Cascade-MVSNet论文笔记
Cascade-MVSNet论文笔记
- 摘要
- 1 立体匹配(Stereo Matching)
- 2 多视图立体视觉(Multi-View Stereo)
- 3 立体视觉和立体视觉的高分辨率输出
- 4 代价体表达方式(Cost volume Formulation)
- 4.1 多视图立体视觉的3D代价体(3D Cost Volumes in Multi-View Stereo)
- 4.2 立体匹配的3D代价体(3D Cost Volumes in Stereo Matching)
- 5 级联代价体(Cascade Cost Volume)
- 5.1 假设范围(Hypothesis Range)
- 5.2 假设平面间隔(Hypothesis Plane Interval)
- 5.3 假设平面数(Number of Hypothesis Planes)
- 5.4 空间分辨率(Spatial Resolution)
- 5.5 翘曲操作或视图变换操作(Warping Operation)
- 6 特征金子塔(Feature Pyramid)
- 7 损失函数
- 8 实验分析
- 8.1 实验数据集
- 8.2 实验比较
X. Gu, Z. Fan, S. Zhu, Z. Dai, F. Tan and P. Tan, “Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching,” 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 2020, pp. 2492-2501, doi: 10.1109/CVPR42600.2020.00257.
摘要
在本文中,作者提出了一种基于三维代价体积的多视点立体匹配方法的三维立体匹配方法。
首先,所提出的代价体是建立在一个特征金字塔编码的几何形状并且背景在逐渐更精细的尺度上。
然后,通过对前一个阶段的预测来缩小每个阶段的深度(或视差)范围。
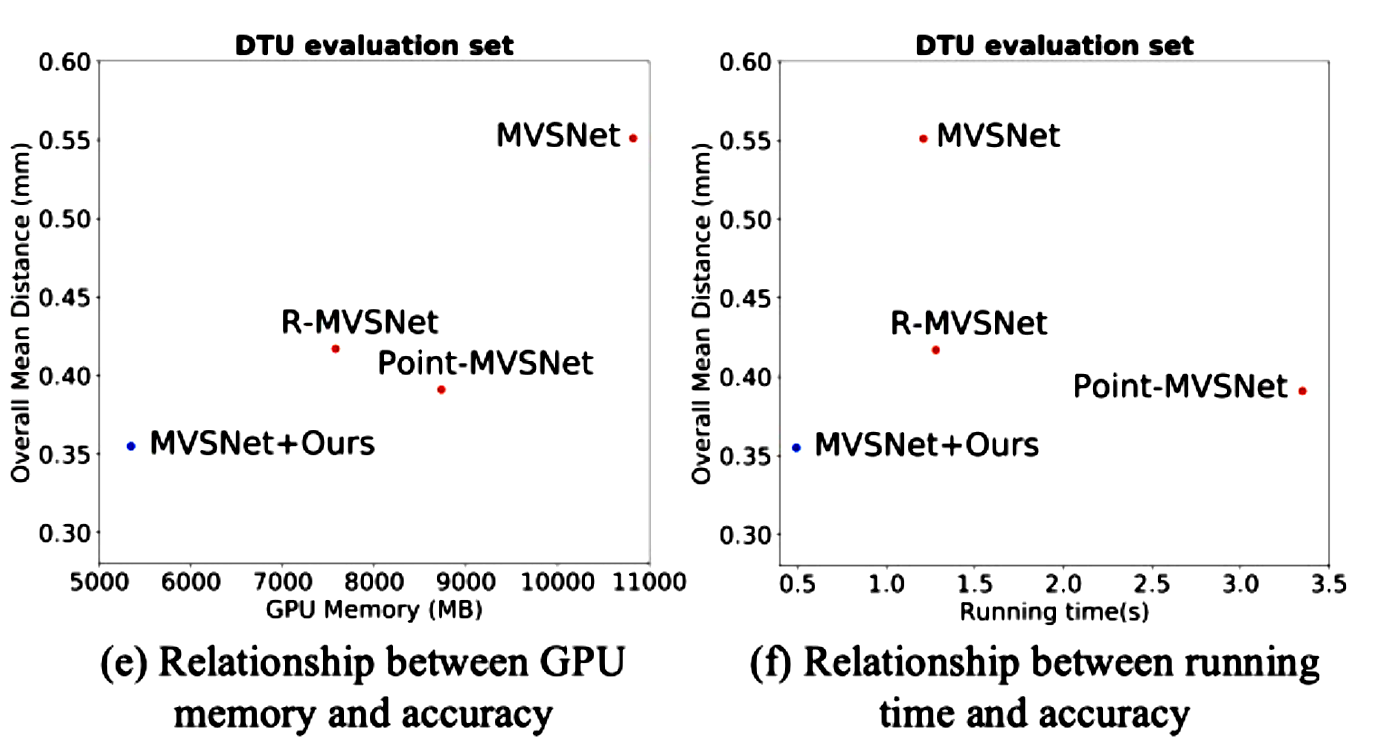
随着越来越高的代价体积分辨率和深度(或视差)间隔的自适应调整,获得由粗到精细的输出。将级联代价体应用到具有代表性的MVS-Net上,比DTU基准(第一名)提高了35.6%,GPU内存和运行时分别减少了50.6%和59.3%。
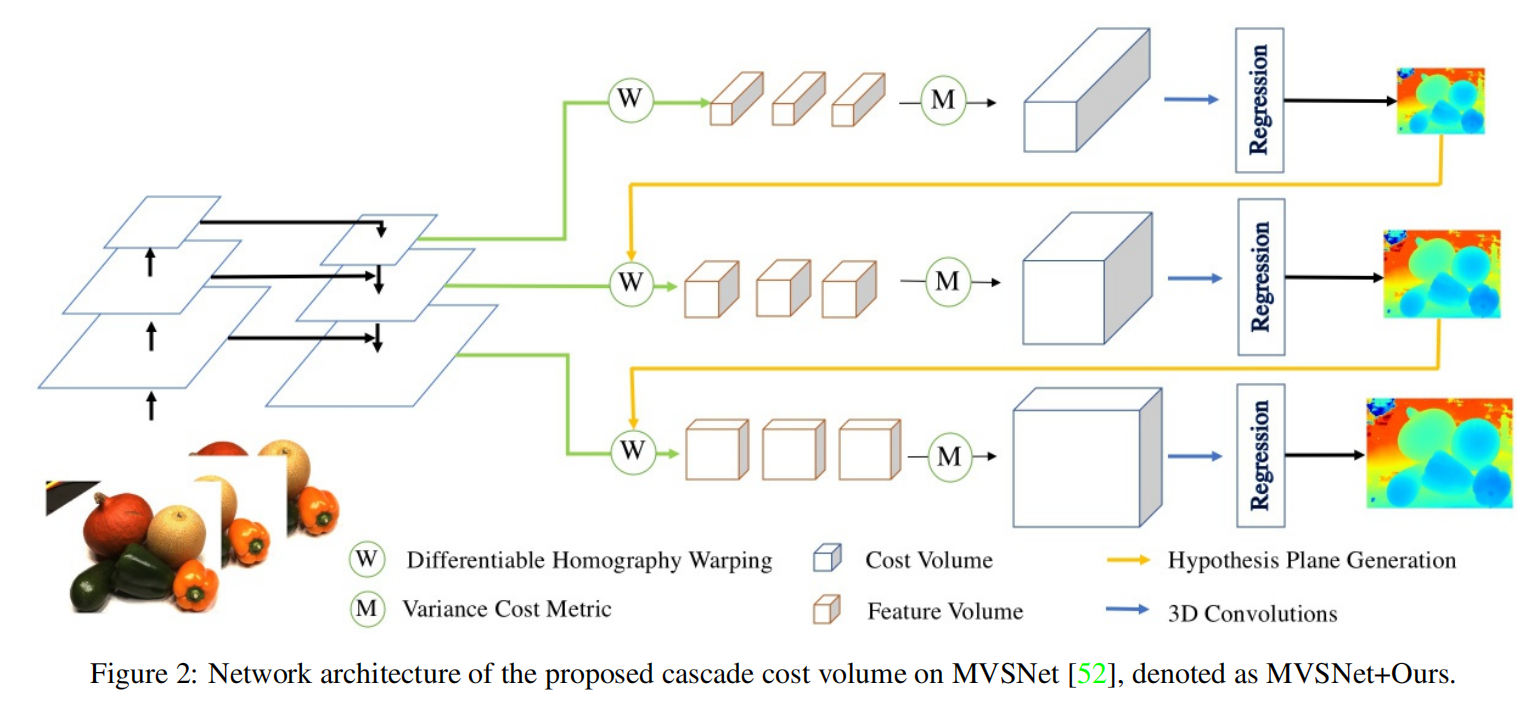
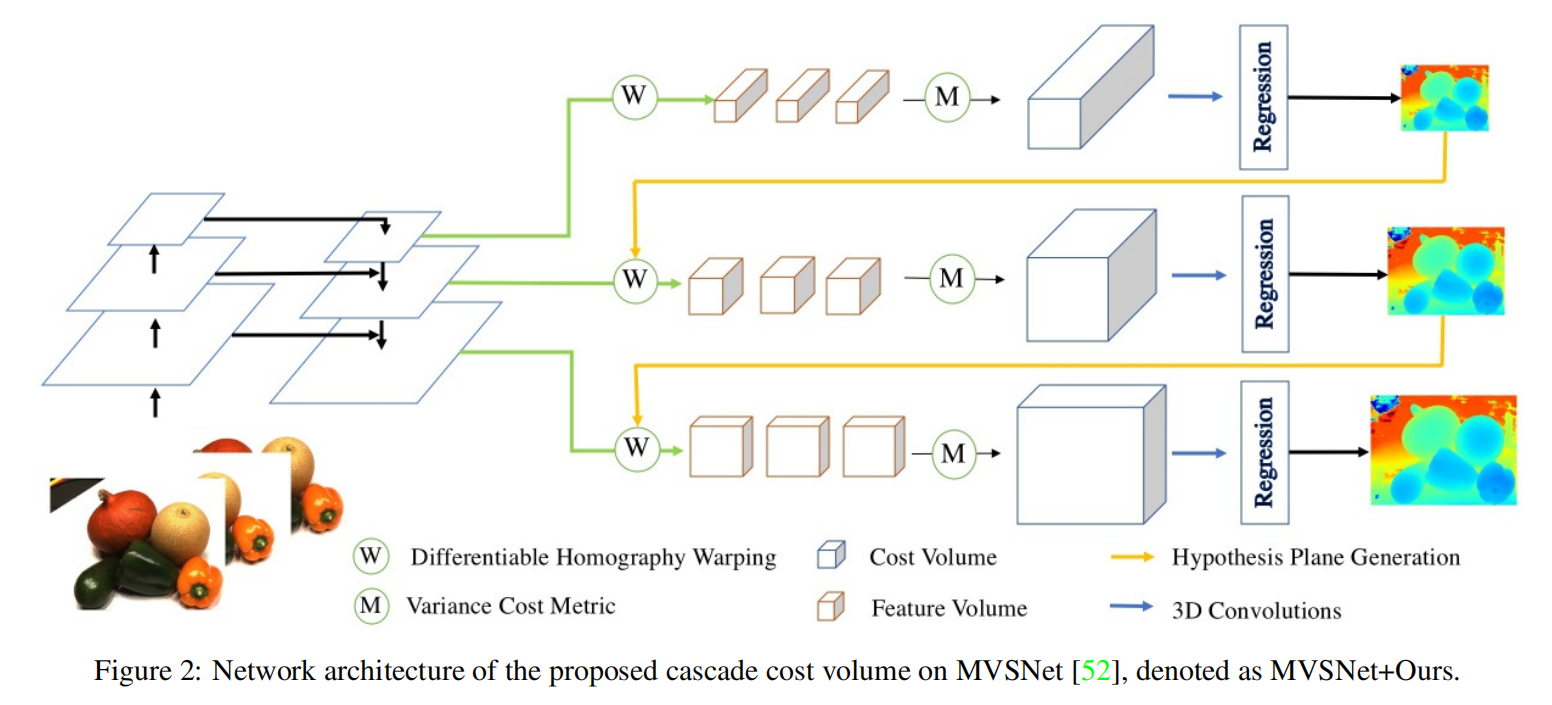
网络结构:
1 立体匹配(Stereo Matching)
一个典型的立体匹配算法包括四个步骤:匹配代价计算、匹配代价聚合、视差计算和视差细化。局部方法与相邻像素聚合匹配代价,通常利用赢家通吃策略来选择最优视差。全局方法构造一个能量函数,并试图将其最小化以找到最优视差。更进一步地方法利用信念传播和半全局匹配进行动态规划逼近全局优化。
在深度神经网络的背景下,Zbontar和LeCun首先引入了基于CNN的立体匹配方法,其中引入了卷积神经网络来学习小斑块对的相似性度量。在GCNet中首次在立体匹配中引入了广泛使用的3D代价体,其中视差回归步骤使用soft argmin操作来找出最佳匹配结果。PSMNet 进一步引入了金字塔空间池和三维沙漏网络进行代价体正则化,得到了更好的结果。GwcNet 修改了三维沙漏的结构,并引入了组间的相关性,形成了一个基于组间的3D代价体。DeepPruner是一种从粗到细的方法,它提出了一种基于可微分补丁匹配的模块来预测每个像素的剪枝搜索范围。
2 多视图立体视觉(Multi-View Stereo)
传统的多视图立体视觉大致可分为基于体素方法(估计每个体素与表面之间的关系);基于点云的方法(直接处理三维点来迭代强化结果);深度图重建方法(它只使用一个参考和少量源图像进行单深度图估计)。对于大规模的运动结构(SFM,Structure-from-Motion)中的工作使用基于分布式运动平均和全局相机共视的分布式方法。
现如今,基于学习的方法在多视图立体视觉也表现出了优越的性能。多补丁相似度引入了一个学习的代价度量。 SurfaceNet和DeepMVS将多视图图像预扭曲到三维空间,并使用深度网络进行正则化和聚合。近些年,提出了基于3D代价体的多视图立体视觉技术。基于多视图扭曲的二维图像特征构建三维代价体,并应用三维CNN进行代价正则化和深度回归。由于3D CNN需要较大的GPU内存,这些方法通常使用下采样的代价体。实现高分辨率的代价体,并进一步提高精度、计算速度和GPU内存效率,是目前研究的热点。
3 立体视觉和立体视觉的高分辨率输出
目前,有一些基于学习的方法试图减少内存需求,以产生高分辨率的输出。Point MVSNet不使用体素网格,而是使用小的代价体来生成粗深度,并使用基于点的迭代细化网络来输出全分辨率深度。相比之下,一个标准的MVSNet结合级联代价体可以比Point MVSNet 使用更少的运行时间和GPU内存,输出全分辨率深度和优越的精度。还有区分高级空间以减少内存消耗,并构建一个缺乏灵活性的固定代价体表示的方法。另外还有用2D CNN建立额外的细化模块,输出高精度的预测。
4 代价体表达方式(Cost volume Formulation)
基于学习的多视图立体视觉和立体匹配构造三维代价体来度量相应图像补丁之间的相似性,并确定它们是否匹配。在多视图立体视觉和立体匹配中构建三维代价体需要三个主要步骤。首先,确定离散假设的深度(或视差)平面。然后,将提取的每个视图的二维特征扭曲到假设平面上,构建特征体,最后将其融合在一起,构建三维代价。像素级的代价计算通常在固有的不适定区域中是模糊的,如遮挡区域、重复模式、无纹理区域和反射表面。为了解决这个问题,通常引入多尺度的3D CNN来聚合上下文信息,并正则可能的噪声污染代价体。
4.1 多视图立体视觉的3D代价体(3D Cost Volumes in Multi-View Stereo)
MVSNet 提出使用不同深度的前段到平行平面作为假设平面,深度范围一般由稀疏重建决定。坐标映射由单应性确定:
H i ( d ) = K i ⋅ R i ⋅ ( I − ( t 1 − t i ) ⋅ n 1 T d ) ⋅ R 1 T ⋅ K 1 − 1 ( 1 ) H_i(d)=K_i \cdot R_i \cdot\left(I-\frac{\left(t_1-t_i\right) \cdot n_1^T}{d}\right) \cdot R_1^T \cdot K_1^{-1} ~~~~ (1) Hi(d)=Ki⋅Ri⋅(I−d(t1−ti)⋅n1T)⋅R1T⋅K1−1 (1)
其中Hi(d)是指第i个视图的特征图与深度d的参考特征图之间的单应性。Ki、Ri、ti分别为相机的内参、第i个视图的旋转矩阵和平移,n1为参考相机的主轴。然后利用可微单应性变换扭曲二维特征图到参考相机的假设平面,形成特征体积。为了将多个特征体汇总为一个代价体,提出基于方差的代价度量来适应任意数量输入的特征体。
4.2 立体匹配的3D代价体(3D Cost Volumes in Stereo Matching)
PSMNet使用视差分层作为假设平面,视差的范围是根据特定的场景来设计的。由于左右图像已被校正,因此坐标映射由x轴方向上的偏移量决定:
C r ( d ) = X l − d ( 2 ) C_r(d) = X_l − d ~~~~(2) Cr(d)=Xl−d (2)
其中, C r ( d ) C_r (d) Cr(d)为右视图在视差d处转换后的x轴坐标, X l X_l Xl为左视图的源x轴坐标。为了构建特征t体,使用沿x轴的平移,将右视图的特征图扭曲到左视图。有多种方法可以构建最终的代价体。GCNet 和PSMNet在不减少特征维度的情况下将左侧特征体和右特征体连接起来。还有人提出使用绝对差值的和来计算匹配代价。DispNetC计算关于左特征体和右特征体的完全相关性并为每个视差级别产生只一个单通道相关图。GwcNet 提出组间相关性,将特征分成组并计算每一组的相关图。
5 级联代价体(Cascade Cost Volume)
下图展示了W×H×D×F的分辨率的标准代价体,其中W×H表示空间分辨率,D是平面假设的数量,F是特征图的通道数。随着平面假设D的数量的增加,更大的空间分辨率W×H和更细的平面间隔可能提高重建精度。然而,GPU内存和运行时间随着代价体分辨率的增加而不断增长。正如R-MVSNet所示,MVSNet能够在16 GB Tesla P100 GPU上处理最大H×W×D×F=1600×1184×256×32的代价体。为了解决上述问题,Cascade MVSNet提出了一个级联代价体公式,并以粗到细的方式预测输出。

5.1 假设范围(Hypothesis Range)
如下图所示,用R1表示的第一阶段的深度(或视差)范围覆盖输入场景的整个深度(或视差)范围。在接下来的阶段中,可以基于前一个阶段的预测输出,并缩小假设范围。因此,有Rk+1 = Rk·wk,其中Rk是第k个阶段的假设范围,wk < 1是假设范围的缩小因子。

5.2 假设平面间隔(Hypothesis Plane Interval)
在第一阶段的深度(或视差)间隔为I1。与通常采用的单代价体公式相比,初始假设平面区间相对较大,可以产生一个粗糙的深度(或视差)估计。在接下来的阶段中,将应用更精细的假设平面区间来恢复更详细的输出。因此,有 Ik+1 = Ik·pk,其中Ik为第k阶段的假设平面区间,pk < 1是假设平面区间的缩小因子。
5.3 假设平面数(Number of Hypothesis Planes)
在第k阶段,给定假设范围Rk和假设平面区间Ik,相应的假设平面数Dk被确定为 Dk = Rk/Ik。当一个代价体的空间分辨率被固定,一个更大的Dk可以获得更多的假设平面和更准确的结果,同时导致增加的GPU内存和运行时间。基于级联公式,可以有效地减少假设平面的总数,因为假设范围是逐步显著减少的,同时仍然覆盖了整个输出范围。
5.4 空间分辨率(Spatial Resolution)
根据特征金字塔网络的实践,在每个阶段将代价体的空间分辨率增加一倍,并将输入特征图的空间分辨率增加一倍。将N定义为级联代价体的总阶段数,然后将第k阶段代价体的空间分辨率定义为 W / 2 N − k × H / 2 N − k W/2^{N−k}×H/2^{N−k} W/2N−k×H/2N−k。我们在多视图立体视觉任务中设置N = 3,在立体匹配任务中设置N = 2。
5.5 翘曲操作或视图变换操作(Warping Operation)
将级联代价体公式应用于多视图立体视觉,基于公式1,将(k+1)阶段的单应性变换改写为:
H i ( d k m + Δ k + 1 m ) = K i ⋅ R i ⋅ ( I − ( t 1 − t i ) ⋅ n 1 T d k m + Δ k + 1 m ) ⋅ R 1 T ⋅ K 1 − 1 ( 3 ) H_i\left(d_k^m+\Delta_{k+1}^m\right)=K_i \cdot R_i \cdot\left(I-\frac{\left(t_1-t_i\right) \cdot n_1^T}{d_k^m+\Delta_{k+1}^m}\right) \cdot R_1^T \cdot K_1^{-1}~~~~(3) Hi(dkm+Δk+1m)=Ki⋅Ri⋅(I−dkm+Δk+1m(t1−ti)⋅n1T)⋅R1T⋅K1−1 (3)
其中 d k m d_k^m dkm为第k阶段第m个像素的预测深度, ∆ k + 1 m ∆_{k+1}^m ∆k+1m为第k+阶段学习的第m个像素的深度差值。
类似地,在立体匹配中,根据级联代价体重新制定公式2。第k+1阶段的第m个像素坐标映射表示为:
C r ( d k m + Δ k + 1 m ) = X l − ( d k m + Δ k + 1 m ) ( 4 ) C_r\left(d_k^m+\Delta_{k+1}^m\right) = X_l − \left(d_k^m+\Delta_{k+1}^m\right) ~~~~(4) Cr(dkm+Δk+1m)=Xl−(dkm+Δk+1m) (4)
其中 d k m d_k^m dkm为第k阶段第m个像素的预测视差, ∆ k + 1 m ∆_{k+1}^m ∆k+1m为第k+1阶段学习的第m个像素的差值。
6 特征金子塔(Feature Pyramid)
为了获得高分辨率的深度(或视差)地图,通常使用标准代价体生成一个相对低分辨率的深度(或视差)图,然后用2D CNN进行上采样和细化。标准代价体是使用高阶段特征图构建的,该特征图包含高级的语义特征,但缺乏低级的更精细的表示。Cascade-MVSNet参考了特征金字塔网络,并采用其具有增加空间分辨率的特征图来构建更高分辨率的代价体。例如,当将级联代价体应用到MVSNet 时,从特征金字塔网络的特征映射{P1、P2、P3}中构建了三个代价体。如下图所示,它们对应的空间分辨率分别为输入图像大小的{1/16、1/4、1}。
7 损失函数
N阶段的级联代价体产生N−1的中间输出和最终预测。对所有输出进行监督,总损失定义为:
Loss = ∑ k = 1 N λ k ⋅ L k ( 5 ) \text { Loss }=\sum_{k=1}^N \lambda^k \cdot L^k~~~~(5) Loss =k=1∑Nλk⋅Lk (5)
其中 L k L^k Lk为第k阶段的损失, λ k λ^k λk为对应的损失权重。在实验中采用与MVSNet相同的损失函数 L k L^k Lk。
8 实验分析
8.1 实验数据集
DTU是一个大规模的MVS数据集,由124个不同的场景组成,在7种不同的光照条件下,在49或64个位置进行扫描。坦克和寺庙数据集(Tanks and Temples dataset)包含具有小深度范围的真实场景。更具体地,它的中间场景由8个场景组成,包括家庭,弗朗西斯,马,灯塔,M60,黑豹,操场和火车。使用DTU训练集来训练Cascade-MVSNet,并在DTU评价集上进行测试。为了验证Cascade-MVSNet的泛化性,Cascade-MVSNet还在坦克和模板数据集的中间集上使用在DTU数据集上训练的不进行任何微调的模型进行测试。
8.2 实验比较
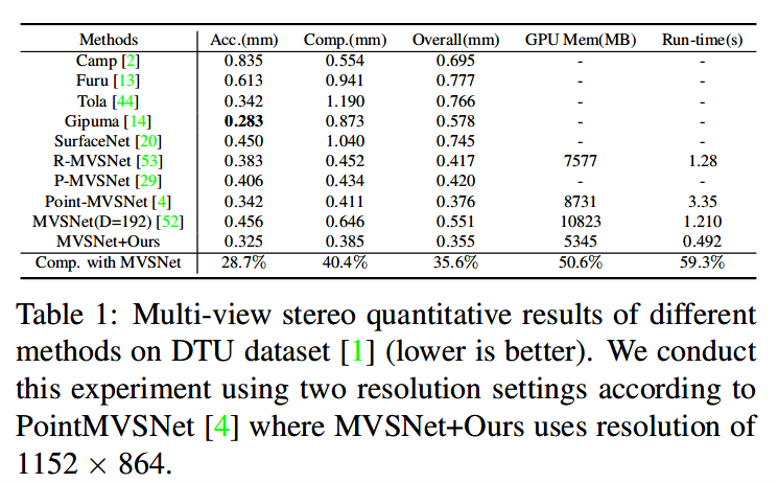
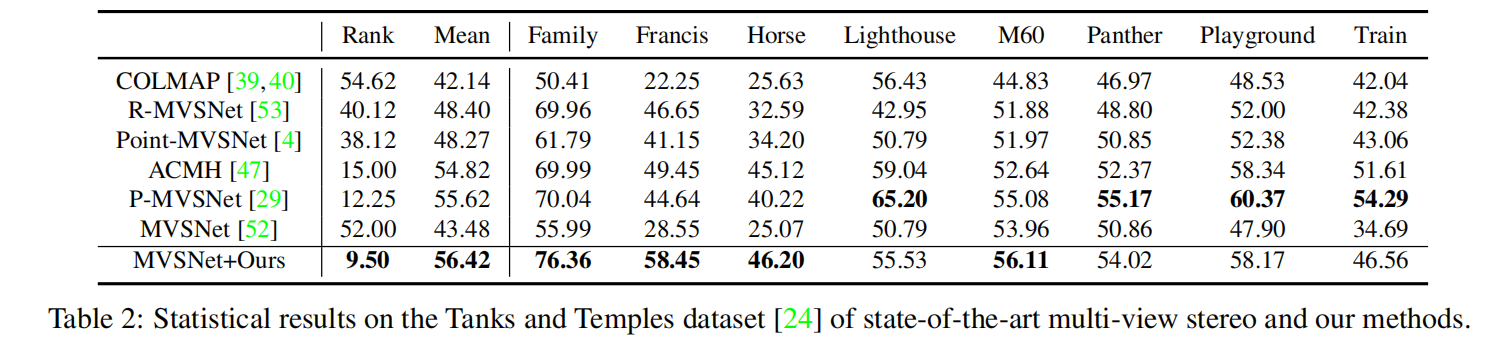
MVSNet+Ours(Cascade-MVSNet)在DTU和Tanks and Temples数据集上的表现都是最佳的。

MVSNet+Ours(Cascade-MVSNet)生成了更完整的点云与更精细的细节。除了R-MVSNet 提供了具有后处理方法的点云结果外,其它都是通过运行它们提供的预训练模型和代码来获得上述方法的结果。

相关文章:
Cascade-MVSNet论文笔记
Cascade-MVSNet论文笔记 摘要1 立体匹配(Stereo Matching)2 多视图立体视觉(Multi-View Stereo)3 立体视觉和立体视觉的高分辨率输出4 代价体表达方式(Cost volume Formulation)4.1 多视图立体视觉的3D代价…...
Linux调试器---gdb的使用
顾得泉:个人主页 个人专栏:《Linux操作系统》 《C/C》 键盘敲烂,年薪百万! 一、gdb的背景 gdb,全称为GNU调试器(GNU Debugger),是一个功能强大的源代码级调试工具,主要…...
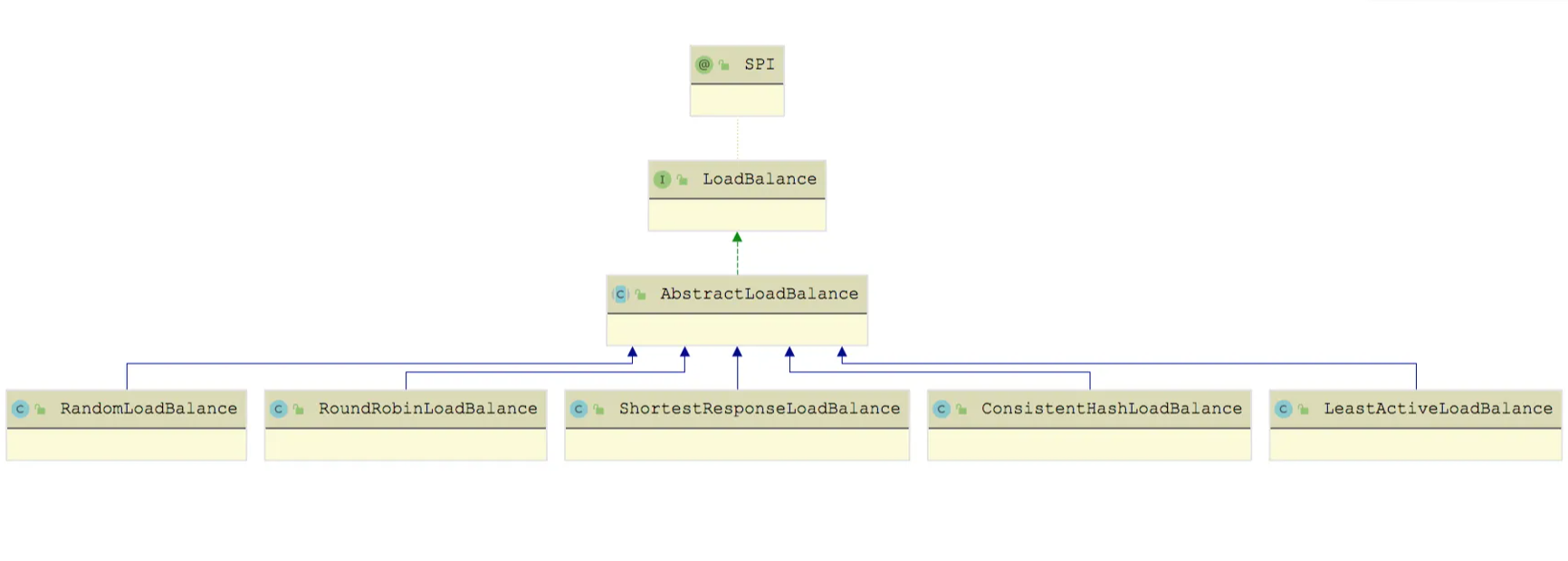
【Dubbo】Dubbo负载均衡实现解析
📫作者简介:小明java问道之路,2022年度博客之星全国TOP3,专注于后端、中间件、计算机底层、架构设计演进与稳定性建设优化,文章内容兼具广度、深度、大厂技术方案,对待技术喜欢推理加验证,就职于…...

怎样备份电脑文件比较安全
域智盾软件是一款功能强大的电脑监控软件,它不仅具备实时屏幕监控、行为审计等功能,还能够对电脑文件进行备份和管理。下面将介绍域智盾软件如何备份电脑文件,以确保数据安全。 1、开启文档备份功能 部署后台,然后点击文档安全&a…...

python 计算最大回撤
1. 什么是最大回撤 最大回撤是评估金融产品收益的一个非常重要的风险指标,它指的是在选定历史周期内任一历史时点往后推,产品净值走到最低点时的收益率回撤幅度的最大值。 以上图为例, 最大回撤 ( V a l u e A − V a l u e B ) V a l u e …...

Linux系统中常用的压缩与解压缩方法
目录 一.前言二.如何压缩与解压缩 一.前言 Linux系统中压缩和解压缩的方法很多,这篇文章只简单介绍一下使用tar和gzip进行压缩与解压缩。 二.如何压缩与解压缩 tar和gzip命令内容很多,这篇文章只是简单介绍一下。 1.看一下gzip命令压缩与解压缩方法。…...
)
目标检测YOLO实战应用案例100讲-基于机器视觉的水稻病虫害监测预警(续)
目录 3.3 试验结果与分析 3.3.1 数据集介绍 3.3.3 评价标准 3.3.4 模型训练参数设置...

【星海随笔】redis 解析
redis 非关系型数据库 支持事务,操作都是原子性 所谓的原子性就是对数据的更改要么全部执行,要么全部不执行。 redis-server:顾名思义,redis服务 redis-cli:redis client,提供一个redis客户端,…...
鸿蒙:实现两个Page页面跳转
效果展示 这篇博文在《鸿蒙:从0到“Hello Harmony”》基础上实现两个Page页面跳转 1.构建第一个页面 第一个页面就是“Hello Harmony”,把文件名和显示内容都改一下,改成“FirstPage”,再添加一个“Next”按钮。 Entry Compone…...

C#有关里氏替换原则的经典问题答疑
目录 理解创建类型与变量类型很关键 先来理解变量类型。 再来理解创建类型。 有了正确的理解再来看疑问 里氏替换原则是面向对象七大原则中最重要的原则。 语法表现:父类容器装子类对象。 namespace 里氏替换原则 {class GameObject { } class Player : GameO…...
【每日一题】689. 三个无重叠子数组的最大和-2023.11.19
题目: 689. 三个无重叠子数组的最大和 给你一个整数数组 nums 和一个整数 k ,找出三个长度为 k 、互不重叠、且全部数字和(3 * k 项)最大的子数组,并返回这三个子数组。 以下标的数组形式返回结果,数组中…...

“开源 vs. 闭源:大模型的未来发展趋势预测“——探讨大模型未来的发展方向
文章目录 每日一句正能量前言什么是大模型的开源与闭源开源与闭源的定义和特点开源的意义开源和闭源的优劣势比较不同的大模型企业,开源、闭源的策略不尽相同。企业在开发垂类模型时选择开源还是闭源大模型开源vs 闭源:两者并非选择题后记 每日一句正能量…...

计算机网络——物理层-信道的极限容量(奈奎斯特公式、香农公式)
目录 介绍 奈氏准则 香农公式 介绍 信号在传输过程中,会受到各种因素的影响。 如图所示,这是一个数字信号。 当它通过实际的信道后,波形会产生失真;当失真不严重时,在输出端还可根据已失真的波形还原出发送的码元…...

【算法挨揍日记】day31——673. 最长递增子序列的个数、646. 最长数对链
673. 最长递增子序列的个数 673. 最长递增子序列的个数 题目解析: 给定一个未排序的整数数组 nums , 返回最长递增子序列的个数 。 注意 这个数列必须是 严格 递增的。 解题思路: 算法思路: 1. 状态表⽰: 先尝试…...
Jmeter做接口测试
1.Jmeter的安装以及环境变量的配置 Jmeter是基于java语法开发的接口测试以及性能测试的工具。 jdk:17 (最新的Jeknins,只能支持到17) jmeter:5.6 官网:http://jmeter.apache.org/download_jmeter.cgi 认识JMeter的目录࿱…...

第14届蓝桥杯青少组python试题解析:23年5月省赛
选择题 T1. 执行以下代码,输出结果是()。 lst "abc" print(lstlst)abcabc abc lstlst abcabc T2. 执行以下代码,输出的结果是()。 age {16,18,17} print(type(sorted(age)))<class set&…...
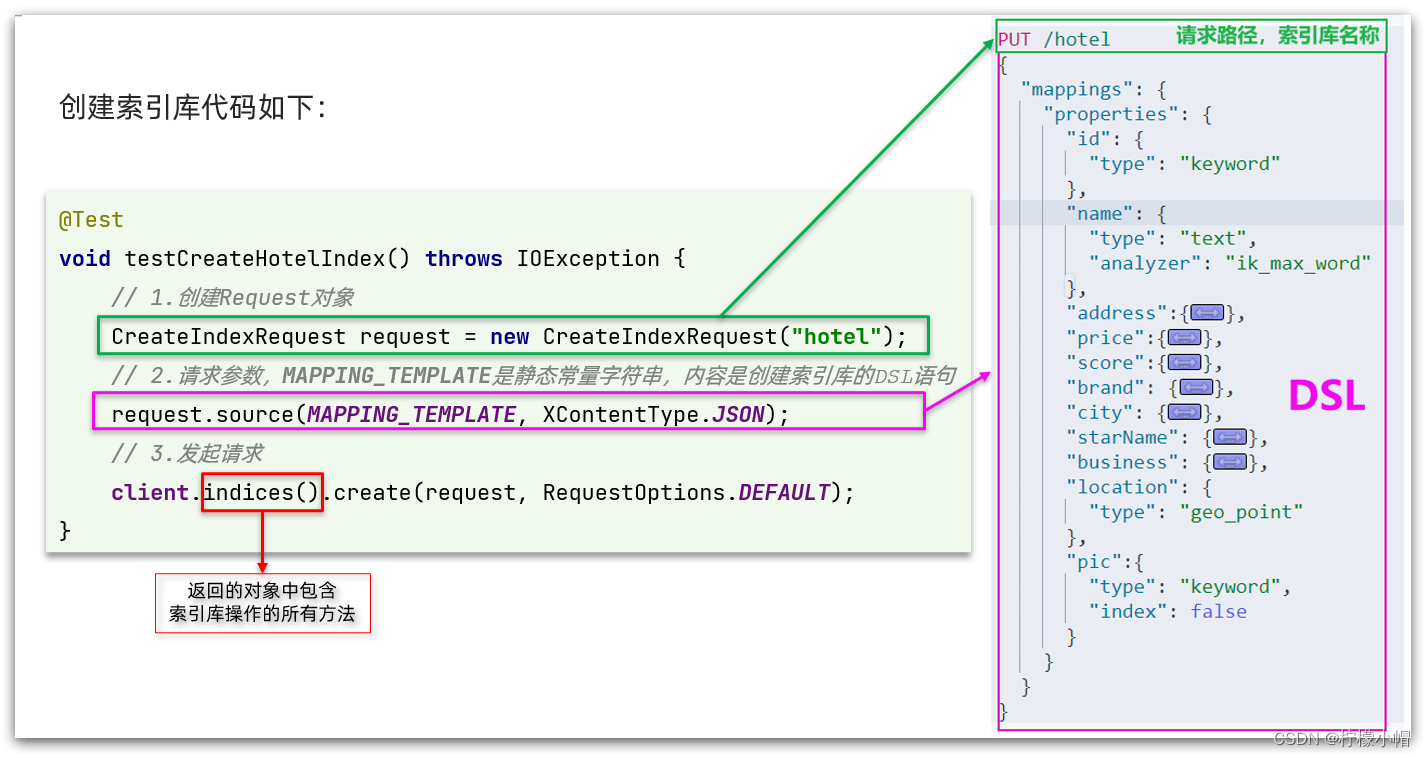
SpringCloud 微服务全栈体系(十四)
第十一章 分布式搜索引擎 elasticsearch 四、RestAPI ES 官方提供了各种不同语言的客户端,用来操作 ES。这些客户端的本质就是组装 DSL 语句,通过 http 请求发送给 ES。官方文档地址:https://www.elastic.co/guide/en/elasticsearch/client/…...

【开题报告】基于微信小程序的个人健康管理系统的设计与实现
1.选题背景与意义 在现代社会,人们对健康的关注日益增加。随着生活方式的变化和工作压力的增加,许多人意识到保持良好的身体健康对于提高生活质量和幸福感的重要性。 然而,许多人在日常生活中缺乏对自身健康状况的了解和管理。他们可能没有…...

Swagger笔记
一、导包 <!--引入swagger--> <dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId><version>2.9.2</version> </dependency> <!--前端的UI界面--> <dependency><…...
数据结构 堆
手写堆,而非stl中的堆 如何手写一个堆? //将数组建成堆 <O(n) for (int i n / 2;i;i--) //从n/2开始down down(i); 从n/2元素开始down,最下面一层元素的个数是n/2,其余上面的元素的个数是n/2,从最下面一层到最高层…...

PotPlayer字幕翻译插件:5分钟实现外语影视无障碍观看的终极免费方案
PotPlayer字幕翻译插件:5分钟实现外语影视无障碍观看的终极免费方案 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu 还在为…...

聚合芘环石墨炔:机器学习模拟揭示新型二维碳负极材料的储锂潜力
1. 项目概述:从石墨烯到PolyPyGY,二维碳负极材料的进阶之路在锂离子电池这个已经相当成熟的领域里,负极材料的创新一直是推动能量密度和功率密度突破的关键。从早期的石墨,到后来的硅基材料,再到如今备受瞩目的二维材料…...

Decompyle++:Python字节码源码恢复实战指南
1. 这不是“反编译”,是字节码层面的源码重建——为什么Decompyle成了Python逆向事实标准你有没有遇到过这样的情况:接手一个只有.pyc文件的遗留项目,没有源码,连__pycache__目录都被人删干净了;或者审计第三方SDK时&a…...

告别K-Means!用Python手撸Science上的DPC算法,搞定任意形状数据聚类
密度峰值聚类DPC:用Python突破传统K-Means的局限当面对螺旋形、环形或交叉分布的数据集时,许多数据科学从业者都有过这样的经历:反复调整K-Means参数却始终无法获得理想的聚类效果。这正是2014年发表在《Science》上的密度峰值聚类算法(DPC)要…...
)
不只是安装:用Carla+Win11快速搭建你的第一个自动驾驶测试场景(手把手教程)
从零到一:用Carla在Win11上构建自动驾驶测试场景的实战指南当你第一次启动Carla仿真环境,看到那个空荡荡的数字化城市时,是否感到既兴奋又迷茫?作为一款开源的自动驾驶仿真平台,Carla的真正价值不在于安装过程…...
)
保姆级教程:在Ubuntu 20.04上从源码编译安装SUMO 1.19.0(含环境变量配置避坑指南)
从源码构建SUMO 1.19.0:Ubuntu 20.04深度编译指南与排错实战在交通仿真领域,SUMO(Simulation of Urban MObility)作为开源微观仿真工具链的核心,其源码编译安装能为研究者带来三大不可替代的优势:定制化模块…...

昇腾CANN cann-spack-package:Spack 包管理器的 CANN 集成实战
HPC(高性能计算)圈子里不用 pip 和 conda——用 Spack。Spack 是一个专为科学计算设计的包管理器,能同时管理一个软件包的多个版本(不同编译器、不同依赖版本、不同架构),每个变体独立安装在 spack/opt/ 下…...

【应用实战】基于Dify与多Agent的凭证与档案管理
一、智能文档处理:基于Dify与多Agent的凭证与档案管理革新 在金融行业,文档处理贯穿业务始终。传统的纯人工方式不仅耗时费力,而且极易出错。智能文档处理(Intelligent Document Processing, IDP)融合了OCR、自然语言处…...

AlphaStar强化学习工程范式:从星际争霸到工业决策
1. 这不是“下棋”的升级版:AlphaStar 的强化学习到底在学什么? 很多人第一次听说 AlphaStar,第一反应是:“哦,又一个打败人类的AI,跟 AlphaGo 差不多吧?”——这个理解偏差非常典型࿰…...

跨系统数据搬运总是要靠人工复制粘贴?2026智能体重塑企业数据流转新范式
在2026年的今天,尽管通用人工智能(AGI)已经深度介入生产力环节,但走进多数企业的财务、供应链或人力资源部门,依然能看到员工在多个窗口间频繁切换,机械地重复着CtrlC和CtrlV。这种看似原始的“数据搬运”行…...