网络爬虫(Python:Selenium、Scrapy框架;爬虫与反爬虫笔记)
网络爬虫(Python:Selenium、Scrapy框架;爬虫与反爬虫笔记)
- Selenium
- WebDriver 对象提供的相关方法
- 定位元素
- ActionChains的基本使用
- selenium显示等待和隐式等待
- 显示等待
- 隐式等待
- Scrapy(异步网络爬虫框架)
- Scrapy框架
- 反爬虫
- 限制手段
- 反爬虫的分类
- 爬虫与反爬虫-功与防
- 基于身份识别反爬和结局思路
- Headers反爬-通过User-agent字段
- Headers反爬-通过cookie字段
- Headers反爬-通过Referer字段
- 基于请求参数反爬
- 验证码反爬
- 基于爬虫行为反爬和解决思路
- 通过请求ip/账号单位时间内请求频率、次数反爬
- 通过同一ip/账号请求间隔进行反爬
- 通过js实现跳转反爬
- 通过蜜罐(陷阱)捕获ip
- 通过假数据进行反爬
- 阻塞任务队列
- 阻塞网络IO
- 基于数据加密反爬和解决思路
- 通过自定义字体反爬
- 通过js动态生成数据进行反爬
- 通过数据图片化进行反爬
- 通过编码格式进行反爬
Selenium
Selenium是一个模拟浏览器浏览网页的工具,主要用于测试网站的自动化测试工具。
Selenium需要安装浏览器驱动,才能调用浏览器进行自动爬取或自动化测试,常见的包括Chrome、Firefox、IE、PhantomJS等浏览器。
注意:驱动下载解压后,置于Python的安装目录下;然后将Python的安装目录添加到系统环境变量路径(Path)中。
WebDriver 对象提供的相关方法
- close() 方法用于关闭单个窗口
- quit() 方法用于关闭所有窗口
- page_source 属性用于获取网页的源代码
- get(url) 方法用于访问指定的 URL
- title 属性用于获取当前页面的标题
- current_url 用于获取当前页面的 URL
- set_window_size(idth,height) 方法用于设置浏览器的尺寸
- back() 方法用于控制浏览器后退
- forward() 方法用于控制浏览器前进
- refresh() 方法用于刷新当前页面
定位元素
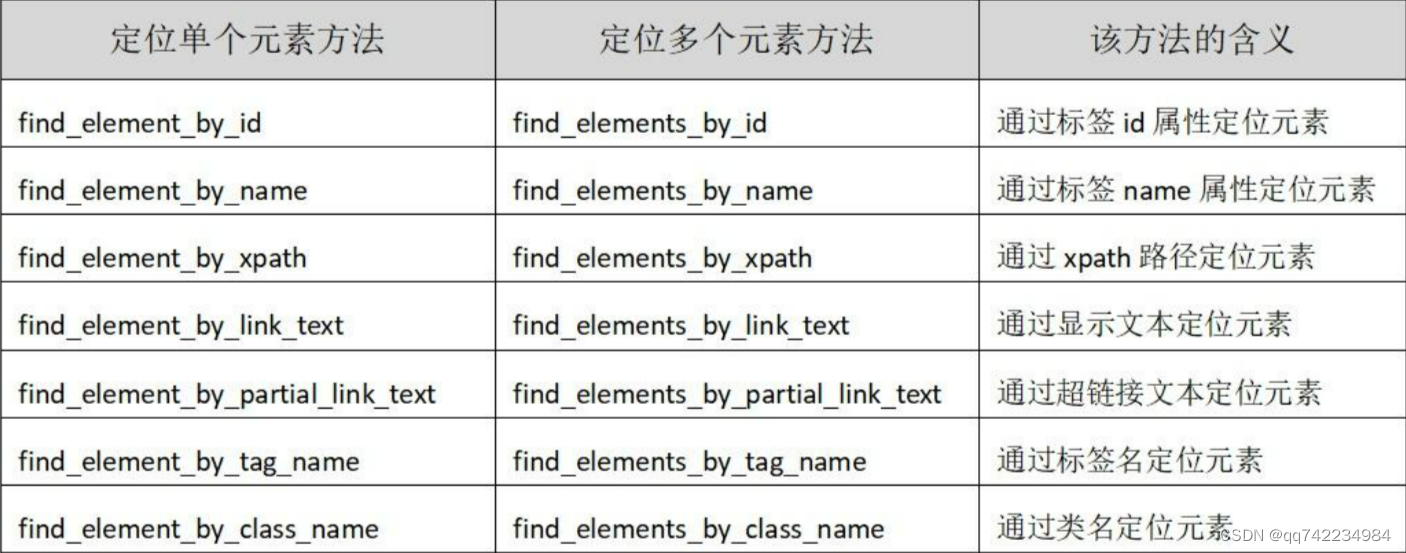
find_elements_by_css_selector("#kw") # 根据选择器进行定位查找,其中#kw表示的是id选择器名称是kw的可以通过 WebElement 对象的相text 属性用于获取元素的文本内容
import timefrom selenium import webdriver#启动浏览器,启动的是chrome浏览器,注意C是大写的
# test_webdriver = webdriver.Chrome()
#调用的phantomjs浏览器
# test_webdriver = webdriver.PhantomJS()
#使用火狐浏览器
test_webdriver = webdriver.Firefox()
#通过get请求的方式请求https://www.echartsjs.com/examples/
test_webdriver.get("https://www.echartsjs.com/examples/")
#浏览器最大化窗口
test_webdriver.maximize_window()
#通过一个for循环来遍历这些数据
#find_elements_by_xpath,注意,双数,方法里面传递的是xpath语句
for item in test_webdriver.find_elements_by_xpath("//h4[@class='chart-title']"):#获取当前节点的textprint(item.text)
#获取当前浏览器的标题
print(test_webdriver.title)
time.sleep(5)
#浏览器退出
test_webdriver.quit()
ActionChains的基本使用
selenium.webdriver.common.action_chains.ActionChains(driver)
click(on_element=None) ——单击鼠标左键
click_and_hold(on_element=None) ——点击鼠标左键,不松开
context_click(on_element=None) ——点击鼠标右键
double_click(on_element=None) ——双击鼠标左键
drag_and_drop(source, target) ——拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset) ——拖拽到某个坐标然后松开
key_down(value, element=None) ——按下某个键盘上的键
key_up(value, element=None) ——松开某个键
move_by_offset(xoffset, yoffset) ——鼠标从当前位置移动到某个坐标
move_to_element(to_element) ——鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset) ——移动到距某个元素(左上角坐标)多少距离的位置
perform() ——执行链中的所有动作
release(on_element=None) ——在某个元素位置松开鼠标左键
send_keys(*keys_to_send) ——发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send) ——发送某个键到指定元素
from selenium import webdriver
import timetest_webdriver = webdriver.Chrome()
test_webdriver.maximize_window()
test_webdriver.get("https://www.baidu.com")
#找到百度首页上的搜索框,发送python
test_webdriver.find_element_by_xpath("//input[@id='kw']").send_keys("python")
#找到百度一下这个按钮,点击一下
test_webdriver.find_element_by_xpath("//input[@id='su']").click()
time.sleep(5)
print(test_webdriver.title)
#获取当前页面的源代码
print(test_webdriver.page_source)
#获取当前的cookie
print(test_webdriver.get_cookies())
test_webdriver.quit()
selenium显示等待和隐式等待
显示等待
明确要等到某个元素的出现或者是某个元素的可点击等条件,等不到,就一直等,除非在规定的时间之内都没找到,就会跳出异常Exception。
WebDriverWait(driver, timeout, poll_frequency=0.5, ignored_exceptions=None)
WebDriverWait()一般由until()或 until_not()方法配合使用
-
until(method, message=’ '):调用该方法提供的驱动程序作为一个参数,直到返回值为True
-
until_not(method, message=’ '):调用该方法提供的驱动程序作为一个参数,直到返回值为False
隐式等待
在创建driver时,为浏览器对象创建一个等待时间,这个方法是得不到某个元素就等待一段时间,直到拿到某个元素位置。
注意:在使用隐式等待的时候,实际上浏览器会在你自己设定的时间内部断的刷新页面去寻找我们需要的元素
driver.implicitly_wait() 默认设置为0
#显示等待
# from selenium import webdriver
# #简写用包
# from selenium.webdriver.common.by import By
# #等待用包
# from selenium.webdriver.support.ui import WebDriverWait
# #场景判断,用来判断某个元素是否出现
# from selenium.webdriver.support import expected_conditions as EC
# import time
#
#
# test_driver = webdriver.Chrome()
# test_driver.maximize_window()
# test_driver.get("https://www.baidu.com")
# #WebDriverWait设置显示等待
# #1、test_driver,2、timeout,3、轮训参数
# #until,EC场景判断,通过id来找相关元素kw
# element = WebDriverWait(test_driver,5,0.5).until(EC.presence_of_element_located((By.ID,'dazhuang')))
# element.send_keys('python')
# time.sleep(2)
# test_driver.quit()#隐式等待
from selenium import webdriver
from selenium.common.exceptions import NoSuchElementException
import timetest_driver = webdriver.Chrome()
test_driver.implicitly_wait(5)
test_driver.get("https://www.baidu.com")
try:test_driver.find_element_by_id('dazhuang').send_keys('python')time.sleep(2)
except NoSuchElementException as e:print('这里报错了')print(e)test_driver.quit()
Chrome无界面浏览器
之前所应用的 Selenium,都是直接操作有界面的浏览器,这就势必会影响爬取数据的速度,而为了尽可能地提高爬取数据的速度,则可以使用 Chrome 无界面浏览器进行数据的爬取,其步骤如下:
- 首先,通过 selenium.webdriver.chrome.options 中的 Options 类创建 Options
对象,用于操作 Chrome 无界面浏览器。 - 其次,使用 Options 对象的 add_argument() 方法启动参数配置,并将该方法中的参数 argument 的值设置为“—headless”,表示使用无界面浏览器。
- 最后,在使用 Chrome 类创建 WebDriver 对象时设置参数 options,并且该参数对应的值需为之前所创建的
Options 对象。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time# 实例化参数的方法
chrome_options = Options()
# 设置浏览器的无头浏览器,无界面,浏览器将不提供界面,linux操作系统无界面情况下就可以运行了
chrome_options.add_argument("--headless")
# 结果devtoolsactiveport文件不存在的报错
chrome_options.add_argument("--no-sandbox")
# 官方推荐的关闭选项,规避一些BUG
chrome_options.add_argument("--disable-gpu")
# 实例化了一个chrome,导入设置项
test_webdriver = webdriver.Chrome(options=chrome_options)
# 最大化
test_webdriver.maximize_window()
# 打开百度
test_webdriver.get("https://www.baidu.com")
# 再输入框里面输入了python
test_webdriver.find_element_by_xpath("//input[@id='kw']").send_keys("python")
# 执行了点击操作
test_webdriver.find_element_by_xpath("//input[@id='su']").click()
time.sleep(2)
# 打印web界面的title
print(test_webdriver.title)
# 浏览器退出
test_webdriver.quit()
Scrapy(异步网络爬虫框架)
Scrapy框架
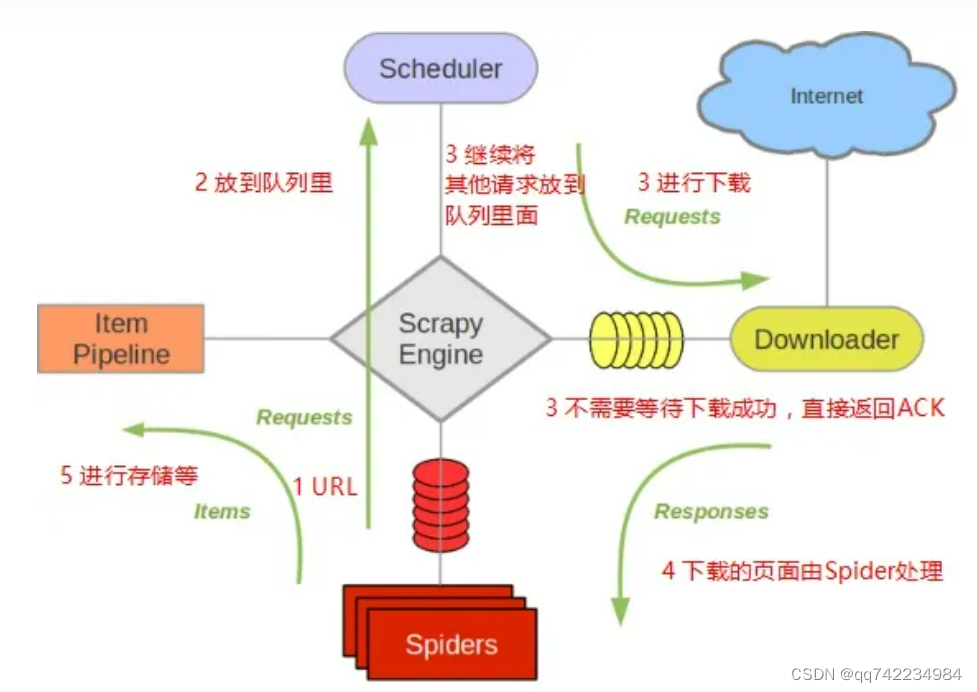
各组件的作用
Scrapy Engine
- 引擎负责控制数据流在系统中所有组件中流动,并在相应动作发生时触发事件。 详细内容查看下面的数据流(Data Flow)部分。
- 此组件相当于爬虫的“大脑”,是整个爬虫的调度中心。
调度器(Scheduler)
- 调度器从引擎接受request并将他们入队,以便之后引擎请求他们时提供给引擎。
- 初始的爬取URL和后续在页面中获取的待爬取的URL将放入调度器中,等待爬取。同时调度器会自动去除重复的URL(如果特定的URL不需要去重也可以通过设置实现,如post请求的URL)
下载器(Downloader)
- 下载器负责获取页面数据并提供给引擎,而后提供给spider。
Spiders
- Spider是Scrapy用户编写用于分析response并提取item(即获取到的item)或额外跟进的URL的类。
每个spider负责处理一个特定(或一些)网站。
Item Pipeline
-
Item Pipeline负责处理被spider提取出来的item。典型的处理有清理、 验证及持久化(例如存取到数据库中)。
-
当页面被爬虫解析所需的数据存入Item后,将被发送到项目管道(Pipeline),并经过几个特定的次序处理数据,最后存入本地文件或存入数据库。
下载器中间件(Downloader middlewares)
-
下载器中间件是在引擎及下载器之间的特定钩子(specific hook),处理Downloader传递给引擎的response。
-
其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
-
通过设置下载器中间件可以实现爬虫自动更换user-agent、IP等功能。
Spider中间件(Spider middlewares)
-
Spider中间件是在引擎及Spider之间的特定钩子(specific
hook),处理spider的输入(response)和输出(items及requests)。 -
其提供了一个简便的机制,通过插入自定义代码来扩展Scrapy功能。
常见的创建scrapy语句:
scrapy startproject 项目名scrapy genspider 爬虫名 域名scrapy crawl 爬虫名
scrapy.cfg 项目的主配置信息。(真正爬虫相关的配置信息在settings.py文件中)items.py 设置数据存储模板,用于结构化数据,如:Django的Modelpipelines 数据持久化处理settings.py 配置文件spiders 爬虫目录
参考:https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
参考:https://www.osgeo.cn/scrapy/topics/architecture.html
反爬虫
限制爬虫程序访问服务器资源和获取数据的行为
限制手段
请求限制、拒绝响应、客户端身份验证、文本混淆和使用动态渲染技术等
反爬虫的分类
身份识别反爬虫
- 验证请求头信息、验证请求参数、使用验证码等
爬虫行为反爬虫
- 对ip进行限制、使用蜜罐获取ip、假数据等
数据加密反爬虫
- 自定义字体、数据图片、编码格式等
爬虫与反爬虫-功与防
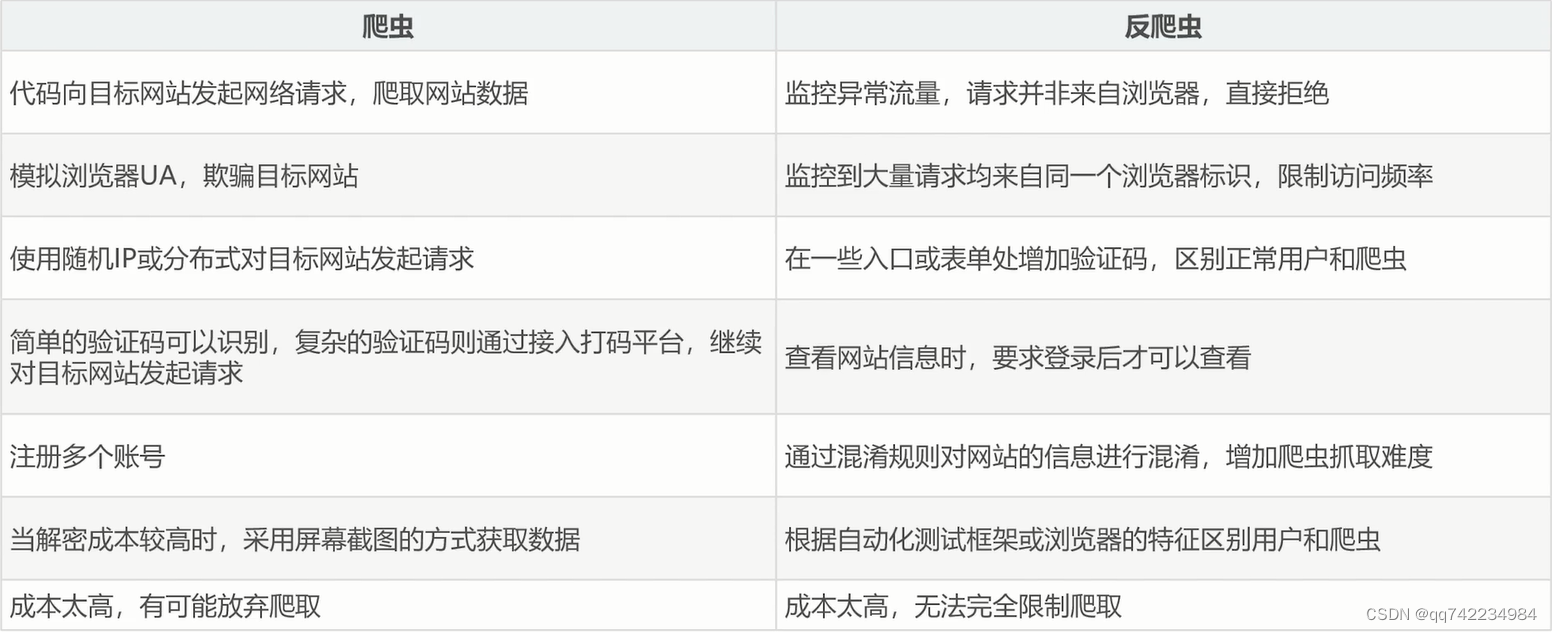
基于身份识别反爬和结局思路
Headers反爬-通过User-agent字段
携带正确的User-agent和使用随机User-agent
Headers反爬-通过cookie字段
注册多个账号请求登录后数据或破解JS生成cookie逻辑
Headers反爬-通过Referer字段
伪造Referer字段
基于请求参数反爬
仔细分析抓到的包,搞清楚请求之间的联系
验证码反爬
Pytesseract/商业打码平台
验证码(CAPTCHA)是“Completely Automated Public Turing testto tell Computers and Humans Apart”(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序。
基于爬虫行为反爬和解决思路
通过请求ip/账号单位时间内请求频率、次数反爬
使用ip代理、多个账号反反爬
通过同一ip/账号请求间隔进行反爬
使用ip代理,设置随机休眠进行反反爬
通过js实现跳转反爬
多次抓包,分析规律
通过蜜罐(陷阱)捕获ip
完成爬虫之后,测试爬取/仔细分析相应内容,找出陷阱
通过假数据进行反爬
长期运行,对比数据库中数据同实际页面数据
阻塞任务队列
分析获取垃圾url的规律,对URL进行过滤
阻塞网络IO
审查抓取连接,对请求时间计时
基于数据加密反爬和解决思路
通过自定义字体反爬
切换到手机版/解析自定义字体
通过js动态生成数据进行反爬
分析js生成数据的流程,模拟生成数据
通过数据图片化进行反爬
通过使用图片引擎,解析图片数据
通过编码格式进行反爬
测试不同格式解码,获取正确的解码格式
相关文章:
网络爬虫(Python:Selenium、Scrapy框架;爬虫与反爬虫笔记)
网络爬虫(Python:Selenium、Scrapy框架;爬虫与反爬虫笔记) SeleniumWebDriver 对象提供的相关方法定位元素ActionChains的基本使用selenium显示等待和隐式等待显示等待隐式等待 Scrapy(异步网络爬虫框架)Sc…...
)
一个简易计算器实现(c语言)
该程序使用c语言实现了一个简易的计算器,该计算器具有以下功能: 1、设计功能选择界面,实现菜单选择、数据输入和输出的功能; 2、至少自定义五个子函数分别完成加、减、乘、除以及求模运算功能; 3、考虑代码的健壮性和…...

JVM——垃圾回收算法(垃圾回收算法评价标准,四种垃圾回收算法)
目录 1.垃圾回收算法发展简介2.垃圾回收算法的评价标准1.吞吐量2.最大暂停时间3.堆使用效率 3.垃圾回收算法01-标记清除算法垃圾回收算法-标记清除算法的优缺点 4.垃圾回收算法02-复制算法垃圾回收算法-复制算法的优缺点 5.垃圾回收算法03-标记整理算法标记整理算法的优缺点 6.…...
【虚拟机】在VM中安装 CentOS 7
1.2.创建虚拟机 Centos7是比较常用的一个Linux发行版本,在国内的使用比例还是比较高的。 大家首先要下载一个Centos7的iso文件,我在资料中给大家准备了一个mini的版本,体积不到1G,推荐大家使用: 我们在VMware《主页》…...

Qt 信号与槽简介
Qt是一个跨平台的C应用程序开发框架,它提供了丰富的功能和工具来帮助开发者构建高质量、高性能的GUI应用程序。在Qt中,信号与槽(Signal and Slot)机制是一种用于处理事件的重要特性。 信号(Signal)…...
ruoyi-plus-vue docker 部署
本文以 ruoyi-vue-plus 5.x docker 部署为基础 安装虚拟机 部署文档 安装docker 安装docker 安装docker-compose 配置idea环境 上传 /doicker 文件夹 到服务器;赋值 777权限 chmod -R 777 /docker idea构建 jar 包 利用 idea 构建镜像; 创建基础服务 docker…...

springboot使用redis缓存乱码(key或者 value 乱码)一招解决
如果查看redis中的值是这样 创建一个配置类就可以解决 package com.deka.config;import org.springframework.beans.factory.annotation.Autowired; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; i…...
rk3588配置uac功能,android13使能uac及adb的复合设备
最近,因新增需求需要在现有产品上增加UAC的功能,查阅并学习相关知识后,在rk3588 SOC硬件平台搭载android13系统平台上成功配置了uac及uac&adb的复合设备。基于开源共享精神希望给大家提供些参考。 1.技术可行性预研 (1&#…...

对未来新能源车测试工具的看法
汽车行业正在经历变革的说法算是比较轻描淡写的了,还记得我1983年加入这个行业时,行业聚焦点是引入发动机管理系统。当时还是以家庭掀背车为主的时代,发动机分析仪的体积像衣柜一样大,还没出现“CAN”通信协议。现在经常听到我的导…...
案例说法:智能网联车背后的安全隐患
随着汽车智能化、网联化的发展,汽车数据处理能力日益增强,未经授权对个人信息和重要数据采集、利用等数据安全问题逐步凸显。对车辆网络攻击、网络侵入等网络安全问题恐将危及个人生命安全、合法权益,甚至危害公共利益、国家安全,…...
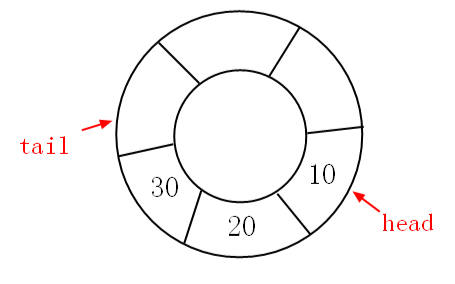
基于C#实现双端队列
话说有很多数据结构都在玩组合拳,比如说:块状链表,块状数组,当然还有本篇的双端队列,是的,它就是栈和队列的组合体。 一、概念 我们知道普通队列是限制级的一端进,另一端出的 FIFO 形式&#…...
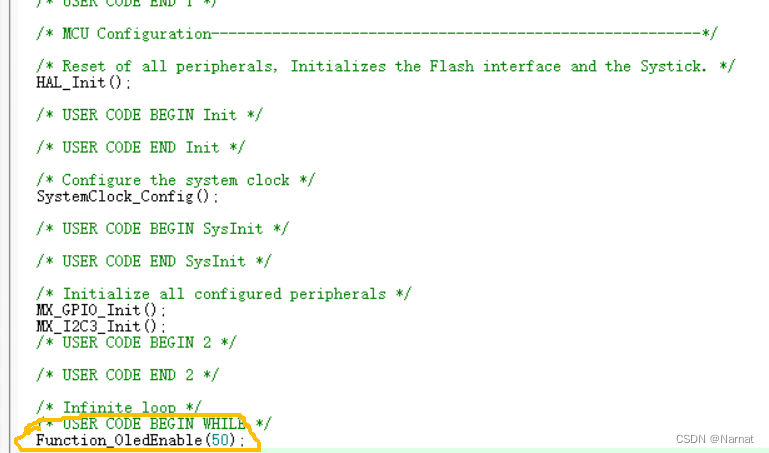
蓝桥杯物联网竞赛_STM32L071_4_按键控制
原理图: 当按键S1按下PC14接GND,为低电平 CubMX配置: Keil配置: main函数: while (1){/* USER CODE END WHILE */OLED_ShowString(24, 0, "<KeyCheck>", 16);if(Function_KEY_S1Check() 1){ OLED_ShowString(…...
【后端卷前端】
为啥现在对后端要求这么高?为啥不要求前端会后端呢? 可能是后端人太多了,要求后端需要会前端的框架(vue react angular ), 这不我为了适应市场的需求来系统的学习vue了: 生成一个基础的vue项目 创建vue项目 vue create projectname 创建vitevue npm init vitelatest p…...

二叉树题目:结点与其祖先之间的最大差值
文章目录 题目标题和出处难度题目描述要求示例数据范围 解法一思路和算法代码复杂度分析 解法二思路和算法代码复杂度分析 题目 标题和出处 标题:结点与其祖先之间的最大差值 出处:1026. 结点与其祖先之间的最大差值 难度 5 级 题目描述 要求 给…...

平衡树 - splay
相比于之前的普通平衡树进行左旋右旋来比,splay的适用性更高,使用更广泛。 核心函数rotate、splay函数,其它的根据需要进行修改。 int n, m; struct Node {int s[2], p, v, cnt; // 左右儿子、父节点、值、出现数量int size, flag; // 子树大…...

Spring Validation实践及其实现原理
Bean Validation 2.0 注解 校验空值 Null:验证对象是否为 null NotNull:验证对象是否不为 null NotEmpty:验证对象不为 null,且长度(数组、集合、字符串等)大于 0 NotBlank:验证字符串不为 nul…...
Java核心知识点整理大全18-笔记
Java核心知识点整理大全-笔记_希斯奎的博客-CSDN博客 Java核心知识点整理大全2-笔记_希斯奎的博客-CSDN博客 Java核心知识点整理大全3-笔记_希斯奎的博客-CSDN博客 Java核心知识点整理大全4-笔记-CSDN博客 Java核心知识点整理大全5-笔记-CSDN博客 Java核心知识点整理大全6…...

vue 富文本编辑器多图上传
首先我使用的富文本编辑器是vue-quill-editor 使用npm进行下载 npm install vue-quill-editor --save当然也可以按照官方的方法下载,到官方 因为我是在原有老项目上开发的使用的组件库是ant-design-vue 1x版,当然使用其他组件库也可以 然后还有重要的一…...
)
简易地铁自动机售票系统实现(C++)
该程序具有以下功能 (1) 一个地铁路线类 Router,包含路线编号,途中的各个站点。可以新增、删除、查询路线,可以根据线路名称,显示线路图片。 (2) 一个地图类 Map,可以显示所有可以乘坐的地铁站名,以及线路…...
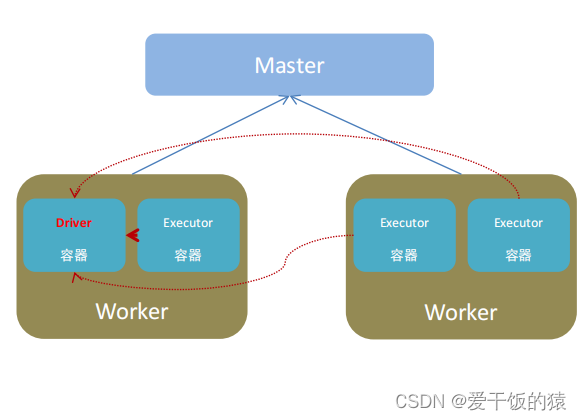
【Spark入门】基础入门
【大家好,我是爱干饭的猿,本文重点介绍Spark的定义、发展、扩展阅读:Spark VS Hadoop、四大特点、框架模块、运行模式、架构角色。 后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍ÿ…...

4种突破数字内容壁垒的技术方案:面向研究者与创作者的开源工具指南
4种突破数字内容壁垒的技术方案:面向研究者与创作者的开源工具指南 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fa…...

ADS DC仿真实战:从零构建电源完整性分析
1. 电源完整性分析为何如此重要? 最近在做一个FPGA板卡项目时,我遇到了一个棘手的问题:板卡在低温环境下频繁出现异常重启。经过排查发现,问题出在核心电源轨的压降上。当环境温度降低时,电源网络的阻抗变化导致供电电…...

Campus-iMaoTai自动化预约系统:技术架构与实践指南
Campus-iMaoTai自动化预约系统:技术架构与实践指南 【免费下载链接】campus-imaotai i茅台app自动预约,每日自动预约,支持docker一键部署(本项目不提供成品,使用的是已淘汰的算法) 项目地址: https://git…...

Ubuntu家族大比拼:Gnome、KDE与Xfce桌面环境全解析
1. Ubuntu家族三剑客:Gnome、KDE与Xfce的定位差异 第一次接触Ubuntu系列发行版的朋友,往往会被各种"*buntu"搞得晕头转向。我自己刚入门时也分不清Kubuntu和Xubuntu的区别,直到把三个系统都装了一遍才发现:它们的内核和…...

Shadow Robot 触觉传感器:摄像头隔着透明层,直接“看见”接触与形变
本文素材源于专利US12025525)一个触觉传感器包括以下组件:1. 第一层:由柔性材料形成,具有外部接触表面和相对的内部接口表面。2. 第二层:由基本透明的柔性材料形成,与第一层在接口表面处连续接触。3. 摄像头…...

如何快速上手Scala Exercises:面向初学者的完整入门指南
如何快速上手Scala Exercises:面向初学者的完整入门指南 【免费下载链接】scala-exercises The easy way to learn Scala. 项目地址: https://gitcode.com/gh_mirrors/sc/scala-exercises Scala Exercises是一个基于Scala编程语言的开源交互式学习平台&#…...

Intv_AI_MK11深入LSTM时间序列预测:模型原理与代码实现详解
Intv_AI_MK11深入LSTM时间序列预测:模型原理与代码实现详解 1. 为什么需要LSTM? 时间序列数据在我们的生活中无处不在——股票价格波动、天气变化、设备传感器读数...这些数据都有一个共同特点:当前时刻的值往往与过去一段时间的值相关。传…...

Git-RSCLIP模型快速入门:10分钟实现第一个图文检索应用
Git-RSCLIP模型快速入门:10分钟实现第一个图文检索应用 1. 引言 你是不是经常遇到这样的情况:电脑里存了几千张照片,想找某张特定的图片却怎么也找不到?或者想用文字描述来搜索相关的图片,但传统的关键词搜索总是不够…...

Windows下OpenClaw安装指南:Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF模型对接详解
Windows下OpenClaw安装指南:Qwen3-4B-Thinking-2507-GPT-5-Codex-Distill-GGUF模型对接详解 1. 为什么选择WindowsOpenClaw组合 作为一个长期在Windows环境下工作的开发者,我一直在寻找能够提升本地开发效率的AI助手方案。直到遇到OpenClaw,…...

Pixel Epic部署指南:Ubuntu/CentOS多系统兼容性部署与故障排查
Pixel Epic部署指南:Ubuntu/CentOS多系统兼容性部署与故障排查 1. 产品概述 Pixel Epic(像素史诗智识终端)是一款基于AgentCPM-Report大模型构建的创新研究报告辅助工具。与传统AI工具不同,它将枯燥的科研过程转化为充满游戏感的…...