2.3 如何使用FlinkSQL读取写入到JDBC(MySQL)
1、JDBC SQL 连接器
FlinkSQL允许使用 JDBC连接器,向任意类型的关系型数据库读取或者写入数据
添加Maven依赖
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version>
</dependency>注意:如果使用 sql-client客户端,需保证 flink-1.17.1/lib 目录下 存在相应的jar包
相关jar可以通过官网下载:JDBC SQL 连接器
2、读取 MySQL
FlinkSQL读取MySQL表时,为批式处理,在流式计算任务中,通常被做维表来使用
-- 在FlinkSQL中创建 MySQL Source 表
drop table mysql_source_table;
CREATE TABLE mysql_source_table (`id` INT,`title` STRING,`author` STRING,`price` DOUBLE,`qty` INT
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://worker01/flink','driver' = 'com.mysql.jdbc.Driver', -- 【可选】不设置时,将自动从url中推导'username' = 'xxxx','password' = 'xxxx','table-name' = 'books'
);-- 批式 sql,查看 JDBC 表中的数据
select * from mysql_source_table;运行结果:

3、写入MySQL
3.1 何时批量写入MySQL呢?
FlinkSQL往MySQL写入数据时,默认会在客户端缓存数据,当触发设置的阈值后,才会向服务端发送数据
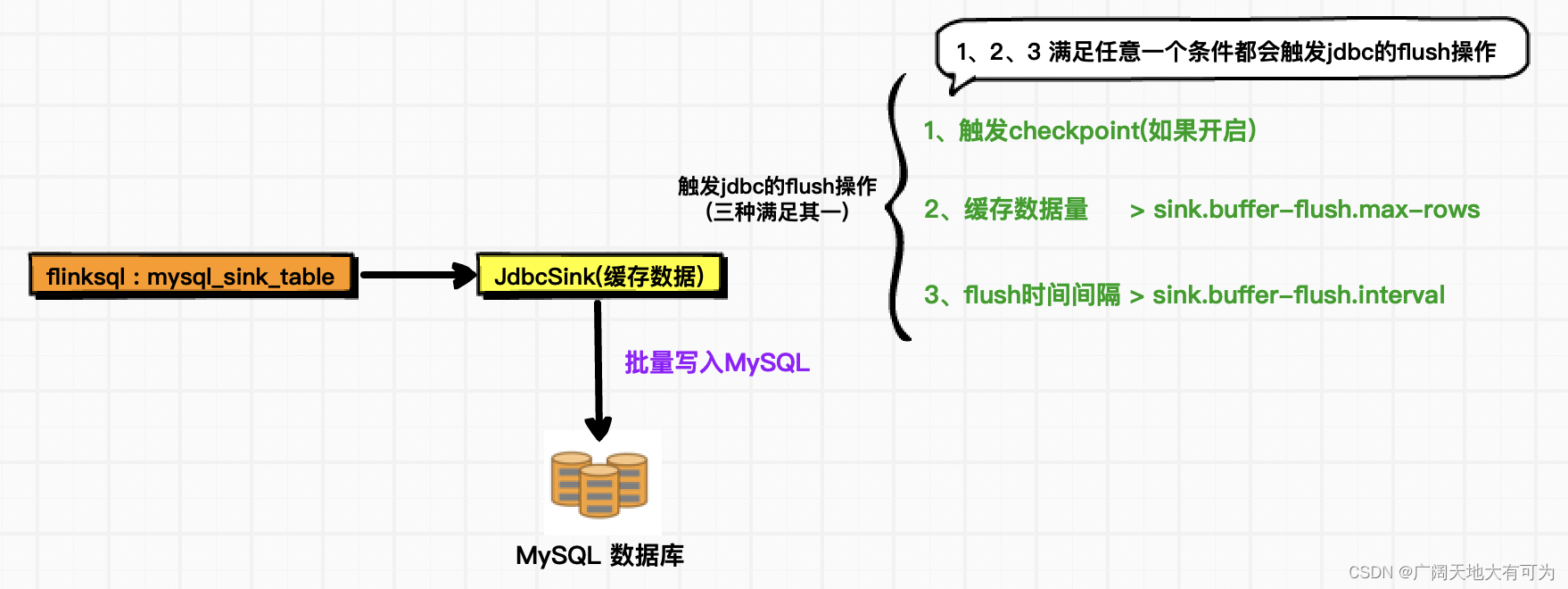
开启checkpoint :
# TODO 开启checkpoint,当checkpoint后,会触发jdbc的flush操作
set execution.checkpointing.interval=300sec;设置 flush 前缓存记录的最大值 、flush 间隔时间:
-- TODO 创建sink mysql table
drop table mysql_sink_table;
CREATE TABLE mysql_sink_table (`id` INT,`title` STRING,`author` STRING,`price` DOUBLE,`qty` INT
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://worker01:3306/flink?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8','username' = 'xxxx','password' = 'xxxx','table-name' = 'books','sink.buffer-flush.max-rows' = '100', -- flush 前缓存记录的最大值,默认值为100,设置为0时,表示不缓存数据(来一条写入一条)'sink.buffer-flush.interval' = '50s' -- flush 间隔时间,超过该时间后异步线程将 flush 数据。默认为1s
);使用说明:
FLinkSQL写入MySQL时,常通过 sink.buffer-flush.max-rows、sink.buffer-flush.interval 来控制写入数据的延迟程度
当 对写入实时性要求较高时,可以将 sink.buffer-flush.max-rows = 0 ,表示到来一条数据后立即写入MySQL,但带来的后果是 长时间占有mysql连接
当 数据量大且对实时要求不高时,可根据业务需求调大配置,可使实时行和性能最优
3.2 sink mysql table 中主键的作用
在FLinkSQL中创建sink mysql table时,如果表中定义了主键,则连接器将以 upsert 模式工作
否则连接器将以 append 模式工作
upsert 模式:Flink 将根据主键判断插入新行或者更新已存在的行
使用这种模式时,确保MySQL中的底表定义主键和添加唯一性约束
append 模式:对MySQL库中底表做insert操作
upsert 模式:
-- TODO 创建MySQL 表
CREATE TABLE `books` (`id` int(11) NOT NULL,`title` varchar(99) DEFAULT NULL,`author` varchar(99) DEFAULT NULL,`price` double DEFAULT NULL,`qty` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;-- TODO 创建FLinkSQL表(sink mysql table)
drop table mysql_sink_table;
CREATE TABLE mysql_sink_table (`id` INT,`title` STRING,`author` STRING,`price` DOUBLE,`qty` INT,PRIMARY KEY (id) NOT ENFORCED -- 指定主键字段
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://worker01:3306/flink?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8','username' = 'root','password' = 'xxxx','table-name' = 'books','sink.buffer-flush.max-rows' = '0' -- 实时写入
);-- TODO 往 mysql中写入数据(相同key的数据写入后,会做upsert操作)
insert into mysql_sink_table
SELECT * FROM (VALUES(5,'A Dream in Red Mansions','y', 3.0,1)
, (6,'Journey to the West','y', 3.0,1)
, (7,'Water Margin','y', 3.0,1)
) AS books (id, title,author,price,qty);append 模式:
-- TODO 创建FLinkSQL表(sink mysql table)
drop table mysql_sink_table;
CREATE TABLE mysql_sink_table (`id` INT,`title` STRING,`author` STRING,`price` DOUBLE,`qty` INT
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://worker01:3306/flink?serverTimezone=Asia/Shanghai&useUnicode=true&characterEncoding=UTF-8','username' = 'root','password' = 'xxx','table-name' = 'books','sink.buffer-flush.max-rows' = '0' -- 实时写入
);-- TODO 往 mysql中写入数据(相同key的数据写入后,会做操作)
insert into mysql_sink_table
SELECT * FROM (VALUES(5,'A Dream in Red Mansions','y', 3.0,1)
, (6,'Journey to the West','y', 3.0,1)
, (7,'Water Margin','y', 3.0,1)
) AS books (id, title,author,price,qty);注意:使用 append模式时,如果MySQL底表中存在主键或唯一性约束时,INSERT 插入可能会失败
insert into 失败:

相关文章:
2.3 如何使用FlinkSQL读取写入到JDBC(MySQL)
1、JDBC SQL 连接器 FlinkSQL允许使用 JDBC连接器,向任意类型的关系型数据库读取或者写入数据 添加Maven依赖 <dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1…...

Flink日志收集到数据库/kafka
引言 我们做项目过程中发现flink日志不同模式启动,存放位置不同,查找任务日志很不方便,具体问题如下: 原始flink的日志配置文件log4j-cli.properties appender.file.append false,取消追加,直接覆盖掉上…...

Go项目踩坑:go get下载超时,goFrame框架下的go项目里将vue项目的dist同步打包发布,go项目打包并压缩
Go项目踩坑:go get下载超时,goFrame框架下的go项目里将vue项目的dist同步打包发布,go项目打包并压缩 go get下载超时goFrame打包静态资源vue项目打包gf pack生成go文件 静态资源使用打包发布go项目交叉编译,省略一些不必要的信息通…...

DataCon【签到题】挖矿流量检测
【签到题】挖矿流量检测 文章目录 答案【多选】1. 个人电脑中了挖矿病毒通常有以下哪些表现?【单选】2. 在典型挖矿场景中,矿工和矿池之间目前最常用的通信协议是哪一个?【单选】3. 目前的虚拟货币挖矿场景中,最常采用的是哪种共识…...
Vivado详细使用教程 | LED闪烁示例
文章目录 整体流程第一步:新建工程第二步:设计输入第三步:功能仿真第四步:分析与综合第五步:约束输入第六步:设计实现第七步:下载比特流 整体流程 打开软甲------>新建工程------->设计输…...
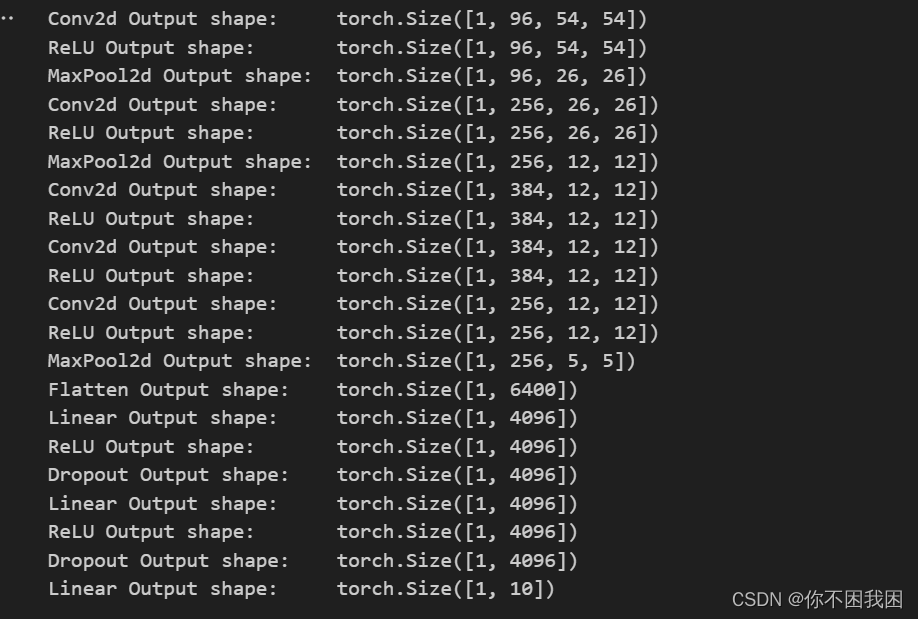
一些经典的神经网络(第17天)
1. 经典神经网络LeNet LeNet是早期成功的神经网络; 先使用卷积层来学习图片空间信息 然后使用全连接层来转到到类别空间 【通过在卷积层后加入激活函数,可以引入非线性、增加模型的表达能力、增强稀疏性和解决梯度消失等问题,从而提高卷积…...

Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件
Hadoop-HA-Hive-on-Spark 4台虚拟机安装配置文件 版本号步骤hadoopcore-site.xmlhdfs-site.xmlmapred-site.xmlslavesworkersyarn-site.xml hivehive-site.xmlspark-defaults.conf sparkhdfs-site.xmlhive-site.xmlslavesyarn-site.xmlspark-env.sh 版本号 apache-hive-3.1.3-…...

Hutool工具类参考文章
Hutool工具类参考文章 日期: 身份证:...

【 Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全】
Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全 本文主要介绍了Python ModuleNotFoundError: No module named ‘xxx‘可能的解决方案大全,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值&#x…...

eclipse 配置selenium环境
eclipse环境 安装selenium的步骤 配置谷歌浏览器驱动 Selenium安装-如何在Java中安装Selenium chrome驱动下载 eclipse 启动配置java_home: 在eclipse.ini文件中加上一行 1 配置java环境,网上有很多教程 2 下载eclipse,网上有很多教程 ps&…...
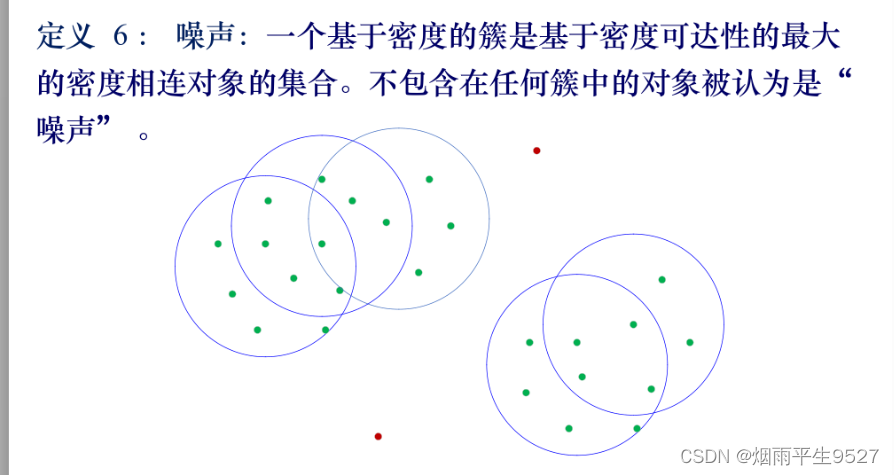
数据挖掘(6)聚类分析
一、什么是聚类分析 1.1概述 无指导的,数据集中类别未知类的特征: 类不是事先给定的,而是根据数据的相似性、距离划分的聚类的数目和结构都没有事先假定。挖掘有价值的客户: 找到客户的黄金客户ATM的安装位置 1.2区别 二、距离和相似系数 …...
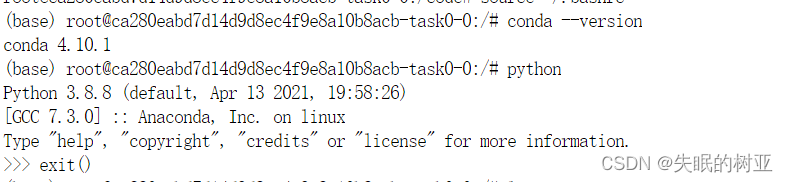
在启智平台上安装anconda
安装Anaconda3-5.0.1-Linux-x86_64.sh python版本是3.6 在下面的网站上找到要下载的anaconda版本,把对应的.sh文件下载下来 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 把sh文件压缩成.zip文件,拖到启智平台的调试页面 上传到平台上 un…...

棒球省队建设实施办法·棒球1号位
棒球省队建设实施办法 1. 建设目标与原则 提升棒球省队整体竞技水平 为了提升棒球省队整体竞技水平,我们需要采取一系列有效的措施。 首先,我们应该加强对棒球运动的投入和关注。各级政府和相关部门应加大对棒球运动的经费投入,提高球队的…...

架构案例2017(五十二)
第5题 阅读以下关于Web系统架构设计的叙述,在答题纸上回答问题1至问题3.【说明】某电子商务企业因发展良好,客户量逐步增大,企业业务不断扩充,导致其原有的B2C商品交易平台己不能满足现有业务需求。因此,该企业委托某…...

给四个点坐标计算两条直线的交点
文章目录 1 chatgpt42、文心一言3、星火4、Bard总结 我使用Chatgpt4和文心一言、科大讯飞星火、google Bard 对该问题进行搜索,分别给出答案。先说结论,是chatgpt4和文心一言给对了答案, 另外两个部分正确。 问题是:python 给定四…...

从入门到进阶 之 ElasticSearch SpringData 继承篇
🌹 以上分享 从入门到进阶 之 ElasticSearch SpringData 继承篇,如有问题请指教写。🌹🌹 如你对技术也感兴趣,欢迎交流。🌹🌹🌹 如有需要,请👍点赞…...
中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例
中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例 中文编程开发语言工具编程案例:计时计费管理系统软件连接灯控器编程案例 中文编程系统化教程,不需英语基础。学习链接 https://edu.csdn.net/course/detail/39036...

YOLOv7改进:动态蛇形卷积(Dynamic Snake Convolution),增强细微特征对小目标友好,实现涨点 | ICCV2023
💡💡💡本文独家改进:动态蛇形卷积(Dynamic Snake Convolution),增强细长微弱的局部结构特征与复杂多变的全局形态特征,对小目标检测很适用 Dynamic Snake Convolution | 亲测在多个数据集能够实现大幅涨点 收录: YOLOv7高阶自研专栏介绍: http://t.csdnimg.…...

从文心大模型4.0与FuncGPT:用AI为开发者打开新视界
今天,在百度2023世界大会上,文心大模型4.0正式发布,而在大洋的彼岸,因为大模型代表ChatGPT之类的AI编码工具来势汹汹,作为全世界每个开发者最爱的代码辅助网站,Stack Overflow的CEO Prashanth Chandrasekar…...
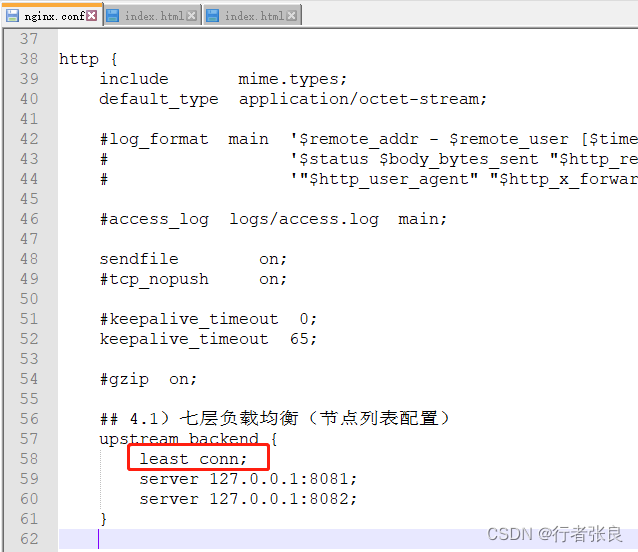
Nginx集群负载均衡配置完整流程
今天,良哥带你来做一个nginx集群的负载均衡配置的完整流程。 一、准备工作 本次搭建的操作系统环境是win11,linux可配置类同。 1)首先,下载nginx。 下载地址为:http://nginx.org/en/download.html 良哥下载的是&am…...

Linux文本管道效率稳定性治理方法
Linux文本管道效率稳定性治理方法这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在文本管道效率,重点讨论管道组合、文本过滤和执行开销。在真实生产环境中,文本管道效率相关问题往往不会以单一错误形式出现,而是混杂在日志、…...
首次实践)
中华民族站起来了,《AI驱动上下五千年:从结绳记事到智能纪元》第三章:周礼分封——面向服务的架构(SOA)首次实践
第三章:周礼分封——面向服务的架构(SOA)首次实践 1.历史现场:周公的架构革命 时间:公元前1046年,周朝建立之初地点:镐京(今西安)明堂人物:周公旦、各诸侯国君…...

从官方例程到实战:剖析lwip+FreeRTOS在Zynq7020上的TCP热拔插实现与任务调度优化
1. 官方例程热拔插实现机制拆解 第一次在Zynq7020上看到TCP热拔插功能时,确实让我这个老嵌入式工程师也眼前一亮。官方例程里那个看似简单的link_detect_thread任务,实际上藏着不少精妙设计。我们先从PHY芯片的状态检测说起——这个看似基础的操作&#…...

【免费下载】 让您的无线网络更稳定:Realtek 8188GU 无线网卡驱动推荐
让您的无线网络更稳定:Realtek 8188GU 无线网卡驱动推荐 【下载地址】Realtek8188GU无线网卡驱动 本仓库提供适用于Windows系统的Realtek 8188GU无线网卡驱动程序。该驱动程序旨在帮助用户解决无线网卡无法正常工作的问题,确保您的设备能够稳定连接到无线…...

STM32F108C8T6小白入门特训营__1.4GPIO.C 代码分析
目录 1.只需要搞明白 cubemx 跟 代码对应关系就可以了 2.GPIO.C 代码加上注释 3.注意引脚的宏定义 1.只需要搞明白 cubemx 跟 代码对应关系就可以了 2.GPIO.C 代码加上注释 读懂注释部分代码即可 /* USER CODE BEGIN Header */ /*****************************************…...

不只是CT重建:手把手教你用RTK+ITK+VS2022搭建可扩展的医学影像处理开发环境
构建医学影像算法开发平台:RTKITKVS2022全流程实战指南 医学影像处理领域正迎来前所未有的技术革新,从传统的CT重建到三维可视化、病灶自动检测等高级应用,开发者需要一套稳定且可扩展的开发环境。本文将带您从零开始,在Windows平…...

从Typora迁移到Obsidian,我踩过的那些坑和高效配置方案
从Typora迁移到Obsidian:无缝过渡的深度实践指南 当我在2022年决定将积累了5年的技术笔记库从Typora迁移到Obsidian时,最初以为只是换个编辑器那么简单。直到实际操作时才发现,这两个看似相似的Markdown工具在使用哲学和操作细节上存在诸多差…...

【软考高级架构】论文范文20——论软件设计方法及其应用
论软件设计方法及其应用 摘要 软件设计是将需求分析结果转换为软件体系结构和内部实现细节的关键活动,设计方法的选择直接影响系统的可维护性、可扩展性和开发效率。结构化设计、面向对象设计、数据驱动设计等经典方法各有侧重,在不同场景下展现出独特的优势。本文以笔者主…...

3分钟终极解决方案:一键将XAPK文件高效转换为通用APK
3分钟终极解决方案:一键将XAPK文件高效转换为通用APK 【免费下载链接】xapk-to-apk A simple standalone python script that converts .xapk file into a normal universal .apk file 项目地址: https://gitcode.com/gh_mirrors/xa/xapk-to-apk 还在为安卓设…...

数字电路模块化设计的艺术:Logisim-evolution中的层次化抽象实践
数字电路模块化设计的艺术:Logisim-evolution中的层次化抽象实践 【免费下载链接】logisim-evolution Digital logic design tool and simulator 项目地址: https://gitcode.com/gh_mirrors/lo/logisim-evolution 在数字电路设计的世界里,复杂系统…...