Spark DataFrame和Dataset使用例子
文章目录
- 1、基本操作
- 1.1、创建SparkSession
- 1.2、创建DataFrames
- 1.3、创建Dataset操作
- 1.4、运行sql查询
- 1.5、创建全局临时视图
- 1.6、创建Datasets
- 1.7、与rdd进行互操作
- 1.7.1、使用反射推断模式
- 1.7.2、以编程方式指定模式
- 2、完整的测试例子
1、基本操作
1.1、创建SparkSession
import org.apache.spark.sql.SparkSession;SparkSession spark = SparkSession
.builder()
.appName("Java Spark SQL basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate();
1.2、创建DataFrames
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;Dataset<Row> df = spark.read().json("examples/src/main/resources/people.json");// Displays the content of the DataFrame to stdout
df.show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
1.3、创建Dataset操作
// col("...") is preferable to df.col("...")
import static org.apache.spark.sql.functions.col;// Print the schema in a tree format
df.printSchema();
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)// Select only the "name" column
df.select("name").show();
// +-------+
// | name|
// +-------+
// |Michael|
// | Andy|
// | Justin|
// +-------+// Select everybody, but increment the age by 1
df.select(col("name"), col("age").plus(1)).show();
// +-------+---------+
// | name|(age + 1)|
// +-------+---------+
// |Michael| null|
// | Andy| 31|
// | Justin| 20|
// +-------+---------+// Select people older than 21
df.filter(col("age").gt(21)).show();
// +---+----+
// |age|name|
// +---+----+
// | 30|Andy|
// +---+----+// Count people by age
df.groupBy("age").count().show();
// +----+-----+
// | age|count|
// +----+-----+
// | 19| 1|
// |null| 1|
// | 30| 1|
// +----+-----+
1.4、运行sql查询
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;// Register the DataFrame as a SQL temporary view
df.createOrReplaceTempView("people");Dataset<Row> sqlDF = spark.sql("SELECT * FROM people");
sqlDF.show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
1.5、创建全局临时视图
// Register the DataFrame as a global temporary view
df.createGlobalTempView("people");// Global temporary view is tied to a system preserved database `global_temp`
spark.sql("SELECT * FROM global_temp.people").show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+// Global temporary view is cross-session
spark.newSession().sql("SELECT * FROM global_temp.people").show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
1.6、创建Datasets
import java.util.Arrays;
import java.util.Collections;
import java.io.Serializable;import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.Encoder;
import org.apache.spark.sql.Encoders;public static class Person implements Serializable {private String name;private long age;public String getName() {return name;}public void setName(String name) {this.name = name;}public long getAge() {return age;}public void setAge(long age) {this.age = age;}
}// Create an instance of a Bean class
Person person = new Person();
person.setName("Andy");
person.setAge(32);// Encoders are created for Java beans
Encoder<Person> personEncoder = Encoders.bean(Person.class);
Dataset<Person> javaBeanDS = spark.createDataset(Collections.singletonList(person),personEncoder
);
javaBeanDS.show();
// +---+----+
// |age|name|
// +---+----+
// | 32|Andy|
// +---+----+// Encoders for most common types are provided in class Encoders
Encoder<Long> longEncoder = Encoders.LONG();
Dataset<Long> primitiveDS = spark.createDataset(Arrays.asList(1L, 2L, 3L), longEncoder);
Dataset<Long> transformedDS = primitiveDS.map((MapFunction<Long, Long>) value -> value + 1L,longEncoder);
transformedDS.collect(); // Returns [2, 3, 4]// DataFrames can be converted to a Dataset by providing a class. Mapping based on name
String path = "examples/src/main/resources/people.json";
Dataset<Person> peopleDS = spark.read().json(path).as(personEncoder);
peopleDS.show();
// +----+-------+
// | age| name|
// +----+-------+
// |null|Michael|
// | 30| Andy|
// | 19| Justin|
// +----+-------+
1.7、与rdd进行互操作
1.7.1、使用反射推断模式
Spark SQL支持将JavaBeans的RDD自动转换为DataFrame。使用反射获得的BeanInfo定义了表的模式。目前,Spark SQL不支持包含Map字段的JavaBeans。但是支持嵌套JavaBeans和List或Array字段。您可以通过创建一个实现Serializable的类来创建JavaBean,并且该类的所有字段都有getter和setter。
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.Encoder;
import org.apache.spark.sql.Encoders;// Create an RDD of Person objects from a text file
JavaRDD<Person> peopleRDD = spark.read().textFile("examples/src/main/resources/people.txt").javaRDD().map(line -> {String[] parts = line.split(",");Person person = new Person();person.setName(parts[0]);person.setAge(Integer.parseInt(parts[1].trim()));return person;});// Apply a schema to an RDD of JavaBeans to get a DataFrame
Dataset<Row> peopleDF = spark.createDataFrame(peopleRDD, Person.class);
// Register the DataFrame as a temporary view
peopleDF.createOrReplaceTempView("people");// SQL statements can be run by using the sql methods provided by spark
Dataset<Row> teenagersDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19");// The columns of a row in the result can be accessed by field index
Encoder<String> stringEncoder = Encoders.STRING();
Dataset<String> teenagerNamesByIndexDF = teenagersDF.map((MapFunction<Row, String>) row -> "Name: " + row.getString(0),stringEncoder);
teenagerNamesByIndexDF.show();
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+// or by field name
Dataset<String> teenagerNamesByFieldDF = teenagersDF.map((MapFunction<Row, String>) row -> "Name: " + row.<String>getAs("name"),stringEncoder);
teenagerNamesByFieldDF.show();
// +------------+
// | value|
// +------------+
// |Name: Justin|
// +------------+
1.7.2、以编程方式指定模式
当JavaBean类不能提前定义时(例如,记录的结构被编码为字符串,或者文本数据集将被解析,字段将以不同的方式投影给不同的用户),可以通过三个步骤以编程方式创建dataset 。
- 从原始RDD的行创建一个RDD;
- 创建由StructType表示的模式,该模式与步骤1中创建的RDD中的Rows结构相匹配。
- 通过SparkSession提供的createDataFrame方法将模式应用到RDD的行。
import java.util.ArrayList;
import java.util.List;import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;// Create an RDD
JavaRDD<String> peopleRDD = spark.sparkContext().textFile("examples/src/main/resources/people.txt", 1).toJavaRDD();// The schema is encoded in a string
String schemaString = "name age";// Generate the schema based on the string of schema
List<StructField> fields = new ArrayList<>();
for (String fieldName : schemaString.split(" ")) {StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true);fields.add(field);
}
StructType schema = DataTypes.createStructType(fields);// Convert records of the RDD (people) to Rows
JavaRDD<Row> rowRDD = peopleRDD.map((Function<String, Row>) record -> {String[] attributes = record.split(",");return RowFactory.create(attributes[0], attributes[1].trim());
});// Apply the schema to the RDD
Dataset<Row> peopleDataFrame = spark.createDataFrame(rowRDD, schema);// Creates a temporary view using the DataFrame
peopleDataFrame.createOrReplaceTempView("people");// SQL can be run over a temporary view created using DataFrames
Dataset<Row> results = spark.sql("SELECT name FROM people");// The results of SQL queries are DataFrames and support all the normal RDD operations
// The columns of a row in the result can be accessed by field index or by field name
Dataset<String> namesDS = results.map((MapFunction<Row, String>) row -> "Name: " + row.getString(0),Encoders.STRING());
namesDS.show();
// +-------------+
// | value|
// +-------------+
// |Name: Michael|
// | Name: Andy|
// | Name: Justin|
// +-------------+
2、完整的测试例子
本例子代码是在window下测试,需要下载https://github.com/steveloughran/winutils,解压放在hadoop对应目录
package com.penngo.spark;import org.apache.log4j.Level;
import org.apache.log4j.Logger;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.MapFunction;
import org.apache.spark.sql.*;
import org.apache.spark.sql.types.DataTypes;
import org.apache.spark.sql.types.StructField;
import org.apache.spark.sql.types.StructType;import java.io.Serializable;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collections;
import java.util.List;import static org.apache.spark.sql.functions.col;public class SparkDataset {private static final String jsonPath = "D:\\hadoop\\spark\\resources\\people.json";private static final String txtPath = "D:\\hadoop\\spark\\resources\\people.txt";public static class Person implements Serializable {private String name;private long age;public String getName() {return name;}public void setName(String name) {this.name = name;}public long getAge() {return age;}public void setAge(long age) {this.age = age;}}public static void createDataFrame(SparkSession spark) throws Exception{// 创建DataFrameDataset<Row> df = spark.read().json(jsonPath);df.show();// 操作operations(df);// sql查询sqlQuery(spark, df);}public static void operations(Dataset<Row> df){df.printSchema();// root// |-- age: long (nullable = true)// |-- name: string (nullable = true)// Select only the "name" columndf.select("name").show();// +-------+// | name|// +-------+// |Michael|// | Andy|// | Justin|// +-------+// Select everybody, but increment the age by 1df.select(col("name"), col("age").plus(1)).show();// +-------+---------+// | name|(age + 1)|// +-------+---------+// |Michael| null|// | Andy| 31|// | Justin| 20|// +-------+---------+// Select people older than 21df.filter(col("age").gt(21)).show();// +---+----+// |age|name|// +---+----+// | 30|Andy|// +---+----+// Count people by agedf.groupBy("age").count().show();// +----+-----+// | age|count|// +----+-----+// | 19| 1|// |null| 1|// | 30| 1|// +----+-----+}/*** SQL查询*/public static void sqlQuery(SparkSession spark, Dataset<Row> df) throws Exception{// 临时视图,会话消失,视图也会消失df.createOrReplaceTempView("people");Dataset<Row> sqlDF = spark.sql("SELECT * FROM people");sqlDF.show();// 全局视图,全局临时视图绑定到系统保留的数据库' global_temp 'df.createGlobalTempView("people");spark.sql("SELECT * FROM global_temp.people").show();// +----+-------+// | age| name|// +----+-------+// |null|Michael|// | 30| Andy|// | 19| Justin|// +----+-------+// 全局临时视图是跨会话的spark.newSession().sql("SELECT * FROM global_temp.people").show();// +----+-------+// | age| name|// +----+-------+// |null|Michael|// | 30| Andy|// | 19| Justin|// +----+-------+}public static void createDataset(SparkSession spark){// 列表转成datasetPerson person = new Person();person.setName("Andy");person.setAge(32);Encoder<Person> personEncoder = Encoders.bean(Person.class);Dataset<Person> javaBeanDS = spark.createDataset(Collections.singletonList(person),personEncoder);System.out.println("createDataset show");javaBeanDS.show();// +---+----+// |age|name|// +---+----+// | 32|Andy|// +---+----+Encoder<Long> longEncoder = Encoders.LONG();Dataset<Long> primitiveDS = spark.createDataset(Arrays.asList(1L, 2L, 3L), longEncoder);Dataset<Long> transformedDS = primitiveDS.map((MapFunction<Long, Long>) value -> value + 1L,longEncoder);transformedDS.collect(); // Returns [2, 3, 4]// 读取文件转成datasetDataset<Person> peopleDS = spark.read().json(jsonPath).as(personEncoder);peopleDS.show();// +----+-------+// | age| name|// +----+-------+// |null|Michael|// | 30| Andy|// | 19| Justin|// +----+-------+}/*** 非Bean的方式转换:rdd->DataFrame->Dataset* @param spark* @throws Exception*/public static void rddToDataset(SparkSession spark) throws Exception{// 读取文件生成一个Person类型的RDDJavaRDD<Person> peopleRDD = spark.read().textFile(txtPath).javaRDD().map(line -> {String[] parts = line.split(",");Person person = new Person();person.setName(parts[0]);person.setAge(Integer.parseInt(parts[1].trim()));return person;});// RDD转成DataFrameDataset<Row> peopleDF = spark.createDataFrame(peopleRDD, Person.class);// 把DataFrame注册为临时视图peopleDF.createOrReplaceTempView("people");// SQL语句可以通过spark提供的SQL方法来运行Dataset<Row> teenagersDF = spark.sql("SELECT name FROM people WHERE age BETWEEN 13 AND 19");// 结果中一行的列可以通过字段索引访问Encoder<String> stringEncoder = Encoders.STRING();Dataset<String> teenagerNamesByIndexDF = teenagersDF.map((MapFunction<Row, String>) row -> "Name: " + row.getString(0),stringEncoder);teenagerNamesByIndexDF.show();// +------------+// | value|// +------------+// |Name: Justin|// +------------+// 也可以通过字段名访问Dataset<String> teenagerNamesByFieldDF = teenagersDF.map((MapFunction<Row, String>) row -> "Name: " + row.<String>getAs("name"),stringEncoder);teenagerNamesByFieldDF.show();// +------------+// | value|// +------------+// |Name: Justin|// +------------+}/*** 非Bean的方式转换:rdd->DataFrame->Dataset* @param spark* @throws Exception*/public static void rddToDataset2(SparkSession spark) throws Exception{// 创建RDDJavaRDD<String> peopleRDD = spark.sparkContext().textFile(txtPath, 1).toJavaRDD();// 字段字义String schemaString = "name age";// 根据schema的字符串生成schemaList<StructField> fields = new ArrayList<>();for (String fieldName : schemaString.split(" ")) {StructField field = DataTypes.createStructField(fieldName, DataTypes.StringType, true);fields.add(field);}StructType schema = DataTypes.createStructType(fields);// 将RDD(people)的记录转换为视图的RowJavaRDD<Row> rowRDD = peopleRDD.map((Function<String, Row>) record -> {String[] attributes = record.split(",");return RowFactory.create(attributes[0], attributes[1].trim());});// 将schema应用于RDD,转为DataFrameDataset<Row> peopleDataFrame = spark.createDataFrame(rowRDD, schema);// 使用DataFrame创建临时视图peopleDataFrame.createOrReplaceTempView("people");// SQL可以在使用dataframe创建的临时视图上运行Dataset<Row> results = spark.sql("SELECT name FROM people");// SQL查询的结果是dataframe,支持所有正常的RDD操作// 结果行的列可以通过字段索引或字段名称访问Dataset<String> namesDS = results.map((MapFunction<Row, String>) row -> "Name: " + row.getString(0),Encoders.STRING());namesDS.show();// +-------------+// | value|// +-------------+// |Name: Michael|// | Name: Andy|// | Name: Justin|// +-------------+}public static void main(String[] args) throws Exception{Logger.getLogger("org.apache.spark").setLevel(Level.WARN);Logger.getLogger("org.apache.eclipse.jetty.server").setLevel(Level.OFF);//windows下调试spark需要使用https://github.com/steveloughran/winutilsSystem.setProperty("hadoop.home.dir", "D:\\hadoop\\hadoop-3.3.1");System.setProperty("HADOOP_USER_NAME", "root");SparkSession spark = SparkSession.builder().appName("SparkDataset").master("local[*]").getOrCreate();createDataFrame(spark);createDataset(spark);rddToDataset(spark);rddToDataset2(spark);spark.stop();}
}参考自官方文档:https://spark.apache.org/docs/3.1.2/sql-getting-started.html
spark支持数据源:https://spark.apache.org/docs/3.1.2/sql-data-sources.html
spark sql语法相关:https://spark.apache.org/docs/3.1.2/sql-ref.html
相关文章:

Spark DataFrame和Dataset使用例子
文章目录 1、基本操作1.1、创建SparkSession1.2、创建DataFrames1.3、创建Dataset操作1.4、运行sql查询1.5、创建全局临时视图1.6、创建Datasets1.7、与rdd进行互操作1.7.1、使用反射推断模式1.7.2、以编程方式指定模式 2、完整的测试例子 1、基本操作 1.1、创建SparkSession …...

CSS彩色发光液体玻璃
效果展示 CSS 知识点 animation 综合运用animation-delay 综合运用filter 的 hue-rotate 属性运用 页面整体布局 <section><div class"glass" style"--i: 1"><div class"inner"><div class"liquid"></d…...

OpenGLES:glReadPixels()获取相机GLSurfaceView预览数据并保存
Android现行的Camera API2机制可以通过onImageAvailable(ImageReader reader)回调从底层获取到Jpeg、Yuv和Raw三种格式的Image,然后通过保存Image实现拍照功能,但是却并没有Api能直接在上层直接拿到实时预览的数据。 Android Camera预览的实现是上层下发…...

小红书蒲公英平台开通后,有哪些注意的地方,以及如何进行报价?
今天来给大家聊聊当小红书账号过1000粉后,开通蒲公英需要注意的事项。 蒲公英平台是小红书APP中的一个专为内容创作者设计的平台。它为品牌和创作者提供了一个完整的服务流程,包括内容的创作、推广、互动以及转换等多个方面。 2.蒲公英平台的主要功能 &…...
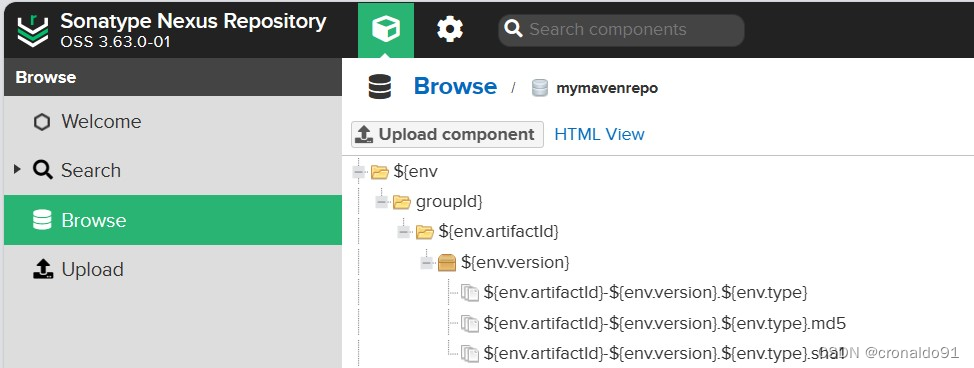
持续集成交付CICD:Jenkins配置Nexus制品上传流水线
目录 一、实验 1.Jenkins配置制品上传流水线 二、问题 1.上传制品显示名称有误 一、实验 1.Jenkins配置制品上传流水线 (1) 新建流水线项目 (2)描述 (3)添加参数 (4)查看构建首页 (5&…...

C语言笔试例题_指针专练30题(附答案解析)
C语言笔试例题_指针专练30题(附答案解析) 指针一直是C语言的灵魂所在,是掌握C语言的必经之路,收集30道C语言指针题目分享给大家,测试环境位64位ubuntu18.04环境,如有错误,恳请指出,文明讨论!&am…...
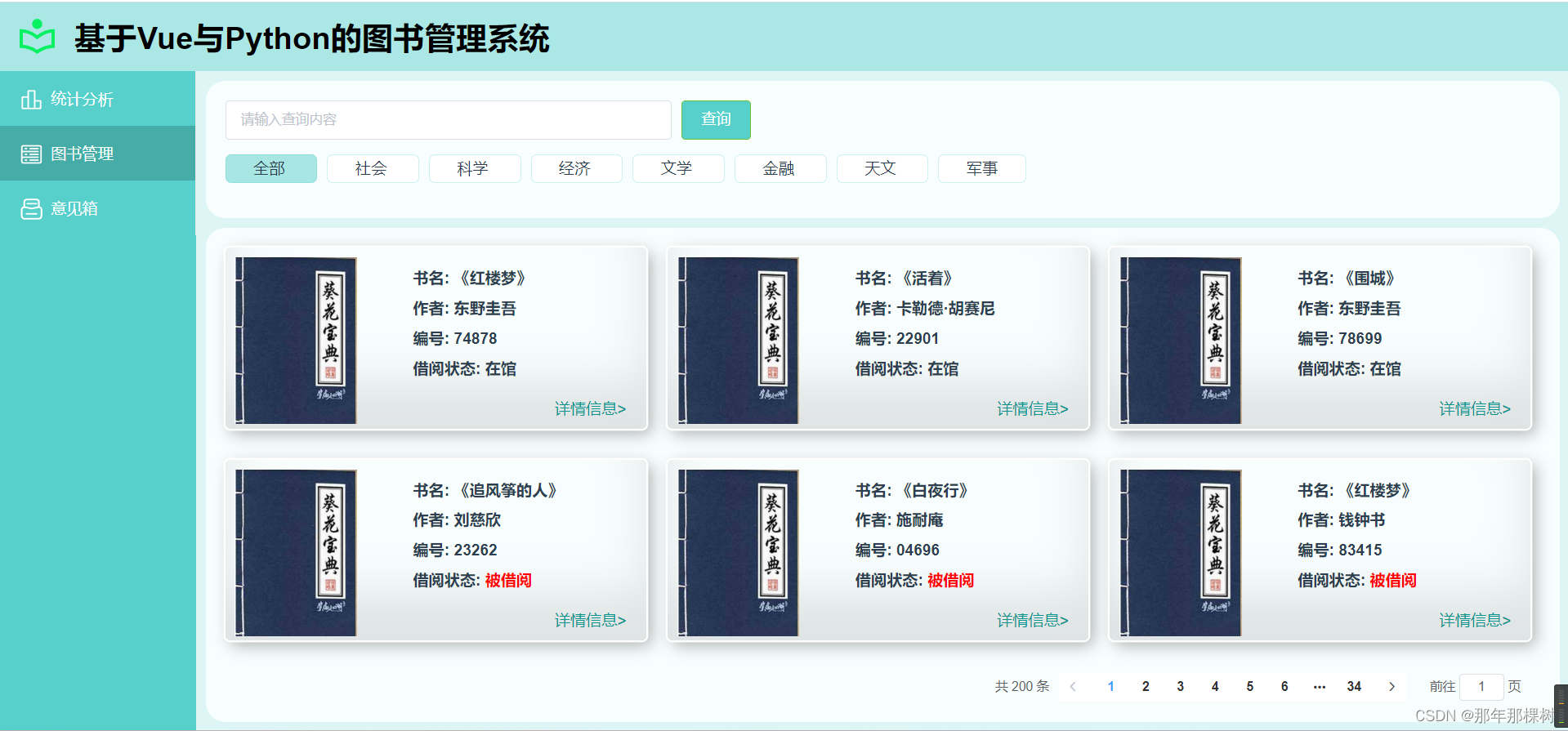
【Vue+Python】—— 基于Vue与Python的图书管理系统
文章目录 🍖 前言🎶一、项目描述✨二、项目展示🏆三、撒花 🍖 前言 【VuePython】—— 基于Vue与Python的图书管理系统 🎶一、项目描述 描述: 本项目为《基于Vue与Python的图书管理系统》,项目…...

智能成绩表 - 华为OD统一考试(C卷)
OD统一考试(C卷) 分值: 100分 题目描述 小明来到某学校当老师,需要将学生按考试总分或单科分数进行排名,你能帮帮他吗? 输入描述 第1行输入两个整数,学生人数n和科目数量m。0<n<100,0<m<10…...
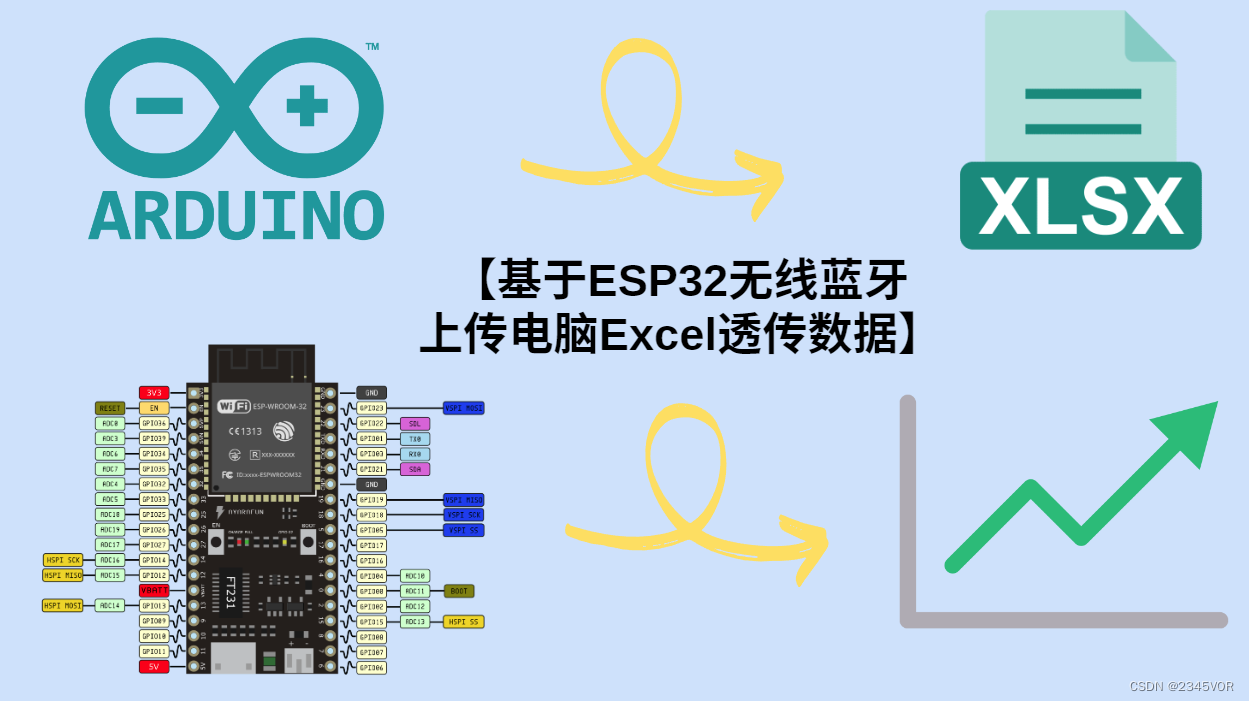
【基于ESP32无线蓝牙上传电脑Excel透传数据】
【基于ESP32无线蓝牙上传电脑透传数据】 1. 引言2. 环境搭建2.1 硬件准备:2.2 软件准备:2.3. 配置Excel端口接收功能3. 测试代码4. 连接电脑和 ESP324.1 烧录程序4.2 启动蓝牙服务4.3 测试数据透传5. 总结1. 引言 随着物联网技术的发展,越来越多的设备开始支持无线通信,其…...
Qt篇——QChartView实现鼠标滚轮缩放、鼠标拖拽平移、鼠标双击重置缩放平移、曲线点击显示坐标
话不多说。 第一步:自定义QChartView,直接搬 FirtCurveChartView.h #ifndef FITCURVECHARTVIEW_H #define FITCURVECHARTVIEW_H #include <QtCharts>class FitCurveChartView : public QChartView {Q_OBJECTpublic:FitCurveChartView(QWidget *…...

掌握VUE中localStorage的使用
文章目录 🍁localStorage的使用🌿设置数据🌿获取数据🌿更新数据🌿删除数据 🍁代码示例🍁使用场景🍁总结 localStorage是一种Web浏览器提供的本地存储机制,允许开发者在用…...

所有行业的最终归宿-我有才打造知识付费平台
随着科技的不断进步和全球化的加速发展,我们生活在一个信息爆炸的时代。各行各业都在努力适应这一变化,寻找新的商业模式和增长机会。在这个过程中,一个趋势逐渐凸显出来,那就是知识付费。可以说,知识付费正在成为所有…...

图的深度和广度优先遍历
题目描述 以邻接矩阵给出一张以整数编号为顶点的图,其中0表示不相连,1表示相连。按深度和广度优先进行遍历,输出全部结果。要求,遍历时优先较小的顶点。如,若顶点0与顶点2,顶点3,顶点4相连&…...

计算机毕业设计JAVA+SSM+springboot养老院管理系统
设计了养老院管理系统,该系统包括管理员,医护人员和老人三部分。同时还能为用户提供一个方便实用的养老院管理系统,管理员在使用本系统时,可以通过系统管理员界面管理用户的信息,也可以进行个人中心,医护等…...

Flutter路由的几种用法
Flutter路由跳转 基本路由跳转 ElevatedButton(onPressed: () {//基本路由跳转Navigator.of(context).push(MaterialPageRoute(builder: (BuildContext context) {return const SearchPage();}),);},child: const Text("基本路由跳转"), ), search.dart页面 impo…...

力扣119双周赛
第 119 场双周赛 文章目录 第 119 场双周赛找到两个数组中的公共元素消除相邻近似相等字符最多 K 个重复元素的最长子数组找到最大非递减数组的长度 找到两个数组中的公共元素 模拟 class Solution { public:vector<int> findIntersectionValues(vector<int>&…...

Redux,react-redux,dva,RTK
1.redux的介绍 Redux – 李立超 | lilichao.com 2.react-redux 1)react-Redux将所有组件分成两大类 UI组件 只负责 UI 的呈现,不带有任何业务逻辑通过props接收数据(一般数据和函数)不使用任何 Redux 的 API一般保存在components文件夹下容器组件 …...

基于Java SSM框架实现高校信息资源共享平台系统【项目源码+论文说明】计算机毕业设计
基于java的SSM框架实现高校信息资源共享平台系统演示 摘要 21世纪的今天,随着社会的不断发展与进步,人们对于信息科学化的认识,已由低层次向高层次发展,由原来的感性认识向理性认识提高,管理工作的重要性已逐渐被人们…...
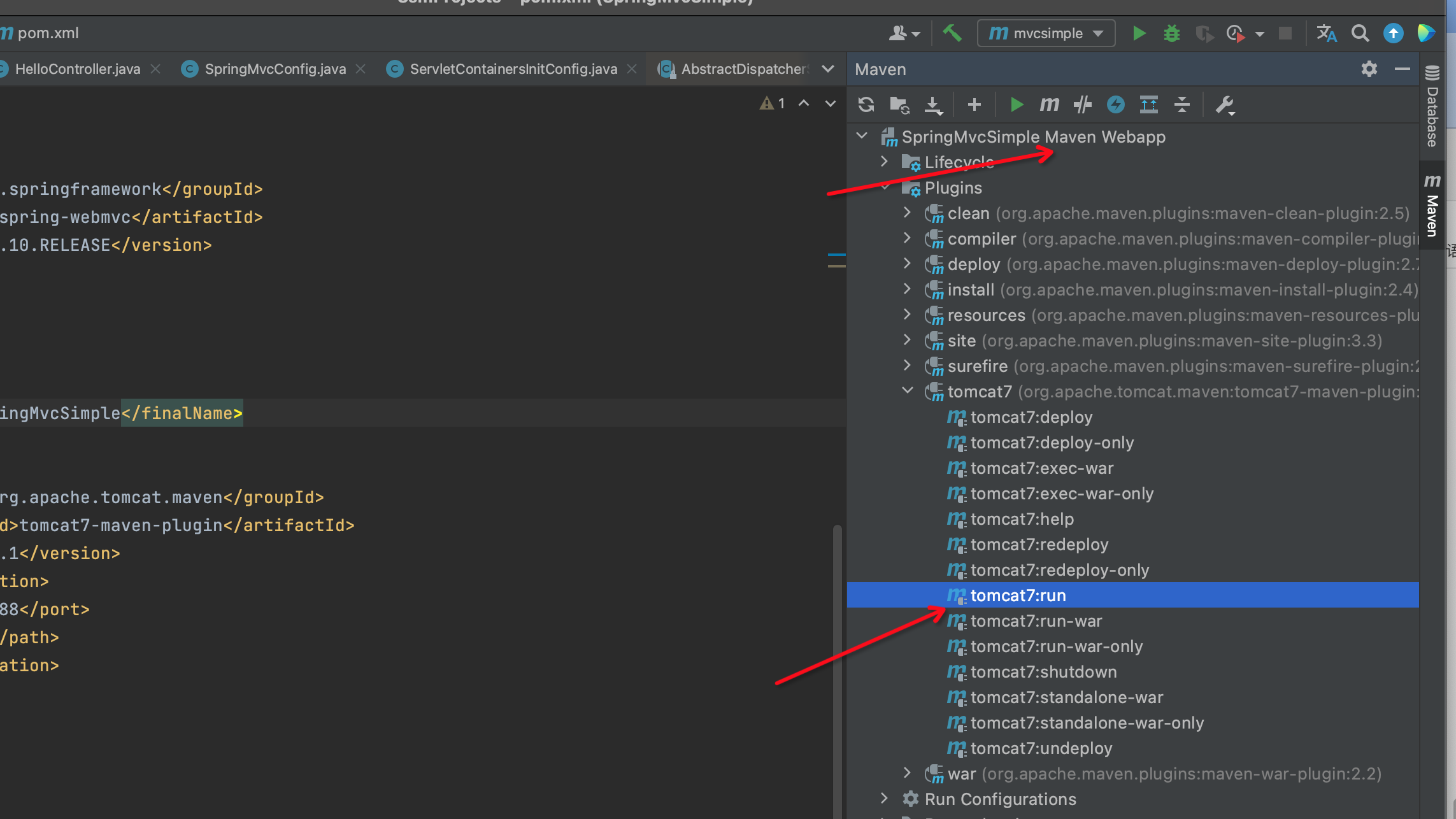
SpringMvc入坑系列(一)----maven插件启动tomcat
springboot傻瓜式教程用久了,回过来研究下SSM的工作流程,当然从Spring MVC开始,从傻瓜式入门处理请求和页面交互,再到后面深入源码分析。 本人写了一年多的后端和半年多的前端了。用的都是springbioot和vue,源码一直来…...

Leetcode—337.打家劫舍III【中等】
2023每日刷题(五十二) Leetcode—337.打家劫舍III 算法思想 实现代码 /*** Definition for a binary tree node.* struct TreeNode {* int val;* TreeNode *left;* TreeNode *right;* TreeNode() : val(0), left(nullptr), right(null…...

从零到精通:Path of Building PoE2构建规划完全指南
从零到精通:Path of Building PoE2构建规划完全指南 【免费下载链接】PathOfBuilding-PoE2 项目地址: https://gitcode.com/GitHub_Trending/pa/PathOfBuilding-PoE2 你是否曾经在《流放之路2》中投入大量资源打造角色,却发现伤害不足、生存堪忧…...

DKC02.3-200-7-FW伺服驱动器
Rexroth DKC02.3-200-7-FW 是博世力士乐 Indramat 系列的高性能数字伺服驱动器,专为高动态响应的工业自动化场景设计。大电流输出:额定100A,峰值200A,满足高负载需求。宽压输入:支持200-480V AC,适应全球电…...

Finch微服务部署:基于Finagle的生产环境最佳实践
Finch微服务部署:基于Finagle的生产环境最佳实践 【免费下载链接】finch Scala combinator library for building Finagle HTTP services 项目地址: https://gitcode.com/gh_mirrors/fin/finch Finch是一个基于Scala的组合器库,专为构建Finagle H…...

解锁ComfyUI-Impact-Pack:从图像精细化到智能增强的完整路径
解锁ComfyUI-Impact-Pack:从图像精细化到智能增强的完整路径 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. 项目地址: ht…...

Tiger框架深度剖析:从依赖注入到组件管理的完整指南
Tiger框架深度剖析:从依赖注入到组件管理的完整指南 【免费下载链接】tiger 项目地址: https://gitcode.com/gh_mirrors/ti/tiger Tiger框架是一个基于Java的依赖注入框架,专为Android和Java应用设计,提供了一套完整的组件管理解决方…...

你的脑洞,值得被“电”亮!TimechoAI 有奖反馈征集令!
五月初,我们“官宣”了将时序大模型“上云”的智能服务平台:TimechoAI,无门槛体验,注册即能试用全部功能!体验过 TimechoAI 的你,心里一定有点想法吧?是惊喜?是建议?还是…...

RDP Wrapper终极指南:Windows家庭版开启多用户远程桌面的完整解决方案
RDP Wrapper终极指南:Windows家庭版开启多用户远程桌面的完整解决方案 【免费下载链接】rdpwrap RDP Wrapper Library 项目地址: https://gitcode.com/gh_mirrors/rd/rdpwrap RDP Wrapper Library是一款让Windows家庭版支持多用户远程桌面连接的革命性工具&a…...

生产级机器学习服务化:FastAPI+Triton+Prometheus实战
1. 项目概述:这不是一次模型训练,而是一场交付实战“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题里藏着太多被新手忽略的潜台词。它不是讲怎么调参、怎么画loss曲线,而是直指机器学习项目生命周期中最…...

微信小程序逆向工程终极指南:wxappUnpacker完整实战解析
微信小程序逆向工程终极指南:wxappUnpacker完整实战解析 【免费下载链接】wxappUnpacker forked from https://github.com/qwerty472123/wxappUnpacker 项目地址: https://gitcode.com/gh_mirrors/wxappu/wxappUnpacker 微信小程序逆向工程是安全研究人员和技…...

如何快速掌握高效屏幕标注:终极免费工具完全指南
如何快速掌握高效屏幕标注:终极免费工具完全指南 【免费下载链接】ppInk Fork from Gink 项目地址: https://gitcode.com/gh_mirrors/pp/ppInk 你是否曾在在线会议中手忙脚乱地试图解释屏幕上的内容?或者作为教师,想要在虚拟课堂上生动…...