软件测试之Python基础学习
目录
一、Python基础
Python简介、环境搭建及包管理
Python简介
环境搭建
包管理
Python基本语法
缩进(Python有非常严格的要求)
一行多条语句
断行
注释
变量
基本数据类型(6种)
1. 数字Number
2. 字符串String
3. 列表List
4. 元组Tuple
序列相关操作方法
5. 集合Set
6. 字典Dict
条件/循环
条件判断
循环
文件读写(文本文件)
文件操作方法
文件打开模式
函数/类
函数定义和调用
参数和返回值
函数作为参数(如: 装饰器)
函数嵌套(支持闭包)
函数递归(自己调用自己,直到满足需求)
模块/包
模块
包
常用系统模块
常见算法
冒泡排序
快速排序
二分查找
结语:
视图网站推荐
1、Data Structure Visualizations
2、visualgo
3、BinaryTreeVisualiser
4、btree-js
5、Algorithm Visualizer
6、bigocheatsheet
7、Algorithms-DataStructures-BigONotation
8、Vamonos
一、Python基础
大致路线:

Python简介、环境搭建及包管理
Python简介
- 特点:Python是一门动态、解释型、强类型语言
- 动态:在运行期间才做数据检查(不用提前声明变量)- 静态语音(C/Java):编译时检查数据类型(编码时需要声明变量类型)
- 解释型:在执行程序时,才一条条解释成机器语言给计算机执行(无需编译,速度较慢)- 编译型语言(C/Java):先要将代码编译成二进制可执行文件,再执行
- 强类型:类型安全,变量一旦被指定了数据类型,如果不强制转换,那么永远是这种类型(严谨,避免类型错误,速度较慢)- 弱类型(VBScript/JavaScript): 类型在运行期间会转化,如 js中的 1+"2"="12", 1会由数字转化为string
- 编码原则:优雅、明确、简单
- 优点
- 简单易学
- 开发效率高
- 高级语言
- 可移植、可扩展、可嵌入
- 庞大的三方库
- 缺点
- 速度慢
- 代码不能加密
- 多线程不能充分利用多核cpu(GIL全局解释性锁,同一时刻只能运行一个线程)
- 应用领域
- 自动化测试(UI/接口)
- 自动化运维
- 爬虫
- Web开发(Django/Flask/..)
- 图形GUI开发
- 游戏脚本
- 金融、量化交易
- 数据分析,大数据
- 人工智能、机器学习、NLP、计算机视觉
- 云计算
环境搭建
Windows Python3环境搭建
- 下载Python3.*.exe安装包
- 双击安装,第一个节目选中Add Python3.*.* to PATH,点击Install Now(默认安装pip),一路下一步
- 验证:打开cmd命令行,输入python,应能进入python shell 并显示为Python 3.*.*版本

包管理
- pip安装
- pip install 包名 - 卸载: pip uninstall 包名
- pip install 下载的whl包.whl
- pip install -r requiements.txt(安装requirements.txt中的所有依赖包)
- 查看已安装的三方包,pip freeze 已文件格式显示已安装的三方包(用于导出requiremnts.txt文件)

- 源码安装
- 下载源码包,解压,进入解压目录
- 打开命令行,执行
python setup.py install - 验证:进入python shell,输入import 包名,不报错表示安装成功
- 三方包默认安装路径:Python3.*.*/Lib/site-packages/ 下
说明:网上有非常多的安装教程大家自由选择,这个不像FPGA和Qt那样难安装(个人觉得)
Python基本语法
-
缩进(Python有非常严格的要求)
x=int(input("请输入一个数\n"))
y=int(input("请输入一个数\n"))
if x > 0:print("正数")
elif x == 0:print("0")
else:print("负数")def add(x,y):return x+y-
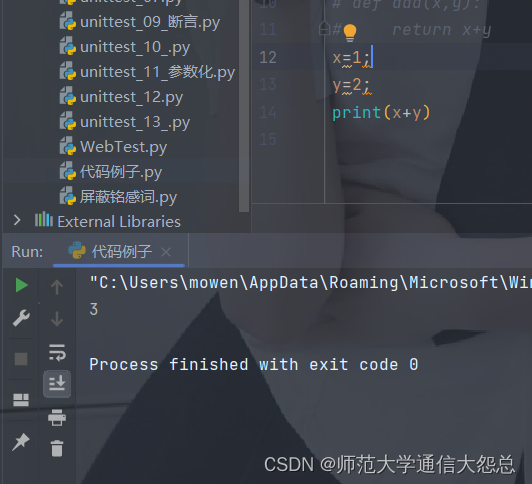
一行多条语句
x=1; y=2; print(x+y)
-
断行
print("this line is too long, \
so I break it to two lines")
-
注释
# 单行注释
a = 1'''这是一段
多行注释'''def add(x, y):"""加法函数:这是docstring(函数说明)"""pass
-
变量
- 变量类型(局部变量、全局变量、系统变量)
- 变量赋值
- 多重赋值
x=y=z=1 - 多元赋值
x,y = y,x
- 多重赋值
- 变量自增
x+=1x-=1(不支持x++,x--)
Python3中没有常量
基本数据类型(6种)
1. 数字Number
- 种类
- 整型int(Python3中没有长整型,int长度几乎没有限制)
- 浮点型float
- 布尔型bool
- False: 0,0.0,'',[],(),{}
- True: 除False以外,['']或[[],[]]不是False
- 复数型complex
- 操作符: +,-,*,/,//(地板除),**(乘方) - Python3中的/是真实除,1/2=0.5
- 类型转
- str(): 其他类型转为字符串, 如
str(12) - int(): 字符串数字转为整型(字符串不是纯整数会报错), 如
int("12") - float(): 字符串转换为浮点数,如
float("1.23")
- str(): 其他类型转为字符串, 如
2. 字符串String
- 字符串系统方法
- len(): 计算字符串长度,如
len("abcdefg") - find()/index(): 查找字符串中某个字符第一次出现的索引(index()方法查找不到会报错), 如
"abcdefg".find("b"); "abcedfgg".index("g") - lower()/upper(): 将字符串转换为全小写/大写,如
"AbcdeF".lower();"abcedF".upper() - isdigit()/isalpha()/isalnum(): 判断字符串是否纯数字/纯字母/纯数字字母组合, 如
isdigit("123"),结果为 True - count(): 查询字符串中某个元素的数量,如
"aabcabc".count("a") - join(): 将列表元素按字符串连接,如
"".join(["a","b","c"])会按空字符连接列表元素,得到"abc" - replace(): 替换字符串中的某已部分,如
"hello,java".replace("java", "python"),将java 替换为 python - split(): 和join相反,将字符串按分隔符分割成列表, 如
"a,b,c,d".split(",")得到["a", "b", "c", "d"] - strip()/lstrip()/rstrip(): 去掉字符串左右/左边/右边的无意字符(包括空格,换行等非显示字符),如
" this has blanks \n".strip()得到"this has balnks"
- len(): 计算字符串长度,如
- 字符串格式化
- %: 如
"Name: %s, Age: %d" % ("Lily", 12)或"Name: %(name)s, Age: %(age)d" % {"name": "Lily", "age": 12} - format: 如
"Name: {}, Age: {}".format("Lily", 12)或"Name: {name}, Age: {age}".format(name="Lily",age=12) - substitude(不完全替换会报错)/safe_substitude: 如
"Name: ${name}, Age: ${age}".safe_substitude(name="Lily",age=12)
- %: 如
- 案例: 利用format生成自定义html报告
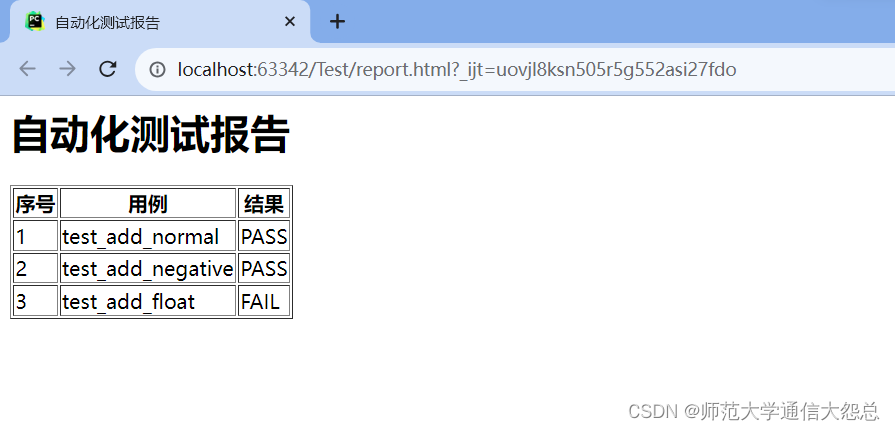
tpl='''<html><head><title>{title}</title></head><body><h1>{title}</h1><table border=1px><tr><th>序号</th><th>用例</th><th>结果</th></tr>{trs}</table></body></html>'''tr='''<tr><td>{sn}</td><td>{case_name}</td><td>{result}</td>'''title="自动化测试报告"case_results = [("1", "test_add_normal", "PASS"),("2", "test_add_negative", "PASS"), ("3", "test_add_float", "FAIL")]trs=''for case_result in case_results:tr_format = tr.format(sn=case_result[0], case_name=case_result[1], result=case_result[2])trs += tr_formathtml = tpl.format(title=title, trs=trs)f = open("report.html", "w")f.write(html)f.close()
运行这个*.html文件:

运行就可以在网页看到结果:
3. 列表List
列表元素支持各种对象的混合,支持嵌套各种对象,如
["a", 1, {"b": 3}, [1,2,3]]
- 列表操作
- 赋值:
l = [1, "hello", ("a", "b")] - 获取:
a = l[0] # 通过索引获取 - 增:
l.append("c");l.extend(["d","e"]);l+["f"] - 删:
l.pop() # 按索引删除,无参数默认删除最后一个;l.remove("c") # 按元素删除 - 改:
l[1]="HELLO" # 通过索引修改 - 查: 遍历
for i in l: print(i)
- 赋值:
- 列表系统方法
- append()/insert()/extend(): 添加/插入/扩展(连接)
- index(): 获取元素索引
- count(): 统计元素个数
- pop()/remove(): 按索引/元素删除
- sort()/reverse(): 排序/反转
- 案例: 字符串反转
s="abcdefg"; r=''.join(reversed(a))
4. 元组Tuple
- 不可改变,常用作函数参数(安全性好)
- 同样支持混合元素以及嵌套
- 只有一个元素时,必须加","号,如
a=("hello",)- 因为Python中()还有分组的含义,不加","会识别为字符串
字符串/列表/元组统称为序列, 有相似的结构和操作方法
序列相关操作方法
1. 索引 - 正反索引: ```l[3];l[-1]``` - 索引溢出(IndexError): 当索引大于序列的最大索引时会报错,如[1,2,3,4]最大索引是3,引用l[4]会报IndexError 2. 切片 - l[1:3] # 从列表索引1到索引3(不包含索引3)进行截取, 如 l = [1, 2, 3, 4, 5], l[1:3]为[2, 3] - l[:5:2] # 第一个表示开始索引(留空0), 第二个表示结束索引(留空为最后一个,即-1), 第三个是步长, 即从开头到第5个(不包含第5个),跳一个取一个 - *案例*: 字符串反转 ```s="abcdefg";r=s[::-1]``` 3. 遍历 - 按元素遍历: ```for item in l: print(item)``` - 按索引遍历: ```for index in range(len(l)): print(l[index])``` - 按枚举遍历: ```for i,v in enumerate(l): print((i,v))``` 4. 扩展/连接(添加多个元素): extend()/+ ```"abc"+"123";[1,2,3]+[4,5];[1,2,3].extend([4,5,6,7])``` 5. 类型互转: str()/list()/tuple() >list转str一般用join(), str转list一般用split()
- 系统函数
- len(): 计算长度
- max()/min(): 求最大/最小元素
- sorted()/reversed(): 排序/反转并生成新序列(sort()/reverse()直接操作原序列)
l_new=sorted(l);l_new2=reversed(l)
5. 集合Set
- 集合可以通过序列生成
a = set([1,2,3]) - 集合无序,元素不重复(所有元素为可哈希元素)
- 集合分为可变集合set和不可变集合frozenset
- 操作方法: 联合|,交集&,差集-,对称差分^
- 系统函数: add()/update()/remove()/discard()/pop()/clear()
- 案例1: 列表去重:
l=[1,2,3,1,4,3,2,5,6,2];l=list(set(l))(由于集合无序,无法保持原有顺序) - 案例2: 100w条数据,用列表和集合哪个性能更好? - 集合性能要远远优于列表, 集合是基于哈希的, 无论有多少元素,查找元素永远只需要一步操作, 而列表长度多次就可能需要操作多少次(比如元素在列表最后一个位置)
6. 字典Dict
- 字典是由若干key-value对组成, 字典是无序的, 字典的key不能重复,而且必须是可哈希的,通常是字符串
- 字典操作
- 赋值:
d = {"a":1, "b":2} - 获取:
a = d['a']或a = d.get("a") # d中不存在"a"元素时不会报错 - 增:
d["c"] = 3; d.update({"d":5, "e": 6} - 删:
d.pop("d");d.clear() # 清空 - 查:
d.has_key("c") - 遍历:
- 遍历key:
for key in d:或for key in d.keys(): - 遍历value:
for value in d.values(): - 遍历key-value对:
for item in d.items():
- 遍历key:
- 赋值:
- 案例: 更新接口参数 api = {"url": "/api/user/login": data: {"username": "张三", "password": "123456"}},将username修改为"李四"
api['data']['username'] = "李四"或api['data'].update({"username": "李四"})
哈希与可哈希元素(一般来说可哈希就是不可变)
- 哈希是通过计算得到元素的存储地址(映射), 这就要求不同长度的元素都能计算出地址,相同元素每次计算出的地址都一样, 不同元素计算的地址必须唯一, 基于哈希的查找永远只需要一步操作, 计算一下得到元素相应的地址, 不需要向序列那样遍历, 所以性能较好
- 可哈希元素: 为了保证每次计算出的地址相同, 要求元素长度是固定的, 如数字/字符串/只包含数字,字符串的元组, 这些都是可哈希元素
6种类型简单的特点总结
- 数字/字符串/元祖: 长度固定
- 序列(字符串/列表/元祖): 有序
- 集合/字典: 无序, 不重复/键值不重复
条件/循环
条件判断
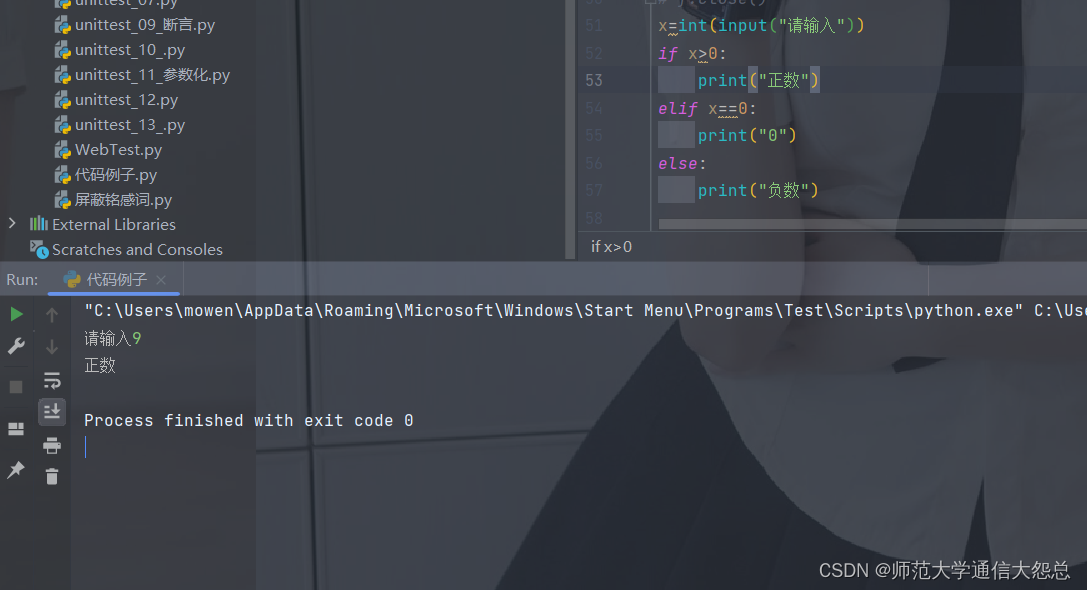
- 示例:
x=int(input("请输入"))
if x>0:print("正数")
elif x==0:print("0")
else:print("负数")
-
三元表达式:
max = a if a > b else b
-
案例: 判断一个字符串是不ip地址
ip_str = '192.168.100.3'
ip_list = ip_str.split(".") # 将字符串按点分割成列表
is_ip = True # 先假设ip合法
if len(ip_list) != 4:
is_ip= False
else:
for num in ip_list:
if not isdigit(num) or not 0 <= int(num) <= 255:
is_ip = False
if is_ip:
print("是ip")
else:
print("不是ip")
使用map函数的实现方法(参考):

循环
- for in 循环
- while 循环
文件读写(文本文件)
html/xml/config/csv也可以按文本文件处理
文件操作方法
- open(): 打开
f =open("test.txt")或f =open("test.txt","r", encoding="utf-8")或with open("test.txt) as f: # 上下文模式,出结构体自动关闭文件 - read()/readline()/readlines(): 读取所有内容/读取一行/读取所有行(返回列表) - 注意: 内容中包含\n换行符,可以通过strip()去掉
- f.write()/f.save(): 写文件/保存文件
- f.seek(): 移动文件指针,如f.seek(0), 移动到文件开头
- f.close(): 关闭文件(打开文件要记得关闭)
文件打开模式
- r/w/a: 只读/只写/追加模式
- rb/wb/ab: 二进制只读/只写/追加模式(支持图片等二进制文件)
- r+/rb+, w+/wb+, a+/ab+: 读写,区别在于, r+/w+会清空文件再写内容, r+文件不存在会报错, a+不清空原文件,进行追加, w+/a+文件不存在时会新建文件
文件是可迭代的,可以直接用 for line in f: 遍历
函数/类
函数定义和调用
def add(x, y): # 定义函数return x+yprint(add(1,3)) # 调用函数

举例: 用户注册/登录函数
users = {"张三": "123456"}def reg(username, password):if users.get(username): # 如果用户中存在username这个keyprint("用户已存在")else:users[username] = password # 向users字典中添加元素print("添加成功")def login(username, password)if not users.get(username):print("用户不存在")elif users['username'] == password:print("登录成功")else:print("密码错误")
参数和返回值
- 函数没有return默认返回None
- 参数支持各种对象,包含数字,支付串,列表,元组,也可以是函数和类
- 参数默认值: 有默认值的参数必须放在最后面, 如```def add(x, y=1, z=2):
- 不定参数: *args和**kwargs, 如
def func(*args, **kwargs):可以接受任意长度和格式的参数 - 参数及返回值类型注释(Python3)
def add(x:int, y:int) -> int: # x,y为int型,函数返回为int型,只是注释,参数格式非法不会报错return x+y函数作为参数(如: 装饰器)
def a():print("I'm a")
def deco(func):print("call from deco")func()deco(a) # 输出"call from deco"并调用a(),输出"I'm a"

函数嵌套(支持闭包)
def a():a_var = 1def b():nonlocal a_vara_var += 1b() # 调用函数 bprint(a_var) # 输出结果为 2函数递归(自己调用自己,直到满足需求)
案例: 求N!
def factorial(n):return 1 if n == 0 or n == 1 else n * factorial(n-1)print(factorial(39))
输入测试

蓝桥杯的填空题我就遇到过,遇到这种直接用Py比较好,因为py没有大数限制
模块/包
模块
- 一个py文件为一个模块
- 模块导入
- import os # 需要通过os调用相关方法, 如os.mkdir(),
- form configparser import ConfigParser: 可以直接使用CinfigParser()
- 支持一次导入多个
包
- 一个文件夹为一个包(Python3,文件夹中不需要建立__init__.py文件)
常用系统模块
- os: 与操作系统交互
- os.name/os.sep/os.linesep: 系统名称/系统路径分隔符/系统换行符
- os.makedir()/os.makedirs(): 建立目录/建立多级目录
- os.getenv("PATH"): 获取系统PATH环境变量的设置
- os.curdir/os.prdir: 获取当前路径/上级路径
- os.walk(): 遍历文件夹及子文件
- os.path.basename()/os.path.abspath()/os.path.dirname(): 文件名/文件绝对路径/文件上级文件夹名
- os.path.join()/os.path.split(): 按当前系统分隔符(os.sep)组装路径/分割路径
- os.path.exists()/os.path.isfile()/os.path.isdir(): 判断文件(文件夹)是否存在/是否文件/是否文件夹
- 案例: 用例发现, 列出文件夹及子文件夹中所有test开头的.py文件,并输出文件路径2
for root,dirs,files in os.walk("./case/"):for file in files:if file.startswith("test") and file.endswith(".py"):print(os.path.join(root, file))
- sys: 与Python系统交互
- sys.path: 系统路径(搜索路径)
- sys.platform: 系统平台,可以用来判断是python2还是3
- sys.argv: py脚本接受的命令行参数
- sys.stdin/sys.stdout/sys.stderr: 标准输入/输出/错误
常见算法
冒泡排序
def buddle_sort(under_sort_list):l = under_sort_listfor j in range(len(l)):for i in range(len(l)-j-1):if l[i] > l[i+1]:l[i], l[i+1] = l[i+1], l[i]
快速排序
def quick_sort(l):if len(l) < 2:return l # 如果列表只有一个元素, 返回列表(用于结束迭代)else:pivot = l[0] # 取列表第一个元素为基准数low = [i for i in l[1:] if i < pivot] # 遍历l, 将小于基准数pivot的全放入low这个列表high = [i for i in l[1:] if i >= pivot ]return quick_sort(low) + [pivot] + quick_sort(high) # 对左右两部分分别进行迭代
二分查找
def bin_search(l, n): # l为有序列表low, high = 0, len(l) - 1 # low,high分别初始化为第一个/最后一个元素索引(最小/最大数索引)while low < high:mid = (high-low) // 2 # 地板除,保证索引为整数if l[mid] == n:return midelif l[mid] > n: # 中间数大于n则查找前半部分, 重置查找的最大数high = mid -1 else: # 查找后半部分, 重置查找的最小数low = mid + 1return None # 循环结束没有return mid 则说明没找到
结语:
目前本人也就预习到这里了,欢迎各位同学分享交流,同时也欢迎大佬给我这个小白推荐路线学习
视图网站推荐
下面推荐几个学习数据结构和算法的可视化工具。
1、Data Structure Visualizations
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html这是一个在线数据可视化工具,可以手动创建各种数据结构,包括队列、栈、堆、树等等,并且支持递归、排序、搜索等算法的动态演示。该工具由旧金山大学开发。
这个工具通过可视化的方式展现了数据结构和算法,方便我们理解其中的原理。网站容易操作、内容丰富且容易理解,非常nice~虽然网站是英文的,不过都是些容易理解的术语,英文不好的小伙伴也不会有很大的阅读障碍。
2、visualgo
https://visualgo.net/en
https://visualgo.net/zh该网站由 Steven Halim 博士开发,对于理解数据结构与算法非常有帮助。网站里面包含了排序、链表、哈希表、二叉搜索树、递归树、循环查找等常见算法动画。
在动画执行的过程中,还会在网站右下角高亮展示动画的代码逻辑。非常适合初学者学习巩固自己的算法知识。

3、BinaryTreeVisualiser
http://www.btv.melezinek.cz/home.html一款二叉树可视化的工具,可以用来学习二叉树,超级好用。

4、btree-js
https://yangez.github.io/btree-js/这是一个专门演示B树的工具,可以在上面插入节点模拟B树的构建过程,对于理解B树这种数据结构非常有帮助。
5、Algorithm Visualizer
https://algorithm-visualizer.org/Algorithm Visualizer 是一个可视化代码算法的交互式平台,内含多种算法(回溯、动态规划、贪心等)并进行了可视化动画呈现,让学习算法和数据结构更加直观。
目前支持的算法包括回溯法、动态规划、贪婪算法、排序算法、搜索算法等。

6、bigocheatsheet
https://www.bigocheatsheet.com/这个网站总结了常用算法的时空Big-O复杂性,常见数据结构操作的时间复杂度。

7、Algorithms-DataStructures-BigONotation
http://cooervo.github.io/Algorithms-DataStructures-BigONotation/index.html这也是一个可以查看算法分析的网站工具,功能相比bigocheatsheet,更丰富一些。

8、Vamonos
http://rosulek.github.io/vamonos/
http://rosulek.github.io/vamonos/demos/index.html有常用的数据结构与算法的演示:栈、队列、二叉树、红黑树、B树、拓扑排序、广度优先算法。
相关文章:
软件测试之Python基础学习
目录 一、Python基础 Python简介、环境搭建及包管理 Python简介 环境搭建 包管理 Python基本语法 缩进(Python有非常严格的要求) 一行多条语句 断行 注释 变量 基本数据类型(6种) 1. 数字Number 2. 字符串String 3. 列表List 4. 元组Tuple 序列相关操作方法 …...

模块化编程+LCD1602调试工具——“51单片机”
各位CSDN的uu们你们好呀,小雅兰又来啦,刚刚学完静态数码管显示和动态数码管显示,感觉真不错呢,下面,小雅兰就要开始学习模块化编程以及LCD1602调试工具的知识了,让我们进入51单片机的世界吧!&am…...

【Linux】UDP的服务端 + 客户端
文章目录 📖 前言1. TCP和UDP2. 网络字节序2.1 大小端字节序:2.2 转换接口: 3. socket接口3.1 sockaddr结构:3.2 配置sockaddr_in:3.3 inet_addr:3.4 inet_ntoa:3.5 bind绑定: 4. 服…...

德国自动驾驶卡车公司【Fernride】完成1900万美元A轮融资
来源:猛兽财经 作者:猛兽财经 猛兽财经获悉,总部位于德国沃尔夫斯堡的自动驾驶卡车公司【Fernride】今日宣布已完成1900万美元A轮融资,本轮融资完成后Fernride的融资金额已经达到了达到5000万美元。 本轮融资由Deep Tech and Cli…...

实现水平垂直居中的十种方式
本文节选自我的博客:实现水平垂直居中的十种方式 💖 作者简介:大家好,我是MilesChen,偏前端的全栈开发者。📝 CSDN主页:爱吃糖的猫🔥📣 我的博客:爱吃糖的猫&…...

头条号热点采集工具-头条号热文采集软件
有一种魔法,能让信息传遍大地,让新闻在互联网上迅速传播,引发关注和讨论,那就是头条热点。无论你是一名自媒体创作者,还是一个信息追踪者,头条热点都是你不能忽视的宝贵资源。然而,如何获取这些…...

了解”变分下界“
“变分下界”:在变分推断中,我们试图找到一个近似概率分布q(x)来逼近真实的概率分布p(x)。变分下界是一种用于评估近似概率分布质量的指标,通常用来求解最优的近似分布。它的计算涉及到对概率分布的积分或期望的估计...

Andriod 简单控件
目录 一、文本显示1.1 设置文本内容1.2 设置文本大小1.3 设置文本颜色 二、视图基础2.1 设置视图宽高2.2 设置视图间距2.3 设置视图对齐方式 三、常用布局3.1 线性布局LinearLayout3.2 相对布局RelativeLayout3.3 网格布局GridLayout3.4 滚动视图ScrollView 四、按钮触控4.1 按…...

Substructure‑aware subgraph reasoning for inductive relation prediction
摘要 关系预测的目的是推断知识图中实体之间缺失的关系,其中归纳关系预测因其适用于新兴实体的有效性而广受欢迎。大多数现有方法学习逻辑组合规则或利用子图来预测缺失关系。尽管在性能方面已经取得了很大的进展,但目前的模型仍然不是最优的,因为它们捕获拓扑信息的能力有…...

古诗词学习鉴赏APP设计与实现(源码+lw+部署文档+讲解等)
文章目录 前言具体实现截图论文参考详细视频演示为什么选择我自己的网站自己的小程序(小蔡coding)有保障的售后福利 代码参考源码获取 前言 💗博主介绍:✌全网粉丝10W,CSDN特邀作者、博客专家、CSDN新星计划导师、全栈领域优质创作…...

深度学习与python theano
文章目录 前言1.人工神经网络2.计算机神经网络3.反向传播4.梯度下降-cost 函数1.一维2.二维3.局部最优4.迁移学习 5. theano-GPU-CPU theano介绍1.安装2.基本用法1.回归2.分类 3.function用法4.shared 变量5.activation function6.Layer层7.regression 回归例子8.classificatio…...
【算法优选】双指针专题——贰
文章目录 😎前言🌲[快乐数](https://leetcode.cn/problems/happy-number/)🚩题目描述🚩题⽬分析:🚩算法思路:🚩代码实现: 🎋[盛水最多的容器](https://leetco…...

AI智能电话机器人实用吗
近几年,人工智能得到很大的发展,同时语音识别技术的不断完善,很多以语音识别为基础的应用涌现出来,尤其是最近3年,出现了很多智能电话机器人。百度开发者大会上展示了百度智能客服也吸引了很多人对智能电话机器人的兴趣…...
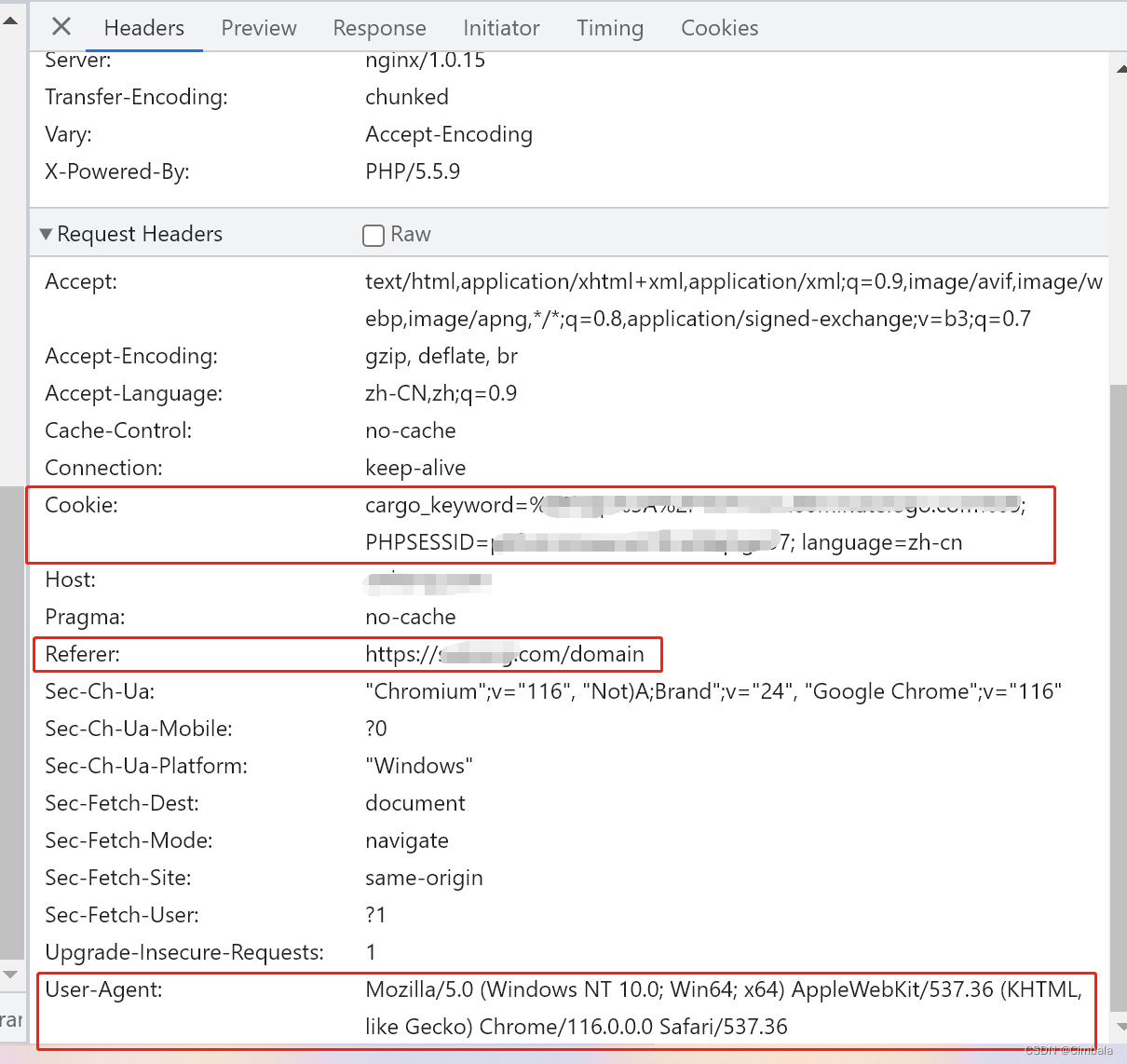
网络爬虫--伪装浏览器
从用户请求的Headers反反爬 在访问某些网站的时候,网站通常会用判断访问是否带有头文件来鉴别该访问是否为爬虫,用来作为反爬取的一种策略。很多网站都会对Headers的User-Agent进行检测,还有一部分网站会对Referer进行检测(一些资…...
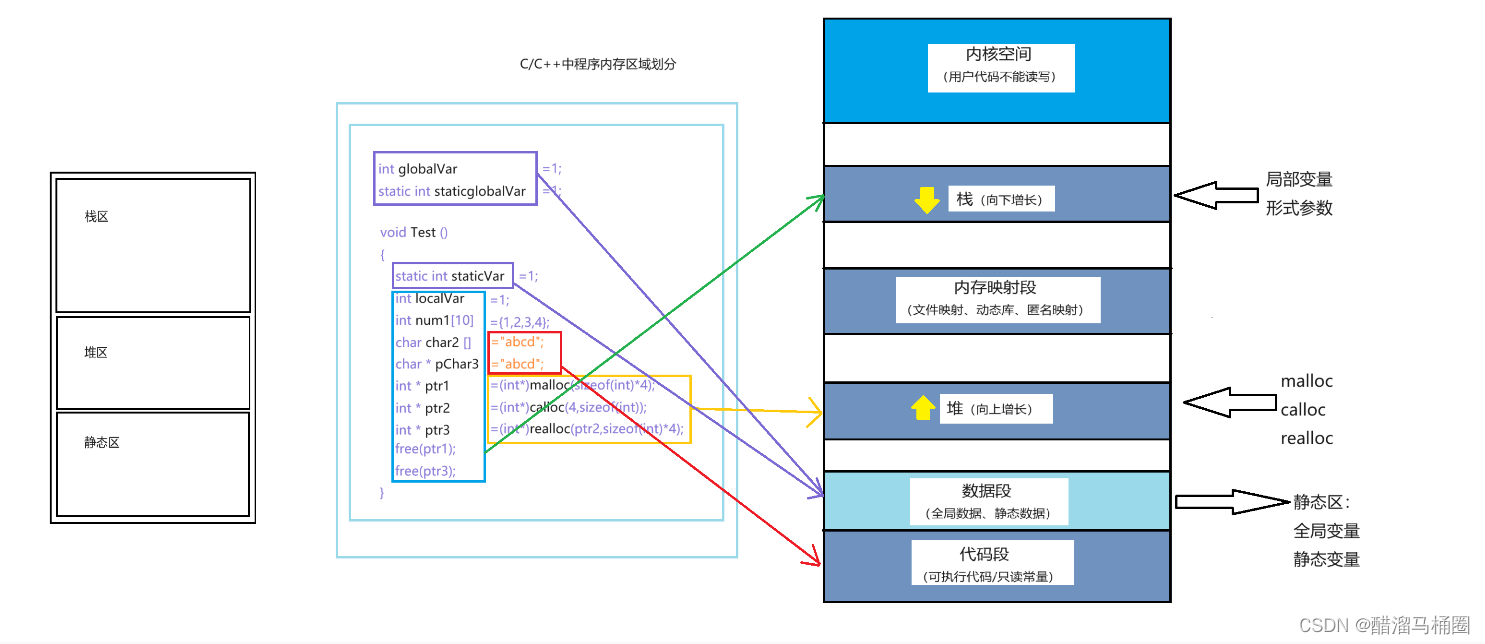
C/C++程序的内存开辟
前面我们说过,计算机中内存分为三个区域:栈区,堆区,静态区 但是这只是个简化的版本,接下来我们仔细看看内存区域的划分 C/C程序内存分配的几个区域: 栈区(stack):在执行…...

【Java 进阶篇】JDBC DriverManager 详解
JDBC(Java Database Connectivity)是 Java 标准库中用于与数据库进行交互的 API。它允许 Java 应用程序连接到各种不同的数据库管理系统(DBMS),执行 SQL 查询和更新操作,以及处理数据库事务。在 JDBC 中&am…...

2023年Linux总结常用命令
1.常用命令 1.1创建文件夹 mkdir -p forever/my 1.2当前目录 pwd 1.3创建文件 touch 1.txt 1.4查看文件 cat 1.txt 1.5复制文件 说明:-r是复制文件夹 cp -r my myCopy 1.6删除文件 说明:-r带包删除文件夹,-f表示强制删除(保存问题) rm -r…...
Mybatis3详解 之 全局配置文件详解
1、全局配置文件 前面我们看到的Mybatis全局文件并没有全部列举出来,所以这一章我们来详细的介绍一遍,Mybatis的全局配置文件并不是很复杂,它的所有元素和代码如下所示: <?xml version"1.0" encoding"UTF-8&…...

力扣-345.反转字符串中的元音字母
Idea 将s中的元音字母存在字符串sv中,并且使用一个数组依次存储元音字母的下标。 然后将字符串sv进行反转,并遍历元音下标数组,将反转后的字符串sv依次插入到源字符串s中 AC Code class Solution { public:string reverseVowels(string s) {…...

643. 子数组最大平均数I(滑动窗口)
目录 一、题目 二、代码 一、题目 643. 子数组最大平均数 I - 力扣(LeetCode) 二、代码 class Solution { public:double findMaxAverage(vector<int>& nums, int k) {double Average INT_MIN;double sum nums[0];int left 0, right 0…...

MSP 盈利、留客、提口碑,核心就盯这12个 KPI
很多 MSP(托管服务提供商)都会陷入一个误区,手里握着一堆散落在各个看板的运营数据,却始终搞不清哪些指标能真正帮自己提升服务质量、拉高利润、留住客户。忙忙碌碌做了一堆报表,最终还是凭感觉做决策,业务…...

Rails控制台集成AI助手:ask_chatgpt Gem的实践指南
1. 项目概述:在Rails控制台里装一个AI助手 如果你是一个Ruby on Rails开发者,并且每天都在跟Rails控制台( rails console )打交道,那你肯定有过这样的时刻:盯着一段复杂的ActiveRecord查询,或…...

Sora 2正式版突然开放API灰度权限?我们逆向解析了127行响应头与rate limit策略,发现3个隐藏调用阈值
更多请点击: https://intelliparadigm.com 第一章:Sora 2正式版核心能力与架构演进 Sora 2正式版标志着视频生成大模型从研究原型迈向工业级部署的关键跃迁。其底层架构采用分层时空联合建模(Hierarchical Spatio-Temporal Transformer&…...

阿里云效前端流水线自动化部署
一、权限准备 如果你想实现这个功能,那么你的云效必须要有权限!!这非常重要!!如何确定自己是否有相关权限呢? 流水线权限 制品仓库权限 就是云服务器的权限,这个权限是要你可以读写文件的…...

对比自行维护与使用Taotoken在模型接入效率上的差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比自行维护与使用Taotoken在模型接入效率上的差异 在开发需要集成大语言模型能力的应用时,团队通常面临一个核心选择…...

别再只点CubeMX的SDRAM选项了!STM32F429IGT6外扩W9825G6KH内存的完整驱动与读写测试指南
STM32F429IGT6外扩W9825G6KH内存实战:从CubeMX配置到完整驱动开发的深度解析 如果你正在使用STM32F429IGT6开发板,并且需要扩展大容量内存,W9825G6KH-6I这颗32MB的SDRAM芯片可能已经在你的硬件清单上。许多开发者习惯性地依赖STM32CubeMX生成…...
)
【2026社工】初级社会工作者历年真题及答案PDF电子版(2010-2025年)
2026年初级社会工作者职业水平考试安排 考试时间: 2026年5月23日 考试科目与形式 科目名称考试形式社会工作实务闭卷笔试社会工作综合能力闭卷笔试 备考资源说明 提供2010-2025年完整历年真题及解析,覆盖全部考试科目,具体功能如下&#…...

金融机器学习实战:MlFinLab工具包核心模块解析与应用指南
1. 从零到一:为什么我们需要一个金融机器学习的“瑞士军刀”?如果你和我一样,在量化金融和算法交易这条路上摸爬滚打了好几年,那你一定经历过这样的场景:为了复现一篇顶级期刊论文里的某个特征工程方法,你需…...

C++智能指针详解:原理、使用及避坑指南
文章目录 前言 一、智能指针核心原理:RAII机制 二、C常用智能指针详解(重点掌握后两种) 三、智能指针高频坑点(重中之重) 四、三大智能指针对比(选择指南) 五、实战案例:智能指…...

大模型风口已至:月薪30K+的AI Agent开发岗,你准备好了吗?
文章介绍了如何借助不同版本的Agents实现智能自动化,并详细描述了AI应用工程师和大模型算法工程师的岗位职责和任职要求。文章还强调了AI学习的重要性,指出最先掌握AI的人将具有竞争优势,并提供了大模型AI学习和面试资料,帮助读者…...