transformers架构实现
目录
架构代码如下
模型打印如下
架构代码如下
import numpy as np
from torch.autograd import Variable
import copy
from torch import softmax
import math
import torch
import torch.nn.functional as F
import torch.nn as nn
# 构建Embedding类来实现文本嵌入层
class Embeddings(nn.Module):def __init__(self,vocab,d_model):""":param vocab: 词表的大小:param d_model: 词嵌入的维度"""super(Embeddings,self).__init__()self.lut = nn.Embedding(vocab,d_model)self.d_model = d_modeldef forward(self,x):""":param x: 因为Embedding层是首层,所以代表输入给模型的文本通过词汇映射后的张量:return:"""return self.lut(x) * math.sqrt(self.d_model)
class PositionalEncoding(nn.Module):def __init__(self,d_model,dropout,max_len=5000):""":param d_model: 词嵌入的维度:param dropout: 随机失活,置0比率:param max_len: 每个句子的最大长度,也就是每个句子中单词的最大个数"""super(PositionalEncoding,self).__init__()self.dropout = nn.Dropout(p=dropout)pe = torch.zeros(max_len,d_model) # 初始化一个位置编码器矩阵,它是一个0矩阵,矩阵的大小是max_len * d_modelposition = torch.arange(0,max_len).unsqueeze(1) # 初始一个绝对位置矩阵 max_len * 1div_term = torch.exp(torch.arange(0,d_model,2)*-(math.log(1000.0)/d_model)) # 定义一个变换矩阵,跳跃式的初始化# 将前面定义的变换矩阵进行奇数、偶数的分别赋值pe[:,0::2] = torch.sin(position*div_term)pe[:,1::2] = torch.cos(position*div_term)pe = pe.unsqueeze(0) # 将二维矩阵扩展为三维和embedding的输出(一个三维向量)相加self.register_buffer('pe',pe) # 把pe位置编码矩阵注册成模型的buffer,对模型是有帮助的,但是却不是模型结构中的超参数或者参数,不需要随着优化步骤进行更新的增益对象。注册之后我们就可以在模型保存后重加载时,将这个位置编码与模型参数一同加载进来def forward(self, x):""":param x: 表示文本序列的词嵌入表示:return: 最后使用self.dropout(x)对对象进行“丢弃”操作,并返回结果"""x = x + Variable(self.pe[:, :x.size(1)],requires_grad = False) # 不需要梯度求导,而且使用切片操作,因为我们默认的max_len为5000,但是很难一个句子有5000个词汇,所以要根据传递过来的实际单词的个数对创建的位置编码矩阵进行切片操作return self.dropout(x)def subsequent_mask(size):""":param size: 生成向后遮掩的掩码张量,参数 size 是掩码张量的最后两个维度大小,它的最后两个维度形成一个方阵:return:"""attn_shape = (1,size,size) # 定义掩码张量的形状subsequent_mask = np.triu(np.ones(attn_shape),k = 1).astype('uint8') # 定义一个上三角矩阵,元素为1,再使用其中的数据类型变为无符号8位整形return torch.from_numpy(1 - subsequent_mask) # 先将numpy 类型转化为 tensor,再做三角的翻转,将位置为 0 的地方变为 1,将位置为 1 的方变为 0
def attention(query, key, value, mask=None, dropout=None):""":param query: 三个张量输入:param key: 三个张量输入:param value: 三个张量输入:param mask: 掩码张量:param dropout: 传入的 dropout 实例化对象:return:"""d_model = query.size(-1) # 得到词嵌入的维度,取 query 的最后一维大小scores = torch.matmul(query,key.transpose(-2,-1)) / math.sqrt(d_model) # 按照注意力公式,将 query 和 key 的转置相乘,这里是将 key 的最后两个维度进行转置,再除以缩放系数,得到注意力得分张量 scores# query(2,8,4,64) key.transpose(-2,-1) (2,8,64,4) 进行矩阵乘法为 (2,8,4,4)if mask is not None:scores = torch.masked_fill(scores,mask == 0,-1e9) # 使用 tensor 的 mask_fill 方法,将掩码张量和 scores 张量中每一个位置进行一一比较,如果掩码张量处为 0 ,则使用 -1e9 替换# scores = scores.masked_fill(mask == 0,-1e9)p_attn = softmax(scores, dim = -1) # 对 scores 的最后一维进行 softmax 操作,使用 F.softmax 方法,第一个参数是 softmax 对象,第二个参数是最后一个维度,得到注意力矩阵if dropout is not None:p_attn = dropout(p_attn)return torch.matmul(p_attn,value),p_attn # 返回注意力表示class MultiHeadAttention(nn.Module):def __init__(self, head, embedding_dim , dropout=0.1):""":param head: 代表几个头的参数:param embedding_dim: 词向量维度:param dropout: 置零比率"""super(MultiHeadAttention, self).__init__()assert embedding_dim % head == 0 # 确认一下多头的数量可以整除词嵌入的维度 embedding_dimself.d_k = embedding_dim // head # 每个头获得词向量的维度self.head = headself.linears = nn.ModuleList([copy.deepcopy(nn.Linear(embedding_dim, embedding_dim)) for _ in range(4)]) # 深层拷贝4个线性层,每一个层都是独立的,保证内存地址是独立的,分别是 Q、K、V以及最终的输出线性层self.attn = None # 初始化注意力张量self.dropout = nn.Dropout(p=dropout)def forward(self, query, key, value, mask=None):""":param query: 查询query [batch size, sentence length, d_model]:param key: 待查询key [batch size, sentence length, d_model]:param value: 待查询value [batch size, sentence length, d_model]:param mask: 计算相似度得分时的掩码(设置哪些输入不计算到score中)[batch size, 1, sentence length]:return:"""if mask is not None:mask = mask.unsqueeze(1) # 将掩码张量进行维度扩充,代表多头中的第 n 个头batch_size = query.size(0)query, key, value = [l(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2) for l, x in zip(self.linears, (query, key, value))] # 将1、2维度进行调换,目的是让句子长度维度和词向量维度靠近,这样注意力机制才能找到词义与句子之间的关系# 将每个头传递到注意力层x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)# 得到每个头的计算结果是 4 维的张量,需要形状的转换# 前面已经将1,2两个维度进行转置了,所以这里要重新转置回来# 前面已经经历了transpose,所以要使用contiguous()方法,不然无法使用 view 方法x = x.transpose(1, 2).contiguous() \.view(batch_size, -1, self.head * self.d_k)return self.linears[-1](x) # 在最后一个线性层中进行处理,得到最终的多头注意力结构输出class LayerNormalization(nn.Module):def __init__(self, features, eps=1e-6):""":param features: 词嵌入的维度:param eps: 出现在规范化公式的分母中,防止分母为0"""super(LayerNormalization, self).__init__()# a 系数的默认值为1,模型的参数self.a = nn.Parameter(torch.ones(features))# b 系统的初始值为0,模型的参数self.b = nn.Parameter(torch.zeros(features))# 把 eps 传递到类中self.eps = epsdef forward(self, x):# 在最后一个维度上求 均值,并且输出维度保持不变mean = x.mean(-1, keepdim=True)std = x.std(-1, keepdim=True)return self.a * (x - mean) / (std + self.eps) + self.bclass PositionFeedForward(nn.Module):def __init__(self, d_model, d_ff, dropout=0.1):""":param d_model: 输入维度,词嵌入的维度:param d_ff: 第一个的输出连接第二个的输入:param dropout: 置零比率"""super(PositionFeedForward, self).__init__()self.linear1 = nn.Linear(d_model, d_ff)self.linear2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(p = dropout)def forward(self, x):return self.linear2(self.dropout(torch.relu(self.linear1(x))))class SublayerConnection(nn.Module):def __init__(self, size, dropout=0.1):super(SublayerConnection,self).__init__()# 实例化了一个 LN 对象self.norm = LayerNormalization(size)self.dropout = nn.Dropout(p = dropout)def forward(self,x,sublayer):""":param x: 接受上一个层或者子层的输入作为第一个参数:param sublayer: 该子层连接中的子层函数胡作为第二个参数:return:""""首先对输出进行规范化,然后将结果交给子层处理,之后对子层进行 dropout处理" \"随机失活一些神经元,来防止过拟合,最后还有一个add操作" \"因此存在跳跃连接,所以是将输入x与dropout后的子层输出结果相加作为最终的子层连接输出"return x + self.dropout(sublayer(self.norm(x)))class EncoderLayer(nn.Module):def __init__(self, size, self_attn, feed_forward, dropout):""":param size: 词嵌入的维度:param self_attn: 传入多头自注意力子层实例化对象,并且是自注意力机制:param feed_forward: 前馈全连接层实例化对象:param dropout: 置零比率"""super(EncoderLayer,self).__init__()self.self_attn = self_attnself.feed_forward = feed_forwardself.sublayer = nn.ModuleList([copy.deepcopy(SublayerConnection(size,dropout)) for _ in range(2)])self.size = sizedef forward(self, x, mask):""":param x: 上一层的输出:param mask: 掩码张量:return:""""首先通过第一个子层连接结构,其中包含多头自注意力子层""然后通过第二个子层连接结构,其中包含前馈全连接子层,最后返回结果"x = self.sublayer[0](x,lambda x:self.self_attn(x,x,x,mask))return self.sublayer[1](x,self.feed_forward)
class Encoder(nn.Module):def __init__(self, layer, N):""":param layer: 编码器层:param N: 编码器的个数"""super(Encoder,self).__init__()self.layers = nn.ModuleList([copy.deepcopy(layer) for _ in range(N)])"初始化一个规范化层,用于最后的输出"self.norm = LayerNormalization(layer.size)# print('layer.size',layer.size) 512def forward(self, x, mask):for layer in self.layers:x = layer(x,mask)return self.norm(x)
class DecoderLayer(nn.Module):def __init__(self, size, self_attn, src_attn, feed_forward, dropout):""":param size: 代表词嵌入的维度,同时也代表解码器层的尺寸:param self_attn: 多头自注意力对象 Q = K = V:param src_attn: 多头自注意力对象,Q! = K = V:param feed_forward: 前馈全链连接层:param dropout: 置零比率"""super(DecoderLayer,self).__init__()self.size = sizeself.self_attn = self_attnself.src_attn = src_attnself.feed_forward = feed_forwardself.sublayer = nn.ModuleList([copy.deepcopy(SublayerConnection(size,dropout))for _ in range(3)])def forward(self, x, memory, source_mask, target_mask):""":param x: 来自上一层的输入x:param memory: 来自编码器层的语义存储变量 mermory:param source_mask: 源数据掩码张量:param target_mask: 目标数据掩码张量:return:""""将x传入第一个子层结构,输入分别是x 和 self_attn函数,因为是自注意力机制,所以Q、K、V相等 ""最后一个数据是目标数据的掩码张量,这时要对目标数据进行遮掩,因为这个时候模型还没有生成任何的目标数据""比如在解码器生成第一个字符或者词汇的时候,我们其实已经传入进来了滴哟个字符以便计算损失,但是我们不希望在生成第一个字符时模型能利用这个信息,同样在生成第二个字符或者词汇时,模型只能使用第一个字符或者词汇信息,第二个词汇以及以后的信息都不被模型允许使用"x = self.sublayer[0](x,lambda x:self.self_attn(x,x,x,target_mask))"进入第二个子层,这个子层中是常规的自注意力机制,q是输入x ,而k、v是编码层输出memory""传入source_mask,进行源数据遮掩并非是抑制信息泄露,而是遮蔽掉对结果没有意义的字符而产生的注意力值,加快模型的训练速度"x = self.sublayer[1](x,lambda x:self.self_attn(x,memory,memory,source_mask))"全连接子层,返回结果"return self.sublayer[2](x,self.feed_forward)
class Decoder(nn.Module):def __init__(self, layer, N):""":param layer: 编码器层:param N: 编码器的个数"""super(Decoder,self).__init__()self.layers = nn.ModuleList([copy.deepcopy(layer) for _ in range(N)])"初始化一个规范化层,用于最后的输出"self.norm = LayerNormalization(layer.size)# print('layer.size',layer.size) 512def forward(self, x, memory, source_mask, target_mask):for layer in self.layers:x = layer(x, memory, source_mask, target_mask)return self.norm(x)
class Generator(nn.Module):def __init__(self, vocab_size, d_model):""":param vocab_size: 词表大小:param d_model: 词向量维度"""super(Generator,self).__init__()self.out = nn.Linear(d_model, vocab_size)def forward(self,x):x = self.out(x)return F.log_softmax(x, dim=-1) # 在词嵌入的维度上进行softmax
class EncoderDecoder(nn.Module):def __init__(self,encoder,decoder,source_embed,target_embed,generator):""":param encoder: 编码器对象:param decoder: 解码器对象:param source_embed: 源输入嵌入函数:param target_embed: 目标数据嵌入函数:param generator: 输出部分的类别生成器对象"""super(EncoderDecoder,self).__init__()self.encoder = encoderself.decoder = decoderself.source_embed = source_embedself.target_embed = target_embedself.generator = generatordef Encode(self,source,source_mask):""":param source: 源数据:param source_mask: 源数据掩码:return:"""return self.encoder(self.source_embed(source),source_mask)def Decode(self,memory,source_mask,target,target_mask):""":param memory: 编码函数结果输出:param source_mask: 源数据掩码:param target: 经过嵌入层输入到解码函数中的目标数据:param target_mask: 目标数据掩码:return:"""return self.decoder(self.target_embed(target),memory,source_mask,target_mask)def forward(self,source,target,source_mask,target_mask):""":param source: 代表源数据:param target: 代表目标数据:param source_mask: 源数据的源码张量:param target_mask: 目标数据的源码张量:return:"""return self.Decode(self.Encode(source,source_mask),source_mask,target,target_mask)
def make_model(source_vocab, target_vocab, N=6, d_model=512, d_ff=2048,head=8, dropout=0.1):c = copy.deepcopyattn = MultiHeadAttention(head, d_model)ff = PositionFeedForward(d_model,d_ff,dropout)position = PositionalEncoding(d_model, dropout)model = EncoderDecoder(Encoder(EncoderLayer(d_model, c(attn), c(ff),dropout),N),Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff),dropout),N),nn.Sequential(Embeddings(source_vocab, d_model),c(position)),nn.Sequential(Embeddings(target_vocab, d_model),c(position)),Generator(target_vocab, d_model))for p in model.parameters():if p.dim() > 1:nn.init.xavier_uniform_(p)return model
if __name__ == "__main__":V = 11model = make_model(V, V, N=2)print(model)模型打印如下
F:\Anaconda\envs\py38\python.exe G:/python_files/transformers/transformers.py
EncoderDecoder(
(encoder): Encoder(
(layers): ModuleList(
(0): EncoderLayer(
(self_attn): MultiHeadAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionFeedForward(
(linear1): Linear(in_features=512, out_features=2048, bias=True)
(linear2): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNormalization()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNormalization()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1): EncoderLayer(
(self_attn): MultiHeadAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionFeedForward(
(linear1): Linear(in_features=512, out_features=2048, bias=True)
(linear2): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNormalization()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNormalization()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNormalization()
)
(decoder): Decoder(
(layers): ModuleList(
(0): DecoderLayer(
(self_attn): MultiHeadAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionFeedForward(
(linear1): Linear(in_features=512, out_features=2048, bias=True)
(linear2): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNormalization()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNormalization()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNormalization()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(1): DecoderLayer(
(self_attn): MultiHeadAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(src_attn): MultiHeadAttention(
(linears): ModuleList(
(0): Linear(in_features=512, out_features=512, bias=True)
(1): Linear(in_features=512, out_features=512, bias=True)
(2): Linear(in_features=512, out_features=512, bias=True)
(3): Linear(in_features=512, out_features=512, bias=True)
)
(dropout): Dropout(p=0.1, inplace=False)
)
(feed_forward): PositionFeedForward(
(linear1): Linear(in_features=512, out_features=2048, bias=True)
(linear2): Linear(in_features=2048, out_features=512, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(sublayer): ModuleList(
(0): SublayerConnection(
(norm): LayerNormalization()
(dropout): Dropout(p=0.1, inplace=False)
)
(1): SublayerConnection(
(norm): LayerNormalization()
(dropout): Dropout(p=0.1, inplace=False)
)
(2): SublayerConnection(
(norm): LayerNormalization()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(norm): LayerNormalization()
)
(source_embed): Sequential(
(0): Embeddings(
(lut): Embedding(11, 512)
)
(1): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(target_embed): Sequential(
(0): Embeddings(
(lut): Embedding(11, 512)
)
(1): PositionalEncoding(
(dropout): Dropout(p=0.1, inplace=False)
)
)
(generator): Generator(
(out): Linear(in_features=512, out_features=11, bias=True)
)
)
Process finished with exit code 0
相关文章:
transformers架构实现
目录 架构代码如下 模型打印如下 架构代码如下 import numpy as np from torch.autograd import Variable import copy from torch import softmax import math import torch import torch.nn.functional as F import torch.nn as nn # 构建Embedding类来实现文本嵌入层 class…...

C++类型推导
这里对C的类型推导方式进行一次全面的总结。 C中有三种类型推导的方式,分别是模板、auto以及decltype()。以下分别介绍这三种方式的同异。 一 模板 假设有这样的函数模板和这样的调用: template<typename T> void f(ParamType param);f(expr);…...
 SVD分解求两个点云的变换矩阵)
Open3D(C++) SVD分解求两个点云的变换矩阵
目录 一、算法原理二、代码实现三、结果展示四、相关链接一、算法原理 计算两个点云的质心计算中心化向量计算协方差矩阵奇异值分解,求解旋转矩阵 R R R计算平移向量 t t...

rtmp htttp推流Windows桌面到srs进行播放
推流命令: ffmpeg -f gdigrab -framerate 30 -i desktop -c:v libx264 -preset ultrafast -tune zerolatency -pix_fmt yuv420p -f flv rtmp://xxx.xxx.xxxx.xx/live/livestream 后面是推流地址 推流后的播放地址为: http://xxxxxx:8080/live/livestream.flv 可以写一个…...

NSSCTF做题(9)
[GDOUCTF 2023]<ez_ze> 看见输入框而且有提示说是ssti注入 输入{{7*7}} 试试,发现报错 输入{%%}发现了是jinja2模板 找到关键函数 Python SSTI利用jinja过滤器进行Bypass ph0ebuss Blog 原理见这篇文章,这里直接给出payload {%set ninedict(aaa…...
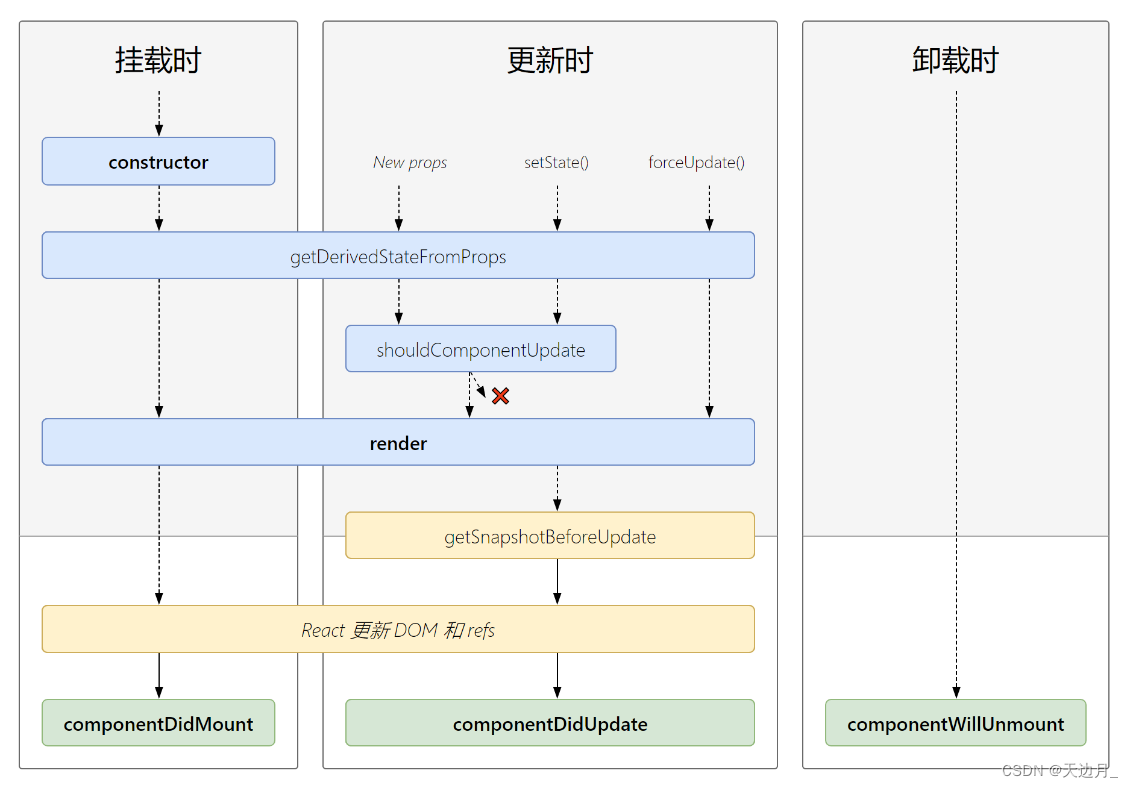
【09】基础知识:React组件的生命周期
组件从创建到死亡它会经历一些特定的阶段。 React 组件中包含一系列勾子函数(生命周期回调函数 <> 生命周期钩子函数 <> 生命周期函数 <> 生命周期钩子),会在特定的时刻调用。 我们在定义组件时,会在特定的生…...

Pytorch之ConvNeXt图像分类
文章目录 前言一、ConvNeXt设计决策1.设计方案2.Training Techniques3.Macro Design🥇Changing stage compute ratio🥈Change stem to "Patchify" 4.ResNeXt-ify5. Inverted Bottleneck6.Large Kernel Size7.Micro Design✨Replacing ReLU wit…...
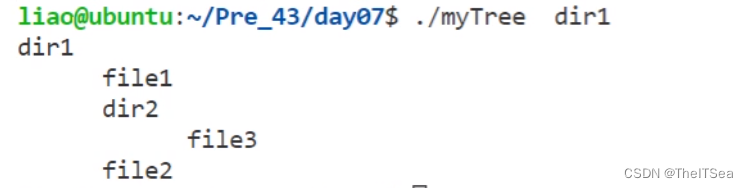
Linux系统编程:makefile以及文件系统编程
增量编译概念 首先回顾一下我们之前写的各种gcc指令用来执行程序: 可以看见非常繁琐,两个文件就要写这么多,那要是成百上千岂不完蛋。 所以为了简化工作量,很自然的想到了将这些命令放在一起使用脚本文件来一键执行,…...

《动手学深度学习 Pytorch版》 8.5 循环神经网络的从零开始实现
%matplotlib inline import math import torch from torch import nn from torch.nn import functional as F from d2l import torch as d2lbatch_size, num_steps 32, 35 train_iter, vocab d2l.load_data_time_machine(batch_size, num_steps) # 仍然使用时间机器数据集8.…...

写一个宏,可以将一个整数的二进制位的奇数位和偶数位交换
我们这里是利用按位与来计算的 我们可以想想怎么保留偶数上的位?我们可以利用0x55555555按位与上这个数就保留了偶数 我们知道,16进制0x55555555转换为二进制就是0x01010101010101010101010101010101 我们知道,二进制每一位,如…...
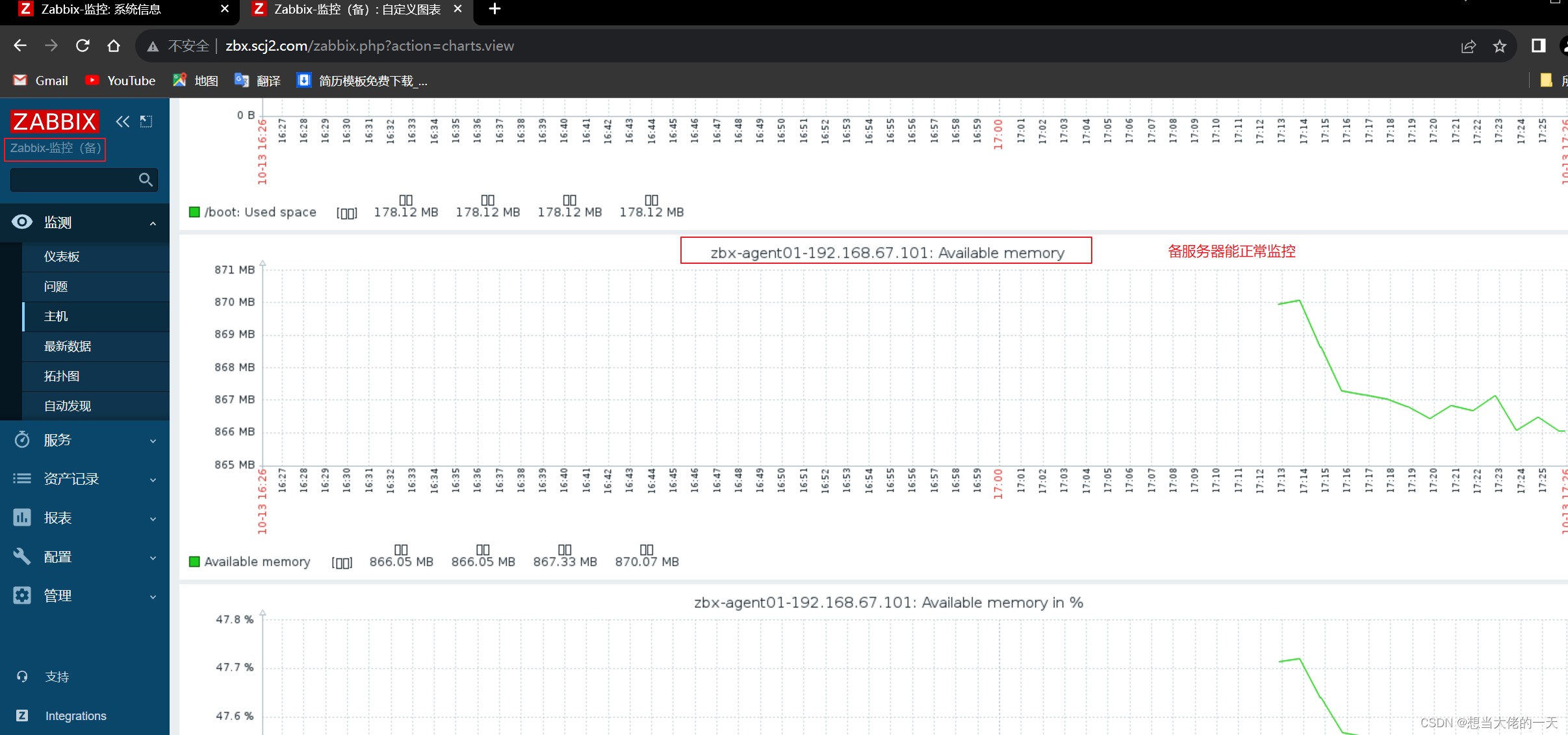
Zabbix监控系统详解2:基于Proxy分布式实现Web应用监控及Zabbix 高可用集群的搭建
文章目录 1. zabbix-proxy的分布式监控的概述1.1 分布式监控的主要作用1.2 监控数据流向1.3 构成组件1.3.1 zabbix-server1.3.2 Database1.3.3 zabbix-proxy1.3.4 zabbix-agent1.3.5 web 界面 2. 部署zabbix代理服务器2.1 前置准备2.2 配置 zabbix 的下载源,安装 za…...
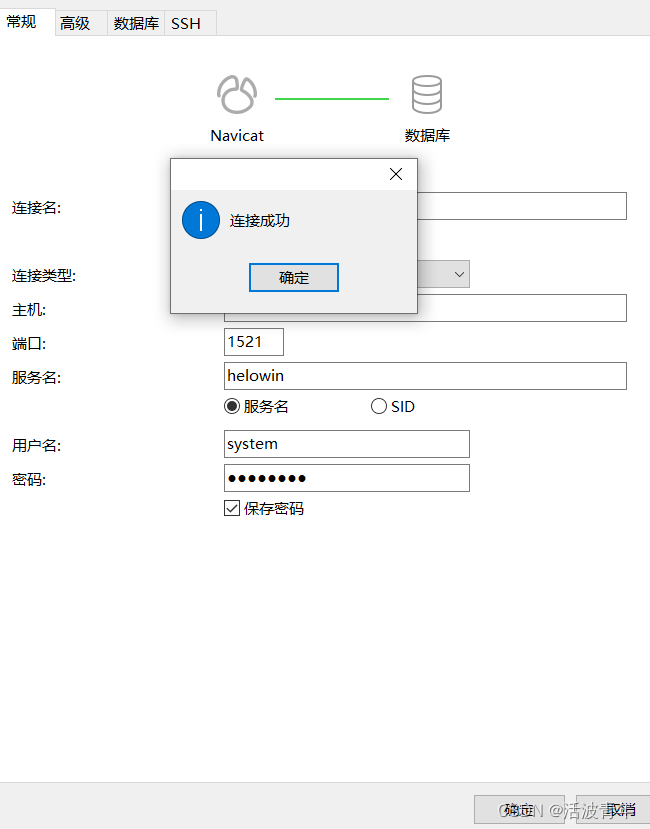
docker 安装oracle
拉取镜像 拉取oracle_11g镜像 拉取oracle镜像(oracle 11.0.2 64bit 企业版 实例名: helowin) Oracle主要在Docker基础上安装,安装环境注意空间和内存,Oracle是一个非常庞大的一个软件, 建议使用网易镜像或阿里镜像网站这里以oracle 11.0.2…...
)
C++ vector 自定义排序规则(vector<vector<int>>、vector<pair<int,int>>)
vector< int > vector<int> vec{1,2,3,4};//默认从小到大排序 1234 sort(vec.begin(),vec.end()); //从大到小排序 4321 sort(vec.begin(),vec.end(),greater<int>());二维向量vector<vector< int >> vector<vector<int>> vec{{0…...

机器学习 Q-Learning
对马尔可夫奖励的理解 看的这个教程 公式:V(s) R(s) γ * V(s’) V(s) 代表当前状态 s 的价值。 R(s) 代表从状态 s 到下一个状态 s’ 执行某个动作后所获得的即时奖励。 γ 是折扣因子,它表示未来奖励的重要性,通常取值在 0 到 1 之间。…...

产品设计心得体会 优漫动游
产品设计需要综合考虑用户需求、市场需求和技术可行性,从而设计出能够满足用户需求并具有市场竞争力的产品。以下是我在产品设计方面的心得体会: 产品设计心得体会 1.深入了解用户需求:在产品设计之前,需要进行充分的用户调研…...

前端--CSS
文章目录 CSS的介绍 引入方式 代码风格 选择器 复合选择器 (选学) 常用元素属性 背景属性 圆角矩形 Chrome 调试工具 -- 查看 CSS 属性 元素的显示模式 盒模型 弹性布局 一、CSS的介绍 层叠样式表 (Cascading Style Sheets). CSS 能够对网页中元素位置的排版进行像素级精…...
实操指南|如何用 OpenTiny Vue 组件库从 Vue 2 升级到 Vue 3
前言 根据 Vue 官网文档的说明,Vue2 的终止支持时间是 2023 年 12 月 31 日,这意味着从明年开始: Vue2 将不再更新和升级新版本,不再增加新特性,不再修复缺陷 虽然 Vue3 正式版本已经发布快3年了,但据我了…...

系统架构设计:15 论软件架构的生命周期
目录 一 软件架构的生命周期 1 需求分析阶段 2 设计阶段 3 实现阶段 4 构件组装阶段...

金山wps golang面试题总结
简单自我介绍如果多个协程并发写map 会导致什么问题如何解决(sync.map,互斥锁,信号量)chan 什么时候会发生阻塞如果 chan 缓冲区满了是阻塞还是丢弃还是panicchan 什么时候会 panic描述一下 goroutine 的调度机制goroutine 什么时…...

计算机视觉实战--直方图均衡化和自适应直方图均衡化
计算机视觉 文章目录 计算机视觉前言一、直方图均衡化1.得到灰度图2. 直方图统计3. 绘制直方图4. 直方图均衡化 二、自适应直方图均衡化1.自适应直方图均衡化(AHE)2.限制对比度自适应直方图均衡化(CRHE)3.读取图片4.自适应直方图均…...

开源智能体技术解析:从LangChain到自主抓取,构建自动化工作流
1. 项目概述:从“Awesome”列表看开源智能体生态的演进 最近在梳理一些前沿的自动化工具链时,又翻到了 mergisi/awesome-openclaw-agents 这个仓库。对于长期关注AI Agent(智能体)和自动化工作流开发的同行来说,这类…...

AI智能体任务编排框架:从概念到实战的Mission Control指南
1. 项目概述:为AI智能体打造一个“任务控制中心”最近在折腾AI智能体(Agent)的开发,发现一个挺普遍的问题:当你想让多个智能体协同工作,或者想让单个智能体执行一系列复杂、有依赖关系的任务时,…...

Fast-GitHub:打破GitHub访问壁垒的智能加速方案
Fast-GitHub:打破GitHub访问壁垒的智能加速方案 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub 你是否曾因GitHub仓库克…...

3个按键冲突场景,Hitboxer如何帮你重获游戏控制权?
3个按键冲突场景,Hitboxer如何帮你重获游戏控制权? 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否曾在激烈的游戏对战中,因为同时按下W和S键而突然卡住?或…...

Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案
Wand-Enhancer终极指南:免费解锁WeMod专业功能的完整解决方案 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费…...

UEFITool解析指南:三步骤掌握固件逆向分析的核心技术
UEFITool解析指南:三步骤掌握固件逆向分析的核心技术 【免费下载链接】UEFITool UEFI firmware image viewer and editor 项目地址: https://gitcode.com/gh_mirrors/ue/UEFITool UEFITool是一款功能强大的UEFI固件分析工具,能够帮助你深入探索计…...

终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题
终极指南:如何用BabelDOC彻底解决PDF翻译格式错乱问题 【免费下载链接】BabelDOC Yet Another Document Translator 项目地址: https://gitcode.com/GitHub_Trending/ba/BabelDOC 还在为学术论文翻译后排版全乱而烦恼吗?😫 技术文档翻…...

LVGL在无显存TFT屏上的驱动适配:双缓冲与DMA优化实践
1. 项目概述:当TFT屏幕遇上LVGL最近在做一个嵌入式GUI项目,核心任务是把LVGL这个轻量级图形库,适配到一块分辨率不算高但接口比较“个性”的TFT屏幕上。这活儿听起来像是把标准插头插到非标插座上,得自己动手改改线序。LVGL这几年…...

Kubernetes配置管理实战:基于Kustomize的结构化部署与多环境管理
1. 项目概述:一个被低估的Kubernetes配置管理利器如果你和我一样,长期在Kubernetes生态里摸爬滚打,那你一定经历过这样的场景:为了部署一个稍微复杂点的应用,需要维护一堆YAML文件——Deployment、Service、ConfigMap、…...
)
别再只会Commit了!用Git Desktop搞定分支合并与冲突解决(附真实开发场景)
别再只会Commit了!用Git Desktop搞定分支合并与冲突解决(附真实开发场景) 当你第一次接触Git时,可能觉得它就是个"保存按钮"——每次改完代码就commit一下。但随着项目规模扩大,特别是多人协作时,…...