优化,他除了在计算更新时考虑上一次的更新,还在计算梯度时考虑上一次的更新。
Δw=mnew=μmold+α∇J(Θ−μmold)\Delta w = m^{new} = \mu m^{old} + \alpha \nabla \mathbf{J}(\Theta- \mu m^{old}) Δw=mnew=μmold+α∇J(Θ−μmold)
这样的改变本质上是对梯度的一个矫正,在计算梯度时不是在当前位置而是在未来位置上,这使得下降具备一定的“
先知能力“,下降的不会那么快。
> AdaGrad
AdaGrad是用另一种方式引入上一次更新的影响——将上一次的梯度作为分母影响这一次的梯度,具体公式是。
Gnew=Gold+∇JΘ⊙∇JΘΔw=αGnew+ε∇JΘG^{new} = G^{old} + \nabla \mathbf{J }\Theta \odot \nabla \mathbf{J }\Theta \\ \Delta w = \frac{\alpha}{\sqrt{G^{new}+\varepsilon}}\nabla \mathbf{J }\Theta Gnew=Gold+∇JΘ⊙∇JΘΔw=Gnew+εα∇JΘ
ε是一个极小值防止分母为0,一般是0.00001
根号函数非负且越大越平缓,所以前面的梯度值越小更新就越快来放大梯度(又称激励阶段),前面的梯度值越大更新的反而越慢来约束梯度(又称惩罚阶段)。这种“原值加上参数乘变量平方和再开根”的思路基本是借鉴L2 正则化(详见4.6.2)
但这样会引入一个新的问题,随着迭代的进行,分母上累加的之前的梯度会越来越大,这加速了对梯度更新值的影响——使得梯度更新值被快速的修正的越来越小,以至训练提前结束。
> RMSProp
为了解决AdaGrad梯度更新快速收缩的问题,RMSProp首先对AdaGrad做了改进,对G的计算进行一阶指数平滑也就是指数加权平均
Gnew=ρGold+(1−ρ)∇JΘ⊙∇JΘG^{new} = \rho G^{old} + (1-\rho)\nabla \mathbf{J \Theta} \odot \nabla \mathbf{J \Theta} Gnew=ρGold+(1−ρ)∇JΘ⊙∇JΘ
这里简单说一下指数加权平均的意义,我们先将AdaGrad的G简单迭代几步:
G0=0G1=G0+∇JΘ1⊙∇JΘ1G2=G1+∇JΘ2⊙∇JΘ2=∇JΘ1⊙∇JΘ1+∇JΘ2⊙∇JΘ2G3=G2+∇JΘ3⊙∇JΘ3=∇JΘ1⊙∇JΘ1+∇JΘ2⊙∇JΘ2+∇JΘ3⊙∇JΘ3\begin{aligned} G^{0} & = 0 \\ G^{1} & = G^{0} + \nabla \mathbf{J \Theta_1} \odot \nabla \mathbf{J \Theta_1} \\ G^{2} & = G^{1} + \nabla \mathbf{J \Theta_2} \odot \nabla \mathbf{J \Theta_2} \\ & = \nabla \mathbf{J \Theta_1} \odot \nabla \mathbf{J \Theta_1} + \nabla \mathbf{J \Theta_2} \odot \nabla \mathbf{J \Theta_2} \\ G^{3} & = G^{2} + \nabla \mathbf{J \Theta_3} \odot \nabla \mathbf{J \Theta_3} \\ & =\nabla \mathbf{J \Theta_1} \odot \nabla \mathbf{J \Theta_1} + \nabla \mathbf{J \Theta_2} \odot \nabla \mathbf{J \Theta_2} + \nabla \mathbf{J \Theta_3} \odot \nabla \mathbf{J \Theta_3} \end{aligned} G0G1G2G3=0=G0+∇JΘ1⊙∇JΘ1=G1+∇JΘ2⊙∇JΘ2=∇JΘ1⊙∇JΘ1+∇JΘ2⊙∇JΘ2=G2+∇JΘ3⊙∇JΘ3=∇JΘ1⊙∇JΘ1+∇JΘ2⊙∇JΘ2+∇JΘ3⊙∇JΘ3
再将RMSProp的G简单迭代几步:
G0=0G1=ρG0+(1−ρ)∇JΘ1⊙∇JΘ1G2=ρG1+(1−ρ)∇JΘ2⊙∇JΘ2=ρ(ρG0+(1−ρ)∇JΘ1⊙∇JΘ1)+(1−ρ)∇JΘ2⊙∇JΘ2=(1−ρ)(ρ∇JΘ1⊙∇JΘ1+∇JΘ2⊙∇JΘ2)G3=ρG2+(1−ρ)∇JΘ3⊙∇JΘ3=(1−ρ)(ρ2∇JΘ1⊙∇JΘ1+ρ∇JΘ2⊙∇JΘ2+∇JΘ3⊙∇JΘ3)\begin{aligned} G^{0} & = 0 \\ G^{1} & = \rho G^{0} + (1-\rho)\nabla \mathbf{J \Theta_1} \odot \nabla \mathbf{J \Theta_1} \\ G^{2} & = \rho G^{1} + (1-\rho)\nabla \mathbf{J \Theta_2} \odot \nabla \mathbf{J \Theta_2} \\ & = \rho(\rho G^{0} + (1-\rho)\nabla \mathbf{J \Theta_1} \odot \nabla \mathbf{J \Theta_1}) + (1-\rho)\nabla \mathbf{J \Theta_2} \odot \nabla \mathbf{J \Theta_2} \\ & = (1-\rho)(\rho\nabla \mathbf{J \Theta_1} \odot \nabla \mathbf{J \Theta_1} + \nabla \mathbf{J \Theta_2} \odot \nabla \mathbf{J \Theta_2}) \\ G^{3} & = \rho G^{2} + (1-\rho)\nabla \mathbf{J \Theta_3} \odot \nabla \mathbf{J \Theta_3} \\ & =(1-\rho)(\rho^2\nabla \mathbf{J \Theta_1} \odot \nabla \mathbf{J \Theta_1} + \rho \nabla \mathbf{J \Theta_2} \odot \nabla \mathbf{J \Theta_2} + \nabla \mathbf{J \Theta_3} \odot \nabla \mathbf{J \Theta_3}) \end{aligned} G0G1G2G3=0=ρG0+(1−ρ)∇JΘ1⊙∇JΘ1=ρG1+(1−ρ)∇JΘ2⊙∇JΘ2=ρ(ρG0+(1−ρ)∇JΘ1⊙∇JΘ1)+(1−ρ)∇JΘ2⊙∇JΘ2=(1−ρ)(ρ∇JΘ1⊙∇JΘ1+∇JΘ2⊙∇JΘ2)=ρG2+(1−ρ)∇JΘ3⊙∇JΘ3=(1−ρ)(ρ2∇JΘ1⊙∇JΘ1+ρ∇JΘ2⊙∇JΘ2+∇JΘ3⊙∇JΘ3)
可以看出随着传递,AdaGrad中越先前的梯度和后进来的梯度永远是等系数1的,这就造成了累积过快过大。但是RMSProp中的梯度前都会有一个小于1的系数,且越先前的梯度的系数幂次会越来越高,也就是越来越小,这样就实现了对遥远梯度的“遗忘”
又因为当ρ取0.5时,分母可以近似为均方根(RMS)公式简化,设目前为迭代的第t步,则最终表示为
Δw=αRMS[G]t∇JΘ\Delta w = \frac{\alpha}{RMS[G]_{t}}\nabla \mathbf{J }\Theta Δw=RMS[G]tα∇JΘ
> AdaDelta
说了这么多,虽然我们逐步提高了梯度下降程度的“智能性”降低调节学习率α的难度,但我们还是没有摆脱它。AdaDelta基于一种想法——使用同样自适应的系数代替学习率。
这里为了后面听着不蒙,捎带一下牛顿法。牛顿法本身是一阶算法,本质是求根算法,但如果用来求最优解(极小值点),这时就要求函数导数为0的根,就需要求二阶导数,就变成了二阶算法。
设Xm为函数f的极小值估计值,则在其对f做二阶泰勒展开有:
F(x)=f(xm)+f′(xm)(x−xm)+12f′′(xm)(x−xm)2F′(x)=f′(xm)+f′′(xm)(x−xm)\mathbf{F}(x)=\mathbf{f}(x_m)+\mathbf{f^{'}}(x_m)(x-x_m)+\frac{1}{2}\mathbf{f^{''}}(x_m)(x-x_m)^2 \\ \mathbf{F^{'}}(x)=\mathbf{f^{'}}(x_m)+\mathbf{f^{''}}(x_m)(x-x_m) F(x)=f(xm)+f′(xm)(x−xm)+21f′′(xm)(x−xm)2F′(x)=f′(xm)+f′′(xm)(x−xm)
因为极值点F的导为0,则推得:
x=xm−f′(xm)f′′(xm)x=x_m-\frac{\mathbf{f^{'}}(x_m)}{\mathbf{f^{''}}(x_m)} x=xm−f′′(xm)f′(xm)
同里推广到高维有:
F(x⃗)=f((xm⃗)+∇f(xm⃗)(x⃗−xm⃗)+12(x⃗−xm⃗)T∇2f(xm⃗)(x⃗−xm⃗)\mathbf{F}(\vec{x})=\mathbf{f}((\vec{x_m})+\nabla \mathbf{f}(\vec{x_m})(\vec{x}-\vec{x_m})+\frac{1}{2}(\vec{x}-\vec{x_m})^T \nabla^2 \mathbf{f}(\vec{x_m})(\vec{x}-\vec{x_m}) F(x)=f((xm)+∇f(xm)(x−xm)+21(x−xm)T∇2f(xm)(x−xm)
其中▽f就是梯度,记作gm,▽^2f我们称为f的Hessian矩阵,记作Hm,推得
x⃗=xm⃗−Hm−1gm\vec{x}=\vec{x_m}-\mathbf{H}^{-1}_m g_m x=xm−Hm−1gm
若我们视X为Xm的下一次估计值Xm+1,则有
Δx=Hm−1gm\Delta x = \mathbf{H}^{-1}_m g_m Δx=Hm−1gm
若我们这个式子套到梯度下降的△w,岂不是说学习率α可以用Hessian矩阵的逆来表示?这就是AdaDelta,他把Hessian矩阵的逆利用**[Becker&LeCun 1988的近似方法]**近似到RMS,具体推导过程不做详解,感兴趣可以搜一下,挺玄学的。这里直接给最终公式,设目前为迭代的第t步
Δwnew=RMS[Δw]t−1RMS[G]t∇JΘ\begin{aligned} \Delta w^{new} = \frac{RMS[\Delta w]_{t-1}}{RMS[G]_{t}}\nabla \mathbf{J }\Theta \end{aligned} Δwnew=RMS[G]tRMS[Δw]t−1∇JΘ
至此,再无学习率α。他唯一的问题就是会在训练后期在局部最小值附近反复抖动。
> Adam
最后说一个,虽然没有摆脱学习率,但仍然活跃在前线的Adam。他的思想就是RMSProp的思想,只不过更大胆!RMSProp只是对G的计算进行一阶指数平滑,而Adam干脆连着梯度一起平滑。
Gnew=ρGold+(1−ρ)∇JΘ⊙∇JΘMnew=γMold+(1−γ)∇JΘΔw=αGnew+εMnew\begin{aligned} G^{new} & = \rho G^{old} + (1-\rho)\nabla \mathbf{J \Theta} \odot \nabla \mathbf{J \Theta} \\ M^{new} & = \gamma M^{old} + (1-\gamma)\nabla \mathbf{J \Theta} \\ \Delta w & = \frac{\alpha}{\sqrt{G^{new}+\varepsilon}}M^{new} \end{aligned} GnewMnewΔw=ρGold+(1−ρ)∇JΘ⊙∇JΘ=γMold+(1−γ)∇JΘ=Gnew+εαMnew
相关文章:
从0探索NLP——神经网络
从0探索NLP——神经网络 1.前言 一提人工智能,最能想到的就是神经网络,但其实神经网络只是深度学习的主要实现方式。 现在主流的NLP相关任务、模型大都是基于深度学习也就是构建神经网络实现的,所以这里讲解一下神经网络以及简单的神经网络…...
计算机操作系统和进程
✨个人主页:bit me👇 ✨当前专栏:Java EE初阶👇 ✨每日一语:心平能愈三千疾,心静可通万事理。 目 录🐬一. 操作系统🍦1. 操作系统是什么?🍨2. 操作系统的两个…...
JAVA服务端实现页面截屏(附代码)
JAVA服务端实现页面截屏适配需求方案一、使用JxBrowser使用步骤:方案二、JavaFX WebView使用步骤:方案三、Headless Chrome使用步骤:综上方案对比记录我的一个失败方案参考适配需求 有正确完整的地址url;通过浏览器能打开该url对…...

Java入门要知道!
首先我们都知道的是Java是一门面向对象的编程语言,不仅吸收了C语言的各种优点,还摒弃了C里难以理解的多继承、指针等概念,因此Java语言具有功能强大和简单易用两个特征。Java语言作为静态面向对象编程语言的代表,极好地实现了面向…...

[6/101] 101次软件测试面试之经典面试题剖析
01、自我介绍答:大家好,我是一名软件测试工程师,但我更喜欢称自己为“软件bug捕手”。我相信,软件测试工程师的使命就是让软件更加健壮、更加可靠、更加美好。我们就像是一群“特警”,在黑暗的代码中寻找漏洞和缺陷&am…...
电脑c盘满了变成红色了怎么清理,清理c盘详细攻略
我们的电脑当用了一段时间之后,其实自然而然的就会有一点点卡,其实这是因为我们的电脑c盘满了,所以会造成卡顿是正常的,今天我们就来聊一聊电脑c盘满了变成红色了怎么清理? 一.电脑c盘为啥会满 软件安装:当…...
现在的00后,实在是太卷了
现在的小年轻真的卷得过分了。前段时间我们公司来了个00年的,工作没两年,跳槽到我们公司起薪18K,都快接近我了。后来才知道人家是个卷王,从早干到晚就差搬张床到工位睡觉了。 最近和他聊了一次天,原来这位小老弟家里条…...

RocketMQ概述
RocketMQ入门学习MQ概述MQ简介MO用途限流削峰异步解耦数据收集常见的MQ产品ActiveMQRabbitMQKafkaRocketMQ对比MQ常见协议JMSSTOMPAMOPMQTTMQ概述 MQ简介 MQ,Message Queue,是一种提供消息队列服务的中间件,也称为消息中间件,是…...
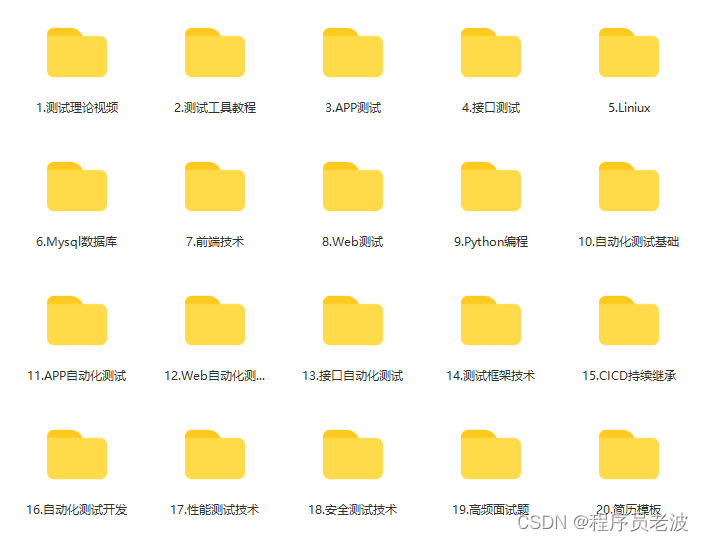
解决Ubuntu22.04.1上安装ch34x串口驱动报 Key was rejected by service 需要签名的问题
解决Ubuntu22.04.1上安装ch34x串口驱动报 Key was rejected by service 需要签名的问题问题官网下载解压驱动包编译安装给驱动签名再来载入模块(设备驱动程序)问题 Ubuntu22.04.1 Linux版本5.19.0-32-generic 运行Qt串口通信 m_serialPort->open(QIO…...
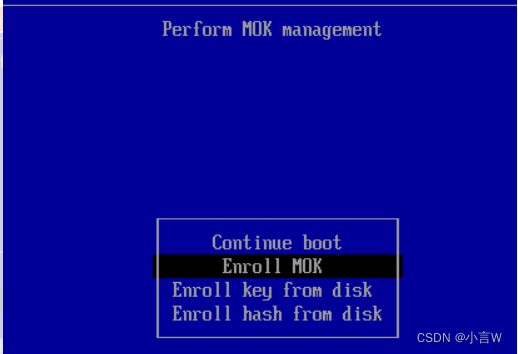
[python入门㊿] - python如何打断点
目录 ❤ 什么是bug(缺陷) ❤ python代码的调试方式 ❤ 使用 pdb 进行调试 测试代码示例 利用 pdb 调试 退出 debug debug 过程中打印变量 停止 debug 继续执行程序 debug 过程中显示代码 使用函数的例子 对函数进行 debug 在调试的时候动态改变值 ❤ 使用 PyC…...
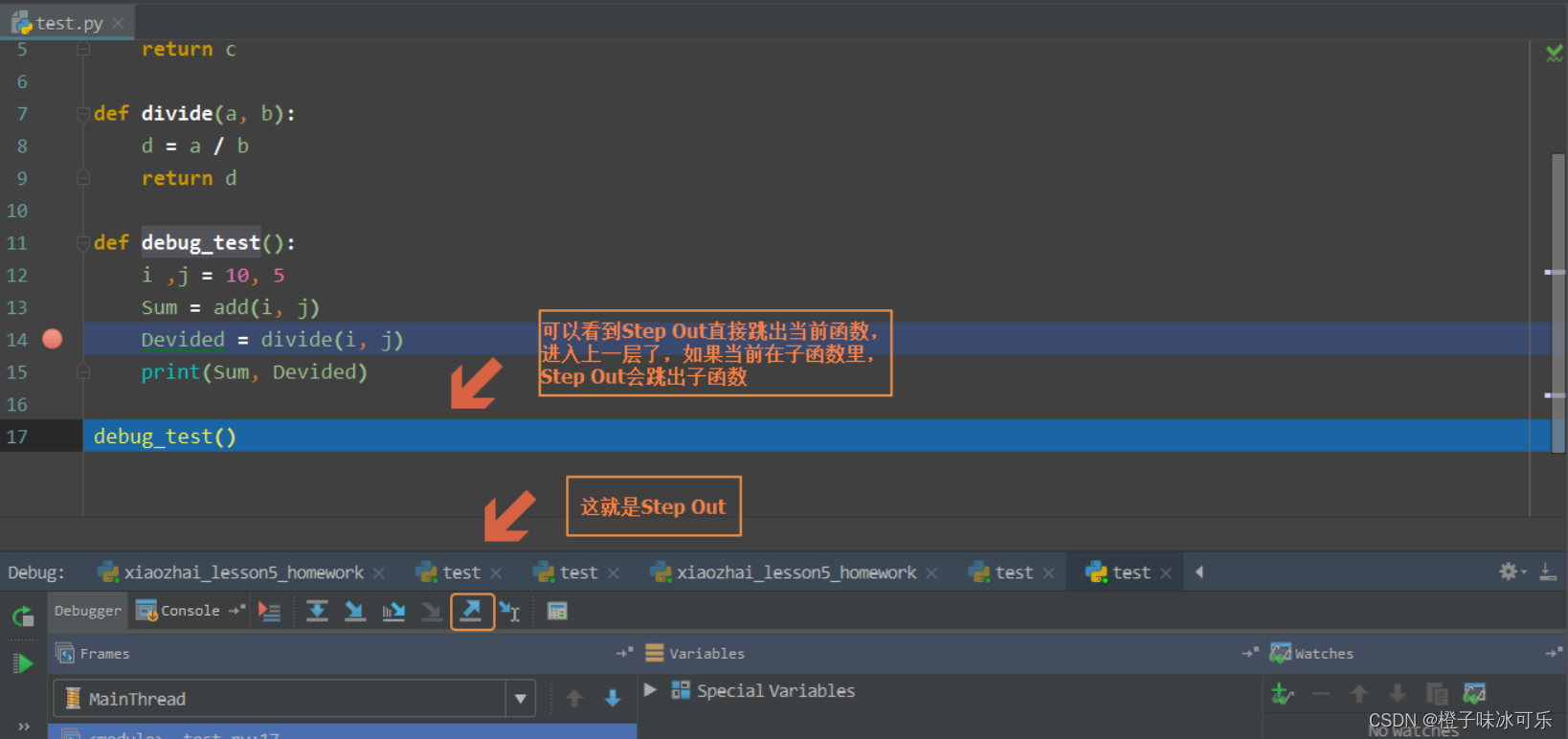
CCNP350-401学习笔记(501-550题)
501、Refer to the exhibit. What is the effect of the configuration? A. The device will allow users at 192.168.0.202 to connect to vty lines 0 through 4 using the password ciscotestkey B. The device will allow only users at 192 168.0.202 to connect to vty …...
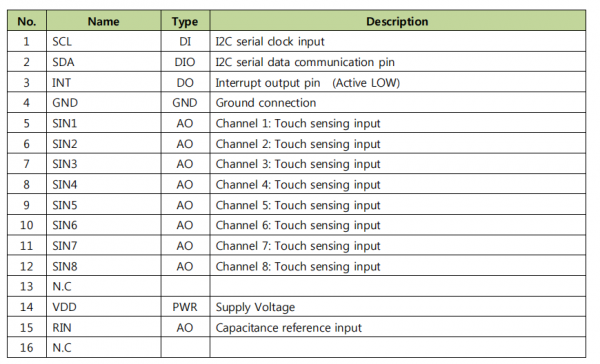
音箱上8键触摸芯片绿芯GTC08L完美替换启攀微
由工采网代理提供的韩国GreenChip电容式触摸芯片-GTC08L是GreenTouch5CTM电容式触摸传感器系列之一;可以在发动机运行下进行8通道电容传感;对电磁兼容、电磁干扰、温湿度变化、电压干扰、温度漂移、湿度漂移等都有较强的抗干扰能力。不会对CS, RS,EFT&am…...
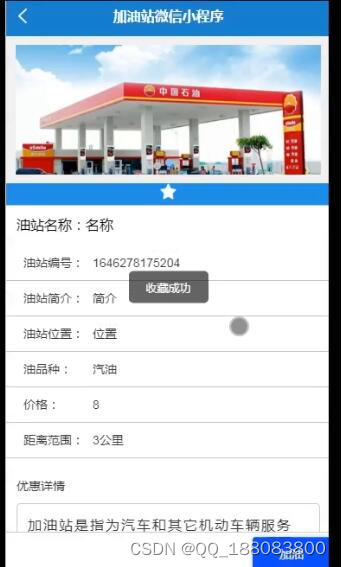
php+vue加油站会员服务系统 java微信小程序
目 录 1绪论 1 1.1项目研究的背景 1 1.2开发意义 1 1.3项目研究现状及内容 5 1.4论文结构 5 2开发技术介绍 7 2.5微信小程序技术 8 3系统分析 9 3.1可行性分析 9 3.1.1技术可行性 9 3.1.2经济可行性 9 3.1.3操作可行性 10 3.2网站性能需求分析 10 3.3网站功能分析 10 3.4系统…...

ES6--class类(详解/看完必会)
目录 1、基本概念 2、基本用法 3、class与构造函数的区别 4、constructor的使用 5、自定义方法 6、extends和super (1)问题一:我们想要在点击按钮二的时候改变字体大小,如何写呢? (2)问…...

ChatGPT的出现网络安全专家是否会被替代?
ChatGPT的横空出世,在业界掀起了惊涛骇浪。很多人开始担心,自己的工作岗位是否会在不久的将来被ChatGPT等人工智能技术所取代。网络安全与先进技术发展密切相关,基于人工智能的安全工具已经得到很多的应用机会,那么未来是否更加可…...

游戏服务器框架设计 总纲
服务器框架篇: 1.配置文件系统 libxml 2.日志系统 log4xx 3.数据库保存以及接口设计 4.Proto协议定义 5.Redis接口设计 6.网络层设计 epoll/iocp 7.服务器内部协议路由层设计 8.分布式节点管理设计 9.服务器负载伸缩管理设计 10.服务器进程热更流程设计 11.GM系…...

PB里post提交
PB 通过 PostRul 一、 创建Standard Class对象 type为"internetresult" n_ir 二、 界面中,增加按钮。点击测试post提交。 Blob lblb_args String ls_header String ls_url String ls_args Long ll_length Integer li_rc inet iinet_base,iinet n_ir ir iinet_ba…...

Linux 配置网卡(基础配置、网卡会话配置、网卡绑定配置)
目录 配置网卡基本信息 通过nmcli命令配置网卡 通过配置网卡文件配置网卡 通过nmtui命令配置网卡 通过nm-connection-editor命令配置网卡 网卡高级配置 配置网络会话 配置网卡绑定(Bonding) 通过nmcli命令配置网卡绑定 nm-connection-editor 进…...
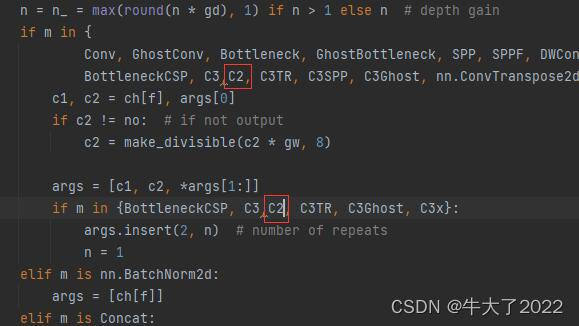
深度学习Week16-yolo.py文件解读(YOLOv5)
目录 简介 需要的基础包和配置 二、主要组件介绍 2.1 parse_model 2.2Detect类 2.3DetectionModel类 三、实验 🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有) 🍖 作者:[K同学啊…...
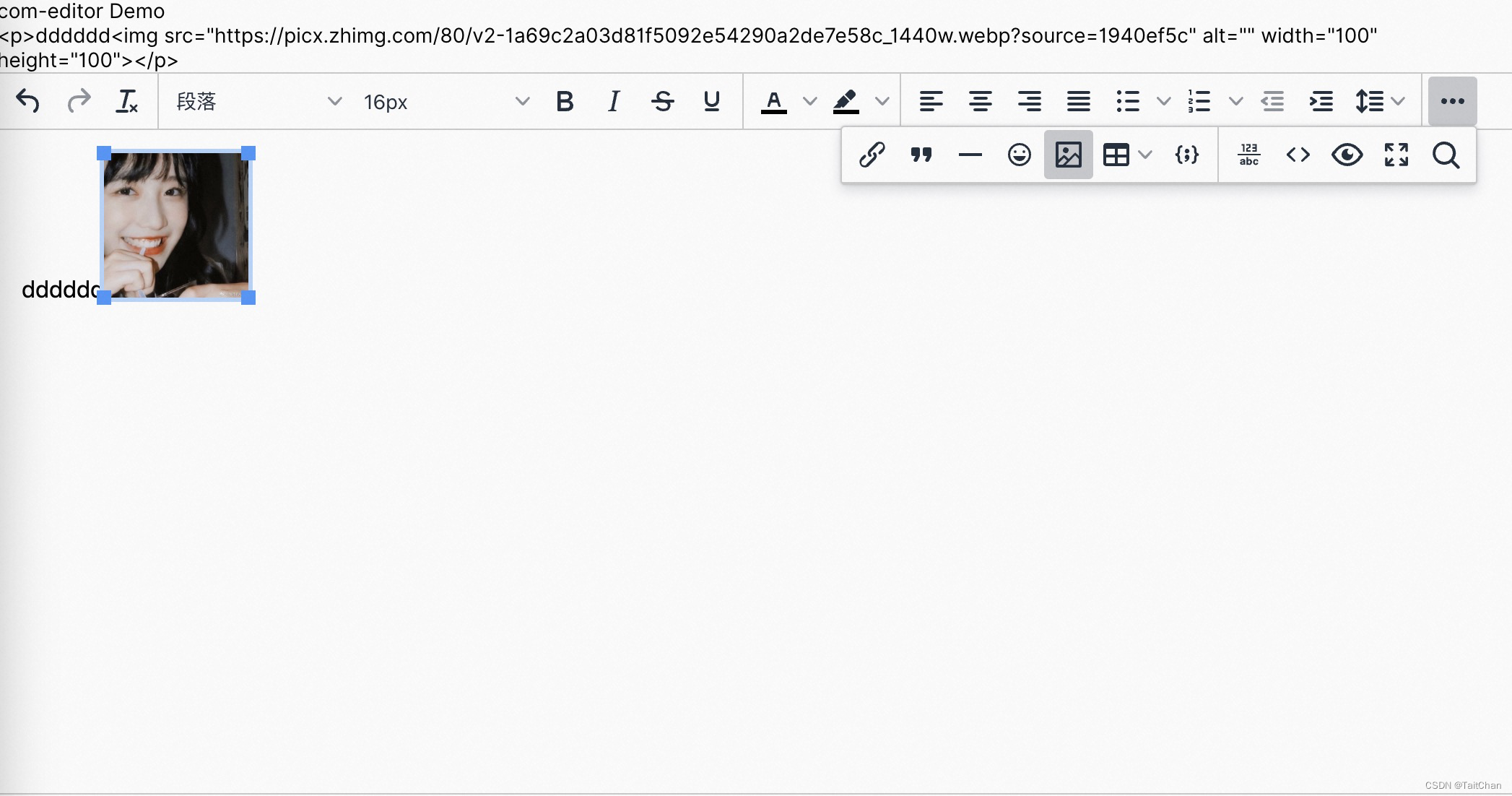
富文本编辑组件封装,tinymce、tinymce-vue
依赖:package.json yarn add tinymce tinymce/tinymce-vue {"dependencies": {"tinymce/tinymce-vue": "5.0.0","tinymce": "6.3.1","vue": "3.2.45",}, } 本地依赖: 在publ…...

PKSM终极指南:从第一世代到第八世代的宝可梦存档管理神器
PKSM终极指南:从第一世代到第八世代的宝可梦存档管理神器 【免费下载链接】PKSM Gen I to GenVIII save manager. 项目地址: https://gitcode.com/gh_mirrors/pk/PKSM PKSM是一款功能强大的免费开源宝可梦存档管理工具,支持从第一世代到第八世代的…...

3大焕新方案:老旧iOS设备性能重生全指南
3大焕新方案:老旧iOS设备性能重生全指南 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to downgrade/restore, save SHSH blobs, and jailbreak legacy iOS devices 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit 老旧iOS设备随着系统…...
在KITTI数据集上的完整流程)
从代码到部署:手把手复现CenterPoint(PyTorch版)在KITTI数据集上的完整流程
从零实现CenterPoint:KITTI数据集3D目标检测全流程实战指南 为什么选择CenterPoint进行3D目标检测? 在自动驾驶和机器人感知领域,3D目标检测一直是核心技术难题。传统基于锚框(Anchor-based)的方法在处理旋转物体时表现…...

OpenClaw 深度研究报告:从开源框架到企业级智能体平台的演进之路
一、核心定位:突破"对话天花板"的执行中枢 OpenClaw(外号"龙虾") 是由奥地利工程师 Peter Steinberger 于 2025 年底开发的本地优先、模型无关的 AI 智能体运行框架。其核心价值主张极为鲜明: “The AI that …...
)
ROS实战:5分钟搞定大华网络摄像机RTSP流接入(Ubuntu18.04+Melodic版)
ROS实战:5分钟搞定大华网络摄像机RTSP流接入(Ubuntu18.04Melodic版) 在智能机器人开发领域,实时视频流处理是构建环境感知系统的核心能力之一。大华作为安防行业领先品牌,其网络摄像机被广泛应用于工业检测、智能巡检等…...

AsrTools终极指南:三步实现免费语音转文本,效率提升300%的完整方案
AsrTools终极指南:三步实现免费语音转文本,效率提升300%的完整方案 【免费下载链接】AsrTools ✨ AsrTools: Smart Voice-to-Text Tool | Efficient Batch Processing | User-Friendly Interface | No GPU Required | Supports SRT/TXT Output | Turn yo…...

开源字体实用指南:Poppins字体家族的全方位应用策略
开源字体实用指南:Poppins字体家族的全方位应用策略 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 价值定位:如何让开源字体成为项目的视觉资产&#x…...

Bilibili-Evolved性能优化实战:突破60fps流畅播放全解析
Bilibili-Evolved性能优化实战:突破60fps流畅播放全解析 【免费下载链接】Bilibili-Evolved 强大的哔哩哔哩增强脚本 项目地址: https://gitcode.com/gh_mirrors/bi/Bilibili-Evolved Bilibili-Evolved作为强大的哔哩哔哩增强脚本,通过深度优化浏…...

OCRmyPDF技术解构:3大创新点与制造业/法律服务效能优化实践
OCRmyPDF技术解构:3大创新点与制造业/法律服务效能优化实践 【免费下载链接】OCRmyPDF OCRmyPDF adds an OCR text layer to scanned PDF files, allowing them to be searched 项目地址: https://gitcode.com/GitHub_Trending/oc/OCRmyPDF 一、技术内核&…...

基于SpringBoot+Vue的月度员工绩效考核管理系统管理系统设计与实现【Java+MySQL+MyBatis完整源码】
摘要 现代企业管理中,绩效考核是提升员工工作效率、优化人力资源配置的重要手段。传统的绩效考核多依赖纸质记录或简单的电子表格,存在数据易丢失、统计效率低、反馈周期长等问题。随着信息化技术的发展,企业亟需一套高效、精准的绩效考核管理…...