优化大表分页查询性能:大表LIMIT 1000000, 10该怎么优化?
在处理大数据量的MySQL表时,我们经常会遇到一个问题:当我们尝试使用LIMIT语句进行分页查询时,性能会随着偏移量的增加而显著下降。例如,SELECT * FROM table LIMIT 1000000, 10 这样的查询可能会非常慢。那么,我们应该如何解决这个问题呢?
问题原因
首先,我们需要理解为什么这个问题会发生。MySQL在执行LIMIT语句时,会先跳过指定的偏移量,然后返回接下来的行。这意味着,如果你的偏移量非常大,比如1,000,000,MySQL需要先跳过1,000,000行,这是非常耗时的。
解决方案
对于这个问题,我们有几种可能的解决方案:
-
使用索引覆盖扫描(Covering Index Scan):如果你的查询可以被一个索引完全覆盖,那么MySQL可以只读取索引,而不需要读取实际的行。这可以大大提高查询速度。
-
记住上次查询的最后一个ID:如果你的表有一个递增的ID列,你可以在每次查询时记住上次查询的最后一个ID,然后在下一次查询时使用这个ID来限制结果。
-
使用分区表:如果你的表非常大,你可以考虑使用分区表。这样,你的查询可以只扫描一个分区,而不是整个表。
下面,我们将详细讨论这些解决方案,并提供Java示例代码。
使用索引覆盖扫描
假设我们有一个用户表,表结构如下:
CREATE TABLE `users` (`id` bigint(20) NOT NULL AUTO_INCREMENT,`username` varchar(255) DEFAULT NULL,`email` varchar(255) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8;
我们的查询是:SELECT * FROM users ORDER BY id LIMIT 1000000, 10。
为了优化这个查询,我们可以创建一个覆盖索引:
CREATE INDEX idx_users_id_username_email ON users(id, username, email);
然后,我们可以修改查询为:
SELECT id, username, email FROM users ORDER BY id LIMIT 1000000, 10;
这样,MySQL可以只读取索引,而不需要读取实际的行。
在Java中,我们可以使用JdbcTemplate来执行这个查询:
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.jdbc.core.RowMapper;import java.util.List;public class UserDao {private JdbcTemplate jdbcTemplate;public UserDao(JdbcTemplate jdbcTemplate) {this.jdbcTemplate = jdbcTemplate;}public List<User> getUsers(int offset, int limit) {String sql = "SELECT id, username, email FROM users ORDER BY id LIMIT ?, ?";return jdbcTemplate.query(sql, new Object[]{offset, limit}, (rs, rowNum) ->new User(rs.getLong("id"), rs.getString("username"), rs.getString("email")));}
}
记住上次查询的最后一个ID
另一个解决方案是在每次查询时记住上次查询的最后一个ID,然后在下一次查询时使用这个ID来限制结果。这样,我们就不需要跳过任何行,而可以直接从需要的位置开始查询。
假设我们的初始查询是:SELECT * FROM users ORDER BY id LIMIT 10。然后,我们记住最后一个用户的ID,假设是10。在下一次查询时,我们可以使用这个ID来限制结果:SELECT * FROM users WHERE id > 10 ORDER BY id LIMIT 10。
在Java中,我们可以修改UserDao类来实现这个功能:
public class UserDao {private JdbcTemplate jdbcTemplate;public UserDao(JdbcTemplate jdbcTemplate) {this.jdbcTemplate = jdbcTemplate;}public List<User> getUsers(long lastId, int limit) {String sql = "SELECT * FROM users WHERE id > ? ORDER BY id LIMIT ?";return jdbcTemplate.query(sql, new Object[]{lastId, limit}, (rs, rowNum) ->new User(rs.getLong("id"), rs.getString("username"), rs.getString("email")));}
}
使用分区表
如果你的表非常大,你可以考虑使用分区表。例如,你可以按照ID的范围来分区你的表。然后,你的查询可以只扫描一个分区,而不是整个表。
在MySQL中,你可以使用PARTITION BY RANGE语句来创建分区表:
CREATE TABLE users (id INT NOT NULL,username VARCHAR(30) NOT NULL,email VARCHAR(30) NOT NULL,PRIMARY KEY(id)
)
PARTITION BY RANGE (id) (PARTITION p0 VALUES LESS THAN (1000000),PARTITION p1 VALUES LESS THAN (2000000),PARTITION p2 VALUES LESS THAN MAXVALUE
);
在Java中,我们可以按照分区来查询数据:
public class UserDao {private JdbcTemplate jdbcTemplate;public UserDao(JdbcTemplate jdbcTemplate) {this.jdbcTemplate = jdbcTemplate;}public List<User> getUsers(int partition, int limit) {String sql = "SELECT * FROM users PARTITION (p" + partition + ") ORDER BY id LIMIT ?";return jdbcTemplate.query(sql, new Object[]{limit}, (rs, rowNum) ->new User(rs.getLong("id"), rs.getString("username"), rs.getString("email")));}
}
结论
在处理大数据量的MySQL表时,我们需要考虑如何优化我们的分页查询。我们可以使用索引覆盖扫描,记住上次查询的最后一个ID,或者使用分区表。每种方法都有其优点和适用场景,我们需要根据我们的具体需求来选择最适合的方法。
👉 💐🌸 公众号请关注 "果酱桑", 一起学习,一起进步! 🌸💐
相关文章:

优化大表分页查询性能:大表LIMIT 1000000, 10该怎么优化?
在处理大数据量的MySQL表时,我们经常会遇到一个问题:当我们尝试使用LIMIT语句进行分页查询时,性能会随着偏移量的增加而显著下降。例如,SELECT * FROM table LIMIT 1000000, 10 这样的查询可能会非常慢。那么,我们应该…...
ubuntu PX4 vscode stlink debug设置
硬件 stlink holybro debug板 pixhawk4 安装openocd 官方文档,但是第一步安装建议从源码安装,bug少很多 github链接 编译安装,参考 ./bootstrap (when building from the git repository)./configure [options]makesudo make install安装后…...

Flask的一种启动方式和三种托管方式
1. 原生启动 Flask 支持使用原生的 app.run() 方法来启动应用程序。这种方法是最简单、最基本的启动方式,适用于开发环境和小型应用程序。 from flask import Flaskapp Flask(__name__)app.route(/) def hello_world():return Hello, World!if __name__ __main__…...

cudnn too short
原因是libcudnn.so为软链接,相当于快捷键,但是没有映射到真正的libcudnn.so.8.9.5上 cd /usr/local/cuda-11.6/lib64 ln -s libcudnn.so.8.9.5 libcudnn.so.8...
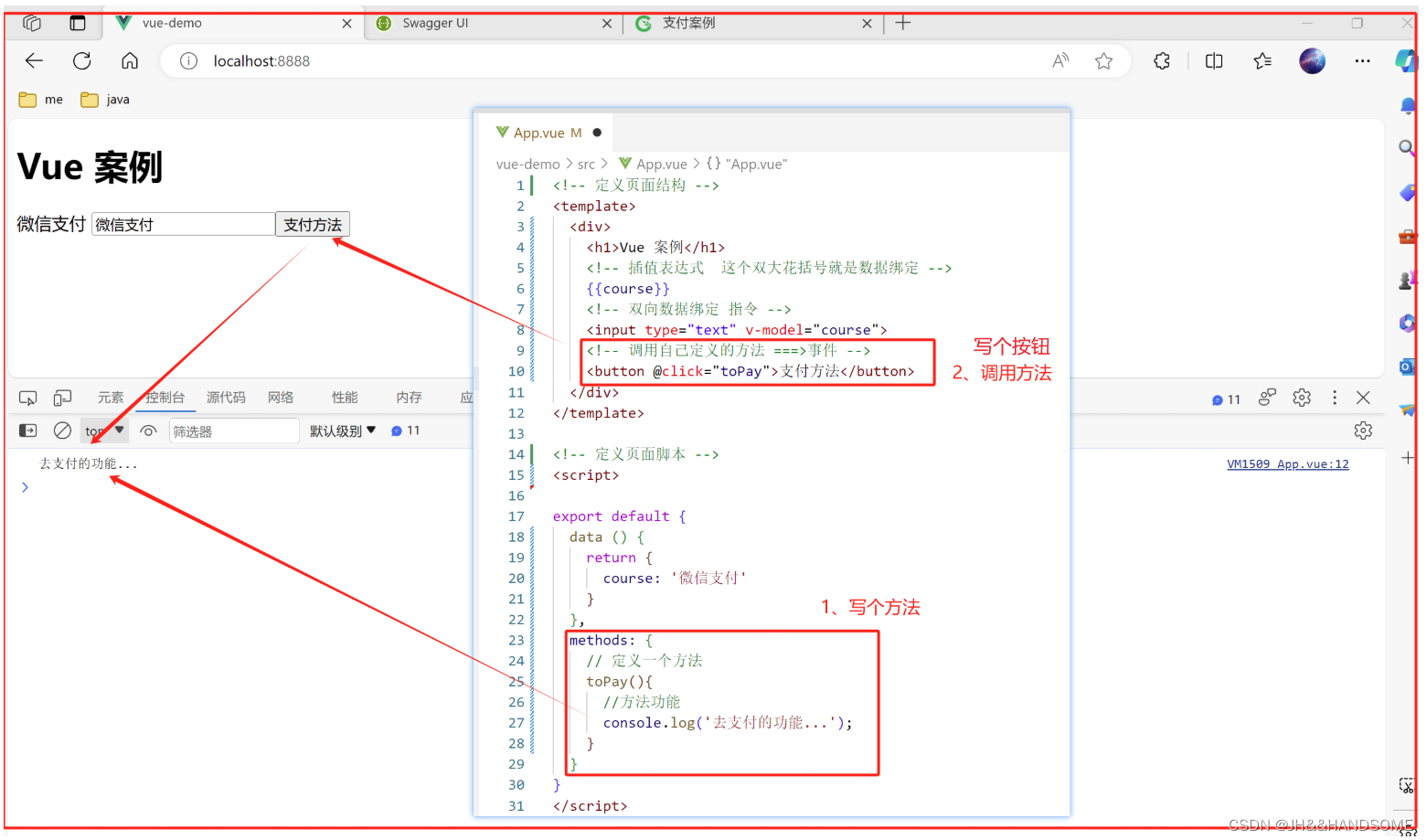
01、SpringBoot + MyBaits-Plus 集成微信支付 -->项目搭建
目录 SpringBoot MyBaits-Plus 集成微信支付 之 项目搭建1、创建boot项目2、引入Swagger作用:2-1、引入依赖2-2、写配置文件进行测试2-3、访问Swagger页面2-4、注解优化显示 3、定义统一结果作用:3-1、引入lombok依赖3-2、写个统一结果的类-->RR类的…...
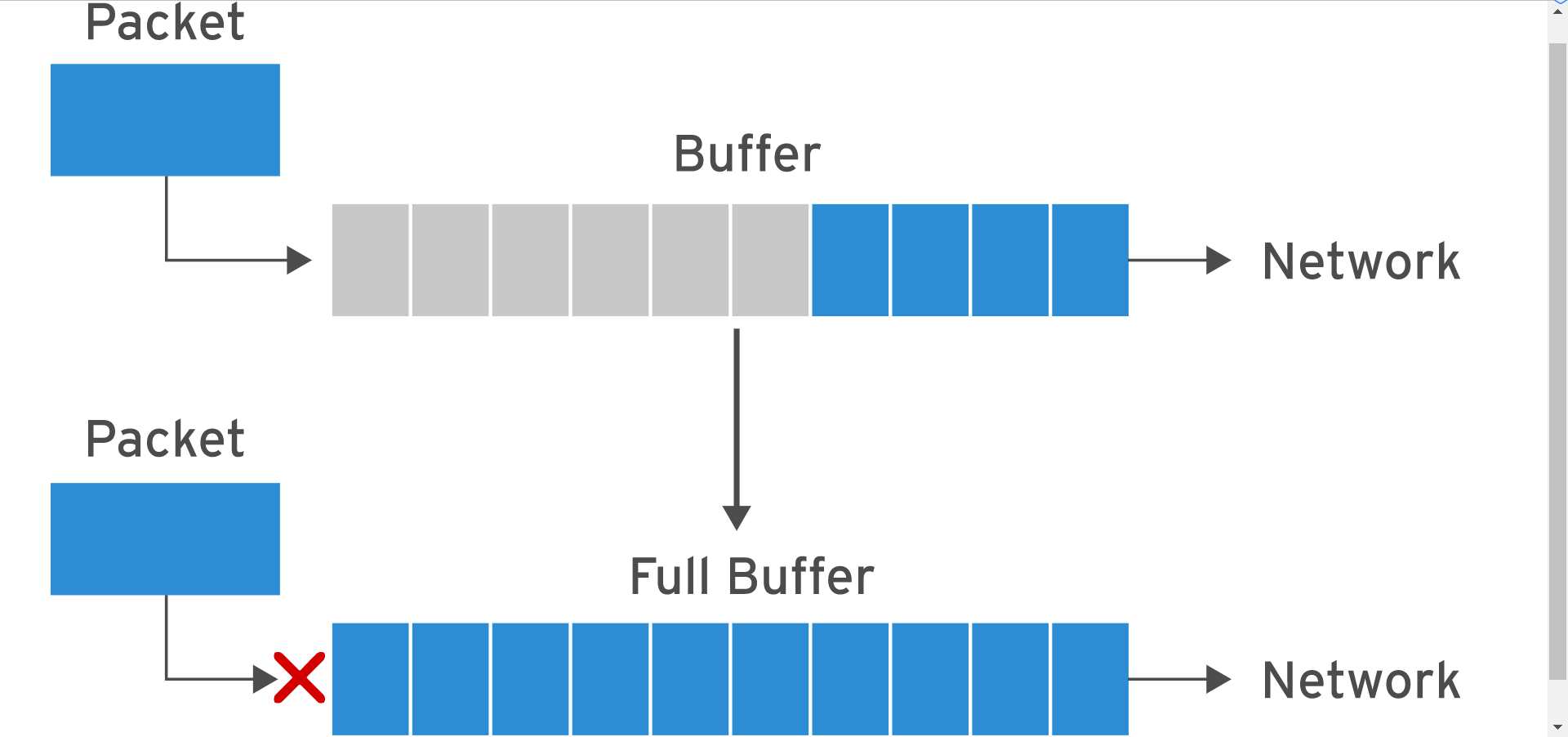
Linux 性能调优之网络优化
写在前面 考试整理相关笔记分享一些 Linux 中网络内核参数调优的笔记理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的,是人的逃…...

RT-Thread系统使用常见问题处理记录
1.使用telnet连接系统时发送help指令显示不全的问题。 原因:telnet发送缓存太小。 解决办法:更改agile_telnet软件包里Set agile_telnet tx buffer size的大小。 2.使用Paho MQTT软件包过一段时间报错hard fault on thread: mqtt0 解决办法࿱…...
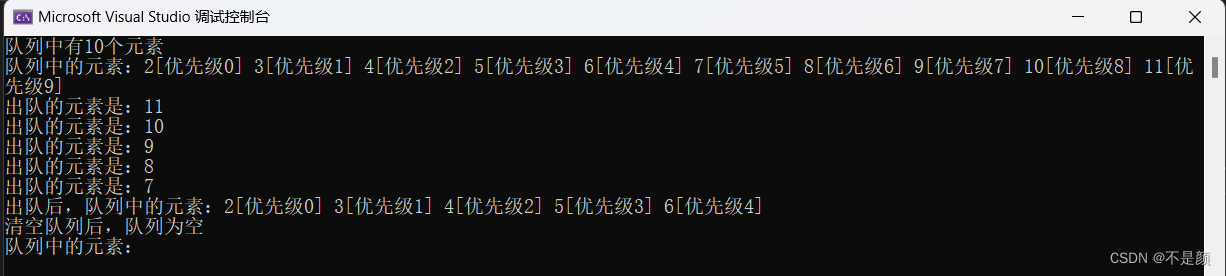
优先队列----数据结构
概念 不知道你玩过英雄联盟吗?英雄联盟里面的防御塔会攻击离自己最近的小兵,但是如果有炮车兵在塔内,防御塔会优先攻击炮车(因为炮车的威胁性更大),只有没有兵线在塔内时,防御塔才会攻击英雄。…...
nginx项目部署教程
nginx项目部署教程 1. 项目部署介绍 当我们的项目开发完毕后,我们需要将项目打包、部署到服务器上,供用户来使用。 目前,常见的部署方式有两种: 后端部署 前后端分离部署 1-1 后端部署 这是最古老的部署方式,也是…...

资源限流 + 本地分布式多重锁——高并发性能挡板,隔绝无效流量请求
前言 在高并发分布式下,我们往往采用分布式锁去维护一个同步互斥的业务需求,但是大家细想一下,在一些高TPS的业务场景下,让这些请求全部卡在获取分布式锁,这会造成什么问题? 瞬时高并发压垮系统 众所周知…...

day52【子序列】300.最长递归子序列 674.最长连续递增序列 718.最长重复子数组
文章目录 300.最长递增子序列674.最长连续递增序列718.最长重复子数组 300.最长递增子序列 题目链接:力扣链接 讲解链接:代码随想录链接 题意:给你一个整数数组 nums ,找到其中最长严格递增子序列的长度。 子序列 是由数组派生而…...

计算机视觉 计算机视觉识别是什么?
计算机视觉识别(Computer Vision Recognition)是计算机科学和人工智能领域中的一个重要分支,它致力于使计算机系统能够模拟和理解人类视觉的过程,从而能够自动识别、分析和理解图像或视频中的内容。这一领域的发展旨在让计算机具备…...
Make.com实现多个APP应用的自动化的入门指南
Make.com是一款基于云的自动化平台,可帮助用户将多个应用程序连接在一起,并通过设置自动化流程来简化日常任务。Make.com提供丰富的API集成,支持连接各种流行的应用程序,包括社交媒体、电子商务、CRM等。 使用Make.com实现多个AP…...
的简介、原理、性能、实现步骤、案例应用之详细攻略)
LLMs之HFKR:HFKR(基于大语言模型实现异构知识融合的推荐算法)的简介、原理、性能、实现步骤、案例应用之详细攻略
LLMs之HFKR:HFKR(基于大语言模型实现异构知识融合的推荐算法)的简介、原理、性能、实现步骤、案例应用之详细攻略 目录 HFKR的简介 异构知识融合:一种基于LLM的个性化推荐新方法...

多模态 多引擎 超融合 新生态!2023亚信科技AntDB数据库8.0产品发布
9月20日,以“多模态 多引擎 超融合 新生态”为主题的亚信科技AntDB数据库8.0产品发布会成功举办,从技术和生态两个角度全方位展示了AntDB数据库第8次大型能力升级和生态建设成果。浙江移动、用友、麒麟软件、华录高诚、金云智联等行业伙伴及业界专家共同…...

elasticsearch无法访问9200端口
近期部署elasticsearch后,启动时发现一直报如下错误: curl: (7) Failed connect to localhost:9200; Connection refused 部署的版本为elasticsearch-7.13.2,排查原因是因为开启了ssl认证。 解决方法: 在/opt/software/elasticsearch-7.13.2/config下…...
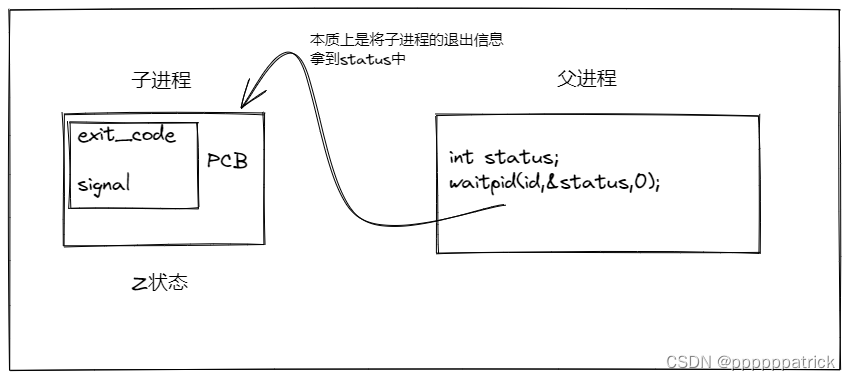
【Linux】进程等待
文章目录 进程等待进程等待必要性实验(见见猪跑)进程等待的方法wait方法waitpid**方法**宏的使用方法获取子进程status 阻塞VS非阻塞概念对比非阻塞有什么好处 具体代码实现进程的阻塞等待方式:进程的非阻塞等待方式:让父进程做其他任务 进程等待 进程等待必要性 之前讲过&am…...

电视「沉浮录」:跌出家电“三大件”?
【潮汐商业评论/原创】 “这年头谁还看电视,家里电视近一年都没打开过了,我明天就打算把它二手卖掉。”想到已落灰许久的电视机,Andy打开了二手平台。 “要不是这几年孩子网课多,我是真没考虑换新电视,家里用了8年的…...

前端实现调用打印机和小票打印(TSPL )功能
Ⅰ- 壹 - 使用需求 前端 的方式 点击这个按钮,直接让打印机打印我想要的东西 Ⅱ - 贰 - 小票打印 目前比较好的方式就是直接用 TSPL 标签打印指令集, 基础环境就不多说了,这个功能的实现就是利用usb发送指令,现在缺少个来让我们能够和usb沟通的工具,下面这就是推…...
串口通信(6)应用定时器中断+串口中断实现接收一串数据
本文为博主 日月同辉,与我共生,csdn原创首发。希望看完后能对你有所帮助,不足之处请指正!一起交流学习,共同进步! > 发布人:日月同辉,与我共生_单片机-CSDN博客 > 欢迎你为独创博主日月同…...

AI系统的四层缓存架构
别再被“提示词缓存”“语义缓存”绕晕了,它们根本不是一回事 先上关系图:AI系统里的四层缓存 很多人把缓存当一个东西聊,其实它们是四个不同的层,各管各的,又互相喂数据。 第一层 长期知识源 项目记忆缓存&#x…...

Beyond Compare 5密钥生成器技术解析与高效配置指南
Beyond Compare 5密钥生成器技术解析与高效配置指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 当Beyond Compare 5的30天评估期结束后,软件会进入受限模式,许多高级…...

ZVM嵌入式实时虚拟机:在ARMv8-A上实现Linux与Zephyr的混合关键性系统
1. 项目概述与核心价值如果你正在从事嵌入式系统开发,尤其是涉及汽车电子、工业控制或5G通信设备这类对实时性和可靠性要求极高的领域,那么你肯定对“既要、又要、还要”的困境深有体会。我们常常需要在同一块硬件上,既要运行一个功能丰富、生…...

技术从业者的面试技巧:如何通过大厂的技术面试
在软件行业的招聘生态中,大厂的技术面试如同一场严苛的专业试炼,尤其对于软件测试从业者而言,不仅要展现扎实的技术功底,更要体现出符合大厂标准的工程思维与问题解决能力。想要在竞争激烈的面试中脱颖而出,需要从面试…...

紧急停止与异常停机:天勤策略里的断线保护与人工兜底
前言 网络闪断、进程被 kill、策略异常未捕获,都可能让持仓暴露在无人管理状态。天勤文档里有紧急停止相关能力(见 advanced/emergency_stop.rst),我把它和自建「停机即平仓/撤单」脚本配合使用。下面写工程清单,不替代…...

蓝桥杯嵌入式第十届真题复盘:从CubeMX配置到EEPROM读写,我是如何一步步踩坑又爬出来的
蓝桥杯嵌入式第十届真题实战复盘:从CubeMX配置到EEPROM读写的深度解析 去年参加蓝桥杯嵌入式比赛的经历,至今回想起来仍让我心有余悸。第十届真题中的LED模块和EEPROM读写部分,堪称"嵌入式开发者的噩梦"。记得当时在实验室熬到凌晨…...

Redis——string类型相关指令
添加键值对SET [key] [value] [EX seconds|PX milliseconds] [NX|XX] //添加一个键值对SETNX [key] [value] //setNX的组合命令,不支持EX/PX选项SETEX [key] [value] //setEX的组合命令,不支持NX/XX选项PSETEX [key] [value] //setPX的组合命令ÿ…...

LDAP查询服务延时查询及问题排查处理
文章目录一、使用服务器管理器管理本地和远程服务器二、LDAP查询用时三、LDAP查询高延迟排查步骤推荐阅读一、使用服务器管理器管理本地和远程服务器 默认情况下,服务器管理器包含在 Windows Server 中,无需单独安装。 在以下步骤中,将使用服…...

别再傻傻分不清!用打电话、对讲机、广播这些生活例子,5分钟搞懂串行通信里的单工、半双工和全双工
从生活场景秒懂通信模式:广播、对讲机与电话的硬核技术解读 刚接触嵌入式开发时,看到UART、I2C这些协议文档里蹦出的"全双工"、"半双工"术语,是不是感觉像在读天书?别急着翻教科书,其实这些抽象概…...

开源项目Markdown Viewer:如何打造完美的浏览器Markdown阅读体验
开源项目Markdown Viewer:如何打造完美的浏览器Markdown阅读体验 【免费下载链接】markdown-viewer Markdown Viewer / Browser Extension 项目地址: https://gitcode.com/gh_mirrors/ma/markdown-viewer 作为一款功能强大的开源项目,Markdown Vi…...