Flask源码篇:Flask路由规则与请求匹配过程(超详细,易懂)
目录
- 1 启动时路由相关操作
- (1)分析app.route()
- (2)分析add_url_rule()
- (3)分析Rule类
- (4)分析Map类
- (5)分析MapAdapter类
- (6)分析 url_rule_class()
- (7)分析map.add(rule)
- 2 请求进来时路由匹配过程
- (1)分析wsgi_app
- (2)分析request_context
- (3)分析ctx.push
- (4)分析full_dispatch_request
- 3 总结
如果不想看具体的解析过程,可以直接看总结,一样可以看懂!
1 启动时路由相关操作
所谓的路由原理,就是Flask如何创建自己的路由体系,并当一个请求到来时,如何根据路由体系准确定位处理函数,并响应请求。
本节还是以最简单一个Flask应用例子来展开讲解路由原理,如下:
from flask import Flaskapp = Flask(__name__)@app.route('/')
def hello_world():return 'Hello World!'if __name__ == '__main__':app.run()
(1)分析app.route()
首先路由的注册是通过scaffold(Flask继承scaffold)包下的route()装饰器实现的,其源码如下:
def route(self, rule: str, **options: t.Any) -> t.Callable:def decorator(f: t.Callable) -> t.Callable:# 获取endpointendpoint = options.pop("endpoint", None)# 添加路由,rule就是app.route()传来的路由字符串,及'/'self.add_url_rule(rule, endpoint, f, **options)return freturn decorator
可以看到这个装饰器主要做了两件事:1.获取endpoint;2.添加路由。
其中最重要的是函数add_url_rule(),用来添加路由映射。
补充:
- endpoint是在后面Flask存储路由和函数名映射的时候用到,如果没有指定,默认是被装饰的函数名。具体如何使用,后面还会分析到;
- 因为app.route()的本质还是add_url_rule()函数,所以我们也可以直接使用这个函数,用法可以参考文章Flask路由。
(2)分析add_url_rule()
下面来看下add_url_rule做了哪些事,其核心源码如下:
class Flask(Scaffold):# 这里只有要讨论的主要代码,其他代码省略了url_rule_class = Ruleurl_map_class = Mapdef __init__(self,import_name: str,static_url_path: t.Optional[str] = None,static_folder: t.Optional[t.Union[str, os.PathLike]] = "static",static_host: t.Optional[str] = None,host_matching: bool = False,subdomain_matching: bool = False,template_folder: t.Optional[str] = "templates",instance_path: t.Optional[str] = None,instance_relative_config: bool = False,root_path: t.Optional[str] = None,):super().__init__(import_name=import_name,static_folder=static_folder,static_url_path=static_url_path,template_folder=template_folder,root_path=root_path,)self.url_map = self.url_map_class()self.url_map.host_matching = host_matchingself.subdomain_matching = subdomain_matchingdef add_url_rule(self,rule: str,endpoint: t.Optional[str] = None,view_func: t.Optional[t.Callable] = None,provide_automatic_options: t.Optional[bool] = None,**options: t.Any,) -> None:# 1.如果没提供endpoint,获取默认的endpointif endpoint is None:endpoint = _endpoint_from_view_func(view_func) # type: ignoreoptions["endpoint"] = endpoint# 2.获取请求方法,在装饰器@app.route('/index', methods=['POST','GET'])的method参数# 如果没有指定,则给个默认的元组("GET",)# 关于provide_automatic_options处理一些暂不看methods = options.pop("methods", None)if methods is None:methods = getattr(view_func, "methods", None) or ("GET",)if isinstance(methods, str):raise TypeError("Allowed methods must be a list of strings, for"' example: @app.route(..., methods=["POST"])')methods = {item.upper() for item in methods}# Methods that should always be addedrequired_methods = set(getattr(view_func, "required_methods", ()))# starting with Flask 0.8 the view_func object can disable and# force-enable the automatic options handling.if provide_automatic_options is None:provide_automatic_options = getattr(view_func, "provide_automatic_options", None)if provide_automatic_options is None:if "OPTIONS" not in methods:provide_automatic_options = Truerequired_methods.add("OPTIONS")else:provide_automatic_options = False# Add the required methods now.methods |= required_methods# 3.重要的一步:url_rule_class方法实例化Rule对象rule = self.url_rule_class(rule, methods=methods, **options)rule.provide_automatic_options = provide_automatic_options # type: ignore# 4.重要的一步:url_map(Map对象)的add方法self.url_map.add(rule)# 5.判断endpoint和view_func的映射存不存在,如果已经有其他view_func用了这个endpoint,则报错,否则新的映射加到self.view_functions里# self.view_functions继承自Scaffold,是一个字典对象if view_func is not None:old_func = self.view_functions.get(endpoint)if old_func is not None and old_func != view_func:raise AssertionError("View function mapping is overwriting an existing"f" endpoint function: {endpoint}")self.view_functions[endpoint] = view_func
分析上面源码,这个方法主要做了以下几件事:
- 如果没提供
endpoint,获取默认的endpoint; - 获取请求方法,在装饰器
@app.route('/index', methods=['POST','GET'])的method参数,如果没有指定,则给个默认的元组(“GET”,); self.url_rule_class():实例化Rule对象,Rule类后面还会再讲解;- 调用
self.url_map.add()方法,其中self.url_map是一个Map对象,后面还会再讲解; self.view_functions[endpoint] = view_func添加endpoint和view_func的映射。
其中实例化Rule对象和self.url_map.add()是Falsk路由里的核心,下面分析Rule类和Map类。
(3)分析Rule类
Rule类在werkzeug.routing模块下,其源码较多,这里也只摘取我们用到的主要代码,如下:
class Rule(RuleFactory):def __init__(self,string: str,methods: t.Optional[t.Iterable[str]] = None,endpoint: t.Optional[str] = None,# 此处省略了其他参数的代码 ...) -> None:if not string.startswith("/"):raise ValueError("urls must start with a leading slash")self.rule = stringself.is_leaf = not string.endswith("/")self.map: "Map" = None # type: ignoreself.methods = methodsself.endpoint: str = endpoint # 省略了其他初始化的代码def get_rules(self, map: "Map") -> t.Iterator["Rule"]:"""获取map对象的rule迭代器"""yield selfdef bind(self, map: "Map", rebind: bool = False) -> None:"""把map对象绑定到Rule对象上,并且根据rule和map信息创建一个path正则表达式,存储在rule对象的self._regex属性里,路由匹配的时候用"""if self.map is not None and not rebind:raise RuntimeError(f"url rule {self!r} already bound to map {self.map!r}")# 把map对象绑定到Rule对象上self.map = mapif self.strict_slashes is None:self.strict_slashes = map.strict_slashesif self.merge_slashes is None:self.merge_slashes = map.merge_slashesif self.subdomain is None:self.subdomain = map.default_subdomain# 调用compile方法创建一个正则表达式self.compile()def compile(self) -> None:"""编写正则表达式并存储到属性self._regex中"""# 此处省略了正则的解析过程代码regex = f"^{''.join(regex_parts)}{tail}$"self._regex = re.compile(regex)def match(self, path: str, method: t.Optional[str] = None) -> t.Optional[t.MutableMapping[str, t.Any]]:"""这个函数用于校验传进来path参数(路由)是否能够匹配,匹配不上返回None"""# 省去了部分代码,只摘录了主要代码,看一下大致逻辑即可if not self.build_only:require_redirect = False# 1.根据bind后的正则结果(self._regex正则)去找path的结果集m = self._regex.search(path)if m is not None:groups = m.groupdict()# 2.编辑匹配到的结果集,加到一个result字典里并返回result = {}for name, value in groups.items():try:value = self._converters[name].to_python(value)except ValidationError:return Noneresult[str(name)] = valueif self.defaults:result.update(self.defaults)return resultreturn None
Rule类继承自RuleFactory类,主要参数有:
string:路由字符串methods:路由方法endpoint:endpoint参数
一个Rule实例代表一个URL模式,一个WSGI应用会处理很多个不同的URL模式,与此同时产生很多个Rule实例,这些实例将作为参数传给Map类。
(4)分析Map类
Map类也在werkzeug.routing模块下,其源码较多,这里也只摘取我们用到的主要代码,主要源码如下:
class Map:def __init__(self,rules: t.Optional[t.Iterable[RuleFactory]] = None# 此处省略了其他参数) -> None:# 根据传进来的rules参数维护了一个私有变量self._rules列表self._rules: t.List[Rule] = []# endpoint和rule的映射self._rules_by_endpoint: t.Dict[str, t.List[Rule]] = {}# 此处省略了其他初始化操作def add(self, rulefactory: RuleFactory) -> None:"""把Rule对象或一个RuleFactory对象添加到map并且绑定到map,要求rule没被绑定过"""for rule in rulefactory.get_rules(self):# 调用rule对象的bind方法rule.bind(self)# 把rule对象添加到self._rules列表里self._rules.append(rule)# 把endpoint和rule的映射加到属性self._rules_by_endpoint里self._rules_by_endpoint.setdefault(rule.endpoint, []).append(rule)self._remap = Truedef bind(self,server_name: str,script_name: t.Optional[str] = None,subdomain: t.Optional[str] = None,url_scheme: str = "http",default_method: str = "GET",path_info: t.Optional[str] = None,query_args: t.Optional[t.Union[t.Mapping[str, t.Any], str]] = None,) -> "MapAdapter":"""返回一个新的类MapAdapter"""server_name = server_name.lower()if self.host_matching:if subdomain is not None:raise RuntimeError("host matching enabled and a subdomain was provided")elif subdomain is None:subdomain = self.default_subdomainif script_name is None:script_name = "/"if path_info is None:path_info = "/"try:server_name = _encode_idna(server_name) # type: ignoreexcept UnicodeError as e:raise BadHost() from ereturn MapAdapter(self,server_name,script_name,subdomain,url_scheme,path_info,default_method,query_args,)
Map类有两个个非常重要的属性:
self._rules,属性是一个列表,存储了一系列Rule对象;self._rules_by_endpoint:
其中有个核心方法add(),这里就是我们分析app.add_url_rule()方法是第4步调用的方法。后面会详细讲解。
(5)分析MapAdapter类
在Map类中,会用到MapAdapter类,下面我们认识下这个类:
class MapAdapter:"""`Map.bind`或`Map.bind_to_environ` 会返回这个类主要用来做匹配"""def match(self,path_info: t.Optional[str] = None,method: t.Optional[str] = None,return_rule: bool = False,query_args: t.Optional[t.Union[t.Mapping[str, t.Any], str]] = None,websocket: t.Optional[bool] = None,) -> t.Tuple[t.Union[str, Rule], t.Mapping[str, t.Any]]:"""匹配请求的路由和Rule对象"""# 只摘摘录了主要代码,省略了大量代码...# 这里是主要步骤:遍历map对象的rule列表,依次和path进行匹配for rule in self.map._rules:try:# 调用rule对象的match方法返回匹配结果rv = rule.match(path, method)except RequestPath as e:# 下面省略了大量代码...# 返回rule对象(或endpoint)和匹配的路由结果if return_rule:return rule, rvelse:return rule.endpoint, rvMap.bind或Map.bind_to_environ 方法会返回MapAdapter对象。
其中MapAdapter对象核心方法是match,主要步骤是遍历map对象的rule列表,依次和path进行匹配,当然也是调用rule对象的match方法返回匹配结果。
接下来可以稍微独立的看下Map类和Rlue对象联合起来怎么用,看下面一个例子:
from werkzeug.routing import Map, Rulem = Map([Rule('/', endpoint='index'),Rule('/blog', endpoint='blog/index'),Rule('/blog/<int:id>', endpoint='blog/detail')
])# 返回一个MapAdapter对象
map_adapter = m.bind("example.com", "/")# MapAdapter对象的 match方法会返回匹配的结果
print(map_adapter.match("/", "GET"))
# ('index', {})print(map_adapter.match("/blog/42"))
# ('blog/detail', {'id': 42})print(map_adapter.match("/blog"))
# ('blog/index', {})
可以看到,Map对象通过bind返回了一个MapAdapter对象,MapAdapter对象的match方法可以找到路由匹配的结果。
(6)分析 url_rule_class()
add_url_rule的第一个主要步骤就是rule = self.url_rule_class(rule, methods=methods, **options),即创建一个Rule对象。
在分析Rlue类的时候,知道了Rule对象主要有string(路由字符串)、methods、endpoint3个属性。在下面以一个具体的示例,看下实例化的Rule对象是什么样子的。
还是一开始最上面的示例,我们看下通过@app.route('/')代码后到实例化Rule对象的时候,这个对象的具体属性,通过debug如下:
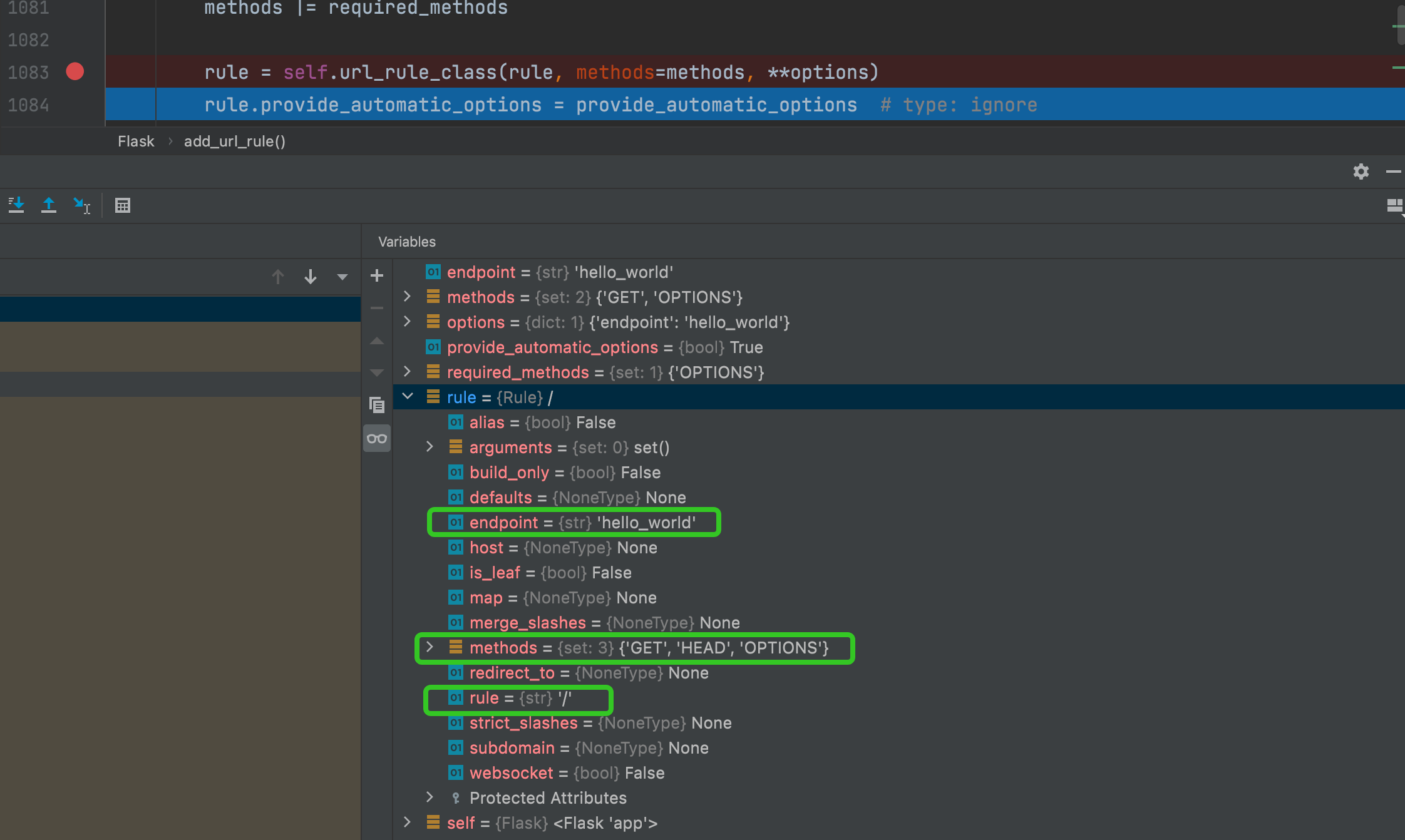
可以看到,rule对象的rule属性是传的路由,endpoint属性是通过函数名获取的,method属性是支持的请求方法,'HEAD’和OPTIONS是默认添加的。
(7)分析map.add(rule)
add_url_rule的第二个主要步骤就是self.url_map.add(rule),即调用Map对象的add方法。
在第4步分析Map对象时,有提到过,现在再回头仔细看下这个方法做了什么:
def add(self, rulefactory: RuleFactory) -> None:"""把Rule对象或一个RuleFactory对象添加到map并且绑定到map,要求rule没被绑定过"""for rule in rulefactory.get_rules(self):# 调用rule对象的bind方法rule.bind(self)# 把rule对象添加到self._rules列表里self._rules.append(rule)# 把endpoint和rule的映射加到属性self._rules_by_endpoint里self._rules_by_endpoint.setdefault(rule.endpoint, []).append(rule)self._remap = True
其实主要就是 把上一步实例化的Rule对象或一个RuleFactory对象添加到Map对象并且绑定到map。
主要做了两件事:
- 调用rule对象的bind方法
rule.bind(self):在分析Rule类时,提到过这个方法,它主要作用是把map对象绑定到Rule对象上,并且根据rule和map信息创建一个正则表达式(Rule对象的self._regex属性)。 - 把rule对象添加到
Map对象的self._rules列表里; - 把
endpoint和rule的映射加到Map对象的属性self._rules_by_endpoint(一个字典)里;
我们可以通过示例看下Map对象在add之后变成了什么样,通过debug,结果如下:

可以看到,Map的self._rules和self._rules_by_endpoint属性都含有新加的’/'路由对应的数据(其中/static/<path:filename>是默认添加的静态文件的位置路由)。
上面就分析完了,如何添加一个路由映射的。
2 请求进来时路由匹配过程
(1)分析wsgi_app
下面分析下,当前一个请求进来时,如何根据前面Map和Rlue对象来进行路由匹配的。
上一章中我们分析了当请求进来时会先经过wsgi服务器处理完请求后调用Flask app的__call__方法,其代码如下:
def __call__(self, environ: dict, start_response: t.Callable) -> t.Any:"""The WSGI server calls the Flask application object as theWSGI application. This calls :meth:`wsgi_app`, which can bewrapped to apply middleware."""return self.wsgi_app(environ, start_response)
可以看到其实就是调用了app的wsgi_app()方法。其代码如下:
def wsgi_app(self, environ: dict, start_response: t.Callable) -> t.Any:# 1.获取请求上下文ctx = self.request_context(environ)error: t.Optional[BaseException] = Nonetry:try:# 2.调用请求上下文的push方法ctx.push()# 3.调用full_dispatch_request()分发请求,获取响应结果response = self.full_dispatch_request()except Exception as e:error = eresponse = self.handle_exception(e)except: error = sys.exc_info()[1]raisereturn response(environ, start_response)finally:if self.should_ignore_error(error):error = Nonectx.auto_pop(error)
其中有3个主要步骤:
- 获取请求上下文:
ctx = self.request_context(environ) - 调用请求上下文的push方法:
ctx.push() - 调用full_dispatch_request()分发请求,获取响应结果:
response = self.full_dispatch_request()
下面来逐个分析下每个步骤的作用。
(2)分析request_context
wsgi_app方法的第一个主要步骤。
这个方法主要就是获取一个上下文对象。
需要把environ(环境变量等)传入到方法中。上下文在Flask中也是一个重要的概念,当然关于上下文的解析下章会重点解析。此章只关注我们我们需要的。
def request_context(self, environ: dict) -> RequestContext:return RequestContext(self, environ)
此方法就是创建一个RequestContext对象。RequestContext类部分源码如下:
class RequestContext:def __init__(self,app: "Flask",environ: dict,request: t.Optional["Request"] = None,session: t.Optional["SessionMixin"] = None,) -> None:self.app = appif request is None:request = app.request_class(environ)self.request = requestself.url_adapter = Nonetry:# 此处是重点,调用了Falsk对象的create_url_adapter方法获取了MapAdapter对象self.url_adapter = app.create_url_adapter(self.request)except HTTPException as e:self.request.routing_exception = eself.flashes = Noneself.session = session# 其他代码省略...# 其他方法的源码省略...
在创建RequestContext对象的初始化方法中,有个很重要的步骤就是获取MapAdapter对象。
前面第4节我们分析过它的作用,主要就是用来匹配路由的。
下面我们看下create_url_adapter源码:
def create_url_adapter(self, request: t.Optional[Request]
) -> t.Optional[MapAdapter]:if request is not None:if not self.subdomain_matching:subdomain = self.url_map.default_subdomain or Noneelse:subdomain = None# 此处是重点,调用了Map对象的bind_to_environ方法return self.url_map.bind_to_environ(request.environ,server_name=self.config["SERVER_NAME"],subdomain=subdomain,)if self.config["SERVER_NAME"] is not None:# 此处是重点,调用了Map对象的bind方法return self.url_map.bind(self.config["SERVER_NAME"],script_name=self.config["APPLICATION_ROOT"],url_scheme=self.config["PREFERRED_URL_SCHEME"],)return None
可以看到,这个方法的主要作用就是调用Map对象的bind_to_environ方法或bind方法。前面讲Map类的时候也分析过,这两个方法主要是返回了MapAdapter对象。
(3)分析ctx.push
wsgi_app方法的第二个主要步骤。
wsgi方法里获取到上下文对象后,就调用了push方法,其代码如下(只保留了核心代码):
class RequestContext:def __init__(self,app: "Flask",environ: dict,request: t.Optional["Request"] = None,session: t.Optional["SessionMixin"] = None,) -> None:# 代码省略passdef match_request(self) -> None:try:# 1.调用了MapAdapter对象的match方法,返回了rule对象和参数对象result = self.url_adapter.match(return_rule=True) # 2.把rule对象和参数对象放到请求上下文中self.request.url_rule, self.request.view_args = resultexcept HTTPException as e:self.request.routing_exception = edef push(self) -> None:"""Binds the request context to the current context."""# 此处省略了前置校验处理代码(上下文、session等处理)if self.url_adapter is not None:# 调用了match_request方法self.match_request()
可以看到push方法主要是调用了match_request方法,这个方法主要做了如下两件事:
- 调用了MapAdapter对象的match方法,会根据
Map对象存储的路由信息去匹配当前请求的路由,返回了rule对象和参数对象。 - 把rule对象和参数对象放到请求上下文中。
(4)分析full_dispatch_request
wsgi_app方法的第三个主要步骤。
full_dispatch_request方法源码如下:
def full_dispatch_request(self) -> Response:self.try_trigger_before_first_request_functions()try:request_started.send(self)rv = self.preprocess_request()if rv is None:# 这里是主要的步骤:分发请求rv = self.dispatch_request()except Exception as e:rv = self.handle_user_exception(e)return self.finalize_request(rv)
其中dispatch_request()是核心方法。
dispatch_request()方法源码如下:
def dispatch_request(self) -> ResponseReturnValue:# 1.获取请求上下文对象req = _request_ctx_stack.top.requestif req.routing_exception is not None:self.raise_routing_exception(req)# 2.从上下文中获取前面存在里面的Rule对象rule = req.url_rule# if we provide automatic options for this URL and the# request came with the OPTIONS method, reply automaticallyif (getattr(rule, "provide_automatic_options", False)and req.method == "OPTIONS"):return self.make_default_options_response()# 这里是重点:根据rule对象的endpoint属性从self.view_functions属性中获取对应的视图函数,# 然后把上下文中的参数传到视图函数中并调用视图函数处理请求,返回处理结果return self.ensure_sync(self.view_functions[rule.endpoint])(**req.view_args)
这个方法主要步骤如下:
req = _request_ctx_stack.top.request:获取请求上下文对象rule = req.url_rule:从上下文中获取前面存在里面的Rule对象,就是ctx.push()方法放进上下文的- 根据rule对象的endpoint属性从self.view_functions属性中获取对应的视图函数,然后把上下文中的参数传到视图函数中并调用视图函数处理请求,返回处理结果:
return self.ensure_sync(self.view_functions[rule.endpoint])(**req.view_args)
至此,一个完整的请求就处理完啦。
3 总结
根据以上分析,对路由规则和请求匹配总结如下:
应用启动时:
app.route()调用add_url_rule方法。add_url_rule方法里:调用self.url_rule_class()实例化Rule对象;add_url_rule方法里:调用self.url_map.add()方法,把Rule对象、endpoint与视图函数的映射关系存储到Map对象中。add_url_rule方法里:self.view_functions[endpoint] = view_func添加endpoint和view_func的映射。
请求匹配过程:
- 请求进来时有
WSGI服务器处理并调用了Flask app的__call__方法,再调用了wsgi_app方法; wsgi_app方法里创建一个上下文对象:ctx = self.request_context(environ)。然后实例化了MapAdapter对象作为上下文对象属性;wsgi_app方法里调用上下文对象的push方法:ctx.push()。这个方法主要使用MapAdapter对象的match方法。MapAdapter对象的match方法,去调用rule对象的match方法。这个方法根据Map对象存储的路由信息去匹配当前请求的路由,得到了rule对象和参数对象放到上下文对象里。wsgi_app方法里调用full_dispatch_request方法,然后里面再调用dispatch_request()方法;dispatch_request()方法里:获取请求上下文对象,拿到里面的Rule对象,根据rule对象的endpoint属性从self.view_functions属性中获取对应的视图函数,然后把上下文中的参数传到视图函数中并调用视图函数处理请求,返回处理结果。
整个流程图如下:
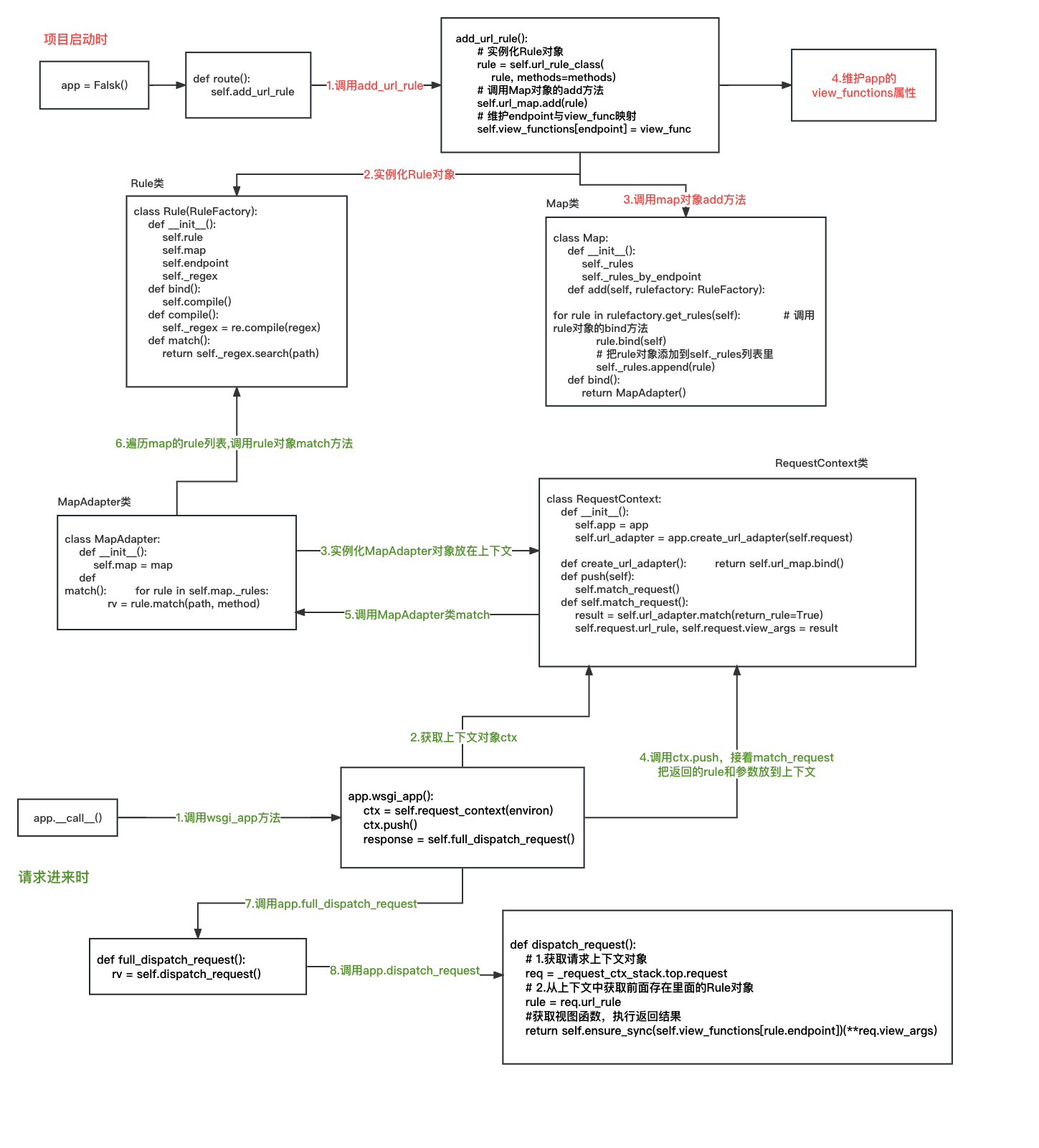
其中上半部分项目启动时如何使用Rule和Map对象建立路由规则;下半部分是请求进来时,如何使用路由规则进行匹配。
相关文章:
Flask源码篇:Flask路由规则与请求匹配过程(超详细,易懂)
目录1 启动时路由相关操作(1)分析app.route()(2)分析add_url_rule()(3)分析Rule类(4)分析Map类(5)分析MapAdapter类(6)分析 url_rule_…...

Jmeter接口测试教程之【参数化技巧总结】,总有一个是你不知道的
目录:导读 一、随机值 二、随机字符串 三、时间戳 四、唯一字符串UUID 说起接口测试,相信大家在工作中用的最多的还是Jmeter。 大家看这个目录就知道jmeter的应用有多广泛了:https://www.bilibili.com/video/BV1e44y1X78S/? JMeter是一个…...

缓存与数据库的双写一致性
背景 在高并发的业务场景下,系统的性能瓶颈往往是出现在数据库上,用户并发访问过大,压力都打到数据库上。所以一般都会用redis做缓存层,起到一个缓冲作用,让请求先访问到缓存层,而不是直接去访问数据库&am…...
)
力扣-213打家劫舍II(dp)
力扣-213打家劫舍II 1、题目 213. 打家劫舍 II 你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通…...
关于【网格结构】岛屿类问题的通用解法DFS(深度遍历)遍历框架+回溯+剪枝总结
最近在刷力扣时遇见的问题,自己总结加上看了力扣大佬的知识总结写下本篇文章,我们所熟悉的 DFS(深度优先搜索)问题通常是在树或者图结构上进行的。而我们今天要讨论的 DFS 问题,是在一种「网格」结构中进行的。岛屿问题…...

【LeetCode】982. 按位与为零的三元组
982. 按位与为零的三元组 题目描述 给你一个整数数组 nums ,返回其中 按位与三元组 的数目。 按位与三元组 是由下标 (i, j, k) 组成的三元组,并满足下述全部条件: 0 < i < nums.length0 < j < nums.length0 < k < num…...

Linux内核源码进程原理分析
Linux内核源码进程原理分析一、Linux 内核架构图二、进程基础知识三、Linux 进程四要素四、task_struct 数据结构主要成员五、创建新进程分析六、剖析进程状态迁移七、写时复制技术一、Linux 内核架构图 二、进程基础知识 Linux 内核把进程称为任务(task),进程的虚…...

电子技术——CMOS反相器
电子技术——CMOS反相器 在本节,我们深入学习CMOS反相器。 电路原理 下图是我们要研究的CMOS反相器的原理图: 下图展示了当输入 vIVDDv_I V_{DD}vIVDD 时的 iD−vDSi_D-v_{DS}iD−vDS 曲线: 我们把 QNQ_NQN 当做是驱动源&#x…...
)
gazebo仿真轨迹规划+跟踪(不在move_base框架下)
以Tianbot为例子,开源代码如下: https://github.com/tianbot/tianbot_mini GitHub - tianbot/abc_swarm: Ant Bee Cooperative Swarm, indicating air-ground cooperation. This repository is for Tianbot Mini and RoboMaster TT swarm kit. 1.在…...

C. Good Subarrays(前缀和)
C. Good Subarrays一、问题二、分析三、代码一、问题 二、分析 这道题目的意思就是给我们一个数组,然后我们从数组中选取一个连续的区间,这个区间满足条件:区间内的元素和等于区间的长度。 对于区间和问题我们先想到的是前缀和的算法。 那…...
关于Facebook Messenger CRM,这里有你想要知道的一切
关于Facebook Messenger CRM,这里有你想要知道的一切!想把Facebook Messenger与你的CRM整合起来吗?这篇博文是为你准备的! 我们将介绍有关获得Facebook Messenger CRM整合的一切信息。然后,我们将解释为什么你需要像SaleSmartly&a…...
ChIP-seq 分析:数据与Peak 基因注释(10)
动动发财的小手,点个赞吧! 1. 数据 今天,我们将继续回顾我们在上一次中研究的 Myc ChIPseq。这包括用于 MEL 和 Ch12 细胞系的 Myc ChIPseq。 可在此处[1]找到 MEL 细胞系中 Myc ChIPseq 的信息和文件可在此处[2]找到 Ch12 细胞系中 Myc ChIP…...
)
《C++ Primer Plus》第18章:探讨 C++ 新标准(8)
使用大括号括起的初始化列表语法重写下述代码。重写后的代码不应使用数组 ar: class Z200 { private:int j;char ch;double z; public:Z200(int jv, char chv, zv) : j(jv), ch(chv), z(zv) {} ... };double x 8.8; std::string s "What a bracing effect!&q…...
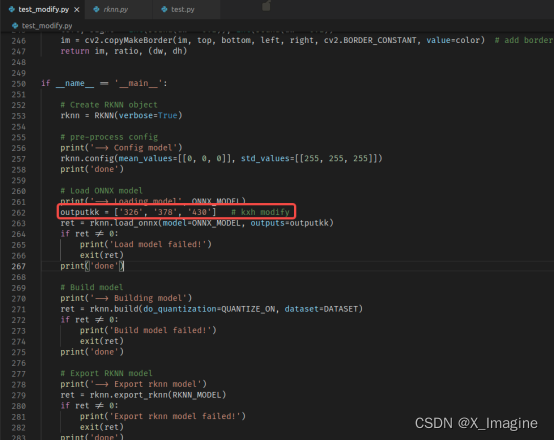
YOLO-V5 系列算法和代码解析(八)—— 模型移植
文章目录工程目标芯片参数查阅官方文档基本流程Python 版工具链安装RKNPU2的编译以及使用方法移植自己训练的模型工程目标 将自己训练的目标检测模型【YOLO-V5s】移植到瑞芯微【3566】芯片平台,使用NPU推理,最终得到正确的结果。整个过程涉及模型量化、…...

js实现复制拷贝的兼容方法
1. 定义复制拷贝的方法 在某个工具类方法中定义该方法,兼容不同浏览器处理 /*** description 拷贝的类方法*/ class CopyClass {// constructor() {}setRange(input) {return new Promise((resolve, reject) > {try {// 创建range对象const range document.c…...
学习 Python 之 Pygame 开发魂斗罗(八)
学习 Python 之 Pygame 开发魂斗罗(八)继续编写魂斗罗1. 创建敌人类2. 增加敌人移动和显示函数3. 敌人开火4. 修改主函数5. 产生敌人6. 使敌人移动继续编写魂斗罗 在上次的博客学习 Python 之 Pygame 开发魂斗罗(七)中࿰…...
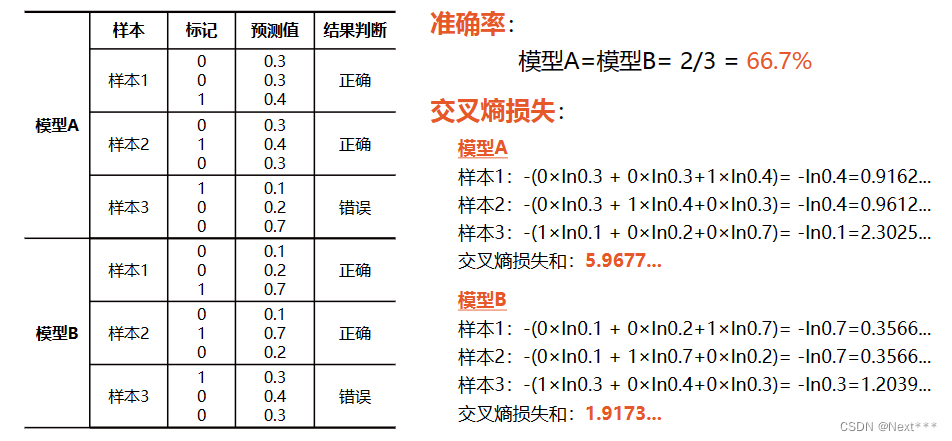
Lesson11---分类问题
11.1 逻辑回归 11.1.1 广义线性回归 课程回顾 线性回归:将自变量和因变量之间的关系,用线性模型来表示;根据已知的样本数据,对未来的、或者未知的数据进行估计 11.1.2 逻辑回归 11.1.2.1 分类问题 分类问题:垃圾…...

Python基础学习12——异常
在Python中,会使用“异常”这个十分特殊的对象来管理程序执行期间发生的错误,即报错。本文将介绍一下python基础的处理异常的方法以及一些基本的异常类型。 异常处理方法 try-except代码块 当我们编写程序时,我们可以编写一个try-except代…...

[日常练习]练习17:链表头插法、尾插法练习
[日常练习]练习17:链表头插法、尾插法练习练习17描述输入输出输入示例1输出示例1输入示例2输出示例2代码演示:总结练习17 【日常练习】 链表头插法、尾插法练习 描述 输入3 4 5 6 7 9999一串整数,9999代表结束,通过头插法新建链…...
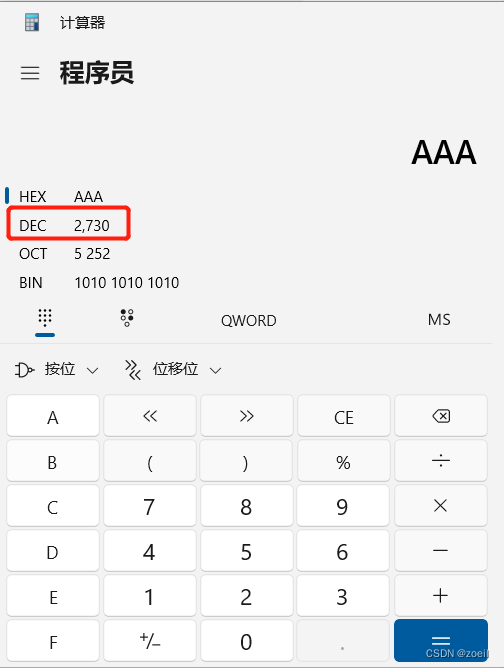
第十四届蓝桥杯模拟赛(第三期)试题与题解 C++
目录 一、填空题 (一)最小的十六进制(答案:2730) (二)Excel的列(答案:BYT) (三)相等日期(答案:70910) (四)多少种取法(答案:189)…...

PyTorch矩阵操作小技巧:用torch.triu和torch.tril快速提取邻接矩阵的上下三角部分
PyTorch矩阵操作实战:高效处理邻接矩阵的三角部分提取技巧 邻接矩阵是图神经网络(GNN)和社交网络分析中最基础的数据结构之一。在处理无向图时,我们常常需要提取邻接矩阵的上三角或下三角部分来避免重复计算或进行特定操作。PyTor…...

手把手教你用Python实现熵权PCA:从数据清洗到可视化,一个案例全讲透
用Python实战熵权PCA:电商商品竞争力分析全流程解析 在电商平台的海量商品中,如何快速识别出真正具有竞争力的产品?传统的人工筛选方式不仅效率低下,还容易受到主观偏见的影响。本文将带你用Python实现一个完整的熵权PCA分析流程&…...

QRCoder:开发者必备的二维码生成解决方案全攻略
QRCoder:开发者必备的二维码生成解决方案全攻略 【免费下载链接】QRCoder A pure C# Open Source QR Code implementation 项目地址: https://gitcode.com/gh_mirrors/qr/QRCoder 在数字化时代,二维码已成为信息传递的重要桥梁,但如何…...

从HTTP到字节流:ESP32与App Inventor通信协议的效率优化实践
1. 为什么需要优化ESP32与App Inventor的通信协议? 当你用ESP32和App Inventor做一个遥控小车时,最让人抓狂的就是按下按钮后小车要等半秒才有反应。这种延迟问题在HTTPJSON通信方案中非常典型。我去年做过一个智能家居控制系统,最初用的就是…...

揭秘Figma-MCP与ClaudeCode:驱动像素级UI还原的协议与智能引擎
1. Figma-MCP协议:设计到代码的桥梁 Figma-MCP协议是连接设计工具与开发环境的关键纽带。我第一次接触这个协议时,就被它解决设计还原痛点的能力震撼了。传统开发流程中,设计师在Figma里精心打磨的界面,到了开发阶段往往要经历痛苦…...
)
YOLOv8特征可视化实战:如何用3种合并模式优化模型调试(附完整代码)
YOLOv8特征可视化实战:3种合并模式优化模型调试的工程实践 在计算机视觉领域,理解神经网络内部工作机制一直是提升模型性能的关键。YOLOv8作为当前最先进的实时目标检测框架之一,其内部特征层的可视化分析能够为模型调试提供直观依据。然而&a…...

【esp32使用jtag下载和调试 Can‘t perform JTAG flash, because OpenOCD server is not running!】
ESP-IDF使用USB的JTAG下载调试时报错现象。 2026年初尝试了很多方法jtag下载,网上很多资料都有问题,以下实操烧录成功过程记录。 提示: Can’t perform JTAG flash, because OpenOCD server is not running! ❌ Error: libusb_open() faile…...

aibye爱毕业推出六大顶尖平台评测,智能润色与高效创作功能一键实现,科研领域不可或缺的AI助手
工具名称 核心功能 特色优势 Aibiye 论文生成降AI率 全学科覆盖、仿写优化、自动图表生成 Aicheck AI检测文献综述辅助 精准查新、3分钟高效成文 GPT学术版 润色/翻译/代码解释 多模型协同、PDF深度解析 摆平论文 大纲生成降重改写 三步出稿、本硕博通用 QuillB…...

OpenClaw对话式编程:Qwen3-32B私有镜像调试代码
OpenClaw对话式编程:Qwen3-32B私有镜像调试代码 1. 为什么选择OpenClawQwen3-32B组合 去年我在重构一个Python数据分析项目时,每天要花大量时间反复执行"写代码-调试-优化"的循环。传统IDE的补全功能对复杂业务逻辑帮助有限,直到…...

3步解放双手:崩坏星穹铁道自动化工具让资源收集效率提升200%
3步解放双手:崩坏星穹铁道自动化工具让资源收集效率提升200% 【免费下载链接】StarRailAssistant 崩坏:星穹铁道自动化 | 崩坏:星穹铁道自动锄大地 | 崩坏:星穹铁道锄大地 | 自动锄大地 | 基于模拟按键 项目地址: https://gitco…...