数据仓库整理
数仓
olap vs oltp
- OLTP主要用于支持日常的业务操作,如银行交易、电子商务等,强调数据的准确性、实时性和并发性。
- OLAP主要用于支持复杂的数据分析,如数据仓库、决策支持等,强调数据的维度、聚合和可视化。
将OLTP数据库的数据转移到OLAP数据库的过程一般包括以下几个步骤:
- 数据抽取:从OLTP数据库中提取需要分析的数据,可以使用SQL语句、ETL工具或者其他方法。
- 数据清洗:对抽取出来的数据进行质量检查和修正,去除重复、错误或者不一致的数据,保证数据的完整性和有效性。
- 数据转换:根据OLAP数据库的结构和需求,对数据进行适当的变换和加工,如进行聚合、分组、排序等操作,生成事实表和维度表。
- 数据加载:将转换后的数据加载到OLAP数据库中,可以使用批量加载、增量加载或者实时加载等方式。
- 数据刷新:定期或者根据事件触发,对OLAP数据库中的数据进行更新和同步,保证数据的时效性和一致性。
数据仓库
源数据层是数据仓库的基础层,它负责从各种数据源抽取、清洗、转换和加载原始数据,保证数据的完整性、准确性和一致性。模型层是数据仓库的核心层,它负责对源数据层的数据进行进一步的加工、聚合和建模,使得数据更加适合分析和查询。模型层通常采用维度建模,将数据划分为事实表和维度表,事实表存储业务过程中发生的事件,维度表存储事件的属性。指标层是数据仓库的最上层,负责对模型层的数据进行最终的应用和呈现,提供给用户或系统使用。分层优点:复杂问题简单化、清晰数据结构(方便管理)、增加数据的复用性、隔离原始数据(解耦)
ods 原始数据层 存放原始数据,保持原貌不做处理
dwd 明细数据层 对ods层数据清洗(去除空值,脏数据,超过极限范围的数据)
dws 服务数据层 轻度聚合
ads 应用数据层 具体需求
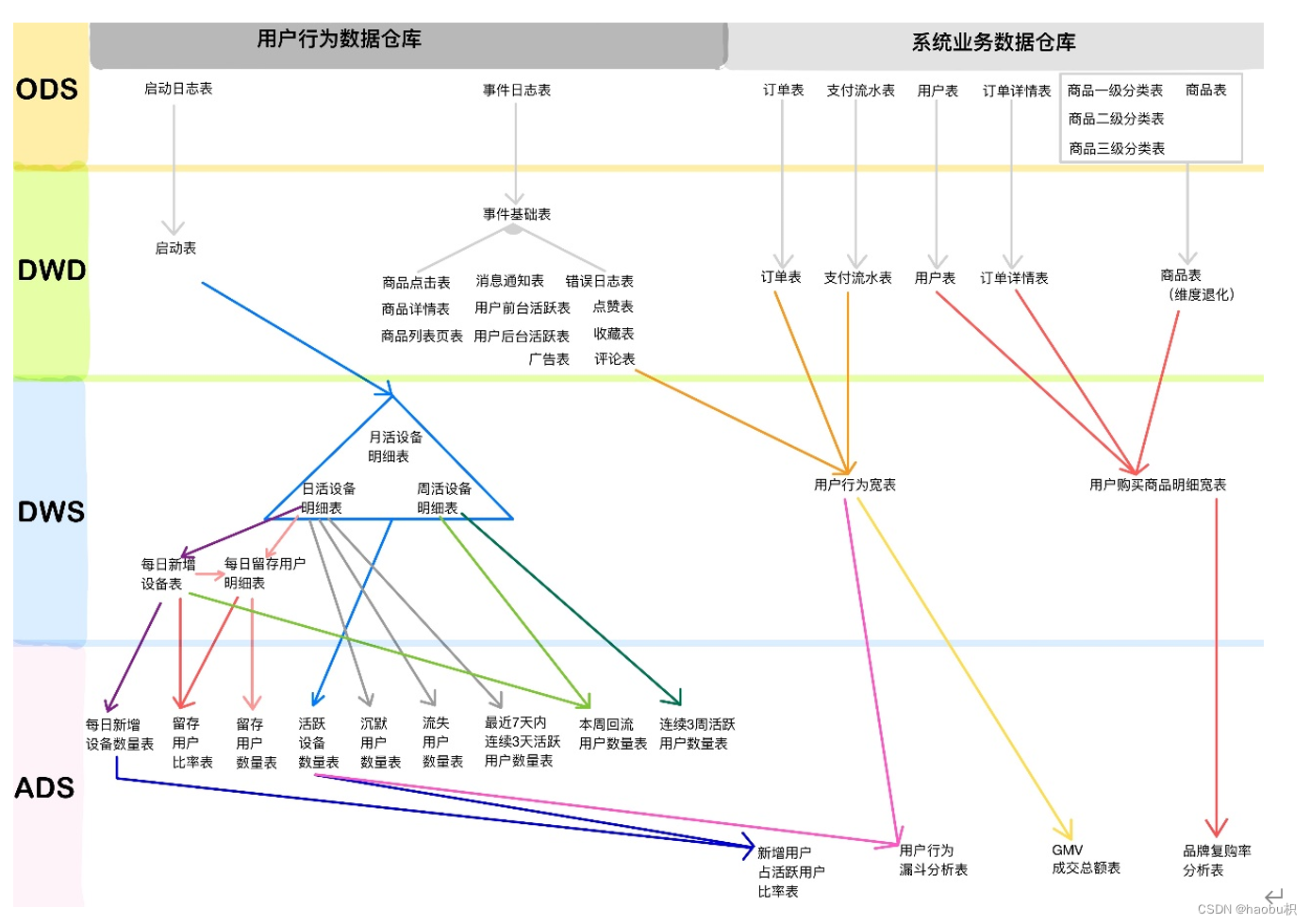
ODS(原始数据库)(Operation Data Store)
保持数据原貌,不做任何修改;压缩采用 LZO,压缩比是 100g 数据压缩完 10g 左右。创建分区表
DWD(明细数据层)(Data Warehouse Detail)
-
数据清洗
(1)空值去除
(2)过滤核心字段无意义的数据,比如订单表中订单 id 为 null,支付表中支付 id 为空
(3)将用户行为宽表和业务表进行数据一致性处理 -
清洗的手段
Sql、mr、rdd、kettle、Python等等 -
清洗掉多少数据算合理
1 万条数据清洗掉 1 条。 -
脱敏
对手机号、身份证号等敏感数据脱敏 -
维度退化
对业务数据传过来的表进行维度退化和降维。(商品一级二级三级、省市县、年月日) -
LZO压缩
-
列式存储 parquet
DWS(服务数据层)(Data Warehouse Summary)
DWS 层有 3-5 张宽表(处理 100-200 个指标 70%以上的需
求)
具体宽表名称:用户行为宽表,用户购买商品明细行为宽表,商品宽表,购物车宽表,物流宽表、登录注册、售后等。
哪个宽表最宽?大概有多少个字段?
最宽的是用户行为宽表。大概有 60-100 个字段
具体用户行为宽表字段名称
评论、打赏、收藏、关注–商品、关注–人、点赞、分享、好价爆料、文章发布、活跃、签到、补签卡、幸运屋、礼品、金币、电商点击、gmv
DWT(主题数据层)(Data Warehouse Topic)
分析过的指标
日活、月活、周活、留存、留存率、新增(日、周、年)、转化率、流失、回流、七天内连续 3 天登录(点赞、收藏、评价、购买、加购、下单、活动)、连续 3 周(月)登录、GMV、复购率、复购率排行、点赞、评论、收藏、领优惠价人数、使用优惠价、沉默、值不值得买、退款人数、退款率 topn 热门商品
留转 G 复活指标
(1)活跃
日活:100 万 ;月活:是日活的 2-3 倍 300 万
总注册的用户多少?1000 万-3000 万之间
(2)GMV
GMV:每天 10 万订单 (50 – 100 元) 500 万-1000 万
10%-20% 100 万-200 万
(3)复购率
某日常商品复购;(手纸、面膜、牙膏)10%-20%
电脑、显示器、手表 1%
(4)转化率
商品详情 =》 加购物车 =》下单 =》 支付
5%-10% 60-70% 90%-95%
(5)留存率
1/2/3、周留存、月留存
搞活动: 10-20%
ADS(应用数据层)(Application Data Store)
如何分析用户活跃?
在启动日志中统计不同设备 id 出现次数。
如何分析用户新增?
用活跃用户表 left join 用户新增表,用户新增表中 mid 为空的即为用户新增。
如何分析用户 1 天留存?
留存用户=前一天新增 join 今天活跃
用户留存率=留存用户/前一天新增
如何分析沉默用户?
(登录时间为 7 天前,且只出现过一次)
按照设备 id 对日活表分组,登录次数为 1,且是在一周前登录。
如何分析本周回流用户?
本周活跃 left join 本周新增 left join 上周活跃,且本周新增 id 和上周活跃 id 都为 null。
如何分析流失用户?
(登录时间为 7 天前)
按照设备 id 对日活表分组,且七天内没有登录过。
如何分析最近连续 3 周活跃用户数?
按照设备 id 对周活进行分组,统计次数大于 3 次。
如何分析最近七天内连续三天活跃用户数?
1)查询出最近 7 天的活跃用户,并对用户活跃日期进行排名
2)计算用户活跃日期及排名之间的差值
3)对同用户及差值分组,统计差值个数
4)将差值相同个数大于等于 3 的数据取出,然后去重,即为连续 3 天及以上活跃的用户
7 天连续收藏、点赞、购买、加购、付款、浏览、商品点击、退货
1 个月连续 7 天
连续两周
数据仓库建模的方法
- ER模型是Inmon提出的,这个模型是符合3范式的,他的出发点就是整合数据,将各个系统中的数据以整个企业角度按主题进行分类,但是不能直接用于分析决策
- 维度模型是Kimball提出的,这个人和Inmon算是数仓的两个流派,他的出发点就是分析决策,为分析需求服务,而现在多数的数仓的搭建都是基于维度模型进行搭建的。
- 区别:ER模型冗余更少,但是在大规模数据跨表分析中,会造成多表关联,这会大大降低执行效率
维度模型
维度模型主要由事实表和维度表组成,事实表存储可度量的指标,维度表存储描述性的属性。维度模型有三种典型的形式:星型模型、雪花模型和星座模型。维度模型简单直观,适合业务变化快速的行业,能够快速交付,提高查询性能。
- 星型模型:星型模型是由一个事实表和多个维度表组成的,每个维度表都直接与事实表相连接,形成一个类似星星的结构。星型模型的优点是简单直观,易于理解和使用,查询性能高,适合快速交付和变化频繁的业务需求。星型模型的缺点是数据冗余度高,可能导致数据不一致和存储空间浪费,维度表的层次结构不明显,不利于分析细节。
- 雪花模型:雪花模型是对星型模型的扩展,它将一些维度表进一步分解为更小的维度表,形成一个类似雪花的结构。雪花模型的优点是数据冗余度低,数据一致性和质量高,维度表的层次结构清晰,有利于分析复杂的业务逻辑。雪花模型的缺点是设计和实现较复杂,查询性能低,需要多次连接操作,不利于快速响应和变更。
维度建模中表的类型
- 维度表:一张维度表就表示对一个对象的一些描述信息。每个维度表都包含单一的主键列,和一些对该主键的描述信息,通常维度表会很宽。比如 乘客信息表,司机信息表,城市首都表
- 事实表:一张事实表就表示对业务过程的描述,比如播单,下单,支付。每个事实表都包含若干维度外键,若干退化维度(维度属性存储到事实表中,减少关联),和数值型的度量值,通常事实表会比较大。
事实表有哪几种类型
a)事务事实表:每一行数据表示一个事务,数据一旦插入就不会修改播单
b)周期快照事实表:不会保存所有时间的数据,只会保留固定时间间隔的数据,比如购物车,每时每刻都会增加或者减少,但是我们更加关心的是一天结束的时候购物车中有几件商品,就会采用周期性快照事实表(汇总事实表) 历史至今快照事实表
c)累积快照事实表:用于追踪事实的变化过程,比如从买家下单到支付的时长,买家支付到卖家发货的时长等(数据会变更)
事实表的设计过程
a)一共有五步,分别是选择业务过程,声明粒度,确定维度,确定事实,冗余维度
a)选择业务过程 就是对业务的整个生命周期进行分析,然后选择与需求有关的业务过程,比如打车呼单的整个过程,乘客呼单,平台播单,司机抢单,司机接驾,完成订单,(买家下单,买家付款,卖家发货,买家确认收货)然后就是根据我们的需求去选择对应的过程
b)声明粒度 ,粒度就是用于确定事实表中一行所表示的业务的细节层次,通常在设计事实表的时候,粒度定义的越细越好,比如订单明细表的粒度就是 订单级别
c)确定维度,选择描述清楚业务过程所处环境的维度信息中,比如订单明细表中 出发城市,到达城市,产品线,司机,订单状态等(支付事实表,买家,买家,商品,收货人信息,业务类型,订单时间)
d)确定事实,事实就是分析业务过程中的度量值,比如订单金额,订单次数等
e)冗余维度,在事实表中冗余一些下游用户需要使用的常用维度,减少多表之间的关联。
维度表的设计过程
a)第一步,选择维度,比如商品维度
b)第二步,确定主维表,一般就是业务系统中商品表同步到ods层的表,就是主维表
c)第三步,确定相关维表,因为不同业务系统或者同一业务系统中的不同表之间都会存在关联性,根据对业务的梳理,确定哪些表和主维表存在关联关系,比如商品会与 类目,spu,卖家,店铺等维度存在关联。
d)第四步,确定维度属性,分为两步,就是从主维表中选择维度属性或者生成新的维度属性,还有就是从相关维表
数据仓库开发包含几步
a)第一步,进行数据调研;包括了业务调研和需求调研,业务调研就是要弄清楚公司有哪些业务,以及每个业务有包括哪些业务线,一般每个业务会独自建设数据仓库。
b)第二步,进行架构设计;包括了数据域划分和构建总线矩阵,数据域就是指 将业务过程或者维度进行抽象的集合,在划分数据域的时候,应该尽可能保证当前划分的能够覆盖所有的业务需求,又能在新业务进入时无影响的被包含到已有的数据域中或者扩展新的数据域,国际化数仓里面的数据域包括司机域,乘客域,交易域,客服域,安全域等等,阿里巴巴就会有 商品域 会员域 店铺域 交易域 日志域等等。构建总线矩阵,就需要明确每个数据域下有哪些业务过程,业务过程与哪些维度相关。
c)第三步,进行规范定义,主要包括定义维度属性和定义指标体系,包括原子指标和派生指标(原子指标+时间周期+修饰词)
d)第四步,进行模型设计,包括明细层DIM和DWD,和汇总层DWS和DM层,以及面向分析人员的app层。
e)第五步,进行代码开发和上线生成调度任务,进行周期运行。
相关文章:
数据仓库整理
数仓 olap vs oltp OLTP主要用于支持日常的业务操作,如银行交易、电子商务等,强调数据的准确性、实时性和并发性。OLAP主要用于支持复杂的数据分析,如数据仓库、决策支持等,强调数据的维度、聚合和可视化。 将OLTP数据库的数据…...
《C++API设计》读书笔记(3):模式
本章内容 本章涵盖了一些与CAPI设计相关的设计模式和惯用法。 “设计模式(Design Pattern)”表示软件设计问题的一些通用解决方案。该术语来源于《设计模式:可复用面向对象软件的基础》(Design Patterns: Elements of Reusable Object-Oriented Softwar…...

小程序搜索词优化:小陈运营的秘密武器
大家好,我是小陈,今天要和大家分享一下小程序搜索词优化的经验和技巧。在数字化时代,小程序已经成为许多企业的重要工具,但要让小程序在竞争激烈的市场中脱颖而出,搜索词优化是不可或缺的一环。在本文中,我…...

SpringSecurity 入门
文章目录 Spring Security概念快速入门案例环境准备Spring配置文件SpringMVC配置文件log4j配置文件web.xmlTomcat插件 整合SpringSecurity 认证操作自定义登录页面关闭CSRF拦截数据库认证加密认证状态记住我授权注解使用标签使用 Spring Security概念 Spring Security是Spring…...

【每日一题Day335】LC1993树上的操作 | dfs
树上的操作【LC1993】 给你一棵 n 个节点的树,编号从 0 到 n - 1 ,以父节点数组 parent 的形式给出,其中 parent[i] 是第 i 个节点的父节点。树的根节点为 0 号节点,所以 parent[0] -1 ,因为它没有父节点。你想要设计…...

FPGA:卷积编码及维特比译码仿真
FPGA:卷积编码及维特比译码仿真 本篇记录一下在FPGA中完成卷积编码和维特比译码的过程,通过代码解释编码的过程和译码的过程,便于理解,同时也方便移植到其他工程中。 1. 准备工作 卷积编译码IP核—convolutionIP核和viterbiIP核…...
MySQL学习笔记4
客户端工具的使用: MySQL: mysql命令行工具,一般用来连接访问mysql的数据。 案例:使用mysql客户端工具连接服务器端(用户名:root;密码:123456). [rootmysql-server ~]#…...

JavaFX:窗体显示状态,模态非模态
程序窗体显示一般有3中模式。非模态和模态,其中模态又分为程序模态和窗体模态。 非模态可以理解为窗体之间没有任何限制,可以用鼠标、键盘等工具在窗体间切换。 程序模态是窗体打开后,该程序的所有窗体都被冻结,无法切换&#x…...
C++17中std::filesystem::path的使用
C17引入了std::filesystem库(文件系统库, filesystem library)。这里整理下std::filesystem::path的使用。 std::filesystem::path,文件系统路径,提供了对文件系统及其组件(例如路径、常规文件和目录)执行操作的工具。此path类主要用法包括&#x…...

命令模式简介
概念: 命令模式是一种行为设计模式,它将请求封装成一个对象,从而允许您将不同的请求参数化、队列化,并且能够在不同的时间点执行。通过引入命令对象(Command)来解耦发送者(Invoker)…...

Boost序列化指针
Boost.Serialization 还能序列化指针和引用。 由于指针存储对象的地址,序列化对象的地址没有什么意义,而是在序列化指针和引用时,对象的引用被自动地序列化。 代码 #include <boost/archive/text_oarchive.hpp> #include <boost/…...
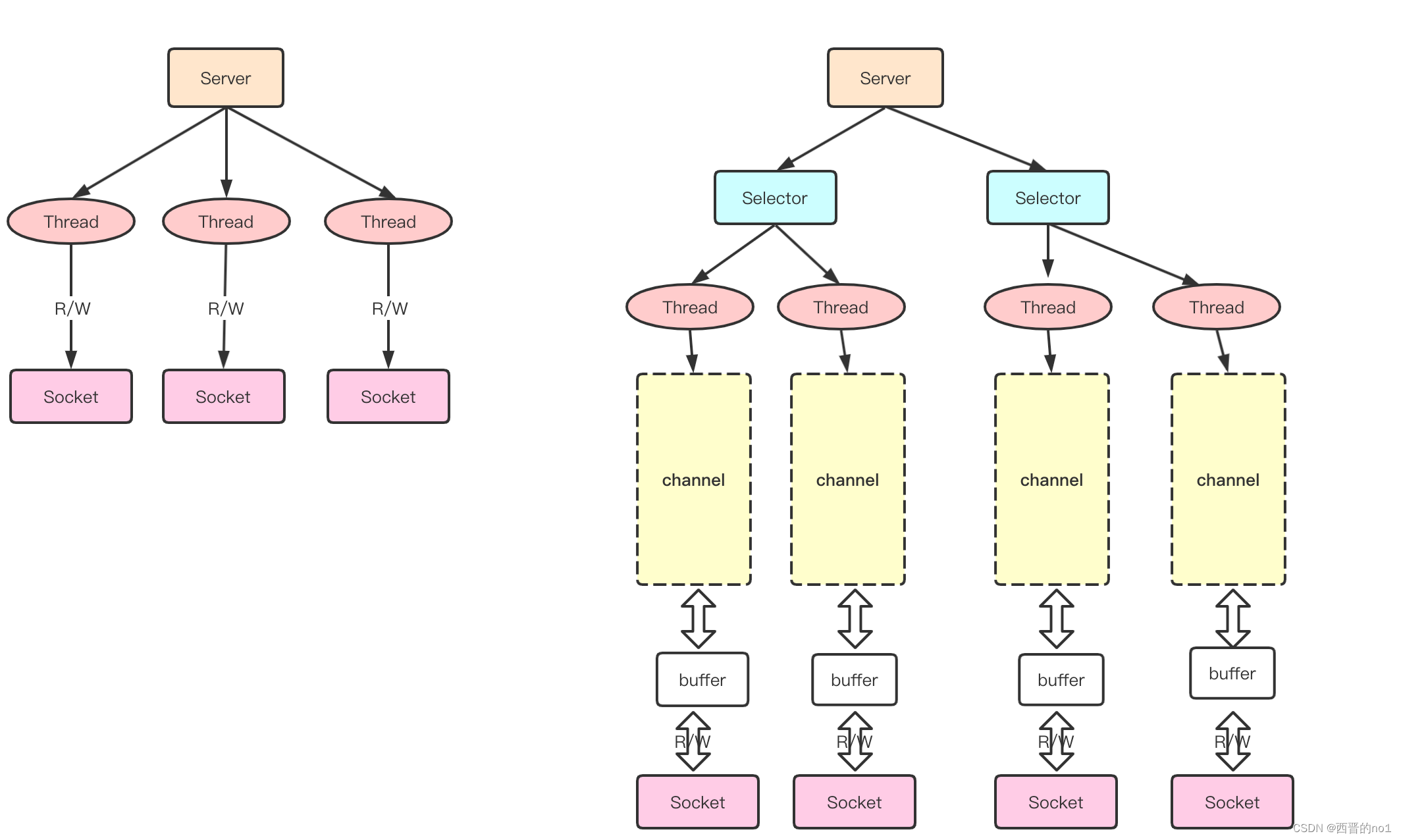
NIO简单介绍
一、什么是NIO 1、Java NIO全称java non-blocking IO, 是指JDK提供的新API。从JDK1.4开始,Java提供了一系列改进的输入/输出的新特性,被统称为NIO(即New IO),是同步非阻塞的 2、NIO有三大核心部分: Channel(通道), Buf…...
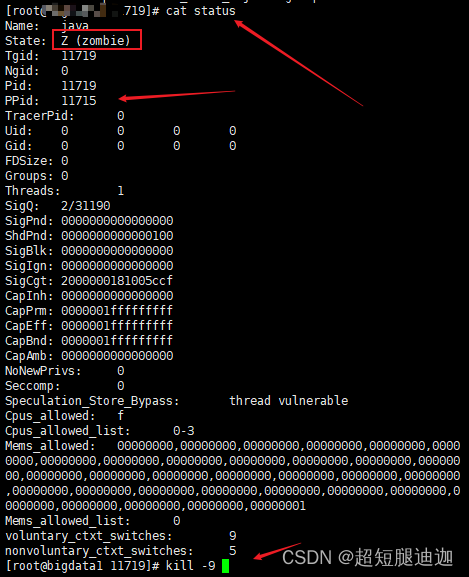
linux进程杀不死
项目场景: 虚拟机 问题描述 linux进程杀不死 无反应 原因分析: 进程僵死zombie 解决方案: 进proc或者find命令找到进程所在地址 cat status查看进程杀死子进程...

5分钟带你搞懂RPA到底是什么?RPA能做什么?
一、RPA的定义 RPA,全称Robotic Process Automation,即机器人流程自动化,是一种软件解决方案,能够模拟人类在计算机上执行的操作,以实现重复性、繁琐任务的自动化。它与传统的计算机自动化有所不同,因为它…...
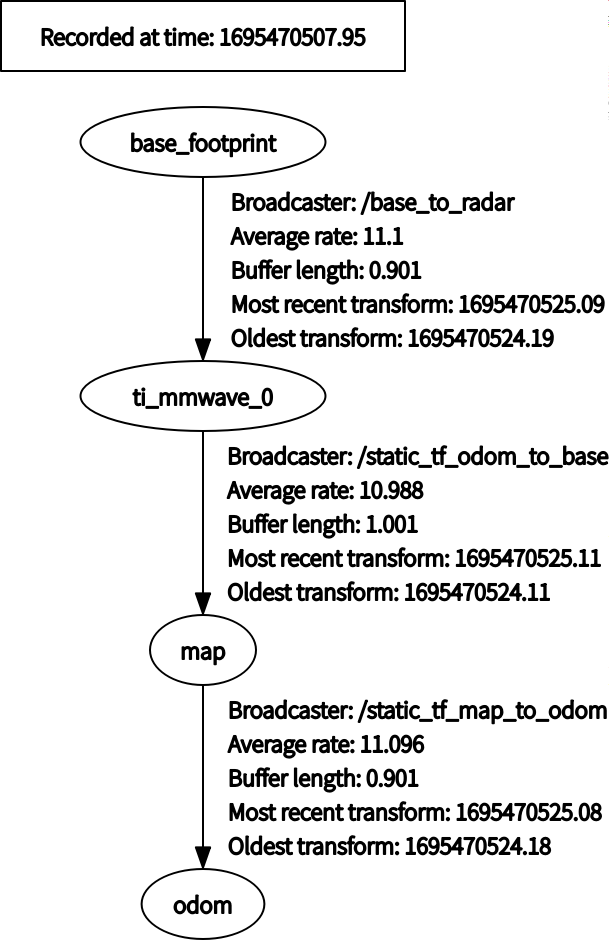
毫米波雷达 TI IWR1443 在 ROS 中进行 octomap 建图
个人实验记录 /mmwave_ti_ros/ros_driver/src/ti_mmwave_rospkg/launch/1443_multi_3d_0.launch <launch><!-- Input arguments --><arg name"device" value"1443" doc"TI mmWave sensor device type [1443, 1642]"/><arg…...

113双周赛
题目列表 2855. 使数组成为递增数组的最少右移次数 2856. 删除数对后的最小数组长度 2857. 统计距离为 k 的点对 2858. 可以到达每一个节点的最少边反转次数 一、使数组成为递增数组的最少右移次数 这题可以直接暴力求解,枚举出每种右移后的数组,将…...
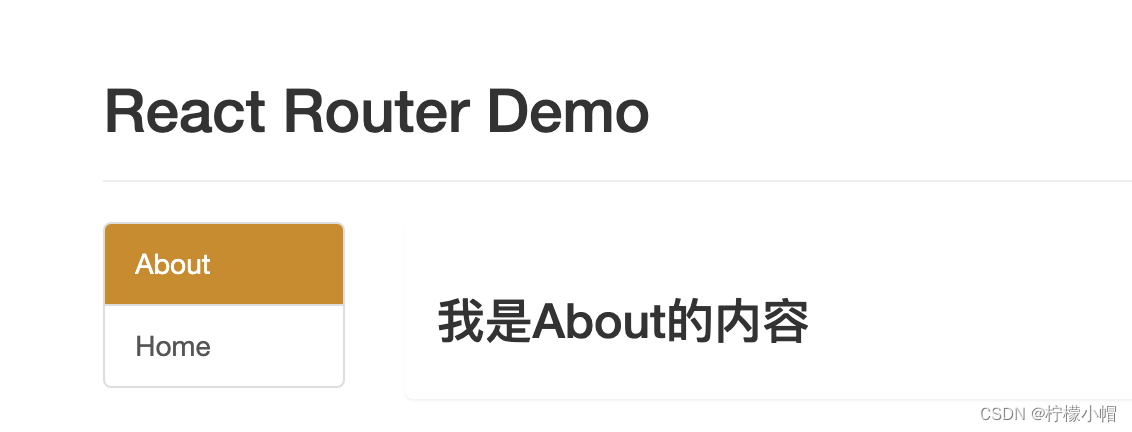
React 全栈体系(九)
第五章 React 路由 一、相关理解 1. SPA 的理解 单页 Web 应用(single page web application,SPA)。整个应用只有一个完整的页面。点击页面中的链接不会刷新页面,只会做页面的局部更新。数据都需要通过 ajax 请求获取, 并在前端…...

阈值化分割,对灰度级图像进行二值化处理(数字图像处理大题复习 P8)
文章目录 画出表格求出灰度直方图 & 山谷画出结果图 画出表格 有几个0就写几,有几个1就写几,如图 求出灰度直方图 & 山谷 跟前面求灰度直方图的方法一样,找出谷底,发现结果为 4 画出结果图 最终的结果就是…...

vue3中withDefaults是什么
问: const props withDefaults(defineProps<{// 数据列表lotteryList: { pic: string; name?: string }[];// 中奖idwinId: number;// 抽奖初始转动速度initSpeed: number;// 抽奖最快转动速度fastSpeed: number;// 抽奖最慢转动速度slowSpeed: number;// 基本圈数baseCi…...
Android进阶之路 - 盈利、亏损金额格式化
在金融类型的app中,关于金额、数字都相对敏感和常见一些,在此仅记录我在金融行业期间学到的皮毛,如后续遇到新的场景也会加入该篇 该篇大多采用 Kotlin 扩展函数的方式进行记录,尽可能熟悉 Kotlin 基础知识 兄弟 Blog StringUti…...

抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播
抖音批量下载神器:5分钟学会免费高效下载视频、音乐和直播 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback s…...

英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化
英雄联盟智能助手Seraphine:告别手动查询,实现高效游戏决策自动化 【免费下载链接】Seraphine 英雄联盟战绩查询工具 项目地址: https://gitcode.com/gh_mirrors/se/Seraphine 在英雄联盟排位赛中,你是否曾因错过接受对局而懊恼不已&a…...

Cursor IDE事件日志分析工具:Python实现开发者行为可视化与效率洞察
1. 项目概述:一个为开发者“把脉”的智能分析工具如果你是一名开发者,尤其是深度使用Cursor这类AI编程助手的开发者,你肯定有过这样的体验:面对一个复杂的项目,你向AI助手提了无数个问题,生成了大量代码片段…...

初创团队如何通过Taotoken的Token Plan实现成本可控的AI应用开发
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何通过Taotoken的Token Plan实现成本可控的AI应用开发 对于预算敏感的初创团队和独立开发者而言,在开发AI应…...

U-Boot实战:FAT文件系统五大核心命令详解与应用
1. U-Boot与FAT文件系统基础认知 刚接触嵌入式开发时,我第一次在U-Boot环境下操作FAT文件系统就踩了个大坑——试图用ext4write命令操作FAT32格式的SD卡,结果系统直接报错"Unknown command"。这个经历让我深刻认识到:U-Boot对文件系…...

嵌入式事件驱动框架Curtroller:模块化设计提升开发效率
1. 项目概述与核心价值最近在嵌入式开发社区里,一个名为“Curtroller”的项目引起了我的注意。这个项目由开发者KenWuqianghao在GitHub上开源,名字本身就是一个巧妙的组合——“Curt”(可能是“Current”电流的缩写或“Control”控制的变体&a…...

Cursor编辑器状态快照插件开发:一键保存与恢复工作区
1. 项目概述:一个专为开发者设计的“后悔药”如果你是一名重度使用 Cursor 编辑器的开发者,那么你一定经历过这样的场景:在沉浸式编码时,为了快速定位或修改,你可能会频繁地使用CtrlClick跳转到函数定义,或…...

5分钟学会创建专业交通网络可视化地图
5分钟学会创建专业交通网络可视化地图 【免费下载链接】transit-map The server and client used in transit map simulations like swisstrains.ch 项目地址: https://gitcode.com/gh_mirrors/tr/transit-map 你想在网页上展示动态的公共交通网络吗?Transit…...

深度解析VS Code Live Server:高效前端开发实时预览配置秘籍
深度解析VS Code Live Server:高效前端开发实时预览配置秘籍 【免费下载链接】vscode-live-server Launch a development local Server with live reload feature for static & dynamic pages. 项目地址: https://gitcode.com/gh_mirrors/vs/vscode-live-serv…...

Agent Framework 中的 Workflow Composition
在前面的文章中,我们已经介绍了 Agent Framework 中如何定义流程节点,以及 Workflow 的流式执行事件。 如果你对这些概念还不太熟悉,可以先回顾上一篇文章: Agent Framework 定义流程节点以及节点的流式输出 这一节我们来介绍 Wor…...