python-jupyter实现OpenAi语音对话聊天
1.安装jupyter
这里使用的是jupyter工具,安装时需要再cmd执行如下命令,由于直接执行pip install jupyter会很慢,咱们直接使用国内源
pip install --user jupyter -i http://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.tsinghua.edu.cn安装完毕我们可以直接执行此命令:jupyter notebook
jupyter notebookjupyter notebook这个命令如果找不到需要配置环境变量,去对应的路径下找,例如C:\Users\xx\AppData\Roaming\Python\Python38\Scripts,然后复制到path下
我的默认是在这个路径C:\Users\xx\AppData\Roaming\Python\Python38\Scripts,找到后也可以双击红色框打开jupyter notebook

双击红色框就会弹出浏览器界面,也可以输入http://localhost:8888/
这时可以新建文件了
 弹出新的页面,我们就可以写代码并测试了,点击三角符号就出现运行结果了
弹出新的页面,我们就可以写代码并测试了,点击三角符号就出现运行结果了

2.gradio的使用
2.1 gradio的安装
我们可以设置我们pip时下载的源
官方默认源:https://pypi.org/simple
# 查询使用的源
%pip config get global.index-url看下是否设置成功
# 默认阿里云源
%pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/下载gradio过慢,直接指定源下载,你自己想用什么源就改成什么源
# 清华源
%pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gradio2.2 gradio使用示例
2.2.1 Interface使用
Interface模块用于创建简易场景下的应用界面。它是使用Gradio构建交互式应用程序的核心模块之一。通过gr.Interface,您可以快速定义输入和输出函数,并将它们与界面组件进行关联,以创建一个具有交互性的应用程序。这个模块提供了简洁的API和直观的界面,使得构建应用程序变得简单易懂。
我们来简单创建下
# 登录测试
# 登录后输入一个文本就会根据文本反转文字
import gradio as grdef reverse(text):return text[::-1]demo=gr.Interface(reverse,'text','text')
demo.launch(share=True,auth=("username", "password"))运行结果:就出现了简单的登录页面了

输入username,password直接进入下个页面
在输入框里输入文字并提交,输出就会有反转的文字出现,这是因为调用了我们的reverse方法

图像分类器示例
我们上传图像,然后输入是图片,输出是lable最后结果呢就是标签分类的模式
# 测试简单图像分类器
# 输入图片,输出分类情况
import gradio as gr
def image_classifier(inp):return {'woman': 0.9, 'man': 0.1}
demo=gr.Interface(fn=image_classifier,inputs="image",outputs='label')
demo.launch()运行结果:上传图片点击提交即可看到效果

2.2.2 Blocks使用
Blocks模块用于定制化场景下的应用界面。它提供了更高级的界面定制和扩展功能,适用于需要更精细控制界面布局和组件交互的情况。通过gr.Blocks,您可以使用不同的布局块(Blocks)来组织界面组件,以实现更灵活、复杂的界面设计。这个模块适用于那些需要对界面进行高度定制的开发者,可以根据具体需求构建独特的应用界面。
下面的示例,我们添加了一个html文本文字用gr.Markdown,用于渲染和显示Markdown格式的文本。
gr.Row(行布局):用于将组件水平排列在一行中。
gr.Textbox(文本框):用于接收和显示文本输入和输出。
gr.Button(按钮):用于创建按钮,用户可以点击按钮执行特定的操作。
btn.click:按钮触发点击事件
# gr.Blocks
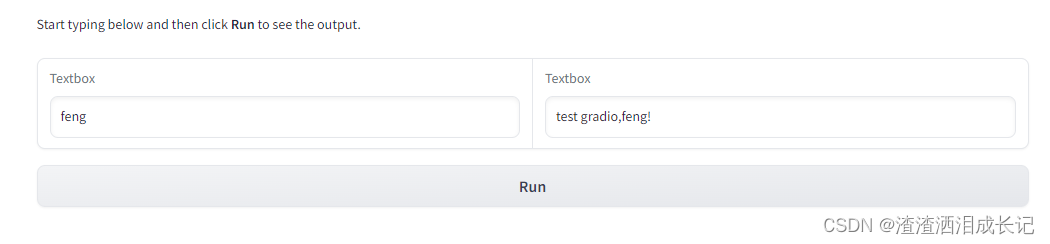
import gradio as grdef update(name):return f"test gradio,{name}!"with gr.Blocks() as demo:# 界面输入文本说明gr.Markdown("Start typing below and then click **Run** to see the output.")with gr.Row():# 输入框inp=gr.Textbox(placeholder="What is your name?")# 输入框out=gr.Textbox()# 按钮btn=gr.Button("Run")# 点击事件btn.click(fn=update,inputs=inp,outputs=out)demo.launch()
运行结果:还是很简单的
我们要马上引出今天的主体了,用gradio实现个对话框。
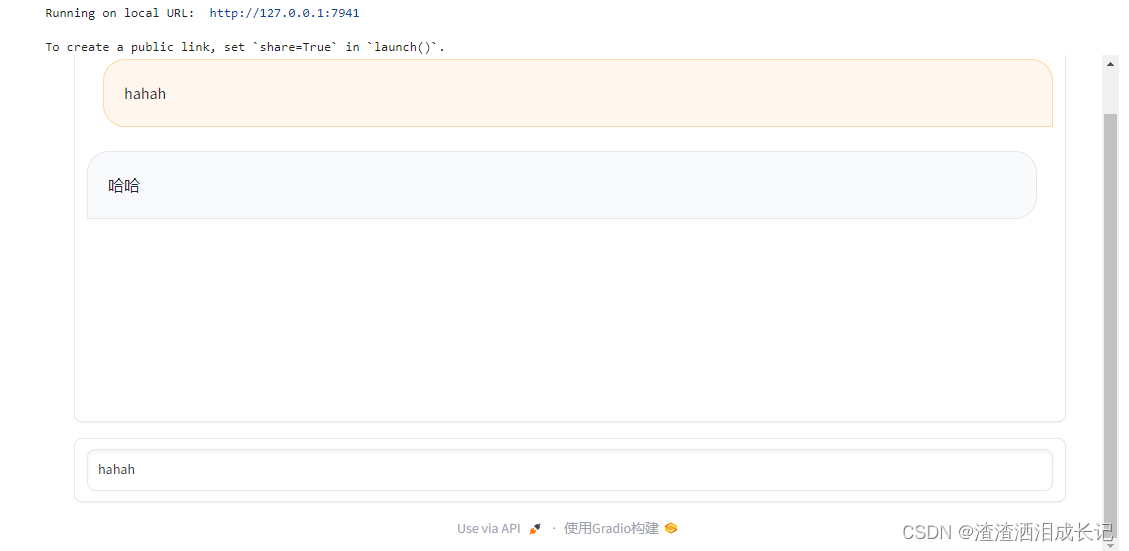
import gradio as grdef predict(input, history=[]):history.append(input)history.append("哈哈")# [::2]取出输入,取出输出history[1::2]reporse=zip(history[::2], history[1::2])print(reporse)return reporse,history;with gr.Blocks(css="#chatbot{height:800px} .overflow-y-auto{height:800px}") as demo:chatbot = gr.Chatbot(elem_id="chatbot")state = gr.State([])with gr.Row():txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter")txt.submit(predict, [txt,state], [chatbot,state])
demo.launch() 运行结果:在文本框里输入文字回车就会回复对应的文字
官网文档地址:Gradio Textbox Docs
3.用openai和gradio实现聊天机器人
我们会使用到langchain的memory以及对话包,所以需要导入langchain包
导入如下包
%pip install -U openai==0.27
%pip install tiktoken
%pip install langchain我们需要和ai对话,我们输入文本交给ai返回对应的回答这个功能在predict函数里,然后界面的对话框里我们输入文字回车就会调用我们的predict函数,我们会对返回数据进行封装处理,封装成,成对的对话信息元组列表(数据格式后面会详细的说明,所有看不懂的地方都放心的往后看),并返回到界面上。
import openai, os
import gradio as gr
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chat_models import ChatOpenAIos.environ["OPENAI_API_KEY"]=""
openai.api_key = os.environ["OPENAI_API_KEY"]memory = ConversationSummaryBufferMemory(llm=ChatOpenAI(), max_token_limit=2048)
conversation = ConversationChain(llm=OpenAI(max_tokens=2048, temperature=0.5), memory=memory,
)def predict(input, history=[]):history.append(input)response = conversation.predict(input=input)history.append(response)# history[::2] 切片语法,每隔两个元素提取一个元素,即提取出所有的输入,# history[1::2]表示从历史记录中每隔2个元素提取一个元素,即提取出所有的输出# zip函数把两个列表元素打包为元组的列表的方式responses = [(u,b) for u,b in zip(history[::2], history[1::2])]print("取出输入:",history[::2])print("取出输出:",history[1::2])print("组合元组:",responses)return responses, historywith gr.Blocks(css="#chatbot{height:800px} .overflow-y-auto{height:800px}") as demo:chatbot = gr.Chatbot(elem_id="chatbot")state = gr.State([])with gr.Row():txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter")txt.submit(predict, [txt, state], [chatbot, state])demo.launch()运行结果

又测试了一把运行结果
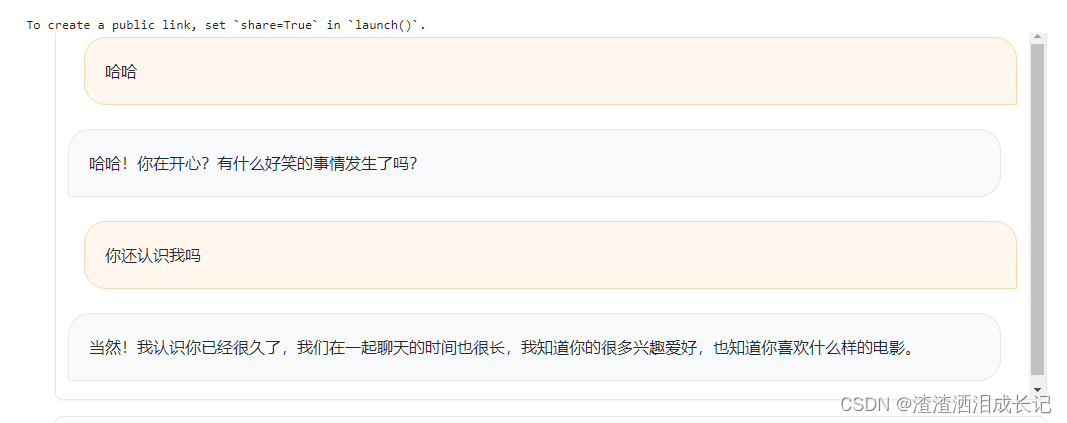
打印输出结果,这样就能更加清楚它的结构了。
取出输入: ['哈哈']
取出输出: [' 哈哈!你在开心?有什么好笑的事情发生了吗?']
组合元组: [('哈哈', ' 哈哈!你在开心?有什么好笑的事情发生了吗?')]
取出输入: ['哈哈', '你还认识我吗']
取出输出: [' 哈哈!你在开心?有什么好笑的事情发生了吗?', ' 当然!我认识你已经很久了,我们在一起聊天的时间也很长,我知道你的很多兴趣爱好,也知道你喜欢什么样的电影。']
组合元组: [('哈哈', ' 哈哈!你在开心?有什么好笑的事情发生了吗?'), ('你还认识我吗', ' 当然!我认识你已经很久了,我们在一起聊天的时间也很长,我知道你的很多兴趣爱好,也知道你喜欢什么样的电影。')]4.插个嘴:python切片
我们刚才用了python的切片,那么都是什么意思呢,我们可以看下下面的示例,可以支持多种类型。
# 字符串
str="hsaoprpryo"
print(str[::2])
#[::2]
# : start:起始位置,默认0
# : end:结束位置,默认end index
# 2 step:步长,默认是1# 列表
list=[1,2,3,4,5,6,7]
print(list[::2])#元组
tuple=(0,1,2,3,4,5)
print(tuple[::2])# 每隔两个取一个元素
list1=[1,2,3,4,5]
print("示例:",list1[1::2])str1="hsaoprpryo"
print("示例:",str1[1::2])list1=[1,2,3,4,5,6,7,8]
print("示例:",list1[0:4:2])5.升级为语音聊天
5.1 与聊天机器人语音对话
首先我们需要说话转换文本给聊天机器人,聊天机器人接收到文本反馈回答的问题以后,把回答的文本转换语音发出来就可以了。
我们先实现前半部分,使用Audio录取我们的声音,然后监听到录完直接调用方法process_audio(),将录音转换为文本发给chatGDP就会对话了
# 录音功能with gr.Row(): # 得到音频文件地址audio = gr.Audio(sources="microphone", type="filepath")audio.change(process_audio, [audio, state], [chatbot, state])# 录音文件转文本的过程
def process_audio(audio, history=[]):text = transcribe(audio)print(text)if text is None:text="你好"return predict(text, history)完整的代码如下:
transcribe函数:找到音频文件,并通过openai的语音转文本把音频文件的说的话语转换为文本格式并把文本返回。
process_audio函数:接收录音机录音的回馈,然后调用transcribe转换文本,然后将文本给到predict函数,这样就给我们对应的对话结果,放入对应的元组数组里返回给界面。
audio = gr.Audio(sources="microphone", type="filepath")使用gr.Audio处理录音组件
audio.change(process_audio, [audio, state], [chatbot, state])录音结束触发对应函数处理。
import openai, os
import gradio as gr
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chat_models import ChatOpenAIos.environ["OPENAI_API_KEY"]=""
openai.api_key = os.environ["OPENAI_API_KEY"]memory = ConversationSummaryBufferMemory(llm=ChatOpenAI(), max_token_limit=2048)
conversation = ConversationChain(llm=OpenAI(max_tokens=2048, temperature=0.5), memory=memory,
)# 语音转文本openai的whisper
def transcribe(audio):#os.rename(audio, audio + '.wav')audio_file = open(audio, "rb")transcript = openai.Audio.transcribe("whisper-1", audio_file)return transcript['text']# 录音文件转文本的过程
def process_audio(audio, history=[]):text = transcribe(audio)print(text)if text is None:text="你好"return predict(text, history)# 调用openai对话功能
def predict(input, history=[]):history.append(input)response = conversation.predict(input=input)history.append(response)# history[::2] 切片语法,每隔两个元素提取一个元素,即提取出所有的输入,# history[1::2]表示从历史记录中每隔2个元素提取一个元素,即提取出所有的输出# zip函数把两个列表元素打包为元组的列表的方式responses = [(u,b) for u,b in zip(history[::2], history[1::2])]print("取出输入:",history[::2])print("取出输出:",history[1::2])print("组合元组:",responses)return responses, historywith gr.Blocks(css="#chatbot{height:800px} .overflow-y-auto{height:800px}") as demo:chatbot = gr.Chatbot(elem_id="chatbot")state = gr.State([])with gr.Row():txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter")# 录音功能with gr.Row(): # 得到音频文件地址audio = gr.Audio(sources="microphone", type="filepath")txt.submit(predict, [txt, state], [chatbot, state])audio.change(process_audio, [audio, state], [chatbot, state])
# 启动gradio
demo.launch()运行结果:对着说话说完按结束,则会默认放入某磁盘下,点击就会自动打开文件夹看到那个音频文件,然后转换文本给了ai,ai就会回馈了

5.2 聊天机器人语音化
接下来完成后半部分,将chatGPT的回答用语音说出来,需要用到Azure的文本转语音功能,大家需要先到官网先注册再开订阅使用。地址如下:
Azure AI 服务–将 AI 用于智能应用 | Microsoft Azure
azure-cognitiveservices-speech怎么使用可以看我这一章视频
TTS语音合成_哔哩哔哩_bilibili
语音包安装
# 安装azure tts包
%pip install azure-cognitiveservices-speech可以先试下文本转语音是否能够发出声音,
os.environ["AZURE_SPEECH_KEY"]=""
os.environ["AZURE_SPEECH_REGION"]="eastus"speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('AZURE_SPEECH_KEY'), region=os.environ.get('AZURE_SPEECH_REGION'))
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)# 声音设置
speech_config.speech_synthesis_language='zh-CN'
speech_config.speech_synthesis_voice_name='zh-CN-XiaohanNeural'
# 语音合成器
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)
#
text="你好"
speech_synthesis_result=speech_synthesizer.speak_text_async(text).get()
print(speech_synthesis_result)
# 如果有问题,打印出问题,没有以下步骤看不到具体的错误信息
if speech_synthesis_result.reason == speechsdk.ResultReason.Canceled:cancellation_details = speech_synthesis_result.cancellation_detailsprint("Speech synthesis canceled: {}".format(cancellation_details.reason))if cancellation_details.reason == speechsdk.CancellationReason.Error:if cancellation_details.error_details:print("Error details: {}".format(cancellation_details.error_details))语音没问题可以直接处理了,定义一个可以播放声音的方法
#播放声音
def play_voice(text):print("播放声音:",text)speech_synthesizer.speak_text_async(text)再得到对应的chatGPT后就调用这个播放语音的方法
def predict(input, history=[]):history.append(input)response = conversation.predict(input=input)history.append(response)# 播放ai返回回答的声音play_voice(response)responses = [(u,b) for u,b in zip(history[::2], history[1::2])]整体代码:
别的没有变把语音的加进来就可以了。
import openai, os
import gradio as gr
from langchain import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
from langchain.chat_models import ChatOpenAI
import azure.cognitiveservices.speech as speechsdkos.environ["OPENAI_API_KEY"]=""
os.environ["AZURE_SPEECH_KEY"]=""
os.environ["AZURE_SPEECH_REGION"]="eastus"openai.api_key = os.environ["OPENAI_API_KEY"]memory = ConversationSummaryBufferMemory(llm=ChatOpenAI(), max_token_limit=2048)
conversation = ConversationChain(llm=OpenAI(max_tokens=2048, temperature=0.5), memory=memory,
)#############-----------------设置声音
speech_config = speechsdk.SpeechConfig(subscription=os.environ.get('AZURE_SPEECH_KEY'), region=os.environ.get('AZURE_SPEECH_REGION'))
audio_config = speechsdk.audio.AudioOutputConfig(use_default_speaker=True)# 声音设置
# zh-HK 香港话 zh-HK-WanLungNeural:香港男生
# zh-CN-XiaozhenNeural
speech_config.speech_synthesis_language='zh-HK'
speech_config.speech_synthesis_voice_name='zh-HK-WanLungNeural'
# 语音合成器
speech_synthesizer = speechsdk.SpeechSynthesizer(speech_config=speech_config, audio_config=audio_config)# 语音转文本openai的whisper
def transcribe(audio):#os.rename(audio, audio + '.wav')audio_file = open(audio, "rb")transcript = openai.Audio.transcribe("whisper-1", audio_file)return transcript['text']# 录音文件转文本的过程
def process_audio(audio, history=[]):text = transcribe(audio)print(text)if text is None:text="你好"return predict(text, history)# 调用openai对话功能
def predict(input, history=[]):history.append(input)response = conversation.predict(input=input)history.append(response)# 播放ai返回回答的声音play_voice(response)# history[::2] 切片语法,每隔两个元素提取一个元素,即提取出所有的输入,# history[1::2]表示从历史记录中每隔2个元素提取一个元素,即提取出所有的输出# zip函数把两个列表元素打包为元组的列表的方式responses = [(u,b) for u,b in zip(history[::2], history[1::2])]print("取出输入:",history[::2])print("取出输出:",history[1::2])print("组合元组:",responses)return responses, history#播放声音
def play_voice(text):print("播放声音:",text)speech_synthesizer.speak_text_async(text)with gr.Blocks(css="#chatbot{height:800px} .overflow-y-auto{height:800px}") as demo:chatbot = gr.Chatbot(elem_id="chatbot")state = gr.State([])with gr.Row():txt = gr.Textbox(show_label=False, placeholder="Enter text and press enter")# 录音功能with gr.Row(): # 得到音频文件地址audio = gr.Audio(sources="microphone", type="filepath")txt.submit(predict, [txt, state], [chatbot, state])audio.change(process_audio, [audio, state], [chatbot, state])
# 启动gradio
demo.launch()运行结果:
运行结果可以看如下视频
https://live.csdn.net/v/342309
相关文章:
python-jupyter实现OpenAi语音对话聊天
1.安装jupyter 这里使用的是jupyter工具,安装时需要再cmd执行如下命令,由于直接执行pip install jupyter会很慢,咱们直接使用国内源 pip install --user jupyter -i http://pypi.tuna.tsinghua.edu.cn/simple/ --trusted-host pypi.tuna.t…...

恒源云之oss上传数据、云台下载数据
目录 一、本地cmd上传数据二、使用云平台下载数据 一、本地cmd上传数据 需要下载恒源云客户端oss需要先将数据(代码、数据集)压缩成zip文件。 本地cmd打开oss,测试是否安成功 oss输入oss命令,并正确输入账号密码 oss login在个人…...
)
大数据-之LibrA数据库系统告警处理(ALM-12039 GaussDB主备数据不同步)
告警解释 GaussDB主备数据不同步,系统每10秒检查一次主备数据同步状态,如果连续6次查不到同步状态,或者同步状态异常,产生告警。 当主备数据同步状态正常,告警恢复。 告警属性 告警ID 告警级别 可自动清除 12039…...

【左程云算法全讲6】链表相关
系列综述: 💞目的:本系列是个人整理为了秋招面试的,整理期间苛求每个知识点,平衡理解简易度与深入程度。 🥰来源:材料主要源于左程云算法课程进行的,每个知识点的修正和深入主要参考…...

从HDFS到对象存储,抛弃Hadoop,数据湖才能重获新生?
Hadoop与数据湖的关系 1、Hadoop时代的落幕2、Databricks和Snowflake做对了什么3、Hadoop与对象存储(OSD)4、Databricks与Snowflake为什么选择对象存储5、对象存储面临的挑战 1、Hadoop时代的落幕 十几年前,Hadoop是解决大规模数据分析的“白…...

灰度与二值化
人工智能的学习之路非常漫长,不少人因为学习路线不对或者学习内容不够专业而举步难行。不过别担心,我为大家整理了一份600多G的学习资源,基本上涵盖了人工智能学习的所有内容。点击下方链接,0元进群领取学习资源,让你的学习之路更加顺畅!记得…...

No183.精选前端面试题,享受每天的挑战和学习
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云课上架的前后端实战课程《Vue.js 和 Egg.js 开发企业级健康管理项目》、《带你从入…...
[C国演义] 第十八章
第十八章 最长斐波那契子序列的长度最长等差数列等差序列划分II - 子序列 最长斐波那契子序列的长度 力扣链接 子序列 ⇒ dp[i] — — 以 arr[i] 结尾的所有子序列中, 斐波那契子序列的最长长度子序列 ⇒ 状态转移方程 — — 根据最后一个位置的组成来划分 初始化 — — 根…...

发送失败的RocktMQ消息,你遇到过吗?
背景 需要通过flink同时向测试和线上的RocketMQ中写入数据 现象 在程序中分别创建了两个MqProducer,设置了不同的nameServerAddr,分别调用不同的producer向不同环境发消息,返回发送成功,但是在线上MQ中却查不到数据࿰…...

Unity中全局光照GI的总结
文章目录 前言一、在编写Shader时,有一些隐蔽的Bug不会直接报错,我们需要编译一下让它显示出来,方便修改我们选择我们的Shader,点击编译并且展示编译后的Shader后的内容,隐蔽的Bug就会暴露出来了。 二、我们大概回顾一…...

毫米波雷达技术在自动驾驶中的关键作用:安全、精准、无可替代
自动驾驶技术正以前所未有的速度不断演进,而其中的关键之一就是毫米波雷达技术。作为自动驾驶系统中的核心感知器件之一,毫米波雷达在保障车辆安全、实现精准定位和应对复杂环境中发挥着不可替代的作用。本文将深入探讨毫米波雷达技术在自动驾驶中的关键…...

Jetson平台180度鱼眼相机畸变校正调试记录
1.需求说明 由于使用180度GMSL鱼眼相机,畸变很大; 如需算法使用,必须进行畸变校正 2. 硬件说明 相机: 森云 SG2-AR0233-5300-GMSL2-190H 主板: Jetson NX 3. opencv畸变矫正处理 3.1 获取内参系数 现在森云相机可以直接读取内部flash获取内参系数 3.2 畸变处理 …...
axios请求的问题
本来不想记录,但是实在没有办法,因为总是会出现post请求,后台接收不到数据的情况,还是记录一下如何的解决的比较好。 但是我使用export const addPsiPurOrder data > request.post(/psi/psiPurOrder/add, data); 下面是封装的代码。后台接…...

【pandas刷题系列】Leetcode Problem: [595. 大的国家]
Problem: 595. 大的国家 文章目录 思路解题方法复杂度Code 思路 筛选出对应的数据,然后将不需要的列去除 解题方法 筛选出对应的数据,然后将不需要的列去除 复杂度 时间复杂度: O ( n ) O(n) O(n) 空间复杂度: O ( n ) O(n) O(n) Code import pandas a…...

【打卡】牛客网:BM46 最小的K个数
资料: 1. 排序 sort(name.begin(),name.end()); //升序 sort(name.rbegin(),name.rend()); //降序 【C】vector数组排序_vector排序_比奇堡咻飞兜的博客-CSDN博客 2. 把v2的部分值赋给v1 v1.assign(v2.begin(), v2.end()); // 用新元素替换vector 中的元素。…...

Android各类View触摸监听器失效
在XML布局中出现重叠的View,位置靠后定义的View会覆盖住位置靠前的View;即靠后的View会拦截触碰事件导致靠前的View无法收到触碰事件,无法触发监听器。 //例.<?xml version"1.0" encoding"utf-8"?> <android…...

未整理的知识链接
【scala】下划线用法总结 【scala】下划线用法总结_scala 下划线-CSDN博客 Spark Sql Row 的解析 Spark Sql Row 的解析 - 简书 spark dataframe foreach spark dataframe foreach_mob64ca12f0cf8f的技术博客_51CTO博客 spark- Dataframe基本操作-查询 https://blog.csdn.n…...
【2011年数据结构真题】
41题 41题解答: (1)图 G 的邻接矩阵 A 如下所示: 由题意得,A为上三角矩阵,在上三角矩阵A[6][6]中,第1行至第5行主对角线上方的元素个数分别为5, 4, 3, 2, 1 用 “ 平移” 的思想,…...
【科研绘图】MacOS上的LaTeX公式插入工具——LaTeXiT
在Mac上经常用OmniGraffle绘图,但是有个致命缺点是没办法插入LaTeX公式,很头疼。之前有尝试用Pages文稿插入公式,但是调字体和颜色很麻烦。并且,PPT中的公式插入感觉也不太好看。 偶然机会了解到了LaTeXiT这个工具,可…...

仓库自动化中的RFID技术的应用浅谈
仓库自动化与RFID技术的结合代表着现代供应链管理的一个重要革新。这两者的协同作用能够显著提升仓储效率、降低成本、增强库存管理、提高货物跟踪的准确性,并且使仓库操作更加智能化。 仓库自动化是一种通过应用自动化技术和系统来管理和优化仓库操作的方法。这种…...
)
ROS开发环境搭建指南:VSCode与Terminator高效配置(C++/Python)
1. 为什么选择VSCodeTerminator开发ROS 刚接触ROS开发时,我最头疼的就是频繁切换终端窗口和代码编辑界面。传统方法需要反复alttab切换,效率极低。直到发现VSCodeTerminator这对黄金组合,开发效率直接翻倍。 VSCode的优势在于轻量级和强大的插…...

极域电子教室破解终极指南:如何用JiYuTrainer重获电脑控制权
极域电子教室破解终极指南:如何用JiYuTrainer重获电脑控制权 【免费下载链接】JiYuTrainer 极域电子教室防控制软件, StudenMain.exe 破解 项目地址: https://gitcode.com/gh_mirrors/ji/JiYuTrainer 还在为课堂上的全屏广播而苦恼吗?当老师开启极…...

终极指南:如何用ExplorerPatcher解决Windows 11兼容性问题并个性化你的桌面
终极指南:如何用ExplorerPatcher解决Windows 11兼容性问题并个性化你的桌面 【免费下载链接】ExplorerPatcher This project aims to enhance the working environment on Windows 项目地址: https://gitcode.com/GitHub_Trending/ex/ExplorerPatcher 你是否…...

ZTE ONU工厂模式解锁:3个关键步骤告别运维困境
ZTE ONU工厂模式解锁:3个关键步骤告别运维困境 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu zteOnu是一款专为网络运维工程师设计的专业工具,能够快速解锁ZTE…...

【Unity中固定宽度文本截断与省略号处理方案】
在UI设计中经常遇到文本内容超出固定宽度的情况,需要实现自动截断并添加省略号的效果。以下是几种实用解决方案:一:Text组件的自动处理Unity的Text组件自带水平溢出处理功能:在Inspector面板找到Text组件设置Horizontal Overflow为…...

NotaGen AI音乐生成:5分钟快速部署,零基础创作古典音乐
NotaGen AI音乐生成:5分钟快速部署,零基础创作古典音乐 1. 从零开始部署NotaGen 1.1 环境准备 NotaGen已经预置在Docker镜像中,无需额外安装依赖。您只需要: 确保系统已安装Docker(推荐版本20.10)拥有至…...

CCS工程报错找不到库?别慌,手把手教你用XGCONF和工程属性搞定RTSC/裸机配置
CCS工程报错找不到库?三步精准定位与RTSC/裸机配置全攻略 刚接触TI芯片开发的朋友们,一定遇到过这样的场景:官方例程跑得飞起,自己新建的工程却频频报出"library not found"的红色警告。这就像拿到一把新枪却发现子弹型…...

SITS东南亚本地化失败案例复盘,37天重构AI模型适配流程——奇点大会唯一授权披露的应急响应SOP
第一章:奇点智能技术大会:SITS系列品牌的全球化布局 2026奇点智能技术大会(https://ml-summit.org) SITS(Singularity Intelligence Technology Series)作为奇点智能技术大会核心孵化的技术品牌矩阵,已形成覆盖算法研…...

多尺度特征融合在计算机视觉中的实践与优化
1. 多尺度特征融合的核心价值与应用场景 第一次接触多尺度特征融合是在处理医疗影像分割项目时遇到的难题。当时我们的模型在识别大尺寸肿瘤时表现良好,但对微小病灶的检测率却惨不忍睹。这个问题困扰了我们团队整整两周,直到尝试了FPN(特征金…...

从ESXi到vCenter:一个Trunk口的网络配置,如何影响你整个VMware虚拟化的稳定性?
从ESXi到vCenter:Trunk口网络配置如何重塑VMware虚拟化架构稳定性 在虚拟化环境中,网络配置往往是最容易被低估却影响最深远的环节。许多管理员在部署VMware集群时,会本能地选择最简单的Access口配置——毕竟它能快速让系统跑起来,…...