大数据 DataX 详细安装教程
目录
一、环境准备
二、安装部署
2.1 二进制安装
2.2 python 3 支持
三、Data X 初体验
3.1 配置示例
3.1.1. 生成配置模板
3.1.2 创建配置文件
3.1.3 运行 DataX
3.1.4 结果显示
3.2 动态传参
3.2.1. 动态传参的介绍
3.2.2. 动态传参的案例
3.3 迸发设置
3.3.1 直接指定
3.3.2 Bps
3.3.3 tps
3.3.4. 优先级
官方参考文档:https://github.com/alibaba/DataX/blob/master/userGuid.md
一、环境准备
-
Linux 操作系统
-
JDK(1.8 及其以上都可以,推荐 1.8):Linux 下安装 JDK 和 Maven 环境_linux安装jdk和maven-CSDN博客
-
Python(2 或者 3 都可以):Spark-3.2.4 高可用集群安装部署详细图文教程_spark高可用-CSDN博客
-
Apache Maven 3.x(只有源码编译安装需要):Linux 下安装 JDK 和 Maven 环境_linux安装jdk和maven-CSDN博客
二、安装部署
2.1 二进制安装
-
1、下载安装 DataX 工具包,下载地址:https://datax-opensource.oss-cn-hangzhou.aliyuncs.com/202309/datax.tar.gz
-
2、将下载好的包上传到 Linux 中
-
3、解压安装即可
(base) [root@hadoop03 ~]# tar -zxvf datax.tar.gz -C /usr/local/
- 4、自检脚本
# python {YOUR_DATAX_HOME}/bin/datax.py {YOUR_DATAX_HOME}/job/job.json# 例如:
python /usr/local/datax/bin/datax.py /usr/local/datax/job/job.json
- 5、异常解决
如果执行自检程序出现如下错误:
[main] WARN ConfigParser - 插件[streamreader,streamwriter]加载失败,1s后重试... Exception:Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件.
[main] ERROR Engine -经DataX智能分析,该任务最可能的错误原因是:
com.alibaba.datax.common.exception.DataXException: Code:[Common-00], Describe:[您提供的配置文件存在错误信息,请检查您的作业配置 .] - 配置信息错误,您提供的配置文件[/usr/local/datax/plugin/reader/._drdsreader/plugin.json]不存在. 请检查您的配置文件.at com.alibaba.datax.common.exception.DataXException.asDataXException(DataXException.java:26)at com.alibaba.datax.common.util.Configuration.from(Configuration.java:95)at com.alibaba.datax.core.util.ConfigParser.parseOnePluginConfig(ConfigParser.java:153)at com.alibaba.datax.core.util.ConfigParser.parsePluginConfig(ConfigParser.java:125)at com.alibaba.datax.core.util.ConfigParser.parse(ConfigParser.java:63)at com.alibaba.datax.core.Engine.entry(Engine.java:137)at com.alibaba.datax.core.Engine.main(Engine.java:204)解决方案:将 plugin 目录下的所有的以 _ 开头的文件都删除即可
cd /usr/local/datax/plugin
find ./* -type f -name ".*er" | xargs rm -rf2.2 python 3 支持
DataX 这个项目本身是用 Python2 进行开发的,因此需要使用 Python2 的版本进行执行。但是我们安装的 Python 版本是 3,而且 3 和 2 的语法差异还是比较大的。因此直接使用 python3 去执行的话,会出现问题。
如果需要使用 python3 去执行数据同步的计划,需要修改 bin 目录下的三个 py 文件,将这三个文件中的如下部分修改即可:
-
print xxx 替换为 print(xxx)
-
Exception, e 替换为 Exception as e
# 以 datax.py 为例进行修改
(base) [root@hadoop03 ~]# cd /usr/local/datax/bin/
(base) [root@hadoop03 /usr/local/datax/bin]# ls
datax.py dxprof.py perftrace.py
(base) [root@hadoop03 /usr/local/datax/bin]# vim datax.pyprint(readerRef)print(writerRef)jobGuid = 'Please save the following configuration as a json file and use\n python {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json \nto run the job.\n'print(jobGuid)
使用 python3 命令执行自检脚本:
(base) [root@hadoop03 /usr/local/datax/bin]# python3 /usr/local/datax/bin/datax.py /usr/local/datax/job/job.json
三、Data X 初体验
3.1 配置示例
3.1.1. 生成配置模板
DataX 的数据同步工作,需要使用 json 文件来保存配置信息,配置 writer、reader 等信息。我们可以使用如下的命令来生成一个配置的 json 模板,在这个模板上进行修改,生成最终的 json文件。
python3 /usr/local/datax/bin/datax.py -r {reader} -w {writer}将其中的 {reader} 替换成自己想要的 reader 组件名字,将其中的 {writer} 替换成自己想要的 writer 组件名字。
- 支持的 reader:
所有的 reader 都存储于 DataX 安装目录下的 plugin/reader 目录下,可以在这个目录下查看:
(base) [root@hadoop03 /usr/local/datax]# ls
bin conf job lib log log_perf plugin script tmp
(base) [root@hadoop03 /usr/local/datax]# ls plugin/reader/
cassandrareader ftpreader hbase11xsqlreader loghubreader odpsreader otsreader sqlserverreader tsdbreader
clickhousereader gdbreader hbase20xsqlreader mongodbreader opentsdbreader otsstreamreader starrocksreader txtfilereader
datahubreader hbase094xreader hdfsreader mysqlreader oraclereader postgresqlreader streamreader
drdsreader hbase11xreader kingbaseesreader oceanbasev10reader ossreader rdbmsreader tdenginereader- 支持的 writer:
所有的 writer 都存储于 DataX 安装目录下的 plugin/writer 目录下,可以在这个目录下查看:
(base) [root@hadoop03 /usr/local/datax]# ls plugin/writer/
adbpgwriter datahubwriter gdbwriter hdfswriter mongodbwriter odpswriter postgresqlwriter streamwriter
adswriter doriswriter hbase094xwriter hologresjdbcwriter mysqlwriter oraclewriter rdbmswriter tdenginewriter
cassandrawriter drdswriter hbase11xsqlwriter kingbaseeswriter neo4jwriter oscarwriter selectdbwriter tsdbwriter
clickhousewriter elasticsearchwriter hbase11xwriter kuduwriter oceanbasev10writer osswriter sqlserverwriter txtfilewriter
databendwriter ftpwriter hbase20xsqlwriter loghubwriter ocswriter otswriter starrockswriter
例如需要查看 streamreader 和 streamwriter 的配置,可以使用如下操作:
python3 /usr/local/datax/bin/datax.py -r streamreader -w streamwriter这个命令可以将 json 模板直接打印在控制台上,如果想要以文件的形式保存下来,重定向输出到指定文件:
python3 /usr/local/datax/bin/datax.py -r streamreader -w streamwriter > ~/stream2stream.json3.1.2 创建配置文件
创建 stream2stream.json 文件:
(base) [root@hadoop03 ~]# mkdir jobs
(base) [root@hadoop03 ~]# cd jobs/
(base) [root@hadoop03 ~/jobs]# vim stream2stream.json
{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"sliceRecordCount": 10,"column": [{"type": "long","value": "10"},{"type": "string","value": "hello,你好,世界-DataX"}]}},"writer": {"name": "streamwriter","parameter": {"encoding": "UTF-8","print": true}}}],"setting": {"speed": {"channel": 5}}}
}3.1.3 运行 DataX
(base) [root@hadoop03 ~/jobs]# python3 /usr/local/datax/bin/datax.py stream2stream.json
3.1.4 结果显示

3.2 动态传参
3.2.1. 动态传参的介绍
DataX 同步数据的时候需要使用到自己设置的配置文件,其中可以定义同步的方案,通常为 json 的格式。在执行同步方案的时候,有些场景下需要有一些动态的数据。例如:
-
将 MySQL 的数据同步到 HDFS,多次同步的时候只是表的名字和字段不同。
-
将 MySQL 的数据增量的同步到 HDFS 或者 Hive 中的时候,需要指定每一次同步的时间。
-
...
这些时候,如果我们每一次都去写一个新的 json 文件将会非常麻烦,此时我们就可以使用 动态传参
所谓的动态传参,就是在 json 的同步方案中,使用类似变量的方式来定义一些可以改变的参数。在执行同步方案的时候,可以指定这些参数具体的值。
3.2.2. 动态传参的案例
{"job": {"content": [{"reader": {"name": "streamreader","parameter": {"sliceRecordCount": $TIMES,"column": [{"type": "long","value": "10"},{"type": "string","value": "hello,你好,世界-DataX"}]}},"writer": {"name": "streamwriter","parameter": {"encoding": "UTF-8","print": true}}}],"setting": {"speed": {"channel": 1}}}
} 在使用到同步方案的时候,可以使用 -D 来指定具体的参数的值。例如在上述的 json 中,我们设置了一个参数 TIMES,在使用的时候,可以指定 TIMES 的值,来动态的设置 sliceRecordCount 的值。
python3 /usr/local/datax/bin/datax.py -p "-DTIMES=3" stream2stream.json3.3 迸发设置
在 DataX 的处理流程中,Job 会被划分成为若干个 Task 并发执行,被不同的 TaskGroup 管理。在每一个 Task 的内部,都由 reader -> channel -> writer 的结构组成,其中 channel 的数量决定了并发度。那么 channel 的数量是怎么指定的?
-
直接指定 channel 数量
-
通过
Bps计算 channel 数量 -
通过
tps计算 channel 数量
3.3.1 直接指定
在同步方案的 json 文件中,我们可以设置 job.setting.speed.channel 来设置 channel 的数量。这是最直接的方式。在这种配置下,channel 的 Bps 为默认的 1MBps,即每秒传输 1MB 的数据。
3.3.2 Bps
Bps(Byte per second)是一种非常常见的数据传输速率的表示,在 DataX 中,可以通过参数设置来限制总 Job 的 Bps 以及单个 channel 的Bps,来达到限速和 channel 数量计算的效果。
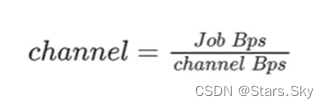
-
Job Bps:对一个 Job 进行整体的限速,可以通过
job.setting.speed.byte进行设置。 -
channel Bps:对单个 channel 的限速,可以通过
core.transport.channel.speed.byte进行设置。
3.3.3 tps
tps(transcation per second)是一种很常见的数据传输速率的表示,在 DataX 中,可以通过参数设置来限制总 Job 的 tps 以及单个 channel 的 tps,来达到限速和 channel 数量计算的效果。
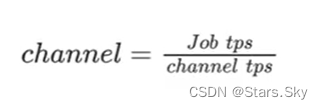
-
Job tps:对一个 Job 进行整体的限速,可以通过
job.setting.speed.record进行设置。 -
channel tps:对单个 channel 的限速,可以通过
core.transport.channel.speed.record进行设置。
3.3.4. 优先级
-
如果同时配置了 Bps 和 tps 限制,以小的为准。
-
只有在 Bps 和 tps 都没有配置的时候,才会以 channel 数量配置为准。
上一篇文章:大数据 DataX 数据同步数据分析入门-CSDN博客
相关文章:
大数据 DataX 详细安装教程
目录 一、环境准备 二、安装部署 2.1 二进制安装 2.2 python 3 支持 三、Data X 初体验 3.1 配置示例 3.1.1. 生成配置模板 3.1.2 创建配置文件 3.1.3 运行 DataX 3.1.4 结果显示 3.2 动态传参 3.2.1. 动态传参的介绍 3.2.2. 动态传参的案例 3.3 迸发设置 …...
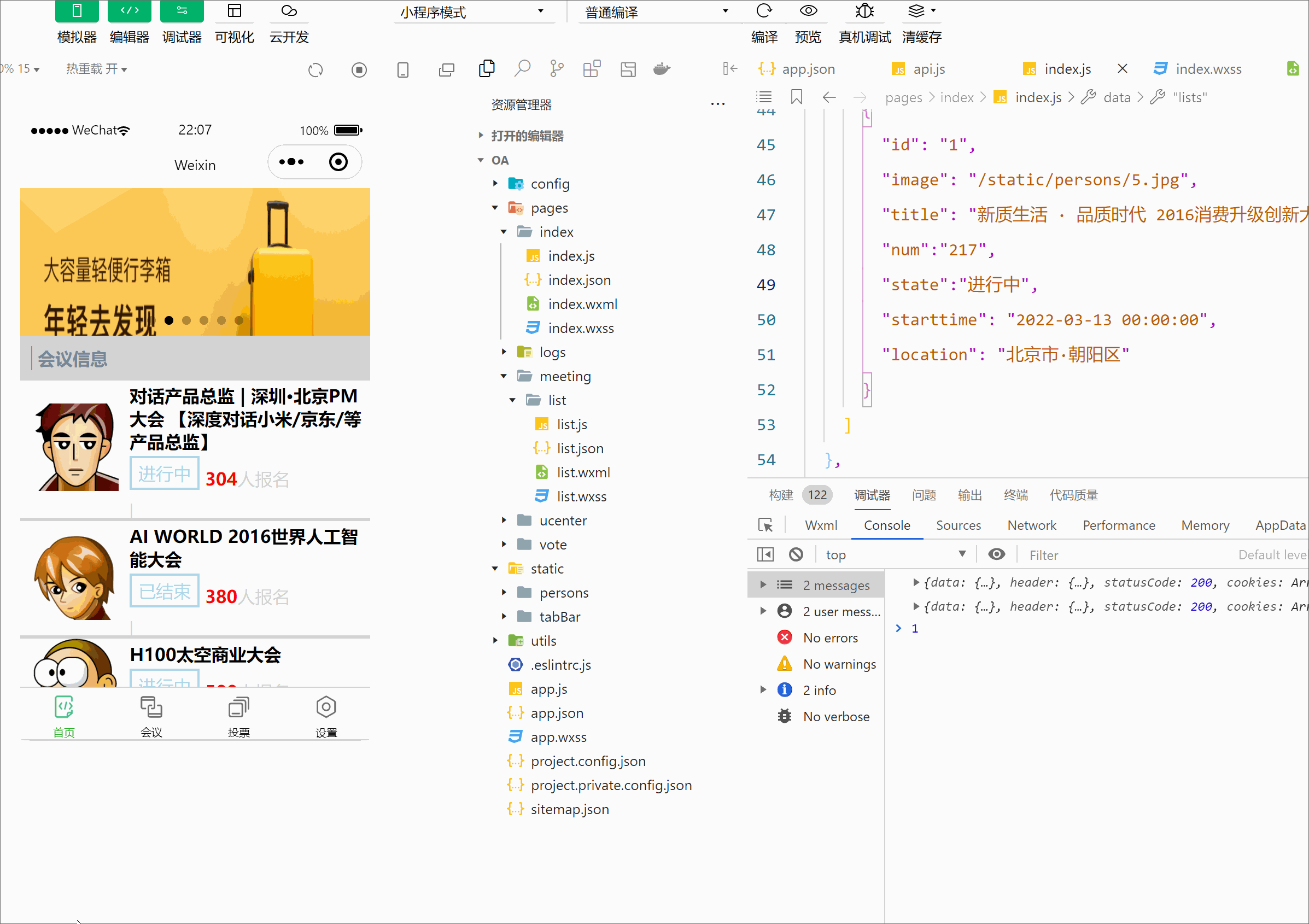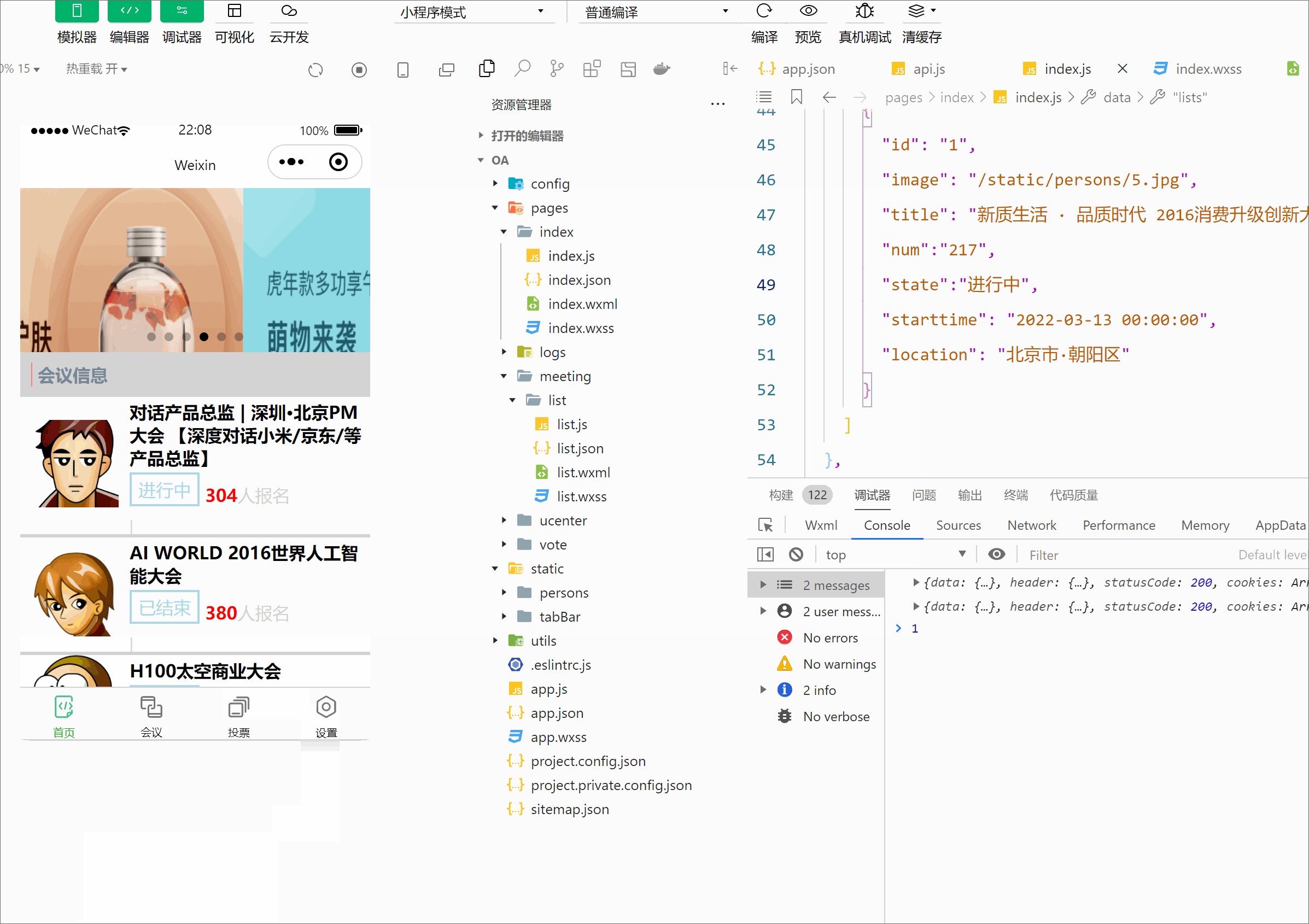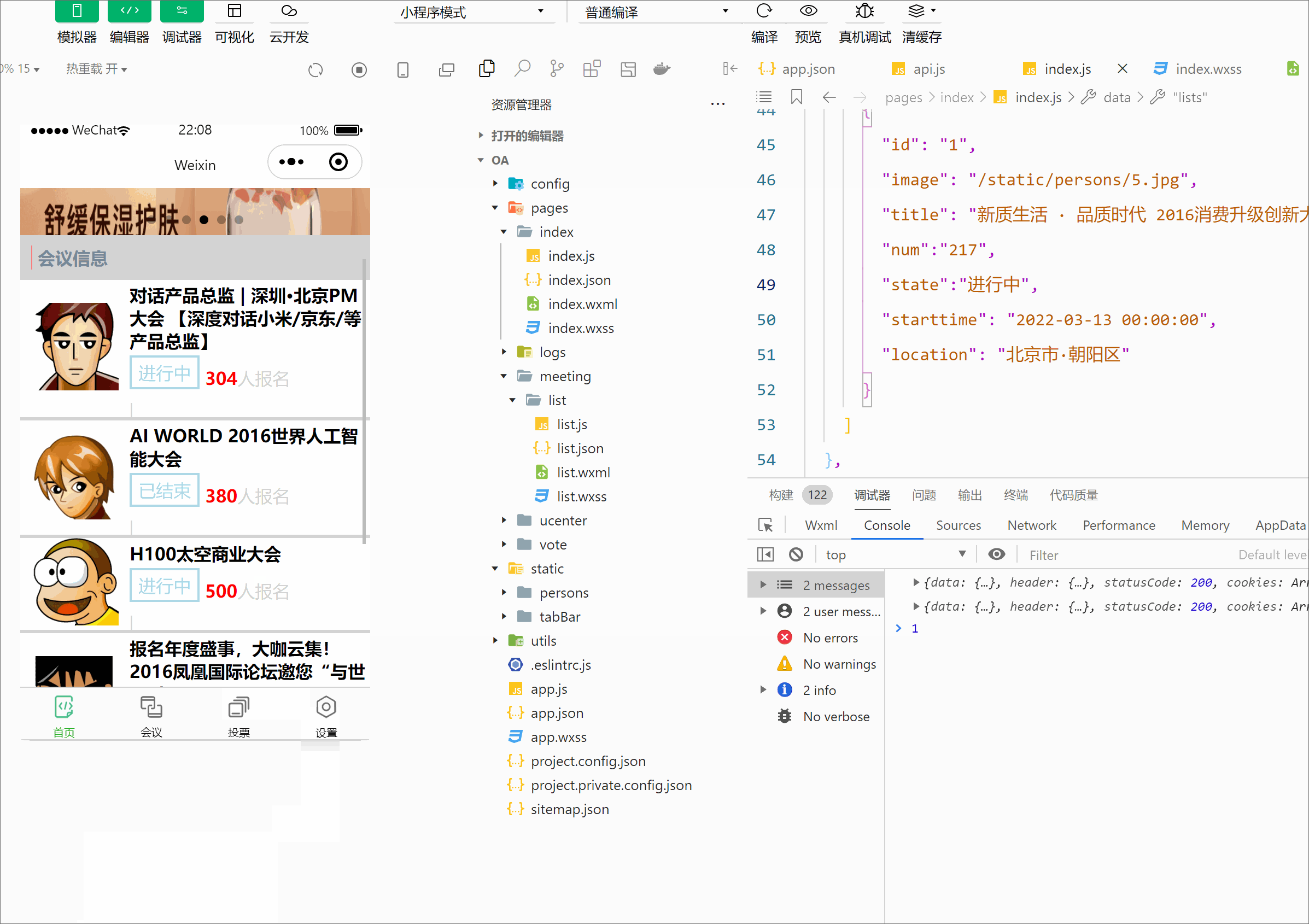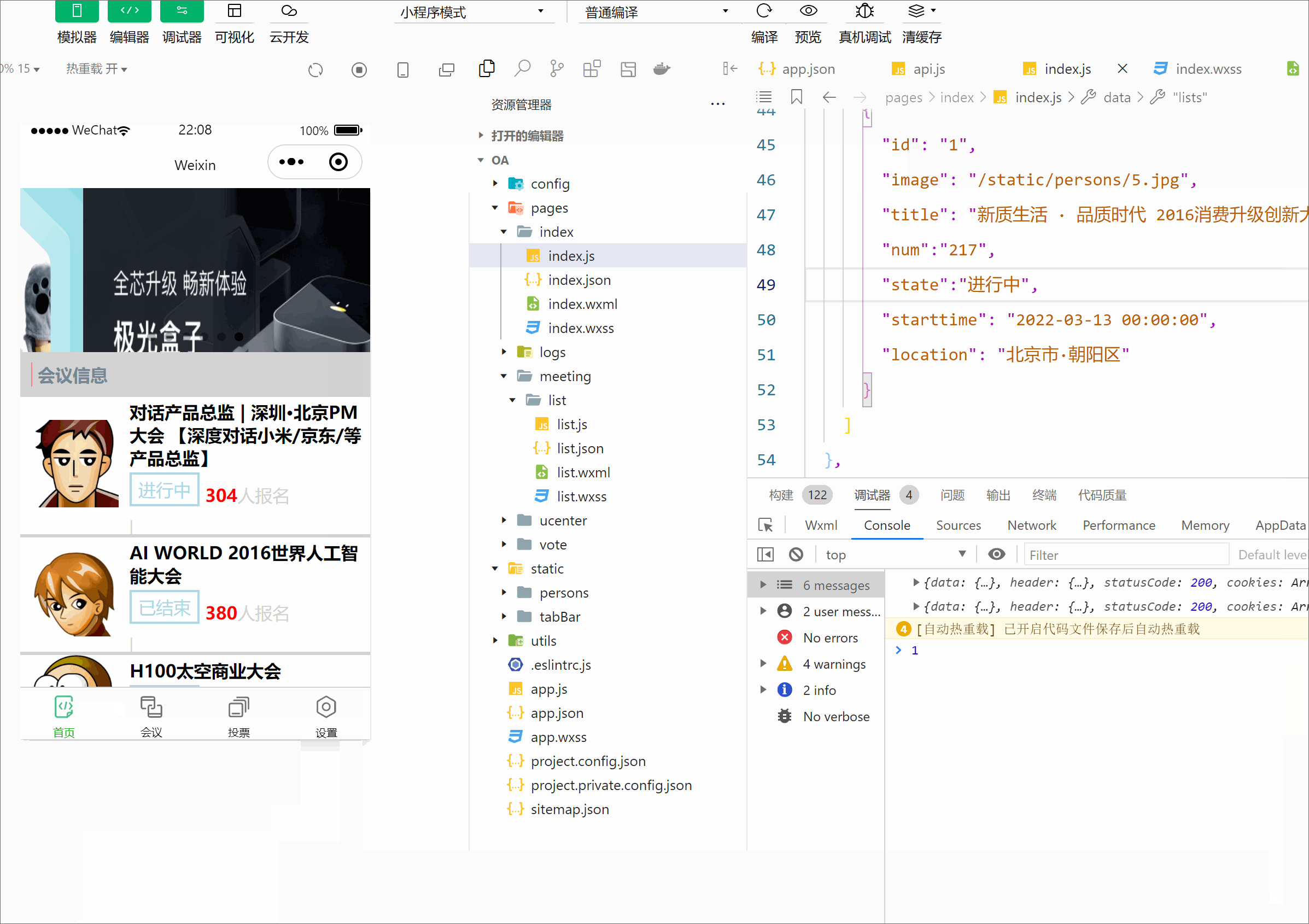
微信小程序开发之会议oa(首页搭建)
前言: 上一篇我们掌握了关于小程序的框架,这篇博客带你完成小程序版的会议OA首页。效果如下: 一, 1.1先创建OA首页页面: 首先我们先建一个新项目,在app.json中编写代码 {"pages": ["pages/…...

了解主启动类怎么运行
//SpringBootApplication 标注这个类是spring boot的应用,启动类下的所有资源都会被导入 SpringBootApplication public class SpringbootApplication { public static void main(String[] args) { //以为是启动了一个方法,没想到启动了一个服务 SpringA…...

【LeetCode】31. 下一个排列
1 问题 整数数组的一个 排列 就是将其所有成员以序列或线性顺序排列。 例如,arr [1,2,3] ,以下这些都可以视作 arr 的排列:[1,2,3]、[1,3,2]、[3,1,2]、[2,3,1] 。 整数数组的 下一个排列 是指其整数的下一个字典序更大的排列。更正式地&a…...

支持语音与视频即时通讯项目杂记(一)
第一部分解释服务端的实现。 (服务端结构) 下面一个用于实现TCP服务器的代码,包括消息服务器(TcpMsgServer)和文件中转服务器(TcpFileServer)。 首先,TcpServer是TcpMsgServer和Tcp…...

文档:htm格式转txt
꧂ 两个地方都保存꧁ import os import codecs from bs4 import BeautifulSoupdef generate_output_filename(file_path, save_path):# 获取文件名(不包含扩展名)file_name os.path.splitext(os.path.basename(file_path))[0]# 构造保存路径和文件名ou…...

电子邮件地址注册过程详解
许多人可能对如何注册电子邮件地址感到困惑,本文将详细解析电子邮件地址的注册过程:确定邮箱厂商、创建邮箱账户、设置电子邮件地址。 1、确定要注册的邮箱厂商 首先我们需要确定要注册哪种类型的电子邮件服务。目前市场上有许多不同的电子邮件服务提供商…...
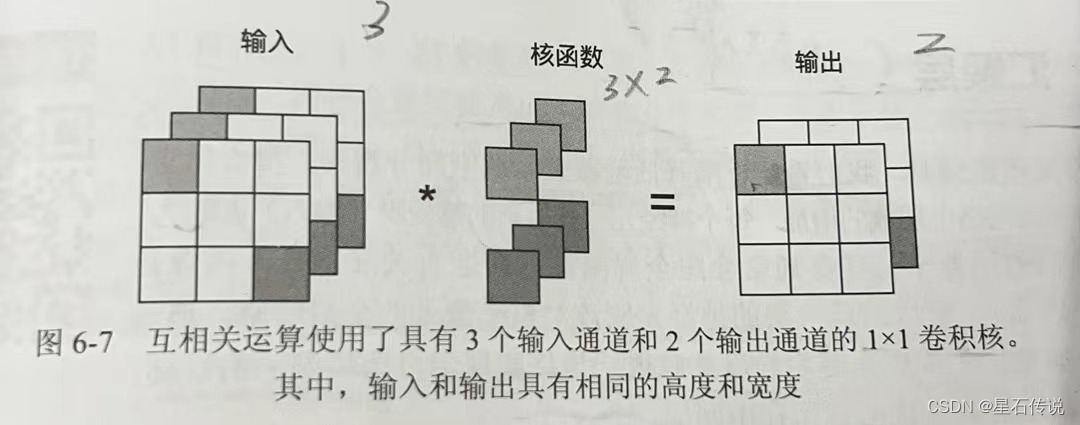
深度学习——卷积神经网络(CNN)基础二
深度学习——卷积神经网络(CNN)基础二 文章目录 前言三、填充和步幅3.1. 填充3.2. 步幅3.3. 小结 四、多输入多输出通道4.1. 多输入通道4.2. 多输出通道4.3. 11卷积层4.4. 小结 总结 前言 上文对卷积有了初步的认识,其实卷积操作就是通过卷积…...
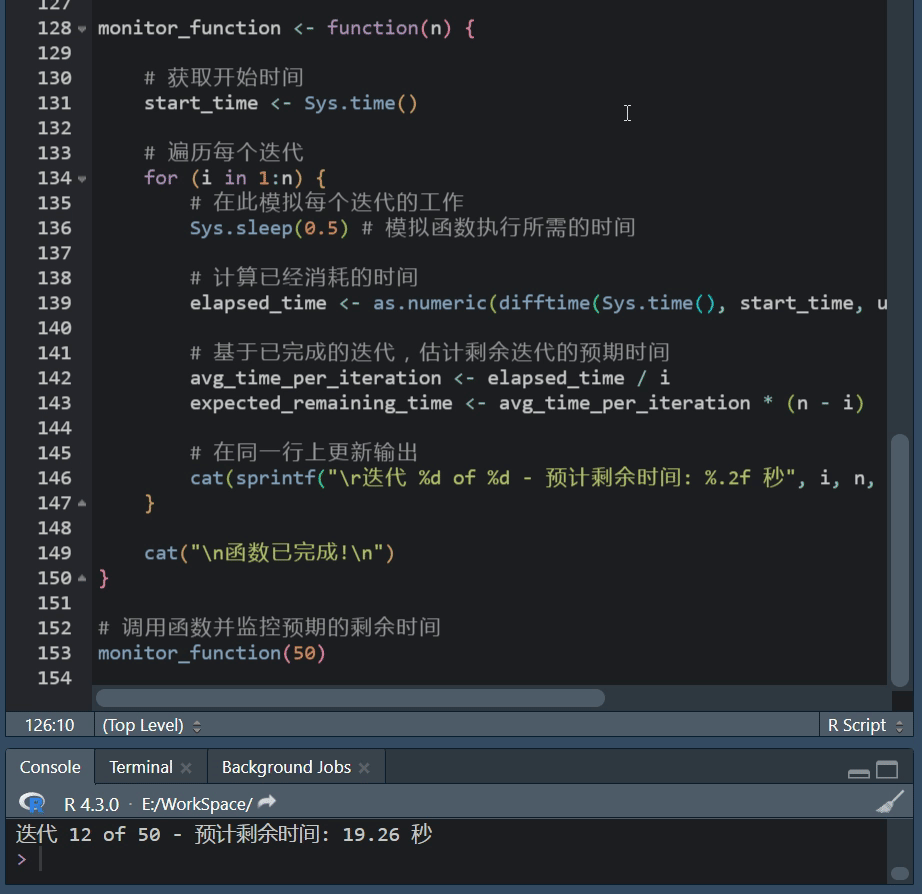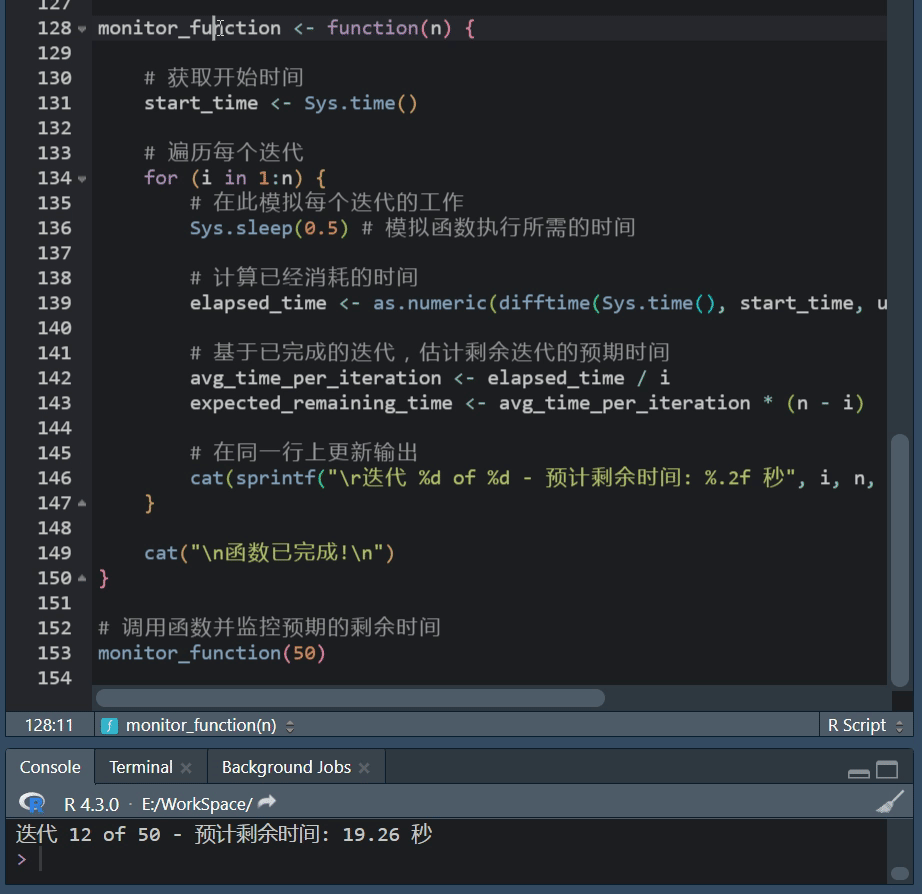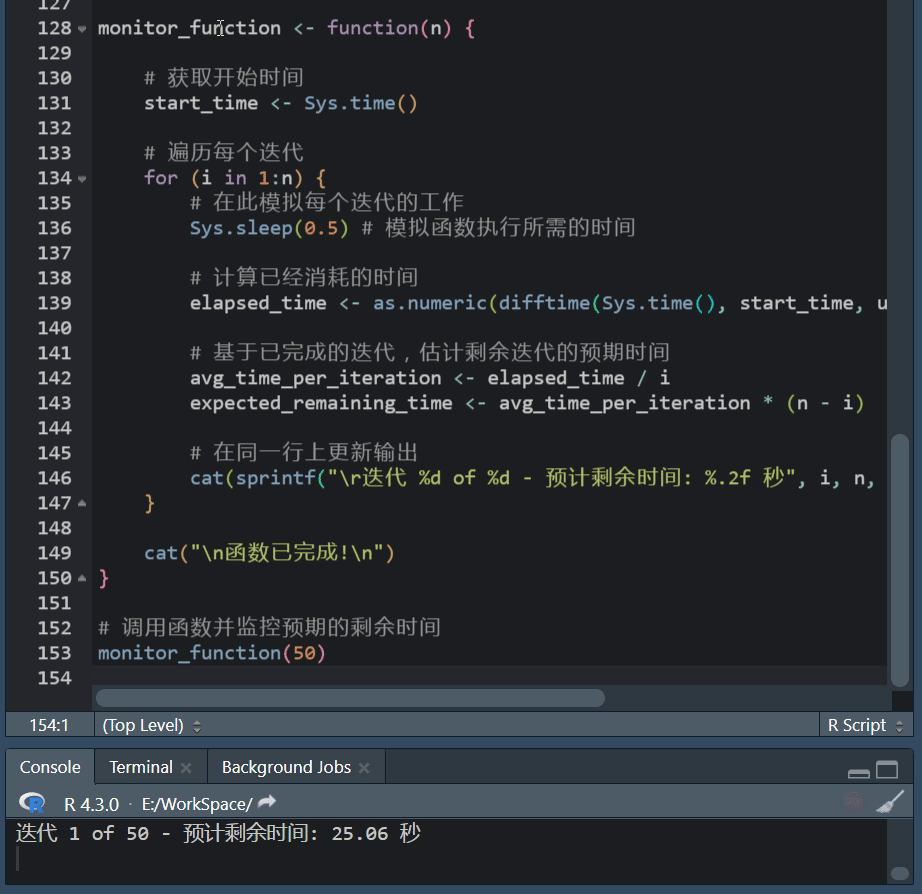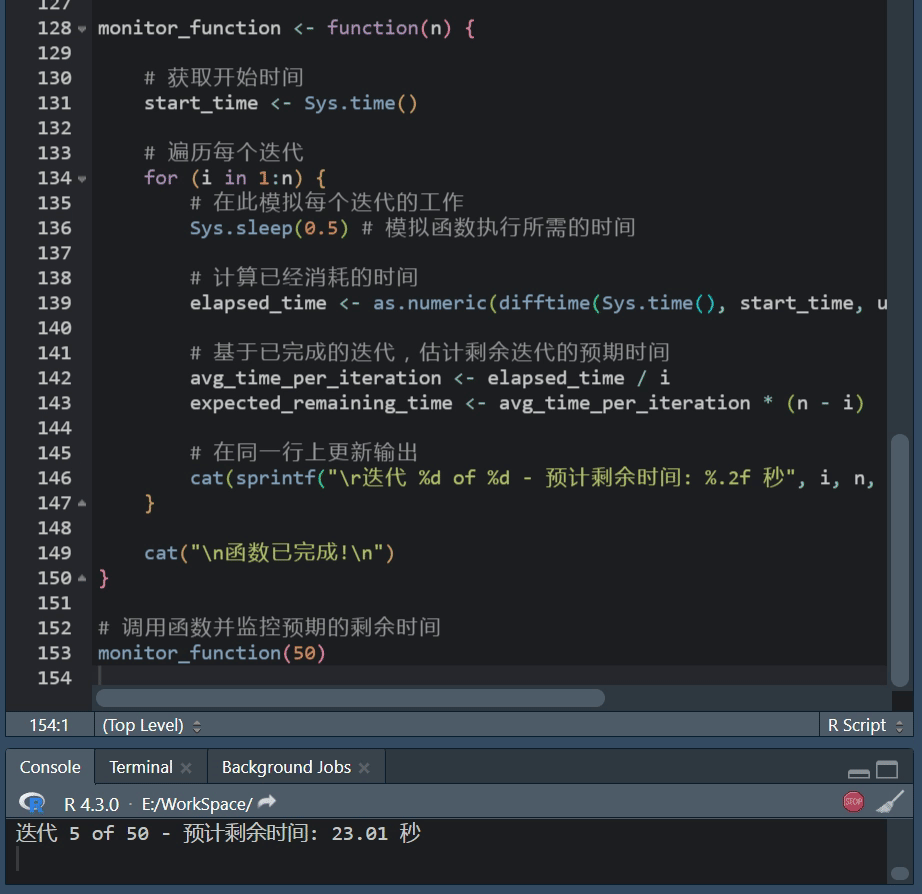
R语言进度条:txtProgressBar功能使用方法
R语言进度条使用攻略 在数据处理、建模或其他计算密集型任务中,我们常常会执行一些可能需要很长时间的操作。 在这些情况下,展示一个进度条可以帮助我们了解当前任务的进度,以及大约还需要多长时间来完成,R语言提供了几种简单且灵…...

Maven实战-声明周期和插件
Maven实战-声明周期和插件 Maven 设计了插件机制,每个构建步骤都可以绑定一个或者多个插件行为,而且 Maven 为大多数构建步骤编写 并绑定了默认插件。例如,针对编译的插件有 maven-compiler-plugin,针对测试的插件有 maven-sure…...
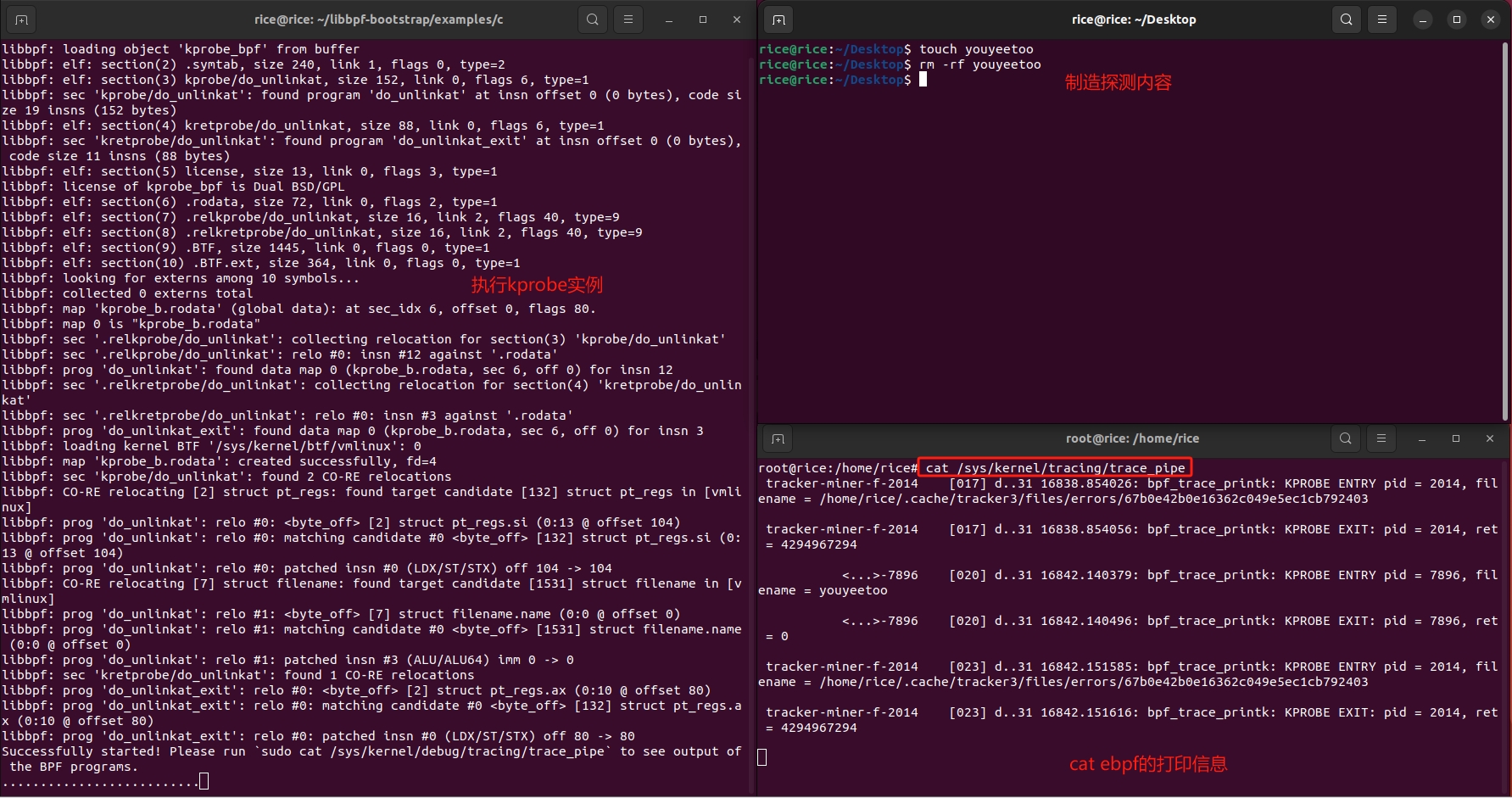
ebpf的快速开发工具--libbpf-bootstrap
基于ubuntu22.04-深入浅出 eBPF 基于ebpf的性能工具-bpftrace 基于ebpf的性能工具-bpftrace脚本语法 基于ebpf的性能工具-bpftrace实战(内存泄漏) 什么是libbpf-bootstrap libbpf-bootstrap是一个开源项目,旨在帮助开发者快速启动和开发使用eBPF(Extended Berk…...

万界星空科技/生产制造执行MES系统/开源MES/免费MES
开源系统概述: 万界星空科技免费MES、开源MES、商业开源MES、市面上最好的开源MES、MES源代码、免费MES、免费智能制造系统、免费排产系统、免费排班系统、免费质检系统、免费生产计划系统、免费数字化大屏。 万界星空开源MES制造执行系统的Java开源版本。开源mes…...

螺纹快速接头在卫浴行业中的应用提高产量降低生产成本
螺纹快速接头在卫浴行业主要用于上下水测试和密封性测试,可以快速密封连接待测产品和水管。取代之前的工人手拧编织管六角螺母的方式,方便快捷,密封性好,产品测试更稳定。 卫浴行业产品必须具备很好的密封性,防止在实际…...
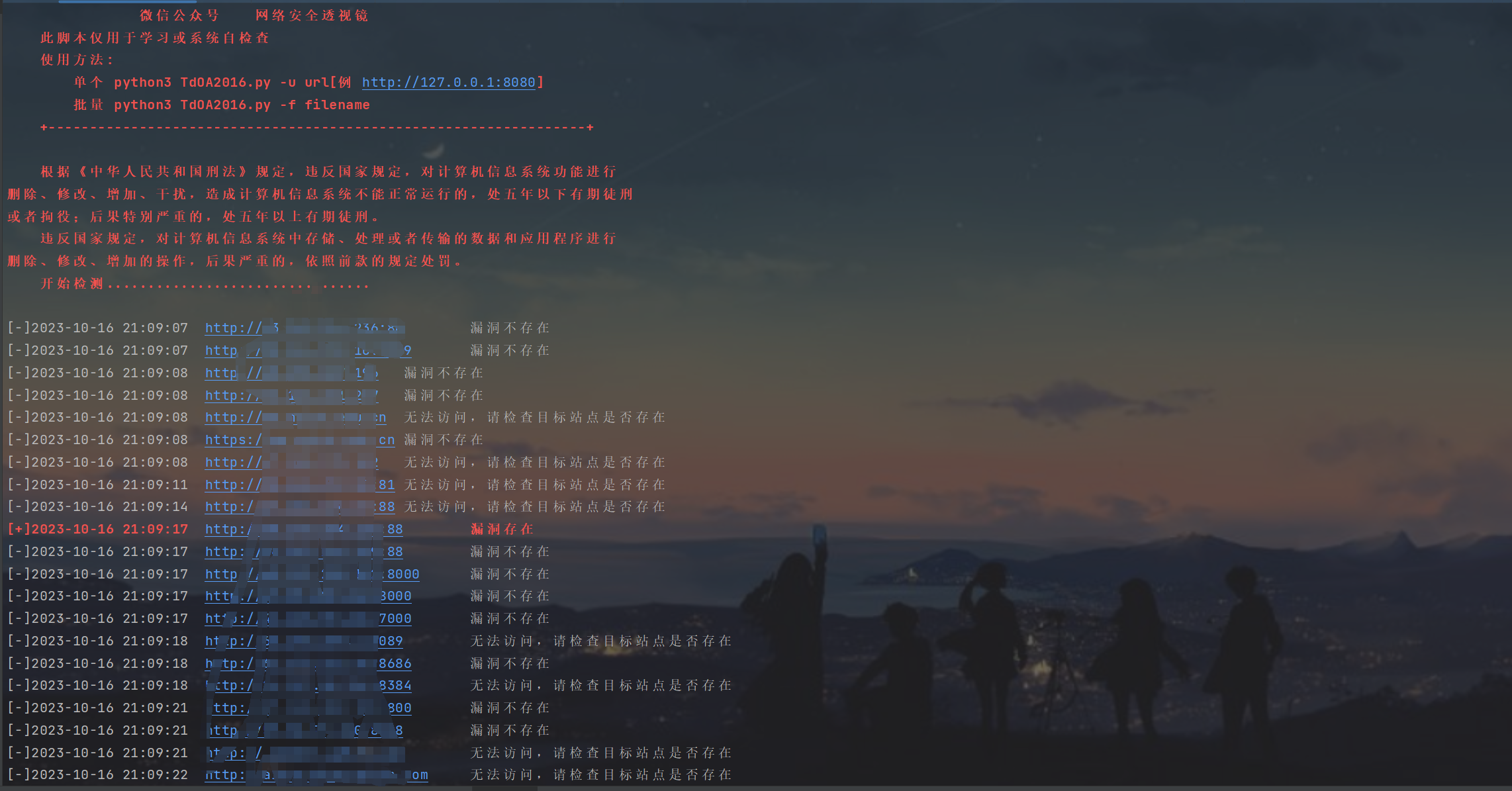
通达OA 2016网络智能办公系统 handle.php SQL注入漏洞
一、漏洞描述 北京通达信科科技有限公司通达OA2016网络智能办公系统 handle.php 存在sql注入漏洞,攻击者可利用此漏洞获取数据库管理员权限,查询数据、获取系统信息,威胁企业单位数据安全。 二、网络空间搜索引擎查询 fofa查询 app"T…...

parameter的各种用法以及localparam的用法
parameter的各种用法以及localparam的用法 一、这种写法放在v文件或者是用来调用其他的ram文件都是正确的。 一、这种写法放在v文件或者是用来调用其他的ram文件都是正确的。 module para_local();parameter a 10; // 第一种用法 parameter a 4d10; // 第二种用法 para…...

网络社区挖掘-图论部分的基本知识笔记
1 网络社区挖掘定义 网络社区挖掘是指利用数据挖掘技术和机器学习算法,分析社交网络、在线社区或互联网上的各种交互数据,以揭示其中隐藏的模式、关系和信息。这些社区可以是社交媒体平台、在线论坛、博客、微博等,人们在这些平台上进行交流…...

Vue Router - 路由的使用、两种切换方式、两种传参方式、嵌套方式
目录 一、Vue Router 1.1、下载 1.2、基本使用 a)引入 vue-router.js(注意:要在 Vue.js 之后引入). b)创建好路由规则 c)注册到 Vue 实例中 d)展示路由组件 1.3、切换路由的两种方式 1.…...

mysql为什么会选错索引,以及优化器是如何选择索引的
一:概念 在 索引建立之后,一条语句可能会命中多个索引,这时,索引的选择,就会交由 优化器 来选择合适的索引。 优化器选择索引的目的,是找到一个最优的执行方案,并用最小的代价去执行语句。 二…...
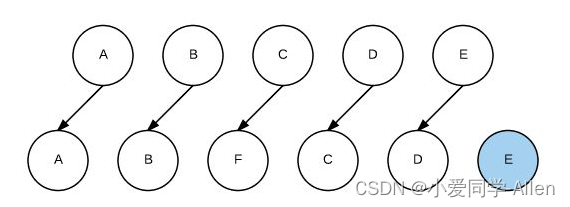
vue基础知识十七:你知道vue中key的原理吗?说说你对它的理解
一、Key是什么 开始之前,我们先还原两个实际工作场景 1.当我们在使用v-for时,需要给单元加上key <ul><li v-for"item in items" :key"item.id">...</li> </ul>2.用new Date()生成的时间戳作为key&#x…...
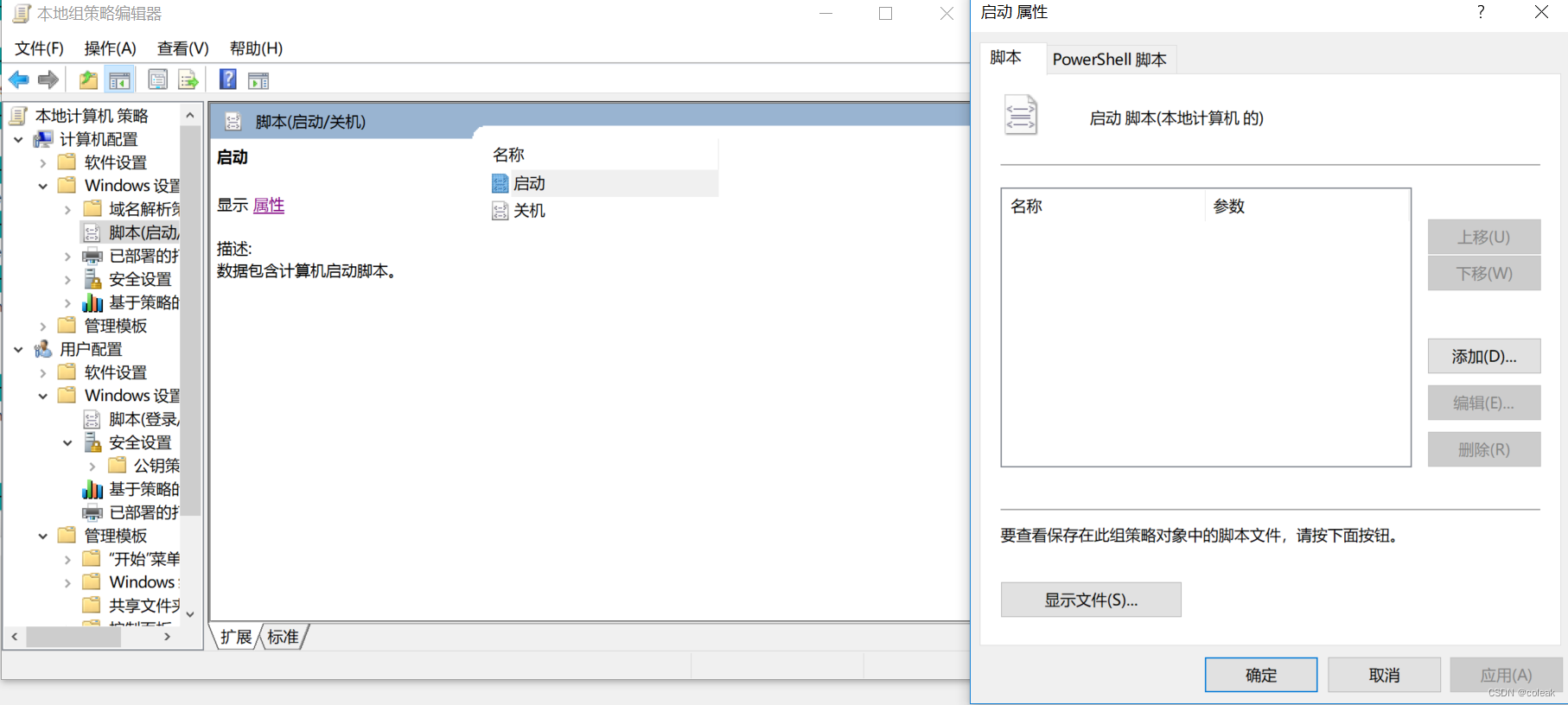
攻防演练蓝队|Windows应急响应入侵排查
文章目录 日志分析web日志windows系统日志 文件排查进程排查新增、隐藏账号排查启动项/服务/计划任务排查工具 日志分析 web日志 dirpro扫描目录,sqlmap扫描dvwa Python dirpro -u http://192.168.52.129 -b sqlmap -u "http://192.168.52.129/dvwa/vulnera…...

CANN/asc-devkit量化API文档
GetAscendDequantMaxMinTmpSize 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: …...

基于 RPA 自动化技术的私域机器人助手构建指南
利用自动化工作流实现私域运营中的消息智能响应与多任务协同 能力介绍 在私域流量运营中,如何高效响应用户需求、精细化管理社群是提升转化率的关键。传统的人工客服模式往往面临响应不及时、重复性劳动繁重等问题。 本方案基于 RPA(机器人流程自动化…...
)
别再新建空文件了!手把手教你用CodeBlocks创建可调试的C/C++工程(避坑中文路径)
别再新建空文件了!手把手教你用CodeBlocks创建可调试的C/C工程(避坑中文路径) 刚接触编程的新手常常会遇到这样的困惑:明明按照教程写好了代码,设置了断点,按下F7却毫无反应。这种挫败感往往源于一个被多数…...

如何快速上手UndertaleModTool:游戏修改的完整指南
如何快速上手UndertaleModTool:游戏修改的完整指南 【免费下载链接】UndertaleModTool The most complete tool for modding, decompiling and unpacking Undertale (and other GameMaker games!) 项目地址: https://gitcode.com/gh_mirrors/un/UndertaleModTool …...

环保设备系统控制柜制造:从工艺联动到稳定达标的完整解析
一、什么是环保设备系统控制柜制造?环保设备系统控制柜制造,是指根据废气治理、污水处理、粉尘治理、喷淋塔、活性炭吸附、催化燃烧、RTO/RCO、除尘器、风机水泵、加药系统、污泥处理、在线监测和环保设备联动控制等实际需求,对PLC、变频器、…...

Beyond Compare 5密钥生成指南:如何解决评估模式错误并快速激活
Beyond Compare 5密钥生成指南:如何解决评估模式错误并快速激活 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 当Beyond Compare 5的30天评估期结束后,许多用户会遇到&q…...

终极魔兽争霸3兼容性修复指南:5分钟让经典游戏在现代电脑上重生
终极魔兽争霸3兼容性修复指南:5分钟让经典游戏在现代电脑上重生 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为魔兽争霸3在现代Win…...

Kali 系统 Burp Suite 安装教程 零基础轻松上手
目录 安装环境 一、Kali Linux系统信息 编辑 二、安装及配置 1.下载Burp Suite 2.安装 3.配置proxy代理 安装环境 主机:MacBooPro 2021 M1 Pro 系统:Ventura 13.1 虚拟机软件:Parallels Desktop 虚拟机系统:Kali Linux…...

解锁AMD Ryzen潜力:SMUDebugTool硬件调试完全指南
解锁AMD Ryzen潜力:SMUDebugTool硬件调试完全指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...

KVM网络配置踩坑记:从virt-install的`--network`参数到virsh管理虚拟网桥
KVM网络配置实战:从virt-install到virsh的深度解析 当你在本地环境搭建KVM虚拟机时,网络配置往往是第一个拦路虎。不同于物理机插上网线就能用的简单体验,虚拟化环境中的网络需要经过多层抽象和配置才能正常工作。本文将带你深入KVM网络配置的…...