缓存与数据库的双写一致性
背景
在高并发的业务场景下,系统的性能瓶颈往往是出现在数据库上,用户并发访问过大,压力都打到数据库上。所以一般都会用redis做缓存层,起到一个缓冲作用,让请求先访问到缓存层,而不是直接去访问数据库,减轻数据库压力,从而减少网络请求的延迟响应,提高系统性能。一般在使用缓存和数据库结合的时候就会面临数据一致性问题,可能会经常遇到“明明数据已经更新了,怎么还是显示旧的”,下面就来分析下产生的原因及其对应处理方案。
数据更新的常见操作
注意:我们讲的数据一致性的前提是数据库更新和缓存删除不把它当成一个原子性操作。因为高并发场景下,我们不可能引入分布式锁将这两者操作绑定为一个原子性操作,如果绑定的话就会很大程度上影响系统并发性能,所以一般只追求最终一致性,本文也是针对非追求强一致性要求的场景,金融或银行业务的小伙伴请自行判断。
本文涉及到一种常用的缓存模式:Cache-Aside Pattern,即旁路缓存模式,这种模式就是为了尽可能地解决缓存和数据库的数据一致性问题。这种模式分为读请求和写请求两种。
读请求流程:
读的时候,先读取缓存,若缓存命中的话,直接返回数据。
若缓存没有命中,就去读数据库,从数据库取出数据,放入缓存后,返回响应。
写请求流程:
更新数据的时候,先更新数据库,然后再删除缓存。
下面罗列出常见的几种数据更新的方式及其对应的问题:
1、先更新数据库,后更新缓存
流程如下图:

1.请求A先发起一个写操作,先更新数据库
2.请求B再发起一个写操作,更新了数据库
3.由于网络等原因,请求B先更新了缓存
4.请求A更新缓存
问题如上所示,缓存保存的是A的数据(旧数据),数据库保存的是B的数据(新数据),数据不一致,脏数据出现。
这种场景一般不推荐使用。因为有的业务需求中缓存里的值并不是直接从数据库中查出的,有的是需要经过一系列操作计算出缓存的值,那么这时候你要更新缓存的代价是很高的。如果这时有大量请求需要对数据库进行写操作,但是读的请求并不多,那么每次写操作都更新一次缓存,性能损耗是非常大的。
举个最简单的例子:数据库中有一个num字段的值为1,这时有10个请求对其进行递增加一的操作,但是这期间读请求很少,如果是先更新数据库,后更新缓存的话,那么就会有十个请求对缓存进行更新,这样会有大量的冷数据产生。如果选择删除缓存而不是更新缓存,那么在读请求进来的时候就只会更新一次缓存。这样的话哪种操作消耗的资源更多是不是就很明显了。
2、先更新缓存,后更新数据库
这一种情况和上一种是类似的,这里就不再赘述。
3、先删除缓存,后更新数据库
流程如下图:

1.请求A先发起一个写操作,先删除缓存,此时会还没更新数据库完成(可能在还没更新,或者正在更新,但事务还未提交)
2.此时请求B发起一个读操作,读取到缓存数据为空
3.请求B在缓存中读不到数据,就去读取数据库并将旧数据写入缓存(脏数据)
4.请求A更新DB完成
问题如上所示,缓存保存的是旧数据(请求B将脏数据写入了缓存),如果是一个读多写少的数据,可能脏数据会存在比较长的时间(要么后续有更新,要么等待缓存过期),这在业务上是不能接受的。
4、先更新数据库,后删除缓存
流程如下图:

1.请求A先发起一个写操作,先更新数据库,此时还没删除缓存完成
2.此时请求B发起一个读操作,读取到的缓存数据为旧数据
3.请求A删除缓存
问题如上所示,在请求A更新数据库和删除缓存之间请求B会读取到旧数据,因为此时整个请求A的操作还没有完成,并且读到旧数据的时间是非常短的,而后请求后会删除缓存,所以可以满足数据最终一致性要求。但是不排除请求A删除缓存失败的可能。
分析
先来对以上几种方式进行概括分析,可以分为这两种选择,1、是更新缓存还是删除缓存,2、是先更新数据库还是先操作缓存
是更新缓存还是删除缓存,结合上面的第1、2点的例子可以得出是选择删除缓存
更新缓存相对于删除缓存两点劣势:
- 如果你写入的缓存,是经过复杂计算才得到的话。更新缓存的频率高,性能损耗大。
- 在写操作多,读数据少的场景下,缓存数据很多时候还没被读取到,又被更新了,浪费了资源(写多读少的场景用缓存不是很划算)
根据上面分析的结论是删除缓存,那么是先更新数据库还是先删除缓存?
由上面第3点的例子,可以看出如果是先删除缓存再更新DB,会有较大可能导致缓存保存的是旧数据,数据库保存的是新数据。
有的人会说,那第4点的先更新数据库再删除缓存,不也可能导致缓存中是旧数据?
其实只要是非原子性操作就都可能出现数据不一致的情况,但是第四点这种方式,一般是因为删除缓存失败等原因,才会导致缓存了脏数据,这个概率会低很多。
解决方案
其实上面第3点和第4点的问题,删除缓存失败的情况,我们只要保证他删除成功就可以。
一、延时双删缓存
以上面第3点例,先删除缓存再更新数据库,最直观能想到的最简单的办法就是延时双删。什么是延时双删,看完如下图流程就明白了。

在原来第3点,先删除缓存再更新数据库的基础上,在请求A更新完数据库后,休眠一下(比如1秒),然后再次删除缓存。
这种方案只有休眠那一下,可能有脏数据被读取,一般业务也可以接受的。这个休眠延迟时间一般要根据读业务逻辑的耗时去估算(比较难)然后增加相应几百毫秒的延迟。
但是如果第二次删除缓存又失败了?给key设置一个过期时间?业务上能否接受在key过期之前的这段时间内的数据不一致?
二、重试删除缓存
根据业务预估缓存过期时间很麻烦,而且你预估的也不一定准,可能还有其他什么原因造成过期时间过短或过长而影响了正常业务。
既然如此,前两次都删除失败了,那我多删他几次保证他删除成功就可以了。
利用消息队列进行重试删除缓存的补偿机制,流程如下图:

1.写请求进来,先更新数据库
2.由于某些原因,删除缓存失败
3.把删除失败的key推送到消息队列
4.消费队列消息,获取要删除的key
5.重试删除缓存
上面第3点和第四点的例子,均可以使用此方案。但这个方案有一个缺点:会对业务代码造成大量侵入,耦合在一起。
三、异步淘汰缓存
重试删除缓存机制已经满足保持数据一致性的要求,但是会造成好多业务代码入侵。所以可以优化下:开一个订阅服务(独立的中间系统),负责通过订阅数据库(如mysql)的binlog来异步淘汰缓存。
mysql更新数据后在binlog日志中都有相应的记录,我们可以订阅mysql的binlog对缓存进行操作。流程如下图:

异步淘汰机制可以达到想要的双写一致性效果,但是对应的也有他的缺点:增加了整个系统的复杂度。
踩坑
注意⚠️:上面讲的数据库和缓存都是普通的单机情况下的。
这里讲下我以前踩过的坑,上面第3点的例子,先删除缓存,后更新数据库,然后异步淘汰。
这里还隐藏着一个问题:如果你使用的是mysql读写分离架构的话,主从同步之间会有时延问题,这就有可能产生脏数据。
看如下图流程你就明白了,先不复杂化,搞个大家都能看懂的。我假设缓存删除成功,更新数据库也成功,这两者之间没有其他读请求插入:

如上所示,请求A和请求B操作时序没问题,是主从同步的时延问题(假设1s),导致读请求读取到从库中的脏数据
1.请求A先发起一个写请求,先删除了缓存
2.请求A请求主库进行更新数据
3.主库与从库进行数据同步
4.请求B发起一个读请求,读取缓存中的数据为空
5.请求B去DB从库中取数据,由于主库压力大/处理数据量多/网络原因等,此时主从同步还没完成。请求B读取到DB从库中的旧数据并写入缓存中
6.最后主从同步完成
我之前的解决方案:如果缓存数据为空,需要查询DB再设置到缓存的操作,就强制将查询的DB指向master进行查询。
总结
每种方式和方案都各有利弊。
比如先删除缓存,后更新数据库这个方式,我们最终选择了重试删除缓存+更新Redis的时候强制走主库查询就能解决问题,但是这操作会对业务代码进行大量的侵入,但是不需要增加新的中间系统去处理,不需要增加整体的服务的复杂度。
如果我们选择异步淘汰缓存的方案,利用订阅binlog日志进行搭建独立的中间系统来操作缓存,但就样就增加了系统复杂度,复杂度增加带来的风险往往是后知后觉的。
其实每种方案的选择都需要我们对本身的业务进行评估,没有一种技术是对所有业务都通用的。我觉得最难的是寻找最佳效益的平衡点的取舍问题,就像常说的:没有最好的,只有最适合你的。
我是六涛sheliutao,文章编写总结不易,转载注明出处,喜欢本篇文章的小伙伴欢迎点赞、关注,有问题可以评论区留言或者私信我,相互交流!!!
相关文章:
缓存与数据库的双写一致性
背景 在高并发的业务场景下,系统的性能瓶颈往往是出现在数据库上,用户并发访问过大,压力都打到数据库上。所以一般都会用redis做缓存层,起到一个缓冲作用,让请求先访问到缓存层,而不是直接去访问数据库&am…...
)
力扣-213打家劫舍II(dp)
力扣-213打家劫舍II 1、题目 213. 打家劫舍 II 你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通…...
关于【网格结构】岛屿类问题的通用解法DFS(深度遍历)遍历框架+回溯+剪枝总结
最近在刷力扣时遇见的问题,自己总结加上看了力扣大佬的知识总结写下本篇文章,我们所熟悉的 DFS(深度优先搜索)问题通常是在树或者图结构上进行的。而我们今天要讨论的 DFS 问题,是在一种「网格」结构中进行的。岛屿问题…...

【LeetCode】982. 按位与为零的三元组
982. 按位与为零的三元组 题目描述 给你一个整数数组 nums ,返回其中 按位与三元组 的数目。 按位与三元组 是由下标 (i, j, k) 组成的三元组,并满足下述全部条件: 0 < i < nums.length0 < j < nums.length0 < k < num…...

Linux内核源码进程原理分析
Linux内核源码进程原理分析一、Linux 内核架构图二、进程基础知识三、Linux 进程四要素四、task_struct 数据结构主要成员五、创建新进程分析六、剖析进程状态迁移七、写时复制技术一、Linux 内核架构图 二、进程基础知识 Linux 内核把进程称为任务(task),进程的虚…...

电子技术——CMOS反相器
电子技术——CMOS反相器 在本节,我们深入学习CMOS反相器。 电路原理 下图是我们要研究的CMOS反相器的原理图: 下图展示了当输入 vIVDDv_I V_{DD}vIVDD 时的 iD−vDSi_D-v_{DS}iD−vDS 曲线: 我们把 QNQ_NQN 当做是驱动源&#x…...
)
gazebo仿真轨迹规划+跟踪(不在move_base框架下)
以Tianbot为例子,开源代码如下: https://github.com/tianbot/tianbot_mini GitHub - tianbot/abc_swarm: Ant Bee Cooperative Swarm, indicating air-ground cooperation. This repository is for Tianbot Mini and RoboMaster TT swarm kit. 1.在…...

C. Good Subarrays(前缀和)
C. Good Subarrays一、问题二、分析三、代码一、问题 二、分析 这道题目的意思就是给我们一个数组,然后我们从数组中选取一个连续的区间,这个区间满足条件:区间内的元素和等于区间的长度。 对于区间和问题我们先想到的是前缀和的算法。 那…...
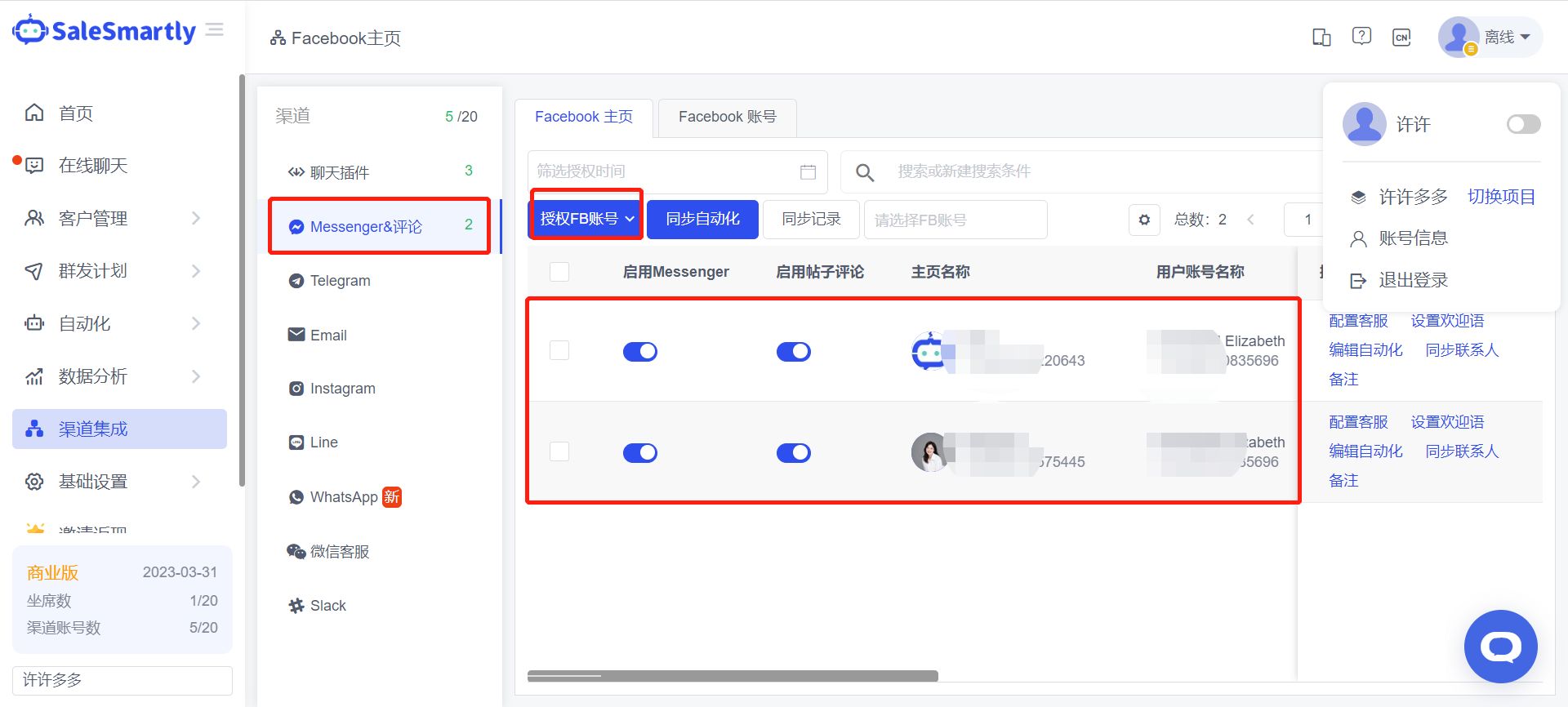
关于Facebook Messenger CRM,这里有你想要知道的一切
关于Facebook Messenger CRM,这里有你想要知道的一切!想把Facebook Messenger与你的CRM整合起来吗?这篇博文是为你准备的! 我们将介绍有关获得Facebook Messenger CRM整合的一切信息。然后,我们将解释为什么你需要像SaleSmartly&a…...
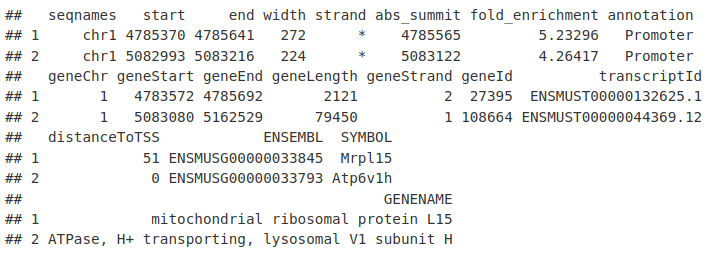
ChIP-seq 分析:数据与Peak 基因注释(10)
动动发财的小手,点个赞吧! 1. 数据 今天,我们将继续回顾我们在上一次中研究的 Myc ChIPseq。这包括用于 MEL 和 Ch12 细胞系的 Myc ChIPseq。 可在此处[1]找到 MEL 细胞系中 Myc ChIPseq 的信息和文件可在此处[2]找到 Ch12 细胞系中 Myc ChIP…...
)
《C++ Primer Plus》第18章:探讨 C++ 新标准(8)
使用大括号括起的初始化列表语法重写下述代码。重写后的代码不应使用数组 ar: class Z200 { private:int j;char ch;double z; public:Z200(int jv, char chv, zv) : j(jv), ch(chv), z(zv) {} ... };double x 8.8; std::string s "What a bracing effect!&q…...
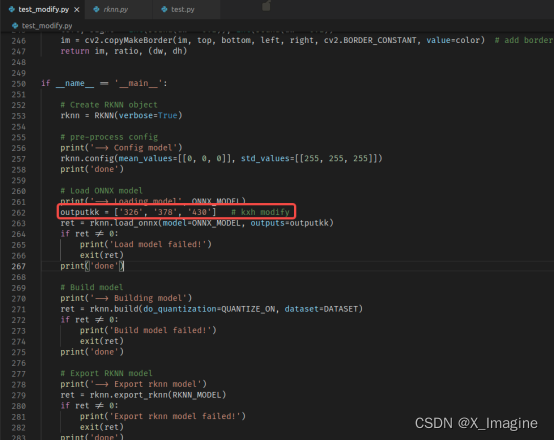
YOLO-V5 系列算法和代码解析(八)—— 模型移植
文章目录工程目标芯片参数查阅官方文档基本流程Python 版工具链安装RKNPU2的编译以及使用方法移植自己训练的模型工程目标 将自己训练的目标检测模型【YOLO-V5s】移植到瑞芯微【3566】芯片平台,使用NPU推理,最终得到正确的结果。整个过程涉及模型量化、…...

js实现复制拷贝的兼容方法
1. 定义复制拷贝的方法 在某个工具类方法中定义该方法,兼容不同浏览器处理 /*** description 拷贝的类方法*/ class CopyClass {// constructor() {}setRange(input) {return new Promise((resolve, reject) > {try {// 创建range对象const range document.c…...
学习 Python 之 Pygame 开发魂斗罗(八)
学习 Python 之 Pygame 开发魂斗罗(八)继续编写魂斗罗1. 创建敌人类2. 增加敌人移动和显示函数3. 敌人开火4. 修改主函数5. 产生敌人6. 使敌人移动继续编写魂斗罗 在上次的博客学习 Python 之 Pygame 开发魂斗罗(七)中࿰…...
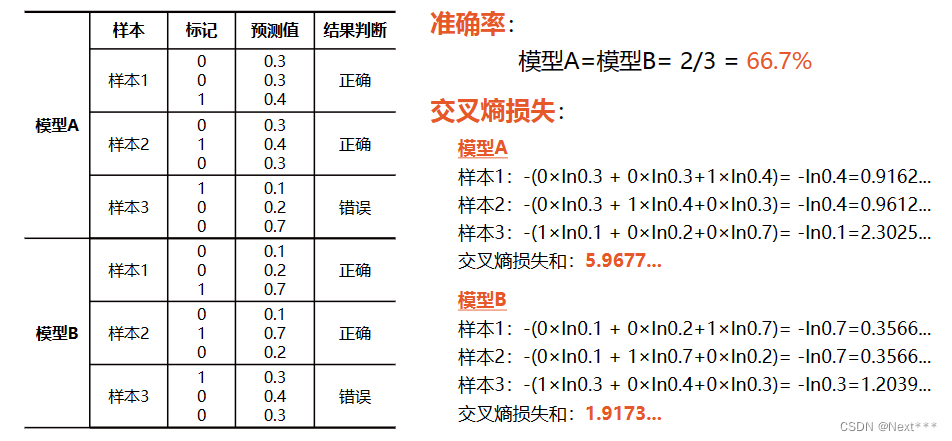
Lesson11---分类问题
11.1 逻辑回归 11.1.1 广义线性回归 课程回顾 线性回归:将自变量和因变量之间的关系,用线性模型来表示;根据已知的样本数据,对未来的、或者未知的数据进行估计 11.1.2 逻辑回归 11.1.2.1 分类问题 分类问题:垃圾…...

Python基础学习12——异常
在Python中,会使用“异常”这个十分特殊的对象来管理程序执行期间发生的错误,即报错。本文将介绍一下python基础的处理异常的方法以及一些基本的异常类型。 异常处理方法 try-except代码块 当我们编写程序时,我们可以编写一个try-except代…...

[日常练习]练习17:链表头插法、尾插法练习
[日常练习]练习17:链表头插法、尾插法练习练习17描述输入输出输入示例1输出示例1输入示例2输出示例2代码演示:总结练习17 【日常练习】 链表头插法、尾插法练习 描述 输入3 4 5 6 7 9999一串整数,9999代表结束,通过头插法新建链…...
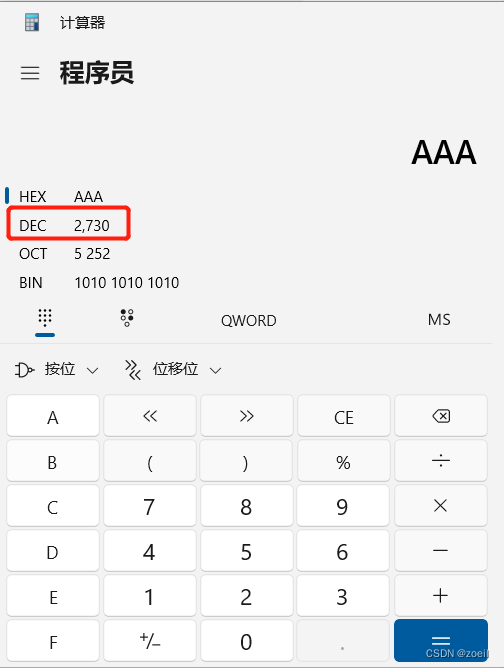
第十四届蓝桥杯模拟赛(第三期)试题与题解 C++
目录 一、填空题 (一)最小的十六进制(答案:2730) (二)Excel的列(答案:BYT) (三)相等日期(答案:70910) (四)多少种取法(答案:189)…...

关于 “宏“
起源 宏 Macro"这个词源于希腊语 “makros”,意为“大的,长的” 延伸使用 随后用于计算机领域是,在汇编语言时用于描述一大堆的汇编指令。 只要用宏指令,就是直接用的一大堆的汇编指令(有点函数的味道…...

1.2 CSS标签选择器,类选择器
CSS选择器: 根据不同的需求选出不同的标签,进行美化装饰 1. 标签选择器 标签选择器(元素选择器):用 HTML标签名作为选择器,按标签名称进行分类,为页面某一类标签指定统一的CSS样式 作用: 可以把某一类标签全部选中&…...

拨叉[831002] 2-钻φ60孔夹具
拨叉作为机械传动系统中的关键零件,其加工精度直接影响设备运行的稳定性。在2-钻φ60孔的工序中,专用夹具的核心作用在于通过精准定位与可靠夹紧,确保孔径尺寸、位置度及表面粗糙度等关键指标符合设计要求。该夹具采用“一面两销”定位原理&a…...
)
线程与进程的区别与联系:操作系统入门详解(含 Python 示例)
、先搞懂:进程与线程到底是什么?(通俗类比官方定义) 1.1 生活化类比:快速建立认知 如果把计算机的操作系统比作一个大型工厂: 进程:就是工厂里的一个个独立车间。每个车间有自己专属的生产资…...
)
告别TeamViewer!用RustDesk自建服务器实现跨平台远程控制(Windows/Ubuntu客户端全配置)
告别商业远程控制软件:用RustDesk自建服务器全流程指南 远程控制软件已经成为现代工作场景中不可或缺的工具,无论是技术支持、远程办公还是跨设备协作,一个稳定高效的远程连接方案都能极大提升工作效率。然而,商业软件如TeamViewe…...

唯品会数据采集API接口||电商API数据采集
唯品会数据采集,优先走合规第三方 API(个人 / 企业均可);企业可申请官方开放平台 API(仅限合作方)。一、合规路径选择(必看)1. 官方开放平台(企业级)入口&…...
)
给STM32密码锁加个“记忆”:手把手教你用CubeMX配置I2C读写EEPROM(AT24C02)
为STM32密码锁赋予持久记忆:CubeMX驱动AT24C02 EEPROM全攻略 当你的密码锁在断电后依然能记住最后一次设置的密码,这种"记忆"能力往往能大幅提升用户体验。本文将带你深入探索如何通过I2C总线连接AT24C02 EEPROM芯片,为基于STM32F1…...

使用Java实现数据的生产和消费
【Kafka】Java实现数据的生产和消费 Kafka介绍 Kafka 是由 LinkedIn 公司开发的,它是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统。 Kafka术语 …...

5大场景重构AI协作流程:Awesome Claude Skills实战指南
5大场景重构AI协作流程:Awesome Claude Skills实战指南 【免费下载链接】awesome-claude-skills A curated list of awesome Claude Skills, resources, and tools for customizing Claude AI workflows 项目地址: https://gitcode.com/GitHub_Trending/aw/awesom…...

若依框架多数据源实战:如何用@DataSource注解轻松切换MySQL主从库
若依框架多数据源实战:用DataSource注解实现MySQL主从库智能切换 当系统流量逐渐攀升,数据库的读写压力开始显现时,很多开发者都会面临一个关键决策:如何在保证数据一致性的前提下,有效分散数据库负载?若依…...

3个技巧快速解锁百度网盘SVIP下载特权
3个技巧快速解锁百度网盘SVIP下载特权 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 你是否曾因百度网盘Mac版的下载速度而苦恼?普通用户下…...

Python量化交易入门:利用Baostock API高效获取股票历史数据
1. 为什么选择Baostock获取股票数据? 第一次接触量化交易时,最头疼的就是数据来源问题。市面上的数据接口要么收费昂贵,要么数据质量参差不齐。直到发现了Baostock这个宝藏工具,我的量化研究才真正走上正轨。 Baostock最大的优势在…...