老生重谈:大模型的「幻觉」问题

一、什么是大模型「幻觉」
大模型的幻觉问题通常指的是模型在处理输入时可能会产生一些看似合理但实际上是错误的输出,这可能是因为模型在训练时过度拟合了训练数据,导致对噪声或特定样本的过度敏感。
"大数据幻觉"指的是在处理大规模数据时,人们可能误认为数据量的增加自动意味着模型的性能将显著提高,或者认为大规模数据本身就足以解决问题,而忽视了其他重要因素。这种幻觉可能导致对数据分析和模型建设的不当期望,以及对结果的错误解释。
二、 造成大模型「幻觉」的原因
"大数据的幻觉"通常指的是在处理大规模数据时可能产生的一些误导性或错误的结果。以下是一些可能导致大数据幻觉的原因:
1. 样本偏差
即使数据规模很大,如果样本不具有代表性,模型仍然可能出现幻觉。样本偏差可能导致模型在未见过的数据上表现不佳,因为模型过度适应了训练数据中的特定模式。
3. 噪声
大规模数据中可能包含大量噪声,这些噪声可能导致模型学习到不准确或不一致的模式。过度关注噪声可能使模型对异常情况过于敏感,从而导致幻觉问题。
4. 维度灾难
随着特征数量的增加,数据的维度也会增加。在高维空间中,数据变得更加稀疏,模型可能过度拟合训练数据中的噪声,而不是学习真正的模式。
5. 过度拟合
大规模数据集中,模型可能会变得更加复杂,以适应更多的数据。这可能导致过度拟合,模型在训练数据上表现很好,但在新数据上表现较差。
6. 缺乏领域知识
大数据分析中,如果忽视了领域专业知识,可能会导致对数据的错误解释。在没有理解背后领域的情况下,模型的结果可能会被误解为具有实际含义,而实际上是幻觉。
7. 数据质量
大规模数据集中可能存在数据质量问题,例如缺失值、异常值或不一致性。这些问题可能对模型的性能产生负面影响。
8. 算法选择不当
不同的算法对于大规模数据的处理方式各不相同。选择不适当的算法可能导致对数据的错误建模,从而产生幻觉。
为了避免大数据的幻觉,重要的是综合考虑数据的质量、样本的代表性、特征的选择、算法的选择以及领域知识等方面。进行适当的数据预处理、特征工程和模型评估是确保在大数据环境中得到可靠结果的关键步骤。

三、解决该问题的方法
以下是一些解决大模型幻觉问题的常见方法:
1. 更多的训练数据
对于机器学习模型来说,训练数据的质量和数量是至关重要的。
拥有更多的训练数据可以帮助模型更好地理解数据分布,减少过拟合现象,并提高对新数据的泛化能力。这是因为更多的数据可以帮助模型涵盖各种情况和变化,使其具有更广泛的适用性。
例如,在图像识别领域,拥有更多的图片数据可以帮助模型更好地识别不同种类的物体和场景。在自然语言处理领域,更多的文本数据可以帮助模型更好地理解语言的语法、语义和上下文信息。
因此,为了提高机器学习模型的效果和泛化能力,我们应该尽可能地获取更多的训练数据,并对数据进行预处理和标注,以确保其质量和可用性。
2. 正则化技术:
使用正则化技术,如L1正则化或L2正则化,来减少模型的复杂性。这有助于防止模型在训练数据中过度拟合,从而减少幻觉问题的发生。
正则化技术是一种重要的机器学习技术,主要用于防止模型过拟合,从而提高模型的泛化能力。在机器学习中,过度拟合是指模型在训练数据上的性能非常好,但在未知数据上的性能较差的现象。为了避免过度拟合,我们可以通过正则化技术来限制模型的复杂性。
其中,L1正则化和L2正则化是最常见的两种正则化技术。L1正则化也称为Lasso回归,它通过对模型权重施加L1范数惩罚来达到减少模型复杂性的目的。L2正则化也称为Ridge回归,它通过对模型权重施加L2范数惩罚来达到同样的效果。这两种正则化技术都可以有效地防止模型过拟合,从而减少幻觉问题的发生。
具体来说,当我们在训练模型时,除了最小化损失函数之外,还要最小化正则化项。这个正则化项就是由L1或L2范数惩罚构成的。通过这种方式,我们可以使得模型的权重更加稀疏,从而减少模型的复杂性。这样,模型就不会对训练数据过于敏感,而是在更广泛的数据上表现出更好的性能。
除了L1和L2正则化之外,还有许多其他的正则化技术,如dropout、weight decay等。这些技术都可以帮助我们提高模型的泛化能力,减少幻觉问题的发生。在实践中,我们应该根据具体的问题和数据来选择合适的正则化技术。
3. 集成学习:
集成学习是一种有效的机器学习方法,通过将多个模型的预测结果结合起来,以获得更准确、更稳定的预测结果。这种方法可以降低单个模型的过度拟合风险,提高模型的泛化能力。
集成学习的基本思想是将多个模型组合成一个强大的模型,以便更好地处理复杂的任务。这些模型可以是同一种类型的模型,也可以是不同类型的模型。通过将多个模型的预测结果进行组合,可以获得更好的预测性能。
集成学习的优点包括:提高模型的准确性和稳定性,降低过拟合的风险,增强模型的泛化能力等。集成学习方法有很多种,包括Bagging、Boosting和Stacking等。这些方法通过不同的方式将多个模型组合在一起,以获得更好的性能。
例如,在Bagging方法中,每个模型在训练数据上的训练样本选择是随机的,每个模型都有不同的权重。Boosting方法则是通过改变每个模型的权重来优化整体的性能。Stacking方法则是将多个模型的预测结果作为新的特征,输入到另一个模型中进行训练。
在实际应用中,集成学习方法可以帮助我们获得更好的预测结果,提高模型的泛化能力。但是,如何选择合适的集成学习方法以及如何将多个模型组合在一起是一个具有挑战性的问题。未来,随着技术的发展和研究的深入,我们期待看到更多创新的集成学习方法出现。
4. 数据增强:
在训练过程中使用数据增强技术,通过对训练数据进行变换和扩充,使模型更加鲁棒,减少对特定样本的过度依赖。
在训练深度学习模型时,数据增强是一种非常重要的技术。通过数据增强,我们可以通过对原始数据进行各种变换和扩充,从而生成大量新的训练样本。这种技术有助于提高模型的泛化能力,使其在面对不同的输入数据时能够更加稳定和可靠。
数据增强可以通过各种方式实现,例如对图像进行旋转、平移、缩放、翻转等操作,或者对音频数据进行重采样、加噪声等处理。这些变换可以帮助模型更好地理解数据的内在结构和模式,从而在训练过程中更加精准地拟合数据。
数据增强在深度学习领域的应用非常广泛,尤其在计算机视觉和语音识别领域。例如,在图像分类任务中,通过对训练图像进行随机裁剪、旋转和翻转等操作,可以扩充训练样本的数量和多样性,从而提高模型的分类准确率。在语音识别任务中,通过对语音信号进行加噪声、变速等处理,可以帮助模型更好地适应不同的语音环境和说话风格。
数据增强不仅可以提高模型的泛化能力,还可以在一定程度上缓解数据不平衡的问题。例如,在处理具有类别不平衡的数据集时,可以通过对少数类别的样本进行数据增强,生成更多的虚拟样本,从而使得模型在训练过程中更多地关注这些样本,提高模型的分类性能。
总之,数据增强是一种非常有效的技术,可以帮助我们训练更加鲁棒和可靠的深度学习模型。通过对训练数据进行各种变换和扩充,我们可以提高模型的泛化能力,使其更好地适应不同的输入数据和环境。在未来,随着深度学习技术的不断发展,数据增强技术也将会更加成熟和多样化。
5. 早停:
在训练模型时,为了避免过度拟合,我们可以采用早停技术。早停是指在训练过程中,通过监测模型在验证集上的性能,当模型的性能停止提升时,提前停止训练。这样可以确保模型在训练数据上不会过拟合,而是在验证数据上仍能保持较好的性能。
过度拟合是指模型在训练数据上表现非常好,但在测试或实际应用中表现较差。这是因为在训练过程中,模型过于复杂,以至于记住了训练数据中的噪声和无关信息,而忽略了更一般的规律。早停技术可以有效地避免过度拟合,因为它在模型性能停止提升时停止训练,避免了模型过拟合的训练数据。
在实际应用中,我们可以设置一个阈值,当模型在验证集上的性能提升小于这个阈值时,就可以认为模型的性能已经停止提升。此时,我们可以选择停止训练,以避免过拟合。
此外,除了早停技术,还有其他一些防止过度拟合的方法,如正则化、集成学习等。这些方法都可以帮助我们训练出更好的模型,提高模型的泛化能力。
6. 特征工程:
特征工程在机器学习中扮演着至关重要的角色,它是将原始数据转化为模型可理解的形式的过程。这个过程涉及到对数据的深入理解、精细的工程设计和领域知识的应用。通过仔细选择和设计输入特征,我们能够降低模型的复杂性,提高其泛化能力,并减少对噪声的敏感度。
在实践中,特征的选择和设计是相辅相成的。首先,我们需要理解数据集的内在结构,识别出关键的特征以及它们之间的关系。例如,在图像分类任务中,边缘和纹理等低级特征可以被组合成更高级的概念,如形状或对象部分。这种特征级别的抽象有助于模型更好地理解和分类图像。
此外,领域知识在特征工程中起着关键作用。领域专家可以提供对数据的深入理解,并指导我们提取有意义、有信息量的特征。例如,在医学影像分析中,医生可以提供有关器官结构和功能的专业知识,帮助我们提取与疾病诊断相关的特征。这种跨学科的合作是推动特征工程发展的重要途径。
为了减少模型对噪声的敏感度,我们还需要关注特征的质量和稳定性。这涉及到对特征的预处理和后处理阶段。例如,通过特征缩放、编码技术或特征选择方法,我们可以消除冗余特征、处理缺失值或降低异常值的影响。此外,使用核方法或深度学习技术可以自动从原始数据中提取复杂的非线性特征,进一步提高模型的鲁棒性。
综上所述,特征工程是机器学习中的一项关键任务。通过深入理解数据、利用领域知识、关注特征质量和稳定性,我们可以成功地降低模型的复杂性,提高其泛化能力,并减少对噪声的敏感度。在未来的研究中,我们将继续探索更加智能和自动的特征工程技术,以推动机器学习领域的进步。
7. 对抗训练:
对抗训练是一种有效的训练深度学习模型的方法,通过在训练数据中添加经过特殊设计的扰动,可以提高模型的鲁棒性和泛化能力。在对抗训练中,模型需要学会识别并抵抗这些扰动,从而更好地适应真实世界的复杂性和不确定性。
在对抗训练中,可以采用多种策略来生成对抗样本。其中一种常见的方法是使用生成对抗网络(GAN)来生成具有挑战性的样本。GAN由两个神经网络组成:生成器和判别器。生成器的任务是生成与真实数据尽可能相似的样本,而判别器的任务是区分真实样本和生成样本。通过让这两个网络相互竞争,可以生成高质量的对抗样本,从而提高模型的鲁棒性。
除了GAN,还有其他方法可以生成对抗样本。例如,可以使用噪声来添加扰动,或者使用优化技术来寻找能够使模型产生错误分类的样本。在对抗训练中,还可以采用不同的攻击方法来评估模型的鲁棒性。这些攻击方法包括但不限于:Fast Gradient Sign Method(FGSM)、Carlini & Wagner Attack(C&W)等。通过对抗训练和攻击评估,可以发现模型中的脆弱点,并采取相应的措施来提高模型的鲁棒性。
对抗训练不仅可以帮助提高模型的鲁棒性,还可以提高模型的泛化能力。在传统的监督学习中,模型通常只会在训练数据上表现良好,而对训练数据以外的数据进行分类时可能会出现偏差。通过对抗训练,模型可以在更加广泛的范围内进行学习,从而更好地泛化到新的数据集上。
总之,对抗训练是一种有效的训练深度学习模型的方法,可以帮助提高模型的鲁棒性和泛化能力。通过在训练数据中添加经过特殊设计的扰动,可以使模型更好地适应真实世界的复杂性和不确定性。在对抗训练中,可以采用多种策略来生成对抗样本和评估模型的鲁棒性,从而发现模型中的脆弱点并采取相应的措施来提高模型的性能。
8. 监控和调试:
在生产环境中,实施有效的监控和调试机制至关重要。通过实时监测模型的表现,我们能够及时发现其在应用中出现的幻觉问题。一旦发现这些问题,我们可以迅速采取措施进行修正或更新模型,以确保其持续提供准确的结果。监控与调试是保障机器学习模型在实际应用中稳定运行的关键环节。
要有效地实施监控和调试,我们需要建立一个完善的监控系统。这个系统应该能够收集并分析模型在生产环境中的实时数据,包括输入和输出数据、运行时指标等。通过定期检查这些数据,我们可以了解模型的性能和可能的异常情况。一旦发现异常,比如模型出现了幻觉问题,我们可以迅速触发相应的调试机制。
在调试过程中,我们需要深入了解模型的工作原理和可能出现幻觉的原因。这可能涉及到对模型的内部结构和算法进行深入分析,以及对比实际应用场景与训练场景的差异。通过对比分析,我们可以定位问题所在,并采取相应的修正措施。
为了确保监控和调试的有效性,我们还需要制定一套完善的流程。这个流程应该包括定期检查、问题诊断、修正措施的制定和实施等环节。每个环节都需要有明确的责任人和时间节点,以确保整个流程的高效运行。
监控和调试是机器学习模型在实际应用中不可或缺的一环。通过建立完善的监控系统、深入分析模型和制定有效的流程,我们可以确保模型在实际应用中稳定运行,并提供准确的结果。这不仅有助于提高模型的可靠性,也有助于提高用户对我们产品的信任度。
选择适合问题的方法可能需要一定的实验和领域专业知识。综合利用上述方法,可以提高大模型的性能,并减少出现幻觉问题的可能性。

四、大模型技术的未来
随着技术的不断进步,大模型技术在未来的发展潜力将会越来越广泛。在语音识别、自然语言处理、计算机视觉等领域,大模型技术都展现出了强大的能力。
首先,大模型技术将会进一步提升语音识别和自然语言处理的能力。通过更深入的学习和训练,大模型将会更好地理解和处理人类语言,进一步提升语音识别和自然语言处理的准确率和效率。这将会带来更高效的人机交互,使人们能够更方便地与机器进行交流。
其次,大模型技术也将会在计算机视觉领域发挥更大的作用。随着深度学习技术的发展,大模型已经在图像识别、目标检测等领域取得了显著的成果。未来,随着计算能力的不断提升和算法的改进,大模型在计算机视觉领域的应用将会更加广泛,能够实现更加精细和准确的图像识别和处理。
此外,大模型技术也将会带来更高效的数据处理和分析能力。通过对大规模数据的处理和分析,大模型能够挖掘出数据中隐藏的规律和模式,从而为企业提供更有价值的商业分析和决策支持。这有助于企业更好地理解市场和客户需求,优化自身的经营和管理。
大模型技术在未来的发展潜力广泛,将会在语音识别、自然语言处理、计算机视觉以及数据处理等领域发挥更大的作用。随着技术的不断进步和应用场景的不断拓展,大模型技术将会为人类带来更多的便利和创新。
相关文章:
老生重谈:大模型的「幻觉」问题
一、什么是大模型「幻觉」 大模型的幻觉问题通常指的是模型在处理输入时可能会产生一些看似合理但实际上是错误的输出,这可能是因为模型在训练时过度拟合了训练数据,导致对噪声或特定样本的过度敏感。 "大数据幻觉"指的是在处理大规模数据时…...

golang实现skiplist 跳表
跳表 package mainimport ("errors""math""math/rand" )func main() {// 双向链表///**先理解查找过程Level 3: 1 6Level 2: 1 3 6Level 1: 1 2 3 4 6比如 查找2 ; 从高层往下找;如果查找的值比当前值小 说明没有可查找的值2比1大 往当前…...
尝试OmniverseFarm的最基础操作
目标 尝试OmniverseFarm的最基础操作。本地机器作为Queue和Agent,同时在本地提交任务。 主要参考了官方文档: Farm Queue — Omniverse Farm latest documentation Farm Agent — Omniverse Farm latest documentation Farm Examples — Omniverse Far…...
)
第28关 k8s监控实战之Prometheus(二)
------> 课程视频同步分享在今日头条和B站 大家好,我是博哥爱运维。 这节课我们用prometheus-operator来安装整套prometheus服务 https://github.com/prometheus-operator/kube-prometheus/releases 开始安装 1. 解压下载的代码包 wget https://github.com/…...

基于 SpringBoot + magic-api + Vue3 + Element Plus + amis3.0 快速开发管理系统
Tansci-Boot 基于 SpringBoot2 magic-api Vue3 Element Plus amis3.0 快速开发管理系统 Tansci-Boot 是一个前后端分离后台管理系统, 前端集成 amis 低代码前端框架,后端集成 magic-api 的接口快速开发框架。包含基础权限、安全认证、以及常用的一…...

Kafka(四)Broker
目录 1 配置Broker1.1 Broker的配置broker.id0listererszookeeper.connectlog.dirslog.dir/tmp/kafka-logsnum.recovery.threads.per.data.dir1auto.create.topics.enabletrueauto.leader.rebalance.enabletrue, leader.imbalance.check.interval.seconds300, leader.imbalance…...

代码随想录第五十二天——最长递增子序列,最长连续递增序列,最长重复子数组
leetcode 300. 最长递增子序列 题目链接:最长递增子序列 dp数组及下标的含义 dp[i]表示i之前包括i的以nums[i]结尾的最长递增子序列的长度递推公式 位置i的最长升序子序列等于j从0到i-1各个位置的最长升序子序列 1 的最大值 所以if (nums[i] > nums[j]) dp[i]…...
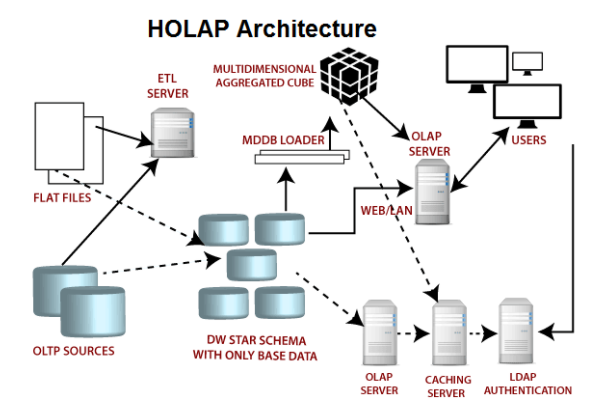
【大数据架构】OLAP实时分析引擎选型
OLAP引擎面临的挑战 常见OLAP引擎对比 OLAP分析场景中,一般认为QPS达到1000就算高并发,而不是像电商、抢红包等业务场景中,10W以上才算高并发,毕竟数据分析场景,数据海量,计算复杂,QPS能够达到1…...
代码随想录刷题题Day29
刷题的第二十九天,希望自己能够不断坚持下去,迎来蜕变。😀😀😀 刷题语言:C Day29 任务 ● 01背包问题,你该了解这些! ● 01背包问题,你该了解这些! 滚动数组 …...
CVE-2023-51385 OpenSSH ProxyCommand命令注入漏洞
一、背景介绍 ProxyCommand 是 OpenSSH ssh_config 文件中的一个配置选项,它允许通过代理服务器建立 SSH 连接,从而在没有直接网络访问权限的情况下访问目标服务器。这对于需要经过跳板机、堡垒机或代理服务器才能访问的目标主机非常有用。 二、漏洞简…...

如何寻找到相对完整的真正的游戏的源码 用来学习?
在游戏开发的学习之路上,理论与实践是并重的两个方面。对于许多热衷于游戏开发的学习者来说,能够接触到真实的、完整的游戏源码无疑是一个极好的学习机会。但问题来了:我们该如何寻找到这些珍贵的资源呢? 开源游戏项目 GitHub:地…...
数模学习day11-系统聚类法
本文参考辽宁石油化工大学于晶贤教授的演示文档聚类分析之系统聚类法及其SPSS实现。 目录 1.样品与样品间的距离 2.指标和指标间的“距离” 相关系数 夹角余弦 3.类与类间的距离 (1)类间距离 (2)类间距离定义方式 1.最短…...

SpringBoot+Redis实现接口防刷功能
场景描述: 在实际开发中,当前端请求后台时,如果后端处理比较慢,但是用户是不知情的,此时后端仍在处理,但是前端用户以为没点到,那么再次点击又发起请求,就会导致在短时间内有很多请求…...

TensorRT加速推理入门-1:Pytorch转ONNX
这篇文章,用于记录将TransReID的pytorch模型转换为onnx的学习过程,期间参考和学习了许多大佬编写的博客,在参考文章这一章节中都已列出,非常感谢。 1. 在pytorch下使用ONNX主要步骤 1.1. 环境准备 安装onnxruntime包 安装教程可…...

springboot常用扩展点
当涉及到Spring Boot的扩展和自定义时,Spring Boot提供了一些扩展点,使开发人员可以根据自己的需求轻松地扩展和定制Spring Boot的行为。本篇博客将介绍几个常用的Spring Boot扩展点,并提供相应的代码示例。 1. 自定义Starter(面试常问) Sp…...
19道ElasticSearch面试题(很全)
点击下载《19道ElasticSearch面试题(很全)》 1. elasticsearch的一些调优手段 1、设计阶段调优 (1)根据业务增量需求,采取基于日期模板创建索引,通过 roll over API 滚动索引; (…...

向爬虫而生---Redis 拓宽篇3 <GEO模块>
前言: 继上一章: 向爬虫而生---Redis 拓宽篇2 <Pub/Sub发布订阅>-CSDN博客 这一章的用处其实不是特别大,主要是针对一些地图和距离业务的;就是Redis的GEO模块。 GEO模块是Redis提供的一种高效的地理位置数据管理方案,它允许我们存储和查询…...

Vue项目里实现json对象转formData数据
平常调用后端接口传参都是json对象,当提交表单遇到有附件需要传递时,通常是把附件上传单独做个接口,也有遇到后端让提交接口一并把附件传递到后端,这种情况需要把参数转成formData的数据,需要用到new FormData()。json…...

leetcode刷题记录
栈 2696. 删除子串后的字符串最小长度 哈希表 1. 两数之和 用map来保存每个数和他的索引 383. 赎金信 用map来存储字符的个数 链表 2. 两数相加 指针的移动 动态规划 53. 最大子数组和 2707. 字符串中的额外字符 递归 101. 对称二叉树 数学 1276. 不浪费原料的汉堡…...
SpringMVC通用后台管理系统源码
整体的SSM后台管理框架功能已经初具雏形,前端界面风格采用了结构简单、 性能优良、页面美观大的Layui页面展示框架 数据库支持了SQLserver,只需修改配置文件即可实现数据库之间的转换。 系统工具中加入了定时任务管理和cron生成器,轻松实现系统调度问…...

OSINT自动化平台ClawShield:模块化架构与安全运营实战解析
1. 项目概述:一个面向安全运营的公开情报收集与分析平台最近在整理自己的开源项目收藏夹,发现一个挺有意思的仓库,叫SleuthCo/clawshield-public。乍一看这个名字,“ClawShield”,爪子与盾牌,就透着一股子攻…...

用PyTorch和ECANet18搞定RAF-DB表情分类:从数据集下载到模型部署的保姆级教程
基于ECANet18的RAF-DB表情识别实战:从零构建高精度分类模型 人脸表情识别(FER)作为计算机视觉领域的重要分支,在情感计算、智能交互等领域展现出巨大潜力。本文将带您完整实现一个基于PyTorch和ECANet18的端到端表情识别系统&…...

Excel MCP Server终极指南:3步实现无界面Excel自动化处理
Excel MCP Server终极指南:3步实现无界面Excel自动化处理 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了手动操作Excel的繁琐…...

PCL2启动器离线登录按钮消失?5分钟快速修复指南
PCL2启动器离线登录按钮消失?5分钟快速修复指南 【免费下载链接】PCL Minecraft 启动器 Plain Craft Launcher(PCL)。 项目地址: https://gitcode.com/gh_mirrors/pc/PCL 你是否遇到过PCL2启动器离线登录按钮突然消失的困扰࿱…...

All in Token, 移动,电信,联通,阿里,百度,华为,字节,Token石油战争,Token经济,百度要“重写”AI价值度量
AI Agent的价值,应该怎么被衡量? 2026年,AI行业的标志性拐点是Agent(智能体)快速普及。Agent作为核心生产力载体,将AI从Chatbot聊天模式带进主动执行的办事时代。 这个时候,如果我们还用旧尺子…...

开源婚礼技能库:用项目管理思维破解备婚焦虑,打造个性化高性价比婚礼
1. 项目概述:婚礼技能库的诞生与价值最近在GitHub上看到一个挺有意思的项目,叫“awesome-wedding-skills”。光看名字,你可能会觉得这又是一个普通的“awesome”系列资源列表,无非是收集一些婚礼策划、摄影、化妆的链接。但当我点…...

从零构建Next.js全栈应用:实战解析服务端渲染与API路由
1. 项目概述与核心价值最近在社区里看到不少朋友在讨论一个叫“panaverse/learn-nextjs”的项目,作为一个在Web开发领域摸爬滚打了十多年的老码农,我立刻来了兴趣。这个项目名直译过来就是“Panaverse的Next.js学习项目”,听起来像是一个学习…...

基于CircuitPython的Fruit Jam OS:在RP2350上构建复古微型计算机系统
1. 项目概述:当复古计算精神遇见现代微控制器如果你和我一样,对早期个人计算机那种开机即用、一切尽在掌控的纯粹体验抱有怀念,同时又痴迷于现代开源硬件带来的无限可能,那么Fruit Jam OS绝对是一个会让你眼前一亮的项目。它不是一…...

Svelte动态光标实现:状态驱动与Spring动画的交互设计
1. 项目概述:一个会“思考”的鼠标指针如果你在开发一个需要高度沉浸感和交互反馈的Web应用,比如一个设计工具、一个游戏界面,或者一个希望用户能“感受”到页面元素质感的网站,那么一个静态的、系统默认的鼠标指针就显得有些格格…...

MEMS传感器机械臂姿态检测【附代码】
✨ 长期致力于MEMS传感器、机械臂、惯性测量单元、数据融合、姿态检测系统研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)设计基于ICM20948的惯性测量…...