Hadoop3.0大数据处理学习3(MapReduce原理分析、日志归集、序列化机制、Yarn资源调度器)
MapReduce原理分析
什么是MapReduce
前言:如果想知道一堆牌中有多少张红桃,直接的方式是一张张的检查,并数出有多少张红桃。
而MapReduce的方法是,给所有的节点分配这堆牌,让每个节点计算自己手中有几张是红桃,然后将这个数汇总,得到结果。
概述
- 官方介绍:MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
- MapReduce是分布式运行的,由俩个阶段组成:Map和Reduce。
- MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()俩个函数,即可实现分布式计算。
原理分析
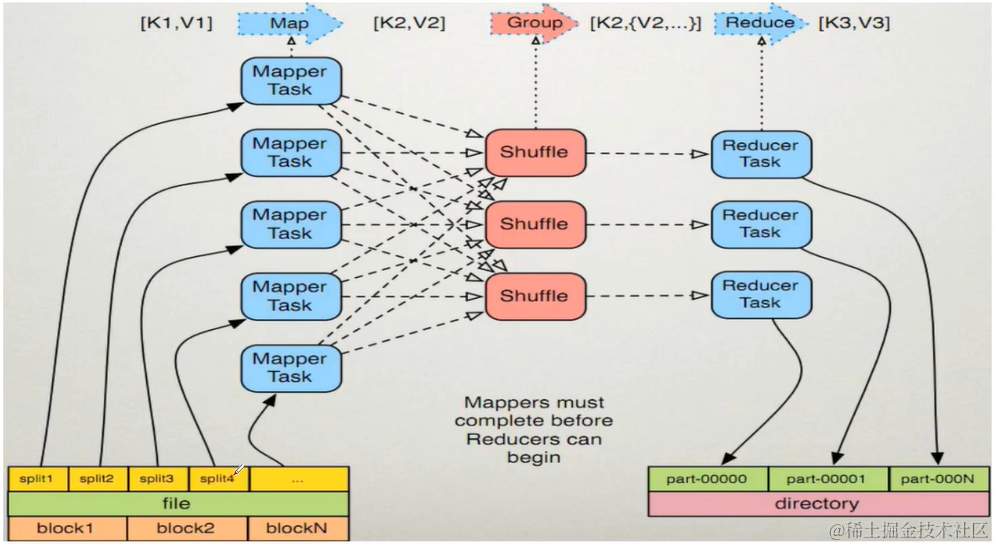
Map阶段执行过程
- 框架会把输入文件划分为很多InputSplit,默认每个hdfs的block对应一个InputSplit。通过RecordReader类,将每个InputSplit解析为一个个键值对<K1,V1>。默认每一个行会被解析成一个键值对。
- 框架会调用Mapper类中的map()函数,map函数的形参是<k1,v1>,输出是<k2,v2>。一个inputSplit对应一个map task。
- 框架对map函数输出的<k2,v2>进行分区。不同分区中的<k2,v2>由不同的reduce task处理,默认只有一个分区。
- 框架对每个分区中的数据,按照k2进行排序、分组。分组指的是相同k2的v2分为一组。
- 在map节点,框架可以执行reduce规约,此步骤为可选。
- 框架会把map task输出的<k2,v2>写入linux的磁盘文件
Reduce阶段执行过程
- 框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点,这个过程称为shuffle。
- 框架对reduce端接收到的相同分区的<k2,v2>数据进行合并、排序、分组
- 框架调用reduce类中的reduce方法,输入<k2,[v2…]>,输出<k3,v3>。一个<k2,[v2…]>调用一次reduce函数。
- 框架把reduce的输出保存到hdfs。
WordCount案例分析
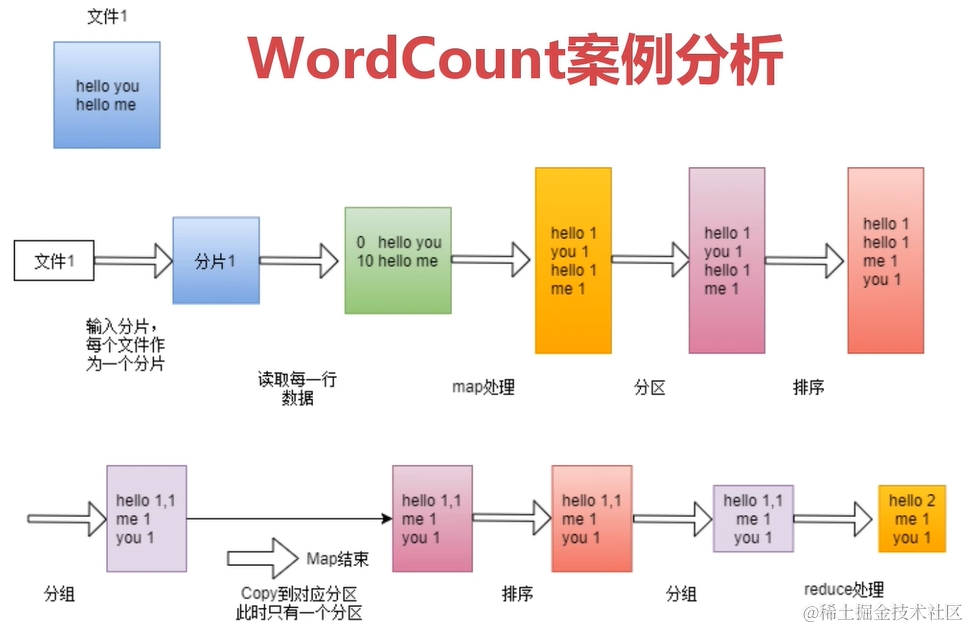
多文件WordCount案例分析
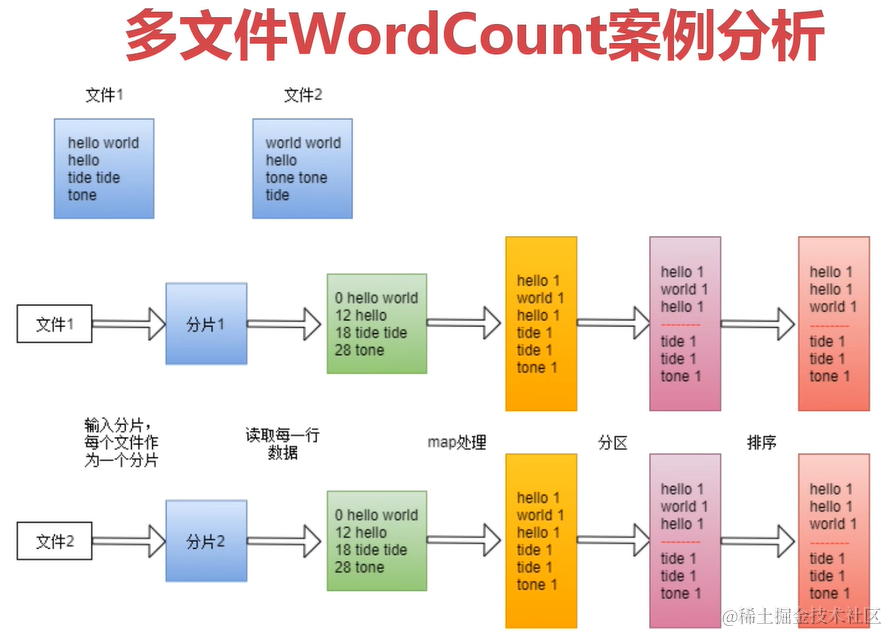
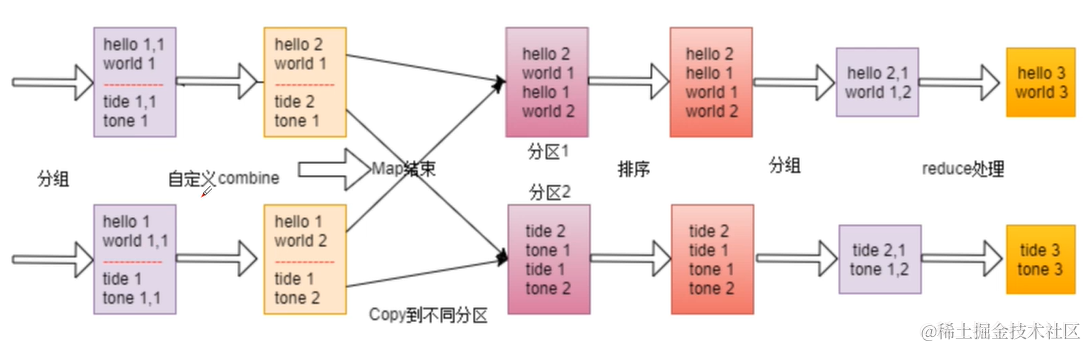
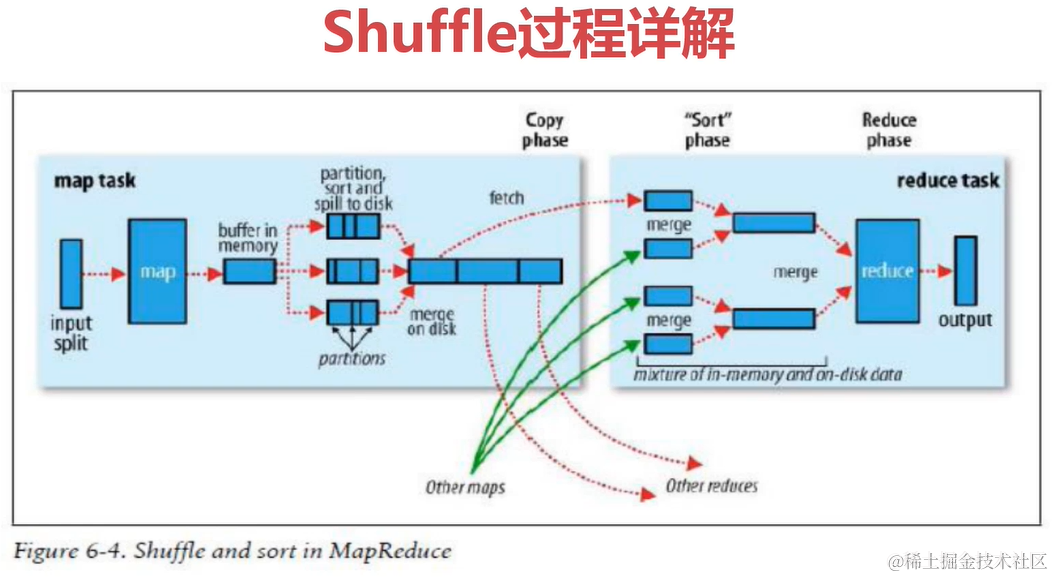
Shuffle过程详解
shuffle是一个过程,贯穿map和reduce,通过网络将map产生的数据放到reduce。
Map与Reduce的WordsCount案例(与日志查看)
引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.14</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.hx</groupId><artifactId>hadoopDemo1</artifactId><version>0.0.1-SNAPSHOT</version><name>hadoopDemo1</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.0</version><scope>provided</scope></dependency></dependencies>
</project>
编码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** @author Huathy* @date 2023-10-21 21:17* @description 组装任务*/
public class WordCountJob {public static void main(String[] args) throws Exception {System.out.println("inputPath => " + args[0]);System.out.println("outputPath => " + args[1]);String path = args[0];String path2 = args[1];// job需要的配置参数Configuration configuration = new Configuration();// 创建jobJob job = Job.getInstance(configuration, "wordCountJob");// 注意:这一行必须设置,否则在集群的时候将无法找到Job类job.setJarByClass(WordCountJob.class);// 指定输入文件FileInputFormat.setInputPaths(job, new Path(path));FileOutputFormat.setOutputPath(job, new Path(path2));job.setMapperClass(WordMap.class);job.setReducerClass(WordReduce.class);// 指定map相关配置job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);// 指定reducejob.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 提交任务job.waitForCompletion(true);}/*** @author Huathy* @date 2023-10-21 21:39* @description 创建自定义映射类* 定义输入输出类型*/public static class WordMap extends Mapper<LongWritable, Text, Text, LongWritable> {/*** 需要实现map函数* 这个map函数就是可以接受keyIn,valueIn,产生keyOut、ValueOut** @param k1* @param v1* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {// k1表示每行的行首偏移量,v1表示每一行的内容// 对获取到的每一行数据进行切割,把单词切割出来String[] words = v1.toString().split("\W");// 迭代切割的单词数据for (String word : words) {// 将迭代的单词封装为<k2,v2>的形式Text k2 = new Text(word);System.out.println("k2: " + k2.toString());LongWritable v2 = new LongWritable(1);// 将<k2,v2>输出context.write(k2, v2);}}}/*** @author Huathy* @date 2023-10-21 22:08* @description 自定义的reducer类*/public static class WordReduce extends Reducer<Text, LongWritable, Text, LongWritable> {/*** 针对v2s的数据进行累加求和,并且把最终的数据转为k3,v3输出** @param k2* @param v2s* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException {long sum = 0L;for (LongWritable v2 : v2s) {sum += v2.get();}// 组装K3,V3LongWritable v3 = new LongWritable(sum);System.out.println("k3: " + k2.toString() + " -- v3: " + v3.toString());context.write(k2, v3);}}}
运行命令与输出日志
[root@cent7-1 hadoop-3.2.4]# hadoop jar wc.jar WordCountJob hdfs://cent7-1:9000/hello.txt hdfs://cent7-1:9000/out /home/hadoop-3.2.4/wc.jar
inputPath => hdfs://cent7-1:9000/hello.txt
outputPath => hdfs://cent7-1:9000/out
set jar => /home/hadoop-3.2.4/wc.jar
2023-10-22 15:30:34,183 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2023-10-22 15:30:35,183 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2023-10-22 15:30:35,342 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1697944187818_0010
2023-10-22 15:30:36,196 INFO input.FileInputFormat: Total input files to process : 1
2023-10-22 15:30:37,320 INFO mapreduce.JobSubmitter: number of splits:1
2023-10-22 15:30:37,694 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1697944187818_0010
2023-10-22 15:30:37,696 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-10-22 15:30:38,033 INFO conf.Configuration: resource-types.xml not found
2023-10-22 15:30:38,034 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-10-22 15:30:38,188 INFO impl.YarnClientImpl: Submitted application application_1697944187818_0010
2023-10-22 15:30:38,248 INFO mapreduce.Job: The url to track the job: http://cent7-1:8088/proxy/application_1697944187818_0010/
2023-10-22 15:30:38,249 INFO mapreduce.Job: Running job: job_1697944187818_0010
2023-10-22 15:30:51,749 INFO mapreduce.Job: Job job_1697944187818_0010 running in uber mode : false
2023-10-22 15:30:51,751 INFO mapreduce.Job: map 0% reduce 0%
2023-10-22 15:30:59,254 INFO mapreduce.Job: map 100% reduce 0%
2023-10-22 15:31:08,410 INFO mapreduce.Job: map 100% reduce 100%
2023-10-22 15:31:09,447 INFO mapreduce.Job: Job job_1697944187818_0010 completed successfully
2023-10-22 15:31:09,578 INFO mapreduce.Job: Counters: 54File System CountersFILE: Number of bytes read=129FILE: Number of bytes written=479187FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=139HDFS: Number of bytes written=35HDFS: Number of read operations=8HDFS: Number of large read operations=0HDFS: Number of write operations=2HDFS: Number of bytes read erasure-coded=0Job Counters Launched map tasks=1Launched reduce tasks=1Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=4916Total time spent by all reduces in occupied slots (ms)=5821Total time spent by all map tasks (ms)=4916Total time spent by all reduce tasks (ms)=5821Total vcore-milliseconds taken by all map tasks=4916Total vcore-milliseconds taken by all reduce tasks=5821Total megabyte-milliseconds taken by all map tasks=5033984Total megabyte-milliseconds taken by all reduce tasks=5960704Map-Reduce FrameworkMap input records=4Map output records=8Map output bytes=107Map output materialized bytes=129Input split bytes=94Combine input records=0Combine output records=0Reduce input groups=5Reduce shuffle bytes=129Reduce input records=8Reduce output records=5Spilled Records=16Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=259CPU time spent (ms)=2990Physical memory (bytes) snapshot=528863232Virtual memory (bytes) snapshot=5158191104Total committed heap usage (bytes)=378011648Peak Map Physical memory (bytes)=325742592Peak Map Virtual memory (bytes)=2575839232Peak Reduce Physical memory (bytes)=203120640Peak Reduce Virtual memory (bytes)=2582351872Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=45File Output Format Counters Bytes Written=35
[root@cent7-1 hadoop-3.2.4]#
MapReduce任务日志查看
- 开启yarn日志聚合功能,将散落在nodemanager节点的日志统一收集管理,方便查看
- 修改yarn-site.xml中的yarn.log-aggregation-enable和yarn.log.server.url
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<property><name>yarn.log.server.url</name><value>http://cent7-1:19888/jobhistory/logs/</value>
</property>
- 启动historyserver:
sbin/mr-jobhistory-daemon.sh start historyserver
UI界面查看
-
访问 http://192.168.56.101:8088/cluster ,点击History
-
点进Successful
-
看到成功记录,点击logs可以看到成功日志
停止Hadoop集群中的任务
Ctrl+C退出终端,并不会结束任务,因为任务已经提交到了Hadoop
- 查看任务列表:
yarn application -list - 结束任务进程:
yarn application -kill [application_Id]
# 查看正在进行的任务列表
[root@cent7-1 hadoop-3.2.4]# yarn application -list
2023-10-22 16:18:38,756 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Total number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []):1Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1697961350721_0002 wordCountJob MAPREDUCE root default ACCEPTED UNDEFINED 0% N/A
# 结束任务
[root@cent7-1 hadoop-3.2.4]# yarn application -kill application_1697961350721_0002
2023-10-22 16:18:55,669 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Killing application application_1697961350721_0002
2023-10-22 16:18:56,795 INFO impl.YarnClientImpl: Killed application application_1697961350721_0002
Hadoop序列化机制
序列化机制作用
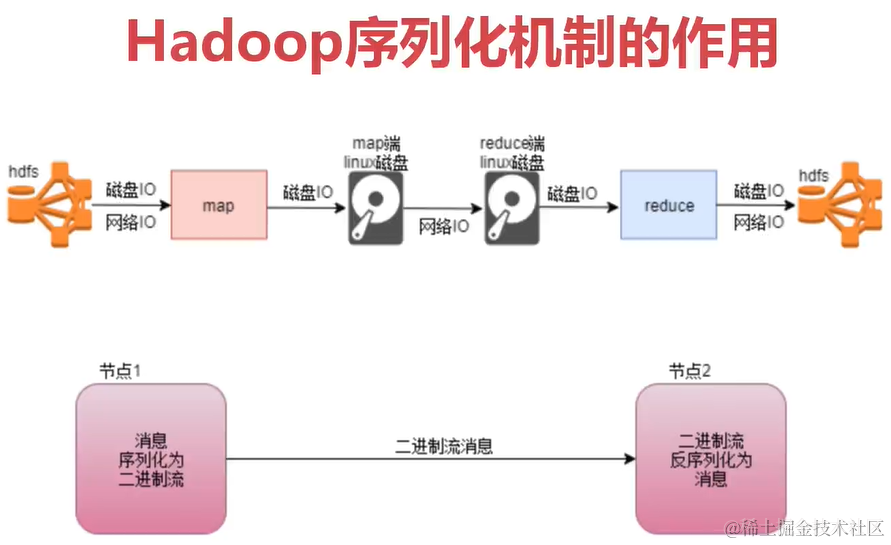
上面可以看出,Hadoop运行的时候大多数IO操作。我们在编写Hadoop的Map和Reduce代码的时候,用的都是Hadoop官方提供的数据类型,Hadoop官方对序列化做了优化,只会序列化核心内容来减少IO开销。
Hadoop序列化机制的特点
- 紧凑:高效的使用存储空间
- 快速:读写数据的额外开销小
- 可扩展:可透明的读取老格式的数据
- 互操作:支持多语言操作
Java序列化的不足
- 不够精简,附加信息多,不适合随机访问
- 存储空间占用大,递归输出类的父类描述,直到不再有父类
- 扩展性差,Hadoop中的Writable可以方便用户自定义
资源管理器(Yarn)详解
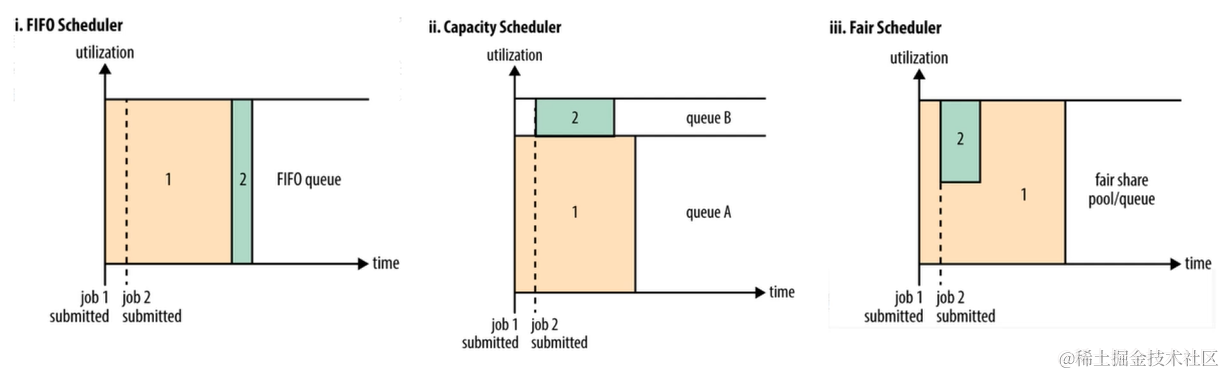
- Yarn目前支持三种调度器:(针对任务的调度器)
- FIFO Scheduler:先进先出调度策略(工作中存在实时任务和离线任务,先进先出可能不太适合业务)
- CapacityScheduler:可以看作是FIFO的多队列版本。可以分成多个队列,每个队列里面是先进先出的。
- FairScheduler:多队列,多用户共享资源。公平任务调度(建议使用)。
相关文章:
Hadoop3.0大数据处理学习3(MapReduce原理分析、日志归集、序列化机制、Yarn资源调度器)
MapReduce原理分析 什么是MapReduce 前言:如果想知道一堆牌中有多少张红桃,直接的方式是一张张的检查,并数出有多少张红桃。 而MapReduce的方法是,给所有的节点分配这堆牌,让每个节点计算自己手中有几张是红桃&#…...

JS DataTable中导出PDF中文乱码
JS DataTable中导出PDF中文乱码 文章目录 JS DataTable中导出PDF中文乱码一. 问题二. 原因三. vfs_fonts.js四. pdfmake.js五. 解决六.参考资料 一. 问题 二. 原因 DataTable使用pdfmake,pdfmake默认字体为Roboto,不支持中文字体。添加自己的字体&#…...
代码签名证书续费
代码签名证书的有效周期是1-3年,这种情况下证书到期了就要重新申请办理,最开始同样的申请验证步骤还要再走一遍,尤其是Ukey还是要CA机构重新颁发,还是要等待快递配送。OV代码签名证书、EV代码签名证书目前行业内统一采取Ukey存储&…...
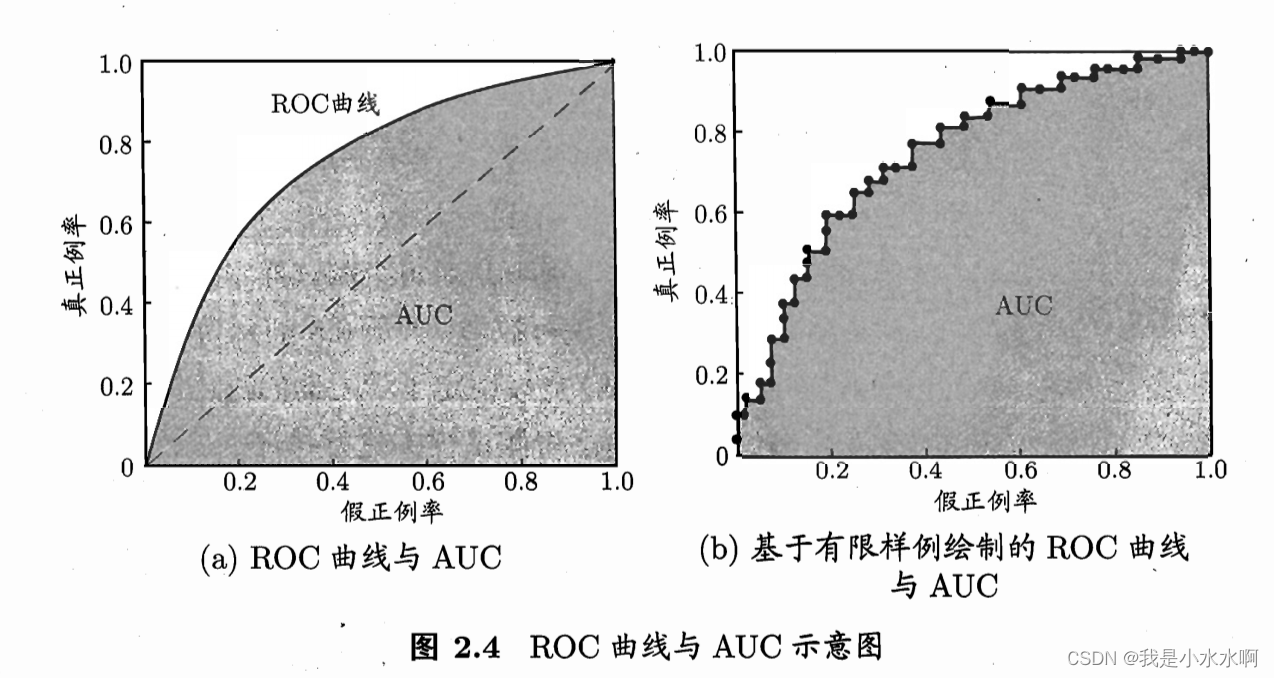
机器学习之ROC与AUC
文章目录 定义ROC曲线:AUC(Area Under the ROC Curve): 定义 ROC(Receiver Operating Characteristic)曲线和AUC(Area Under the ROC Curve)是用于评估二分类模型性能的重要工具。 …...
实用篇-Eureka注册中心
一、提供者与消费者 服务提供者:一次业务中,被其他微服务调用的服务。(提供接口给其他微服务) 服务消费者:一次业务中,调用其他微服务的服务。(调用其他微服务提供的接口) 例如前面的案例中,order-service微服务是服…...
基于springboot实现篮球竞赛预约平台管理系统项目【项目源码+论文说明】
基于springboot实现篮球竞赛预约平台管理系统演示 摘要 随着信息化时代的到来,管理系统都趋向于智能化、系统化,篮球竞赛预约平台也不例外,但目前国内仍都使用人工管理,市场规模越来越大,同时信息量也越来越庞大&…...
OpenHarmony docker环境搭建所见的问题和解决
【摘要】OpenHarmony docker环境搭建需要一台安装Ubuntu的虚拟机,并且虚拟机中需要有VScode。 整个搭建流程请参考这篇博客:OpenHarmony docker环境搭建-云社区-华为云 (huaweicloud.com) 上篇博主是用Ubuntu的服务器进行环境搭建的,在使用VS…...
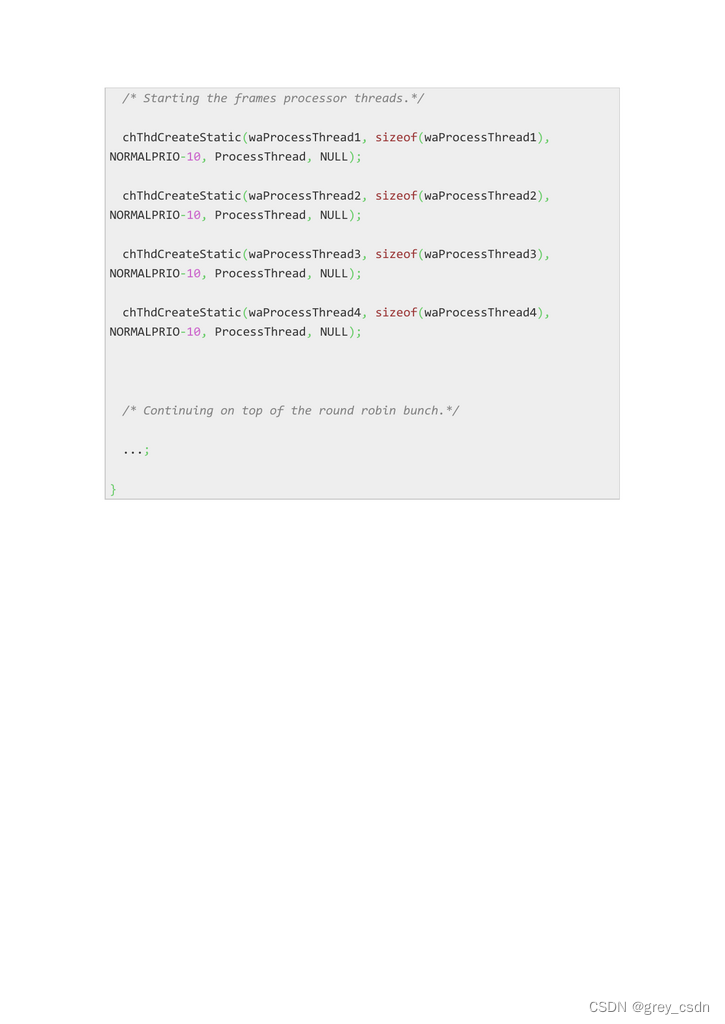
1817_ChibiOS的RT线程
全部学习汇总: GreyZhang/g_ChibiOS: I found a new RTOS called ChibiOS and it seems interesting! (github.com) 1. 关于线程,有几个概念需要弄清楚:声明、生命循环、延迟、线程引用、线程队列、线程时间、优先级管理、调度。 2. 两个声明…...

牛客网刷题-(7)
🌈write in front🌈 🧸大家好,我是Aileen🧸.希望你看完之后,能对你有所帮助,不足请指正!共同学习交流. 🆔本文由Aileen_0v0🧸 原创 CSDN首发🐒 如…...

多模态领域的先进模型
多模态学习领域涌现了许多先进的模型,这些模型能够处理来自不同感官模态的信息并实现多模态任务。以下是一些先进的多模态学习模型: CLIP (Contrastive Language-Image Pretraining):由OpenAI开发的CLIP是一种多模态预训练模型,能…...

列表自动向上滚动
列表自动向上滚动 鼠标放上去 自动停止滚动 <div id"list-detail-main"><div class"my_table_thead_tr"><div v-for"(item, index) in header" :key"index" class"my_table_thead_th">{{ item }}</div…...

嘴笨的技术人员怎么发言
对于嘴笨的人来说,即兴发言简直就是灾难,想想自己窘迫的模样,自己都受不了,但职场又避免不了这种场合,所以,就要靠一些技巧让我们顺利打开思路了。 那么,今天就分享几个解救过我的不同场景即兴发…...
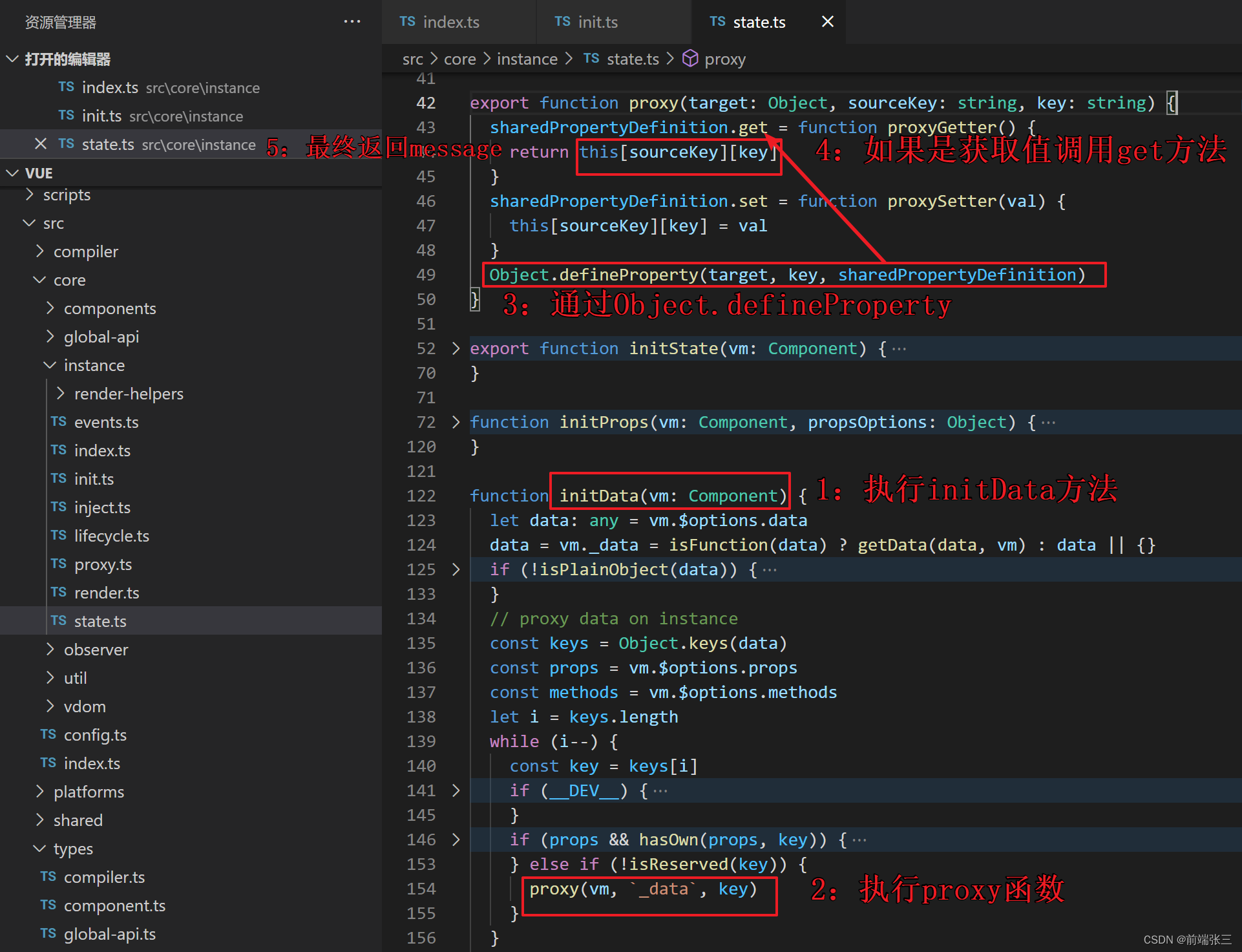
vue源码分析(三)——new Vue 的过程(详解data定义值后如何获取的过程)
文章目录 零、准备工作1.创建vue2项目2.修改main.js 一、import Vue from vue引入的vue是哪里来的(看导入node_modules包)1: 通过node_modules包的package.json文件2: 通过配置中的main入口文件进入开发环境的源码(1&a…...
软考系统架构师知识点集锦四:信息安全技术基础知识
一、考情分析 二、考点精讲 2.1信息加解密技术 2.1.1对称加密 概念:对称加密(又称为私人密钥加密/共享密钥加密) : 加密与解密使用同一密钥。特点:加密强度不高,但效率高;密钥分发困难。 (大量明文为了保证加密效率一般使用对称加密) 常见对称密钥加密算法:DES:…...

Vscode中不显示.ipynb文件单元格行号
找到设置,搜索line number: 看到下面那个Notebook: Line Numbers 控制单元格编辑器中行号的显示。,选择on即可;...
【Oracle】[INS-30131]执行安装程序验证所需的初始设置失败。
这里写目录标题 一、问题描述1 报错内容1.1 无法从节点“kotin”检索 exectask 的版本1.2 工作目录"xxx"无法在节点"kotin"上使用 2 相关环境2.1 安装软件2.2 安装系统 3 解决思路分析 二、解决方案1 方案一、 满足验证条件 - 不换系统1.1 第一步、检查文件…...

二进制部署kubernetes集群的推荐方式
软件版本: 软件版本containerdv1.6.5etcdv3.5.0kubernetesv1.24.0 一、系统环境 1.1 环境准备 角色IP服务k8s-master01192.168.10.10etcd、containerd、kube-apiserver、kube-scheduler、kube-controller-manager、kubele、kube-proxyk8s-node01后续etcd、conta…...

智能矩阵,引领商业新纪元!拓世方案:打破线上线下界限,开启无限营销可能!
在科技赋能商业大潮中,一切行业都在经历巨大变革,传统的营销策略被彻底改变,催生着无数企业去打造横跨线上线下、多维度、全方位的矩阵营销帝国。无数的成功案例已经告诉我们,营销不再只是宣传,而是建立品牌与消费者之…...
)
ADB原理(第四篇:聊聊adb shell ps与adb shell ps有无双引号的区别)
前言 对于经常使用adb的同学,不可避免的一定会这样用adb,比如我们想在手机里执行ps命令,于是在命令行中写下如下代码: adb shell ps -ef 或者 adb shell "ps -ef" 两种方式都可以使用,你喜欢用哪个呢&#…...
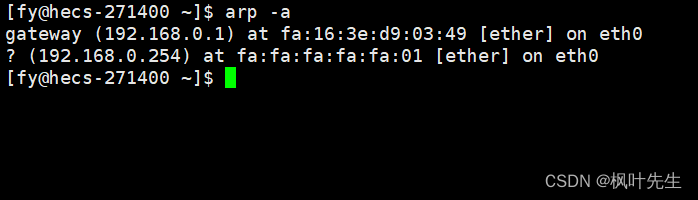
「网络编程」数据链路层协议_ 以太网协议学习
「前言」文章内容是数据链路层以太网协议的讲解。 「归属专栏」网络编程 「主页链接」个人主页 「笔者」枫叶先生(fy) 目录 一、以太网协议简介二、以太网帧格式(报头)三、MTU对上层协议的影响四、ARP协议4.1 ARP协议的作用4.2 ARP协议报头 一、以太网协…...

Windows多显示器DPI缩放终极解决方案:告别模糊显示,享受清晰视觉体验
Windows多显示器DPI缩放终极解决方案:告别模糊显示,享受清晰视觉体验 【免费下载链接】SetDPI 项目地址: https://gitcode.com/gh_mirrors/se/SetDPI 你是不是曾经遇到过这样的困扰?连接多个显示器时,文字和图标大小不一&…...

3大核心模块+5步实战:用RPFM彻底改变《全面战争》模组开发体验
3大核心模块5步实战:用RPFM彻底改变《全面战争》模组开发体验 【免费下载链接】rpfm Rusted PackFile Manager (RPFM) is a... reimplementation in Rust and Qt6 of PackFile Manager (PFM), one of the best modding tools for Total War Games. 项目地址: http…...

OpenPLC虚拟PLC:5分钟搭建开源工业控制器的完整指南
OpenPLC虚拟PLC:5分钟搭建开源工业控制器的完整指南 【免费下载链接】OpenPLC Software for the OpenPLC - an open source industrial controller 项目地址: https://gitcode.com/gh_mirrors/op/OpenPLC 想要零成本学习工业自动化?OpenPLC虚拟PL…...

2023B卷,最佳植树距离
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:华为OD面试 文章目录 一、🍀前言 1.1 ☘️题目详情 1.2 ☘️参考解题答案 一、🍀前言 2023B卷,最佳植树距离。 1.1 ☘️题目详情 题目: 小明在直…...

告别手动分类!用Python+ArcPy批量处理DEM,一键生成坡度坡向等高线报告
用PythonArcPy实现DEM地形分析全自动化:从数据到报告的智能工作流 第一次接手山区风电项目的地形分析任务时,我花了整整三天时间在ArcGIS界面里反复点击同样的按钮——加载DEM、计算坡度坡向、生成等高线、调整分类阈值、导出图片。当第五个区域的报告终…...

游戏开发/机器人导航必看:极坐标到底比XY坐标强在哪?Unity/ROS中的实战案例
你的输出 (必须严格遵循以下YAML格式,无需任何分析过程)相关性: ... 改写后查询: ... 企业名称: ... 基础信息: ... 职位: ... json {"business_segment": "礼品","main_product": "百度电商","reason": "用…...

终极鼠标连点器MouseClick:5分钟免费获取完整使用指南
终极鼠标连点器MouseClick:5分钟免费获取完整使用指南 【免费下载链接】MouseClick 🖱️ MouseClick 🖱️ 是一款功能强大的鼠标连点器和管理工具,采用 QT Widget 开发 ,具备跨平台兼容性 。软件界面美观 ,…...

小学阶段物理学习书籍推荐
结合小学阶段认知特点,推荐以下几本兼具趣味性和实用性的物理启蒙书籍,适配不同年级孩子的学习需求: 一、低龄(1-2年级/6-8岁):趣味感知,激发好奇 1、漫画物理全套6册 用孩子最喜欢的漫画形式拆…...

SISSO符号回归算法:革命性可解释AI模型的3大技术突破
SISSO符号回归算法:革命性可解释AI模型的3大技术突破 【免费下载链接】SISSO A data-driven method combining symbolic regression and compressed sensing for accurate & interpretable models. 项目地址: https://gitcode.com/gh_mirrors/si/SISSO 在…...

《当下的力量》前三章深度解读:从思维奴隶到临在大师的觉醒之路
《当下的力量》前三章深度解读:从思维奴隶到临在大师的觉醒之路这是一本不能用大脑读的书,这是一本需要用生命去体验的书。——张德芬前言 在这个信息爆炸、节奏飞快的时代,我们似乎永远活在过去的遗憾和未来的焦虑中。我们的大脑像一台永不停…...