【计组】内存和总线
课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间
一、虚拟内存和内存保护
日常使用的操作系统下,程序不能直接访问物理内存。内存需要被分成固定大小的页(Page),再通过虚拟内存地址(Virtual Address)到物理内存地址(Physical Address)的地址转换(Address Translation),才能到达实际存放数据的物理内存位置。而程序看到的内存地址,都是虚拟内存地址。
(一)简单页表
想要把虚拟内存地址映射到物理内存地址,最直观的办法就是来建一张映射表。这个映射表,能够实现虚拟内存里面的页到物理内存里面的页的一 一映射。这个映射表,在计算机里面,就叫作页表(Page Table)。页表会把一个内存地址分成页号(Directory)和偏移量(Offset)两个部分。
做地址转换的页表,只需要保留虚拟内存地址的页号和物理内存地址的页号之间的映射关系就可以了。同一个页里面的内存,在物理层面是连续的。
对于一个内存地址转换,其实就是这样三个步骤:
- 把虚拟内存地址,切分成页号和偏移量的组合;
- 从页表里查询出虚拟页号对应的物理页号;
- 拿物理页号加上前面的偏移量,得到物理内存地址。
每一个进程,都有属于自己独立的虚拟内存地址空间,也就意味着,每一个进程都需要这样一个页表。
(二)多级页表
在整个进程的内存地址空间,通常是“两头实、中间空”。在程序运行的时候,内存地址从顶部往下,不断分配占用的栈的空间。而堆的空间,内存地址则是从底部往上,是不断分配占用的。
所以,在一个实际的程序进程里面,虚拟内存占用的地址空间,通常是两段连续的空间。而不是完全散落的随机的内存地址。而多级页表,就特别适合这样的内存地址分布。
以一个 4 级的多级页表为例,同样一个虚拟内存地址,偏移量的部分和简单页表一样不变,但是页号部分拆成四段,从高到低,分成 4 级到 1 级这样 4 个页表索引。
对应的,一个进程会有一个 4 级页表。 4 级页表里面存放的是每张 3 级页表所在的位置。3级表指向二级表,二级表指向一级表。

我们可能有很多张 1 级页表、2 级页表,乃至 3 级页表。但是,因为实际的虚拟内存空间通常是连续的,所以可能只需要很少的 2 级页表,甚至只需要 1 张 3 级页表就够了。
事实上,多级页表就像一个多叉树的数据结构,所以我们常常称它为页表树(Page Table Tree)。因为虚拟内存地址分布的连续性,树的第一层节点的指针,很多就是空的,也就不需要有对应的子树了。所谓不需要子树,其实就是不需要对应的 2 级、3 级的页表。找到最终的物理页号,就好像通过一个特定的访问路径,走到树最底层的叶子节点。
大部分进程所占用的内存是有限的,需要的页也自然是很有限的,只需要去存那些用到的页之间的映射关系就好了。
多级页表虽然节约了存储空间,却带来了时间上的开销,所以它其实是一个“以时间换空间”的策略。原本进行一次地址转换,只需要访问一次内存就能找到物理页号,算出物理内存地址。但是,用了 4 级页表,就需要访问 4 次内存,才能找到物理页号了。
二、解析TLB和内存保护
(一)加速地址转换:TLB
机器指令里面的内存地址都是虚拟内存地址。程序里面的每一个进程,都有一个属于自己的虚拟内存地址空间。可以通过地址转换来获得最终的实际物理地址。每一个指令和数据都存放在内存里面因此,“地址转换”是一个非常高频的动作,“地址转换”的性能至关重要。
从虚拟内存地址到物理内存地址的转换通过页表来处理。为了节约页表的内存存储空间,我们会使用多级页表数据结构。这就需要多次访问内存,然而,内存访问比 Cache 要慢很多,为了提高性能,可以采用加个"加个缓存"的方法。
程序使用的指令,存放和执行都是顺序进行的。也就是说,对于指令地址的访问,存在“空间局部性”和“时间局部性”,而需要访问的数据也是一样的。连续执行的几条指令通常存放在同一个"虚拟页"里,转换的结果自然也就是同一个物理页号。那就可以用“加个缓存”的办法把之前的内存转换地址缓存下来。这样就不用反复去访问内存来进行内存地址转换了。
于是,计算机工程师们专门在 CPU 里放了一块缓存芯片。这块缓存芯片我们称之为 TLB,全称是地址变换高速缓冲(Translation-Lookaside Buffer)。这块缓存存放了之前已经进行过地址转换的查询结果。这样,当同样的虚拟地址需要进行地址转换的时候,就可以直接在 TLB 里面查询结果了。
TLB 和我们前面讲的 CPU 的高速缓存类似,可以分成指令的 TLB 和数据的 TLB,也就是 ITLB 和 DTLB。同样的,也可以根据大小对它进行分级,变成 L1、L2 这样多层的 TLB。
除此之外,和 CPU 里的高速缓存一样,它也需要用脏标记这样的标记位,来实现“写回”缓存管理策略。
为了性能,整个内存转换过程都由硬件来执行。 CPU 芯片里封装了内存管理单元(MMU,Memory Management Unit)芯片,用来完成地址转换。和 TLB 的访问和交互,都是由这个 MMU 控制的。
(二)安全性与内存保护
指令、数据都存放在内存里,如果被人修改了内存里的内容, CPU 就可能会去执行计划之外的指令。这个指令可能是破坏服务器里面的数据,也可能是被人获取到服务器里面的敏感信息。
虽然现代的操作系统和 CPU已经做了各种权限的管控。正常情况下,已经通过虚拟内存地址和物理内存地址的区分,隔离了各个进程。但是难免还是存在一些漏洞。在对于内存的管理里面,计算机有一些最底层的安全保护机制。这些机制统称为内存保护(Memory Protection)。
内存层面的安全保护核心策略,是在可能有漏洞的情况下进行安全预防。
1、可执行空间保护
可执行空间保护(Executable Space Protection)是说,对于一个进程使用的内存,只把其中指令部分设置成“可执行”的,对于其他部分,比如数据部分,不给予“可执行”的权限。因为无论是指令,还是数据,在 CPU 看来,都是二进制的数据,直接把数据部分拿给 CPU,如果这些数据解码后,也能变成一条合理的指令,那也是可执行的。
对进程里内存空间的执行权限进行控制,可以使得 CPU 只能执行指令区域的代码。对于数据区域的内容,即使找到了其他漏洞想要加载成指令来执行,也会因为没有权限而被阻挡掉。
2、地址空间布局随机化
地址空间布局随机化(Address Space Layout Randomization)。原先一个进程的内存布局空间是固定的,所以第三方很容易知道指令在哪里,程序栈在哪里,数据在哪里,堆又在哪里。而地址空间布局随机化这个机制,就是让这些区域的位置不再固定,在内存空间随机去分配这些进程里不同部分所在的内存空间地址,让破坏者猜不出来。猜不出来呢,就没法找到想要修改的内容的位置。如果只是随便做点修改,程序只会 crash 掉,而不会去执行计划之外的代码。
三、总线
(一)总线的设计思路
计算机里其实有很多不同的硬件设备,除了 CPU 和内存之外,还有大量的输入输出设备。可以说,计算机上的每一个接口,键盘、鼠标、显示器、硬盘,乃至通过 USB 接口连接的各种外部设备,都对应了一个设备或者模块。
如果各个设备间的通信,都是单独进行的,每一个设备或者功能电路模块,都要和其他 N−1 个设备去通信,那么, N 个不同的设备,系统复杂度就会变成 ![]() 。总线是为了简化复杂度而引入的,它把
。总线是为了简化复杂度而引入的,它把 ![]() 的复杂度,变成了 N 。
的复杂度,变成了 N 。
对应的设计思路,在软件开发中也是非常常见的,譬如事件总线(Event Bus)的设计模式。
【延申阅读】设计模式:事件总线 - DZone
在事件总线这个设计模式里,各个模块触发对应的事件,并把事件对象发送到总线上。也就是说,每个模块都是一个发布者(Publisher)。而各个模块也会把自己注册到总线上,去监听总线上的事件,并根据事件的对象类型或者是对象内容,来决定自己是否要进行特定的处理或者响应。
这样的设计下,注册在总线上的各个模块就是松耦合的。模块互相之间并没有依赖关系。无论代码的维护,还是未来的扩展,都会很方便。
(二)三种线路和多总线架构
现代的 Intel CPU 的体系结构里面,通常有好几条总线。
首先,CPU 和内存以及高速缓存通信的总线,这里面通常有两种总线。这种方式,叫作双独立总线(Dual Independent Bus,缩写为 DIB)。CPU 里,有一个高速的本地总线(Local Bus),也叫后端总线(Back-side Bus),是用来和高速缓存通信的;还有一个速度相对较慢的前端总线(Front-side Bus),处理器总线(Processor Bus)、内存总线(Memory Bus),是用来和主内存以及输入输出设备通信的。
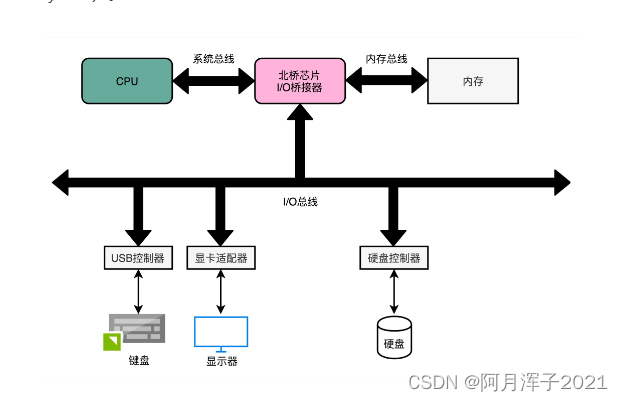
前端总线其实就是系统总线。CPU 里面的内存接口,直接和系统总线通信,然后系统总线再接入一个 I/O 桥接器(I/O Bridge)。 I/O 桥接器的另一边接入内存总线,使CPU 和内存通信。
在物理层面,其实完全可以把总线看作一组“电线”。这些电线之间是有分工的,通常有三类线路:
- 数据线(Data Bus),用来传输实际的数据信息。
- 地址线(Address Bus),用来确定到底把数据传输到哪里去,是内存的某个位置,还是某一个 I/O 设备。
- 控制线(Control Bus),用来控制对于总线的访问。
总线减少了设备之间的耦合,也降低了系统设计的复杂度,但同时也带来了一个新问题,那就是总线不能同时给多个设备提供通信功能。
课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间
相关文章:
【计组】内存和总线
课程链接:深入浅出计算机组成原理_组成原理_计算机基础-极客时间 一、虚拟内存和内存保护 日常使用的操作系统下,程序不能直接访问物理内存。内存需要被分成固定大小的页(Page),再通过虚拟内存地址(Virtu…...

CUDA中的数学方法
CUDA中的数学方法 文章目录CUDA中的数学方法1. Standard FunctionsSingle-Precision Floating-Point FunctionsDouble-Precision Floating-Point Functions2. Intrinsic FunctionsSingle-Precision Floating-Point FunctionsDouble-Precision Floating-Point Functions参考手册…...
Elasticsearch基本概念和索引原理
一、Elasticsearch是什么? Elasticsearch是一个基于文档的NoSQL数据库,是一个分布式、RESTful风格的搜索和数据分析引擎,同时也是Elastic Stack的核心,集中存储数据。Elasticsearch、Logstash、Kibana经常被用作日志分析系统&…...

《NFL橄榄球》:堪萨斯城酋长·橄榄1号位
堪萨斯城酋长队(Kansas City Chiefs)是位于密苏里州堪萨斯城的职业美式橄榄球队;目前在全国橄榄球联盟隶属于美国橄榄球联合会(AFC)西区;其夏季训练营在威斯康星大学河瀑校区举行。 酋长队的前身是达拉斯得州佬队,这支…...
python+django在线教学网上授课系统vue
随着科技的进步,互联网已经开始慢慢渗透到我们的生活和学习中,并且在各个领域占据着越来越重要的部分,很多传统的行业都将面临着巨大的挑战,包括学习也不例外。现在学习竞争越来越激烈,人才的需求量越来越大࿰…...
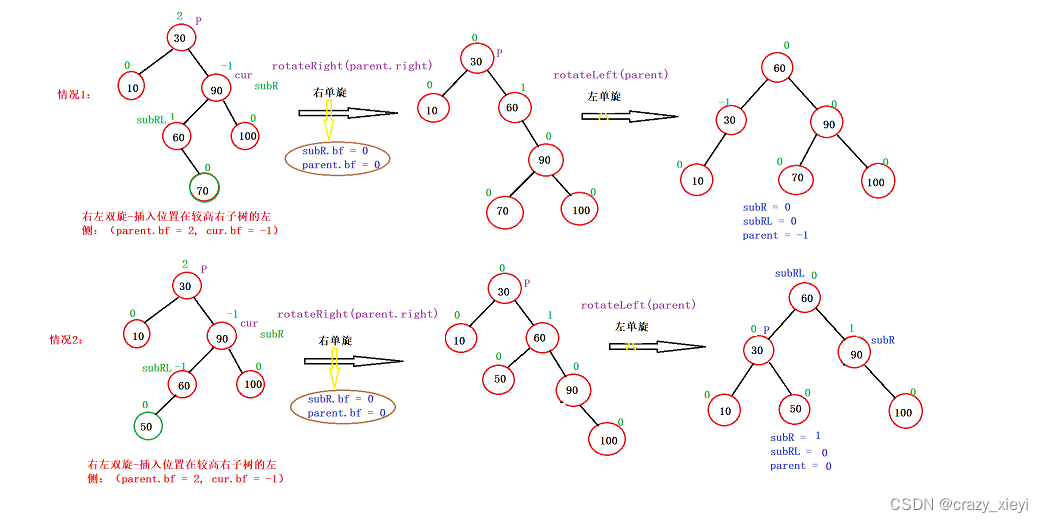
二叉搜索树之AVL树
AVL树的概念二叉搜索树虽可以缩短查找的效率,但如果数据有序或接近有序二叉搜索树将退化为单支树,查找元素相当于在顺序表中搜索元素,效率低下。因此,两位俄罗斯的数学家G.M.Adelson-Velskii和E.M.Landis在1962年 发明了一种解决上…...

全栈自动化测试技术笔记(二):准备工作的切入点
自动化测试技术笔记(二):准备工作的切入点 上篇整理的技术笔记,聊了自动化测试的前期调研工作如何开展,最后一部分也提到了工作的优先级区分。 这篇文章,接上篇文章的内容,来聊聊自动化测试前期的准备工作࿰…...
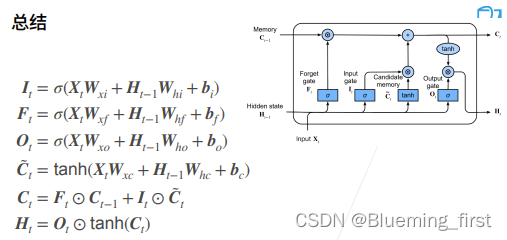
57 长短期记忆网络(LSTM)【动手学深度学习v2】
57 长短期记忆网络(LSTM)【动手学深度学习v2】 深度学习学习笔记 学习视频:https://www.bilibili.com/video/BV1JU4y1H7PC/?spm_id_fromautoNext&vd_source75dce036dc8244310435eaf03de4e330 长短期记忆网络(LSTM)…...
算法第十五期——动态规划(DP)之各种背包问题
目录 0、背包问题分类 1、 0/1背包简化版 【代码】 2、0/ 1背包的方案数 【思路】 【做法】 【代码】 空间优化1:交替滚动 空间优化2:自我滚动 3、完全背包 【思路】 【代码】 4、分组背包 核心代码 5、多重背包 多重背包解题思路1:转化…...
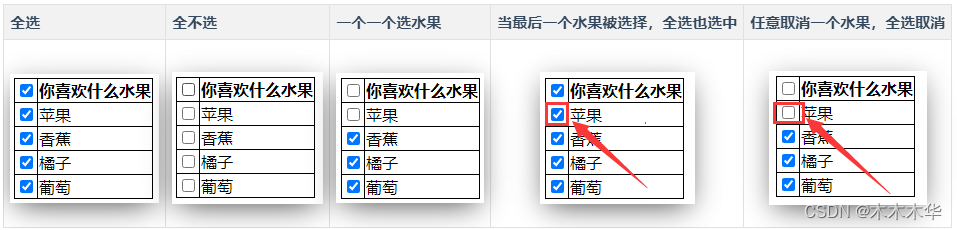
实现复选框全选和全不选的切换
今天,复看了一下JS的菜鸟教程,发现评论里面都是精华呀!! 看到函数这一节,发现就复选框的全选和全不选功能展开了讨论。我感觉挺有意思的,尝试实现了一下。 1. 全选、全不选,两个按钮ÿ…...
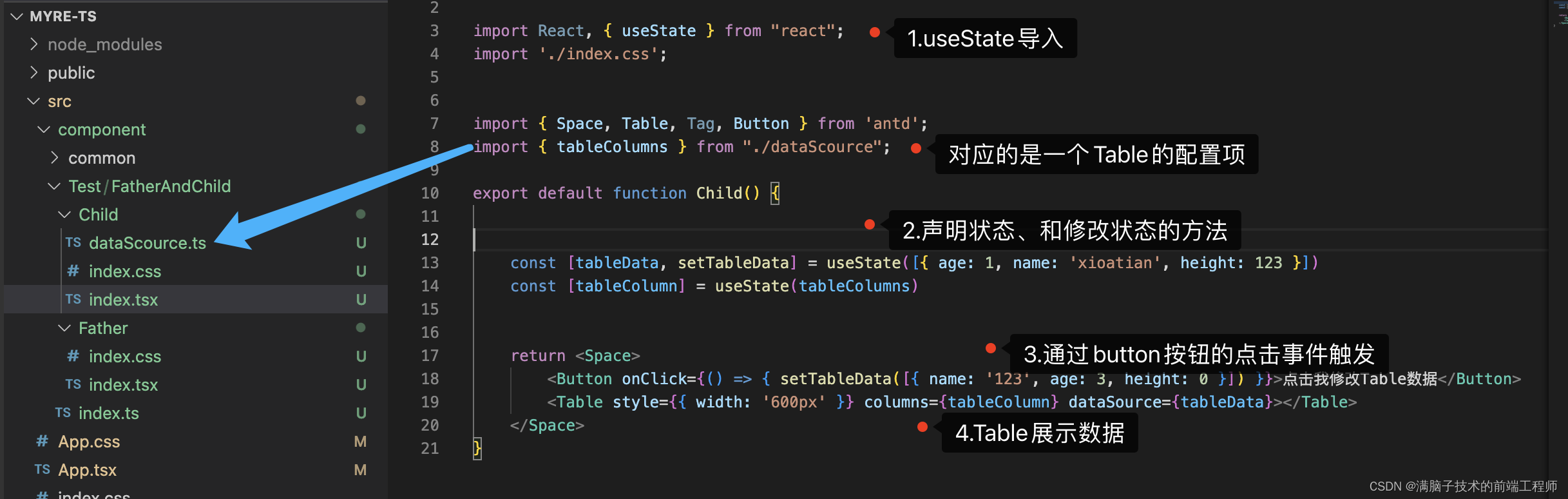
React hooks之useState用法(一)
系列文章目录 学习React已经有很长的一段时间了,今天决定重新回顾一下跟React相关的一些知识点 文章目录系列文章目录结构如下一、hooks是什么?useState可以能做什么二、如何使用useState()第一步:创建【函数组件&…...
spring的简单理解
目录 1 .ioc容器(控制反转) 2. Aop面向切面编程 3. 事务申明 4. 注解的方式启动 5. spring是什么与他的优势 6. 代理设计模式(比如aop) 7. springmvc中相应json数据 8. 使用lombok来进行对代码的简化 9. 使用logback记录…...
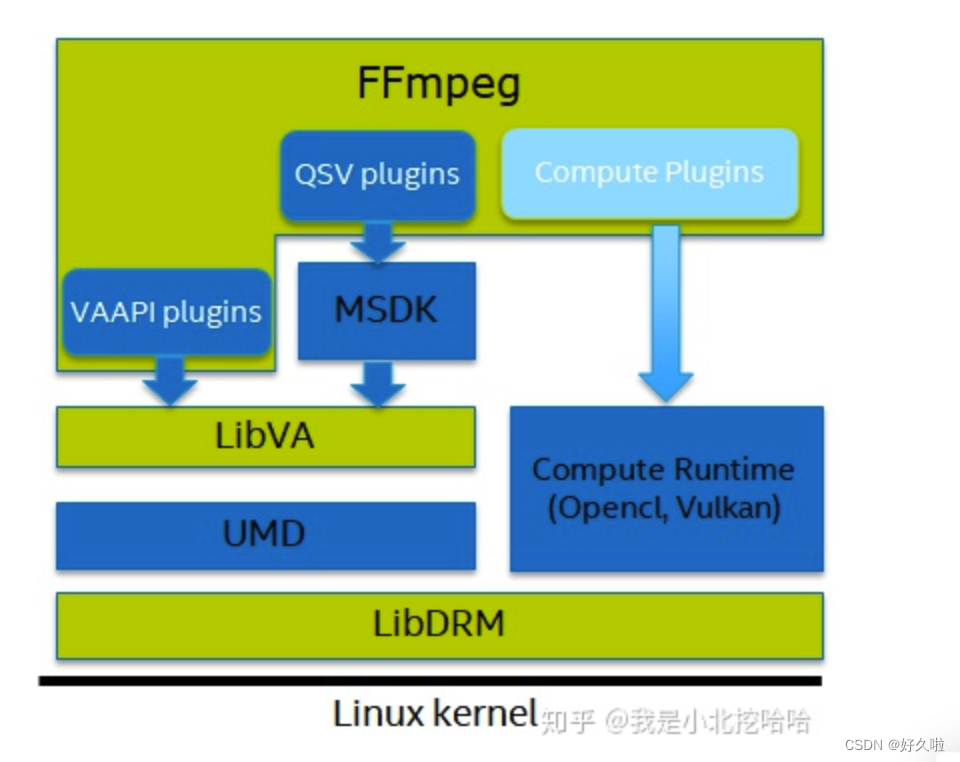
Docker调用Intel集显实现FFmpeg硬解码
文章目录Docker调用Intel集显实现FFmpeg硬解码参考FFmpeg 集成qsv方式一 容器完成所有步骤方式二 容器完成部分步骤方式三 dockerfile部署Docker调用Intel集显实现FFmpeg硬解码 参考 ffmpeg_qsv_docker拉取该镜像可以实现FFmpeg集成vaapi的硬加速,通过dockerfile文…...

端到端模型(end-to-end)与非端到端模型
一、端到端(end to end) 从输入端到输出端会得到一个预测结果,将预测结果和真实结果进行比较得到误差,将误差反向传播到网络的各个层之中,调整网络的权重和参数直到模型收敛或者达到预期的效果为止,中间所…...
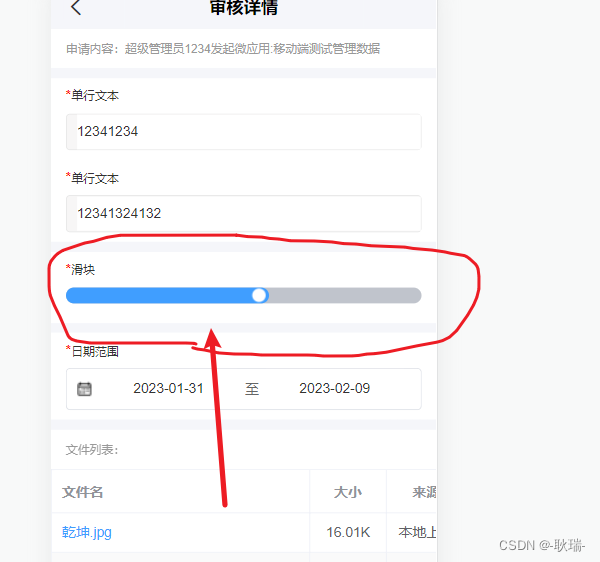
uniApp封装一个滑块组件
最近 项目中有一个需求 PC端动态设计的表单 移动端要能渲染出来 那么 就要去找到对应的组件 而其中 没有的 就包括滑块 没有又能怎么办 只能自己封装一个 我们直接上代码 <template><view class"u-slider" tap"onClick" :class"[disabled…...

运动基元(二):贝塞尔曲线
贝塞尔曲线是我第一个深入接触并使用于路径规划的运动基元。N阶贝塞尔曲线具有很多优良的特性,例如端点性、N阶可导性、对称性、曲率连续性、凸包性、几何不变性、仿射不变性以及变差缩减性。本章主要介绍贝塞尔曲线用于运动基元时几个特别有用的特性。 一、贝塞尔曲线的定义 …...

Android 11.0 关于Launcher3中调用截图功能总是返回null的解决方案
1.1概述 在11.0的系统产品开发中,在某些时候需要调用截图接口来进行截屏功能实现,而在Launcher3中发现调用系统截屏接口SurfaceControl.screenshot进行截图的时候始终为null, 获取不到系统当前页面的截屏功能,所以需要找到当前截屏失败的原因然后来实现截屏功能的实现,下面来…...

random随机数
random随机数 1.概述 random用来生成一些随机数,下面介绍random模块提供的方法根据需求生成不同的随机数。 2.random常用操作 2.1.random默认随机数 random()函数返回一个随机的浮点值,默认返回值范围在0 < n < 1.0区间 import randomfor i …...
【金三银四系列】Spring面试题-上(2023版)
Spring面试专题 1.Spring应该很熟悉吧?来介绍下你的Spring的理解 有些同学可能会抢答,不熟悉!!! 好了,不开玩笑,面对这个问题我们应该怎么来回答呢?我们给大家梳理这个几个维度来回答 1.1 Spring的发展历程 先介绍…...

linux基本功系列之tar命令实战
文章目录前言一. tar命令介绍二. 语法格式及常用选项三. 参考案例3.1 仅打包不压缩3.2 打包后使用调用压缩命令进行压缩3.3 列出文件的内容3.4 追加文件到tar命令中3.5 释放文件到指定的目录四 . 各种压缩方式的比较总结前言 大家好,又见面了,我是沐风晓…...

【ChatGPT SEO写作黄金法则】:20年SEO专家亲授7大不可绕过的AI内容合规红线
更多请点击: https://kaifayun.com 第一章:ChatGPT SEO写作的底层逻辑与合规本质 ChatGPT SEO写作并非简单地将关键词堆砌进AI生成文本,其底层逻辑建立在三重耦合关系之上:搜索引擎语义理解机制、用户真实搜索意图建模࿰…...

五分钟完成Taotoken的Python SDK配置并调用多模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 五分钟完成Taotoken的Python SDK配置并调用多模型 基础教程类,面向刚注册Taotoken的Python开发者,指导其完…...

如何利用Taotoken模型广场为你的项目选择最合适的大模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何利用Taotoken模型广场为你的项目选择最合适的大模型 当你的项目需要集成大模型能力时,面对市场上众多的模型提供商…...

别再死磕SAR ADC了!聊聊那些被低估的‘算法ADC’与‘流水线ADC’实战选型心得
算法ADC与流水线ADC实战选型指南:突破SAR ADC的思维定式 在嵌入式系统与传感器信号链设计中,模数转换器(ADC)的选择往往直接决定整个系统的性能天花板。当工程师们面对"高精度低速"、"中速中精度"和"高速高动态范围"等不同…...

从“能听见”到“听得清”:一款高集成度AI语音处理模组的落地实践
在嵌入式产品开发中,语音交互功能的开发往往是一个“隐形的坑”。很多团队在Demo阶段用普通麦克风和喇叭一切正常,一到真实环境就问题百出:空调噪音盖过人声、对方听到刺耳的回声、音量开大就爆麦。一、产品定位:解决什么痛点&…...

vscode+stm32+embedded ide+cortex debug+gcc
用stm32cubemx生成项目。下载三个软件,设置环境变量 openocd是仿真用,gcc-arm-none-eabi-10.3是编译用,w64evkit只用其中的make.exe根据生成的makefile文件,添加c源文件,包含目录,startup文件&#…...

【DeepSeek事实准确性测试权威报告】:2024年7大维度实测数据揭穿幻觉率真相
更多请点击: https://intelliparadigm.com 第一章:DeepSeek事实准确性测试权威报告总览 本报告基于2024年Q3由AI Safety Benchmark Consortium(ASBC)主导的跨模型事实一致性评估项目,对DeepSeek-V2、DeepSeek-Coder-3…...

凡亿AD最小系统板--元件模型组成介绍
一、课程整体概述原理图库创建是PCB设计流程的第二步核心工作,也是电子设计建模的源头工序。所有电路板上的电子元器件,都需要先在原理图库中绘制对应的电气模型,才能完成后续原理图绘制、封装匹配、PCB布局布线等操作。本系列课程将通过多类…...

观察Taotoken在多模型聚合调用时的路由与容错表现
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Taotoken在多模型聚合调用时的路由与容错表现 在构建依赖大模型能力的应用时,服务的稳定性是开发者关心的核心问题…...

安装 KubeSphere
安装 KubeSphere KubeSphere Core (ks-core) 是 KubeSphere 的核心组件,为扩展组件提供基础的运行环境。KubeSphere Core 安装完成后,即可访问 KubeSphere Web 控制台。 1. 安装 KubeSphere Core 在集群节点上,执行以下命令安装 KubeSpher…...