聊聊MySql索引的类型以及失效场景
文章目录
- 概念
- 常见的索引
- 1.B树索引
- 2.哈希索引
- 3.全文索引
- 4.空间索引
- 5.聚集索引
- 如何设计合理?
- 1.明确索引需求
- 2.选择索引列
- 3.选择索引类型
- 4.考虑索引维护开销
- 5.设计联合索引
- 6.删除不必要索引
- 7.关注索引统计信息
- 8.测试查询效果
- 常见不生效场景
- 1.全表扫描
- 2.索引列计算
- 3.模糊查询未用前置匹配
- 4.复合索引条件次序错误
- 5.or条件索引无效
- 6.子查询或关联查询inner side未用索引
- 7.数据分布严重不均匀
- 8.返回未命中索引覆盖字段
- 9.索引统计信息没有及时更新
- 总结
- 写在最后

概念
索引是数据库管理系统中一个重要的优化结构,目的是提高数据库查询和操作的速度。
索引的工作原理是对数据库表中的一列或多列的值进行预排序,然后存储该列值与数据行的地址映射,在查询时可以直接查找到数据,而无需全表扫描。
常见的索引
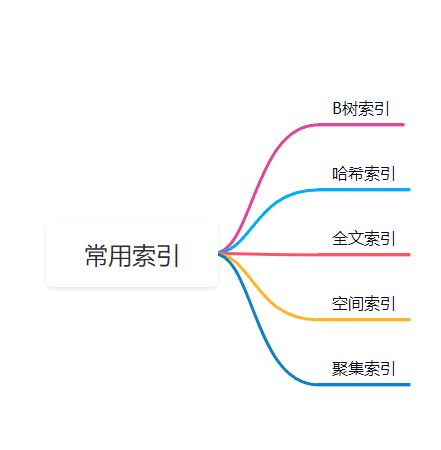
1.B树索引
最常见的索引类型,可以对一个或多个列创建索引。
2.哈希索引
通过哈希函数直接定位到数据行。查找速度极快,但只支持等值查询。
3.全文索引
可以对文本中的关键词创建索引,支持模糊查询。
4.空间索引
用于空间数据类型的索引,可以优化空间计算。
5.聚集索引
索引结构和数据结构相结合,只能有一个聚集索引。
如何设计合理?
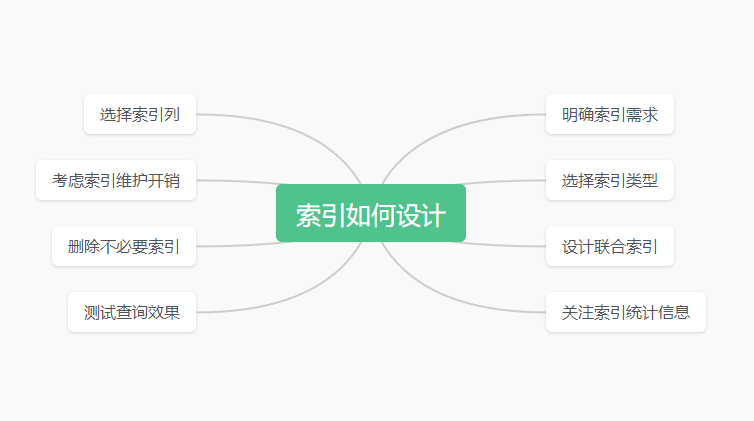
1.明确索引需求
分析查询语句和业务场景,确定需要创建索引的列,以优化查询性能。
2.选择索引列
选择区分度高、查询频繁的列作为索引列。避免冗余和相关列的索引。
3.选择索引类型
根据查询方式选择合适的索引类型,如B树索引、哈希索引、全文索引等。
4.考虑索引维护开销
写入操作会增加索引维护开销。权衡查询优化与维护成本。
5.设计联合索引
多个列的联合索引可以覆盖更多查询,但要注意索引列顺序。
6.删除不必要索引
清理冗余和未使用的索引,减少维护损耗。
7.关注索引统计信息
分析索引的使用情况,优化设计。
8.测试查询效果
不同场景测试索引设计的查询性能,验证索引有效性。
常见不生效场景
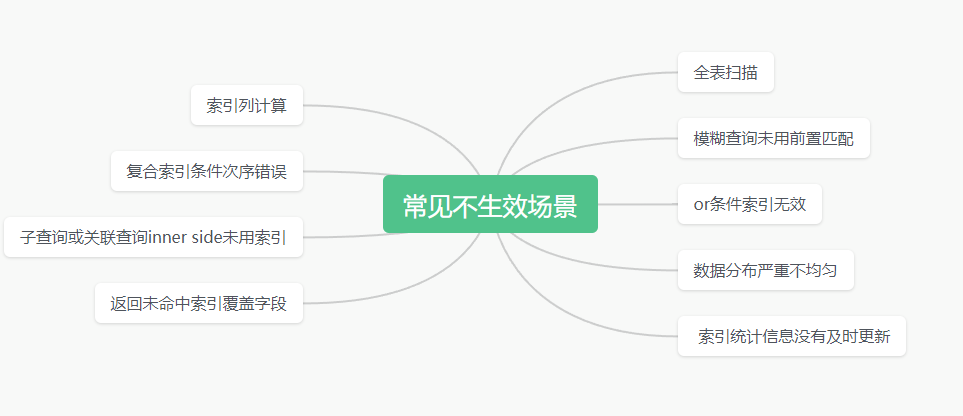
1.全表扫描
SQL语句中没有对索引列进行过滤条件限定,导致全表扫描,索引不生效。
下面是一个全表扫描导致索引失效的例子:
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(50),age INT, KEY idx_age (age)
);SELECT * FROM users WHERE name = 'John';
上面创建了users表,并在age列上创建了索引idx_age。但在查询时,条件是name列,而没有使用索引列age进行限定,这会导致全表扫描,idx_age索引不会生效。如果查询改为:
SELECT * FROM users WHERE age = 30 AND name = 'John';
先用索引列age进行过滤,再联合name一起查找,这样可以利用到idx_age索引,避免全表扫描,提高查询效率。
2.索引列计算
对索引列进行算数运算、函数转换、类型转换等,结果索引不再生效。
下面是一个索引列计算导致索引失效的例子:
CREATE TABLE users (id INT PRIMARY KEY,age INT, KEY idx_age (age)
);SELECT * FROM users WHERE age + 3 = 33;
上面在age列上创建了索引idx_age。但查询条件中对age进行了计算,将age+3进行比较。这导致索引idx_age无法起到作用。因为计算后age的值已经改变,无法直接用于索引查找。改写为不计算age的形式:
SELECT * FROM users WHERE age = 30;
直接比较age的值,这样可以充分利用idx_age索引,避免表扫描,提高查询效率。
3.模糊查询未用前置匹配
like语句的模糊匹配没有用%放在查询条件后面,索引的优势无法利用。
下面是一个模糊查询未用前置匹配导致索引失效的例子:
CREATE TABLE users (id INT PRIMARY KEY,name VARCHAR(50),KEY idx_name (name)
);SELECT * FROM users WHERE name LIKE '%John';
上面在name列上创建了索引idx_name。但模糊查询中,使用了%John方式,没有指明前置匹配。这种情况下,idx_name索引很难发挥作用,执行会变成全表扫描。改为使用前置匹配的形式:
SELECT * FROM users WHERE name LIKE 'John%';
指明 name 以John开头的条件,这样可以利用索引idx_name进行前置匹配优化,避免全表扫描。
4.复合索引条件次序错误
复合索引的条件没有按索引建立的顺序使用,导致部分索引无法生效。
下面是一个复合索引条件次序错误导致部分索引失效的示例:
CREATE TABLE users (id INT PRIMARY KEY, last_name VARCHAR(50),first_name VARCHAR(50),KEY idx_name (last_name, first_name)
);SELECT * FROM users WHERE first_name = 'John' AND last_name = 'Smith';
上面在last_name和first_name上创建了复合索引idx_name。但是查询条件的顺序是first_name在前,last_name在后。这与索引次序相反,导致索引只能生效于first_name条件,但无法生效于last_name条件。如果调整查询为:
SELECT * FROM users WHERE last_name = 'Smith' AND first_name = 'John';
保持与索引次序一致,那么idx_name索引可以完全生效,避免表扫描,提高查询效率。
5.or条件索引无效
or条件使得索引无法正确限定范围,无法利用索引进行筛选。
or条件导致索引失效的示例如下:
CREATE TABLE users (id INT PRIMARY KEY,age INT, name VARCHAR(50),KEY idx_age (age),KEY idx_name (name)
);SELECT * FROM users WHERE age = 30 OR name = 'John';
上面在age和name列上分别创建了单列索引。但是查询条件使用了or进行连接,这导致索引无法正确限定范围进行过滤。因为age=30的记录和name='John’的记录可能是两组没有交集的记录。使用or时就需要扫描更大范围,索引效率下降。可以改写为:
SELECT * FROM users WHERE age = 30
UNION
SELECT * FROM users WHERE name = 'John';
将or拆分为两个查询语句,每个查询只有一个条件,可以独立利用原有的索引,避免全表扫描。所以or条件往往会导致合理利用不到索引,需要特别注意。
6.子查询或关联查询inner side未用索引
子查询或关联查询的内层查询没有用到合的索引。
一个子查询或者关联查询inner side未使用索引导致外层索引失效的示例如下:
SELECT * FROM users
WHERE id IN (SELECT user_id FROM orders WHERE order_date = '2020-01-01'
);
外层查询在users表上根据id进行了索引查询。但是子查询orders表的查询没有使用索引,会全表扫描orders表来做IN查询。这会导致外层users表的id索引无效。可以这样修改:
SELECT * FROM users
WHERE id IN (SELECT user_id FROM orders WHERE order_date = '2020-01-01'INDEX (order_date)
);
在子查询orders表查询中,添加order_date列的索引,这样子查询可以利用索引进行筛选。外层的id索引也随之生效,避免全表扫描users表。所以要注意嵌套查询的内层查询也要注意索引的使用,否则容易导致外层索引失效。
7.数据分布严重不均匀
当索引列数据分布严重不均匀时,比如大量重复数据,索引效率会下降。
数据分布不均匀导致索引失效的一个典型例子如下:
CREATE TABLE users (id INT PRIMARY KEY,gender CHAR(1) DEFAULT 'm',KEY idx_gender (gender)
);INSERT INTO users(id) VALUES (1),(2),(3),(4),(5),(6),(7),(8),(9),(10);
上面在gender列创建了索引idx_gender。但是数据插入时,gender列都是默认值’m’,分布完全不均匀。此时如果查询:
SELECT * FROM users WHERE gender = 'm';
索引idx_gender实际上无法生效,因为几乎全表数据都匹配条件。会走全表扫描,而无法利用到索引的优点。这种数据分布极不均匀的情况下,对应的索引效果会大打折扣。要避免这种情况,应该在创建索引时注意对应数据的分布情况,对已存在索引的表也要定期分析数据分布,避免索引失效。
8.返回未命中索引覆盖字段
查询需要返回的字段没有完全被复合索引覆盖。
一个复合索引覆盖字段未命中导致索引失效的示例如下:
CREATE TABLE users (id INT PRIMARY KEY,last_name VARCHAR(50),first_name VARCHAR(50),age INT,KEY idx_name_age (last_name, first_name, age)
);SELECT id, last_name FROM users WHERE last_name='Smith';
这里在last_name,first_name和age上创建了复合索引idx_name_age。查询语句的where条件可以利用这个复合索引。但是SELECT返回的字段id和last_name不完全被idx_name_age索引覆盖。这种情况下,查询还是需要回表去寻找id字段的数据,idx_name_age索引就未能完全生效。解决方法是创建覆盖需要返回的所有字段的索引:
CREATE INDEX idx_name_id ON users (last_name, first_name, id);
或者将查询需要的所有字段都放入复合索引中。所以复合索引的字段覆盖也需要注意,否则索引的利用效率会大打折扣。
9.索引统计信息没有及时更新
导致查询优化器误判查询成本,选择了非最优索引。
示例如下:
CREATE TABLE users (id INT PRIMARY KEY,age INT, phone VARCHAR(15),KEY idx_age(age),KEY idx_phone(phone)
);INSERT INTO users VALUES
(1, 35, '13800000000'),
(2, 40, '13800000001'),
(3, 25, '13800000002');ANALYZE TABLE users; -- 统计信息默认采样扫描表EXPLAIN SELECT * FROM users WHERE age = 40;
开始我们对users表做analyze,收集表的统计信息,包括索引的基数估算等。但analyze默认就是对表做抽样扫描,如果表数据发生大量变更,索引统计信息就会失效。explain显示的结果可能是based on idx_phone, 而不是最优的idx_age索引。这就导致了选择错误索引的问题。解决方法是及时收集更新统计信息:
ANALYZE TABLE users UPDATE INDEXES;
或者在重要SQL语句前强制绑定使用的索引:
SELECT * FROM users FORCE INDEX(idx_age) WHERE age = 40;
所以及时更新统计信息和合理使用optimizer hints都可以避免这类问题。
总结
了解索引的机制和原理,合理设置索引,可以使查询效率大大提升,从而提升后端的运行效率
写在最后
感谢您的支持和鼓励! 😊🙏
如果大家对相关文章感兴趣,可以关注公众号"架构殿堂",会持续更新AIGC,java基础面试题, netty, spring boot, spring cloud等系列文章,一系列干货随时送达!
相关文章:
聊聊MySql索引的类型以及失效场景
文章目录 概念常见的索引1.B树索引2.哈希索引3.全文索引4.空间索引5.聚集索引 如何设计合理?1.明确索引需求2.选择索引列3.选择索引类型4.考虑索引维护开销5.设计联合索引6.删除不必要索引7.关注索引统计信息8.测试查询效果 常见不生效场景1.全表扫描2.索引列计算3.…...
零代码编程:用ChatGPT批量调整文件名称中的词汇顺序
文件夹里面很多文件,需要批量挑战标题中的一些词组顺序:“Peppa Pig - Kylie Kangaroo (14 episode _ 4 season) [HD].mp4”这个文件名改成“14 episode _ 4 season _ Peppa Pig - Kylie Kangaroo.mp4”,可以在ChatGPT中输入提示词࿱…...
stm32 hal库 st7789 1.54寸lcd
文章目录 前言一、软件spi1.cubemx配置2.源码文件 二、硬件spi1.cubemx配置2.源码文件3.小小修改 总结 前言 1.54寸lcd 240*240 一、软件spi 1.cubemx配置 一定要注意把这几个东西上拉。 使用c8 2.源码文件 我使用的是中景园的源码,他本来是是标准库的稍微修改…...

【arm实验1】GPIO实验-LED灯的流水亮灭
linuxlinux:~/study/01-asm$ cat asm-led.S .text .global _start _start: 1.设置GPIOE寄存器的时钟使能 RCC_MP_AHB4ENSETR[4]->1 0x50000a28 LDR R0,0X50000A28 LDR R1,[R0] 从r0为起始地址的4字节数据取出放在R1 ORR R1,R1,#(0x1<<4) 第4位设置为1 ORR R…...

MySQL关联数据表操作方式
1、准备工作(创建数据表) create table employee( emp_id int primary key, name varchar(20), birth_date date, sex varchar(1), salary int, branch_id int, sup_id int );create table client( client_id int primary key, client_name varchar(20)…...
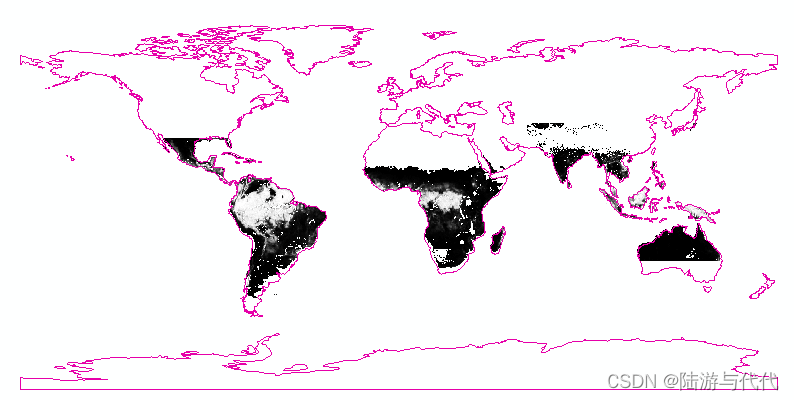
SMOS数据处理,投影变换,‘EPSG:6933‘转为‘EPSG:4326‘
在处理SMOS数据时,遇到了读取nc数据并存为tif后,影像投影无法改变,因此全球数据无法重叠。源数据的投影为EPSG:6933,希望转为EPSG:4326。 解决代码。 python import os import netCDF4 as nc import numpy as np from osgeo impo…...
游戏服务端性能测试实战总结
导语:近期经历了一系列的性能测试,涵盖了Web服务器和游戏服务器的领域。在这篇文章中,我将会对游戏服务端所做的测试进行详细整理和记录。需要注意的是,本文着重于记录,而并非深入的编程讨论。在这里,我将与…...

塔望食观察 | 中国海参产业发展现状及挑战
海参,一个古老的物种,堪称海底活化石,据资料显示,海参在地球上存活超过6亿年,比恐龙还早。海参的药用、食疗和营养滋补价值极高,清朝学者赵学敏编的《本草纲目拾遗》有这样的叙述:“海参性温补&…...
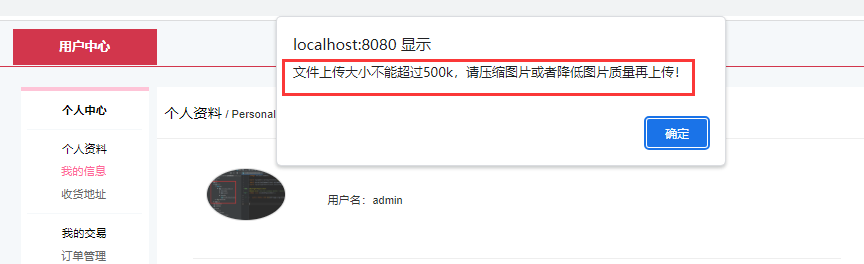
springboot 捕获特点异常信息并处理
前端获取效果图 springboot 捕获特点异常信息并处理 import com.one.utils.JSONResult; //JSONResult定义处理结果对象 import org.springframework.web.bind.annotation.ExceptionHandler...
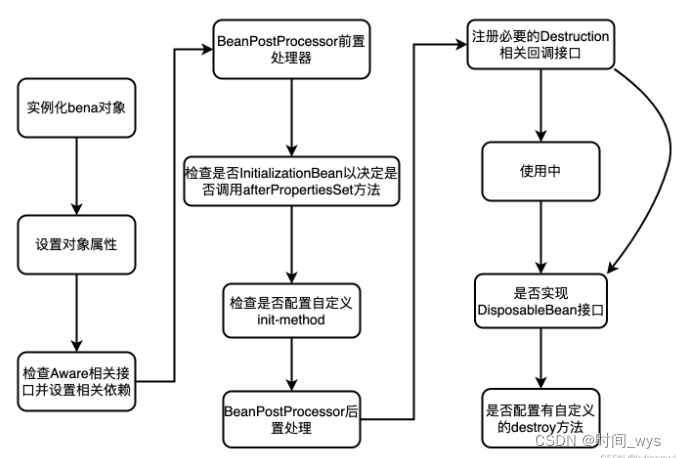
【Spring框架学习3】Spring Bean的作用域 及 生命周期
一、Spring Bean的作用域有哪些? Spring框架支持以下五种Bean的作用域: Singleton:这是默认的作用域,在每个Spring IoC容器中只有一个Bean的实例(IoC初始化后)。Spring 中的 bean 默认都是单例的,是对单例设计模式的…...

多线程并发篇---第四篇
系列文章目录 文章目录 系列文章目录一、Java中synchronized 和 ReentrantLock 有什么不同?二、有三个线程T1,T2,T3,如何保证顺序执行?三、SynchronizedMap和ConcurrentHashMap有什么区别?一、Java中synchronized 和 ReentrantLock 有什么不同? 相似点: 这两种同步方式有…...
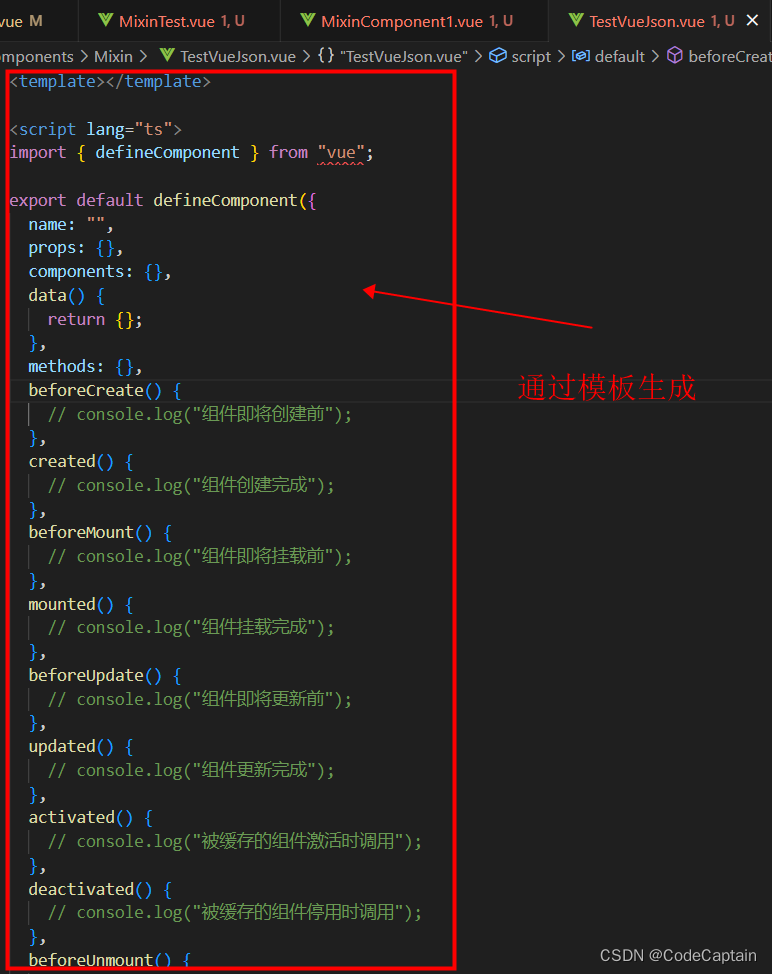
vs code 添加vue3代码模板方法
最终效果 vs code 添加vue文件模板用于通过简写自动生成代码 操作步骤如下 1.找到vue模板代码编写入口 2.修改模板内容 2.1 vue.json内容 {// Place your snippets for vue here. Each snippet is defined under a snippet name and has a prefix, body and// description. T…...

怎么通过Fiddler对APP进行抓包?以及高级应用场景分析
前言 我们经常需要用到Fiddler做代理服务器对Web、APP应用进行抓包,以便我们对接口功能进行测试调试,定位问题等。这篇将讲述怎么通过Fiddler对APP进行抓包,以及简单介绍一些高级应用场景。 首先,附上Fiddler使用的环境配置清单…...
centos下安装配置redis7
1、找个目录下载安装包 sudo wget https://download.redis.io/release/redis-7.0.0.tar.gz 2、将tar.gz包解压至指定目录下 sudo mkdir /home/redis sudo tar -zxvf redis-7.0.0.tar.gz -C /home/redis 3、安装gcc-c yum install gcc-c 4、切换到redis-7.0.0目录下 5、修改…...
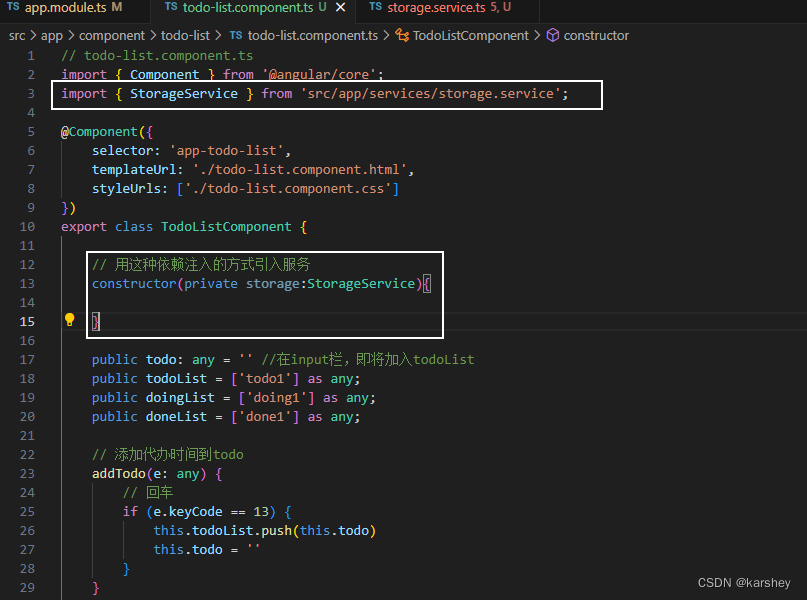
【angular】TodoList小项目(已开源)
参考:https://segmentfault.com/a/1190000013519099 文章目录 准备工作headerTodo、Doing、Done样式(HTMLCSS)功能(TS)将输入框内容加入todoList(addTodo)将todo事件改到doing 服务 参考开源 效…...

【Java 进阶篇】HTML块级元素详解
HTML(Hypertext Markup Language)是用于创建网页的标记语言。在HTML中,元素被分为块级元素和内联元素两种主要类型。块级元素通常用于构建网页的结构,而内联元素则嵌套在块级元素内,用于添加文本和其他内容。本文将重点…...

CSS设置鼠标样式和添加视频样式
鼠标的样式 <div style"cursor: default">默认鼠标的样式</div><div style"cursor: pointer">小手样式</div><div style"cursor: move">移动样式</div><div style"cursor: text">文本样式&…...
项目文件上传到行云codeup teambition
接手公司好几年的老项目,在行云上已经有1.9G的大小所以被限制上传了 只有花钱扩容或者重新建库。 1.重新建库:登录你的行云账户在代码库中新建代码库(网上有详细的) 创建成功后的库中只有readme文件。 2.复制代码库的下载地址 …...

现货黄金和实物黄金有什么区别?
在黄金投资市场中,现货黄金和实物黄金都是两种比较受欢迎的黄金投资品种。想想越来越多人认识到黄金投资的重要性,那么要选择一个投资品种,应该选哪个黄金投资品种呢?下面我们就来讨论一下这两者有何区别,以及投资者应…...
)
/dev下没有video0这个文件(ubuntu无法打开摄像头)
文章目录 硬件问题一、查看虚拟机摄像头连接情况二、解决红色报错三、虚拟机硬件处理内容问题一、设备号二、视频格式问题硬件问题 一、查看虚拟机摄像头连接情况 报错详情 ERROR: cannot launch node of type [image_view/image_view]: image_view ROS path [0]=/opt/ros/m…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

Godot中型项目工程化实践:目录规范、资源引用与状态管理
1. 这不是续集,而是项目落地的分水岭“Godot 游戏引擎项目(二)”——看到这个标题,很多人第一反应是:“哦,上一篇讲了环境搭建和Hello World,这篇该讲节点树和信号了?”但我在带三个…...

智慧树自动刷课助手:3步告别手动操作的学习效率工具
智慧树自动刷课助手:3步告别手动操作的学习效率工具 【免费下载链接】zhihuishu 智慧树刷课插件,自动播放下一集、1.5倍速度、无声 项目地址: https://gitcode.com/gh_mirrors/zh/zhihuishu 还在为智慧树平台的重复刷课操作而烦恼吗?智…...

如何高效批量下载音乐歌词:智能歌词管理完整指南
如何高效批量下载音乐歌词:智能歌词管理完整指南 【免费下载链接】ZonyLrcToolsX ZonyLrcToolsX 是一个能够方便地下载歌词的小软件。 项目地址: https://gitcode.com/gh_mirrors/zo/ZonyLrcToolsX ZonyLrcToolsX 是一款专业的跨平台歌词下载工具,…...

Raspberry Pi Debug Probe:RP2040嵌入式开发的调试利器与实战指南
1. 项目概述:为什么你需要一个Raspberry Pi Debug Probe?如果你玩过树莓派Pico或者任何基于RP2040芯片的开发板,肯定遇到过这样的场景:写好的代码,点一下“上传”,然后……就没有然后了。板子上的LED没按你…...

深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案
深度解析HS2-HF Patch:从技术框架到创作工具链的完整升级方案 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 你是否曾因Honey Select 2的原版体验受…...

LoRa物联网与动态基线算法在养殖体温监测中的实战应用
1. 项目概述:为什么我们需要一个智能体温监测系统?在规模化养殖场里干了十几年,我见过太多因为体温异常没被及时发现而导致的损失。一头育肥猪突然不吃食,等饲养员第二天巡栏发现时,可能已经高烧好几天,继发…...

UE4SS终极指南:从零开始掌握虚幻引擎脚本系统
UE4SS终极指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE4S…...

XZ6128A工作电压5-100V 输出电流5A 升压型大功率LED灯恒流驱动控制芯片
概述 XZ6128A是一款高效率、高精度的升压型大功率LED灯恒流驱动控制芯片。 XZ6128A内置高精度误差放大器,固定关断时间控制电路,恒流驱动电路等,特别适合大功率、多个高亮度LED灯串的恒流驱动。 XZ6128A采用固定关断时间的控制方式࿰…...

如何快速定制Office界面:终极开源工具使用指南
如何快速定制Office界面:终极开源工具使用指南 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-editor O…...