SQL进阶理论篇(四):索引的结构原理(B树与B+树)
文章目录
- 简介
- 如何评价索引的数据结构设计好坏
- 二叉树的局限性
- 什么是B树
- 什么是B+树
- 总结
- 参考文献
简介
我们在上一节中说过,索引其实是一种数据结构,那它到底是一种什么样的数据结构呢?本节将简单介绍一下几个问题:
- 什么样的数据结构更适合作为索引?平衡二叉树是否合适?
- 什么是B树和B+树,为什么我们常用B+树作为索引的数据结构?
如何评价索引的数据结构设计好坏
由于索引是存放在磁盘上的,所以我们在通过索引来查找某行数据的时候,大量的时间其实是花在了磁盘的IO上。
因此,如果我们能让索引的数据结构尽量减少与磁盘的IO次数,那么就能减少查询所消耗的时间,这样的数据结构就是更好的。
二叉树的局限性
二叉树是一种高效且常见的数据检索方式。其时间复杂度为O(log2N),那么,采用二叉树作为索引的数据结构合适么?
让我们看一下最基础的二叉搜索树,假设需要搜索的数值是key:
- 如果key大于根节点,则在右子树中进行查找;
- 如果key小于根节点,则在左子树中进行查找;
- 如果key等于根节点,那么就是找到了这个节点。
举个例子,(34,22,89,5,23,77,91)创造出来的二叉搜索树为:

最多只需要经过3次搜索,就能找到指定值。
但是存在特殊的情况,比如说以(5, 22, 23, 34, 77, 89, 91)的顺序创造出来的二分查找树为:

在这个树里,最多需要经过7次比较之后才能找到指定的节点。
因为第二棵树实际上已经退化成了一张链表,查找数据的时间复杂度变成了O(n)。
当然,如果使用平衡二叉搜索树的话,就可以解决这个问题,因为平衡二叉数在二分搜索树的基础上添加了约束,其约定每个节点的左子树和右子树的高度差不能超过1,即左右子树依然是平衡二叉树。
常见的平衡二叉树有很多种,比如说平衡二叉搜索树、红黑树、数堆、伸展树。平衡二叉搜索树是最早提出的一种平衡二叉树。因此我们一般说的平衡二叉树,其实就是平衡二叉搜索树,搜索时间复杂度就是 O ( l o g 2 n ) O(log_2n) O(log2n)。
由于每访问一次节点就要进行一次磁盘IO操作,所以对平衡二叉搜索树来讲,一般会进行 O ( l o g 2 n + 1 ) O(log_2n+1) O(log2n+1)次IO操作。比如说一个5层的平衡二叉树,共31个节点,正常会进行5次IO操作。树的深度越大,意味着IO操作的次数就越多,就越影响整体数据查询的效率。
所以我们可以考虑下,如果将二叉树换成M叉树(M>2),是不是就可以降低树的高度了呢?比如说,同样的31个节点,使用三叉树来存储的话,树深就变成了 l o g 3 ( 31 + 1 ) log_3(31+1) log3(31+1),就是4层。
可以看到,此时树的高度降低了,当数据量足够大的时候,确实比二叉树要好一些。
什么是B树
上一小节中,我们讲到了M叉树(M>2)的表现要优于二叉树。因此一个节点应该允许有M个子节点。
B树就是这么被提出来的。B树,即Balance Tree,就是平衡的多路搜索树,它的高度远小于平衡二叉搜索树的高度。在文件系统和数据库系统中的索引结构经常使用B树来实现。
B树的结构如下图:

可以看到,B树中每个节点最多可以包含M个子节点,而M则称为是B树的阶。
同时,每个磁盘块中包括了关键字(如17/35)和子节点的指针(如P1、P2和P3)。指针数是关键字数量 + 1。
对一个100阶的B树来讲,如果有3层的话最多可以存储 ( 99 ∗ 1 + 99 ∗ 10 0 1 + 99 ∗ 10 0 2 ) = 999999 (99*1 + 99*100^1 + 99*100^2)=999999 (99∗1+99∗1001+99∗1002)=999999,约100w的索引数据。
在存储数据相同的情况下,其高度远远低于二叉树的高度。
简单总结下,一个M阶B树(M>2)的特性:
- 根节点的孩子节点数为[2, M]
- 每个中间节点包含n-1个关键字和n个孩子,其中n的取值范围是[ceil(M/2),M]
- 假设中间节点的关键字为 k 1 , k 2 , . . . . , k n − 1 k_1, k_2,....,k_{n-1} k1,k2,....,kn−1,且关键字按照升序排序,即 k i < k i + 1 k_i < k_{i+1} ki<ki+1。此时n-1个关键字相当于是划分出了n个数值范围,因此对应着n个指针,即 P 1 , P 2 , . . . . , P n P_1, P_2,....,P_n P1,P2,....,Pn,其中, P 1 P_1 P1指向关键字小于 K 1 K_1 K1的子节点, P 2 P_2 P2指向关键字属于 ( k 1 , k 2 ) (k_1, k_2) (k1,k2)的节点,以此类推。
- 所有叶子节点位于同一层。
可以结合上面图来查看刚刚总结的这些特性。
相比平衡二叉树,B树的深度要更低,从而要进行的磁盘IO操作也更少,在数据查询中的效率就显得更高。
虽然M越大,一次读进内存的用来比较的数据就越多,但这个比较的过程是在内存里进行的,时间消耗可以忽略不计。
什么是B+树
B+树是对B树的改进,主流的DBMS都支持B+树的索引方式,比如说MySQL。
B+树和B树的差异在哪儿呢?
- 每个节点内的关键字数量和孩子数量一样。而B树中,孩子数量 = 关键字数量 + 1;
- 非叶子节点的关键字也会同时出现在子节点里,并且是子节点关键字里的最大或者最小。而B树中,则不会同时出现在子节点中;
- 非叶子节点仅用于索引,不保存数据记录,所有的数据记录都是放在叶子节点里。而B树中,所有的节点都是可以既保存索引,也保存数据记录。
- 所有关键字都在叶子节点里出现,每个节点内部所有关键字按照大小从小到大顺序排列,所有叶子节点构成一个有序链表。
比如说下面这张图,就是一棵B+树:

比如说,想查找关键字16,就会自顶向下逐层进行查找,先后访问磁盘块1、磁盘块2、磁盘块7。三次IO操作即可。
在IO的次数上,B+ 树看起来似乎跟B树差不多,那么B+树到底好在哪儿呢?
这个要看B+树和B树的根本差异:B+树的中间节点并不直接存储数据。
这样有什么好处呢?
首先,B+树查询效率更加稳定。B+树每次只有访问到叶子节点后才能取出数据,而B树中,由于非叶子节点也可以存储数据,这就造成了查询效率不稳定的情况,有时候需要访问到叶子节点才能找到数据,有时候走一半到非叶子节点就可以找到数据。时间不好量化。
其次,B+树查询效率更高。通常B+树比B树更矮胖(非叶子节点只存放索引,因此一个节点可以放更多关键字,从而减少深度),所需的磁盘IO就更少。同样的磁盘页大小,B+树可以存储更多的节点关键字。
在做区间查询的时候,B+树的效率同样比B树高。因为B+树里,所有的关键字都出现在叶子节点上,并通过有序链表进行了链接,非常适合寻找范围数据。而B树则需要通过中序遍历扫一遍才能完成范围数据的查找,效率要低很多。
总结
索引在使用时,时间的消耗主要是两部分带来的,一是读取磁盘块来取出里面保存的索引值数据,二是比较索引值数据。不过比较的工作是在内存中进行的,速度很快,所以这部分时间其实可以忽略不计。
因此,制约索引使用速度的唯一因素,就是与磁盘块的IO。只要能减少这块的IO,就能减少索引在使用时的时间消耗,从而提升整个查询的效率。
构造索引的时候,我们更倾向于采用矮胖的数据结构,因此平衡二叉树的结构被果断舍弃了。
B树和B+树都可以作为索引的数据结构,在MySQL中采用的是B+树,其查询性能更加稳定,在磁盘页大小相同的情况下,树的构造更加矮胖,所需要的IO次数更少,也更适合进行关键字的范围查找。
参考文献
- 24丨索引的原理:我们为什么用B+树来做索引?
相关文章:
SQL进阶理论篇(四):索引的结构原理(B树与B+树)
文章目录 简介如何评价索引的数据结构设计好坏二叉树的局限性什么是B树什么是B树总结参考文献 简介 我们在上一节中说过,索引其实是一种数据结构,那它到底是一种什么样的数据结构呢?本节将简单介绍一下几个问题: 什么样的数据结…...
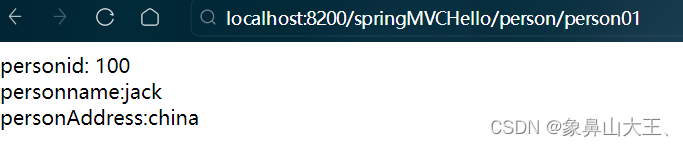
springMVC-模型数据的处理
一、数据放入到request域当中 1、把获取的数据放入request域中, 方便在跳转页面去显示 <a>添加主人信息</a> <form action"vote/vote04" method"post" >主人id:<input type"text" name"id&q…...
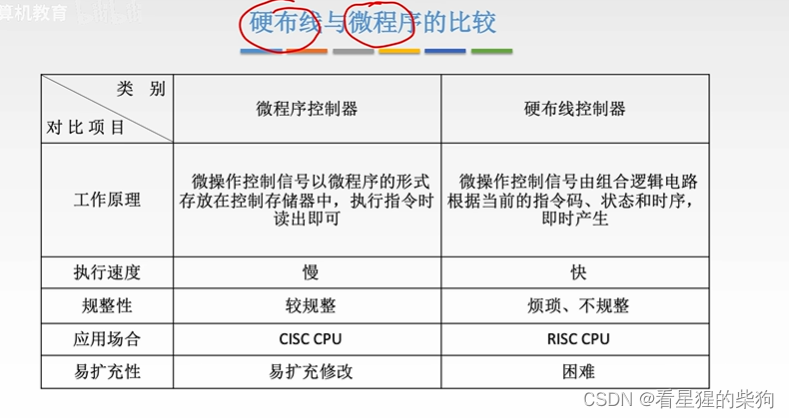
计算机组成原理-微指令的设计与微程序控制单元的设计
文章目录 微指令的设计微指令的格式微指令的编码方式水平型微指令的操作控制部分的编码方式直接编码字段直接编码例题字段间接编码方式 微指令的地址形成方式例题小结 微程序控制单元的设计微程序设计分类硬布线与微程序的比较 微指令的设计 微指令的格式 水平型微指令的操作…...

PyTorch机器学习与深度学习
近年来,随着AlphaGo、无人驾驶汽车、医学影像智慧辅助诊疗、ImageNet竞赛等热点事件的发生,人工智能迎来了新一轮的发展浪潮。尤其是深度学习技术,在许多行业都取得了颠覆性的成果。另外,近年来,Pytorch深度学习框架受…...

羊奶vs牛奶,羊大师告诉你谁是更营养的选择?
羊奶vs牛奶,羊大师告诉你谁是更营养的选择? 羊奶和牛奶是两种常见的乳制品,它们不仅在口味上有所差异,而且在营养成分方面也存在一些差异。本文将对羊奶和牛奶的营养成分进行全面对比,旨在帮助读者更好地了解这两种乳…...
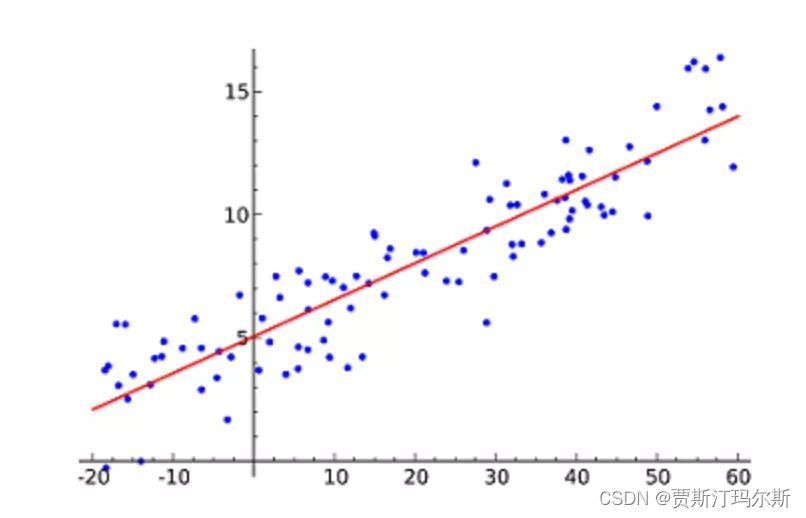
机器学习之线性回归(Linear Regression)
概念 线性回归(Linear Regression)是机器学习中的一种基本的监督学习算法,用于建立输入变量(特征)与输出变量(目标)之间的线性关系。它假设输入变量与输出变量之间存在线性关系,并试图找到最佳拟合线来描述这种关系。 在简单线性回归中,只涉及两个变量:一个是自变量…...
ChatGPT与ArcGIS PRO 如何结合,打造一个全新的工作流程
在地学领域,ArcGIS几乎成为了每位科研工作者作图、数据分析的必备工具,而ArcGIS Pro3除了良好地继承了ArcMap强大的数据管理、制图、空间分析等能力,还具有二三维融合、大数据、矢量切片制作及发布、任务工作流、时空立方体等特色功能&#x…...

【深度学习】对比学习的损失函数
前言 对比学习损失(Contrastive Learning Loss)是一种用于自监督学习的损失函数。它侧重于学习一个特征空间,其中相似的样本被拉近,而不相似的样本被推远。在二分类任务中,对比学习损失可以用来学习区分正负样本的特征…...

哈夫曼解码
【问题描述】 给定一组字符的Huffman编码表(从标准输入读取),给定一个用该编码表进行编码的Huffman编码文件(存在当前目录下的in.txt中),编写程序对Huffman编码文件进行解码。 例如给定的一组字符的Huffm…...

Excel小技能:excel如何将数字20231211转化成指定日期格式2023/12/11
给了一串数字20231211,想要转成指定格式的日期格式,发现设置单元格格式为指定日期格式不生效,反而变成很长很长的一串#这个,如图所示: 其实,正确的做法如下: 1)打开数据功能界面&am…...
Selenium自动化测试框架(超详细总结分享)
设计思路 本文整理归纳以往的工作中用到的东西,现汇总成基础测试框架提供分享。 框架采用python3 selenium3 PO yaml ddt unittest等技术编写成基础测试框架,能适应日常测试工作需要。 1、使用Page Object模式将页面定位和业务操作分开ÿ…...

STM32 DAC+串口
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、DAC是什么?二、STM32 DAC1.什么型号有DAC2. 简介3. 主要特点4. DAC框图5. DAC 电压范围和引脚 三、程序步骤1. 开启DAC时钟2. 配置引脚 PA4 PA5…...
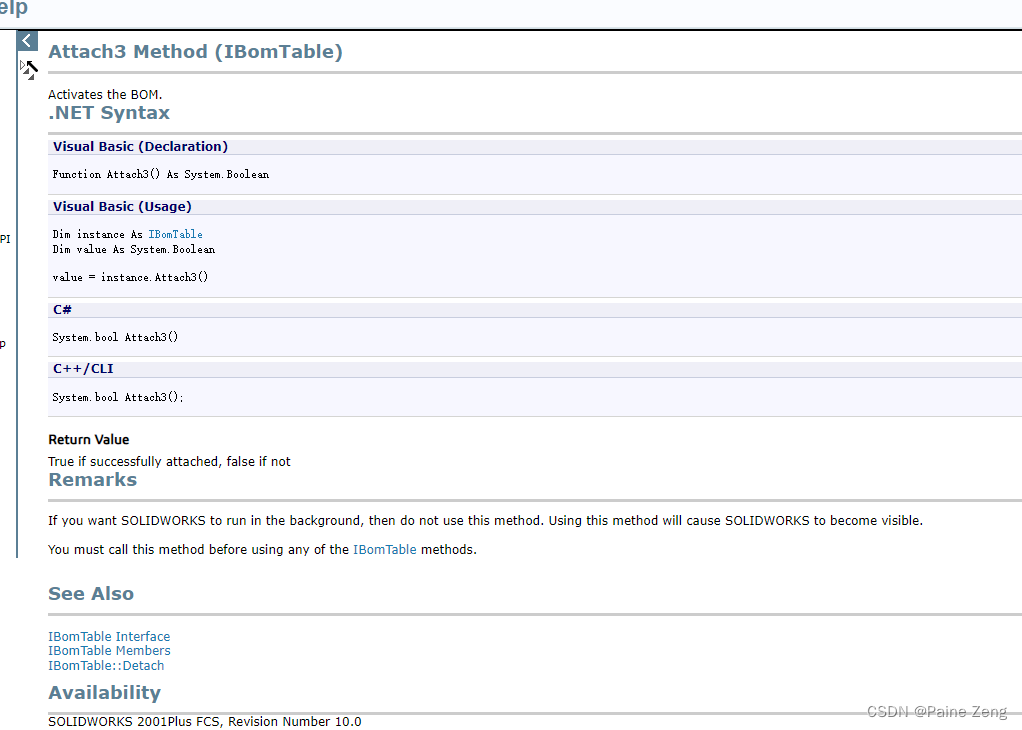
SolidWorks二次开发 C#-读取基于Excel的BOM表信息
SolidWorks二次开发 C#-读取基于Excel的BOM表信息 问题点来源解决方案及思路相关引用链接 问题点来源 这是一位粉丝问的一个问题,他说到: 老师,请问Solidworks二次开发工程图中"基于Excel的材料明细表"怎么读取里面的数据? Ps:这…...
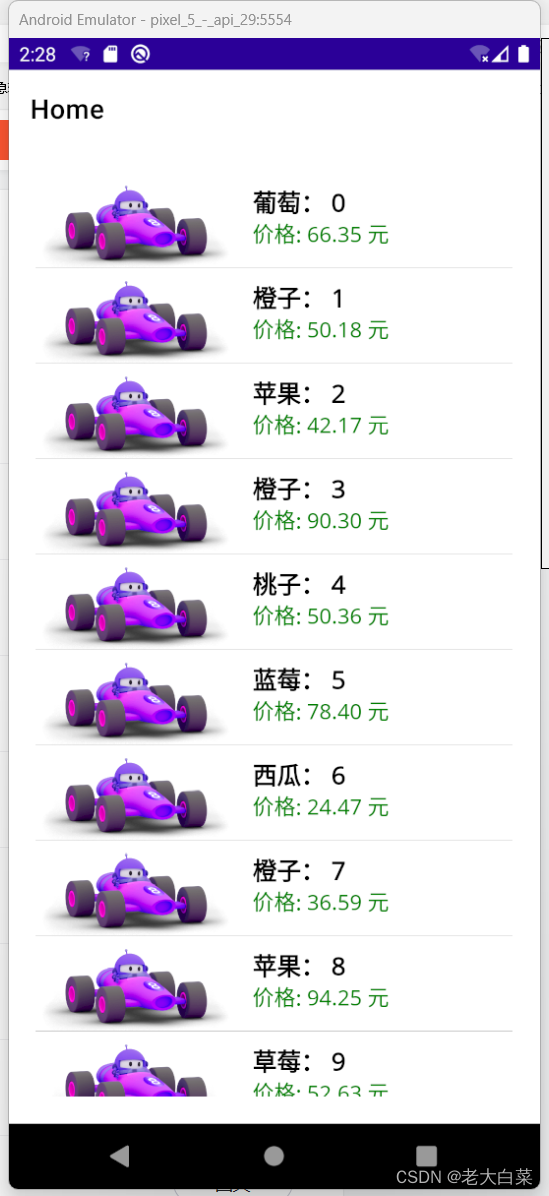
maui中实现加载更多 RefreshView跟ListView(2)
一个类似商品例表的下拉效果: 代码 新增个类为商品商体类 public class ProductItem{public string ImageSource { get; set; }public string ProductName { get; set; }public string Price { get; set; }}界面代码: <?xml version"1.0&quo…...
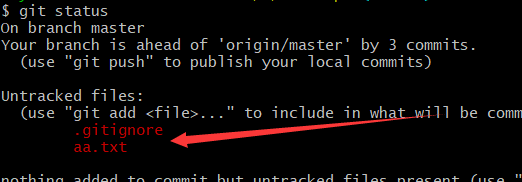
win10环境下git安装和基础操作
简述 关于git的作用就不多赘述了,配合GitHub,达到方便人们日常项目维护和管理,每一次项目增删改查都可以看的清清楚楚,方便团队协作和个人项目日常维护。 下载git 首先我们自然是要到官网下载git,下载地址为https:/…...

将yolo格式转化为voc格式:txt转xml(亲测有效)
1.文件目录如下所示: 对以上目录的解释: 1.dataset下面的image文件夹:里面装的是数据集的原图片 2.dataset下面的label文件夹:里面装的是图片对应得yolo格式标签 3.dataset下面的Annotations文件夹:这是一个空文件夹&…...
)
字符串 - 541.反转字符串II(C#和C实现)
字符串 - 541.反转字符串II(C#和C实现) 题目描述 给定一个字符串 s 和一个整数 k,你需要对从字符串开头算起的每隔 2k 个字符的前 k 个字符进行反转。 如果剩余字符少于 k 个,则将剩余字符全部反转。如果剩余字符小于 2k 但大于或等于 k 个࿰…...

机器视觉技术与应用实战(开运算、闭运算、细化)
开运算和闭运算的基础是膨胀和腐蚀,可以在看本文章前先阅读这篇文章机器视觉技术与应用实战(Chapter Two-04)-CSDN博客 开运算:先腐蚀后膨胀。开运算可以使图像的轮廓变得光滑,具有断开狭窄的间断和消除细小突出物的作…...

云原生之深入解析云原生架构的日志监控
一、什么是云原生架构的日志监控? 云原生架构的日志监控要求现代 Web 应用程序采用与传统应用程序略有不同的方法。部分原因是应用程序环境要复杂得多,包括从微服务中获取数据、使用 Kubernetes 和其他容器技术,以及在许多情况下集成开源组件…...
基于hfl/rbt3模型的情感分析学习研究——文本挖掘
参考书籍《HuggingFace自然语言处理详解 》 什么是文本挖掘 文本挖掘(Text mining)有时也被称为文字探勘、文本数据挖掘等,大致相当于文字分析,一般指文本处理过程中产生高质量的信息。高质量的信息通常通过分类和预测来产生&…...

ComfyUI-FramePackWrapper终极指南:3种AI视频生成模型加载方案深度对比
ComfyUI-FramePackWrapper终极指南:3种AI视频生成模型加载方案深度对比 【免费下载链接】ComfyUI-FramePackWrapper 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI-FramePackWrapper 在AI视频生成领域,ComfyUI-FramePackWrapper是一款革…...

良久团购报单查单小程序开发
需求分析与规划 明确小程序的核心功能:报单(提交订单)、查单(查询订单状态)、团购管理(商品展示、拼团进度)。 确定用户角色:普通用户(参与团购)、管理员&…...

If、switch选择结构
if单选结构package 选择结构;import java.util.Scanner;public class If单选择结构 {public static void main(String[] args) {Scanner scanner new Scanner(System.in);System.out.println("请输入内容:");String sscanner.nextLine();//equals&#x…...

res-downloader:智能资源捕获工具的技术实现与高效工作流指南
res-downloader:智能资源捕获工具的技术实现与高效工作流指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader 资源…...

企业级低代码平台JeecgBoot快速搭建指南:从环境配置到实战应用
企业级低代码平台JeecgBoot快速搭建指南:从环境配置到实战应用 【免费下载链接】jeecg-boot 一款 AI 驱动的低代码平台,提供"零代码"与"代码生成"双模式——零代码模式一句话搭建系统,代码生成模式自动输出前后端代码与建…...

从零开始!DeepSeek-R1-Distill-Qwen-1.5B完整部署流程详解
从零开始!DeepSeek-R1-Distill-Qwen-1.5B完整部署流程详解 1. 模型简介与核心优势 1.1 什么是DeepSeek-R1-Distill-Qwen-1.5B? DeepSeek-R1-Distill-Qwen-1.5B是一款经过知识蒸馏优化的轻量级语言模型,由DeepSeek团队基于Qwen-1.5B架构开发…...

Android USB串口通信终极指南:智能家居物联网项目实战
Android USB串口通信终极指南:智能家居物联网项目实战 【免费下载链接】usb-serial-for-android Android USB host serial driver library for CDC, FTDI, Arduino and other devices. 项目地址: https://gitcode.com/gh_mirrors/us/usb-serial-for-android …...

3步解决macOS应用更新烦恼:开源神器Latest使用指南
3步解决macOS应用更新烦恼:开源神器Latest使用指南 【免费下载链接】Latest A small utility app for macOS that makes sure you know about all the latest updates to the apps you use. 项目地址: https://gitcode.com/gh_mirrors/la/Latest 你是否曾为m…...

AD20 原理图与PCB的协同设计:从单向更新到双向同步的进阶指南
1. AD20协同设计的基础概念 刚接触AD20时,最让我头疼的就是原理图和PCB之间的同步问题。记得第一次做多板卡项目,光是处理不同原理图之间的元件冲突就折腾了一整天。AD20的协同设计功能远比我们想象的强大,但要用好它,得先理解几个…...

3分钟解锁外语游戏:XUnity自动翻译器让你无障碍畅玩全球游戏 [特殊字符]
3分钟解锁外语游戏:XUnity自动翻译器让你无障碍畅玩全球游戏 🎮 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 还在为看不懂的外语游戏而烦恼吗?XUnity自动翻译器就是…...