关于Hbase的一些问题
HBase
1. RowKey如何设计,设计不好会产生什么后果
唯一原则:在设计上要保持RowKey的唯一性。
- 因为HBase中的数据是以KV的格式来存储的,所以如果向同一张表中插入RowKey相同的数据,旧的数据会被覆盖掉。
长度原则:建议RowKey的长度不要过长最好不要超过十六字节。对齐RowKey长度。
- 因为数据的持久化文件HFile是按照Key Value存储的,如果RowKey的长度过长,会使得文件过大,从而影响HFile的存储效率。
- MemStore将缓存部分数据到内存,如果RowKey的长度过长就会导致内存的有效利用率降低,系统将无法缓存更多的数据,降低检索速率。
散列原则:设计出来的RowKey需要均匀的分布在各个RegionServer上。
- 如果数据分布的不均匀就可能会造成数据倾斜的发生,进一步导致热点问题的出现,最终造成节点崩溃。
2. 列族如何设计,为什么不建议HBase设计过多列族
-
HBase的列族不是越多越好,官方推荐一个表的列族最好不超过三个,过多的列族不利于HBase数据的管理和索引。
-
将所有相关性很强的key_value都放在同一个列族。这样可以增加查询效率,减少访问不同的磁盘文件。
-
列族的长度尽可能小,一个是为了增加查询速率,一个是为了节省空间。
- 内存开销:列族过多,内存开销会逐渐积累,导致RegionServer的内存占用增加,影响集群的稳定性。
- 磁盘开销:过多的列族会导致更多的磁盘寻址和IO操作,增加磁盘开销。
- 查询性能下降:查询跨越多个列族,会影响性能。
- 写入性能下降:写入操作需要锁定列族,列族过多会导致性能下降。
3. HBase读取数据的流程
- Client访问Zookeeper,获取hbase:meta所在的HRegionServer的节点信息;
- Client访问hbase:meta所在的HRegionServer,获取hbase:meta记录的元数据后加载到内存中,然后再从内从中查询出RowKey所在的Hregion(HRegion所在的HRegionServer);
- Client对RowKey所在的HRegion对应的HRegionServer发起读取请求;
- HRegionServer构建RegionScanner(需要查询的RowKey分布在多少个HRegion中就需要构建多少个RegionScanner),用于对该HRegion的数据检索;
- RegionScanner构建StoreScanner(HRegion中有多少个Store就需要构建多少个StoreScanner,Store的数量取决于表中的列族的数量),用于对该列族的检索;
- 所有的StoreScanner合并构建最小堆(已排序的完全二叉树)StoreHeap:PriorityQueue;
- StoreScanner构建一个MemStoreScanner和一个或多个StoreFIleScanner(数量取决于StoreFile的数量);
- 过滤掉能够确定索要查询的RowKey一定不存在的StoreFileScanner或MemStoreScanner(布隆过滤器);
- 经过筛选后留下的Scanner开始做读取数据的准备,将对应的StoreFile定位到满足的RowKey的起始位置;
- 将所有的StoreFileScanner和MemStoreScanner合并构建最小堆KeyValueHeap:PriorityQueue,排序的规则按照KeyValue从小到大排序;
- 从KeyValueHeap:PriorityQueue中经过一系列筛选后一行行的得到需要查询的KeyValue。
4. HBase写入数据的流程
- Client访问ZooKeeper,获取hbase:meta所在的HRegionServer的节点信息;
- Client访问hbase:meta所在的HRegionServer,获取hbase:meta记录的元数据后现加载到内存中,然后再从内存中查询出RowKey所在的HRegion(HRegion所在的HRegionServer);
- Client对RowKey所在的HRegion对应的HRegionServer发起写入请求;
- 建立连接后,首先将DML要做的操作写入到日志HLog;
- 然后将数据的修改更新到MemStore中,本次操作结束。一个HRegion由多个Store组成,一个Store对应一个列族,Store包括位于内存的MemStore和位于磁盘的StoreFile,写入操作先写入MemStore;
- 当MemStore数据达到阈值后(128M),创建一个新的MemStore;
- 旧的MemStore将刷写成为一个独立的StoreFIle(HRegionServer会启动FlushCache进程写入StoreFIle)并存放到HDFS,最后删除HLog中的历史数据。
5. Hive 和 HBase的区别
HBase和Hive都是架构在Hadoop之上的,都使用了HDFS作为底层存储。
不同点:
- Hive是一个数仓工具,可以将结构化数据映射为表格。HBase是一个分布式的非关系型数据库。
- Hive本身并不存储和计算数据,它底层通过Hadoop的MapReduce框架来处理数据。HBase底层使用HDFS和ZooKeeper分布式协调服务来存储和管理数据。
- HBase是物理表,提供了一个超大内存的Hash表,搜索引擎通过它来存储索引,方便查询操作。
- Hive不支持随机写入操作,HBase支持随机写入操作。
- Hive适合查询和分析结构化数据,HBase适合存储和查询非结构化数据。
6. 为什么要使用Phoenix
- 提供标准的SQL以及完备的ACID事务支持;
- 通过利用HBase作为存储,让NoSQL数据库具备通过有模式的方式读取数据,可以使用SQL语句来操作HBase。
- Phoenix通过协处理器在服务器端执行操作,最小化客户机/服务器数据传输。
- Phoenix可以很好地与其他的Hadoop组件整合到一起,例如Spark、Hive等。
Phoenix只是在HBase之上构建了SQL查询引擎,Phoenix可以使用SQl快速查询HBase中的数据,但是数据的底层必须符合HBase的存储结构,HBase结合Phoenix可以实现海量数据的快速随机读写。Phoenix就相当于一个特别好用的皮肤,方便了程序员的操作。
7. HBase的热点Key会产生什么问题
HBase中的热点Key是指在同一时间内被频繁访问的行键,造成少数RegionServer的读写请求过多,负载过大,而其他RegionServer负载却很小,造成热点现象。
- 读写性能下降:由于多个请求涌入到一台RegionServer中,导致该RegionServer的负载过高,从而影响读写性能。
- 均衡性差:由于不同RegionServer负责不同的Region,而热点Key的存在会导致某些RegionServer的负载过高,从而影响整个集群的负载不平衡。
- 单点故障:如果某个RegionServer负责的某个Region出现热点Key问题,该RegionServer发生故障会导致该Region不可用,从而影响整个集群的可用性。
避免HBase的热点Key的方式:
- 合理设计RowKey
- 采用哈希算法对RowKey进行分片,使数据分布更均匀
- 使用预分区技术
8. 说一说HBase的数据刷写与合并
数据刷写(FLush):数据刷写是将内存中的数据写入到磁盘存储的过程。在HBase中,写入的数据首先会被缓存在内存的MemStore中,而不是直接写入磁盘。当MemStore中的数据达到一定大小阈值时,或者出发了一定的时间阈值,HBase会将该MemStore中的数据刷写到磁盘,生成一个新的Store文件。这样可以减少磁盘的随机写入操作,提高写入性能。
数据合并(Comoaction):数据合并是将多个Store文件合并成为一个更大的文件的过程。在HBase中,随着数据的写入和删除,会产生大量的小文件,这样对于查询操作会引入额外的磁盘寻址开销。为了优化性能和减少磁盘空间的占用,HBase会定期执行那个数据合并操作。数据合并会将多个Store文件合并成更大的文件,从而减少文件数量和磁盘寻址次数。
- 触发数据合并的三种方式:MemStore刷盘,后台线程周期性检查,手动触发。
- 小合并(Minor Compaction):当一个Region中的Store文件达到一定的数量或累积了一定大小时,会触发小合并。小合并只会合并相邻的几个Store文件,并生成一个新的更大的文件。
- 不做任何删除数据、多版本数据的清理工作,但是会对 minVersion=0 并且设置 TTL 的过期版本数据进行清理。
- 大合并(Major Compaction):当一个Region中的Store文件数量达到一定阈值,或者手动触发大合并操作时,会执行大合并。大合并会将所有的Store文件都合并为一个更大的文件。大合并 可以进一步优化查询性能和节省磁盘空间,但相应地需要更多的计算和IO资源。
- 清理三类无意义数据:被删除的数据、TTL 过期数据、版本号超过设定版本号的数据。
相关文章:

关于Hbase的一些问题
HBase 1. RowKey如何设计,设计不好会产生什么后果 唯一原则:在设计上要保持RowKey的唯一性。 因为HBase中的数据是以KV的格式来存储的,所以如果向同一张表中插入RowKey相同的数据,旧的数据会被覆盖掉。 长度原则:建…...

level=warning msg=“failed to retrieve runc version: signal: segmentation fault“
安装docker启动后,发现里面没有runc版本信息 目前看是少了runc组件 那我们安装runc https://github.com/opencontainers/runc/releases/download/v1.1.10/runc.amd64 [rootlocalhost ~]# mv runc.amd64 /usr/bin/runc mv:是否覆盖"/usr/bin/runc&q…...

电力工作记录仪、智能安全帽、智能布控球助力智能电网建设
电力行业的建设和发展是国家经济发展的重要支撑,而智能电网作为电力系统的重要组成部分,它的安全高效运行关乎到整个电力系统乃至民生的稳定和安全。为了加快国家经济的发展以及满足人们对电力的需求和用电可靠性的要求,国家早在十二规划中就…...
)
【CSS】各百分比透明度 opacity 对应的 16 进制颜色值(例如:#FFFFFF80)
文章目录 使用:6位颜色值2位透明度值 color: #000000D4; /* 等价于 */ color: #000000; opacity : 0.83; /* 等价于 */ color: #000000; opacity : 83%; 对照表(0:完全透明,1:不透明) 透明度值百分百值十…...

有依次对应关系的数组X、Y、Z,如何排序其中一个X数组,使得另外的数组还与排序完成后的数组相对应(C语言实现)
1. 目的 有依次对应关系的数组X、Y、Z,排序其中一个X数组,使得另外的数组还与排序完成后的数组相对应,并打印出排序完成后的X、Y、Z数组。 2. 具体实现 以下面的这个对应关系为例,进行相应编程实现。 X [3.7,7.7,-6.6,1.5,-4.5…...

Mysql之聚合函数
Mysql之聚合函数 什么是聚合函数常见的聚合函数GROUP BYWITH ROLLUPHAVINGHAVING与WHERE的对比 总结SQL底层原理 什么是聚合函数 对一组数据进行汇总的函数,但是还是返回一个结果 聚合函数也叫聚集,分组函数 常见的聚合函数 1.AVG(): 求平均值 2.SUM() :…...

Flutter笔记:拖拽手势
Flutter笔记 拖拽手势 作者:李俊才 (jcLee95):https://blog.csdn.net/qq_28550263 邮箱 :291148484163.com 本文地址:https://blog.csdn.net/qq_28550263/article/details/134485123 目 录 1. 概述2. 垂直拖…...

软件运维面试题
文章目录 面试题如销售签有一外地客户,要求实施人员在客户现场一周内完成所有项目实施,而标准实施一般为期一个月,针对以上情况实施人员应该如何应对?答案 当你觉得工作的付出和你的收入不成正比的时候你会怎么做?答案 在你进行实…...

代码随想录算法训练营第23期day53|1143.最长公共子序列、1035.不相交的线、53. 最大子序和
目录 一、1143.最长公共子序列 二、1035.不相交的线 三、53. 最大子序和 一、1143.最长公共子序列 力扣题目链接 class Solution { public:int longestCommonSubsequence(string text1, string text2) {vector<vector<int>> dp(text1.size() 1, vector<int…...
MySQL 的执行原理(五)
5.6 再深入查询优化 5.6.1. 全局考虑性能优化 5.6.3.1. 为什么查询速度会慢 在尝试编写快速的查询之前,需要清楚一点,真正重要是响应时间。如果把查询看作是一个任务,那么它由一系列子任务组成,每个子任务都会消耗一定的时间。…...
如何快速将txt类型的日志文件转换为excel表格并进行数据分析报表统计图(如:饼图、折线图、柱状图)?
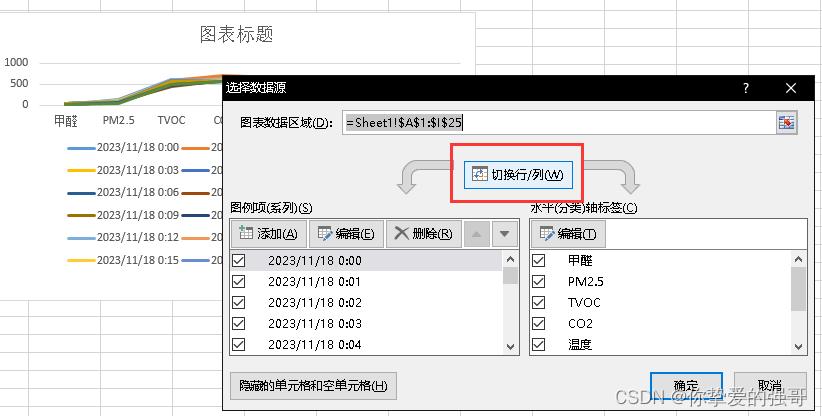
打开excel创建空白文档 选择一个txt文件 一动下面箭头↑竖线,可以拖拽左右调整要判断转换为一列的数据宽度 根据情况设置不同列的数据格式(每一列可以点击),设置好后点击【完成】 设置单元格数据格式 手动插入第一行为每列数据的…...
内网穿透的应用-如何在Docker中部署MinIO服务并结合内网穿透实现公网访问本地管理界面
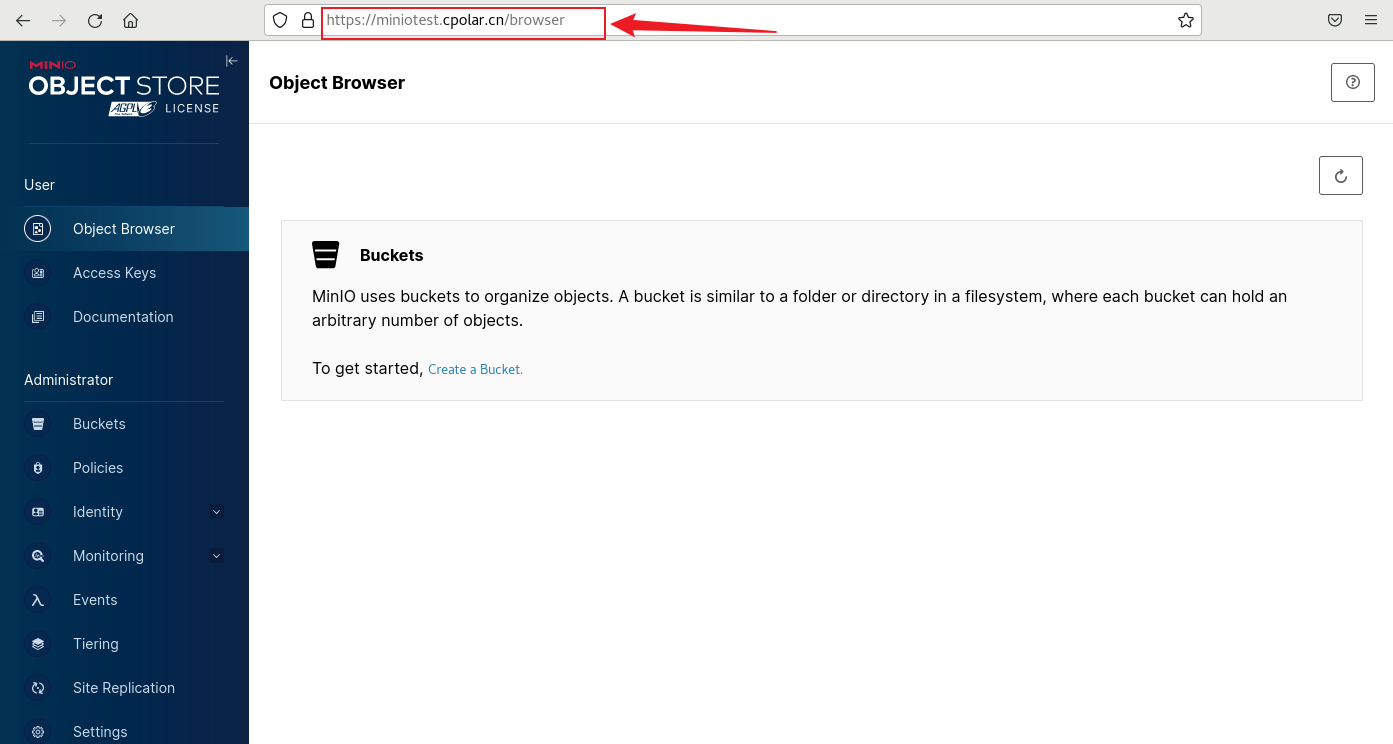
文章目录 前言1. Docker 部署MinIO2. 本地访问MinIO3. Linux安装Cpolar4. 配置MinIO公网地址5. 远程访问MinIO管理界面6. 固定MinIO公网地址 前言 MinIO是一个开源的对象存储服务器,可以在各种环境中运行,例如本地、Docker容器、Kubernetes集群等。它兼…...

关于Unity自带的保存简单且持久化数据PlayerPrefs类的使用
Unity的PlayerPrefs类是用于在游戏中保存和读取玩家偏好设置或其他简单数据的工具。它提供了一种简单的键值对存储方式,可以在游戏中持久化保存数据。 PlayerPrefs提供了三种类型的数据的处理:分别是int,float,string。 具体使用方法如下: …...

力扣贪心——跳跃游戏I和II
1 跳跃游戏 利用边界进行判断,核心就是判定边界,边界内所有步数一定是最小的,然后在这个边界里找能到达的最远地方。 1.1 跳跃游戏I class Solution {public boolean canJump(int[] nums) {int len nums.length;int maxDistance 0;int te…...
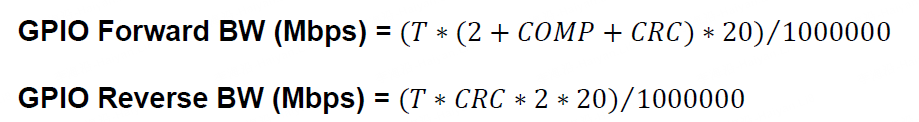
【SA8295P 源码分析 (三)】132 - GMSL2 协议分析 之 GPIO/SPI/I2C/UART 等通迅控制协议带宽消耗计算
【SA8295P 源码分析】132 - GMSL2 协议分析 之 GPIO/SPI/I2C/UART 等通迅控制协议带宽消耗计算 一、GPIO 透传带宽消耗计算二、SPI 通迅带宽消耗计算三、I2C 通迅带宽消耗计算四、UART 通迅带宽消耗计算系列文章汇总见:《【SA8295P 源码分析 (三)】Camera 模块 文章链接汇总 -…...

毕业论文GPT说:
作为一个计算机专业的大四学生,学过英语,微积分,离散数学,概率论与数理统计,线性代数,具体数学,数论,C语言,汇编语言,在网格机算、数据科学、机器学习与智能工…...
Week-T10 数据增强
文章目录 一、准备环境和数据1.环境2. 数据 二、数据增强(增加数据集中样本的多样性)三、将增强后的数据添加到模型中四、开始训练五、自定义增强函数六、一些增强函数 🍨 本文为🔗365天深度学习训练营 中的学习记录博客…...

史上最全!PMP实用应试技巧汇总!
PMP(Project Management Professional 项目管理专业人士资格认证,由全球最大的项目管理专业组织机构——美国PMI发起,目的是用来严格评估管理项目人员知识技能是否具有高品质的资格认证考试。给大家带来关于PMP考试的实用应试技巧。 PMP解题…...
037、目标检测-SSD实现
之——实现 目录 之——简单实现 杂谈 正文 1.类别预测层 2.边界框预测 3.多尺度输出联结做预测(提高预测效率) 4.多尺度实现 5.基本网络块 6.完整模型 杂谈 原理查看:037、目标检测-算法速览-CSDN博客 正文 1.类别预测层 类别预测…...

【开题报告】基于SpringBoot的摄影作品展示网站的设计与实现
1.研究背景 随着社会的发展和人民生活水平的提高,摄影作品已成为一种非常受欢迎的艺术形式。越来越多的人开始对摄影艺术产生兴趣,并且拥有了自己的摄影作品。然而,如何将这些摄影作品展示出来并与其他摄影爱好者进行交流,成为了…...

IEEE 802.11az安全Wi-Fi测距技术解析与应用
1. IEEE 802.11az/bk安全Wi-Fi测距技术深度解析Wi-Fi网络早已超越单纯的通信功能,成为室内定位和距离测量的重要基础设施。想象一下这样的场景:当你走进智能家居环境,灯光自动调节到舒适亮度;在大型商场里,导航系统精准…...

CANN/HCCL算法分析器使用指南
算法分析器使用指导 【免费下载链接】hccl 集合通信库(Huawei Collective Communication Library,简称HCCL)是基于昇腾AI处理器的高性能集合通信库,为计算集群提供高性能、高可靠的通信方案 项目地址: https://gitcode.com/cann…...
CANN/ops-transformer FFA算子设计
1 计算过程 【免费下载链接】ops-transformer 本项目是CANN提供的transformer类大模型算子库,实现网络在NPU上加速计算。 项目地址: https://gitcode.com/cann/ops-transformer 按照FusedFloydAttention正向计算流程实现,整体计算流程如下&#x…...

多智能体粒子群优化的ELM模型预测控制附Matlab代码
✅作者简介:热爱科研的Matlab仿真开发者,擅长毕业设计辅导、数学建模、数据处理、程序设计科研仿真。🍎完整代码获取 定制创新 论文复现点击:Matlab科研工作室👇 关注我领取海量matlab电子书和数学建模资料 dz…...

照片去背景的方法有哪些?2026年最全工具对比指南
最近身边好多朋友问我:"怎样才能快速给照片去掉背景?"无论是做证件照、电商产品图,还是准备社交媒体素材,去背景这个需求几乎每个人都会遇到。我自己用过十来个工具,今天就把这几年的经验整理出来࿰…...

ROS2 Control实战:从URDF到控制器,手把手教你搭建一个可动的仿真机器人
ROS2 Control实战:从URDF到控制器,手把手教你搭建一个可动的仿真机器人 当你已经完成了机器人的URDF建模,看着屏幕上精美的3D模型,是否迫不及待想让它动起来?ROS2 Control正是连接虚拟模型与真实运动的桥梁。不同于简单…...

AC-GAN原理与Keras实现:从零构建条件生成对抗网络
1. 从零开始构建AC-GAN:原理与架构解析在深度学习领域,生成对抗网络(GAN)已经成为图像生成任务的重要框架。而辅助分类器生成对抗网络(AC-GAN)作为GAN的重要变体,通过引入类别信息显著提升了生成…...

FUTURE POLICE入门实操:无需代码,图形化界面完成语音解构
FUTURE POLICE入门实操:无需代码,图形化界面完成语音解构 1. 什么是FUTURE POLICE语音解构系统 想象一下,你有一段会议录音,需要精确到每个字的字幕;或者你有一段采访音频,想要快速找到关键语句的位置。传…...
)
保姆级教程:手把手教你给YOLOv8的SPPF模块换上LSKA注意力(附完整代码)
深度优化YOLOv8:用LSKA注意力重构SPPF模块的实战指南 在目标检测领域,YOLOv8凭借其出色的速度和精度平衡成为工业界和学术界的宠儿。但真正让YOLOv8发挥最大潜力的,往往是对其核心模块的定制化改造。今天我们要探讨的,是如何用最新…...

SenCache:扩散模型推理加速技术解析
1. 项目概述SenCache是一种针对扩散模型(Diffusion Models)的推理加速技术,其核心思想是通过分析模型对不同输入区域的敏感性差异,实现计算资源的动态分配。这项技术特别适合需要实时生成高质量图像的场景,比如游戏内容…...